
並發編程可以讓開發者實現並行的算法以及編寫充分利用多處理器和多核性能的程序。在當前大部分主流的編程語言裡,如C、C++、Java等,編寫、維護和調試並發程序相比單線程程序而言要困難很多。而且,也不可能總是為了使用多線程而將一個過程切分成更小的粒度來處理。不管怎麼說,由於線程本身的性能損耗,多線程編程不一定能夠達到我們想要的性能,而且很容易犯錯誤。
一種解決辦法就是完全避免使用線程。例如,可以使用多個進程將重擔交給操作系統來處理。但是,這裡有個劣勢就是,我們必須處理所有進程間通信,通常這比共享內存的並發模型有更多的開銷。
Go語言的解決方案有3個優點。首先,Go語言對並發編程提供了上層支持,因此正確處理並發是很容易做到的。其次,用來處理並發的goroutine比線程更加輕量。第三,並發程序的內存管理有時候是非常複雜的,而Go語言提供了自動垃圾回收機制,讓程序員的工作輕鬆很多。
Go語言為並發編程而內置的上層API基於CSP模型(Communicating Sequential Processes)。這就意味著顯式鎖(以及所有在恰當的時候上鎖和解鎖所需要關心的東西)都是可以避免的,因為 Go語言通過線程安全的通道發送和接受數據以實現同步。這大大地簡化了並發程序的編寫。還有,通常一個普通的桌面計算機跑十個二十個線程就有點負載過大了,但是同樣這台機器卻可以輕鬆地讓成百上千甚至過萬個goroutine進行資源競爭。Go語言的做法讓程序員理解自己的程序變得更加容易,他們可以從自己希望程序實現什麼樣的功能來推斷,而不是從鎖和其他更底層的東西來考慮。
雖然其他大部分語言對非常底層的並發操作(原子級的兩數相加、比較、交換等)和其他一些底層的特性例如互斥量都提供了支持,但是在主流語言裡,還沒有在語言層面像 Go語言一樣直接支持並發操作的(以附加庫方式存在的方式並不能算是語言的組成部分)。
除了作為本章主題的Go語言在較高層次上對並發的支持以外,Go和其他語言一樣也提供了對底層功能的支持。在標準庫的sync/atomic包裡提供了最底層的原子操作功能,包括相加、比較和交換操作。這些高級功能是為了支持實現線程安全的同步算法和數據結構而設計的,但是這些並不是給程序員準備的。Go語言的sync包還提供了非常方便的底層並發原語:條件等待和互斥量。這些和其他大多數語言一樣屬於較高層次的抽像,因此程序員通常必須使用它們。
Go語言推薦程序員在並發編程時使用語言的上層功能,例如通道和goroutine。此外, sync.Once 類型可以用來執行一次函數調用,不管程序中調用了多少次,這個函數只會執行一次,還有sync.WaitGroup類型提供了一個上層的同步機制,後面我們會看到。
在第5章(5.4節)我們就已經接觸過通道和goroutine的基本用法,已經講過的內容不會在這裡再講一遍,但是內容主要還是這些,所以如果能快速複習一遍之前講過的內容也許會很有幫助。
這一章我們首先對Go語言並發編程的幾個關鍵概念做一個大概的瞭解,然後還有5個關於並發編程的完整程序作為示例,並展示了 Go語言中並發編程的範式。第一個例子展示了如何創建一個管道,為了最大化管道的吞吐量,管道裡每一部分都各自執行一個獨立的goroutine。第二個例子展示了怎麼將一個工作切分成讓固定的若干個goroutine去完成,而每部分的輸出結果都是獨立的。第三個例子展示了如何創建一個線程安全的數據結構,不需要使用鎖或者其他底層的原語。第四個例子使用了3種不同的方法,展示了如何使用固定的若干個goroutine來獨立處理其中的一部分工作,並將最終的結果合併在一塊。第五個例子展示了如何根據需要來動態創建goroutine並將每個goroutine的工作輸出到一個結果集中。
7.1 關鍵概念
在並發編程裡,我們通常想將一個過程切分成幾塊,然後讓每個goroutine各自負責一塊工作,除此之外還有main函數也是由一個單獨的goroutine 來執行的(為了方便起見,我們將main函數所在的goroutine稱為主goroutine,其他附加創建用來負責處理相應工作的goroutine簡稱為工作goroutine,以後如果沒有特別說明,我們統一沿用這種叫法,雖然本質上它們都是一樣的)。每個工作goroutine執行完畢後可以立即將結果輸出,或者所有的工作goroutine都完成後再做統一處理。
儘管我們使用Go語言上層的API來處理並發,但仍有必要去避免一些陷阱。例如,其中一個常見的問題就是很可能當程序完成時我們沒有得到任何結果。因為當主goroutine退出後,其他的工作 goroutine 也會自動退出,所以我們必須非常小心地保證所有工作 goroutine 都完成後才讓主goroutine退出。
另一個陷阱就是容易發生死鎖,這個問題有一點和第一個陷阱是剛好相反的,就是即使所有的工作已經完成了,但是主 goroutine和工作 goroutine 還存活,這種情況通常是由於工作完成了但是主 goroutine 無法獲得工作 goroutine的完成狀態。死鎖的另一種情況就是,當兩個不同的goroutine(或者線程)都鎖定了受保護的資源而且同時嘗試去獲得對方資源的時候,如圖7-1所示。也就是說,只有在使用鎖的時候才會出現,所以這種風險一般在其他語言裡比較常見,但在Go語言裡並不多,因為Go程序可以使用通道來避免使用鎖。
為了避免程序提前退出或不能正常退出,常見的做法是讓主goroutine在一個done通道上等待,根據接收到的消息來判斷工作是否完成了(我們馬上就能看到,7.2.2節和7.2.4節也有介紹,也可以使用一個哨兵值作為最後一個結果發送,不過相對其他辦法來說這就顯得有點拙劣了)。
另外一種避免這些陷阱的辦法就是使用sync.WaitGroup來讓每個工作goroutine報告自己的完成狀態。但是,使用sync.WaitGroup本身也會產生死鎖,特別是當所有工作goroutine都處於鎖定狀態的時候(等待接受通道的數據)調用 sync.WaitGroup.Wait。後面我們會看到如何使用sync.WaitGroup(參見7.2.5節)。
就算只使用通道,在Go語言裡仍然可能發生死鎖。舉個例子,假如我們有若干個goroutine可以相互通知對方去執行某個函數(向對方發一個請求),現在,如果這些被請求執行的函數中有一個函數向執行它的goroutine發送了一些東西,例如數據,死鎖就發生了。如圖7-2所示(後面我們還會看到這種死鎖的另一種情況)。
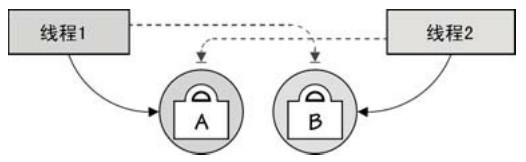
圖7-1 死鎖:兩個或多個阻塞線程試圖取得對方的鎖
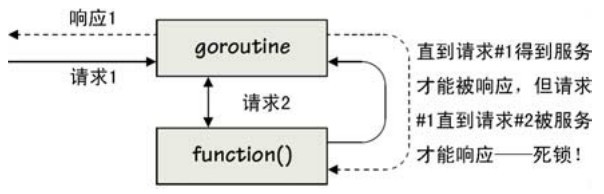
圖7-2 死鎖:一個試圖用對自身的請求來服務於請求的goroutine
通道為並發運行的goroutine之間提供了一種無鎖通信方式(儘管實現內部可能使用了鎖,但無需我們關心)。當一個通道發生通信時,發送通道和接受通道(包括它們對應的goroutine)都處於同步狀態。
默認情況下,通道是雙向的,也就是說,既可以往裡面發送數據也可以從裡面接收數據。但是我們經常將一個通道作為參數進行傳遞而只希望對方是單向使用的,要麼只讓它發送數據,要麼只讓它接收數據,這個時候我們可以指定通道的方向。例如,chan<- Type 類型就是一個只發送數據的通道。我們之前的章節裡並沒有這樣用過,一來沒這個必要,用 chan Type就行,二來還有很多其他的東西要學習。但是從現在開始,我們會在所有合適的地方使用單向的通道,因為它們會提供額外的編譯期檢查,這是非常好的處理方式。
本質上說,在通道裡傳輸布爾類型、整型或者 float64 類型的值都是安全的,因為它們都是通過複製的方式來傳送的,所以在並發時如果不小心大家都訪問了一個相同的值,這也沒有什麼風險。同樣,發送字符串也是安全的,因為Go語言裡不允許修改字符串。
但是Go語言並不保證在通道裡發送指針或者引用類型(如切片或映射)的安全性,因為指針指向的內容或者所引用的值可能在對方接收到時已被發送方修改。所以,當涉及指針和引用時,我們必須保證這些值在任何時候只能被一個goroutine訪問得到,也就是說,對這些值的訪問必須是串行進行的。除非文檔特別聲明傳遞這個指針是安全的,比如,*regexp.Regexp 可以同時被多個goroutine訪問,因為這個指針指向的值的所有方法都不會修改這個值的狀態。
除了使用互斥量實現串行化訪問,另一種辦法就是設定一個規則,一旦指針或者引用發送之後發送方就不會再訪問它,然後讓接收者來訪問和釋放指針或者引用指向的值。如果雙方都有發送指針或者引用的話,那就發送方和接受方都要應用這種機制(我們會在7.2.4.3節看到一個使用這個機制的例子),這種方法的問題就是使用者必須足夠自律。第三種安全傳輸指針和引用的方法就是讓所有導出的方法不能修改其值,所有可修改值的方法都不引出。這樣外部可以通過引出的這些方法進行並發訪問,但是內部實現只允許一個goroutine去訪問它的非導出方法(例如在它們的包裡,包將會在第9章介紹)。
Go語言裡還可以傳送接口類型的值,也就是說,只要這個值實現了接口定義的所有方法,就可以以這個接口的方式在通道裡傳輸。只讀型接口的值可以在任意多個goroutine裡使用(除非文檔特別聲明),但是對於某些值,它雖然實現了這個接口的方法,但是某些方法也修改了這個值本身的狀態,就必須和指針一樣處理,讓它的訪問串行化。
舉個例子,如果我們使用 image.NewRGBA函數來創建一個新的圖片,我們得到一個*image.RGBA類型的值。這個類型實現了image.Image接口定義的所有方法(只有一個讀取的方法,理所當然是只讀型的接口)和draw.Image接口(這個接口除了實現了image.Image接口的所有方法之外,還實現了一個 Set方法)。所以如果我們只是讓某個函數去訪問一個image.Image值的話,我們可以將這個 *image.RGBA值隨意發送給多個goroutine。(不幸的是,這種安全性是隨時可以顛覆的,比如說,接受方可以使用一個類型斷言將這個值轉換成draw.Image 接口類型,因此,就必須要有一種機制能防止這種事情的發生。)或者我們希望在多個 goroutine 裡訪問甚至修改同一個*image.RGBA的值,就應該以 *image.RGBA 或者draw.Image類型來傳送,不管哪種方式,都必須讓這個值的訪問是串行的。
使用並發的最簡單的一種方式就是用一個 goroutine 來準備工作,然後讓另一個 goroutine來執行處理,讓主goroutine和一些通道來安排一切事情。例如,下面的代碼是如何在主goroutine裡創建一個名為「jobs」的通道和一個叫「done」的通道。
jobs := make(chan Job)
done := make(chan bool, len(jobList))
這裡我們創建了一個沒有緩衝區的jobs通道,用來傳遞一些自定義Job類型的值。我們還創建了一個done通道,它的緩衝區大小和任務列表的數量是相對應的,任務列表jobList是Job類型(它的初始化這裡我們沒有列出來)。
只要設置了通道和任務列表(jobList),我們就可以開始幹活了。
go func {
for _, job := range jobList {
jobs <- job // 阻塞,等待接收
}
close(jobs)
}
這段代碼創建了一個goroutine(goroutine#1),它遍歷jobList切片然後將每一個工作發送到jobs通道。因為通道是沒有緩衝的,所以goroutine#1會馬上阻塞,直到有別的goroutine從這個通道裡將任務讀取出去。發送完所有任務之後,就關閉 jobs 通道,這樣接收工作的goroutine就會知道什麼時候沒有其他工作了。
這段代碼所表達的語義還不止這些。例如,goroutine#1會直到for循環結束才關閉jobs通道,而且goroutine#1會和創建它的主goroutine並發執行。還有,go聲明語句會立即返回,主 goroutine(main函數所在的goroutine)繼續執行後面的代碼,但是由於 jobs 通道是沒有緩衝的,所以goroutine#1會反覆執行這樣一個過程:往jobs裡發送一個任務,等待任務被接收,繼續往jobs裡發送任務,等到任務被接收……直到jobList任務列表裡的所有任務都被處理完後,關閉jobs通道。顯然,從for循環開始執行到關閉jobs之間得耗一段時間。
go func {
for job := range jobs { // 等待數據發送
fmt.Println(job) // 完成一項工作
done <- true
}
}
這是我們創建的第二個goroutine(goroutine#2),遍歷jobs通道,並處理(這裡就是打印出來),然後將完成狀態true(其實什麼都可以,因為我們這裡只關心往done裡發了多少個值,而不是實際的什麼值)發送到done通道。
同理,這個go語句也是立即返回的,for循環會阻塞直到有其他的goroutine(在我們這個例子裡,發送數據的是goroutine#1)往通道裡發送了數據。此時,整個進程共有3個並發的goroutine在運行,主goroutine、goroutine#1和goroutine#2,如圖7-3所示。
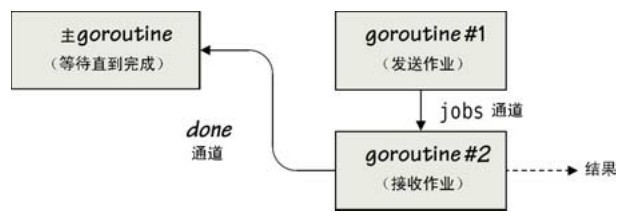
圖7-3 並發獨立的準備與處理
當goroutine#1發送了一個任務然後等待的時候,goroutine#2就直接接收過來然後處理,期間 goroutine#1 仍然阻塞,一直持續到它發送第二個工作。一旦 goroutine#2 處理完一個任務,它就往done通道裡發送一個true值。done通道是有緩衝的,所以這個發送操作不會被阻塞。控制流回到goroutine#2的for循環裡,它接收下一個從goroutine#1發送過來的工作,如此反覆,直到完成所有的工作。
for i := 0; i < len(jobList); i++ {
<-done // 阻塞,等待接收
}
主goroutine創建完兩個工作goroutine後(注意不會阻塞的,所有的goroutine並發執行),繼續執行最後一段代碼,這段代碼的目的是確保主goroutine等到所有的工作完成了才退出。
for循環迭代的次數和任務列表的大小是一樣的。每次迭代都從done通道裡接收一個值。每次迭代和處理工作都是同步的,只有一個工作被完成後 done 通道裡才有一個值可以被接收(接收到的值將被拋棄)。所有工作完成後,done 通道發送和接收數據的次數將和迭代的次數一致,此時 for 循環也將結束。這時候主 goroutine 就可以退出了,這樣我們也就保證了所有任務都能處理完畢。
對於通道的使用,我們有兩個經驗。第一,我們只有在後面要檢查通道是否關閉(例如在一個for...range循環裡,或者select,或者使用<-操作符來檢查是否可以接收等)的時候才需要顯式地關閉通道;第二,應該由發送端的goroutine 關閉通道,而不是由接收端的goroutine來完成。如果通道並不需要檢查是否被關閉,那麼不關閉這些通道並沒有什麼問題,因為通道非常輕量,因此它們不會像打開文件不關閉那樣耗盡系統資源。
例如我們這個例子就是用for...range循環來迭代讀取jobs通道的,所以我們在發送端把它給關閉了。這和我們的經驗是一致的。另外,我們沒必要關閉 done 通道,因為它後面並沒有用在什麼特別的語句裡(for...range或者select等)。
這個例子所展示的是 Go語言並發編程裡很典型的一種模式,雖然實際上這種情況下這麼做沒有什麼好處。下一章還有一些例子和這個模式是差不多的,但是卻非常適合使用並發。
7.2 例子
雖然Go語言裡使用goroutine和通道的語法很簡單,如<-、chan、go、select等,但足以應付大多數的並發場合。由於篇幅有限,本章我們無法對所有的並發編程方法都一一介紹,所以這裡我們只介紹並發編程中比較常見的3種模式,分別是管道、多個獨立的並發任務(需要或者不需要同步的結果)以及多個相互依賴的並發任務,然後我們看下它們如何使用 Go語言的並發支持來實現。
接下來的例子以及本章的練習對 Go語言並發編程實踐進行了深入的探討。你可以將這些實踐應用到其他新程序中。
7.2.1 過濾器
第一個例子用於顯示一種特定並發編程範式。這個程序可以輕鬆地擴展以完成更多其他可以從並發模型中獲益的任務。
有Unix背景的人會很容易從Go語言的通道回憶起Unix裡的管道,唯一不同的是Go語言的通道為雙向而Unix管道為單向。利用管道我們可以創建一個連續管道,讓一個程序的輸出作為另一個程序的輸入,而另一個程序的輸出還可以作為其他程序的輸入,等等。例如,我們可以使用Unix管道命令從Go源碼目錄樹裡得到一個Go文件列表(去除所有測試文件):
find $GOROOT/src -name "*.go" | grep -v test.go
這種方法的一個妙處就是可以非常容易地擴展。比如說,我們可以增加| xargs wc -l來列出每一個文件和它包含的行數,還可以用| sort -n得到一個按行數進行排序的文件列表。
真正的Unix風格的管道可以使用標準庫裡的io.Pipe函數來創建,例如Go語言標準庫裡就用管道來比較兩個圖像(在go/src/pkg/image/png/reader_test.go文件裡)。除此之外,我們還可以利用Go語言的通道來創建一個Unix風格的管道,這個例子就用到了這種技術。
filter 程序(源文件是 filter/filter.go)從命令行讀取一些參數(例如,指定文件大小的最大值最小值,以及只處理的文件後綴等)和一個文件列表,然後將符合要求的文件名輸出,main函數的主要代碼如下。
minSize, maxSize, suffixes, files := handleCommandLine
sink(filterSize(minSize, maxSize, filterSuffixes(suffixes, source(files))))
handleCommandLine函數(這裡我們未顯示相關代碼)用到了標準庫裡的flag包來處理命令行參數。第二行代碼展示了一條管道,從最裡面的函數調用(source(files)開始)到最外面的(sink函數),為了方便大家理解,我們將管道展開如下。
channel1 := source(files)
channel2 := filterSuffixes(suffixes, channel1)
channel3 := filterSize(minSize, maxSize, channel2)
sink(channel3)
傳給source函數的files是一個保存文件名的切片,然後得到一個chan string類型的通道channel1。在source函數中files裡的文件名會輪流被發送到channel1。另外兩個過濾函數都是傳入過濾條件和chan string 通道,並各自返回它們自己的chan string 通道。其中第一個過濾器返回的通道被賦值到 channel2,第二個被賦值到channel3。每個過濾器都會迭代讀傳入的通道,如果符合條件,就將結果發送到輸出通道(這個通道會被返回並可能會作為下一個過濾器的輸入源)。sink函數會提取channel3里的每一項並打印出來。

圖7-4 並發goroutine之間的管道
圖7-4簡略地闡明了整個filter程序發生了什麼事情,sink函數是在主goroutine裡執行的,而另外幾個管道函數(如source、filterSuffixes和filterSize函數)都會創建各自的goroutine 來處理自己的工作。也就是說,主 goroutine的執行過程會很快地執行到sink這裡,此時所有的goroutine都是並發執行的,它們要麼在等待發送數據要麼在等待接收數據,直到所有的文件處理完畢。
func source(files string) <-chan string {
out := make(chan string, 1000)
go func {
for _, filename := range files {
out <- filename
}
close(out)
}
return out
}
source函數創建了一個帶有緩衝區的out通道用來傳輸文件名,因為實際測試中緩衝區可以提高吞吐量(這就是我們常說的以空間換時間)。
當輸出通道創建完畢後,我們創建了一個goroutine 來遍歷文件列表並將每一個文件名發送到輸出通道。當所有的文件發送完畢之後我們將這個通道關閉。go 語句會立即返回,而且從發送第一個文件名到發送最後一個文件名還有最終關閉通道,這之間可能會有相當長的一個時間差。往通道裡發送數據是不會阻塞的(至少,發送前1000個文件時是不會阻塞的,或者說文件數小於1000時不會阻塞),但是如果要發送更多的東西,還是會阻塞的,直到至少通道裡有一個數據被接收。
之前我們提到,默認情況下通道是雙向的,但我們可將一個通道限制為單向。回憶下前一節我們講過的,chan<- Type 是一個只允許發送的通道,而<-chan Type 是一個只允許接收的通道。函數最後返回的out通道就被強制設置成了單向,我們可以從裡面接收文件名。當然,直接返回一個雙向的通道也是可以的,但我們這裡這麼做是為了更好地表達程序的思想。
go語句之後,這個新創建的goroutine就開始執行匿名函數里的工作裡,它會往out通道裡發送文件名,而當前的函數也會立即將out通道返回。所以,一旦調用source函數就會執行兩個goroutine,分別是主goroutine和在source函數里創建的那個工作goroutine。
func filterSuffixes(suffixes string, in <-chan string) <-chan string {
out := make(chan string, cap(in))
go func {
for filename := range in {
if len(suffixes) == 0 {
out <- filename
continue
}
ext := strings.ToLower(filepath.Ext(filename))
for _, suffix := range suffixes {
if ext == suffix {
out <- filename
break
}
}
}
close(out)
}
return out
}
這是兩個過濾函數中的第一個。第二個函數filterSize的代碼也是類似的,所以這裡就不顯示了。
其實參數里的in 通道是只讀或者可讀寫都是沒有關係的,不過,這裡我們在參數類型聲明時指定了in是一個只讀的通道(我們知道source函數返回的,也就是這個in通道,實際上就是一個只讀的通道)。對應地,函數最後將雙向(創建時默認就是可讀寫的)out通道以只讀的方式返回,和之前source的做法一樣。其實就算我們忽略掉所有的<-,函數也一樣可以工作,但是指定了通道的方向有助於精確地表達到底我們想讓程序做什麼事情,並借助編譯器來強製程序按照這種語義來執行。
filterSuffixes函數首先創建一個帶有緩衝區的輸出通道,通道緩衝區和輸入通道 in的大小是一樣的,以最大化吞吐量。然後程序新建一個goroutine做相應的處理。在goroutine裡,遍歷in通道(例如,輪流接收每個文件名)。如果沒有指定任何後綴的話則任意後綴的文件名我們都接收,也就是簡單地發送到輸出通道裡去。如果我們指定了文件名的後綴,那麼只有匹配的文件名(大小寫不敏感)才會發送到輸出通道,其他的則被丟棄。(filepath.Ext函數返回文件名的擴展名,也就是它的後綴,包括前導的句點,如果沒有匹配的話就返回一個空的字符串。)
和source函數一樣,一旦所有的處理完畢,輸出通道就會被關閉,儘管還需要一些時間才會執行到這裡。創建goroutine之後輸出通道就被函數返回了,這樣管道就能從這裡接收文件名。
這時,有3個goroutine會在運行,它們是主goroutine和source函數里的goroutine,以及這個函數里的goroutine。filterSize函數調用之後就會有4個goroutine,它們都會並發地執行。
func sink(in <-chan string) {
for filename := range in {
fmt.Println(filename)
}
}
source函數和兩個過濾函數分別在它們各自的goroutine裡並發處理,並通過通道來進行通信。sink函數在主goroutine裡處理其它函數返回的最後一個通道,它迭代讀取成功通過所有過濾器的文件名並進行相應輸出。
sink函數的range語句遍歷一個只讀通道,將文件名打印出來或者等待通道被關閉,這樣就可以保證主goroutine在所有工作goroutine處理完畢之前不會提前退出。
自然地,我們可以給管道增加一些額外的函數,例如過濾文件名或者處理到目前為止所有通過了過濾器的文件。只要這個函數能接收一個輸入通道(前一個函數的輸出通道)和返回它自己的輸出通道。當然,如果我們想傳一些更複雜的值,我們也可以讓通道傳輸的是一個結構而不是一個簡單的字符串。
雖然這一節裡的管道程序是一個管道框架非常好的示例,不過由於每一階段處理的東西並不多,所以從管道方案並沒有得到非常大的好處。真正能夠從並發中獲益的管道類型是每一個階段可能有很多的工作需要處理,或者依賴於別的其他正在被處理的項,這樣每個goroutine都能盡可能充分地利用時間。
7.2.2 並發的Grep
並發編程的一種常見的方式就是我們有很多工作需要處理,且每個工作都可以獨立地完成。例如,Go語言標準庫裡的net/http包的HTTP服務器利用這種模式來處理並發,每一個請求都在一個獨立的goroutine 裡處理,和其他的goroutine 之間沒有任何通信。這一節我們以實現一個cgrep程序為例說明實現這種模式的一種方法,cgrep表示「並發的grep」。
和標準庫裡的HTTP服務不同的是,cgrep使用固定數量的goroutine來處理任務,而不是動態地根據需求來創建。(我們會在後面的7.2.5節看到一個動態創建goroutine的例子。)
cgrep程序從命令行讀取一個正則表達式和一個文件列表,然後輸出文件名、行號,和每個文件裡所有匹配這個表達式的行。沒匹配的話就什麼也不輸出。
cgrep1程序(在文件cgrep1/cgrep.go裡)使用了3個通道,其中兩個是用來發送和接收結構體的。
type Job struct {
filename string
results chan<- Result
}
我們用這個結構體來指定每一個工作,filename表示需要被處理的文件,results是一個通道,所有處理完的文件都會被發送到這裡。我們可以將results定義為一個chan Result類型,但我們只往通道裡發送數據,不會從裡面讀取數據,所以我們指定這是一個單向的只允許發送的通道。
type Result struct {
filename string
lino int
line string
}
每個處理結果都是一個Result類型的結構體,包含文件名、行號碼,以及匹配的行。
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的機器核心
if len(os.Args) < 3 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <regexp> <files>\n",filepath.Base(os.Args[0]))
os.Exit(1)
}
if lineRx, err := regexp.Compile(os.Args[1]); err != nil {
log.Fatalf("invalid regexp: %s\n", err)
} else {
grep(lineRx, commandLineFiles(os.Args[2:]))
}
}
程序的main函數的第一條語句告訴 Go 運行時系統盡可能多地利用所有的處理器,調用 runtime.GOMAXPROCS(0)僅僅是返回當前處理器的數量,但如果傳入一個正整數就會設置Go運行時系統可以使用的處理器數。runtime.NumCPU函數返回當前機器的邏輯處理器或者核心的數量[1],Go語言裡大多數並發程序的開始處都有這一行代碼,但這行代碼最終將會是多餘的,因為Go語言的運行時系統會變得足夠聰明以自動適配它所運行的機器。
main函數處理命令行參數(一個正則表達式和一個文件列表),然後調用grep函數來進行相應處理(我們在4.4.2節裡已經看過commandLineFiles函數)。
lineRx是一個*regexp.Regexp類型(參見3.6.5節)的變量,傳給grep函數並被所有的工作goroutine共享。這裡有一點需要注意的,通常,我們必須假設任何共享指針指向的值都不是線程安全的。這種情況下我們必須自己來保證數據的安全性,如使用互斥量(mutex)等。或者,我們為每個工作goroutine單獨提供一個值而不是共享它,這就需要多一點內存的開銷。幸運的是,對於 *regexp.Regexp,Go語言的文檔說這個指針指向的值是線程安全的,這就意味著我們可以在多個goroutine裡共享使用這個指針。
var workers = runtime.NumCPU
func grep(lineRx *regexp.Regexp, filenames string) {
jobs := make(chan Job, workers)
results := make(chan Result, minimum(1000, len(filenames)))
done := make(chan struct{}, workers)
go addJobs(jobs, filenames, results) // 在自己的goroutine中執行
for i := 0; i < workers; i++ {
go doJobs(done, lineRx, jobs) // 每一個都在自己的goroutine中執行
}
go awaitCompletion(done, results) // 在自己的goroutine中執行
processResults(results) // 阻塞,直到工作完成
}
這個函數為程序創建了 3 個帶有緩衝區的雙向通道,所有的工作都會分發給工作goroutine來處理。goroutine的總數量和當前機器的處理器數相當,jobs通道和done通道的緩衝區大小也和機器的處理器數量一樣,將不必要的阻塞盡可能地降到最低。(當然,我們也可以不用管實際機器的處理器數量,而讓用戶在命令行指定到底需要開啟多少個工作goroutine。)對於 results 通道我們像前一小節的filter 程序那樣使用了一個更大的緩衝區,然後使用一個自定義的minimum函數(這裡不顯示,參見5.6.1.2節的實現,或者cgrep.go源碼)。
和之前章節的做法不同,之前通道的類型是chan bool而且只關心是否發送了東西,不關心是true還是false,我們這裡的通道類型是chan struct{}(一個空結構),這樣可以更加清晰地表達我們的語義。我們能往通道裡發送的是一個空的結構(struct{}{}),這樣只是指定了一個發送操作,至於發送的值我們不關心。
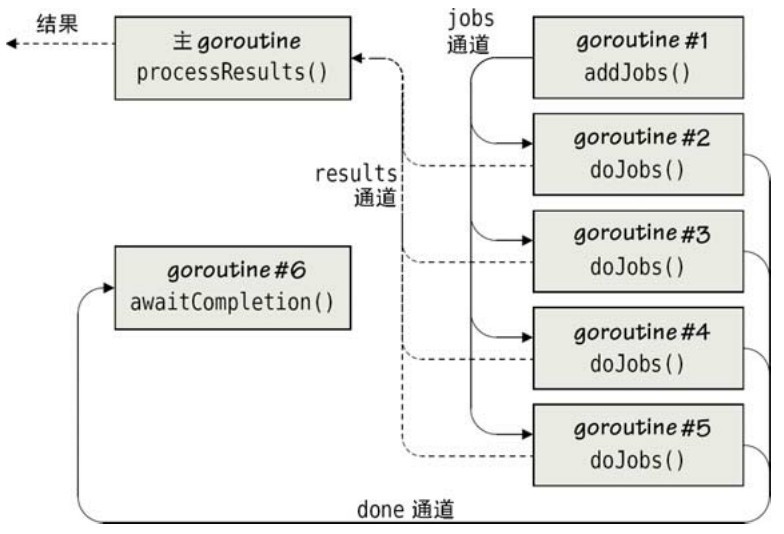
圖7-5 多個獨立的並發作業
有了通道之後,我們開始調用 addJobs函數往 jobs 通道裡增加工作,這個函數也是在一個單獨的goroutine裡運行的。再調用doJobs函數來執行實際的工作,實際上我們調用了這個函數四次,也就是創建了 4 個獨立的goroutine,各自做自己的事情。然後我們調用awaitCompletion函數,它在自己的goroutine裡等待所有的工作完成然後關閉results通道。最後,我們調用processResults函數,這個函數是在主goroutine裡執行的,這個函數處理從 results 通道接收到的結果,當通道裡沒有結果時就會阻塞,直到接收完所有的結果才繼續執行。圖7-5展示了這個程序並發部分的語義。
func addJobs(jobs chan<- Job, filenames string, results chan<- Result) {
for _, filename := range filenames {
jobs <- Job{filename, results}
}
close(jobs)
}
這個函數將文件名一個接一個地以Job類型發送到jobs通道裡。jobs通道有一個大小為4的緩衝區(和工作goroutine的數量一樣),所以最開始那4個工作是立即就增加到通道裡去的,然後該函數所在的goroutine 阻塞等待其他的工作 goroutine 從通道裡接收工作,以騰出通道空間來發送其他的工作。一旦所有的工作發送完畢(這取決於有多少個文件名需要處理,和處理每一個文件名的時間多長),jobs通道會被關閉。
儘管實際上傳入的兩個通道是雙向的,但是我們將它們都指定為單向只允許發送的通道,因為我們在函數里就是這樣使用的,Job結構裡Job.results通道也是這麼定義的。
func doJobs(done chan<- struct{}, lineRx *regexp.Regexp, jobs <-chan Job) {
for job := range jobs {
job.Do(lineRx)
}
done <- struct{}{}
}
前面我們已經知道,分別有4個獨立的goroutine在執行doJobs函數,它們都共享同一個jobs通道(只讀),並且每個goroutine都會阻塞到直到有一個工作分配給它。拿到工作之後調用這個工作的Job.Do方法(很快我們就可以看到Do方法裡做了什麼事情),當一個調用遍歷完jobs之後,往done通道裡發送一個空的結構報告自己的完成狀態。
順便提一下,按照 Go語言的慣例,帶有通道參數的函數,通常會將目標通道放在前面,接下來才是源通道。
func awaitCompletion(done <-chan struct{}, results chan Result) {
for i := 0; i < workers; i++ {
<-done
}
close(results)
}
這個函數(以及processResults函數)確保主goroutine在所有的處理都完成後才退出,這樣可以避免我們在前一節裡提到過的陷阱(7.1節)。這個函數在它自己的goroutine裡運行,然後等待從done通道裡接收所有工作goroutine的完成狀態,等待過程中它是阻塞的。一旦退出循環後 results 通道也會被關閉,因為這個函數能知道什麼時候接收最後一個結果。注意這裡我們不能將results通道作為一個只允許接收的通道(<-chan Result)來傳給函數,因為Go語言不允許關閉這樣的通道。
func processResults(results <-chan Result) {
for result := range results {
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
}
}
這個函數是在主goroutine裡執行的,遍歷results通道或者阻塞在那裡,一旦接收並處理完(例如打印)所有的完成狀態後,循環結束,函數就會返回,然後整個程序將退出。
Go語言的並發支持是相當靈活的,這裡我們使用的方法是,等待所有工作完成,關閉通道,並輸出所有的結果,但我們還有其他的方法。例如,cgrep2(它的文件在cgrep2/cgrep.go文件裡)這個程序就是我們這一節討論的cgrep1的另一個變種,它並沒有使用awaitCompletion或者precessResults函數,只用了一個waitAndProcessResults函數。
func waitAndProcessResults(done <-chan struct{}, results <-chan Result) {
for working := workers; working > 0; {
select { // 阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-done:
working--
}
}
DONE:
for {
select { // 非阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
default:
break DONE
}
}
}
這個函數首先就是一個for循環,它會一直執行到所有的goroutine退出。每一次進入循環體裡都會執行select語句,然後阻塞直到接收到一個結果值或者一個完成值。(如果我們使用了一個非阻塞的select,也就是有一個default分支,相當於創建了一個非常省CPU的spin-lock。)當所有的goroutine退出後for循環也會結束,也就是說,所有的工作goroutine都往done通道裡發送了一個結果值。
所有的工作goroutine完成自己的任務後,我們啟動了另一個for循環,在這個循環裡我們使用了非阻塞的select。如果results通道裡還有未處理的值,select就會匹配第一個分支,將這個值輸出,然後再一次執行循環體,一直重複到 results 通道裡所有的值都被處理完畢。但如果這時沒有結果值需要接收(最明顯的就是剛進入for循環的時候results通道裡是空的),程序就會退出for循環然後跳轉到DONE標籤處(單純使用一個break語句是不夠的,它只會跳出select語句),這個for循環不是很耗CPU,因為每一次迭代要麼接收了一個結果值要麼我們就完成了,沒有不必要的等待時間。
實際上 waitAndProcessResults函數要比原先的awaitCompletion和process Results函數更長和更複雜一點。但是,當有好幾個不同的通道需要處理的時候,使用 select語句是非常有好處的。例如我們可以在一定時間之後停止處理,即使那時還有未完成的任務。
下面是這個程序的第三個版本,也是最後一個版本,cgrep3(在文件cgrep3/cgrep.go裡)。
func waitAndProcessResults(timeout int64, done <-chan struct{}, results <-chan Result) {
finish := time.After(time.Duration(timeout))
for working := workers; working > 0; {
select { // 阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-finish:
fmt.Println("timed out")
return // 超時,因此直接返回
case <-done:
working--
}
}
for {
select { // 非阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-finish:
fmt.Println("timed out")
return // 超時,因此直接返回
default:
return
}
}
}
這是cgrep2的一個變種,不同的就是多了一個超時的參數,將一個time.Duration(其實就是一個納秒值)值傳入time.After函數,返回一個超時通道。這個超時通道的作用就是超過了time.Duration指定的時間後,通道會返回一個值,如果我們從這個通道裡讀到一個值,也就是說超時了。這裡我們將返回的通道賦值給finish變量,並在兩個for循環裡為finish增加一個case分支。一旦超時(即finish通道發送了一個值),即使還有工作未完成,函數也會返回,然後程序結束。
如果在超時之前我們得到了所有的結果值,也就是所有的工作goroutine都完成自己的任務並向results通道發送了一個結果值,這時第一個for循環就會退出,程序接著執行第二個for循環,這過程和cgrep2是完全一樣的,唯一不同的是這裡並沒有直接從for循環中跳出,而是簡單地在默認分支裡執行一個return語句,還增加了一個超時的case分支。
現在我們已經知道並發是怎麼處理的了,下面的代碼是關於每個工作是怎麼被處理的,這個之後cgrep例子的所有的代碼我們就已經講解完了。
func (job Job) Do(lineRx *regexp.Regexp) {
file, err := os.Open(job.filename)
if err != nil {
log.Printf("error: %s\n", err)
return
}
defer file.Close
reader := bufio.NewReader(file)
for lino := 1; ; lino++ {
line, err := reader.ReadBytes('\n')
line = bytes.TrimRight(line, "\n\r")
if lineRx.Match(line) {
job.results <- Result{job.filename, lino, string(line)}
}
if err != nil {
if err != io.EOF {
log.Printf("error:%d: %s\n", lino, err)
}
break
}
}
}
這個方法是用來處理每一個文件的,它傳入一個*regexp.Regexp值,這是一個線程安全的指針,所以它不必關心有多少個不同的goroutine同時在用它。整個函數的代碼我們已經很熟悉了:打開一個文件,讀取它的數據,對所有的出錯進行處理,如果沒有錯誤我們就用 defer 語句來關閉文件,然後創建了一個帶緩衝區的reader來遍歷文件內容裡的所有行,一旦遇到了匹配的行,我們就將它作為一個Result值發送到results通道,當通道滿時發送操作會被阻塞,最後所有被處理的文件都會產生N個結果值,如果文件裡沒有匹配的行,那N的值為0。
在Go語言裡處理文本文件時,如果在讀一行文本中出現錯誤,我們會在處理完當前行後處理這個錯誤。如果bufio.Reader.ReadBytes方法遇到了一個錯誤(包括文件結束),它會和錯誤一起返回出錯前已經成功讀取到的字節數。有時候文件最後一行不是以換行符結束的,所以為了確保我們處理最後一行(不管它是否是以換行符結束的),我們都會在處理完這一行後再處理相關錯誤。這樣做有一點不好,就是正則表達式如果匹配了一個空的字符串,我們會得到既不是nil也不是io.EOF的錯誤,從而被當做一個假的匹配(當然,我們有辦法繞過這個問題)。
bufio.Reader.ReadBytes方法會一直讀到一個指定的字符後才返回。返回的字節流裡包括那個指定的字符,如果整個文件都沒出現這個字符的話,會將整個文件的數據都讀取出來。我們這裡不需要換行符,所以我們使用 bytes.TrimRight方法將它去掉。bytes.TrimRight方法的作用就是從行的右邊向左去除指定的字符串或字符(類似於strings.TrimRight函數)。為了能讓我們的程序跨平台,我們將換行和回車字符都除掉。
另一個需要注意的小細節就是,我們讀出來的是字節切片,而 regexp.Regexp.Match和regexp.Regexp.MatchString方法只能處理字符串,所以我們將byte轉換成string類型,當然轉換的代價很小。還有我們統計行數從1開始而不是從0開始,這樣會方便很多。
cgrep程序的設計中比較好的一點就是它的並發框架足夠簡單,並和實際的業務處理過程(也就是Job.Do方法)分離,只使用results通道來進行交互。這種框架與業務的分離在Go語言的並發編程裡是很常見的,與那些使用底層同步數據結構(如同步鎖)的方法相比有諸多好處,因為鎖相關的代碼會讓程序的邏輯變得更加複雜和晦澀難懂。
7.2.3 線程安全的映射
Go語言標準庫裡的sync和sync/atomic包提供了創建並發的算法和數據結構所需要的基礎功能。我們也可以將一些現有的數據結構變成線程安全,例如映射或者切片等(參見6.5.3節),這樣可以確保在使用上層API時所有的訪問操作都是串行的。
這一節我們會開發一個線程安全的映射,它的鍵是字符串,值是 interface{}類型,不需要使用鎖就能夠被任意多個goroutine共享(當然,如果我們存的值是一個指針或引用,我們還必須得保證所指向的值是只讀的或對於它們的訪問是串行的)。線程安全的映射的實現在safemap/safemap.go 文件裡,包含了一個導出的SafeMap 接口,以及一個非導出的safeMap 類型,safeMap 實現了 SafeMap 接口定義的所有方法。下一節我們來看看這個safeMap是怎麼使用的。
安全映射的實現其實就是在一個goroutine裡執行一個內部的方法以操作一個普通的map數據結構。外界只能通過通道來操作這個內部映射,這樣就能保證對這個映射的所有訪問都是串行的。這種方法運行著一個無限循環,阻塞等待一個輸入通道中的命令(即「增加這個」,「刪除那個」等)。
我們先看看 SafeMap 接口的定義,再分析內部 safeMap 類型可導出的方法,然後就是safemap包的New函數,最後分析未導出的safeMap.run方法。
type SafeMap interface {
Insert(string, interface{})
Delete(string)
Find(string) (interface{}, bool)
Len int
Update(string, UpdateFunc)
Close map[string]interface{}
}
type UpdateFunc func(interface{}, bool) interface{}
這些都是SafeMap接口必須實現的方法。(我們在前一章討論過可導出的接口和不能導出的具體類型是什麼樣的。)
UpdateFunc類型讓自定義更新操作函數變得很方便,我們會在後面討論Update方法時講到它。
type safeMap chan commandData
type commandData struct {
action commandAction
key string
value interface{}
result chan<- interface{}
data chan<- map[string]interface{}
updater UpdateFunc
}
type commandAction int
const (
remove commandAction = iota
end
find
insert
length
update
)
safeMap的實現基於一個可發送和接收commandData類型的通道。每個commandData類型值指明了一個需要執行的操作(在 action 字段)及相應的數據,例如,大多數方法需要一個key來指定需要處理的項。我們會在分析safeMap的方法時看到所有的字段是如何被使用的。
注意,result和data通道都是被定義為只寫的,也就是說,safeMap可以往裡面發送數據,不能接收。但是下面我們會看到,這些通道在創建的時候都是可讀寫的,所以它們能夠接收safeMap發給它們的任何值。
func (sm safeMap) Insert(key string, value interface{}) {
sm <- commandData{action: insert, key: key, value: value}
}
這種方法相當於一個線程安全版本的m[key] = value 操作,其中 m 是 map[string] interface{}類型。它創建了一個commandData值,指明是一個insert操作,並將傳入的key和value保存到commandData結構中並發送到一個安全的映射裡。我們剛剛介紹過,這個安全映射的類型是基於chan commandData實現的(我們在6.4節講過,在Go語言裡創建一個結構時所有未被顯式初始化的字段都會被默認初始化成它們各自的零值)。
當我們查看 safemap 包裡的New函數時我們會發現該函數返回的safeMap 關聯了一個goroutine。safeMap.run方法在這個goroutine裡執行,也是一個捕獲了該safeMap通道的閉包。safeMap.run裡有一個底層 map 結構,用來保存這個安全映射的所有項,還有一個 for循環遍歷safeMap通道,並執行每一個從safeMap通道接收到的對底層map的操作。
func (sm safeMap) Delete(key string) {
sm <- commandData{action: remove, key: key}
}
這個方法告知該安全映射刪除key所對應的項,如果給定key不存在則不做任何事。
type findResult struct {
value interface{}
found bool
}
func (sm safeMap) Find(key string) (value interface{}, found bool) {
reply := make(chan interface{})
sm <- commandData{action: find, key: key, result: reply}
result := (<-reply).(findResult)
return result.value, result.found
}
safeMap.Find方法創建了一個reply通道用來接收發送commandData後的響應,然後把這個 reply 通道和指定要查找的key 放到一個 commandData 值裡,再往 safeMap發送一個 find 命令。因為所有的通道都沒有帶緩衝區,因此一條命令的發送操作會一直阻塞直到沒有其他的goroutine往裡面發送命令。一旦命令發送完畢我們立即接收reply通道的返回值(對應於find命令是一個findResult結構),然後我們將這個結果返回給調用者。順便提一句,這裡我們使用命名返回值是為了讓它們的用途更加清晰。
func (sm safeMap) Len int {
reply := make(chan interface{})
sm <- commandData{action: length, result: reply}
return (<-reply).(int)
}
這個方法和Find方法在結構上大體是相似的,首先創建一個用來接收結果的reply通道,最後將結果分析出來返回給調用者。
func (sm safeMap) Update(key string, updater UpdateFunc) {
sm <- commandData{action: update, key: key, updater: updater}
}
這個方法貌似看起來有點不太常規,因為它的第二個參數是一個簽名為func(interface{}, bool)的函數。Update方法往通道發送一條更新命令時會帶上指定的key和一個updater函數,當這條命令被接收時,updater函數會被調用並帶上兩個調用參數,一個是指定的key對應的值(若key不存在,則傳nil作為參數),還有一個bool變量表示這個鍵對應的項是否存在。指定的鍵對應的值會被設置為updater函數的返回值(如果key不存在則創建一個新項)。
需要特別注意的是, updater函數調用safeMap的方法會導致死鎖。後面涉及safemap.safeMap.run方法時會進一步解釋。
但我們為什麼需要這麼奇怪的方法呢,又怎麼去用它?
當我們需要插入、刪除或查找safeMap裡的項時,Insert、Delete和Find方法都能工作得很好。但當我們想去更新一個已經存在的項時會發生什麼呢?舉個例子,我們在safeMap裡保存了機器零件的價格,現在我們需要將某個零件的價格上調5%,會發生什麼事情呢?我們知道Go語言會自動將一個未初始化的值初始化為0,如果我們指定的鍵已經存在的話,它對應的值會增加5%,如果不存在的話,就創建一個新的零值。下面我們實現了一個能保存float64類型的值的安全映射。
if price, found := priceMap.Find(part); found { // 錯誤!
priceMap.Insert(part, price.(float64)*1.05)
}
這段代碼的問題是可能會有多個goroutine同時使用這個priceMap,也就有可能在Find和Insert之間修改數據,從而沒法保證我們插入的價格值確實比原來的值高5%。
我們需要的是一個原子的更新操作,也就是說,讀和更新這個值應該作為不可中斷的一個操作。下面的Update方法就是這樣做的。
priceMap.Update(part, func(price interface{}, found bool) interface{} {
if found {
return price.(float64) * 1.05
}
return 0.0
})
這段代碼實現了一個原子更新操作,如果指定的鍵不存在,我們就創建一個新的項,它的值為0.0,否則我們就將這個鍵對應的值增加5%。因為這個更新是在safeMap的goroutine裡執行的,這期間不會有其他的命令被執行(例如,從其他goroutine發送過來的命令)。
func (sm safeMap) Close map[string]interface{} {
reply := make(chan map[string]interface{})
sm <- commandData{action: end, data: reply}
return <-reply
}
Close方法的工作原理和Find以及 Len方法類似,不過它有兩個不同的目標。首先,它需要關閉safeMap通道(在safeMap.run方法裡),這樣就不會再有其他的更新操作。關閉safeMap通道將導致safeMap.run方法裡的for循環退出,進而釋放相應用於自動垃圾收集的goroutine。第二個目標是將底層的map[string]interface{}返回給調用者(如果調用者不需要,可以忽略它)。每一個safeMap只允許執行一次Close方法,不管有多少個goroutine在訪問,而且一旦Close被調用就不能再調用任何其他方法。我們可以保留Close方法返回的map並像使用一個普通map一樣使用它,但只能在一個goroutine裡使用。
到這裡我們已經分析了safeMap所有導出的方法,最後一個我們要分析的是safemap包的New函數,New函數的作用就是創建一個safeMap並以SafeMap接口的方式返回,並執行safeMap.run方法使用通道,提供一個map[string]interface{}用來保存實際的數據,並且處理所有的通信。
func New SafeMap {
sm := make(safeMap) // safeMap類型chan commandData go sm.run
return sm
}
safeMap實際上是chan commandData類型,所以我們必須使用內置的make函數來創建一個通道並返回它的一個引用。有了safeMap之後我們調用它的run方法,在run裡還會創建一個底層映射用來保存實際的數據,run在自己的goroutine裡執行,執行go語句之後通常會立即返回。最後函數將這個safeMap返回。
func (sm safeMap) run {
store := make(map[string]interface{})
for command := range sm {
switch command.action {
case insert:
store[command.key] = command.value
case remove:
delete(store, command.key)
case find:
value, found := store[command.key]
command.result <- findResult{value, found}
case length:
command.result <- len(store)
case update:
value, found := store[command.key]
store[command.key] = command.updater(value, found)
case end:
close(sm)
command.data <- store
}
}
}
創建了一個用來存儲的映射後,run方法啟動了一個無限循環來讀取 safeMap 通道的命令,如果通道是空的,就一直阻塞在那裡。
因為store是一個再普通不過的映射,所以接收到每一個命令該怎麼處理就怎麼處理,非常容易理解。另一個稍微不同的是更新操作。某個鍵所對應項的值將被設置成command.updater函數的返回值。最後一個end分支對應Close調用,首先關閉通道以防止再接收其他的命令,然後將存儲映射返回給調用者。
前面我們提過如果 command.updater函數要是調用了 safeMap的方法就會發生死鎖,這是因為如果command.updater函數不返回,update這個分支就不能正常結束。如果updater函數調用了一個safeMap方法,它會一直阻塞到update分支完成,這樣兩個都完成不了。圖7-2解釋了這種死鎖。
顯然,使用一個線程安全的映射相比一個普通的map會有更大的內存開銷,每一條命令我們都需要創建一個 commandData 結構,利用通道來達到多個 goroutine 串行化訪問一個safeMap的目的。我們也可以使用一個普通的map配合sync.Mutex以及sync.RWMutex使用以達到線程安全的目的。另外還有一種方法就是如同相關理論所描述的那樣創建一個線程安全的數據結構(例如,參見附錄 C)。還有一種方法就是,每個 goroutine 都有自己的映射,這樣就不需要同步了,然後在最後將所有goroutine的結果合併在一起即可。儘管方法很多,這裡所實現的安全映射不但易用而且足以應對各種的場景。下一小節我們會看到如何應用這個safeMap,並順帶與一些其他方法進行了對比。
7.2.4 Apache報告
並發處理最常見的一個需求就是更新共享數據。一個常見的方案是使用互斥量來串行化所有的數據訪問。在Go語言裡,我們除互斥量外還可以使用通道來達到串行化的目的。這一節,我們將使用通道和一個安全的映射(上一節講過的)來開發一個小程序,然後再分析如何使用以互斥量保護的共享map來達成同樣的目標。最後,我們將講解如何使用通道局部的map來避免訪問串行化從而最大化吞吐量,並使用通道來對一個map進行更新。
這裡所有的工作都由apachereport程序完成。它讀取從命令行指定的Apache網頁服務器的access.log文件數據,然後統計所有記錄裡每個HTML頁面被訪問的次數。這個日誌文件很容易就增長到很大,所以我們用了一個 goroutine 來讀取每一行日誌(每行一條記錄),以及另外3個goroutine一起處理這些行。每讀到一個HTML頁面被訪問的記錄,就將它更新到映射裡去,如果這個HTML是第一次訪問,則映射裡對應的計數器為1,然後每再發現一條記錄,計數器做加一處理。所以儘管有多個獨立goroutine同時處理這些行記錄,但是它們所有的更新都是在同一個映射裡進行的。不同版本的程序採取不同的方法來更新映射。
7.2.4.1 用線程安全的共享映射同步
現在我們來回顧下apachereport1 程序(在文件apachereport1/apachereport.go裡),使用前一節開發的safeMap,所用到的並發數據結構如圖7-6所示。
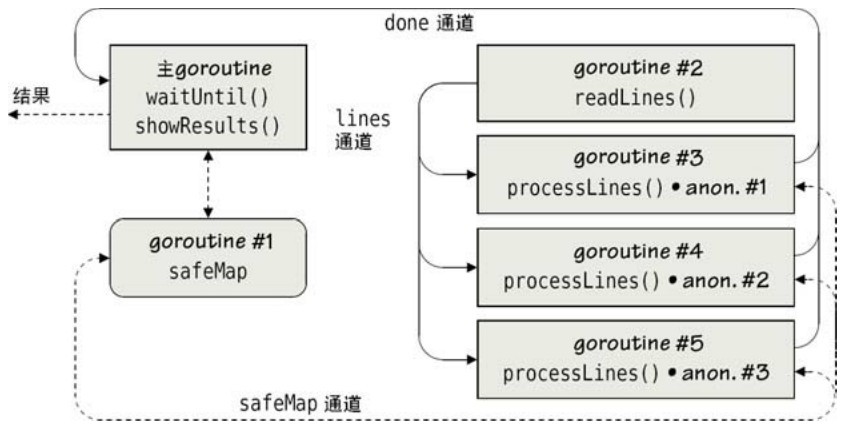
圖7-6 帶有同步結果的多個相互依賴的並發作業
在圖7-6中,goroutine#2創建了一個通道,將從日誌讀到的每一行發送到工作通道裡,然後goroutine#3到goroutine#5處理這個通道的每一行並更新到共享的safeMap數據結構。對safeMap的操作本身是在一個獨立的goroutine裡完成的,所以整個程序一共使用了6個goroutine。
var workers = runtime.NumCPU
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的機器內核
if len(os.Args) != 2 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <file.log>\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
lines := make(chan string, workers*4)
done := make(chan struct{}, workers)
pageMap := safemap.New
go readLines(os.Args[1], lines)
processLines(done, pageMap, lines)
waitUntil(done)
showResults(pageMap)
}
main函數首先確保Go運行時系統充分利用所有的處理器,然後創建兩個通道來組織所有的工作。從日誌文件裡讀取到的每一行將被發送到lines通道,然後工作goroutine再將每一行讀取出來進行處理,我們為lines通道分配了一個小緩衝區以降低工作goroutine阻塞在lines 通道上的可能性。done 通道用來跟蹤何時所有工作被完成。因為我們只關心發送和接收操作的發生而非實際傳遞的值,所以我們使用一個空結構。done 通道也是帶有緩衝的,所以當一個goroutine報告工作完成時不會被阻塞在發送操作上。
接著我們使用safemap.New函數創建了一個pageMap,它是一個非導出的safeMap類型的值,實現了SafeMap接口所有定義的方法,可以隨意傳遞。然後我們啟動一個goroutine來從日誌文件裡讀取行記錄,並啟動其他的goroutine 負責處理這些行。最後程序等待所有的goroutine工作完成,並將最終的結果輸出。
func readLines(filename string, lines chan<- string) {
file, err := os.Open(filename)
if err != nil {
log.Fatal("failed to open the file:", err)
}
defer file.Close
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if line != "" {
lines <- line
}
if err != nil {
if err != io.EOF {
log.Println("failed to finish reading the file:", err)
}
break
}
}
close(lines)
}
這個函數看起來並不陌生,因為與之前我們見過的幾個例子相當類似。首先最關鍵的第一個地方就是我們將每一個文本行發送到 lines 通道,lines 是只允許發送的,而且當通道緩衝區滿了之後這個操作會一直阻塞在那裡,直到有一個其他的goroutine從通道裡接收一個文本行。不過就算有阻塞,也只會對這個 goroutine 有影響,其他的goroutine 還會繼續工作而不受影響。第二個關鍵的地方就是當所有的文本行發送完畢之後我們關閉lines通道,這就告訴了其他的goroutine已經沒有數據需要接收了。記住,儘管這個goroutine和其他的goroutine(也就是其他負責處理任務的工作 goroutine)是並發執行的,但是一般只有在大部分工作完成後close語句才會被執行到。
func processLines(done chan<- struct{}, pageMap safemap.SafeMap, lines <-chan string) {
getRx := regexp.MustCompile('GET[ \t]+([^ \t\n]+[.]html?)')
incrementer := func(value interface{}, found bool) interface{} {
if found {
return value.(int) + 1
}
return 1
}
for i := 0; i < workers; i++ {
go func {
for line := range lines {
if matches := getRx.FindStringSubmatch(line); matches != nil {
pageMap.Update(matches[1], incrementer)
}
}
done <- struct{}{}
}
}
}
這裡函數參數的順序遵循Go語言的約定,先是目標通道(也就是done通道),然後是源通道(lines通道)。
該函數創建了一些goroutine(實際上是3個)來處理實際的工作。每個goroutine都共享同一個*regexp.Regexp數據(和普通的指針不同,這個是線程安全的)和一個incrementer函數(這個函數不會有任何副作用,因為它不訪問任何共享的數據),還共享了同一個pageMap (是一個SafeMap接口類型的值)。前面我們已經知道,safeMap的修改都是線程安全的。
如果沒有匹配任何數據,那麼 regexp.Regexp.FindStringSubmatch函數返回nil,否則就返回一個string 類型的字符串切片,其中第一個字符串是整個正則表達式的匹配,隨後其他的字符串對應表達式裡的每一個小括號括起來的子表達式。這裡我們只有一個子表達式,所以如果我們得到一個匹配的結構,那這個結果裡有兩個字符串,一個是完整的匹配,另一個是括號裡子表達式的匹配,在這裡是HTML頁面的文件名。
每一個工作 goroutine 從只允許接收的lines 通道裡讀取文本行,通道中的數據由readLines函數里的goroutine 從日誌文件裡讀取並發送。對於某一行的匹配說明對於HTML文件發生了一個GET請求,在這種情況下safeMap.Update方法將被調用並傳入頁面的文件名(也就是 matches[1])和incrementer函數。incrementer函數是safeMap的內部 goroutine 調用的,對於之前被訪問過的頁面,那就返回一個增量值,對於未被訪問過的頁面則返回1(回憶起前一小節我們說過的,如果被傳給safeMap.Update的函數自身又調用了 safeMap的其他方法的話會出現死鎖)。當所有頁面被處理後,每一個工作goroutine會發送一個空結構體到done通道以說明工作已經完成。
func waitUntil(done <-chan struct{}) {
for i := 0; i < workers; i++ {
<-done
}
}
這個函數在主 goroutine 裡執行,阻塞在 done 通道上,當所有的工作 goroutine 往 done裡發送了一個空結構體後,for循環將結束。和平時一樣,我們不需要關閉done通道,因為沒有在別的需要檢查這個通道是否被關閉的地方使用這個通道。通過阻塞,這個函數可以確保所有的處理工作在主goroutine退出之前完成。
func showResults(pageMap safemap.SafeMap) {
pages := pageMap.Close
for page, count := range pages {
fmt.Printf("%8d %s\n", count, page)
}
}
當所有的文本行都被讀取並且所有的匹配項都增加到 safeMap 之後,該函數將被調用以輸出結果。它首先調用 safemap.safeMap.Close方法關閉 safeMap的通道,退出在goroutine裡運行的safeMap.run方法,然後返回一個底層的map[string]interface{}給調用者。這個返回的映射將無法再被其他的goroutine通過安全映射的通道訪問,所以可以在一個單獨的goroutine中安全地使用它(或者使用互斥量來讓多個goroutine串行訪問)。由於從該處之後我們只在主goroutine裡訪問這個映射,所以串行化訪問並沒必要。我們簡單地遍歷映射裡所有的「鍵/值」對,然後將它們輸出到控制台。
使用一個 SafeMap 接口類型的值同時提供了線程安全性和簡單的語法,不需要擔心鎖的問題。這種方法不好的一點就是安全映射的值是 interface{}類型而不是一個特定的類型,這樣我們就得在incrementer函數里使用類型斷言(我們將在7.2.4.3節討論另一個缺陷)。
7.2.4.2 用帶互斥量保護的映射同步
現在我們將對簡單乾淨的基於通道的做法和傳統的基於互斥量的做法做一個對比。為此我們首先簡要地討論一下apachereport2程序(在文件apachereport2/apachereport.go裡)。這個程序是 apachereport1的變種,使用了一個封裝了映射的自定義數據類型和互斥量來取代線程安全的映射。這兩個程序所做的工作是完全一樣的,唯一不同的是映射的值是一個int型值而不是SafeMap裡的interface{}類型,並且相比安全映射中的完全方法列表,這裡只提供了這個工作相關的最小功能集合—— 一個Increment方法。
type pageMap struct {
countForPage map[string]int
mutex *sync.RWMutex
}
使用自定義類型的好處就是我們可以用所需要的特定數據類型而不是通用的interface{}類型。
func NewPageMap *pageMap {
return &pageMap{make(map[string]int), new(sync.RWMutex)}
}
這個函數返回一個可立即使用的*pageMap值。(順便提一句,可以使用&sync.RWMutex{}來創建一個讀寫鎖,而不用new(sync.RWMutex)。4.1節中我們討論過這兩者的一致性。)
func (pm *pageMap) Increment(page string) {
pm.mutex.Lock
defer pm.mutex.Unlock
pm.countForPage[page]++
}
每個修改 countForPage的方法都需要使用互斥量來串行化訪問。我們這裡用的方法很傳統:首先鎖定互斥量,然後使用defer關鍵字來調用解鎖互斥量的語句,這樣無論什麼時候返回都能保證可以解鎖互斥量(即使發生了異常),然後再訪問映射裡的數據(每次鎖定的時間越少越好)。
基於Go語言的自動初始化機制,當頁面在countForPage中第一次被訪問時(即該頁面還不在countForPage裡),我們就將它增加到這個映射裡面並將值設置為0,然後馬上遞增該值。相對的,之後對已經存在於映射中的頁面的訪問都會導致對應值的遞增。
我們使用互斥量來串行化所有方法對countForPage的訪問,所以如果要更新映射的值,就必須使用sync.RWMutex.Lock和sync.RWMutex.Unlock,但對於只讀的訪問,我們可以用另一種只讀的方法。
func (pm *pageMap) Len int {
pm.mutex.RLock
defer pm.mutex.RUnlock
return len(pm.countForPage)
}
我們將這個放進來純粹是為了展示一下如何使用一個讀鎖。這個用法和普通的鎖是一樣的,但讀鎖可能更加高效一點(因為我們承諾只是讀取但不修改受保護的資源)。例如,如果我們有多個goroutine都同時讀同一個的countForPage,利用讀鎖,它們可以安全地並發執行。但如果它們其中一個得到了一個讀寫鎖,它將可以修改映射的數據,但其餘的goroutine就無法再獲取任何鎖。
pageMap.Increment(matches[1])
在有了pageMap類型後,工作goroutine就可以用這個語句來更新共享映射。
7.2.4.3 同步:使用通道來合併局部映射
不管我們用的是安全的映射還是用互斥量保護的映射,通過增加工作goroutine的數量可能能夠提升應用程序的運行速度。但是由於訪問安全映射或者用互斥量保護的映射時必須是串行化的,增加goroutine的數量會直接導致競爭的增加。
對於這種情況,通常我們可以通過犧牲一些內存來提升速度。例如,我們可以讓每個工作goroutine都擁有自己的映射,這樣可以極大地提高應用程序的吞吐量,因為處理過程中不會發生任何競爭,代價就是使用了更多的內存(因為很可能每個映射都有部分甚至所有相同的頁面)。最後我們當然還必須將這些映射合併起來,這會是一個性能瓶頸,因為一個映射在合併時所有其他準備好合併的映射只能等著。
程序apachereport3(在文件apache3/apachereport.go裡)使用每個goroutine特定的本地映射結構,並最後將它們全部合併到同一個映射裡去。該程序的代碼和apachereport1以及 apachereport2 幾乎是一樣的,這樣我們就只重點介紹這個方法不一樣的地方。這個程序的並髮結構如圖7-7所示。
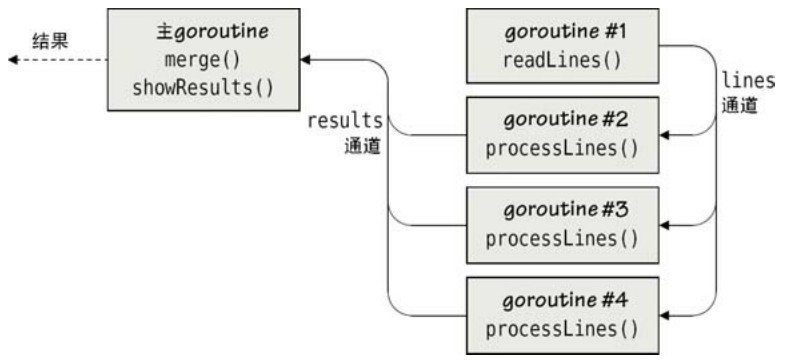
圖7-7 帶有同步結果的多個相互依賴的並發作業
//...
lines := make(chan string, workers*4)
results := make(chan map[string]int, workers)
go readLines(os.Args[1], lines)
getRx := regexp.MustCompile('GET[ \t]+([^ \t\n]+[.]html?)')
for i := 0; i < workers; i++ {
go processLines(results, getRx, lines)
}
totalForPage := make(map[string]int)
merge(results, totalForPage)
showResults(totalForPage)
//...
這是apachereport3程序main函數的一部分。這裡我們沒有使用done通道而是使用了一個results通道,當每個goroutine處理完成之後,將本地生成的映射發送到results這個通道裡。另外,我們還創建一個保存所有結果的映射(叫totalForPage)以保存所有合併所有的結果。
func processLines(results chan<- map[string]int, getRx *regexp.Regexp,
lines <-chan string) {
countForPage := make(map[string]int)
for line := range lines {
if matches := getRx.FindStringSubmatch(line); matches != nil {
countForPage[matches[1]]++
}
}
results <- countForPage
}
這個函數和前一個版本幾乎是一樣的,關鍵的區別有兩個,第一個就是我們創建了一個本地映射來保存頁面的數量,第二個就是在函數處理完所有的文本行之後(也就是lines通道被關閉了),我們將本地的映射結果發送到results通道(而不是發送一個struct{}{}到done通道)。
func merge(results <-chan map[string]int, totalForPage map[string]int) {
for i := 0; i < workers; i++ {
countForPage := <-results
for page, count := range countForPage {
totalForPage[page] += count
}
}
}
merge函數的結構和之前我們看過的waitUntil是一樣的,只是這一次我們需要使用接收到的值,用以更新 totalForPage 映射。需要注意的是,這裡接收的映射不會再被發送的goroutine訪問,所以無需使用鎖。
showResults函數也基本上和之前的是一樣的(所以這裡就不貼代碼了),我們將totalForPage作為它的參數,然後在函數里遍歷這個映射,將每個頁面的統計結果打印出來。
apachereport3程序的代碼相對apachereport1和apachereport2來說非常的簡潔,而且它所用的並發模型在很多場合是非常有用的,也就是每個goroutine都有局部的數據結構來保存計算結果,並將最後所有goroutine運行的結果合併在一塊。
當然,對於那些習慣使用鎖的程序員來說,大多還是傾向於使用互斥量來串行化共享數據的訪問。但是,Go語言文檔強烈推薦使用goroutine和通道,它提倡「不要使用共享內存來通信,相反,應使用通信來共享內存」,而且Go編譯器對於上面提到的並發模型進行了相應的優化。
7.2.5 查找副本
這是這章最後一個關於並發的例子,使用SHA-1值而不是根據文件名來查找重複的文件[2]。
我們即將分析的程序名字是 findduplicates(在文件 fundduplicates/finddup licates.go裡)。程序使用了標準庫裡的filepath.Walk函數,遍歷一個給定路徑的所有文件和目錄,包括子目錄、子目錄的子目錄等。程序根據工作量的多少而決定使用多少個goroutine。對於每一個大文件會有一個goroutine被單獨創建以用於計算文件的SHA-1值,而小文件則是直接在當前的goroutine 裡計算。這意味著我們不知道實際會有多少個 goroutine 在運行,不過我們也可以設置一個上限。
怎麼處理若干個不固定數量的goroutine呢,一種辦法就是和之前的例子一樣使用done通道,只不過這一次是用來監控所有goroutine的狀態。使用sync.WaitGroup雖然容易,但是我們需要將goroutine的數量傳給它,而goroutine的數量我們是不知道的。
const maxGoroutines = 100
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的機器核心
if len(os.Args) == 1 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <path>\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
infoChan := make(chan fileInfo, maxGoroutines*2)
go findDuplicates(infoChan, os.Args[1])
pathData := mergeResults(infoChan)
outputResults(pathData)
}
main函數從命令行讀取一個路徑作為處理起始點並安排所有之後的工作。它首先創建一個通道用來傳送 fileInfo 值(我們很快就會看到)。我們為這個通道設置了緩衝,因為實驗表明這將能穩定的提升性能。
接下來函數在一個goroutine裡執行findDuplicates函數,並調用mergeResults函數以讀取infoChan通道裡的數據直到它關閉。當合併結果返回後,我們將結果打印出來。
程序所有的goroutine和通信流程圖如圖 7-8 所示。圖中的結果通道中的值是 fileInfo類型的,這些值會被一個叫「walker」的函數(filepath.WalkFunc類型)發送到infoChan通道,walker函數是我們調用filepath.Walk時傳入的參數。filepath.Walk函數也是在fileDuplicates裡被調用的。mergeResults函數負責接收最後的結果。圖中所示的goroutine 是在 findDuplicates函數和walker 函數里創建的。另外,標準庫裡的filepath.Walk函數也會創建goroutine(例如,每一個goroutine處理一個目錄),至於它是怎麼工作的則屬於實現細節。
type fileInfo struct {
sha1 byte
size int64
path string
}
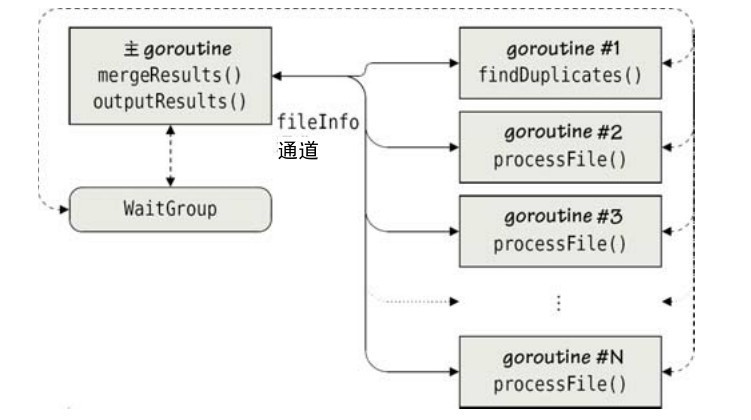
圖7-8 帶有同步結果的多個獨立的並發作業
我們用這個結構體來保存文件的一些信息,如果兩個文件的SHA-1值和文件尺寸都是一樣的,不管它們的路徑或者文件名是什麼,我們都會把它們認為是重複的。
func findDuplicates(infoChan chan fileInfo, dirname string) {
waiter := &sync.WaitGroup{}
filepath.Walk(dirname, makeWalkFunc(infoChan, waiter))
waiter.Wait // 一直阻塞到工作完成
close(infoChan)
}
這個函數調用filepath.Walk來遍歷一個目錄樹,並對於每一個文件或者目錄調用作為該函數第二個參數傳入的filepath.Walk函數來處理。
walker函數會創建任意個goroutine,我們必須等所有的goroutine完成任務之後才可以返回findDuplicates函數。為此,我們創建了一個 sync.WaitGroup,每次我們創建一個goroutine 時,就調用一次 sync.WaitGroup.Add函數,而當 goroutine 完成任務之後,再調用 sync.WaitGroup.Done。所有的goroutine 都設置為正在運行後,我們調用sync.WaitGroup.Wait函數來等待所有工作goroutine完成。sync.WaitGroup.Wait將阻塞到宣佈完成的done數量和添加的數量相等為止。
所有的工作goroutine都退出後將不會再有其他的fileInfo值發送到infoChan裡,因此我們可以關閉infoChan通道。當然mergeResults仍然可以讀這個通道,直到將所有的數據都被讀取出來。
const maxSizeOfSmallFile = 1024 * 32
func makeWalkFunc(infoChan chan fileInfo, waiter *sync.WaitGroup)
func(string, os.FileInfo, error) error {
return func(path string, info os.FileInfo, err error) error {
if err == nil && info.Size > 0 && (info.Mode&os.ModeType == 0) {
if info.Size < maxSizeOfSmallFile || runtime.NumGoroutine > maxGoroutines {
processFile(path, info, infoChan, nil)
} else {
waiter.Add(1)
go processFile(path, info, infoChan, func { waiter.Done })
}
return nil // 忽略所有錯誤
}
}
}
makeWalkFunc創建了一個類型為 filepath.WalkFunc的匿名函數,原型為func(string, os.FileInfo, error) error。每當filepath.Walk得到一個文件或者目錄之後就會相應地調用這個匿名函數。函數中的path是指目錄或者文件的名字,info保存了部分stat調用的結果,err要麼為nil要麼包含了詳細的關於路徑的錯誤信息。如果我們需要忽略目錄,可以使用 filepath.SkipDir 作為 error的返回值,還可以返回其他non-nil的錯誤,這樣filepath.Walk函數就會終止返回。
這裡我們只處理那些非零大小的正常文件(當然,所有文件大小為0都是一樣的,不過我們忽略掉這些)。os.ModeType是一個位集合,包含了目錄、符號連接、命名管道、套接字和設備,所以如果這些對應的位沒有設置,那它就是一個普通的文件。
如果文件很小,如不到32 KB,我們使用自定義函數processFile來計算它的SHA-1值,其他文件則創建一個新的goroutine來異步調用processFile函數,這就意味著小的文件會被阻塞(直到我們計算出它們的SHA-1值),但大文件就不會,因為它們的計算是在一個獨立的goroutine裡完成的。總之,當所有的計算都完成了,作為結果的fileInfo值就會被發送到infoChan通道。
當我們創建一個新的goroutine 之後,我們只需要調用 sync.WaitGroup.Add方法,但這麼做的話,當goroutine完成自己的工作後還必須調用對應的sync.WaitGroup.Done方法。我們利用 Go語言的閉包來實現這個功能。如果我們在一個新的goroutine 裡調用processFile函數,我們將一個匿名函數作為最後一個參數傳入,當匿名函數被調用時會調用 sync.WaitGroup.Done方法,processFile函數應以延遲方式調用這個匿名函數,以保證當 goroutine 完成時 Done方法會被調用。如果我們在當前的goroutine 裡調用processFile函數,我們傳一個nil參數來代替匿名函數。
為什麼我們不簡單地為每一個文件都創建一個新的goroutine呢?在Go語言裡完全可以這麼做,就算我們創建了成百上千個goroutine也不會遇到任何問題。不幸的是,大部分的操作系統都限制同時打開的文件數。在Windows系統上默認只有512,儘管能提升到2048。Mac OS X系統更低,只能同時打開256個文件,Linux系統默認限制在1024,但是這些類Unix操作系統通常可以將這個值設置成一萬、十萬或者更高。很明顯,如果我們將每一個文件都放到單獨的goroutine裡去處理,就很容易會超出這個限制。
為了避免打開過多的文件,我們配合使用兩個策略。首先,我們將所有的小文件都放在同一個goroutine裡處理(或者幾個goroutine,如果碰巧filepath.Walk將它的工作分散到幾個goroutine裡去處理然後並發地調用walker函數的話),這樣就可以確保如果我們遇到了一個包含上千個小文件的目錄,不需要一次打開太多的文件,因為一個goroutine或者幾個就能很快地把它處理完。
我們還應該讓大文件在單獨一個goroutine裡處理,因為大文件通常處理起來很慢,我們也就沒有辦法同時打開太多的大文件。所以我們的第二個策略就是,當有足夠多的goroutine在運行後,我們就不再為處理大的文件創建新的goroutine了(runtime.NumGoroutine函數能告訴我們在該函數調用的瞬間有多少goroutine在運行),而是強制讓當前的goroutine直接處理後續的每一個文件,不管它的大小是多少,並同時監控當前正在運行的goroutine的總數,這也就相當於限制了我們同時打開的文件數。一個goroutine處理完大文件並被Go運行時系統移除後,goroutine的總數就會減少。這會導致有時goroutine總數低於我們限制的最大數量,這時我們可以再創建新的goroutine去處理大文件。