
在前面幾章中我們看了幾個與創建以及讀寫文件有關的例子。本章我們將深入瞭解一下Go語言中的文件處理,特別是如何讀寫標準格式(如 XML和JSON 格式)的文件以及自定義的純文本和二進制格式文件。
由於前面的內容已覆蓋 Go語言的所有特性(下一章將要講到的使用自定義包和第三方包來創建程序的內容除外),現在我們可以靈活地使用Go語言提供的所有工具。我們會充分利用這種靈活性並利用閉包(參見5.6.3節)來避免重複性的代碼,同時在某些情況下充分利用Go語言對面向對象的支持,特別是對為函數添加方法的支持。
本章的重點在於文件而非目錄或者通用的文件系統。對於目錄,前面章節的findduplicates示例(參見7.2.5節)展示了如何使用filepath.Walk函數來迭代訪問目錄下的文件及其子目錄。此外,標準庫 os 包中的os.File 類型提供了用於讀取目錄下的文件名的方法(os.File.Readdirnames),以及用於獲取目錄下每一項的os.FileInfo 值的方法(os.File.Readdir)。
本章的第一節講解了如何使用標準和自定義的文件格式進行文件的讀寫。第二節講解了Go語言對處理壓縮文件及相應的壓縮算法的支持。
8.1 自定義數據文件
對一個程序非常普遍的需求包括維護內部數據結構,為數據交換提供導入導出功能,也支持使用外部工具來處理數據。由於我們這裡的關注重點是文件處理,因此我們純粹只關心如何從程序內部數據結構中讀取數據並將其寫入標準和自定義格式的文件中,以及如何從標準和自定義格式文件中讀取數據並寫入程序的內部數據結構中。
本節中,我們會為所有的例子使用相同的數據,以便直接比較不同的文件格式。所有的代碼都來自 invoicedate 程序(在 invoicedata 目錄中的invoicedata.go、gob.go、inv.go、jsn.go、txt.go和xml.go等文件中)。該程序接受兩個文件名作為命令行參數,一個用於讀,另一個用於寫(它們必須是不同的文件)。程序從第一個文件中讀取數據(以其後綴所表示的任何格式),並將數據寫入第二個文件(也是以其後綴所表示的任何格式)。
由invoicedata程序創建的文件可跨平台使用,也就是說,無論是什麼格式,Windows上創建的文件都可在 Mac OS X 以及 Linux 上讀取,反之亦然。Gzip 格式壓縮的文件(如invoices.gob.gz)可以無縫讀寫。壓縮相關的內容在8.2節闡述。
這些數據由一個*Invoice組成,也就是說,是一個保存了指向Invoice值的指針的切片。每一個發票數據都保存在一個Invoice類型的值中,同時每一個發票數據都以*Item的形式保存著0個或者多個項。

這兩個結構體用於保存數據。表8-1給出了一些非正式的對比,展示了每種格式下讀寫相同的50000份隨機發票數據所需的時間,以及以該格式所存儲文件的大小。計時按秒計,並向上捨入到最近的十分之一秒。我們應該把計時結果認為是無絕對單位的,因為不同硬件以及不同負載情況下該值都不盡相同。大小一欄以千字節(KB)算,該值在所有機器上應該都是相同的。對於該數據集,雖然未壓縮文件的大小千差萬別,但壓縮文件的大小都驚人的相似。而代碼的函數不包括所有格式通用的代碼(例如,那些用於壓縮和解壓縮以及定義結構體的代碼)。
表8-1 各種格式的速度以及大小對比
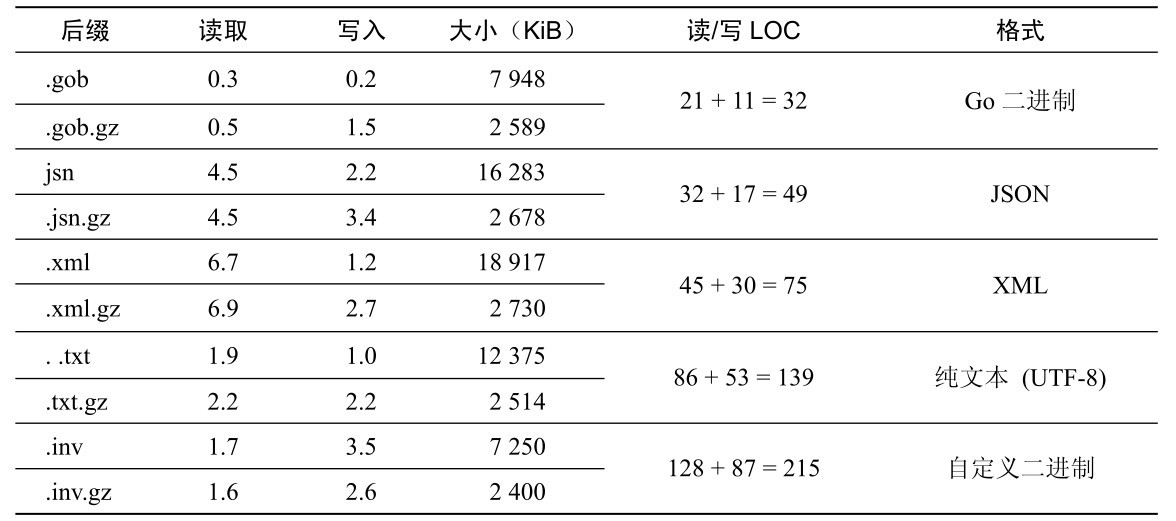
這些讀寫時間和文件大小在我們的合理預期範圍內,除了純文本格式的讀寫異常快之外。這得益於 fmt 包優秀的打印和掃瞄函數,以及我們設計的易於解析的自定義文本格式。對於JSON和XML 格式,我們只簡單地存儲了日期部分而非存儲默認的time.Time 值(一個ISO-8601 日期/時間字符串),通過犧牲一些速度和增加一些額外代碼稍微減小了文件的大小。例如,如果讓JSON代碼自己來處理time.Time值,它能夠運行得更快,並且其代碼行數與Go語言二進制編碼差不多。
對於二進制數據,Go語言的二進制格式是最便於使用的。它非常快且極端緊湊,所需的代碼非常少,並且相對容易適應數據的變化。然而,如果我們使用的自定義類型不原生支持 gob編碼,我們必須讓該類型滿足gob.Encoder和gob.Decoder接口,這樣會導致gob格式的讀寫相當得慢,並且文件大小也會膨脹。
對於可讀的數據,XML可能是最好使用的格式,特別是作為一種數據交換格式時非常有用。與處理JSON格式相比,處理XML格式需要更多行代碼。這是因為Go 1沒有一個xml.Marshaler接口(這個缺失有希望在Go 1.x之後的發行版中得到彌補),也因為我們這裡使用了並行的數據類型(XMLInvoice和XMLItem)來幫助映射XML數據和發票數據(Invoice和Item)。使用XML作為外部存儲格式的應用程序可能不需要並行的數據類型或者也不需要 invoicedata 程序這樣的轉換,因此就有可能比invoicedata例子中所給出的更快,並且所需的代碼也更少。
除了讀寫速度和文件大小以及代碼行數之外,還有另一個問題值得考慮:格式的穩健性。例如,如果我們為Invoice結構體和Item結構體添加了一個字段,那麼就必須再改變文件的格式。我們的代碼適應讀寫新格式並繼續支持讀舊格式的難易程度如何?如果我們為文件格式定義版本,這樣的變化就很容易被適應(會以本章一個練習的形式給出),除了讓JSON格式同時適應讀寫新舊格式稍微複雜一點之外。
除了Invoice和Item結構體之外,所有文件格式都共享以下常量:
const (
fileType = "INVOICES" // 用於純文本格式
magicNumber = 0x125D // 用於二進制格式
fileVersion = 100 // 用於所有的格式
dataFormat = "2006-01-02" // 必須總是使用該日期
)
magicNumber用於唯一標記發票文件[1]。fileVersion用於標記發票文件的版本,該標記便於之後修改程序來適應數據格式的改變。dataFormat稍後介紹(參見5.1.1.2節),它表示我們希望數據如何按照可讀的格式進行格式化。
同時,我們也創建了一對接口。
type InvoiceMarshaler interface {
MarshalInvoices(writer io.Writer, invoices *Invoice) error
}
type InvoiceUnmarshaler interface {
UnmarshalInvoices(reader io.Reader) (*Invoice, error)
}
這樣做的目的是以統一的方式針對特定格式使用 reader和writer。例如,下列函數是invoicedata程序用來從一個打開的文件中讀取發票數據的。
func readInvoices(reader io.Reader, suffix string)(*Invoice, error) {
var unmarshaler InvoicesUnmarshaler
switch suffix {
case ".gob":
unmarshaler = GobMarshaler{}
case ".inv":
unmarshaler = InvMarshaler{}
case ".jsn", ".json":
unmarshaler = JSONMarshaler{}
case ".txt":
unmarshaler = TxtMarshaler{}
case ".xml":
unmarshaler = XMLMarshaler{}
}
if unmarshaler != nil {
return unmarshaler.UnmarshalInvoices(reader)
}
return nil, fmt.Errorf("unrecognized input suffix: %s", suffix)
}
其中,reader 是任何能夠滿足 io.Reader 接口的值,例如,一個打開的文件(其類型為*os.File)、一個gzip解碼器(其類型為 *gzip.Reader)或者一個string.Reader。字符串 suffix 是文件的後綴名(從.gz 文件中解壓之後)。在接下來的小節中我們將會看到GobMarshaler和InvMarshaler 等自定義的類型,它們提供了 MarshalInvoices和UnmarshalInvoices方法(因此滿足InvoicesMarshaler和InvoicesUnmarshaler接口)。
8.1.1 處理JSON文件
根據www.json.org介紹,JSON(JavaScript對像表示法,JavaScript Object Notation)是一種易於人讀寫並且易於機器解析和生成的輕量級的數據交換格式。JSON 是一種使用 UTF-8編碼的純文本格式。由於寫起來比 XML 格式方便,並且(通常)更為緊湊,而所需的處理時間也更少,JSON格式已經越來越流行,特別是在通過網絡連接傳送數據方面。
這裡是一個簡單的發票數據的JSON表示,但是它省略了該發票的第二項的大部分字段。
{
"Id": 4461,
"CustomerId": 917,
"Raised": "2012-07-22",
"Due": "2012-08-21",
"Paid": true,
"Note": "Use trade entrance",
"Items": [
{
"Id": "AM2574",
"Price": 415.8,
"Quantity": 5,
"Note": ""
},
{
"Id": "MI7296",
...
}
]
}
通常,encodeing/json 包所寫的JSON 數據沒有任何不必要的空格,但是這裡我們為了更容易看明白數據的結構而使用了縮進和空白來展示它。雖然 encoding/json 包支持time.Times,但是我們通過自己實現自定義的MarshalJSON和UnmarshalJSON Invoice方法來處理發票的開具和到期日期。這樣我們就可以存儲更短的日期字符串(因為對於我們的數據來說,其時間部分始終為0),例如「2012-09-06」,而非整個日期/時間值,如「2012-09-06T00:00:00Z」。
8.1.1.1 寫JSON文件
我們創建了一個基於空結構體的類型,它定義了與 JSON 相關的MarshalInvoices和UnmarshalInvoices方法。
type JSONMarshaler struct{}
該類型滿足我們在前文看到的InvoicesMarshaler和InvoicesUnmarshaler接口(見8.1節)。
這裡的方法使用encoding/json包中標準的Go到JSON序列化函數將*Invoice項中的所有數據以JSON格式寫入一個io.Writer中。該writer可以是os.Create函數返回的*os.File,或者是 gzip.NewWriter函數返回的*gzip.Writer,或者是任何滿足io.Writer接口的其他值。
unc (JSONMarshaler) MarshalInvoices(writer io.Writer, invoices *Invoice) error {
encoder := json.NewEncoder(writer)
if err := encoder.Encode(fileType); err != nil {
return err
}
if err := encoder.Encode(fileVersion); err != nil {
return err
}
return encoder.Encode(invoices)
}
JSONMarshaler類型沒有數據,因此我們沒必要將其值賦值給一個接收器變量。
函數開始處,我們創建了一個 JSON 編碼器,它包裝了 io.Writer,可以接收我們寫入的支持JSON編碼的數據。
我們使用json.Encoder.Encode方法來寫入數據。該方法能夠完美地處理發票切片,其中每個發票都包含一到多個項的切片。該方法返回一個錯誤值或者空值nil。如果返回的是一個錯誤值,則立即返回給調用者。
文件的類型和版本不是必須寫入的,但在後面一個練習中會看到,這樣做是為了以後更容易更改文件格式(例如,為了適應Invoice和Item結構體中額外的字段),以及為了能夠同時支持讀取新舊格式的數據。
需注意的是,該方法實際上與它所編碼的數據類型無關,因此很容易創建類似函數用於寫入其他可JSON編碼的數據。另外,只要新的文件格式中新增的字段是導出的且支持JSON編碼,該JSONMarshaler.MarshalInvoices方法無需做任何更改。
如果這裡所給出的代碼就是JSON相關代碼的全部,這樣當然可以很好地工作。然而,由於我們希望更好地控制JSON的輸出,特別是對time.Time值的格式化,我們還為Invoice類型提供了一個滿足 json.Marshaler 接口的MarshalJSON方法。json.Encode函數足夠智能,它會去檢查所需編碼的值是否支持 json.Marshaler 接口,如果支持,該函數會使用該值的MarshalJSON方法而非內置的編碼代碼。
type JSONInvoice struct {
Id int
CustomerId int
Raised string // Invoice結構體中的time.Time
Due string // Invoice結構體中的time.Time
Paid bool
Note string
Items *Item
}
func (invoice Invoice) MarshalJSON(byte, error) {
jsonInvoice := JSONInvoice {
invoice.Id,
invoice.CustomerId,
invoice.Raised.Format(dateFormat),
invoice.Due.Format(dateFormat),
invoice.Paid,
invoice.Note,
invoice.Items,
}
return json.Marshal(jsonInvoice)
}
該自定義的Invoice.MarshalJSON方法接受一個已有的Invoice 值,返回一個該數據 JSON 編碼後的版本。該函數的第一個語句簡單地將發票的各個字段複製到自定義的JSONInvoice結構體中,同時將兩個time.Time值轉換成字符串。由於JSONInvoice結構體的字段都是布爾類型、數字或者字符串,該結構體可以使用 json.Marshal函數進行編碼,因此我們使用該函數來完成工作。
為了將日期/時間(即 time.Time 值)以字符串的形式寫入,我們必須使用 time.Time.Format方法。該方法接受一個格式字符串,它表示該日期/時間值應該如何寫入。該格式字符串非常特殊,必須是一個Unix時間1 136 243 045的字符串表示,即精確的日期/時間值2006-01-02T15:04:05Z07:00,或者跟這裡一樣,使用該日期/時間值的子集。該特殊的日期/時間值是任意的,但必須是確定的,因為沒有其他的值來聲明日期、時間以及日期/時間的格式。
如果我們想自定義日期/時間格式,它們必須按照 Go語言的日期/時間格式來寫。假如我們要以星期、月、日和年的形式來寫日期,我們必須使用「Mon, Jan 02, 2006」這種格式,或者如果我們希望刪除前導的0,就必須使用「Mon, Jan _2, 2006」這種格式。time包的文檔中有完整的描述,並列出了一些預定義的格式字符串。
8.1.1.2 讀JSON文件
讀JSON數據與寫JSON數據一樣簡單,特別是當將數據讀回與寫數據時類型一樣的變量時。JSONMarshaler.UnMarshalInvoices方法接受一個 io.Reader 值,該值可以是一個 os.Open函數返回的*os.File 值,或者是一個 gzip.NewReader函數返回的*gzip.Reader值,也可以是任何滿足io.Reader接口的值。
func (JSONMarshaler) UnmarshalInvoices(reader io.Reader) (*Invoice, error){
decoder := json.NewDecoder(reader)
var kind string
if err := decoder.Decode(&king); err != nil {
return nil, err
}
if kind != fileType {
return nil, errors.New("Cannot read non-invoices json file")
}
var version int
if err := decoder.Decode(&version); err != nil {
return nil, err
}
if version > fileVersion {
return nil, fmt.Error("version %d is too new to read", version)
}
var invoices *Invoice
err := decoder.Decode(&invoices)
return invoices, err
}
我們需讀入3項數據:文件類型、文件版本以及完整的發票數據。json.Decoder.Decode方法接受一個指針,該指針所指向的值用於存儲解碼後的JSON數據,解碼後返回一個錯誤值或者nil。我們使用前兩個變量(kind和version)來保證接受一個JSON格式的發票文件,並且該文件的版本是我們能夠處理的。然後程序讀取發票數據,在該過程中,隨著json.Decoder.Decode方法所讀取發票數的增多,它會增加invoices切片的長度,並將相應發票的指針(及其項目)保存在切片中,這些指針是UnmarshalInvoices函數在必要時實時創建的。最後,該方法返回解碼後的發票數據和一個nil值。或者,如果解碼過程中遇到了問題則返回一個nil值和一個錯誤值。
如果我們之前純粹依賴於json包內置的功能把數據的創建及到期日期按照默認的方式序列化,那麼這裡給出的代碼已經足以反序列化一個 JSON 格式的發票文件。然而,由於我們使用自定義的方式來序列化數據的建立和到期日期 time.Times(只存儲日期部分),我們必須提供一個自定義的反序列化方法,該方法理解我們的自定義序列化流程。
func (invoice *Invoice) UnmarshalJSON(data byte) (err error) {
var jsonInvoice JSONInvoice
if err = json.Unmarshal(data, &jsonInvoice); err != nil {
return err
}
var raised, due time.Time
if raised, err = time.Parse(dateFormat, jsonInvoice.Raised);
err != nil {
return err
}
if due, err = time.Parse(dateFormat, jsonInvoice.Due); err != nil {
return err
}
*invoice = Invoice {
jsonInvoice.Id,
jsonInvoice.CustomerId,
raised,
due,
jsonInvoice.Paid,
jsonInvoice.Note,
jsonInvoice.Items,
}
return nil
}
該方法使用與前面一樣的JSONInvoice結構體,並且依賴於json.Unmarshal函數來填充數據。然後,我們將反序列化後的數據以及轉換成 time.Time的日期值賦給新創建的Invoice變量。
json.Decoder.Decode足夠智能會檢查它需要解碼的值是否滿足 json.Unmarshaler接口,如果滿足則使用該值自己的UnmarshalJSON方法。
如果發票數據因為新添加了導出字段而發生改變,該方法能繼續正常工作的前提是我們必須讓Invoice.UnmarshalJSON方法也能處理版本變化。另外,如果新添加字段的零值不可被接受,那麼當以原始格式讀文件的時候,我們必須對數據做一些後期處理,並給它們一個合理的值。(有一個練習需要添加新字段以及進行此類後期處理工作。)
雖然要支持兩個或者更多個版本的JSON文件格式有點麻煩,但JSON是一種很容易處理的格式,特別是如果我們創建的結構體的導出字段比較合理時。同時,json.Encoder.Encode函數和json.Decoder.Decode函數也不是完美可逆的,這意味著序列化後得到的數據經過反序列化後不一定能夠得到原始的數據。因此,我們必須小心檢查,保證它們對我們的數據有效。
順便提一下,還有一種叫做BSON(Binary JSON)的格式與JSON非常類似,它比JSON更為緊湊,並且讀寫速度也更快。godashboard.appspot.com/project 網頁上有一個支持BSON格式的第三方包(gobson)。(安裝和使用第三方包的內容將在第9章闡述。)
8.1.2 處理XML文件
XML(eXtensible Markup Language)格式被廣泛用作一種數據交換格式,並且自成一種文件格式。與JSON相比,XML複雜得多,手動寫起來也囉嗦而且乏味得多。
encoding/xml包可以用在結構體和XML格式之間進行編解碼,其方式跟encoding/json包類似。然而,與encoding/json包相比,XML的編碼和解碼在功能上更苛刻得多。這部分是由於encoding/xml包要求結構體的字段包含格式合理的標籤(然而JSON格式卻不需要)。同時, Go 1的encoding/xml包沒有xml.Marshaler接口,因此與編解碼JSON格式和Go語言的二進制格式相比,我們處理 XML 格式時必須寫更多的代碼。(該問題有望在 Go 1.x 發行版中得以解決。)
這裡有個簡單的XML 格式的發票文件。為了適應頁面的寬度和容易閱讀,我們添加了換行和額外的空白。
<INVOICE Id="2640" CustomerId="968" Raised="2012-08-27" Due="2012-09-26"
Paid="false"><NOTE>See special Terms & Conditions</NOTE>
<ITEM Id="MI2419" Price="342.80" Quantity="1"><NOTE></NOTE></ITEM>
<ITEM Id="OU5941" Price="448.99" Quantity="3"><NOTE>
"Blue" ordered but will accept "Navy"</NOTE> </ITEM>
<ITEM Id="IF9284" Price="475.01" Quantity="1"><NOTE></NOTE></ITEM>
<ITEM Id="TI4394" Price="417.79" Quantity="2"><NOTE></NOTE></ITEM>
<ITEM Id="VG4325" Price="80.67" Quantity="5"><NOTE></NOTE></ITEM>
</INVOICE>
對於xml包中的編碼器和解碼器而言,標籤中如果包含原始字符數據(如invoice和item中的Note字段)處理起來比較麻煩,因此invoicedata示例使用了顯式的<NOTE>標籤。
8.1.2.1 寫XML文件
encoidng/xml包要求我們使用的結構體中的字段包含encoding/xml包中所聲明的標籤,所以我們不能直接將Invoice和Item結構體用於XML序列化。因此,我們創建了針對XML格式的XMLInvoices、XMLInvoice和XMLItem結構體來解決這個問題。同時,由於invoicedata程序要求我們有並行的結構體集合,因此必須提供一種方式來讓它們相互轉換。當然,使用XML格式作為主要存儲格式的應用程序只需一個結構體(或者一個結構體集合),同時要將必要的encoidng/xml包的標籤直接添加到結構體的字段中。
下面是保存整個數據集合的XMLInvoices結構體。
type XMLInvoices struct {
XMLName xml.Name `xml:"INVOICES"`
Version int `xml:"version,attr"`
Invoice *XMLInvoice `xml:"INVOICE"`
}
在Go語言中,結構體的標籤本質上沒有任何語義,它們只是可以使用Go語言的反射接口獲得的字符串(參見9.4.9節)。然而,encoding/xml包要求我們使用該標籤來提供如何將結構體的字段映射到XML的信息。xml.Name字段用於為XML中的標籤命名,該標籤包含了該字段所在的結構體。以`xml:「,attr」`標記的字段將成為該標籤的屬性,字段名字將成為屬性名。我們也可以根據自己的喜好使用另一個名字,只需在所給的名字簽名加上一個逗號。這裡,我們把Version字段當做一個叫做version的屬性,而非默認的名字Version。如果標籤只包含一個名字,則該名字用於表示嵌套的標籤,如此例中的<INVOICE>標籤。有一個非常重要的細節需注意的是,我們把 XMLInvoices的發票字段命名為 Invoice,而非Invoices,這是為了匹配XML格式中的標籤名(不區分大小寫)。
下面是原始的Invoice結構體,以及與XML格式相對應的XMLInvoice結構體。

在這裡,我們為屬性提供了默認的名字。例如,字段CustomerId在XML中對應一個屬性,其名字與該字段的名字完全一樣。這裡有兩個可嵌套的標籤:<NOTE>和<ITEM>,並且如XMLInvoices結構體一樣,我們把XMLInvoice的item字段定義成Item(大小寫不敏感)而非Items,以匹配標籤名。
由於我們希望自己處理創建和到期日期(只存儲日期),而非讓encoding/xml包來保存完整的日期/時間字符串,我們為它們在XMLInvoice結構體中定義了相應的Raised和Due字段。
下面是原始的Item結構體,以及與XML相對應的XMLItem結構體。

除了作為嵌套的<NOTE>標籤的Note字段和用於保存該XML標籤名的XMLName字段之外,XMLItem的字段都被打上了標籤以作為屬性。
正如處理JSON格式時所做的那樣,對於XML格式,我們創建了一個空的結構體並關聯了XML相關的MarshalInvoices方法和UnmarshalInvoices方法。
type XMLMarshaler struct{}
該類型滿足前文所述的InvoicesMarshaler和InvoiceUnmarshaler接口(參見8.1節)。
func (XMLMarshaler) MarshalInvoices(writer io.Writer, invoices *Invoice) error {
if _, err := writer.Writer(byte(xml.Header)); err != nil {
return err
}
xmlInvoices := XMLInvoicesForInvoices(invoices)
encoder := xml.NewEncoder(writer)
return encoder.Encode(xmlInvoices)
}
該方法接受一個io.Writer(也就是說,任何滿足io.Writer接口的值如打開的文件或者打開的壓縮文件),以用於寫入XML數據。該方法從寫入標準的XML頭部開始(該xml.Header常量的末尾包含一個新行)。然後,它將所有的發票數據及其項寫入相應的XML結構體中。這樣做雖然看起來會耗費與原始數據相同的內存,但是由於Go語言的字符串是不可變的,因此在底層只將原始數據字符串的引用複製到XML結構體中,因此其代價並不是我們所看到的那麼大。而對於直接使用帶有XML標籤的結構體的應用而言,其數據沒必要再次轉換。
一旦填充好 xmlInvoices(其類型為 XMLInvoices)後,我們創建了一個新的xml.Encoder,並將我們希望寫入數據的io.Writer傳給它。然後,我們將數據編碼成XML格式,並返回編碼器的返回值,該值可能為一個error值也可能為nil。
func XMLInvoicesForInvoices(invoices *Invoice) *XMLInvoices {
xmlInvoices := &XMLInvoices{
Version: fileVersion,
Invoice: make(*XMLInvoice, 0, len(invoices)),
}
for _, invoice := range invoices {
xmlInvoices.Invoice = append(xmlInvoices.Invoice,
XMLInvoiceForInvoice (invoice))
}
return xmlInvoices
}
該函數接受一個*Invoice 值並返回一個 *XMLInvoices 值,其中包含轉換成*XMLInvoices(還包含 *XMLItems 而非 *Items)的所有數據。該函數又依賴於XmlInvoiceForInvoice函數來為其完成所有工作。
我們不必手動填充 xml.Name 字段(除非我們想使用名字空間),因此在這裡,當創建*XMLInvoices的時候,我們只需填充Version字段以保證我們的標籤有一個version屬性,例如<INVILES verion=」100」>。同時,我們將 Invoice字段設置成一個空間足夠容納所有的發票數據的空切片。這樣做不是嚴格必須的,但是與將該字段的初始值留空相比,這樣做可能更高效,因為這樣做意味著調用內置的append函數時無需分配內存和複製數據以擴充切片容量。
func XMLInvoiceForInvoice(invoice *Invoice) *XMLInvoice {
xmlInvoice := &XMLInvoice{
Id: invoice.id,
CustomerId: invoice.CustomerId,
Raised: invoice.Raised.Format(dateFormat),
Due: invoice.Due.Format(dateFormat),
Paid: invoice.Paid,
Note: invoice.Note,
Item: make(*XMLItem, 0, len(invoice.Items)),
}
for _, item := range invoice.Items {
xmlItem := &XMLItem {
Id: item.Id,
Price: item.Price,
Quantity: item.Quantity,
Note: item.Note,
}
xmlInvoice.Item = append(xmlInvoice.Item, xmlItem)
}
return xmlInvoice
}
該函數接受一個Invoice值並返回一個等價的XMLInvoice值。該轉換非常直接,只需簡單地將Invoice中每個字段的值複製至XMLInvoice字段中。由於我們選擇自己來處理創建以及到期日期(因此我們只需存儲日期而非完整的日期/時間),我們只需將其轉換成字符串。而對於Invoice.Items字段,我們將每一項轉換成XMLItem後添加到XMLInvoice.Item切片中。與前面一樣,我們使用相同的優化方式,創建 Item 切片時分配了足夠多的空間以避免 append時需要分配內存和複製數據。前文闡述 JSON 格式時我們已討論過 time.Time值的寫入(參見8.1.1.1節)。
最後需要注意的是,我們的代碼中沒有做任何 XML 轉義,它是由 xml.Encoder.Encode方法自動完成的。
8.1.2.2 讀XML文件
讀XML文件比寫XML文件稍微複雜,特別是在必須處理一些我們自定義的字段的時候(例如日期)。但是,如果我們使用合理的打上XML標籤的結構體,就不會複雜。
func (XMLMarshaler) UnmarshalInvoices(reader io.Reader)(*Invoice, error) {
xmlInvoices := &XMLInvoices{}
decoder := xml.NewDecoder(reader)
if err := decoder.Decode(xmlInvoices); err != nil {
return nil, err
}
if xmlInvoices.Version > fileVersion {
return nil, fmt.Errorf("version %d is too new to read", xmlInvoices.Version)
}
return xmlInvoices.Invoices
}
該方法接受一個 io.Reader(也就是說,任何滿足 io.Reader 接口的值如打開的文件或者打開的壓縮文件),並從其中讀取XML。該方法的開始處創建了一個指向空XMLInvoices結構體的指針,以及一個 xml.Decoder 用於讀取 io.Reader。然後,整個 XML 文件由xml.Decoder.Decode方法解析,如果解析成功則將 XML 文件的數據填充到該*XMLInvoices結構體中。如果解析失敗(例如,XML文件語法有誤,或者該文件不是一個合法的發票文件),那麼解碼器會立即返回錯誤值給調用者。如果解析成功,我們再檢查其版本,如果該版本是我們能夠處理的,就將該XML結構體轉換成我們程序內部使用的結構體。當然,如果我們直接使用帶XML標籤的結構體,該轉換步驟就沒必要了。
func (xmlInvoices *XMLInvoices) Invoices (invoices *Invoice, err error){
invoices = make(*Invoice, 0, len(xmlInvoices.Invoice))
for _, XMLInvoice := range xmlInvoices.Invoice {
invoice, err := xmlInvoice.Invoice
if err != nil {
return nil, err
}
invoices = append(invoices, invoice)
}
return invoices, nil
}
該XMLInvoices.Invoices方法將一個*XMLInvoices值轉換成一個*Invoice值,它是 XmlInvoicesForInvoices函數的逆反操作,並將具體的轉換工作交給XMLInvoice.Invoice方法完成。
func (xmlInvoice *XMLInvoice) Invoice (invoice *Invoice, err error) {
invoice = &Invoice{
Id: xmlInvoice.Id,
CustomerId: xmlInvoice.CustomerId,
Paid: xmlInvoice.Paid,
Note: strings.TrimSpace(xmlInvoice.Note),
Items: make(*Item, 0, len(xmlInvoice.Item)),
}
if invoice.Raised, err = time.Parse(dateFormat, xmlInvoice.Raised);
err != nil {
return nil, err
}
if invoice.Due, err = time.Parse(dateFormat, xmlInvoice.Due);
err != nil{
return nil, err
}
for _, xmlItem := range xmlInvoice.Item {
item := &Item {
Id: xmlItem.Id,
Price: xmlItem.Price,
Quantity: xmlItem.Quantity,
Note: strings.TrimSpace(xmlItem.Note),
}
invoice.Items = append(invoice.Items, item)
}
return invoice, nil
}
該方法用於返回與調用它的*XMLInvoice值相應的*Invoice值。
該方法在開始處創建了一個Invoice值,其大部分字段都由來自XMLInvoice的數據填充,而Items字段則設置成一個容量足夠大的空切片。
然後,由於我們選擇自己處理這些,因此手動填充兩個日期/時間字段。time.Parse函數接受一個日期/時間格式的字符串(如前所述,該字符串必須基於精確的日期/時間值,如2006-01-02T15:04:05Z07:00),以及一個需要解析的字符串,並返回等價的time.Time 值和nil,或者,返回一個nil和一個錯誤值。
接下來是填充發票的Items 字段,這是通過迭代 XMLInvoice的Item 字段中的*XMLItems並創建相應的*Items來完成的。最後,返回 *Invoice。
正如寫 XML 時一樣,我們無需關心對所讀取的XML 數據進行轉義,xml.Decoder.Decode函數會自動處理這些。
xml 包支持比我們這裡所需的更為複雜的標籤,包括嵌套。例如,標籤名為`xml:"Books> Author"`產生的是<Books><Author>content</Author></Books>這樣的XML內容。同時,除了`xml:",attr"`之外,該包還支持`xml:",chardata"`這樣的標籤表示將該字段當做字符數據來寫,支持`xml:",innerxml"`這樣的標籤表示按照字面量來寫該字段,以及`xml:",comment"`這樣的標籤表示將該字段當做 XML 註釋。因此,通過使用標籤化的結構體,我們可以充分利用好這些方便的編碼解碼函數,同時合理控制如何讀寫XML數據。
8.1.3 處理純文本文件
對於純文本文件,我們必須創建自定義的格式,理想的格式應該易於解析和擴展。
下面是某單個發票以自定義純文本格式存儲的數據。
INVOICE ID=5441 CUSTOMER=960 RAISED=2012-09-06 DUE=2012-10-06 PAID=true
ITEM ID=BE9066 PRICE=400.89 QUANTITY=7: Keep out of <direct> sunlight
ITEM ID=AM7240 PRICE=183.69 QUANTITY=2
ITEM ID=PT9110 PRICE=105.40 QUANTITY=3: Flammable

在該格式中,每個發票是一個INVOICE行,然後是一個或者多個ITEM行,最後是換頁符。每一行(無論是發票還是它們的項)的基本結構都相同:起始處有一個單詞表示該行的類型,接下來是一個空格分隔的「鍵=值」序列,以及可選的跟在一個冒號和一個空格後面的註釋文本。
8.1.3.1 寫純文本文件
由於Go語言的fmt包中打印函數強大而靈活(這在前文已有闡述,詳見3.5節),寫純文本數據非常簡單直接。
type TxtMarshaler struct{}
func (TxtMarshaler) MarshalInvoices(writer io.Writer,
invoices *Invoice) error {
bufferedWriter := bufio.NewWriter(writer)
defer bufferedWriter.Flush
var write writerFunc = func(format string, args…interface{}) error {
_, err := fmt.Fprintf(bufferedWriter, format, args...)
return err
}
if err := write("%s %d\n", fileType, fileVersion); err != nil {
return err
}
for _, invoice := range invoices {
if err := write.WriteInvoice(invoice); err != nil {
return err
}
}
return nil
}
該方法在開始處創建了一個帶緩衝區的writer,用於操作所傳入的文件。延遲執行刷新緩衝區的操作是必要的,這可以保證我們所寫的數據確實能夠寫入文件(除非發生錯誤)。
與以if _, err := fmt.Fprintf(bufferedWriter,...); err != nil {return err}的形式來檢查每次寫操作不同的是,我們創建了一個函數字面量來做兩方面的簡化。第一,該writer函數會忽略fmt.Fprintf函數報告的所寫字節數。其次,該函數處理了bufferedWriter,因此我們不必在自己的代碼中顯式地提到。
我們本可以將 write函數傳給輔助函數的,例如,writeInvoice(write, invoice)。但不同於此做法的是,我們往前更進了一步,將該方法添加到writerFunc類型中。這是通過聲明接受一個writerFunc值作為其接收器的方法(即函數)來達到,跟定義任何其他類型一樣。這樣就允許我們以write.writeInvoice(invoice)這樣的形式調用,也就是說,在 write函數自身上調用方法。並且,由於這些方法接受 write函數作為它們的接收器,我們就可以使用write函數。
需注意的是,我們必須顯式地聲明write函數的類型(writerFunc)。如果不這樣做, Go語言就會將其類型定義為func(string,...interface{}) error(當然,它本來就是這種類型),並且不允許我們在其上調用writerFunc方法(除非我們使用類型轉換的方法將其轉換成writerFunc類型)。
有了方便的write函數(及其方法),我們就可以開始寫入文件類型和文件版本(後者使得容易適應數據的改變)。然後,我們迭代每一個發票項,針對每一次迭代,我們調用write函數的writeInvoice方法。
const noteSep = ":"
type writerFunc func(string,..interface{}) error
func (write writerFunc) writeInvoice(invoice *Invoice) error {
note := ""
if invoice.Note != "" {
note = noteSep + " " + invoice.Note
}
if err := write("INVOICE ID=%d CUSTOMER=%d RAISED=%s DUE=%s" +
"PAID=%t%s\n", invoice.Id, invoice.CustomerId,
invoice.Raised.Format(dateFormat),
invoice.Due.Format(dateFormat), invoice.Paid, note); err != nil {
return err
}
if err := write.writeItems(invoice.Items); err != nil {
return err
}
return write("\f\n")
}
該方法用於寫每一個發票項。它接受一個要寫的發票項,同時使用作為接收器傳入的write函數來寫數據。
發票數據一次性就可以寫入。如果給出了註釋文本,我們就在其前面加入冒號以及空格來將其寫入。對於日期/時間(即 time.Time 值),我們使用 time.Time.Format方法,跟我們以JSON和XML格式寫入數據時一樣。而對於布爾值,我們使用%t格式指令,也可以使用%v格式指令或strconv.FormatBool函數。
一旦發票行寫好了,就開始寫發票項。最後,我們寫入分頁符和一個換行符,表示發票數據的結束。
func (write writerFunc) writeItems(items *Item) error {
for _, item := range items {
note := ""
if item.Note != "" {
note = noteSep + " " + item.Note
}
if err := write("ITEM ID=%s PRICE=%.2f QUANTITY=%d%s\n", item.Id,
item.Price, item.Quantity, note); err != nil {
return err
}
}
return nil
}
該writeItems方法接受發票的發票項,並使用作為接收器傳入的write函數來寫數據。它迭代每一個發票項並將其寫入,並且也跟寫入發票數據一樣,如果其註釋文檔為空則無需寫入。
8.1.3.2 讀純文本文件
打開並讀取一個純文本格式的數據跟寫入純文本格式數據一樣簡單。要解析文本來重建原始數據可能稍微複雜,這需根據格式的複雜性而定。
有4種方法可以使用。前3種方法包括將每行切分,然後針對非字符串的字段使用轉換函數如strconv.Atoi和time.Parse。這些方法是:第一,手動解析(例如,一個字母一個字母或者一個字一個字地解析),這樣做實現起來煩瑣,不夠健壯並且也慢;第二,使用fmt.Fields或者 fmt.Split函數來將每行切分;第三,使用正則表達式。對於該invoicedata 程序,我們使用第四種方法。無需將每行切分或者使用轉換函數,因為我們所需的功能都能夠交由fmt包的掃瞄函數處理。
func (TxtMarshaler) UnmarshalInvoices(reader io.Reader) (*Invoice, error) {
bufferedReader := bufio.NewReader(reader)
if err := checkTxtVersion(bufferedReader); err != nil {
return nil, err
}
var invoices *Invoice
eof := false
for lino := 2; !eof; lino++ {
line, err := bufferedReader.ReadString('\n)
if err == io.EOF{
err = nil // io.EOF不是一個真正的錯誤
eof = true // 下一次迭代的時候會終止循環
} else if err != nil {
return nil, err // 遇到真正的錯誤則立即停止
}
if invoices, err = parseTxtLine(lino, line, invoices); err != nil {
return nil, err
}
}
return invoices, nil
}
針對所傳入的io.Reader,該方法創建了一個帶緩衝的reader,並將其中的每一行輪流傳入解析函數中。通常,對於文本文件,我們會對io.EOF進行特殊處理,以便無論它是否以新行結尾其最後一行都能被讀取。(當然,對於這種格式,這樣做相當自由。)
按照常規,從行號1開始,該文件被逐行讀取。第一行用於檢查文件是否有個合法的類型和版本號,因此處理實際數據時,行號(lino)從2開始讀起。
由於我們逐行工作,並且每一個發票文件都表示成兩行甚至多行(一行 INVOICE 行和一行或者多行ITEM行),我們需跟蹤當前發票,以便每讀一行就可以將其添加到當前發票數據中。這很容易做到,因為所有的發票數據都被追加到一個發票切片中,因此當前發票永遠是處於位置invoices[len(invoices)-1]處的發票。
當parseTxtLine函數解析一個INVOICE行時,它會創建一個新的Invoice值,並將一個指向該值的指針追加到invoices切片中。
如果要在一個函數內部往一個切片中追加數據,有兩種技術可以使用。第一種技術是傳入一個指向切片的指針,然後在所指向的切片中操作。第二種技術是傳入切片值,同時返回(可能被修改過的)切片給調用者,以賦值回原始切片。parseTxtLine函數使用第二種技術。(我們在前文已看過一個使用第一種技術的例子。)
func parseTxtLine(lino int, line string, invoices *Invoice) (*Invoice, error) {
var err error
if strings.HasPrefix(line, "INVOICE") {
var invoice *Invoice
invoice, err = parseTxtInvoice(lino, line)
invoices = append(invoices, invoice)
} else if strings.HasPrefix(line, "ITEM") {
if len(invoices) == 0 {
err = fmt.Errorf("item outside of an invoice line %d", lino)
} else {
var item *Item
item, err = parseTxtItem(lino, line)
items := &invoices[len(invoices)-1].Items 1
*items = append(*items, item)
}
}
return invoices, err
}
該函數接受一個行號(lino,用於錯誤報告),需被解析的行,以及我們需要填充的發票切片。
如果該行以文本「INVOICE」開頭,我們就調用 parseTxtInvoice函數來解析該行並創建一個 Invoice 值,並返回一個指向它的指針。然後,我們將該*Invoice 值追加到invoices切片中,並在最後返回該invoices切片和nil值或者錯誤值。需注意的是,這裡的發票信息是不完整的,我們只有它的ID、客戶 ID、創建和持續時間、是否支付以及註釋信息,但是沒有任何發票項。
如果該行以「ITEM」開頭,我們首先檢查當前發票是否存在(即invoices切片不為空)。如果存在,我們調用parseTxtItem函數來解析該行並創建一個Item值,然後返回一個指向該值的指針。然後我們將該項添加到當前發票的項中。這可以通過取得指向當前發票項的指針(見標注1)以及將指針的值設置為追加新*Item後的結果來達到。當然,我們本可以使用invoices[len(invoices)-1].Items = append(invoices[len(invoices)-1].Items, item)來直接添加 *Item。
任何其他的行(例如空和換頁行)都被忽略。順便提一下,理論上而言,如果我們優先處理「ITEM」的情況該函數會更快,因為數據中發票項的行數遠比發票和空行的行數多。
func parseTxtInvoice(lino int, line string) (invoice *Invoice, err error) {
invoice = &Invoice{}
var raised, due string
if _, err = fmt.Sscanf(line, "INVOICE ID=%d CUSTOMER=%d" +
"RAISED=%s DUE=%s PAID=%t", &invoice.Id, &invoice.CustomerId,
&raised, &due, &invoice.Paid); err != nil {
return nil, fmt.Errorf("invalid invoice %v line %d", err, lino)
}
if invoice.Raised, err = time.Parse(dateFormat, raised); err != nil {
return nil, fmt.Errorf("invalid raised %v line %d", err, lino)
}
if invoice.Due, err = time.Parse(dateFormat, due); err != nil {
return nil, fmt.Errorf("invalid due %v line %d", err, lino)
}
if i := strings.Index(line, noteSep); i > -1 {
invoice.Note = strings.TrimSpace(line[i+len(noteSep):])
}
return invoice, nil
}
函數開始處,我們創建了一個0值的Invoice值,並將指向它的指針賦值給invoice變量(類型為*Invoice)。掃瞄函數可以處理字符串、數字以及布爾值,但不能處理time.Time值,因此我們將創建以及持續時間以字符串的形式輸入,並單獨解析它們。表8-2中列出了掃瞄函數。
表8-2 fmt中的掃瞄函數

續表
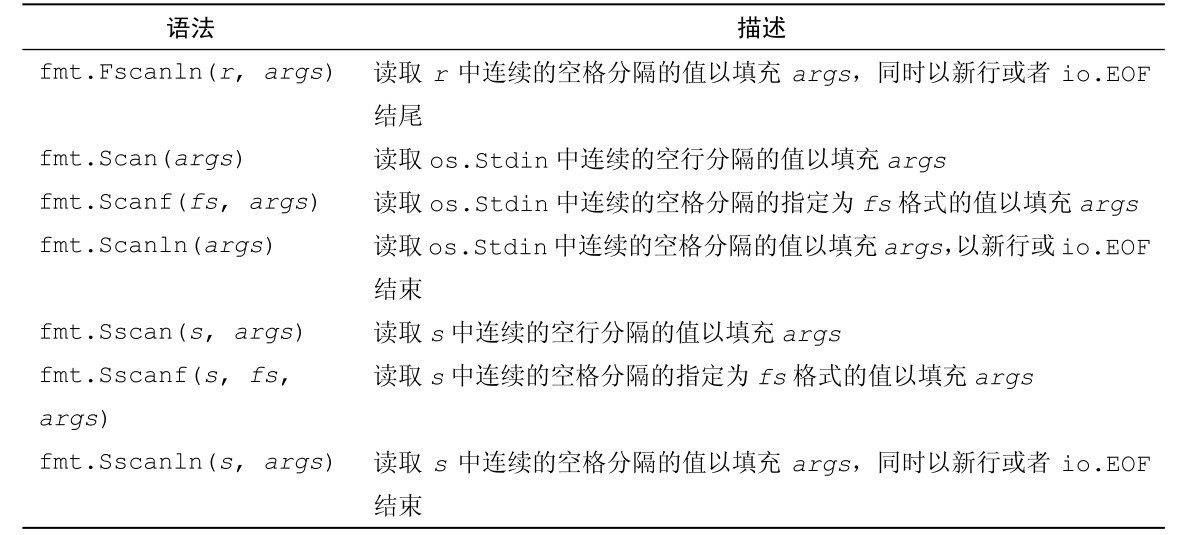
如果fmt.Sscanf函數不能讀入與我們所提供的值相同數量的項,或者如果發生了錯誤(例如,讀取錯誤),函數就會返回一個非空的錯誤值。
日期使用time.Parse函數來解析,這在之前的節中已有闡述。如果發票行有冒號,則意味著該行末尾處有註釋,那麼我們就刪除其空白符,並將其返回。我們使用了表達式line[i+1:]而非line[i+len(noteSep):],因為我們知道noteSep的冒號字符佔用了一個UTF-8字節,但為了更為健壯,我們選擇了對任何字符都有效的方法,無論它佔用多少字節。
func parseTxtItem(lino int, line string) (item *Item, err error) {
item = &Item{}
if _, err = fmt.Sscanf(line, "ITEM ID=%s PRICE=%f QUANTITY=%d",
&item.Id, &item.Price, &item.Quantity); err != nil {
return nil, fmt.Errorf("invalid item %v line %d", err, lino)
}
if i := strings.Index(line, noteSep); i > -1 {
item.Note = strings.TrimSpace(line[i+len(noteSep):])
}
return item, nil
}
該函數的功能如我們所見過的parseTxtInvoice函數一樣,區別在於除了註釋文本之外,所有的發票項值都可以直接掃瞄。
func checkTxtVersion(bufferReader *buffio.Reader) error {
var version int
if _, err := fmt.Fscanf(bufferedReader, "INVOICES %d\n", &version);
err != nil {
return errors.New("cannot read non-invoices text file")
} else if version > fileVersion {
return fmt.Erroff("version %d is too new to read", version)
}
return nil
}
該函數用於讀取發票文本文件的第一行數據。它使用 fmt.Fscanf函數來直接讀取bufio.Reader。如果該文件不是一個發票文件或者其版本太新而不能處理,就會報告錯誤。否則,返回nil值。
使用fmt包的打印函數來寫文本文件比較容易。解析文本文件卻挑戰不小,但是Go語言的regexp包中提供了strings.Fields和strings.Split函數,fmt包中提供了掃瞄函數,使得我們可以很好的解決該問題。
8.1.4 處理Go語言二進制文件
Go語言的二進制(gob)格式是一個自描述的二進制序列。從其內部表示來看,Go語言的二進制格式由一個0塊或者更多塊的序列組成,其中的每一塊都包含一個字節數,一個由0個或者多個 typeId-typeSpecification 對組成的序列,以及一個 typeId-value 對。如果 typeId-value對的typeId是預先定義好的(例如,bool、int和string等),則這些typeId-typeSpecification對可以省略。否則就用類型對來描述一個自定義類型(如一個自定義的結構體)。類型對和值對之間的typeId沒有區別。正如我們將看到的,我們無需瞭解其內部結構就可以使用gob格式,因為encoding/gob包會在幕後為我們打理好一切底層細節[2]。
encoding/gob包也提供了與encoding/json包一樣的編碼解碼功能,並且容易使用。通常而言,如果對肉眼可讀性不做要求,gob格式是Go語言上用於文件存儲和網絡傳輸最為方便的格式。
8.1.4.1 寫Go語言二進制文件
下面有個方法用於將整個*Invoice項的數據以gob的格式寫入一個打開的文件(或者是任何滿足io.Writer接口的值)中。
type GobMarshaler struct{}
func (GobMarshaler) MarshalInvoices(writer io.Writer, invoices *Invoice) error {
encoder := gob.NewEncoder(writer)
if err := encoder.Encode(magicNumber); err != nil {
return err
}
if err := encoder.Encode(fileVersion); err != nil {
return err
}
return encoder.Encode(invoices)
}
在方法開始處,我們創建了一個包裝了io.Writer的gob編碼器,它本身是一個writer,讓我們可以寫數據。
我們使用gob.Encoder.Encode方法來寫數據。該方法能夠完美地處理我們的發票切片,其中每個發票切片包含它自身的發票項切片。該方法返回一個空或者非空的錯誤值。如果發生錯誤,則立即返回給它的調用者。
往文件寫入幻數(magic number)和文件版本並不是必需的,但正如將在練習中所看到的那樣,這樣做可以在後期更方便地改變文件格式。
需注意的是,該方法並不真正關心它編碼數據的類型,因此創建類似的函數來寫gob數據區別不大。此外,GobMarshaler.MarshalInvoices方法無需任何改變就可以寫新數據格式。
由於Invoice結構體的字段都是布爾值、數字、字符串、time.Time值以及包含布爾值、數字、字符串和time.Time值的結構體(如Item),這裡的代碼可以正常工作。
如果我們的結構體包含某些不可用gob格式編碼的字段,那麼就必須更改該結構體以便滿足gob.GobEncoder和gob.GobDecoder接口。該gob編碼器足夠智能來檢查它需要編碼的值是不是一個 gob.GobEncoder,如果是,那麼編碼器就使用該值自身的GobEncode方法而非編碼器內置的編碼方法來編碼。相同的規則也作用於解碼時,檢查該值是否定義了GobDecode方法以滿足gob.GobDecoder接口。(該invoicedata例子的源代碼gob.go文件中包含了相應的代碼,將 Invoice 定義成一個編碼器和解碼器。因為這些代碼不是必須的,因此我們將其註釋掉,只是為了演示如何做。)讓一個結構體滿足這些接口會極大地降低gob的讀寫速度,也會產生更大的文件。
8.1.4.2 讀Go語言二進制文件
讀 gob 數據和寫一樣簡單,如果我們的目標數據類型與寫時相同。GobMarshaler.UnmarshalInvoices方法接受一個 io.Reader(例如,一個打開的文件),並從中讀取gob數據。
func (GobMarshaler) UnmarshalInvoices(reader io.Reader)(*Invoice, error) {
decoder := gob.NewDecoder(reader)
var magic int
if err := decoder.Decode(&magic); err != nil {
return nil, err
}
if magic != magicNumber {
return nil, errors.New("cannot read non-invoices gob file")
}
var version int
if err := decoder.Decode(&version); err != nil {
return nil, err
}
if version > fileVersion {
return nil, fmt.Errorf("version %d is too new to read", version)
}
var invoices *Invoice
err := decoder.Decode(&invoices)
return invoices, err
}
我們有3項數據要讀:幻數、文件版本號以及所有發票數據。gob.Decoder.Decode方法接受一個指向目標值的指針,返回一個空或者非空的錯誤值。我們使用頭兩個變量(幻數和版本號)來確認我們得到的是一個gob格式的發票文件,並且該文件的版本是我們可以處理的。然後,我們讀取發票文件,在此過程中,gob.Decoder.Decode方法會根據所讀取的發票數據增加invoices切片的大小,並根據需要來將指向函數實時創建的Invoices數據(及其發票項)的指針保存在invoices切片中。最後,該方法返回invoices切片,以及一個空的錯誤值,或者如果發生問題則返回非空的錯誤值。
如果發票數據由於添加了導出字段被更改了,針對布爾值、整數、字符串、time.Time值以及包含這些類型值的結構體,該方法還能繼續工作。當然,如果數據包含其他類型,那就必須更新方法以滿足gob.GobEncoder和gob.GobDecoder接口。
處理結構體類型時,gob 格式非常靈活,能夠無縫地處理一些不同的數據結構。例如,如果一個包含某值的結構體被寫成gob格式,那麼就必然可以從gob格式中將該值讀回到此結構體,甚至也讀回到許多其他類似的結構體,比如包含指向該值指針的結構體,或者結構體中的值類型兼容也可(比如int相對於uint,或者類似的情況)。同時,正如invoicedata示例所示,gob格式可以處理嵌套的數據(但是,在本書撰寫時,它還不能處理遞歸的值)。gob的文檔中給出了它能處理的格式以及該格式的底層存儲結構,但如果我們使用相同的類型來進行讀寫,正如上例中所做的那樣,我們就不必關心這些。
8.1.5 處理自定義的二進制文件
雖然Go語言的encoding/gob包非常易用,而且使用時所需代碼量也非常少,我們仍有可能需要創建自定義的二進制格式。自定義的二進制格式有可能做到最緊湊的數據表示,並且讀寫速度可以非常快。不過,在實際使用中,我們發現以Go語言二進制格式的讀寫通常比自定義格式要快非常多,而且創建的文件也不會大很多。但如果我們必須通過滿足 gob.GobEncoder和gob.GobDecoder接口來處理一些不可被gob編碼的數據,這些優勢就有可能會失去。在有些情況下我們可能需要與一些使用自定義二進制格式的軟件交互,因此瞭解如何處理二進制文件就非常有用。
圖8-1給出了.inv自定義二進制格式如何表示一個發票文件的概要。整數值表示成固定大小的無符號整數。布爾值中的true表示成一個int8類型的值1,false表示成0。字符串表示成一個字節數(類型為int32)後跟一個它們的UTF-8編碼的字節切片byte。對於日期,我們採取稍微非常規的做法,將一個ISO-8601格式的日期(不含連字符)當成一個數字,並將其表示成int32值。例如,我們將日期2006-01-02表示成數字20 060 102。每一個發票項表示成一個發票項的總數後跟各個發票項。(回想一下,發票項ID是字符串而非整數,這與發票ID不同,參見8.1節。)
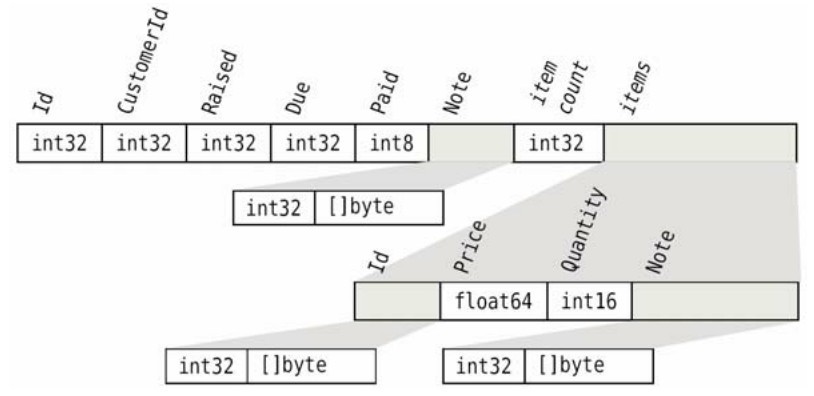
圖8-1.inv自定義二進制格式
8.1.5.1 寫自定義二進制文件
encoding/binary包中的binary.Write函數使得以二進制格式寫數據非常簡單。
type InvMarshaler struct{}
var byteOrder = binary.LittleEndian
func (InvMarshaler) MarshalInvoices(writer io.Writer, invoices *Invoice) error {
var write invWriterFunc = func(x interface{}) error {
return binary.Write(writer, byteOrder, x)
}
if err := write(uint32(magicNumber)); err != nil {
return err
}
if err := write(uint16(fileVersion)); err != nil {
return err
}
if err := write(int32(len(invoices))); err != nil {
return err
}
for _, invoice := range invoices {
if err := write.writeInvoice(invoice); err != nil {
return err
}
}
return nil
}
該方法將所有發票項寫入給定的io.Writer 中。它開始時創建了一個便捷的write函數,該函數能夠捕獲我們要使用的io.Writer和字節序。正如處理.txt格式所做的那樣,我們將write函數定義為一個特定的類型(invWriterFunc),並且為該write函數創建了一些方法(例如invWriterFunc.WriteInvoices),以便後續使用。
需注意的是,讀和寫二進制數據時其字節序必須一致。(我們不能將byteOrder定義為一個常量,因為binary.LittleEndian或者binary.BigEndian不是像字符串或者整數這樣的簡單值。)
這裡,寫數據的方式與我們之前在看到寫其他格式數據的方式類似。一個非常重要的不同在於,將幻數和文件版本寫入後,我們寫入了一個表示發票數量的數字。(也可以跳過而不寫該數字,而只是簡單地將發票寫入。然後,讀數據的時候,持續地依次讀入發票直到遇到io.EOF。)
type invWriterFunc func(interface{}) error
func (write invWriterFunc) writeInvoice(invoice *Invoice) error {
for _, i := range int{invoice.Id, invoice.CustomerId} {
if err := write(int32(i)); err != nil {
return err
}
}
for _, date := range time.Time{invoice.Raised, invoice.Due} {
if err := write.writeDate(date); err != nil {
return err
}
}
if err := write.writeBool(invoice.Paid); err != nil {
return err
}
if err := write.writeString(invoice.Note); err != nil {
return err
}
if err := write(int32(len(invoice.Items))); err != nil {
return err
}
for _, item := range invoice.Items {
if err := write.writeItem(item); err != nil {
return err
}
}
return nil
}
對於每一個發票數據,writeInvoice方法都會被調用一遍。它接受一個指向被寫發票數據的指針,並使用作為接收器的write函數來寫數據。
該方法開始處以int32寫入了發票ID及客戶ID。當然,以純int型寫入數據是合法的,但底層機器以及所使用的Go語言版本的改變都可能導致int的大小改變,因此寫入時非常重要的一點是確定整型的符號和大小,如 uintf32和int32 等。接下來,我們使用自定義的writeDate方法寫入創建和過期時間,然後寫入表示是否支付的布爾值和註釋字符串。最後,我們寫入了一個代表發票中有多少發票項的數字,隨後再使用writeItem方法寫入發票項。
const invDateFormat = "20060102" // 必須總是使用該日期值
func (write invWriterFunc) writeDate(date time.Time) error {
i, err := strconv.Atoi(date.Format(invDateFormat))
if err != nil {
return err
}
return write(int32(i))
}
前文中我們討論了time.Time.Format函數以及為何必須在格式字符串中使用特定的日期2006-01-02。這裡,我們使用了類ISO-8601格式,並去除連字符以便得到一個八個數字的字符串,其中如果月份和天數為單一數字則在其前面加上 0。然後,將該字符串轉換成數字。例如,如果日期是 2012-08-05,則將其轉換成一個等價的數字,即 20120805,然後以 int32的形式將該數字寫入。
值得一提的是,如果我們想存儲日期/時間值而非僅僅是日期值,或者只想得到一個更快的計算,我們可以將對該方法的調用替換成調用write(int64(date.Unix)),以存儲一個Unix新紀元以來的秒數。相應的讀取數據的方法則類似於var d int64;if err:=binary.Read(reader, byteOrder, &d); err != nil { return err }; date := time.Unix(d, 0)。
func (write invWriterFunc) writeBool(b bool) error {
var v int8
if b {
v = 1
}
return write(v)
}
本書撰寫時,encoding/binary包還不支持讀寫布爾值,因此我們創建了該簡單方法來處理它們。順便提一下,我們不必使用類型轉換(如int8(v)),因為變量v已經是一個有符號並且固定大小的類型了。
func (write invWriterFunc) writeString(s string) error {
if err := write(int32(len(s))); err != nil {
return err
}
return write(byte(s))
}
字符串必須以它們底層的UTF-8編碼字節的形式來寫入。這裡,我們首先寫入了所需寫入的字節總數,然後再寫入所有字節。(如果數據是固定寬度的,就不需要寫入字節數。當然,前提是,讀取數據時,我們創建了一個存儲與寫入的數據大小相同的空切片byte。)
func (write invWriterFunc) writeItem(item *Item) error {
if err := write.writeString(item.Id); err != nil {
return err
}
if err := write(item.Price); err != nil {
return err
}
if err := write(int16(item.Quantity)); err != nil {
return err
}
return write.writeString(item.Note)
}
該方法用於寫入一個發票項。對於字符串 ID和註釋文本,我們使用 invWriterFunc.writeString方法,對於物品數量,我們使用無符號的大小固定的整數。但是對於價格,我們就以它原始的形式寫入,因為它本來就是個固定大小的類型(float64)。
往文件中寫入二進制數據並不難,只要我們小心地將可變長度數據的大小在數據本身前面寫入,以便讀數據時知道該讀多少。當然,使用gob格式非常方便,但是使用一個自定義的二進制格式所產生的文件更小。
8.1.5.2 讀自定義二進制文件
讀取自定義的二進制數據與寫自定義二進制數據一樣簡單。我們無需解析這類數據,只需使用與寫數據時相同的字節順序將數據讀進相同類型的值中。
func (InvMarshaler) UnmarshalInvoices(reader io.Reader) (*Invoice, error){
if err := checkInvVersion(reader); err != nil {
return nil, err
}
count, err := readIntFromInt32(reader)
if err != nil {
return nil, err
}
invoices := make(*Invoice, 0, count)
for i := 0; i < count; i++ {
invoice, err := readInvInvoice(reader)
if err != nil {
return nil, err
}
invoices = append(invoices, invoice)
}
return invoices, nil
}
該方法首先檢查所給定版本的發票文件能否被處理,然後使用自定義的readIntFromInt32函數從文件中讀取所需處理的發票數量。我們將 invoices 切片的長度設為 0(即當前還沒有發票),但其容量正好是我們所需要的。然後,輪流讀取每一個發票並將其存儲在invoices切片中。
另一種可選的方法是使用make(*Invoice, count)代替make,使用invoices[i]= invoice 代替 append。不管怎樣,我們傾向於使用所需的容量來創建切片,因為與實時增長切片相比,這樣做更有潛在的性能優勢。畢竟,如果我們再往一個其長度與容量相等的切片中追加數據,切片會在背後創建一個新的容量更大的切片,並將起原始切片數據複製至新切片中。然而,如果其容量一開始就足夠,後面就沒必要進行複製。
func checkInvVersion(reader io.Reader) error {
var magic uint32
if err := binary.Read(reader, byteOrder, &magic); err != nil {
return err
}
if magic != magicNumber {
return errors.New("cannot read non-invoices inv file")
}
var version uint16
if err := binary.Read(reader, byteOrder, &version); err != nil {
return err
}
if version > fileVerson {
return fmt.Errorf("version %d is too new to read", version)
}
return nil
}
該函數試圖從文件中讀取其幻數及版本號。如果該文件格式可接受,則返回nil;否則返回非空錯誤值。
其中的binary.Read函數與 binary.Write函數相對應,它接受一個從中讀取數據的io.Reader、一個字節序以及一個指向特定類型的用於保存所讀數據的指針。
func readIntFromInt32(reader io.Reader) (int, error) {
var i32 int32
err := binary.Read(reader, byteOrder, &i32)
return int(i32), err
}
該輔助函數用於從二進制文件中讀取一個int32值,並以int類型返回。
func readInvInvoice(reader io.Reader) (invoice *Invoice, err error) {
invoice = &Invoice{}
for _, pId := range *int{&invoice.Id, &invoice.CustomerId} {
if *pId, err = readIntFromInt32(reader); err != nil {
return nil, err
}
}
for _, pDate := range *time.Time{&invoice.Raised, &invoice.Due} {
if *pDate, err = readInvDate(reader); err != nil {
return nil, err
}
}
if invoice.Paid, err = readBoolFromInt8(reader); err != nil {
return nil, err
}
if invoice.Note, err = readInvString(reader); err != nil {
return nil, err
}
var count int
if count, err = readIntFromInt32(reader); err != nil {
return nil, err
}
invoice.Items, err = readInvItems(reader, count)
return invoice, err
}
每次讀取發票文件的時候,該函數都會被調用。函數開始處創建了一個初始化為零值的Invoice值,並將指向它的指針保存在invoice變量中。
發票ID和客戶ID使用自定義的readIntFromInt32函數讀取。這段代碼的微妙之處在於,我們迭代那些指向發票ID和客戶ID的指針,並將返回的整數賦值給指針(pId)所指的值。
一個可選的方案是單獨處理每一個 ID。例如,if invoice.Id, err =readIntFromInt32(reader); err != nil { return err}等。
讀取創建及過期日期的流程與讀取 ID的流程完全一樣,只是這次我們使用的是自定義的readInvDate函數。
正如讀取ID一樣,我們也可以以更加簡單的方式單獨處理日期。例如,if invoice.Due, err = readInvDate(reader); err != nil { return err}等。
稍後將看到,我們使用一些輔助函數讀取是否支付的標誌和註釋文本。發票數據讀完之後,我們再讀取有多少個發票項,然後調用 readInvItems函數讀取全部發票項,傳遞給該函數一個用於讀取的io.Reader值和一個表示需要讀多少項的數字。
func readInvDate(reader io.Reader) (time.Time, error) {
var n int32
if err := binary.Read(reader, byteOrder, &n); err != nil {
return time.Time{}, err
}
return time.Parse(invDateFormat, fmt.Sprint(n))
}
該函數用於讀取表示日期的int32值(如20130501),並將該數字解析成字符串表示的日期值,然後返回對應的time.Time值(如2013-05-01)。
func readBoolFromInt8(reader io.Reader) (bool, error) {
var i8 int8
err := binary.Read(reader, byteOrder, &i8)
return i8 == 1, err
}
該簡單的輔助函數讀取一個int8數字,如果該數字為1則返回true,否則返回false。
func readInvString(reader io.Reader) (string, error) {
var length int32
if err := binary.Read(reader, byteOrder, &length); err != nil {
return "", nil
}
raw := make(byte, length)
if err := binary.Read(reader, byteOrder, &raw); err != nil {
return "", err
}
return string(raw), nil
}
該函數讀取一個byte 切片,但它的原理適用於任何類型的切片,只要寫入切片之前寫明了切片中包含多少項元素。
函數首先將切片項的個數讀到一個length變量中。然後創建一個長度與此相同的切片。給binary.Read函數傳入一個指向切片的指針之後,它就會往該切片中盡可能地讀入該類型的項(如果失敗則返回一個非空的錯誤值)。需注意的是,這裡重要的是切片的長度,而非其容量(其容量可能等於或者大於長度)。
在本例中,該byte切片保存了UTF-8編碼的字節,我們將其轉換成字符串後將其返回。
func readInvItems(reader io.Reader, count int) (*Item, error) {
items := make(*Item, 0, count)
for i := 0; i < count; i++ {
item, err := readInvItem(reader)
if err != nil {
return nil, err
}
items = append(items, item)
}
return items, nil
}
該函數讀入發票的所有發票項。由於傳入了一個計數值,因此它知道應該讀入多少項。
func readInvItem(reader io.Reader) (item *Item, err error) {
item = &Item{}
if item.Id, err = readInvString(reader); err != nil {
return nil, err
}
if err = binary.Read(reader, byteOrder, &item.Price); err != nil {
return nil, err
}
if item.Quantity, err = readIntFromInt16(reader); err != nil {
return nil, err
}
item.Note, err = readInvString(reader)
return item, nil
}
該函數讀取單個發票項。從結構上看,它與 readInvInvoice函數類似,首先創建一個初始化為零值的Item值,並將指向它的指針存儲在變量item中,然後填充該item變量的字段。價格可以直接讀入,因為它是以float64類型寫入文件的,是一個固定大小的類型。Item.Price 字段的類型也一樣。(我們省略了 readIntFromInt16函數,因為它與我們前文所描述的readIntFromInt32函數基本相同。)
至此,我們完成了對自定義二進制數據的讀和寫。只要小心選擇表示長度的整數符號和大小,並將該長度值寫在變長值(如切片)的內容之前,那麼使用二進制數據進行工作並不難。
Go語言對二進制文件的支持還包括隨機訪問。這種情況下,我們必須使用os.OpenFile函數來打開文件(而非os.Open),並給它傳入合理的權限標誌和模式(例如,os.O_RDWR表示可讀寫)參數[3]。然後,就可以使用os.File.Seek方法來在文件中定位並讀寫,或者使用os.File.ReadAt和os.File.WriteAt方法來從特定的字節偏移中讀取或者寫入數據。Go語言還提供了其他常用的方法,包括os.File.Stat方法,它返回的os.FileInfo包含了文件大小、權限以及日期時間等細節信息。
8.2 歸檔文件
Go語言的標準庫提供了對幾種壓縮格式的支持,其中包括gzip,因此Go程序可以無縫地讀寫.gz 擴展名的gzip 壓縮文件或非.gz 擴展名的非壓縮文件。此外,標準庫也提供了讀和寫.zip文件、tar包文件(.tar和.tar.gz),以及讀.bz2文件(即.tar.bz2文件)的功能。
本節中我們會看一些從兩個程序中抽出的代碼。第一個是pack程序(在文件pack/pack.go中),它從命令行接受一個歸檔文件的文件名和需打包的文件列表。它通過檢測歸檔文件的擴展名來判斷該使用何種打包格式。第二個是unpack 程序(在文件unpack/unpack.go 中),也從命令行接受一個歸檔文件的文件名,並從中提取所有打包的文件,如有必要則在提取過程中重建目錄結構。
8.2.1 創建zip歸檔文件
要使用 zip 包來壓縮文件,我們首先必須打開一個用於寫的文件,然後創建一個*zip.Writer值來往其中寫入數據。然後,對於每一個我們希望加入.zip歸檔文件的文件,我們必須讀取該文件並將其內容寫入 *zip.Writer中。該pack程序使用了createZip和writeFileToZip兩個函數以這種方式來創建一個.zip文件。
func createZip(filename string, files string) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close
zipper := zip.NewWriter(file)
defer zipper.Close
for _, name := range files {
if err := writeFileToZip(zipper, name); err != nil {
return err
}
}
return nil
}
該 createZip函數和writeFileToZip函數都比較簡短,因此容易讓人覺得應該寫入一個函數中。這是不明智的,因為在該 for 循環中我們可能打開一個又一個的文件(即files 切片中的所有文件),從而可能超出操作系統允許的文件打開數上限。這點我們在前面章節中已有簡短的闡述。當然,我們可以在每次迭代中調用os.File.Close,而非延遲執行它,但這樣做還必須保證程序無論是否出錯文件都必須關閉。因此,最為簡便而乾淨的解決方案是,像這裡所做的那樣,總是創建一個獨立的函數來處理每個獨立的文件。
func writeFileToZip(zipper *zip.Writer, filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close
info, err := file.Stat
if err != nil {
return err
}
header, err := zip.FileInfoHeader(info)
if err != nil {
return err
}
header.name = sanitizedName(filename)
writer, err := zipper.CreateHeader(header)
if err != nil {
return err
}
_, err = io.Copy(writer, file)
return err
}
首先我們打開需要歸檔的文件以供讀取,然後延遲關閉它。這是我們處理文件的老套路了。
接下來,我們調用os.File.Stat方法來取得包含時間戳和權限標誌的os.FileInfo值。然後,我們將該值傳給 zip.FileInfoHeader函數,該函數返回一個zip.FileHeader 值,其中保存了時間戳、權限以及文件名。在壓縮文件中,我們無需使用與原始文件名一樣的文件名,因此這裡我們使用淨化過的文件名來覆蓋原始文件名(保存在zip.FileHeader.Name字段中)。
頭部設置好之後,我們將其作為參數調用zip.CreateHeader函數。這會在.zip壓縮文件中創建一個項,其中包含頭部的時間戳、權限以及文件名,並返回一個 io.Writer,我們可以往其中寫入需要被壓縮的文件的內容。為此,我們使用了 io.Copy函數,它能夠返回所複製的字節數(我們已將其丟棄),以及一個為空或者非空的錯誤值。
如果在任何時候發生錯誤,該函數就會立即返回並由調用者處理錯誤。如果最終沒有錯誤發生,那麼該.zip壓縮文件就會包含該給定文件。
func sanitizedName(filename string) string{
if len(filename) > 1 && filename[1] == ':' &&
runtime.GOOS == "windows" {
filename = filename[2:]
}
filename = filepath.ToSlash(filename)
filename = strings.TrimLeft(filename, "/.")
return strings.Replace(filename, "../", "", -1)
}
如果一個歸檔文件中包含的文件帶有絕對路徑或者含有「..」路徑組件,我們就有可能在解開歸檔的時候意外覆蓋本地重要文件。為了降低這種風險,我們對保存在歸檔文件裡每個文件的文件名都做了相應的淨化。
該 sanitizedName函數會刪除路徑頭部的盤符以及冒號(如果有的話),然後刪除頭部任何目錄分隔符、點號以及任何「..」路徑組件,並將文件分隔符強制轉換成正向斜線。
8.2.2 創建可壓縮的tar包
創建tar歸檔文件與創建.zip歸檔文件非常類似,主要不同點在於我們將所有數據都寫入相同的writer 中,並且在寫入文件的數據之前必須寫入完整的頭部,而非僅僅是一個文件名。我們在該pack程序的實現中使用了createTar和writeFileToTar函數。
func createTar(filename string, files string) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close
var fileWriter io.WriterCloser = file
if strings.HasSuffix(filename, ".gz") {
fileWriter = gzip.NewWriter(file)
defer fileWriter.Close
}
writer := tar.NewWriter(fileWriter)
defer writer.Close
for _, name := range files {
if err := writeFileToTar(writer, name); err != nil {
return err
}
}
return nil
}
該函數創建了包文件,而且如果擴展名顯示該 tar 包需要被壓縮則添加一個 gzip 過濾。gzip.NewWriter函數返回一個*gzip.Writer值,它滿足io.WriteCloser接口(正如打開的*os.File一樣)。
一旦文件準備好寫入,我們創建一個*tar.Writer 往其中寫入數據。然後迭代所有文件並將每一個寫入歸檔文件。
func writeFileToTar(writer *tar.Writer, filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close
stat, err := file.Stat
if err != nil {
return err
}
header := &tar.Header{
Name: sanitizedName(filename),
Mode: int64(stat.Mode),
Uid: os.Getuid,
Gid: os.Getuid,
Size: stat.Size,
ModTime: stat.ModTime,
}
if err = writer.WriteHeader(header); err != nil {
return err
}
_, err = io.Copy(writer, file)
return err
}
函數首先打開需要處理的文件並設置延遲關閉。然後調用Stat方法取得文件的模式、大小以及修改日期/時間。這些信息用於填充*tar.Header,每個文件都必須創建一個tar.Header結構並寫入到tar歸檔文件裡,(此外,我們設置了頭部的用戶以及組ID,這會在類Unix系統中用到。)我們必須至少設置頭部的文件名(其Name字段)以及表示文件大小的Size字段,否則這個.tar包就是非法的。
當*tar.Header結構體創建好後,我們將它寫入歸檔文件,再接著寫入文件的內容。
8.2.3 解開zip歸檔文件
解開一個.zip歸檔文件與創建一個歸檔文件一樣簡單,只是如果歸檔文件中包含帶有路徑的文件名,就必須重建目錄結構。
func unpackZip(filename string) error {
reader, err := zip.OpenReader(filename)
if err != nil {
return err
}
defer reader.Close
for _, zipFile := range reader.Reader.File {
name := sanitizedName(zipFile.Name)
mode := zipFile.Mode
if mode.IsDir {
if err = os.MkdirAll(name, 0755); err != nil {
return err
}
} else {
if err = unpackZippedFile(name, zipFile); err != nil {
return err
}
}
}
return nil
}
該函數打開給定的.zip文件用於讀取。這裡沒有使用os.Open函數來打開文件後調用zip.NewReader,而是使用zip包提供的zip.OpenReader函數,它可以方便地打開並返回一個*zip.ReadCloser 值讓我們使用。zip.ReadCloser 最為重要的一點是它包含了導出的zip.Reader 結構體字段,其中包含一個包含指向 zip.File 結構體指針的*zip.File切片,其中的每一項表示.zip壓縮文件中的一個文件。
我們迭代訪問該reader的zip.File結構體,並創建一個淨化過的文件及目錄名(使用我們在pack程序中用到的sanitizedName函數),以降低覆蓋重要文件的風險。
如果遇到一個目錄(由*zip.File的os.FileMode的IsDir方法報告),我們就創建一個目錄。os.MkdirAll函數傳入了有用的屬性信息,會自動創建必要的中間目錄以創建特定的目標目錄,如果目錄已經存在則會安全地返回 nil 而不執行任何操作。[4]如果遇到的是一個文件,則交由自定義的unpackZippedFile函數進行解壓。
func unpackZippedFile(filename string, zipFile *zipFile) error {
writer, err := os.Create(filename)
if err != nil {
return err
}
defer writer.Close
reader, err := zipFile.Open
if err != nil {
return err
}
defer reader.Close
if _, err = io.Copy(writer, reader); err != nil {
return err
}
if filename == zipFile.Name {
fm.Println(filename)
} else {
fmt.Printf("%s [%s]\n", filename, zipFile.Name)
}
return nil
}
unpackZippedFile函數的作用就是將.zip 歸檔文件裡的單個文件抽取出來,寫到filename指定的文件裡去。首先它創建所需要的文件,然後,使用zip.File.Open函數打開指定的歸檔文件,並將數據複製到新創建的文件裡去。
最後,如果沒有錯誤發生,該函數會往終端打印所創建文件的文件名,如果處理後的文件名與原始文件名不一樣,則將原始文件名包含在方括號中。
值得注意的是,該*zip.File類型也有一些其他的方法,如zip.File.Mode(在前面的unpackZip函數中已有使用),zip.File.ModTime(以time.Time值返回文件的修改時間)以及返回文件的os.FileInfo值的zip.FileInfo。
8.2.4 解開tar歸檔文件
解開tar歸檔文件比創建tar歸檔文檔稍微簡單些。然而,跟解開.zip文件一樣,如果歸檔文件中的某些文件名包含路徑,必須重建目錄結構。
func unpackTar(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close
var fileReader io.ReadCloser = file
if strings.HasSuffix(filename, ".gz") {
if fileReader, err = gzip.NewReader(file); err != nil {
return err
}
defer fileReader.Close
}
reader := tar.NewReader(fileReader)
return unpackTarFiles(reader)
}
該方法首先按照Go語言的常規方式打開歸檔文件,並延遲關閉它。如果該文件使用了gzip壓縮則創建一個 gzip 解壓縮過濾器並延遲關閉它。gzip.NewReader函數返回一個*gzip.Reader 值,正如打開一個常規文件(類型為*os.File)一樣,它也滿足io.ReadCloser接口。
設置好了文件reader之後,我們創建一個*tar.Reader來從中讀取數據,並將接下來的工作交給一個輔助函數。