
本章的目的是講解在Go語言中如何進行面向對像編程。來自於其他過程式編程背景的程序員可能會發現,本章的所有內容都建立在他們所學以及本書前面章節的基礎之上。但是來自於其他基於繼承到面向對像編程背景(如C++、Java和Python)的程序員可能需要將許多曾經常用的概念和習慣放在一邊,特別是繼承相關的,因為Go語言的面向對像編程方式與它們的完全不同。
Go語言的標準庫大部分情況下提供的都是函數包,但也適當地提供了包含方法的自定義類型。在前面的章節中,我們創建了一些自定義類型(如regexp.Regexp和os.File)的值,並也調用了它們的方法。此外,我們甚至創建了一些簡單的自定義類型,以及相應的方法。例如,支持打印和排序。因此,我們已經熟悉了Go語言類型的基本使用以及類型方法的調用。
本章第一節用非常簡短的篇幅描述了一些 Go語言面向對像編程中的關鍵概念。第二節包含了創建無方法的自定義類型的內容。接下來我們往自定義類型中添加了方法,創建了構造函數,以及驗證字段數據,總之,講解了創建一個獨立的自定義類型所需的所有基礎內容。第三節講解了接口,這是 Go語言實現類型安全的鴨子類型的基礎。第四節講解了結構體,介紹了許多前面章節中未曾涉及的細節。
本章的最後一節給出了3個關於自定義類型的完整示例,它們覆蓋了本章前面各節中的大部分內容以及本書中前面章節中的相當一部分內容。其中,第一個例子是一個簡單的只包含單值數據類型的自定義類型,第二個例子是一小部數據類型的集合,第三個例子是一個通用集合類型。
6.1 幾個關鍵概念
Go語言的面向對像之所以與C++、Java以及(較小程度上的)Python這些語言如此不同,是因為它不支持繼承。面向對像編程剛流行的時候,繼承是它首先被捧吹的最大優點之一。但是歷經幾十載的實踐之後,事實證明該特性也有些明顯的缺點,特別是當用於維護大系統時。與其他大部分同時使用聚合和繼承的面向對像語言不同的是,Go語言只支持聚合(也叫做組合)和嵌入。為了弄明白聚合與嵌入的區別,讓我們看一小段代碼。
type ColoredPoint struct{
color.Color // 匿名字段(嵌入)
x, y int// 具名字段(聚合)
}
這裡,color.Color是來自image/color包的類型,x和y則是整型。在Go語言的術語中,color.Color、x和y,都是ColoredPoint結構體的字段。color.Color字段是匿名的(因為它沒有變量名),因此是嵌入字段。x和y字段是具名的聚合字段。如果我們創建一個 ColoredPoint 值(例如,point := ColoredPoint{}),其字段可以通過point.Color、point.x和point.y 來訪問。需注意的是,當訪問來自於其他包中的類型的字段時,我們只用到了其名字的最後一部分,即Color而非color.Color(我們會在6.2.1.1節、6.3節及6.4節詳細討論這些內容)。
術語「類」(class)、「對像」(object)以及「實例」(instance)在傳統的多層次繼承式面向對像編程中已經定義的非常清晰,但在Go語言中我們完全避開使用它們。相反,我們使用「類型」和「值」,其中自定義類型的值可以包含方法。
由於沒有繼承,因此也就沒有虛函數。Go語言對此的支持則是採用類型安全的鴨子類型(duck type)。在 Go語言中,參數可以被聲明為一個具體類型(例如,int、string、或者*os.File以及MyType),也可以是接口(interface),即提供了具有滿足該接口的方法的值。對於一個聲明為接口的參數,我們可以傳入任意值,只要該值包含該接口所聲明的方法。例如,如果我們有一個值提供了一個Write(byte)(int, error)方法,我們就可以將該值當做一個io.Writer(即作為一個滿足io.Writer接口的值)提供給任何一個需要io.Writer參數的函數,無論該值的實際類型是什麼。這點非常靈活而強大,特別是當它與 Go語言所支持的訪問嵌入字段的方法相結合時。
繼承的一個優點是,有些方法只需在基類中實現一次,即可在子類中方便地使用。Go語言為此提供了兩種解決方案。其中一種解決方案是使用嵌入。如果我們嵌入了一個類型,方法只需在所嵌入的類型中實現一次,即可在所有包含該嵌入類型的類型中使用[1]。另一種解決方案是,為每一種類型提供獨立的方法,但是只是簡單地將包裝(通常都只有一行)了功能性作用的代碼放進一個函數中,然後讓所有類的方法都調用這個函數。
Go語言面向對像編程中的另一個與眾不同點是它的接口、值和方法都相互保持獨立。接口用於聲明方法簽名,結構體用於聲明聚合或者嵌入的值,而方法用於聲明在自定義類型(通常為結構體)上的操作。在一個自定義類型的方法和任何特殊接口之間沒有顯式的聯繫。但是如果該類型的方法滿足一個或者多個接口,那麼該類型的值可以用於任何接受該接口的值的地方。當然,每一個類型都滿足空接口(interface{}),因此任何值都可以用於聲明了空接口的地方。
一種按Go語言的方式思考的方法是,把is-a關係看成由接口來定義,也就是方法的簽名。因此,一個滿足 io.Reader 接口(即有一個簽名為 Read(byte)(int, error)的方法)的值就叫做 Reader,這並不是因為它是什麼(一個文件、一個緩衝區或者一些其他自定義類型),而是因為它提供了什麼方法,在這裡是Read方法。如圖6-1中的解釋。而has-a關係可以使用聚合或者嵌入特定類型值的結構體來表達,這些類型構成自定義類型。

圖6-1 用於讀寫字節切片的接口和類型
雖然沒法為內置類型添加方法,但可以很容易地基於內置類型創建自定義的類型,然後為其添加任何我們想要的方法。該類型的值可以調用我們提供的方法,同時也可以與它們底層類型提供的任何函數、方法以及操作符一起使用。例如,假設我們有個類型聲明為type Integer int,我們可以不拘形式地使用整型的+操作符將這兩種類型的值相加。並且,一旦我們有了一個自定義類型,我們也可以添加自定義的方法。例如,func (i Integer) Double Integer{ return i * 2 },稍後將會看到(參見6.2.1節)。
基於內置類型的自定義類型不但容易創建,運行時效率也非常高。將基於內置類型的自定義類型與該內置類型相互轉換無需耗費運行時代價,因為這種轉換能夠在編譯時高效完成。鑒於此,要使用自定義類型的方法時將內置類型「升級」成自定義類型,或者要將一個類型傳入給一個只接收內置類型參數的函數時將自定義類型「降級」成內置類型,都是非常實用的做法。我們在前文中曾看過一個「升級」的例子,在那裡我們將一個string類型轉換成一個FoldedStrings類型(參見4.2.4節)的值,在本章末尾我們講解到Count類型的時候我們會舉一個「降級」的例子。
6.2 自定義類型
自定義類型使用Go語言的如下語法創建:
type typeName typeSpecification
typeName可以是一個包或者函數內唯一的任何合法的Go標識符。typeSpecification可以是任何內置的類型(如string、int、切片、映射或者通道)、一個接口(參見6.3節)、一個結構體(參見前面章節,本書後面將介紹更多相關內容,參見6.4節)或者一個函數簽名。
在有些情況下創建一個自定義類型就足夠了,但有些情況下我們需要給自定義類型添加一些方法來讓它更實用。下面是一些沒有方法的自定義類型例子。
type Count int
type StringMap map[string]string
type FloatChan chan float64
這些自定義類型就其自身而言,雖然使用這樣的類型可以提升程序的可讀性,同時也可以在後面改變其底層類型,但是沒一個看起來有用,因此只把它們當做基本的抽像機制。
var i Count = 7
i++
fmt.Println(i)
sm := make(StringMap)
sm[〞key1〞] = 〞value1〞
sm[〞key2〞] = 〞value2〞
fmt.Println(sm)
fc := make(FloatChan, 1)
fc <- 2.29558714939
fmt.Println(<-fc)
8
map[key2:value2 key1:value1]
2.29558714939
像Count、StringMap和FloatChan這樣的類型,它們是直接基於內置類型創建的,因此可以拿來當做內置類型一樣使用。例如,我們可以使用內置的append函數來操作type StringSlice string類型。但是如果要將其傳遞給一個接受其底層類型的函數,就必須先將其轉換成底層類型(無需成本,因為這是在編譯時完成的)。有時,我們可能需要進行相反的操作,將一個內置類型的值升級成一個自定義類型的值,以使用其自定義類型的方法。我們已經見過一個這樣的例子,在 SortFoldedStrings函數中將一個string 轉換成一個FoldedStrings值(參見4.2.4節)。
type RuneForRuneFunc func(rune) rune
當使用高階函數(參見 5.6.7 節)時,通過自定義類型來聲明我們要傳入的函數的簽名更為方便。這裡我們聲明了一個接收和返回rune值的函數簽名。
var removePunctuation RuneForRuneFunc
上面創建的removePunctuation變量引用一個RuneForRuneFunc類型的函數(即其簽名為func(rune) rune)。與所有Go變量一樣,它也被自動初始化為零值,因此在這裡它被初始化成nil值。
phrases := string{〞Day; dusk, and night.〞, 〞All day long〞}
removePunctuation = func(char rune) rune {
if unicode.Is(unicode.Terminal_punctuation, char){
return -1
}
return char
}
processPhrases(phrases, removePunctuation)
這裡我們創建了一個匹配 RuneForRuneFunc 簽名的匿名函數,並將其傳給自定義的processPhrases函數。
func processPhrases(phrases string, function RuneForRuneFunc) {
for _, phrase := range phrases {
fmt.Println(strings.Map(function, phrase))
}
}
Day dust and night
All day long
對讀者來說,將RuneForRuneFunc當成一個類型而非底層的func(rune) rune更為有意義,同時它也提供了一些抽像。(strings.Map函數已在第3章中講解過。)
基於內置類型或者函數簽名創建自定義的類型非常有用,但對我們來說還遠遠不夠。我們需要的是自定義的方法,即下一節的內容。
6.2.1 添加方法
方法是作用在自定義類型的值上的一類特殊函數,通常自定義類型的值會被傳遞給該函數。該值可以以指針或者值的形式傳遞,這取決於方法如何定義。定義方法的語法幾乎等同於定義函數,除了需要在 func 關鍵字和方法名之間必須寫上接收者(寫入括號中)之外,該接收者既可以以該方法所屬於的類型的形式出現,也可以以一個變量名及類型的形式出現。當調用方法的時候,其接收者變量被自動設為該方法調用所對應的值或者指針。
我們可以為任何自定義類型添加一個或者多個方法。一個方法的接收者總是一個該類型的值,或者只是該類型值的指針。然而,對於任何一個給定的類型,每個方法名必須唯一。唯一名字要求的結果是,我們不能同時定義兩個相同名字的方法,讓其中一個的接收者為指針類型而另一個為值類型。另一個結果是,不支持重載方法,也就是說,不能定義名字相同但是不同簽名的方法。一種提供等價方法的方式是使用可變參數(也就是說,接受可變數目參數,參見本書的第5.6節)。不過,Go語言推薦的方式是使用名字唯一的函數。例如,strings.Reader類型提供 3 個不同的方法:strings.Reader.Read、strings.Reader.ReadByte和strings.Reader.ReadRune。
type Count int
func (count *Count) Increment { *count++ }
func (count *Count) Decrement { *count-- }
func (count Count) IsZero bool { return count == 0 }
這個簡單的基於整型的自定義類型支持3個方法,其中前兩個聲明為接受一個指針類型的接收者(receiver,也就是方法施加的目標對像),因為這兩個函數都修改了它們的值[2]。
var count Count
i := int(count)
count.Increment
j := int(count)
count.Decrement
k := int(count)
fmt.Println(count, i, j, k, count.IsZero)
0 0 1 0 true
上面的代碼片段展示了 Count 類型的實際使用。它看起來沒什麼,但我們會將其用於本章的第4節。
讓我們再稍微多看一個更詳細的自定義類型,這回是基於一個結構體定義的(我們會在6.3節中回來再看這個例子)。
type Part struct {
Id int // 具名字段(聚合)
Name string // 具名字段(聚合)
}
func (part *Part) LowerCase {
part.Name = strings.ToLower(part.Name)
}
func (part *Part) UpperCase {
part.Name = strings.ToUpper(part.Name)
}
func (part Part) String string {
return fmt.Sprintf(〞<<%d %q>>〞, part.Id, part.Name)
}
func (part Part) HasPrefix(prefix string) bool {
return strings.HasPrefix(part.Name, prefix)
}
為了演示它是如何工作的,我們創建了接收者為值類型的String和HasPrefix方法。當然,傳值的話無法修改原始數據,而傳遞指針的話可以。
part := Part{5, 〞wrench〞}
part.UpperCase
part.Id += 11
fmt.Println(part, part.HasPrefix(〞w〞))
«16 〞WRENCH〞»false
當創建的自定義類型是基於結構體時,我們可以使用其名字及一對大括號包圍的初始值來創建該類型的值。(我們在下一節將看到,Go語言提供了一種語法,讓我們只提供想要的值,而讓Go自己去初始化剩餘的值。)
一旦創建了part值,我們可以在其上調用方法(如Part.UpperCase),訪問它導出的(公開的)字段(如Part.Id),以及安全地打印它,因為如果自定義的類型中定義了String方法,Go語言的打印函數足夠智能會自動調用該方法進行打印。
類型的方法集是指可以被該類型的值調用的所有方法的集合。
一個指向自定義類型的值的指針,它的方法集由為該類型定義的所有方法組成,無論這些方法接受的是一個值還是一個指針。如果在指針上調用一個接受值的方法,Go語言會聰明地將該指針解引用,並將指針所指的底層值作為方法的接收者。
一個自定義類型值的方法集則由為該類型定義的接收者類型為值類型的方法組成,但是不包括那些接收者類型為指針的方法。但這種限制通常並不像這裡所說的那樣,因為如果我們只有一個值,仍然可以調用一個接收者為指針類型的方法,這可以借助於 Go語言傳值的地址的能力實現,前提是該值是可尋址的(即它是一個變量、一個解引用指針、一個數組或切片項,或者結構體中的一個可尋址字段)。因此,假設我們這樣調用value.Method,其中Method需要一個指針接收者,而 value 是一個可尋址的值,Go語言會把這個調用等同於(&value).Mehtod。
*Count類型的方法集包含3個方法:Increment、Decrement和IsZero。然而Count類型的方法集則只有一個方法:IsZero。所有這些方法都可以在*Count上調用。同時,正如我們在前面的代碼片段中所看到的,只要Count值是可尋址的,這些函數也可以在Count值上調用。*Part類型的方法集包含4個方法:LowerCase、UpperCase、String和HasPrefix,而 Part 類型的方法集則只包含 String和HasPrefix方法。然而,LowerCase和UpperCase函數也可以作用於可尋址的Part值,正如我們在上面代碼片段中所看到的。
將方法的接收者定義為值類型對於小數據類型來說是可行的,如數值類型。這些方法不能修改它們所調用的值,因為只能得到接收者的一份副本。如果我們的數據類型的值很大,或者需要修改該值,則需要讓方法接受一個指針類型的接收者。這樣可以使得方法調用的開銷盡可能的小(因為接收者是以32位或者64位的形式傳遞,無論調用該方法的值多大)。
6.2.1.1 重寫方法
本章末尾我們將看到,可以創建包含一個或者多個類型作為嵌入字段的自定義結構體(參見6.4節)。這種方法非常方便的一點是,任何嵌入類型中的方法都可以當做該自定義結構體自身的方法被調用,並且可以將其內置類型作為其接收者。
type Item struct {
id string // 具名字段(聚合)
price float64 // 具名字段(聚合)
quantity int // 具名字段(聚合)
}
func (item *Item) Cost float64 {
return item.price * float64(item.quantity)
}
type SpecialItem struct {
Item // 匿名字段(嵌入)
catalogId int// 具名字段(聚合)
}
這裡,SpecialItem嵌入了一個Item類型。這意味著我們可以在一個SpecialItem上調用Item的Cost方法。
special := SpecialItem{Item{〞Green〞, 3, 5}, 207}
fmt.Println(special.id, special.price, special.quantity, special.catalogId)
fmt.Println(special.Cost)
Green 3 5 207
15
當調用 special.Cost的時候,SpecialItem 類型沒有它自身的Cost方法,Go語言使用 Item.Cost方法。同時,傳入其嵌入的Item 值,而非整個調用該方法的SpecialItem值。
稍後我們將看到,如果嵌入的Item中有任何字段與SpecialItem的字段同名,那麼我們仍然可以通過使用類型作為該名字的一部分來調用Item的字段。例如,special.Item.price。
同時也可以在自定義的結構體中創建與所嵌入的字段中的方法同名的方法,來覆蓋被嵌入字段中的方法。例如,假設我們有一個新的item類型:
type LuxuryItem struct {
Item // 匿名字段(嵌入)
markup float64 // 具名字段(聚合)
}
如上所述,如果我們在LuxuryItem上調用Cost方法,就會使用嵌入的Item.Cost方法,就像SpecialItems中一樣。下面提供了3種不同的覆蓋嵌入方法的實現(當然,只使用了其中的一種!)。
/*
func (item *LuxuryItem) Cost float64 { // 沒必要這麼冗長!
return item.Item.price * float64(item.Item.quantity) * item.markup
}
func (item *LuxuryItem) Cost float64 { // 沒必要的重複!
return item.price * float64(item.quantity) * item.markup
}
*/
func (item *LuxyryItem) Cost float64{ // 完美
return item.Item.Cost * item.markup
}
最後一個實現充分利用了嵌入的Cost方法。當然,如果我們不希望這樣做,也沒必要使用嵌入類型的方法來重寫方法(嵌入字段將在稍後講解結構體時講到,參見6.4節)。
6.2.1.2 方法表達式
就像我們可以對函數進行賦值和傳遞一樣,我們也可以對方法表達式進行賦值和傳遞。方法表達式是一個必須將方法類型作為第一個參數的函數。(在其他語言中常常使用術語「未綁定方法」(unbound method)來表示類似的概念。)
asStringV := Part.String // 有效簽名:func(Part) string
sv := asStringV(part)
hasPrefix := Part.HasPrefix // 有效簽名:func(Part, string) bool
asStringP := (*Part).String // 有效簽名:func(*Part) string
sp := asStringP(&part)
lower := (*Part).LowerCase // 有效簽名:func(*Part)
lower(&part)
fmt.Println(sv, sp, hasPrefix(part, 〞w〞), part)
«16 〞WRENCH〞» «16 〞WRENCH〞» true «16 〞wrench〞»
這裡我們創建了 4 個方法表達式:asStringV接受一個 Part 值作為其唯一的參數, hasPrefix接受一個 Part 值作為其第一個參數以及一個字符串作為其第二個參數, asStringP和lower都接受一個*Part值作為其唯一參數。
方法表達式是一種高級特性,在關鍵時刻非常有用。
目前為止我們所創建的自定義類型都有一個潛在的致命錯誤。沒有一個自定義類型可以保證它們初始化的數據是有效的(或者說強制有效),也沒有任何方法可以保證這些類型的數據(或者說結構體類型中的字段)不會被賦值為非法數據。例如,Part.Id和Part.Name字段可以設置為任何我們想設置的值。但如果我們想為其設置限制呢?例如,只允許ID為正整數,而且只允許名字為某固定格式?我們將在下一節討論該問題,屆時我們會創建一個小而全的其字段經驗證的自定義類型。
6.2.2 驗證類型
對於許多簡單的自定義類型來說,沒必要進行驗證。例如,我們可能這樣定義一個類型type Point {x, y int},其中任何x和y值都是合法的。此外,由於Go語言保證初始化所有變量(包括結構體的字段)為它們的零值,因此顯式的構造函數就是多餘的。
對於其零值構造函數不能滿足條件的情況下,我們可以創建一個構造函數。Go語言不支持構造函數,因此我們必須顯式地調用構造函數。為了支持這些,我們必須假設該類型有一個非法的零值,同時提供一個或者多個構造函數用於創建合法的值。
當碰到其字段必須被驗證時,我們也可以使用類似的方法。我們可以將這些字段設為非導出的,同時使用導出的訪問函數來做一些必要的驗證。[3]
讓我們來看一個短小但完整的自定義類型來解釋這些要點。
type Place struct {
latitude, longitude float64
Name string
}
func New(latitude, longitude float64, name string) *Place {
return &Place{ saneAngle(0, latitude), saneAngle(0, longitude), name }
}
func (place *Place) Latitude float64 { return place.latitude }
func (place *Place) SetLatitude(latitude float64) {
place.latitude = saneAngle(place.latitude, latitude)
}
func (place *Place) Longitude float64{ return place.longitude }
func (place *Place) SetLongitude(longitude float64) {
place.longitude = saneAngle(place.longitude, longitude)
}
func (place *Place) String string {
return fmt.Sprintf(〞(%.3f°, %.3f°) %q〞, place.latitude, place.longitude, place.Name)
}
func (original *Place) Copy *Place {
return &Place{ original.latitude, original.longitude, original.Name }
}
類型Place是導出的(從place包中),但是它的latitude和longitude字段是非導出的,因為它們需要驗證。我們創建了一個構造函數New來保證總是能夠創建一個合法的*place.Place。Go語言的慣例是調用New構造函數,如果定義了多個構造函數,則調用以「New」開頭的那些。(由於有點跑題,我們還沒給出saneAngle函數。它接受一個舊的角度值和一個新的角度值,如果新值在其範圍內則返回新值。否則返回舊值。)同時通過提供未導出字段的getter和setter函數,我們可以保證只為其設置合法的值。
String方法的定義意味著*Place值滿足fmt.Stringer接口,因此*Place會按照我們想要的方式而非Go語言的默認格式進行打印。同時我們也提供了一個Copy方法,但並未為它提供任何驗證機制,因為我們知道被複製的原始值是合法的。
newYork := place.New(40.716667, -74, 〞New York〞) // newYork是一個*Place
fmt.Println(newYork)
baltimore := newYork.Copy // baltimore是一個*Place
baltimore.SetLatitude(newYork.Latitude - 1.43333)
baltimore.SetLongitude(newYork.Longitude - 2.61667)
baltimore.Name = 〞Baltimore〞
fmt.Println(baltimore)
(40.717°, -74.000°) 〞New York〞
(39.283°, -76.617°) 〞Baltimore〞
我們將Place類型放在place包中,並調用place.New函數來創建一個*Place的值。一旦創建了一個*Place,我們就可以像調用任何標準庫中自定義類型的方法一樣調用該*Place值的方法。
6.3 接口
在 Go語言中,接口是一個自定義類型,它聲明了一個或者多個方法簽名。接口是完全抽像的,因此不能將其實例化。然而,可以創建一個其類型為接口的變量,它可以被賦值為任何滿足該接口類型的實際類型的值。
interface{}類型是聲明了空方法集的接口類型。無論包含不包含方法,任何一個值都滿足 interface{}類型。畢竟,如果一個值有方法,那麼其方法集包含空的方法集以及它實際包含的方法。這也是 interface{}類型可以用於任意值的原因。我們不能直接在一個以interface{}類型值傳入的參數上調用方法(雖然該值可能有一些方法),因為該值滿足的接口沒有方法。因此,通常而言,最好以實際類型的形式傳入值,或者傳入一個包含我們想要的方法的接口。當然,如果我們不為有方法的值使用接口類型,我們就可以使用類型斷言(參見5.1.2節)、類型開關(參見5.2.2.2節)或者甚至是反射(參見9.4.9節)等方式來訪問方法。
這裡有個非常簡單的接口。
type Exchanger interface {
Exchange
}
Exchanger接口聲明了一個方法Exchange,它不接受輸入值也不返回輸出。根據Go語言的慣例,定義接口時接口名字需以er結尾。定義只包含一個方法的接口是非常普遍的。例如,標準庫中的io.Reader和io.Writer接口,每一個都只聲明了一個方法。需注意的是,接口實際上聲明的是一個API(Application Programming Interface,程序編程接口),即0個或者多個方法,雖然並不明確規定這些方法所需的功能。
一個非空接口自身並沒什麼用處。為了讓它發揮作用,我們必須創建一些自定義的類型,其中定義了一些接口所需的方法[4]。這裡有兩個自定義類型。
type StringPair struct { first, second string }
func (pair *StringPair) Exchange {
pair.first, pair.second = pair.second, pair.first
}
type Point [2]int
func (point *Point) Exchange { point[0], point[1] = point[1], point[0] }
自定義的類型StringPair和Point完全不同,但是由於它們都提供了Exchange方法,因此兩個都能夠滿足Exchanger接口。這意味著我們可以創建StringPair和Point值,並將它們傳給接受Exchanger的函數。
需注意的是,雖然StringPair和Point類型都能夠滿足Exchanger接口,但是我們並沒有這樣顯式地聲明,我們也沒有寫任何implements或者inherits語句。StringPair和Point類型提供了該接口所聲明的方法(在這裡只有一個方法),這一事實足夠讓Go語言知道它們滿足該接口。
方法的接收者聲明為指向其類型的指針,以便我們可以修改調用該方法的(指針所指向的)值。
雖然 Go語言足夠聰明會以合理的方式打印自定義類型,我們更希望通過它們的字符串表示來控制打印。這可以很容易地通過為其添加一個滿足 fmt.Stringer 接口的方法來實現,即一個滿足簽名Stringstring的方法。
func (pair StringPair) String string {
return fmt.Sprintf(〞%q+%q〞, pair.first, pair.second)
}
該方法返回一個字符串,該字符串由兩個用雙引號包圍的字符串組合而成,中間用「+」號連接。該方法定義好後,Go語言的fmt包的打印函數就會使用它來打印StringPair值。當然也包括*StringPair的值,因為Go語言會自動將其解引用,以得到其所指向的值。
下面有個代碼片段,展示了一些Exchanger值的創建、它們對Exchange方法的調用,以及對接受Exchanger值的自定義方法exchangeThese函數的調用。
jekyll := StringPair{〞Henry〞, 〞Jekyll〞}
hyde := StringPair{〞Edward〞, 〞Hyde〞}
point := Point{5, -3}
fmt.Println(〞Before: 〞, jekyll, hyde, point)
jekyll.Exchange // 當做: (&jekyll).Exchange
hyde.Exchange // 當做: (&hyde).Exchange
point.Exchange // 當做: (&point).Exchange
fmt.Println(〞After #1:〞, jekyll, hyde, point)
exchangeThese(&jekyll, &hyde, &point)
fmt.Println(〞After #2:〞, jekyll, hyde, point)
Before: 〞Henry〞+〞Jekyll〞 〞Edward〞+〞Hyde〞 [5 -3]
After #1: 〞Jekyll〞+〞Henry〞 〞Hyde〞+〞Edward〞 [-3 5]
After #2: 〞Henry〞+〞Jekyll〞 〞Edward〞+〞Hyde〞 [5 -3]
上面所創建的變量都是值,然而Exchange方法需要的是一個指針類型接收者。我們之前也注意到,這並不是什麼問題,因為當我們調用一個需要指針參數的方法而實際傳入的只是可尋址的值時,Go語言會智能地將該值的地址傳給方法。因此,在上面的代碼片段中,jekyll.Exchange會自動被當做(&jekyll).Exchange用,其他的方法調用情況也類似。
在調用exchangeThese函數的時候,我們必須顯式地傳入值的地址。假如我們傳入的是StringPair類型的值hyde,Go編譯器會發現StringPair不能滿足Exchanger接口,因為在StringPair接收者上並未定義方法,從而停止編譯並報告錯誤。然而,如果我們傳入一個*StringPair(如&hyde),編譯就能成功。之所以這樣,是因為有一個接受*StringPair接收者的方法Exchange,也意味著*StringPair滿足Exchanger接口。
這裡是exchangeThese函數。
func exchangeThese(exchangers…Exchanger) {
for _, exchanger := range exchangers {
exchanger.Exchange
}
}
這個函數並不關心我們傳入的是什麼類型(實際上我們傳入的是兩個*StringPair 值和一個*Point 值),只要它滿足 Exchanger 接口即可(編譯器檢查),所以這裡用的鴨子類型是類型安全的。
正如我們在定義StringPair.String方法以滿足fmt.Stringer接口時所看到的一樣,除了滿足我們自定義的接口之外,我們也可以滿足標準庫中或者任何其他我們需要的接口。另一個例子io.Reader接口,它聲明了Read(byte)(int, error)方法簽名,當被調用時,它會將調用它的值的數據寫入給定的byte 切片中。這種寫是破壞式的,也就是說,寫入的每一字節都從其調用處被刪除。
func (pair *StringPair) Read(data byte) (n int, err error) {
if pair.first == 〞〞 && pair.second == 〞〞 {
return 0, io.EOF
}
if pair.first != 〞〞 {
n = copy(data, pair.first)
pair.first = pair.first[n:]
}
if n < len(data) && pair.second != 〞〞 {
m := copy(data[n:], pair.second)
pair.second = pair.second[m:]
n += m
}
return n, nil
}
只要實現了這個Read方法,StringPair類型就滿足了io.Reader接口的定義。因此,現在StringPair(或者準確地說是*StringPair,因為有些方法需要指針類型的接收者)既是Exchanger和fmt.Stringer,也是io.Reader。不用說,*StringPair肯定實現了這些接口所定義的所有方法了。當然,我們也可以添加更多的方法以滿足更多我們想要的接口。
該方法使用了內置的copy函數(參見4.2.3節)。該函數可以用於將數據從一個切片複製到另一個切片。但是這裡我們以另外一種形式使用它,將字符串拷進byte。函數copy複製的數據不會超出目標byte的容量,同時返回其複製的字節數。自定義的StringPair.Read方法從其第一個字符串寫數據(同時將已寫的數據刪除),然後對第二個字符串做同樣的操作。如果兩個字符串都是空的,則方法返回一個字節數0以及io.EOF。值得一提的是,如果第二條if語句的聲明無條件地執行了,而第三個if語句的第二個條件刪除了,該方法仍能夠完美地運行,只是損失了一些(也許是微不足道的)效率。
這裡有必要使用一個指針接收者,因為 Read方法會修改調用它的值。通常而言,除小數據外,我們更傾向於使用指針接收者,因為傳指針比傳值更為高效。
定義了Read方法之後,我們就可以使用它了。
const size = 16
robert := &StringPair{〞Robert L.〞, 〞Stevenson〞}
david := StringPair{〞David〞, 〞Balfour〞}
for _, reader := range io.Reader{robert, &david} {
raw, err := ToBytes(reader, size)
if err != nil {
fmt.Println(err)
}
fmt.Printf(〞%q\n〞, raw)
}
〞Robert L.Stevens〞
〞DavidBalfour〞
該代碼片段創建了兩個io.Reader。由於我們實現StringPair.Read方法的時候接收者是一個指針類型,因此只有*StringPair 類型才能滿足 io.Reader接口,而StringPair值不能滿足。對於第一個StringPair,我們創建了它的值,並將robert變量賦值為指向它的指針,對於第二個StringPair,我們將david變量賦值為一個StringPair值,因此在io.Reader切片中使用了它的地址。
一旦變量設置好後,我們就可以迭代它們,對於每一個變量,我們使用自定義的ToBytes函數將其數據複製到byte中,然後將其原始字節以雙引號括起來的字符串的形式打印出來。
該 ToBytes函數接受一個 io.Reader(即任何包含簽名為 Read(byte)(int,error)的方法的值,例如*os.File 值)和一個大小限制,同時返回一個包含所讀數據的byte切片和一個error值。
func ToBytes(reader io.Reader, size int) (byte, error) {
data := make(byte, size)
n, err := reader.Read(data)
if err != nil {
return data, err
}
return data[:n], nil // 清除無用的字節
}
就像我們之前所看到的exchangeThese函數一樣,該函數不知道也不關心所傳入值的具體類型,只要它是某種類型的io.Reader。
如果數據讀成功,該數據切片會被重新切片以將其長度減至實際所讀數據的字節數。如果我們不這樣做,並且其預設的大小值太大,那麼最終得到的數據也會包含所讀數據之外的字節(每個字節的值為 0x00)。例如,如果不重新切片,david 變量的值可能是這樣的〞DavidBalfour\ x00\x00\x00\x00〞。
需注意的是,接口和滿足該接口的任何類型之間沒有顯式的連接。我們無需聲明一個自定義的類型inherits、extends或者implements一個接口,只需給某個類型定義所需的方法就足夠了。這使得Go語言非常靈活。我們可以很容易地隨時添加新接口、類型以及方法,而無需破壞繼承樹。
接口嵌入
Go語言的接口(也包括我們將在下一節看到的結構體)對嵌入的支持非常好。接口可以嵌入其他接口,其效果與在接口中直接添加被嵌入接口的方法一樣。讓我們以一個簡單的例子來解釋。
type LowerCaser interface {
LowerCase
}
type UpperCaser interface {
UpperCase
}
type LowerUpperCaser interface {
LowerCaser // 就像在這裡寫了LowerCase函數一樣
UpperCaser // 就像在這裡寫了UpperCase函數一樣
}
LowerCaser 接口聲明了一個方法 LowerCase,它不接受參數,也沒有返回值。UpperCaser 接口也類似。而 LowerUpperCaser 接口則將這兩個接口嵌套進來。這也意味著對於一個具體的類型,如果要滿足LowerUpperCaser接口,就必須定義LowerCase和UpperCase方法。
這個小例子的嵌入可能看起來沒多大優勢。然而,如果我們要為前兩個接口添加額外的方法(例如,LowerCaseSpecial方法和UpperCaseSpecial方法),那麼LowerUpperCaser接口也會自動地將其包含進來,而無需修改自己的代碼。
type FixCaser interface {
FixCase
}
type ChangeCaser interface {
LowerUpperCaser // 就像在這裡寫了LowerCase函數和UpperCase函數一樣
FixCaser //就像在這裡寫了FixCase函數一樣
}
這裡我們再添加兩個接口,因此現在得到了一個分等級的嵌套接口,如圖6-2所示。
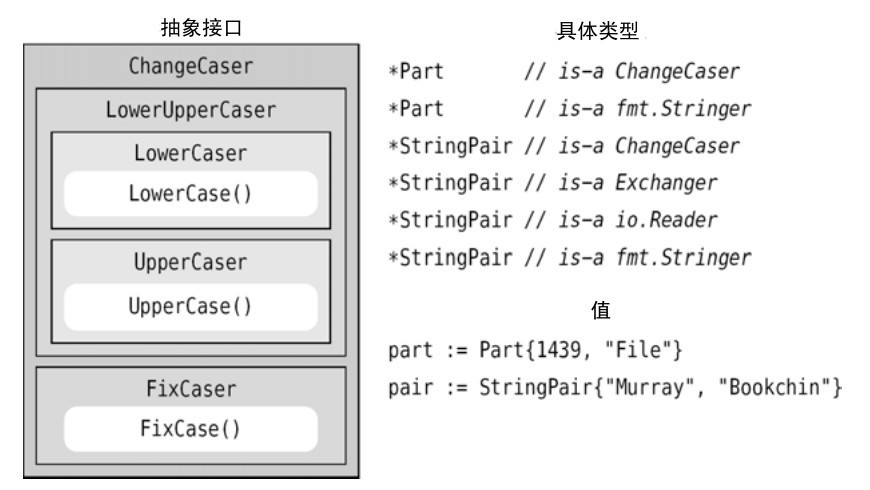
圖6-2 Caser接口、類型和示例值
當然,這些接口本身並沒多大用處。為了讓它們發揮作用,我們需要定義具體的類型來實現它們。
func (part *Part) FixCase {
part.Name = fixCase(part.Name)
}
我們在前面已給出了自定義類型 Part(參見 6.2.1 節)。這裡,為其添加了一個額外的方法FixCase,它工作於Part的Name字段,就像前文的LowerCase和UpperCase方法一樣。所有這些大小寫轉換方法都接受一個指針類型的接收者,因為它們需要修改調用它的值。LowerCase方法和UpperCase方法通過標準庫來實現,而FixCase方法則依賴於自定義的fixCase函數。這種簡短方法依賴於函數來實現具體功能的模式在Go語言中非常普遍。
Part.String方法滿足標準庫中的fmt.Stringer接口,這意味著任何Part(或者*Part)類型的值都可以使用該方法返回的字符串進行打印。
func fixCase(s string) string {
var chars rune
upper := true
for _, char := range s {
if upper {
char = unicode.ToUpper(char)
} else {
char = unicode.ToLower(char)
}
chars = append(chars, char)
upper = unicode.IsSpace(char) || unicode.Is(unicode.Hyphen, char)
}
return string(chars)
}
這個簡單的函數返回給定字符串的一份副本,其中除了字符串的首字母及空格或者連字符後面的第一個字母大寫之外,其他所有字母都是小寫的。例如,給定字符串「lobelia sackville-baggins」,該函數會將其轉換成「Lobelia Sackville-Baggins」。
自然,我們可以讓所有自定義類型都滿足這些大小寫轉換接口。
func (pair *StringPair) UpperCase {
pair.first = strings.ToUpper(pair.first)
pair.second = strings.ToUpper(pair.second)
}
func (pair *StringPair) FixCase {
pair.first = fixCase(pair.first)
pair.second = fixCase(pair.second)
}
這裡我們為之前所創建的StringPair類型添加了兩個方法,使它滿足LowerCaser、UpperCaser和FixCaser接口。我們沒有列出StringPair.LowerCase方法,因為它與StringPair.UpperCase方法的代碼結構完全相同。
*Part和*StringPair兩種類型都能夠滿足caser接口,包括ChangeCaser接口,因為這些類型滿足其所有嵌入的接口。它們也同時滿足標準庫中的fmt.Stringer 接口。而*StringPair類型滿足我們的Exchanger接口以及標準庫中的io.Reader接口。
我們並不是強制要求滿足每個接口。例如,如果我們選擇不實現StringPair.FixCase接口,*StringPair類型就只能滿足LowerCaser、UpperCaser、LowerUpperCaser、Exchanger、fmt.Stringer和io.Reader接口。
下面讓我們創建一些值,看看它們的方法。
toaskRack := Part{8427, 〞TOAST RACK〞}
toastRack.LowerCase
lobelia := StringPair{〞LOBELIA〞, 〞SACKVILLE-BAGGINS〞}lobelia.FixCase
fmt.Println(toastRack, lobelia)
«8427 〞toast rack〞» 〞Lobelia〞+〞Sackville-Baggins〞
這些方法被調用時其行為如我們所料。但如果我們有一堆這樣的值而想在它們之上調用方法呢?下面的做法不太好。
for _, x := range interface{}{&toastRack, &lobelia} { // 不安全!
x.(LowerUpperCaser).UpperCase // 未經檢查的類型斷言
}
由於所有的大小寫轉換方法都會修改調用它的值,因此我們必須使用指向值的指針,因此需要傳入指針接收者。
這裡所使用的方法有兩點缺陷。相對較小的一個缺陷是該未經檢查的類型斷言是作用於LowerUpperCaser接口的,它比我們實際所需要的接口更泛化。更糟糕的一種做法是使用更為泛化的ChangeCaser接口。但是我們不能使用FixCaser接口,因為它只提供了FixCase方法。我們應該採用剛好能滿足條件的特定接口,這個例子中是UpperCaser接口。該方法最主要的缺陷是使用了一個未經檢查的類型斷言,可能導致拋出異常!
for _, x := range interface{}{&toastRack, &lobelia} {
if x, ok := x.(LowerCaser); ok { // 影子變量
x.LowerCase
}
}
上面的代碼片段使用了一種更為安全的方式且使用了最合適的特定接口來完成工作,但這相當笨拙。這裡的問題是,我們使用的是一個通用的interface{}值的切片,而非一個具體類型的值或者滿足某個特殊類型接口的切片。當然,如果所給的都是interface{},那麼這種做法是我們所能做到的最好的。
for _, x := range FixCaser { &toastRack, &lobelia } { // 完美的做法
x.FixCase}
上面代碼所示的方式是最好的。我們將切片聲明為符合我們需求的FixCaser而不是對原始的interface{}接口做類型檢查,從而把類型檢查工作交給編譯器。
接口的靈活性的另一方面是,它們可以在事後創建。例如,假設我們創建了一些自定義的類型,其中有一些有一個 IsValid bool 方法。如果後面我們有一個函數需要檢查其所接收到的某個值是不是我們定義的,通過檢查它是否支持 IsValid方法來調用該方法,這就很容易做到。
type IsValider interface {
IsValid bool
}
首先,我們創建了一個接口,它聲明了一個我們希望檢查的方法。
if thing, ok := x.(IsValider); ok {
if !thing.IsValid{
reportInvalid(thing)
} else {
//...處理有效的thing...
}
}
創建了該接口之後,我們現在就可以檢查任意自定義類型看它是否提供IsValid bool方法了,如果提供了,我們就調用該方法。
接口提供了一種高度抽像的機制。當某些函數或者方法只關心該傳入的值能完成什麼功能,而不關心該值的實際類型時,接口允許我們聲明一個方法集合,並讓這些函數或者方法使用接口參數。本章的後面節中我們將進一步討論它們的使用(參見6.5.2節)。
6.4 結構體
在Go語言中創建自定義結構體最簡單的方式是基於Go語言的內置類型創建。例如,type Integer int創建了一個自定義的Integer類型,其中我們可以添加自己的方法。自定義類型也可以基於結構體創建,用於聚合和嵌入。這種方式非常有用,因為當值(在結構體中叫做字段)來自不同類型時,它不能存儲在一個切片中(除非我們使用interface{})。與C++的結構體相比,Go語言的結構體更接近於C的結構體(例如,它們不是類),並且由於對嵌入的完美支持,它更容易使用。
在前面的章節以及本章中,我們已經看過了很多關於結構體的例子,本書接下來還有更多關於結構體的例子。但是,有些結構體的特性我們還沒看到過,因此讓我們從一些說明性的例子開始講解。
points := [2]int{{4, 6}, {}, {-7, 11}, {15, 17}, {14, -8}}
for _, point := range points {
fmt.Printf(〞(%d, %d)〞, point[0], point[1])
}
上面代碼片段中的points變量是一個[2]int類型的切片,因此我們必須使用索引操作符來獲得每一個坐標。(順便提一下,得益於Go語言的自動零值初始化功能,{}項與{0, 0}項等價。)對於小而簡單的數據而言,這段代碼能夠工作得很好,但還有一種使用匿名結構體的更好的方法。
points := struct{x, y int} {{4, 6}, {},{-7,11},{15,17},{14,-8}}
for _, point := range points {
fmt.Printf(〞(%d, %d)〞, point.x, point.y)
}
在這裡,上面的代碼片段中的points變量是一個struct{x, y int}結構體。雖然該結構體本身是匿名的,我們仍然可以通過具名字段來訪問其數據,這比前面所使用的數組索引更為簡便和安全。
結構體的聚合與嵌入
我們可以像嵌入接口或者其他類型的方式那樣來嵌入結構體,也就是通過將一個結構體的名字以匿名字段的方式放入另一個結構體中來實現。(當然,如果我們給內部結構體一個名字,那該結構體就成了一個聚合的具名字段,而非一個嵌入的匿名字段。)
通常一個嵌入字段的字段可以通過使用.(點)操作符來訪問,而無需提及其類型名,但是如果外部結構體有一個字段的名字與嵌入的結構體中某個字段名字相同,那麼為了避免歧義,我們使用時必須帶上嵌入結構體的類型名。
結構體中的每一個字段的名字都必須是唯一的。對於嵌入的(即匿名的)字段,唯一性要求足以保證避免歧義。例如,如果我們有一個類型為 Integer的匿名字段,那麼我們還可以包含名字為比如Integer2或者BigInteger的字段,因為它們有明顯的區別,但卻不能包含像Matrix.Integer或者*Integer這樣的字段,因為這些名字的最後部分字段嵌入的Integer 字段完全一樣,而字段的名字的唯一性要求是基於它們的最後部分的。
嵌入值
讓我們看一個簡單的例子,它涉及了兩個結構體。
type Person struct {
Title string // 具名字段(聚合)
Forenames string // 具名字段(聚合)
Surname string // 具名字段(聚合)
}
type Author1 struct {
Names Person // 具名字段(聚合)
Title string // 具名字段(聚合)
YearBorn int // 具名字段(聚合)
}
在前面的章節中,我們看到過許多類似的例子。這裡,Author1結構體的字段都是具名的。下面演示了如何使用這些結構體,並給出了它們的輸出(使用一個自定義的Author1.String方法,這裡未給出)。
author1 := Author1{ Person{〞Mr〞, string{〞Robert〞, 〞Louis〞,〞Balfour〞}, 〞Stevenson〞},
string{〞Kidnapped〞, 〞Treasure Island〞}, 1850}
fmt.Println(author1)
author1.Names.Title = 〞〞
author1.Names.Forenames = string{〞Oscar〞, 〞Fingal〞, 〞O'Flahertie〞,〞Wills〞}
author1.Names.Surname = 〞Wilde〞
author1.Title = string{〞The Picture of Dorian Gray〞}
author1.YearBorn += 4
fmt.Println(author1)
Stevenson, Robert Louis Balfour, Mr (1850) 〞Kidnapped〞 〞Treasure Island〞
Wilde, Oscar Fingal O'Flahertie Wills (1854) 〞The Picture of Dorian Gray〞
上面代碼開始時創建了一個 Author1 值,並將其所有字段都填充上,然後打印。然後,我們更改了該值的字段並再次將其輸出。
type Author2 struct {
Person // 匿名字段(嵌入)
Title string // 具名字段(聚合)
YearBorn int // 具名字段(聚合)
}
為了嵌入一個匿名字段,我們使用了要嵌入類型(或者接口,稍後看到)的名字而未聲明一個變量名。我們可以直接訪問這些字段的字段(即無需聲明類型或者接口名),或者為了與外圍結構體的字段的名字區分開,使用類型或者接口的名字訪問嵌入字段的字段。
下面給出的Author2結構體嵌入了一個Person結構體作為其匿名字段。這意味著我們可以直接訪問Person字段(除非我們需要避免歧義)。
author2 := Author2{Person{〞Mr〞, string{〞Robert〞, 〞Louis〞, 〞Balfour〞},
〞Stevenson〞}, string{〞Kidnapped〞, 〞Treasure Island〞}, 1850}
fmt.Println(author2)
author2.Title = string{〞The Picture of Dorian Gray〞}
author2.Person.Title = 〞〞 // 必須使用類型名以消除歧義
author2.Forenames = string{〞Oscar〞, 〞Fingal〞, 〞O'Flahertie〞, 〞Wills〞}
author2.Surname = 〞Wilde〞 // 等同於:author2.Person.Surname = 〞Wilde〞
author2.YearBorn += 4
fmt.Println(author2)
上面演示Author1結構體使用的代碼在這裡重複了一遍,用於演示Author2結構體的使用。它的輸出與上例相同(假設我們創建了一個功能與 Author1.String方法相同的Author2.String方法)。
通過嵌入Person作為匿名字段,我們所得到的效果與直接添加Person結構體的字段所得到的效果幾乎相同。但也不全是,因為如果我們把這些字段添加進來,就得到兩個Title字段了,從而不能通過編譯。
創建 Author2 值的效果等價於創建 Author1的效果,除非需要消除歧義(author2.Persion.Title與author2.Title的歧義),我們可以直接引用Person中的字段(例如, author2.Forenames)。
嵌入帶方法的匿名值
如果一個嵌入字段帶方法,那我們就可以在外部結構體中直接調用它,並且只有嵌入的字段(而不是整個外部結構體)會作為接收者傳遞給這些方法。
type Tasks struct {
slice string // 具名字段(聚合)
Count // 匿名字段(嵌入)
}
func (tasks *Tasks) Add(task string) {
task.slice = append(tasks.slice, task)
task.Increment // 就像寫tasks.Count.Increment一樣
}
func (tasks *Tasks) Tally int {
return int(tasks.Count)
}
我們前面講過Count類型。Tasks結構體有兩個字段:一個聚合的字符串切片和一個嵌入的Count值。正如Tasks.Add方法的實現所說明的那樣,我們可以直接訪問匿名的Count值的方法。
tasks := Takss{}
fmt.Println(tasks.IsZero, tasks.Tally, tasks)
tasks.Add(〞One〞)
tasks.Add(〞Two〞)
fmt.Println(tasks.IsZero, tasks.Tally, tasks)
true 0 { 0}
false 2 {[One Two] 2}
這裡我們創建了兩個 Tasks 值,並調用了它們的Tasks.Add、Tasks.Tally和Tasks.Count.IsZero(以 Tasks.IsZero的形式)方法。雖然我們沒有定義Tasks.String方法,但是當要打印Tasks變量的時候,Go語言仍然能夠智能地將其打印出來。(值得注意的是,我們沒有把Tally方法叫做Count,是因為嵌入的Tasks.Count值與此有衝突,會導致程序無法編譯。)
需重點注意的是,當調用嵌入字段的某個方法時,傳遞給該方法的只是嵌入字段自身。因此,當我們調用Tasks.IsZero、Tasks.Increment,或者任何其他在某個Tasks值上調用的Count方法時,這些方法接受到的是一個Count值(或者*Count值),而非Tasks值。
本例中Tasks類型定義了它自己的方法(Add和Tally),同時也有嵌入的Count類型的方法(Increment、Decrement和IsZero方法)。當然,也可以讓Tasks類型覆蓋任何Count類型中的方法,只需以相同的名字實現該方法就行。(前面我們已經看過了一個相關的例子,參見6.2.1.1節)。
嵌入接口
結構體除了可以聚合和嵌入具體的類型外,也可以聚合和嵌入接口。(自然地,反之在接口中聚合或者嵌入結構體是行不通的,因為接口是完全抽像的概念,所以這樣的聚合與嵌入毫無意義)。當一個結構體包含聚合(具名的)或者嵌入(匿名的)接口類型的字段時,這意味著該結構體可以將任意滿足該接口規格的值存儲在該字段中。
讓我們以一個簡單的例子結束對結構體的討論,該例子展示了如何讓「選項」支持長名字和短名字(例如,「-o」和「-outfile」)且規定選項值為某特定類型(int、float64和string),以及一些通用的方法。(該例子主要用於做說明用,而非為了其優雅性。如果需要一個全功能的選項解析器,可以查看標準庫中的flag包,或者godashboard.appspot.com/project上的某個第三方選項解析器。)
type Optioner interface {
Name string
IsValid bool
}
type OptionCommon struct {
ShortName string 〞short option name〞
LongName string 〞long option name〞
}
Optioner 接口聲明了所有選項類型都必須提供的通用方法。OptionCommon 結構體定義了每一個選項常用到的字段。Go語言允許我們用字符串(用Go語言的術語來說是標籤)對結構體的字段進行註釋。這些標籤並沒有什麼功能性的作用,但與註釋不同的是,它們可以通過Go語言的反射支持來訪問(參見9.4.9 節)。有些程序員使用標籤來聲明字段驗證。例如,對字符串使用像「check:len(2, 30)」這樣的標籤,或者對數字使用「check:range(0, 500)」這樣的標籤,或者使用程序員自定義的任何語義。
type IntOption struct {
OptionCommon // 匿名字段(嵌入)
Value, Min, Max int // 具名字段(聚合)
}
func (option IntOption) Name string {
return name(option.ShortName, option.LongName)
}
func (option IntOption) IsValid bool {
return option.Min <= option.Value && option.Value <= option.Max
}
func name(shortName, longName string) string {
if longName == 〞〞 {
return shortName
}
return longName
}
上面代碼片段包括IntOption自定義類型和一個輔助函數name的完全實現。由於嵌入了OptionCommon結構體,我們可以直接訪問它的字段,正如我們在IntOption.Name方法中所使用的那樣。IntOption 滿足 Optioner 接口(因為它提供了一個 Name和IsValid方法,而其簽名也一樣)。
雖然 name所做的處理非常簡單,我們還是選擇將其功能獨立出來,而非在IntOption.Name中實現。這使得IntOpiton.Name函數非常簡短,並且也讓我們可以在其他自定義選項中重用這些功能。因此,像GenericOption.Name和StringOption.Name這樣的方法其方法體等價於IntOption.Name中的單語句方法體,而這3條語句都依賴於name函數完成實質性的工作。這是Go語言中非常普通的模式,我們將在本章的最後一節中再次看到這種模式。
StringOption的實現非常類似於IntOption的實現,因此我們沒有給出。(不同點在於,它的Value字段是string類型的,而它的IsValid方法在Value值為非空的情況下返回true。)對於FloatOption類型,我們使用了嵌入的接口,下面給出它是如何實現的。
type FloatOption struct {
Optioner // 匿名字段(接口嵌入:需要具體的類型)
Value float64 // 具名字段(聚合)
}
這是 FloatOpiton 類型的完全實現。嵌入的Optioner 字段意味著當我們創建一個FloatOption值時,必須給該字段賦一個滿足該接口的值。
type GenericOption struct {
OptionCommon // 匿名字段(嵌入)
}
func (option GenericOption) Name string {
return name(option.ShortName, option.LongName)
}
func (option GenericOption) IsValid bool {
return true
}
這是GenericOption類型的完全實現,它滿足Optioner接口。
FloatOption類型有一個嵌入的Optioner類型的字段,因此FloatOption值需要一個具體的類型來滿足該字段的Optioner接口。這可以通過給FloatOption值的Optioner字段賦一個GenericOption類型的值來實現。
現在我們定義了所需的類型(IntOption和FloatOption等),讓我們看看如何創建並使用它們。
fileOption := StringOption{OptionCommon{〞f〞, 〞file〞}, 〞index.html〞}
topOption := IntOption {
OptionCommon: OptionCommon{〞t〞, 〞top〞},
Max: 100,
}
sizeOption := FloatOption{
GenericOption{OptionCOmmon{〞s〞, 〞size〞}}, 19.5}
for _, option := range Optioner{topOption, fileOption, sizeOption} {
fmt.Print(〞name=〞, option.Name, 〞‧valid=〞, option.IsValid)
fmt.Print(〞 ‧value=〞)
switch option := option.(type) { // 影子變量
case IntOption:
fmt.Print(option.Value, 〞‧min=〞, option.Min, 〞 ‧max= 〞, optiuon.Max, 〞\n〞)
case StringOption:
fmt.Println(option.Value)
case FloatOption:
fmt.Println(option.Value)
}
}
name=top‧valid=true‧value=0‧min=0‧max=100
name=file‧valid=true‧value=index.html
name=size‧valid=true‧value=19.5
StringOption類型的fileOption值使用傳統的方式創建,並且每一個字段都按順序被賦以一個合適值。但是對於IntOpiton類型的topOption值,我們只為OptionCommon和Max字段賦值,而其他字段只需零值就夠了(即Value字段和Min字段只需零值就夠了)。Go語言允許我們使用fieldName: fieldValue的形式初始化我們創建的結構體的值中的字段。使用這種語法後,任何沒有顯式賦值的字段都被自動賦值為零值。
FloatOption類型的sizeOption值的第一個字段是一個Optioner接口,因此我們必須提供一個滿足該接口的具體類型。為此,我們在這裡創建了一個GenericOption值。
創建了3個不同的選項後我們就可以使用Optioner,即一個保存滿足Optioner接口的值的切片來迭代它們。在循環中,option變量輪流保存每個選項(其類型為Optioner)。我們可以通過 option 變量來調用 Optioner 接口中聲明的任何方法,這裡我們調用了Option.Name和Option.IsValid方法。
每一個選項類型都有一個Value字段,但是它們是屬於不同類型的。例如,IntOption.Value是一個int類型,而StringOption.Value是一個string類型。因此,為了訪問特定類型的Value字段(任何其他特定類型的字段或者方法也類似),我們必須將給定的選項轉換為正確的類型。這可以通過使用一個類型開關(參見5.2.2.2節)來輕鬆完成。在上面的類型開發代碼片段中,我們創建了一個影子變量(option),它在case語句中執行時總是擁有正確的類型(例如,在IntOption case語句中,option是IntOption類型,等等),因此在每個case語句中,我們都能夠訪問任何特定類型的字段或者方法。
6.5 例子
既然我們知道了如何創建自定義類型,就讓我們來看一些更為實際和複雜的例子。第一個例子展示了如何創建一個簡單的自定義類型。第二個例子展示了如何使用嵌入來創建一系列相關接口和結構體,以及如何提供類型構造函數和創建包中所有導出類型的值的工廠函數。第三個例子展示了如何實現一個完整的自定義通用集合類型。
6.5.1 FuzzyBool——一個單值自定義類型
在本節中,讓我們看看如何創建一個基於單值的自定義類型及其支撐方法。這個示例基於一個結構體,保存在文件fuzzy/fuzzybool/fuzzybool.go中。
內置的布爾類型是雙值的(true和false),但在一些人工智能領域中,使用的是模糊(fuzzy)布爾類型。它們的值與「true」和「false」相關,並且是介於它們之間的中間體。在我們的實現,我們使用一個浮點值,0.0表示false而1.0表示true。在這個系統中,0.5表示50%的真(50%的假),而0.25表示0.25%的真(75%的假),依次類推。這裡有些使用示例及其產生的結果。
func main {
a, _ := fuzzybool.New(0) // 使用時可以安全地忽略err值
b, _ := fuzzybool.New(.25) // 已確定是合法的值。使用時需確認
c, _ := fuzzybool.New(.75) // 仍是變量
d := c.Copy
if err := d.Set(1); err != nil {
fmt.Println(err)
}
process(a, b, c, d)
s := *fuzzybool.FuzzyBool{a, b, c, d}
fmt.Println(s)
}
func process(a, b, c, d *fuzzybool.FuzzyBool) {
fmt.Println(〞Original:〞, a, b, c, d)
fmt.Println(〞Not: 〞, a.Not, b.Not, c.Not, d.Not)
fmt.Println(〞Not Not: 〞, a.Not.Not, b.Not.Not, c.Not.Not,
d.Not.Not)
fmt.Print(〞0.And(.25)→〞, a.And(b), 〞‧.25.And(.75)→〞, b.And(c),
〞‧.75.And(1)→〞, c.And(d), 〞 ‧.25.And(.75,1)→〞, b.And(c, d), 〞\n〞)
fmt.Print(〞0.Or(.25)→〞, a.Or(b), 〞‧.25.Or(.75)→〞, b.Or(c),
〞‧.75.Or(1)→〞, c.Or(d), 〞 ‧.25.Or(.75,1)→〞, b.Or(c, d), 〞\n〞)
fmt.Println(〞a < c, a == c, a > c:〞, a.Less(c), a.Equal(c), c.Less(a))
fmt.Println(〞Bool: 〞, a.Bool, b.Bool, c.Bool, d.Bool)
fmt.Println(〞Float: 〞, a.Float, b.Float, c.Float, d.Float)
}
Original: 0% 25% 75% 100%
Not: 100% 75% 25% 0%
Not Not: 0% 25% 75% 100%
0.And(.25)→0%.25.And(.75)→25%.75.And(1)→75% 0.And(.25,.75,1)→0%
0.Or(.25)→25%.25.Or(.75)→75%.75.Or(1)→100% 0.Or(.25,.75,1)→100%
a < c, a == c, a > c: true false false
Bool: false false true true
Float: 0 0.25 0.75 1
[0% 25% 75% 100%]
該自定義類型叫做 FuzzyBool。我們從類型定義開始看起,然後再看其構造函數。最後再看看它的方法定義。
type FuzzyBool struct{ value float32 }
FuzzyBool類型基於一個包含單float32值的結構體。該值是不可導出的,因此任何導入fuzzybool包的用戶都必須使用構造函數(按照Go語言的慣例,我們將其定義為New)來創建模糊布爾值。當然,這意味著我們可以保證只創建包含合法值的模糊布爾值。
由於FuzzyBool類型是基於結構體的,而該結構體所包含的值的類型在結構體中是獨一無二的,因此我們可以將其定義簡化為type FuzzyBool struct{ float32 }。這意味著需要將訪問該值的代碼從fuzzy.value更改為fuzzy.float32,包括下面我們將看到的一些方法中的代碼。我們更傾向於使用具名變量,部分是因為這樣更為美觀,部分是因為如果我們要更改該結構體的底層類型(如改成float64),我們只需做少量的更改。
往後的更改也有可能,因為該結構體只包含一個單值。例如,我們可以將其類型更改為type FuzzyBool float32,使它直接基於float32。這樣做能夠很好地工作,但稍微需要多點代碼,並且與基於結構體的方式相比較,實現起來也稍微麻煩。然而,如果將我們自己局限於創建不可變的模糊布爾值(唯一的區別在於,不是使用Set方法來設置新值,而是直接使用一個新的模糊布爾值賦值),通過直接基於float32類型的方式,我們可以極大地簡化代碼。
func New(value interface{}) (*FuzzyBool, error) {
amount, err := float32ForValue(value)
return &FuzzyBool{amount}, err
}
為了方便模糊布爾值的用戶,除了只接受一個 float32 值作為初始值之外,我們也可以接受float64型(Go語言的默認浮點類型)、int型(默認的整型)以及布爾值。這種靈活性是通過使用 float32ForValue函數來達到的,對應給定的值,它會返回一個 float32和nil,或者如果的給定值沒法處理則返回0.0和一個錯誤值。
如果我們傳入了一個非法值,就犯了一個編程錯誤,我們希望馬上知道該錯誤。但我們並不希望程序在用戶那裡崩潰。因此,除了返回一個*FuzzyBool值外,我們也返回錯誤值。如果我們給New函數傳入一個合法的字面量(正如前文代碼片段中所見,),我們可以安全地忽略錯誤。但是如果我們傳入的是一個變量,就必須檢查返回的錯誤值,以防它不是非空值。
New函數返回一個指向FuzzyBool類型值的指針而非一個值,因為我們在實現中讓模糊布爾值是可更改的。這也意味著這些修改模糊布爾值的方法(本例中只有一個Set)必須接受一個指針接收者,而非一個值[5]。
一個合理的經驗法則是,對於不可變的類型創建只接受值接收者的方法,而為可變的類型創建接受指針接收者的方法。(對於可變類型,讓部分方法接受值而讓其他方法接受指針是完全可行的,但是在實際使用中可能不太方便。)同時,對於大的結構體類型(例如,那些包含兩個或者更多個字段的類型),最好使用指針,這樣就能將開銷保持在只傳遞一個指針的程度。
func float32ForValue(value interface{}) (fuzzy float32, err error) {
switch value := value.(type) { // 影子變量
case float32:
fuzzy = value
case float64:
fuzzy = float32(value)
case int:
fuzzy = float32(value)
case bool:
fuzzy = 0
if value {
fuzzy = 1
}
default:
return 0, fmt.Errorf(〞float32ForValue: %v is not a 〞 +
〞number or Boolean〞, value)
}
if fuzzy < 0 {
fuzzy = 0
} else if fuzzy > 1 {
fuzzy = 1
}
return fuzzy, nil
}
該非導出的輔助函數用於在 New和Set方法中將一個值導出為[0.0, 1.0]範圍內的float32值。通過使用類型開關(參見5.2.2.2節)來處理不同的類型非常簡單。
如果該函數以一個非法值調用,我們就返回一個非空值錯誤。調用者有責任檢查返回值並在錯誤發生時採取相應處理。調用者可以拋出異常以讓應用程序崩潰,或者自己來處理問題。出現問題時,這樣的底層函數返回錯誤值是種很好的做法,因為它們沒有足夠多關於程序邏輯的信息,來瞭解如何或者是否處理錯誤,而只是將錯誤向上推給調用者,而調用者更清楚應該如何處理。
雖然我們將傳入非法值當做一種編程錯誤且認為應該返回一個非空的錯誤值,我們對超出預期的值採取從簡處理,只將其轉換成最接近的合法值。
func (fuzzy *FuzzyBool) String string {
return fmt.Sprintf(〞%.0f%%〞, 100*fuzzy.value)
}
該方法滿足 fmt.Stringer 接口。這意味著模糊布爾值會按聲明的方式輸出,而模糊布爾值可以傳遞給任何接受fmt.Stringer值的地方。
我們讓模糊布爾值的字符串表示成數字百分比。(回想一下,「%.0f」字符串格式聲明了一個沒有小數點也沒有小數位的浮點類型數字,而「%%」格式聲明了字面量%字母。字符串格式相關的內容在前文已有闡述,參見3.5節。)
func (fuzzy *FuzzyBool) Set(value interface{}) (err error) {
fuzzy.value, err = float32ForValue(value)
return err
}
該方法使得我們的模糊布爾變量變得可更改。該方法與New函數非常類似,只是這裡我們工作於一個已存在的*FuzzyBool,而非創建一個新的。如果返回的錯誤值非空,那麼模糊布爾值就是非法的,因此我們希望調用者檢查返回值。
func (fuzzy *FuzzyBool) Copy *FuzzyBool {
return &FuzzyBool(fuzzy.value)
}
對於需將自定義類型以指針的形式傳來傳去的情況,提供Copy方法會更為方便。這裡,我們簡單創建了一個新的FuzzyBool值,其值與接收者的值相同,並返回一個指向它的指針。這裡不用做任何驗證,因為我們知道接收者的值一定是合法的。這裡假設原始值使用New函數創建時其返回的錯誤值為空,對於後續Set方法調用也有類似的假設。
func (fuzzy *FuzzyBool) Not *FuzzyBool {
return &FuzzyBool{1 - fuzzy.value}
}
這是第一個邏輯運算方法,並且與其他所有方法一樣,它也工作於一個*FuzzyBool接收者。
對於該方法我們本可以有3種合理的設計方式。第一種方式是直接更改調用該方法的值而不返回任何東西。另一種方式是修改調用該方法的值並將修改後的值返回,這是標準庫中大多數big.Int和big.Rat類型的方法所採用的方式。這種方式意味著操作可以被鏈接(例如, b.Not.Not)。這也可以節省內存(因為值被重用而非重新創建),但也容易讓我們在忘記了返回值與其自身是同一個值並且已被改過時措手不及。還有一種方式跟我們這裡所採取的方式一樣:不改變其值本身,但是返回一個新的經過邏輯運算的模糊布爾值。這很容易理解和使用,並且也支持鏈式,代價是創建了更多值。我們在所有的邏輯運算函數中都使用最後一種方式。
順便提一下,模糊的〞非〞邏輯非常簡單,對於 1.0 值返回 0.0,對於 0.0 值返回 1.0,對於0.75值返回0.25,對於0.25返回0.75,對於0.5值返回0.5,依次類推。
func (fuzzy *FuzzyBool) And(first *FuzzyBool, rest...*FuzzyBool) *FuzzyBool {
minimum := fuzzy.value
rest = append(rest, first)
for _, other := range rest {
if minimum > other.value {
minimum = other.value
}
}
return &FuzzyBool{minimum}
}
模糊的「與」操作的邏輯是返回給定模糊值中最小的那個。該方法的簽名保證調用該方法時,調用者至少會傳入一個別的*FuzzyBool值(first),另外,還接受零到多個同類型的值(rest)。該方法只是簡單地將first值添加進(可能為空的)rest切片的末尾,然後迭代該切片,如果發現minimum值比迭代過程中的值大,則將minimum值設為當前迭代的值。同時,就像Not方法一樣,我們會返回一個新的*FuzzyBool值,並將原始的調用方法的模糊布爾值保持不變。
模糊的「或」操作的邏輯是返回給定模糊值中最大的那個。我們沒有給出 Or方法是因為它結構上與 And方法相同。唯一的區別就是 Or方法使用一個 maximum 變量而非一個minimum變量,並且比較的時候使用的是<小於操作符而非>大於操作符。
func (fuzzy *FuzzyBool) Less(other *FuzzyBool) bool {
return fuzzy.value < other.value
}
func (fuzzy *FuzzyBool) Equal(other *FuzzyBool) bool {
return fuzzy.value == other.value
}
這兩個方法允許我們以它們所包含的float32 值的形式比較模糊布爾值。兩個方法的返回值都為布爾值。
func (fuzzy *FuzzyBool) Bool bool {
return fuzzy.value >=.5
}
func (fuzzy *FuzzyBool) Float float64{
return float64(fuzzy.value)
}
可以將fuzzybool.New構造函數看成一個轉換函數,因為給定float32、float64、int和bool型的值,它都能夠輸出一個*FuzzyBool值。這兩個方法採用別的方式進行類似的轉換。
FuzzyBool 類型提供了一個完整的模糊布爾數據類型,可以像其他所有自定義類型一樣使用。因此,*FuzzyBool可以存儲在切片中,或者以鍵或值甚至既是鍵也是值的形式存儲在映射(map)中。當然,如果我們使用*FuzzyBool 來做一個映射(map)的鍵值,我們就可以存儲多個模糊布爾值,哪怕它們值是相同的,因為它們每個都含有不同的地址。一種解決方案是採用基於值的模糊布爾值(例如本書源代碼中的fuzzy_value例子)。另一種方法是,我們可以定義自定義集合類型,使用指針來存儲,但使用它們的值來進行比較。自定義的omap.Map類型也能完成這些功能,只要提供一個合適的小於函數(參見6.5.3節)。
除了本節給出的模糊布爾類型外,本書的例子中也包含3個備選的模糊布爾實現供比較。這些備選方案沒在本書中給出也未詳細討論。第一個可選的實現在文件 fuzzy_value/fuzzybool/fuzzybool.go和fuzzy_mutable/fuzzybool/fuzzybool.go中,其功能與本節給出的版本完全一樣(在文件fuzzy/fuzzybool/fuzzybool.go中)。fuzzy_value版本是基於值的,而非*FuzzyBool,而fuzzy_mutable版本則直接基於一個float32值而非結構體。fuzzy_mutable的代碼稍微比基於結構體的版本冗長而且難懂。第三個可選的版本提供的功能稍微比其他的少,因為它提供的是一個不可變的模糊布爾類型。它也是直接基於float32類型的,該版本的代碼在文件fuzzy_immutable/fuzzybool/ fuzzybool.go中。這是3個可選實現中最簡單的一種。
6.5.2 Shapes——一系列自定義類型
當我們希望在一系列相關的類型(例如各種形狀)之上應用一些通用的操作時(例如,讓一個形狀把它們自身畫出來),可以採取兩種用的比較廣泛的實現方法。熟悉C++、Java以及Python的程序員可能會使用層次結構,在Go語言中是嵌套接口。然而,通常更為方便而強大的做法是創建一系列能夠相互獨立的結構體。在本節中,我們兩種方式都會給出,第一種方式在文件shaper1/shapes/shapes.go中,而第二種方式在文件shaper2/shapes/shapes.go中。(值得注意的是,由於大多數包的類型、函數和方法名都是一樣的,我們簡單地使用「形狀包」來指代它們。自然地,當提到具體到某個例子的代碼時,我們會以「shaper1形狀包」和「shaper2形狀包」來區分它們。)
圖 6-3 給出了個示例,展示了我們的形狀包所能做的事情。這裡創建了一個白色的矩形,並在其上畫了一個圓,以及一些邊數和顏色不一的多邊形。
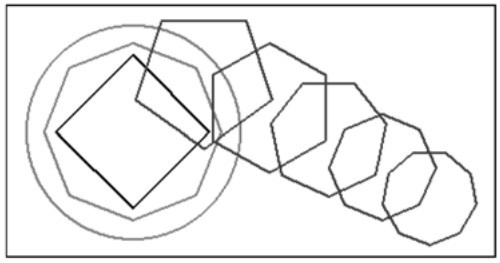
圖6-3 shaper示例的shapes.png文件
該形狀包提供了3個操作圖像的可導出函數,以及3種創建圖像的類型,其中兩種是可導出的。分層次的shapes1形狀包提供了5個可導出接口。我們從圖像相關的代碼(便捷函數)開始,然後再看看其中的接口(在兩個小節中),最後再回顧一下具體形狀相關的代碼。
6.5.2.1 包級便捷函數
標準庫中的image包提供了image.Image接口。該接口聲明了3個方法:image.Image.ColorModel返回圖像的顏色模型(以color.Model的形式),image.Image.Bounds返回圖像的邊界盒子(以image.Rectangle的形式),而image.Image.At(x, y)返回對應像素的color.Color值。需注意的是,接口image.Image中沒有聲明設置像素的方法,雖然多個圖像類型都提供了Set(x, y int, fill color.Color)方法。不過image/draw包提供了draw.Image接口,它嵌套了image.Image接口也包含了一個Set方法。標準庫中的image.Graw和image.RGBA類型以及其他類型都滿足draw.Image接口。
func FilledImage(width, height int, fill color.Color) draw.Image {
if fill == nil { // 默認將空的顏色值設為黑色
fill = color.Black
}
width = saneLength(width)
height = saneLength(height)
img := image.NewRGBA(image.Rect(0, 0, width, height))
draw.Draw(img, img.Bounds, &image.Uniform{fill}, image.ZP, draw.Src)
return img
}
該導出的便捷函數以給定的規格及統一的填充色創建圖像。
函數開始處我們將零值的顏色替換為黑色,並且保證寬度和高度兩個維度的值都是合理的。然後創建了一個 image.RGBA 值(一個使用紅色、綠色、藍色以及α-透明度值創建的圖像),並將其以draw.Image類型返回,因為我們只關心拿它來做什麼,而不關心它的實際值是什麼。
draw.Draw函數接受的參數包括一個目標圖像(類型為draw.Image)、一個聲明在哪畫圖的矩形(在本例中是整個目標圖像)、一個用於複製的源圖像(本例中是一張以給定顏色填充大小無限的圖像)、一個聲明模板矩形從哪開始畫圖的點(image.ZP是一個0點,即點(0,0)),以及如何繪製該圖的參數。這裡,我們聲明了draw.Src,因此該函數會簡單地將原圖複製至目標圖。因此,我們這裡得到的效果是將給定顏色複製至目標圖像中的每一個像素中。(draw包也有一個draw.DrawMask函數,它支持一些Porter-Daff合成運算。)
var saneLength, saneRadius, saneSides func(int) int
func init {
saneLength = makeBoundedIntFunc(1, 4096)
saneRadius = makeBoundedIntFunc(1, 1024)
saneSides = makeBoundedIntFunc(3, 60)
}
我們定義了 3 個未導出的變量來保存輔助函數,這些函數都接受一個 int 值並返回一個int值。同時我們給該包定義了一個init函數,其中這些變量被賦值成合適的匿名函數。
func makeBoundedIntFunc(minimum, maximim int) func(int) int {
return func(x int) int {
valid := x
switch {
case x < minimum:
valid = minimum
case x > maximum:
valid = maximum
}
if valid != x {
log.Printf(〞%s: replaced %d width %d\n〞, caller(1), x, valid)
}
return valid
}
}
該函數返回一個函數。在返回的函數中,對於給定的值x,如果它在minimum和maximum之間(包含這兩個值)則返回它,否則返回最接近的邊界值。
如果x值不合法,除了返回合法的替代值,我們也將相應的問題記錄下來。然而,我們並不想報告成在此處創建的函數(即saneLength、saneRadius和saneSides函數)中存在該問題,因為問題屬於其調用者。因此,這裡我們不記錄此處創建函數的名字,而是用一個自定義的caller函數記錄了調用者的名字。
func caller(steps int) string{
name := 〞?〞
if pc, _, _, ok := runtime.Caller(steps + 1); ok {
name = filepath.Base(runtime.FuncForPC(pc).Name)
}
return name
}
runtime.Caller函數返回當前被調用函數的信息,並且也不是在當前goroutine中返回。int參數定義了往回退多遠(即多少層函數)。如果傳入的參數值為0,那麼只查看當前函數信息(即shapes.caller函數),而如果傳入的值為1,則查看該函數的調用者信息,等等。我們加上1以便從函數的調用者開始查看。
函數runtime.Caller能夠返回4塊信息:程序計數器(我們將其保存在變量pc中了)、文件名以及當前調用發生處所在的行(兩個都使用空標識符忽略了),以及一個匯報信息是否可以獲取得到的布爾標識(我們將其保存在ok變量中)。
如果成功獲取到程序計數器,那麼我們就調用 runtime.FuncForPC函數以返回一個*runtime.Func 值,然後在其之上調用 runtime.Func.Name方法以獲得主調函數的方法名。其返回的名字像一條路徑,例如,對於函數返回/home/mark/goeg/src/shaper1/shapes.FilledRectangle,而對於方法則返回/home/mark/goeg/src/ shaper1/shapes.*shape‧SetFill。對於小項目而言,該路徑沒必要,因此我們使用filepath.Base函數將其剝離掉。然後我們將其名字返回。
例如,如果我們傳入一個超界的寬度值和高度值如5000來調用shapes.FilledImage函數,則saneLength函數會將問題修正。另外,由於存在問題,就會產生一個記錄,本例中該記錄是「shapes.FilledRectangle: replaced 5000 with 4096」。之所以產生這樣的結果,是因為saneLength函數使用參數1調用caller函數,在caller內部該值被設為2,因此caller函數會向上回溯3層:它自己(0層)、saneLength(1層)以及FilledImage(2層)。
func DrawShapes(img draw.Image, x, y int, shapes..Shaper) error {
for _, shape := range shapes {
if err := shape.Draw(img, x, y); err != nil {
return err
}
}
return nil
}
這是另一個導出的便捷函數,也是形狀包的兩種實現中的唯一區別。這裡給出的函數來自於層次結構的shapes1 形狀包。組合型的shapes2 形狀包區別在於其函數簽名中接受的是Drawer值,即滿足Drawer接口(它有一個Draw方法)的值,而非必須包含Draw、Fill和SetFill方法的Shaper類型的值。因此,在本例中,與層次結構的Shaper類型相比,組合的方式意味著我們使用一個更加具體且所需參數更少的類型(Drawer)。我們會在接下來的兩個節中講解這兩個接口。