
如果我們只關注大腦上一個個郵票大小的區域,我們恐怕永遠都無法理解語言器官和語法基因。心智的計算處理是以錯綜複雜的神經網絡為基礎的,這些神經網絡構成了我們的大腦皮質。數百萬計的神經元分佈於這些網絡之中,每個神經元都和數千個神經元相連,並以千分之一秒的速度傳遞著各種信息。如果我們能將顯微鏡伸進大腦,近距離觀察語言區域的神經回路,我們會看到怎樣的景象呢?沒有人知道答案,但我可以給出一個合理的猜測。具有諷刺意味的是,這是語言本能最為重要的方面,因為它是語言表達和理解能力的真正源頭,但同時它也正是我們最不瞭解的一個方面。接下來,我將要從神經元的視角,為你展現語法信息的處理過程。你不必對其中的細節過於較真,我只想讓你明白,語言本能其實與物理世界的因果定律合轍同軌,而不是一種披著生物學外衣的神秘論調。
神經網絡模型的設計基於一個簡化抽像的神經元。這個神經元能做的事情不多,它有時活躍,有時不活躍。在活躍時,它會沿著軸突(輸出線路)向與它相連的其他神經元發出信號,各神經元之間的連接點被稱作突觸。突觸可以分為興奮性突觸和抑制性突觸,它們擁有的傳遞強度也各不相同。位於接收端的神經元會將來自興奮性突觸的所有信號相加,再減去來自抑制性突觸的信號,如果差數超過了某個閾值,它就會變得活躍起來。
如果這個簡化的神經網絡足夠龐大,它就可以成為一台計算機,從而計算出任何具體問題的答案。這就像我們在第2章所看到的圖靈機一樣——通過在紙上來回穿梭,它可以得出「蘇格拉底會死」的結論。之所以這樣說,是因為我們可以用一些簡單的方式將這些模擬神經元連接起來,使之成為一個個的「邏輯門」(logic gate),以執行「與」「或」「非」等邏輯運算。邏輯「與」是指:若A為真,且B也為真,則「A與B」為真。因此,當所有的輸入端都打開時,「與門」就會自行打開。假設模擬神經元的閾值為0.5,而兩個輸入突觸的權重分別都小於0.5,但總和卻大於0.5(假設分別為0.4),這便是「與門」,如圖9-2左圖所示。
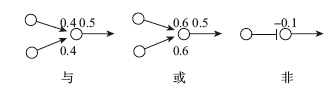
圖9-2 「與」「或」「非」
邏輯「或」是指:若A為真,或B為真,則「A或B」為真。因此,只要有一個輸入端打開,「或門」就可以打開。為了實現這一點,每個突觸的權重都必須大於這個神經元的閾值,比如說0.6,就像圖9-2中間圖所示。邏輯「非」是指:若A為假,則「非A」為真,反之亦然。因此,當輸入端打開時,「非門」就關閉,當輸入端關閉時,「非門」就打開,這一任務由抑制性突觸來完成,如圖9-2右圖所示,這個抑制性突觸的負值權重必須大到能關閉神經元的輸出。
下面來看一下神經網絡是如何計算一個適度複雜的語法規則的。在英語中,「Bill walks」中的屈折後綴「-s」的適用條件為:主語為第三人稱、單數,且動詞為現在時態,並表示習慣性動作(這就是語言學中的「體」),但動詞不能是「do」「have」「say」「be」等不規則動詞(例如可以說「Bill is」,但不能說「Bill be』s」)。一個由邏輯門構成的神經網絡可以用圖9-3的方式解決這一組邏輯關係。
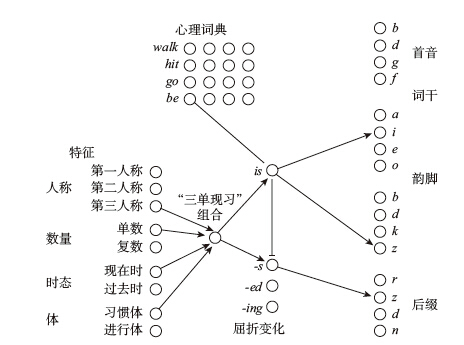
圖9-3 神經網絡模型
首先,圖9-3左下方有一組神經元代表屈折變化的各種特徵,其中相關特徵通過「與門」和一個代表「第三人稱、單數、現在時、習慣體」(簡稱「三單現習」)的神經元相連。這個神經元會刺激屈折變形「-s」所對應的神經元,進而刺激代表音素[z]的神經元。如果句子使用的是規則動詞,所有與後綴「-s」有關的計算就到此為止,例如「hit」的變化就是「hit+s」,「wug」的變化就是「wug+s」。至於詞干的發音,則可以依據心理詞典中的具體說明,通過相應的連接逐一複製到詞干神經元中,只不過我並未在圖中把這些連接畫出來。但是,如果碰到像「be」這樣的不規則動詞,整個計算過程就必須被阻斷,否則這個神經網絡就會產生出「be』s」這樣的錯誤形式,「三單現習」神經元也會向「is」(be的不規則形式)神經元發出信號。如果這個人一定要用動詞「be」,那麼代表「be」的神經元就會活躍起來,它也會向神經元「is」發出信號。由於和「is」相連的兩個輸入端是一個「與門」,所以只有當兩個輸入端同時打開時,「is」才會被激活。這就是說,當且僅當一個人想用「be」,同時又符合「三單現習」的條件時,「is」神經元才會被激活。「is」神經元通過一個「非門」抑制了「-s」變化,阻止了「ises」或「be』s」的產生,同時,它又分別激活了代表元音[i]和輔音[z]的神經元。當然,在描述過程中,我省略了大腦其他部分的許多神經元和神經連接。
這是我搭建的一個神經網絡模型,但它是專為英語設計的,而一個真正的大腦必須通過學習才能掌握所需知識。現在讓我們繼續展開聯想,將這個神經網絡想像成一個嬰兒的大腦,假設其中各組神經元都是與生俱來的。不過和圖9-3不同的是,每個神經元向外伸出的箭頭不只一個,而是有多個,這些箭頭將它與另一組神經元中的任何一個連接起來。也就是說,這個嬰兒天生就能「預料」到有與人稱、數量、時態和體有關的後綴的存在,以及可能存在的不規則動詞,但他並不清楚某一門特定語言的組合、後綴或者不規則動詞。然而,通過不斷強化箭頭指向的某些突觸(就像我在圖9-3所畫的那些箭頭),並忽視其他的突觸,嬰兒就可以學到相應的語法知識。這個學習過程可以描述如下:當嬰兒聽到某個單詞以[z]音作為後綴時,圖9-3右下角的[z]音神經元就被激活,同時,當嬰兒想到「三單現習」時,圖9-3左下角的4個相關神經元也被激活。如果這種刺激不但會向前傳導,也會向後傳導,而且如果每個突觸在被激活時都會得到強化,同時它的輸出神經也被激活,那麼所有將「第三人稱」「單數」「現在時」「習慣體」連接起來的突觸都會得到強化,而[z]音神經元也會得到強化。如果這個經驗重複多次,嬰兒的神經網絡就會逐漸發展為成人模式,就像圖9-3所畫的一樣。
讓我們把畫面再拉近一些。神經元和它們之間的潛在連接到底是如何鋪設的呢?這是當今神經科學界的研究熱點,而且我們已經對大腦的串聯方式有了一些瞭解,當然,這裡指的不是人類的語言區,而是果蠅的眼球、雪貂的丘腦,以及貓和猴子的視覺皮質。在出生時,神經元就已經在腦室的周壁排列妥當(腦室位於大腦半球的中心,是一個充滿液體的空腔),它們一個個整裝待發,即將奔赴大腦的不同區域。接下來,這些神經元開始沿著由膠質細胞構成的索道向外延伸(腦質細胞是一種支持細胞,它和神經元一起,構成了大腦的主體部分),它們朝著腦殼的方向前進,一直延伸到它們在大腦皮質的棲息地。大腦皮質不同區域的神經元之所以會形成連接,常常是因為目標區域所釋放的某種化學物質。一旦「嗅到」這種化學物質的氣味,神經元的軸突就會循著氣味的方向生長開來,而且氣味越濃,它就越往那裡去,就像植物的根部會被水分和肥料吸引一樣。軸突也對膠質細胞表面的某些特殊分子十分敏感,這些分子可以引導軸突的延伸方向,就像格林童話《糖果屋》(Hansel and Gretel)裡面的漢斯和格萊泰跟隨麵包屑的指引一樣。一旦軸突抵達目標區附近,就會生出更為精細的突觸連接,因為延伸而來的軸突與目標神經元表面的某些分子可以嚴絲合縫地對接,就像鑰匙和鎖頭一樣。當然,最初的連接常常是非常隨意的,因為神經元總是迫不及待地伸出軸突,而這可能會把它導向各種不合適的目標區。這些連接會相繼死亡,這可能是因為目標區無法提供必要的化學物質供其存活,也可能是因為當胚胎大腦正式啟動之後,這些連接沒有得到足夠的使用。
請隨我繼續神經奧秘的探索之旅,我們已經離「語法基因」不遠了。對神經元起著引導、連接和保護作用的分子叫蛋白質,蛋白質又受基因的指導。所謂基因,就是染色體內部DNA的鹼基序列。啟動基因的是「轉錄因子」和其他調節分子,這些配件依附於DNA鹼基序列的某個位置,並解壓一個鄰近區段,使得這個基因轉錄為RNA,然後再翻譯成蛋白質。一般情況下,這些調節因子本身就是蛋白質,因此生物體的建構過程就是一個錯綜複雜的連鎖反應:DNA製造蛋白質,其中一些蛋白質又與其他DNA相互作用,產生更多的蛋白質。某一蛋白質在製造時間或製造數量上的微小差異,都會對生物體的建構產生重大影響。
可見,單個基因很少對生物體的某一具體部件做出規定。相反,它指導的是蛋白質的釋放。這些蛋白質是構成某種複雜配方的原料,能夠對各類部件的塑造產生特定的作用,而這些部件同時又受到其他基因的影響。特別是大腦的連接回路,它與負責神經布線的基因有著非常複雜的關係。一個表面分子也許並不是用在某個單一的回路之中,而是為許多回路所共用,每個回路都是依據特定方式組合而成的。舉例而言,假設細胞膜上有X、Y、Z三種蛋白質,某個軸突可能會連接到X、Y所在的表面上,而另一個軸突則可能連接到Y、Z所在的表面上。神經學家估計,用來構建大腦和神經系統的基因大約有3萬個,這佔到人類基因組的絕大部分。
而這一切都源自一個細胞,即受精卵。受精卵中包含了兩個染色體的副本,其中一個來自母親,另一個來自父親。每個染色體都是在父母的生殖腺中,通過隨機拼接的方式,將源自祖父母(外祖父母)的部分染色體組合而成的。
現在我們已經可以給語法基因下一個定義了:語法基因就是DNA的一個區段,它可以在特定的時間、特定的大腦部位為蛋白質的合成指定遺傳密碼,或者啟動蛋白質的轉錄,從而指導、吸引或者黏合神經元構成一個網絡。這個網絡與經過學習而不斷強化的突觸相互配合,成為解決語法問題(例如選擇詞綴或單詞)必不可少的計算工具。
那麼語法基因是真實存在的嗎?或許它只是一個繞來繞去的說法而已?布萊恩·達菲(Brian Duffy)在1990年創作了一幅漫畫。一頭直立行走的豬問農夫:「今天的晚餐是什麼?不會是我吧?」農夫轉頭對朋友說道:「這就是那頭移植了人類基因的豬。」然而,這個場景是否真的會發生呢?
目前,我們還無法直接驗證人類身上的語法基因。但是,與生物學上的許多案例一樣,如果某個基因與特定的個體差異(通常為病理差異)形成了對應關係,我們就能很容易地將其識別出來。
我們確切地知道,在精子和卵子中存在著某種物質,它會影響胎兒日後的語言能力,例如口吃、難語症(一種閱讀障礙,患者往往無法在心中將音節拆分為音素),特定型語言障礙也具有家族性特點。當然,家族性並不一定代表著遺傳性(比如飲食口味和資產財富也同樣具有家族性特點),但上述三種病症卻很可能與遺傳有關,因為我們找不出任何環境因素來合理地解釋為什麼家族中有的人會患病,而有的人卻完全正常。而且,同卵雙胞胎的共同發病率要遠遠高於異卵雙胞胎,前者擁有相同的生長環境和完全相同的DNA,後者也擁有相同的生長環境,但只有一半的DNA相同。例如,一對4歲大的同卵雙胞胎讀錯同一個單詞的概率要高於異卵雙胞胎。此外,如果一個孩子患有特定型語言障礙,他的同卵雙胞胎兄弟患上此種疾病的可能性高達80%;但如果是異卵雙胞胎,可能性則只有35%。那麼,從小就被收養的孩子在語言能力上是否與自己的親生父母更為相似呢?這是一個有趣的問題,因為他們身上有著父母的DNA,卻與父母不在一起生活。我還沒有見到有關特定型語言障礙或難語症的收養研究,但根據一項研究結果顯示,嬰兒出生一年之內的語言能力(如詞語量、口頭模仿、詞語搭配、含混表達以及單詞理解等)與其生母的一般認知能力和記憶力有關,而與養父母無關。
英國的K氏家庭接連三代都出現特定型語言障礙,它的某些家族成員只能說出「Carol is cry in the church」這樣的病句,或者不知該如何處理「wug」的複數形式。到目前為止,這個家族是最能表明語法障礙具有遺傳性的活證據,即語法能力的缺陷與「單基因常染色體顯性遺傳」有關。這個引起廣泛關注的觀點是以孟德爾的遺傳定律為依據的,我們找不到合理的環境因素來解釋為什麼家族中的某些成員會患上此種疾病,而同齡的其他成員卻不受影響。例如,這個家族中有一對異卵雙胞胎,其中一個是患者,另一個卻完全正常。而且,這個家族中有53%的人患有此種疾病,而全社會的患病率大約只有3%。當然,從理論上說,你也可以認為是這個家族運氣不好,因為他們畢竟不是從總人口中隨機抽取出來的,而是因為高發病率才受到遺傳學家的關注,但這種辯解顯然是吹毛求疵。之所以說這種疾病是由單一基因造成的,是因為如果它涉及幾個基因,而且每個基因都對語言能力具有某種程度的影響的話,那麼家族成員的語法障礙應該會有輕重、緩急之別,因為他們所繼承的有害基因肯定有多有少。但是這個家族的語法障礙表現出「全有或全無」的特點。無論是學校的人還是家裡人,大家對誰存在缺陷、誰一切正常有一致的看法。而且在高普尼克的大多數測試中,家族患病成員的分數全都集中在量表的最低端,而正常成員的分數則集中在最高端,二者沒有重疊的部分。那為什麼說這個基因是位於常染色體(而非X染色體)之上,而且屬於顯性基因呢?這是因為在這個家族中,男性和女性的發病率是一樣的。而且,在所有病例中,患者的父母之中都有一方是正常人。如果這個基因是常染色體隱性基因,那麼只有在父母雙方都患病的情況下,孩子才會發病。如果它是X染色體隱性基因,那麼只有男性才會發病,女性只是攜帶者。如果它是X染色體顯性基因,那麼患病的父親會將它傳給女兒,而不會傳給兒子,因為兒子的X染色體來自母親,而女兒則有兩條X染色體,一條來自母親,一條來自父親。但在這個家族中,有一位父親雖然患病,但他的一個女兒卻是正常的。
但是,與美聯社、基爾帕特裡克的說法正好相反,這個單一基因並不是負責整個語法回路的運行。我們前面說過,雖然一台複雜的機器需要許多部件才能正常運行,但只要一個部件出現問題,整個機器都可能癱瘓。事實上,也許這個基因根本沒有參與語法回路的構建,只不過當它存在缺陷時,會製造出一種特殊的蛋白質,這種蛋白質會對某種化學過程產生阻礙作用,而這種化學過程恰巧是構建語法回路的必要條件。也許這個基因會導致大腦的某個區域過度生長,以至越過自己的領地,擠掉預留給語言的地盤。
不過,這個發現仍然值得關注。在K氏家族中,大部分語言受損的成員在智力上都處於中等水平,而在其他家族中,有些患者的智力還更高一些。高普尼克曾經研究過一個男孩,他的數學成績在班上數一數二。因此,這種特定型語言障礙表明,在大腦發育過程中,一定存在某種受基因指導的生理活動,它專門負責搭建語言計算的神經回路,當這種生理活動遭到破壞時,就會引起語言障礙。這一生理活動影響的範圍很廣,不僅包括語音的發音區和聽覺區,還牽涉語法處理所必需的神經機制。雖然語言受損的家庭成員在兒時都會出現發音問題,學會說話的時間也比正常人晚,但他們最終能夠擺脫語音的問題,但語法問題卻會相伴終生。例如,這個家族中的患者雖然常常漏掉後綴「-ed」或「-s」,但這並不是因為他們無法聽懂或發出這個音,他們完全可以區分「car」和「card」,也從來不會將「nose」讀成「no」。換句話說,他們是將一個單詞的固定部分和根據語法而添加的部分區別對待,即便這兩個部分擁有相同的發音。
同樣有趣的是,這種語言障礙並不會摧毀全部的語法能力,也不會對語法的所有部分產生同等的影響。雖然語言受損的家族成員在變化時態、添加後綴等問題上存在困難,但他們並非不可救藥,而只是比家族中的其他人更差一些而已。他們最常出現的毛病主要集中在詞法和詞形變化上,例如時態、人稱和數量,其他方面則很少受到影響。舉例而言,患者能夠發現動詞短語的錯誤,比如說「The nice girl gives」或「The girl eats a cookie to the boy」,他們也能聽懂複雜的句子,並根據句子內容進行表演。我們已經知道基因是如何工作的,因此,如果單個基因與某種特定功能之間不存在對應關係,我們也不會感到奇怪。
到目前為止,我們已經找到了語法基因存在的間接證據,因為有些基因似乎會對處理語法的神經回路產生特定的影響。我們還不知道這個基因位於染色體的哪個位置,也不知道它會對大腦結構產生怎樣的影響。不過,研究者已經開始對這個家族進行血液抽樣,準備進行專門的遺傳分析。此外,有人對另一些特定型語言障礙患者的大腦進行了掃瞄,結果發現,患者大腦的外側裂周區缺乏正常人的不對稱性。其他一些學者則開始對患者的語法能力和家族史進行更為仔細的檢查,其中一些人覺得高普尼克的觀點令人振奮,另一些人則將信將疑。他們試圖弄清特定型語言障礙的遺傳普遍性,以及這種疾病到底會引發哪些不同的症狀。不出意外的話,你將在未來幾年裡看到不少來自神經學和遺傳學的有趣發現。