
數據正在呈指數級增長。之所以增長速度如此之快,背後有許多原因。現在幾乎所有數據的產生形式,都是數字化的。各種傳感器的劇增,高清晰度的圖像和視頻,都是數據爆炸的原因。
如何收集、管理和分析數據正在日漸成為我們網絡信息技術研究的重中之重。以機器學習01、數據挖掘為基礎的高級數據分析技術,將促進從數據到知識的轉化、從知識到行動的跨越。
聯邦政府的每一個機構和部門,都需要制定一個應對「大數據」(Big Data)的戰略。02
——《規劃數字化的未來:美國總統科學技術顧問委員會給總統和國會的報告》2010年
如果說《信息自由法》在法律的層面上規定了政府機關的文件可以公開,其後的《陽光政府法》規定政府機關的會議必須公開,《電子信息自由法》又規定了計算機內的數據也不能例外,那麼奧巴馬繼續開拓的空間似乎已經不大了。
他所謂的「要建設一個前所未有的開放政府」,究竟指的是什麼呢?
奧巴馬是哈佛大學法學院的高才生,他在就讀期間,就擔任了久負盛名的《哈佛法律評論》的主編;博士畢業之後,曾在律師行從業多年,還長期在哥倫比亞大學講授《憲法學》。嚴謹的科班訓練加上律師實務生涯,他的邏輯思維是非常嚴密的。
他用「前所未有」(unprecedented)來形容他將要開創的事業,是因為,他清楚地知道:透明無止盡。對政府而言,只有更透明,沒有最透明。雖然聯邦政府的文件、會議甚至數據都規定了可以公開,但近年來信息技術突飛猛進的發展,特別是互聯網的興起,不僅給信息公開的內容、也給公開的方式帶來了新的機遇和挑戰。
這是個技術奔騰、信息爆炸的時代。奧巴馬領導的聯邦政府,正是美國社會的信息中樞。他的雄心,有廣袤的用武空間。
摩爾定律:全世界半個世紀的發展規律
摩爾定律已經成為工業界一切呈指數型增長事物的代名詞。……下一個十年,摩爾定律可能還將有效……可以肯定的是,創新無止境。03
——戈登·摩爾,英特爾公司創始人,2003年
聯邦政府是美國最大的僱主,共僱用了約200萬名工作人員。04
聯邦政府主要由三大塊組成:一是總統行政辦公室(The Executive Office of the President),二是15個內閣部門(Cabinet Department),三是70多個獨立的聯邦機構(Independent Agency)。
總統行政辦公室的結構
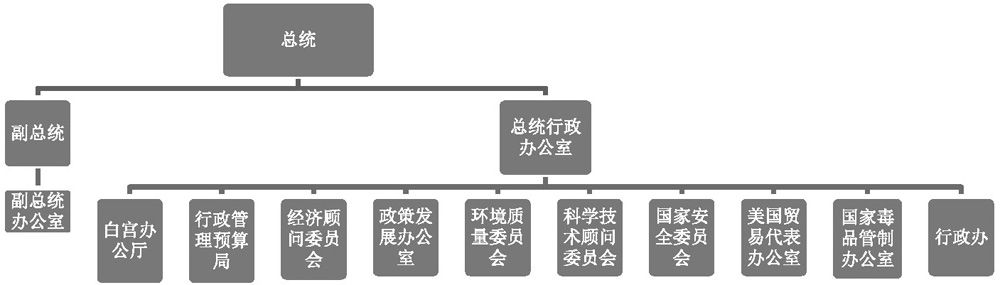
總統行政辦公室是直接為總統服務的中樞部門。
其下轄白宮辦公廳(The White House Office)、行政管理預算局(OMB)、經濟顧問委員會(Council of Economic Advisers)、科學技術顧問委員會(PCAST)等機構。其中,最重要、最大的機構當屬白宮辦公廳和行政管理預算局,它們控制了信息、掌握了財權,是15個內閣部門和70多個獨立機構的管理和協調單位,可謂中樞中的中樞。鑒於這兩個機構的重要性,本書將會多次提及。
作為全美最龐大的組織和機構,聯邦政府也一直號稱他們是美國最大的信息生產、收集、使用和發佈的單位。05
數據和信息的區別
很多情況下,「數據」和「信息」兩個詞經常替換使用。但嚴格地說,數據和信息這兩個概念有很大的區別:
數據是對信息數字化的記錄,其本身並無意義;信息是指把數據放置到一定的背景下,對數字進行解釋、賦予意義。
例如:「1.85」是個數據,「奧巴馬身高1.85米」則是一則信息。
但進入信息時代之後,人們趨向把所有存儲在計算機上的信息,無論是數字還是音樂、視頻,都統稱為數據。
如果要考察信息的多少,就必須以物理存儲器上保存的數據量作為度量。因為所有的信息,都是以數據的形式保存在物理存儲器上的。由於人類的數據量不斷增多,近幾十年來,科學家也相應定義了一些新的名詞,來表示新的存儲單位,以方便對客觀世界的描述。
美國聯邦政府到底收集了多少數據,其總量無從得知,但我們可以從現有的一些研究資料中窺見一斑。
理解數據的存儲單位
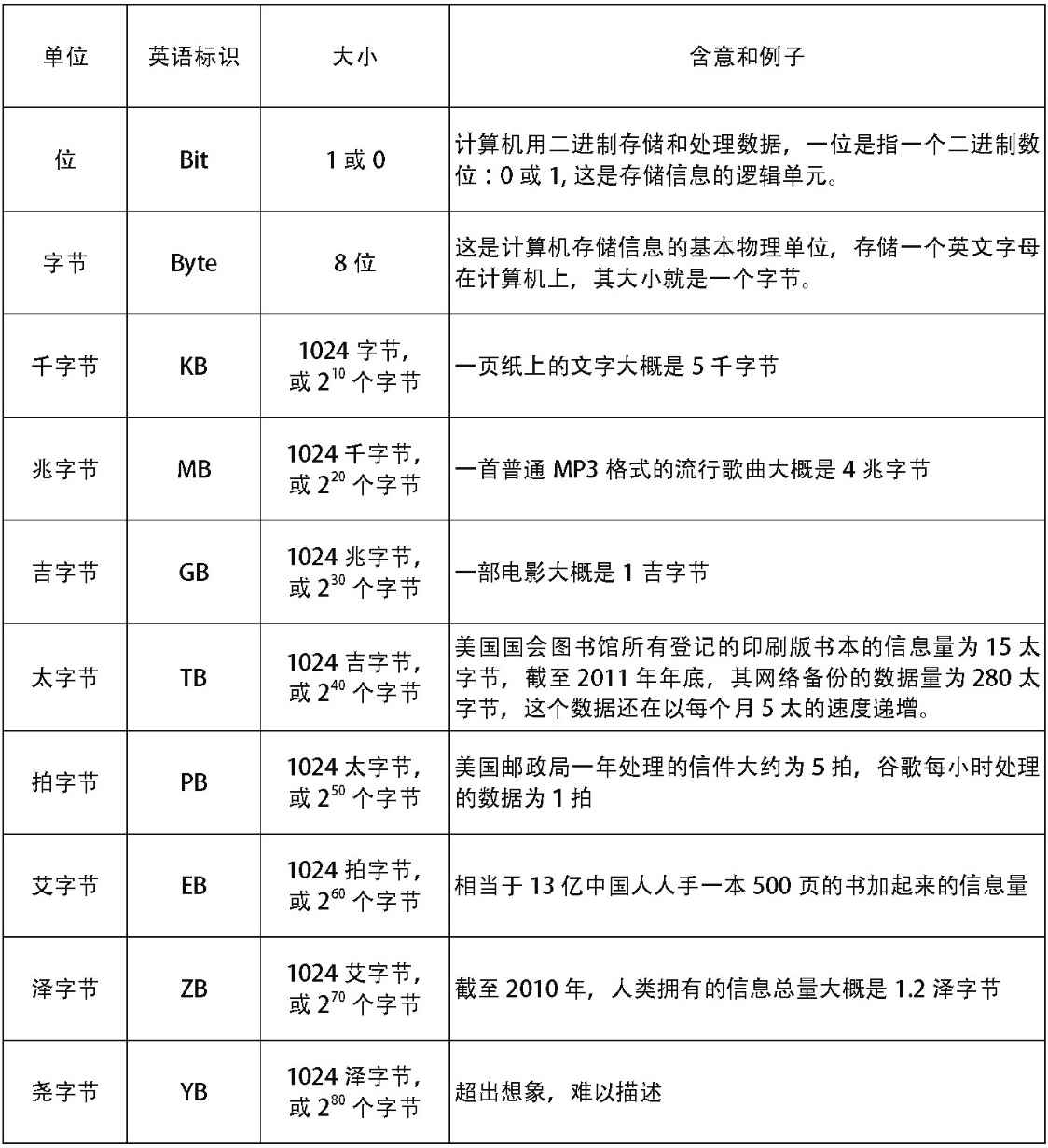
(部分例子參照了All too much,The Economist,2010年2月25日)
2009年美國各行業數據存儲量對比
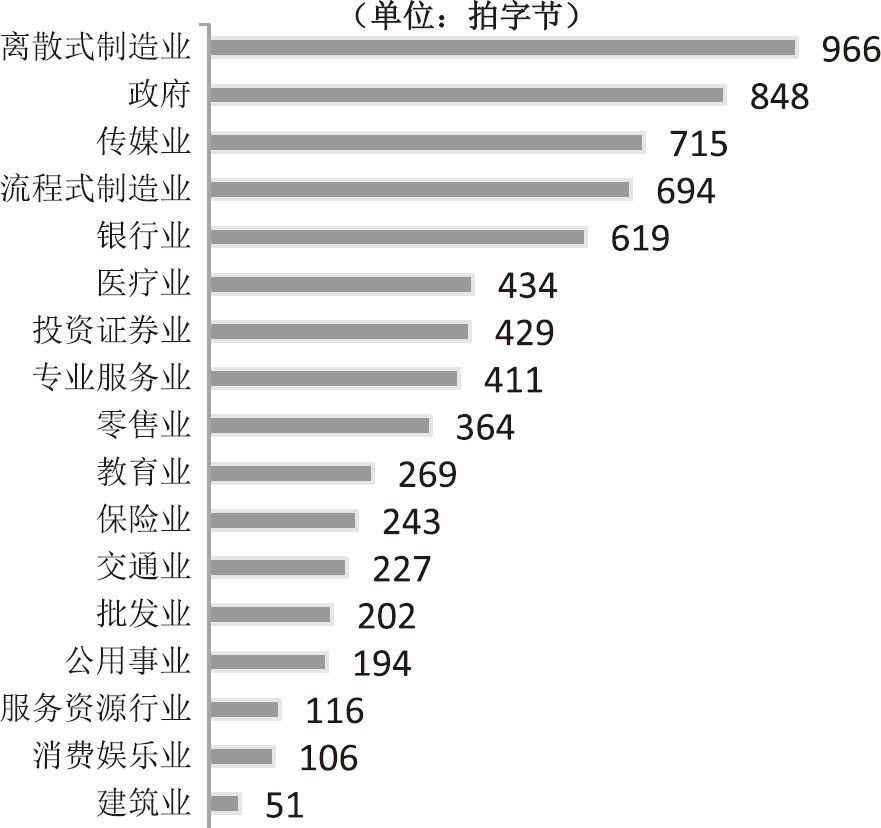
(數據來源:International Data Corporation)
2011年5月,麥肯錫公司下屬的全球研究所(McKinsey Global Institute)出版了一份專門的研究報告《大數據:下一個創新、競爭和生產率的前沿》。06該報告對美國政府目前擁有的數據量進行了估算,在製造業、新聞業、銀行業、零售業等17個行業當中,美國政府共擁有848拍字節(Petabyte)的數據總量,僅次於離散式製造業07的966拍,居第二位;居第三位的是新聞傳媒業,共有715拍字節。
這是美國政府作為一個行業的總體情況,下面我們來考察聯邦政府中具體的單個組織。
以商務部下屬的美國普查局(USCB)為例,它目前擁有2560太字節(Terabyte)的數據。「太」,代表2的40次方,它的大小,已經大大超出了人類的直接感知能力,只能通過形象的比喻來描述:如果把這些數據全部打印出來,用4個門的文件櫃來裝,需要5000萬個才能裝得下。沃爾瑪是世界上最大的零售王國,它每小時要處理100多萬筆電子交易記錄,可謂每分每秒都在源源不斷地生產數據;2010年,其數據庫大小為2500太字節左右,還沒有趕上美國普查局。
除了美國普查局,國家安全局(NSA)和中央情報局(CIA)都擁有超級巨大的數據庫。2011年5月,歷經十年,美國人終於在巴基斯坦將本·拉登擊斃,報了「9·11」的一箭之仇。帕拉契尼(John Parachini)是蘭德(Rand)公司情報政策研究中心的主任,他在接受《巴爾的摩太陽報》的採訪時介紹說,國家安全局是從電話監控的記錄當中發現了本·拉登的蛛絲馬跡。08該局對全美的電話進行監控,所收集的數據量是驚人的,它每6小時產生的數據量就相當於美國國會圖書館所有印刷體藏書的信息總量。而美國國會圖書館,是世界上館藏量最大的圖書館。
再說中情局,其本職工作就是收集情報信息。業內專家普遍認為,其數據庫比普查局、國安局的還要大,很可能擁有全世界最大的數據庫。
普查局、國安局、中情局只是聯邦政府數百個機構當中的幾個例子,還有財政部、衛生部、勞工部,這些都是數據密集型的行政管理部門。即以財政部為例,根據行政管理預算局的信息收集年度報告,2009年,財政部因為收集信息產生的社會負擔為76億小時,佔全部聯邦政府收集信息社會負擔總數的78%,09之所以如此,是因為收稅和退稅的過程極為繁瑣,但76億小時收集工作會產生多少數據量,其大小也難以想像。
再換一個角度,我們來看看這個聯邦政府的硬件資產。
1998年,聯邦政府共擁有432所數據中心,專門負責各類數據的存儲和維護工作。2010年,數據中心的總數躍升到2094所,翻了幾倍。
龐大的數據資產,是需要經費來支持的。1996年,聯邦政府的年度IT預算是180億美元,十多年來不斷地上升,2010年,已經高達784億美元;由於連年巨額的投資,聯邦政府已經聲稱,他們是全世界範圍之內最大的信息技術消費者。而據報道,這些投資中的一半以上,都用在了購買存儲數據的硬件設備上。
這是一個不折不扣的數據帝國。
帝國形成的原因,已經有很好的解釋,這就是摩爾定律(Moore's Law)。
1965年,英特爾(Intel)的創始人之一戈登·摩爾(Gordon Moore)考察了計算機硬件的發展規律,提出了著名的摩爾定律。該定律認為,同一個面積集成電路上可容納的晶體管數目,一到兩年將增加一倍,10也就是說,其性能將提升一倍。換句話說,計算機硬件的處理速度和存儲能力,一到兩年將提升一倍。
1971年至2011年不同中央處理器上的晶體管數量和摩爾定律
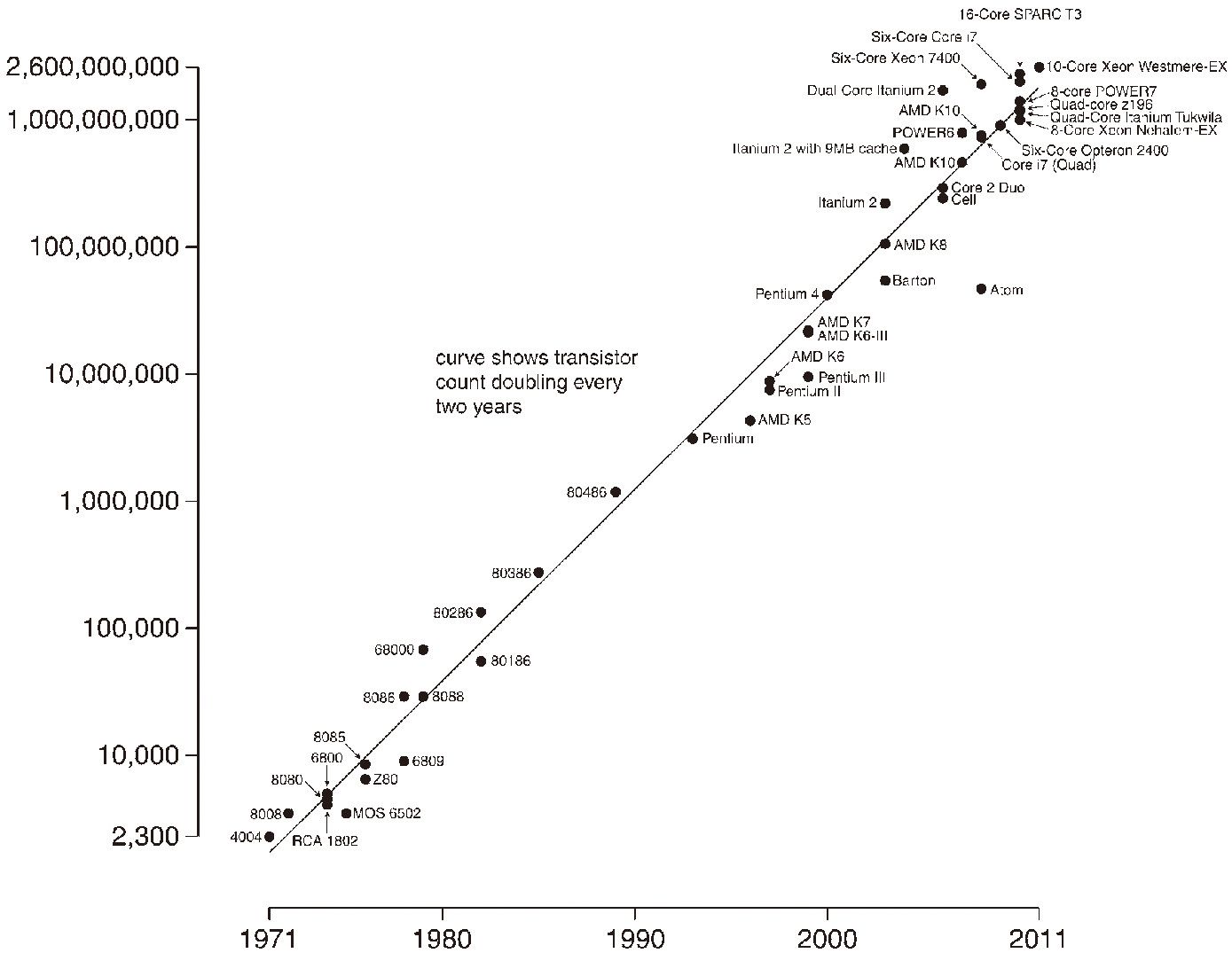
說明:縱坐標為晶體管數量,橫坐標為年份。圖中圓點表示不同品牌的中央處理器。該曲線表明,從1971年至2011年,大概每兩年同一面積大小中央處理器集成電路上的晶體管就增加了一倍。(圖表來源:維基百科)
回顧這近半個世紀的歷史,硬件技術的發展,基本符合摩爾定律。摩爾定律的一個重要結果,是推動了全世界對物理存儲器的消費;其消費量增加的速度,有學者認為,甚至比摩爾總結的硬件發展速度還要快,從1990年代起,全世界的物理存儲器,每9個月就增加一倍。11

戈登·摩爾
出生於1929年,至今健在,他於1956獲得加州理工學院的博士,1968年成為英特爾的創始人之一,也是摩爾定律的首創人。(圖片來源:英特爾公司網頁)
其中的原因,是因為物理存儲器的性能不斷提高,同時價格還不斷下降。1955年,IBM推出了第一款商用硬盤存儲器,每兆字節的存儲量需要6000多美元。此後,硬盤存儲器的價格以越來越大的加速度下降。1993年,購買1兆字節的存儲量只需大概1美元;2010年,這個價格下降到不足1美分。多數專家都相信,計算機硬件的技術將持續發展,價格還將下跌,直到2020年,摩爾定律還將仍然有效。
計算機硬件這種令人「瞠目結舌」的發展速度,使全世界的數據處理和存儲不僅越來越快、越來越方便,還越來越便宜,海量數據的積累最終成為可能。
但像盛水的杯子一樣,存儲器畢竟只是容器。關鍵的問題在於,帝國的數據從何而來?海量數據的源頭在哪裡?
美國聯邦政府的數據來源,當然首先緣於它各個部門的業務工作,也就是業務數據。
作為社會管理和公共服務的提供部門,收集數據、使用數據,是自古以來全世界的政府都在普遍採用的做法。但政府開始大規模、系統地收集數據,其歷史並不久遠。在美國聯邦政府的發展歷史上,業務數據的收集,有一個重要的里程碑,這就是「最小數據集」。
最小數據集:上升到立法高度的開路先鋒
一個好的數據結構和一個糟糕的代碼,比一個糟糕的數據結構和好的代碼要強多了。12
——埃裡克·雷蒙
美國軟件開源運動的領導者,1999年
最小數據集的概念起源於美國的醫療領域。
1973年,在國家生命健康統計委員會(NCVHS)的主導下,為了規範出院病人的信息收集工作,美國第一次制定了統一的出院病人最小數據集,既然是出院,核心的環節就是付錢,所以這些數據不久後又被用於創建統一的醫療賬單(Uniform Bill,UB)。
1975年,美國醫院協會(AHA)成立了國家統一賬單委員會。經過了幾年的討論,1982年,該委員會出台了UB-82的數據格式,統一了全國的醫療賬單格式。1992年,UB-82又被修改升級到UB-92,並被擴大應用到了醫療保險和索賠的領域。
由於其實用性,最小數據集的概念在醫療領域被迅速推廣。近幾十年以來,幾乎每年都有新的最小數據集被定義、開發和推廣。目前,已經被應用到眼科、牙科、皮膚科、婦科以及體檢、護理、急救、住院等醫療服務的方方面面,衍生出各種各樣的、特定的最小數據集。
隨著時間的推移,「最小數據集」在美國已經演變成了一個一般性的概念,它指代國家的管理層面針對某個業務管理領域強制收集的數據指標。不少領域的「最小數據集」甚至被上升到立法的高度。例如,對於養老院的管理,美國國會就規定,每個養老院都必須提交一系列關於老人健康指標的最小數據集給州政府的醫療管理部門,該部門匯總之後,再提交聯邦政府的管理部門。
當然,何為「最小」,政府的管理者、決策者和公共服務的提供方、接受方都有不同的需求和看法,很難達成一致。某一特定的數據指標是否應該納入,不同的立場、視角、環境和管理水平都會導致不同的意見。而且,各個最小數據集本身可能是完整的、有效的,但當各行各業的最小數據集越來越多之後,從全局出發,它卻不一定是合理的,因為可能存在更好的劃分方法,使各個最小數據集之間具有更明確的邊界和更少的重疊。
最小數據集(Minimum Data Set, MDS)
最小數據集是指通過收集最少的數據,最好地掌握一個研究對像所具有的特點或一件事情、一份工作所處的狀態,其核心是針對被觀察的對象建立一套精簡實用的數據指標。
因此,每一個「最小數據集」的出台,都意味著多年的紛爭和詳盡的論證。
最小數據集的出現,最早是因為不同組織之間信息交換的需要,例如,兩個醫院之間,醫院和政府醫療管理部門,醫院和保險公司之間以及一些社會福利部門之間,都有交換信息的需要。隨著最小數據集的推廣,越來越多的社會組織、地方政府和聯邦政府的業務部門之間都建立了標準的「數據接口」,從此彼此「數據」相連。
但到了1980年代,一場新的技術浪潮又把最小數據集的應用推上了新的高點。
這就是信息管理系統的興起。
1975年,比爾·蓋茨創辦了微軟。次年,史蒂夫·喬布斯成立了蘋果電腦公司。之後,個人電腦、商業軟件開始得到大面積普及,開發新的信息管理系統開始成為各行各業邁向信息化的主要措施。
所謂的「信息管理系統」,也就是實現某一特定業務管理功能的軟件。
軟件的構成,主要有兩部分,一是程序(也可稱為代碼),二是數據(或稱為數據庫)。程序和數據的關係,就好像發動機和燃料,所有的程序,都是靠數據驅動的;數據之於程序,又好比血液之於人體,一旦血液停止流動,人就失去了生命,代碼也將停止運行。
數據的生命力,甚至比程序更持久。程序可以不停地升級、換代甚至退出使用,但保存數據的數據庫卻會繼續存在,其價值很可能與日俱增、歷久彌新。世界萬維網之父蒂姆·伯納斯-李,曾經在2006年這樣論述說:
「數據是寶貴的,它的生命力,比收集它的軟件系統還要持久。」13
對於軟件開發而言,數據庫的設計甚至比程序的設計還要重要。埃裡克·雷蒙,是美國軟件開源運動的領袖,他在談到代碼和數據時曾表示:
「一個好的數據結構和一個糟糕的代碼,比一個糟糕的數據結構和好的代碼要強多了。」
最小數據集,其實就是一個業務管理過程當中最重要的數據指標。它在各個公共領域的定義和推廣,成了這些部門在開發設計信息管理系統時最重要的一個參考,因為一旦核心的數據收集指標被確定,數據庫的結構設計就成為一個水到渠成的過程。有些最小數據集,甚至直接就被引用,成為信息管理系統的數據結構。
就好像開路先鋒,最小數據集為信息管理系統的開發和設計起了重要的鋪墊作用。1970年代以來,隨著計算機的普及,美國產生了越來越多的最小數據集,各種信息管理系統也開始大幅增加。截至2011年,美國的聯邦政府已經擁有1萬多個獨立的信息管理系統。14
幾乎每一項業務,每一個新的立法、新的計劃,都會有一個數據庫和信息管理系統與之對應。因為,沒有任何一項工作,不涉及收集信息,而這些都離不開數據。
如今,聯邦政府可謂事無鉅細,都有一個信息系統在管理,其背後的數據庫可謂五花八門,多不勝舉。
例如,美國現在債台高築、不斷衝擊上限,聯邦政府甚至一度產生財務危機,奧巴馬也為此頭痛不已。聯邦政府財政部下屬的公共債務局(BPD)是國家債務的主管部門,要追蹤這樣一筆龐大國債的來龍去脈,該局自然擁有不少信息管理系統,其中,有一個是專門用來記錄「捐款」的。
「欠債」和「捐款」,聽起來似乎風馬牛不相及。但在美國,兩者還是拉上了關係,這是因為有些美國人試圖通過自己的捐助來緩解國家的財政負擔。公共債務局就為此專門建了一個信息系統,來記錄美國公民為減少國債作出的個人捐贈。數據表明,2010財政年度,該局共收到2840466.75美元的捐款,2009年的捐款曾突破300萬元,為3063057.05美元。捐款數量的下降,表明了人們的可支配收入在減少,也從另外一個側面證明了美國經濟確實在衰退。
歷史上最大的一筆個人捐贈來自於2006年,一位俄亥俄州的老人在去世之後將自己價值110萬美元的財產捐贈給了聯邦政府公共債務局。當然,這些捐款,對於美國14.6萬億的債務來說,只是杯水車薪。但系統的管理,不僅筆筆在案、賬目清晰,便於統計分析,也體現了對捐贈者的尊重。
民意幾時有:選票催生的創新
我想要成就的事情,就是我的人民想要做的事情;我的任務,就是要準確地發現人民的需要。15
——亞伯拉罕·林肯,第16任美國總統
一般來說,業務數據都由下級部門和各類社會組織通過「數據接口」上報給聯邦政府。
但作為一個中央政府,只接受數據是遠遠不夠的,聯邦政府也需要走出去,主動收集數據,瞭解全社會對某項政策的評價、單個公民對某個問題的看法,這就是所謂的民意調查、社會調查。
民意調查(Public Opinion Poll)
民意調查是指通過對一小群、有代表性人口的調查和訪談,預測社會全體公眾對一些政治、經濟和社會問題的態度和看法。其本質是「觀一斑而知全豹」、「觀一葉而知秋」。
美國的各種調查(Survey)之多,可謂鋪天蓋地,這些調查的直接目的,就是收集、掌握、分析反映民意和社情的第一手數據。

1948年,喬治·蓋洛普登上《時代》雜誌的封面。
這一年,杜威和杜魯門競選總統,蓋洛普預測杜威將勝出。開票結果出來的當晚,《紐約時報》、《生活》、《芝加哥論壇報》等報刊都印刷好了杜威的照片,並題為「美國新總統」,但最終杜魯門勝出。這次預測失敗,又引起了人們對民意調查的質疑。蓋洛普總結原因說:因為兩人的民調一直相差太大,他們在大選前3周就提前結束了調查。此後,蓋洛普持續改進調查的方法,最終在美國乃至在全世界都贏得了巨大的聲譽。現在,蓋洛普的品牌已經成為民意調查的代名詞。
美國的民意調查最早源於對總統大選投票結果的預測。
1824年,位於賓夕法尼亞州的一家報紙Harrisburg Pennsylvanian第一次發佈了關於誰能當選總統的預測。雖然其預測最後被證明是錯誤的,但卻被大眾一再津津樂道。
此後,各大報紙雜誌都不想錯過這個「搶眼球、聚人氣」的話題,爭相開展民意調查,以期準確地預測到底誰能當選總統,這開啟了民意調查的時代。
蜂擁而上的結果,就是競爭。競爭的結果,就是民意調查的科學性不斷提高,範圍不斷擴大;在20世紀30年代的美國,最終形成了一個社會調查的產業。
其中的轉折點,是1936年。
這一年,第32任美國總統富蘭克林·羅斯福為了爭取連任,與共和黨的蘭登(Alfred Landon)對壘,打響了選戰。
這時候,一本叫做《文學文摘》(Literary Digest)的雜誌風頭正勁。
《文學文摘》成立於1890年,其暢銷的主要原因,是因為它準確地預測了1920、1924、1928、1932年等4屆總統大選的結果,隨著該雜誌銷售量的年年攀升,民意調查的熱度和可信度也不斷上升。
1936年,《文學文摘》在對240萬普通公眾進行了調查之後,把「寶」壓在了蘭登的身上。這個時候,一家剛剛成立不久的研究所,只對5000人進行了調查,卻宣佈羅斯福會勝出。
這家研究所就是1935年成立的美國輿論研究所(AIPO),它的奠基人,是美國民意調查科學化的先驅:喬治·蓋洛普(George Gallup)。
羅斯福最終以大比分擊敗蘭登,成功連任;蓋洛普也取代了《文學文摘》,成了新的行業領袖。這一仗,成了《文學文摘》的「滑鐵盧」,該雜誌次年就宣佈破產、退出市場。5000人的問卷擊敗了240萬人的調查,蓋洛普領導的美國輿論研究所當然隨之身價倍增、名揚全國。
蓋洛普的成功,根本原因在於他掌握了一套科學的人群抽樣方法,而不是盲目的大面積訪談。此後,一大批新的、專業化的民意調查機構應運而生,調查方法的科學性不斷增強。從1936年到2008年,共舉行了18次總統選舉,蓋洛普民調(Gallup)成功地預測了16次。16
報紙舉辦民意調查,其目的是為了一「鳴」驚人,製造新聞效應,擴大報紙的聲譽和銷量。但對總統候選人來說,他們也要參考民意調查的結果,因為他們對民意的掌握,往往關係到選舉的最終成敗。
這是因為,在民主社會,誰上誰下,人民的選票有最終的話語權。
票多,則勝。
作為候選人,爭取選票的唯一方法就是爭取民意。要爭取民意,首先就要瞭解民意。現代政治學中,有一個「中間選民理論」很好地解釋了其中的奧秘。
中間選民理論(Median Voter Theory)
該理論也是在1940年代提出的。在選舉中,所有的選民都有自己的個人偏好,這個偏好對應於平面坐標上的一點,全部選民的偏好將呈正態分佈,也就是一個鍾形曲線,這個曲線就是民意分佈圖。
每個選民最終都會把自己的選票投給與自己意見最接近的候選人。在多個候選人競爭的情況下,候選人想要勝出,就要爭取最多的選票,他就必須找準民意最集中的地方,為最多的民眾說話,這一點,就是民意的「中值」。
中間選民理論提出,民意有一個「中值」,而民意調查,正是幫助候選人找準民意「中值」的「阿拉丁神燈」。
羅斯福雖然在當選總統前就半身癱瘓,長期坐在輪椅上,但後世卻常常把他和華盛頓、林肯相提並論,公認為美國歷史上最偉大的總統之一。作為唯一一位連任過4屆的總統,他深諳民意調查的作用和潛力。他不僅在競選中應用民意調查,1940年,他還正式將民意調查的方法引進到了聯邦政府的政策制定過程當中,成為美國歷史上第一位將民意調查和公共政策相結合的總統。這些成就,使他成為美國歷屆總統當中至今無人超越的「民意大師」。
民意的「中值」和選票多少的關係
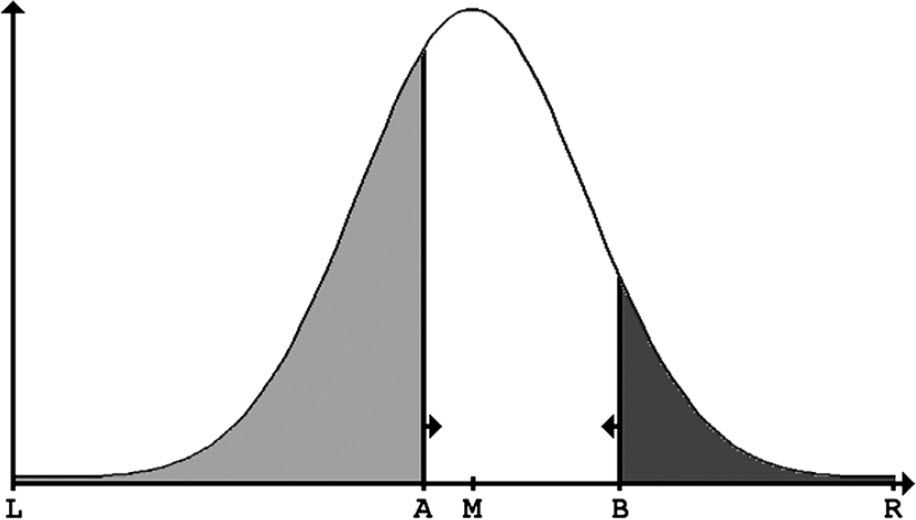
說明:圖中的鍾形曲線即代表民意的分佈,左邊淺色和右邊深色的區域面積大小,分別代表候選人A和候選人B可以預期得到的選票多少。M代表民意的中值點,候選人A和B,誰能確定M點,不斷向M點靠攏,誰就能獲得更多的選票。
上圖表明:候選人A比候選人B更接近民意的中值,將獲得更多的選票。
羅斯福之後,幾乎每一位美國總統,不論是競選還是執政,都大規模地採用民意調查的方法。
隨著計算機技術的不斷發展、統計分析水平的提高,民意調查逐漸成了聯邦政府瞭解社會、掌握民情最有效的工具和方法。調查的範圍也不斷擴大,從普通公民的觀點和看法,慢慢延伸到個人的行為、事實和社會現象,最後發展成了更廣泛意義上的社會調查。
到今天,可以說,聯邦政府的各個職能部門都在開展社會調查。其中,有兩個機構堪稱聯邦政府社會調查的「航空母艦」,它們每年開展無數大大小小的社會調查,其他機構都望塵莫及。這兩艘「航空母艦」,一是勞工部下轄的勞工統計局(BLS),一是商務部下屬的普查局(BC)。

富蘭克林·羅斯福(1882-1945)
羅斯福從1921年起下半身全部癱瘓,但這位殘疾人卻在1933年至1945年連續4次當選總統,帶領美國人走過了第二次世界大戰的艱難時段。對於民意,他強調:不僅要掌握民意,還要領先民意一小步,才是民主政治中的勝選之道。(圖片來源:維基百科)
勞工統計局對就業市場開展很多專業調查,其中最大的一種被稱為「國家縱向調查」(National Longitudinal Survey)。所謂「縱向」,是指以時間軸為單位,在確定調查對像之後,對其進行長期的跟蹤、反覆的問卷,收集大量的數據,然後進行統計分析。
1966年,勞工統計局開展了美國歷史上第一個國家縱向調查。調查對象是全國的男性,分為青年和老年兩組,該局在全國範圍內鎖定了10245名男性,進行了長達24年的全方位跟蹤調查,直到部分老人撒手歸西為止。類似的國家縱向調查項目一共有4個。1997年最新鋪開的一個,調查對象是1980年至1984年出生的青少年,簡稱為NLSY97(National Longitudinal Survey of Youth 1997),該局在全國範圍內確定了約9000名青少年,每年都進行一次特定話題的跟蹤問卷調查,至今還沒有結束。
以1997年的青少年縱向調查為例,它跟蹤調查的對象雖然是青少年本身,但受訪人、問卷人卻可以是家長、老師、僱主等等和該青少年密切相關的個人和群體,每次問卷都有數十個問題,需要受訪人1小時左右才能完成。因為付出了時間,受訪人在完成問卷之後,能獲得8到20美元不等的報酬。同樣的問題,也可能在不同的年份、在相同受訪人員的問卷中重複出現,以測試受訪人態度的變化。
NLSY97雖然是由勞工統計局負責實施,但卻是一個綜合項目,涉及青少年生活的方方面面,該局邀請了多個政府部門參與問卷的設計。例如,青少年犯罪預防辦公室(OJJDP)隸屬於美國司法部,是青少年犯罪問題的國家主管部門,他們幫助勞工統計局設計了有關青少年犯罪方面的問卷。就青少年犯罪而言,問題可能包括輕度違法記錄、毒品濫用情況、酗酒情況、性行為、家庭成員的構成及背景、收入、教育、家庭關係、和父母的關係、青春期情況、約會情況、戀愛情況、生育情況、職業培訓情況、接受社會福利項目的援助情況、個人時間管理、生活目標的變化、學習成績、宗教活動、所住社區的人口特點、所在城市的經濟特點,等等。
隨著數據的積累,一幅以個人成長為中心、越來越大的社會畫卷也開始展開。這種以一個國家為單位的大型社會調查,是研究一個社會長期變遷不可或缺的重要資源,也為政策的制定、調整和評價提供了重要的參考和依據。
另一艘「航母」是普查局。和勞工統計局相比,它的社會調查名目更多、範圍更廣。除了負責十年一次的人口普查之外,該局每年還在全國範圍之內開展系統的行業調查,其中最著名的有:全國社區調查、全國消費者開支調查、全國醫院調查、全國建築調查、全國房屋調查,等等。
除了掌握民情、瞭解社會,問卷調查還是聯邦政府評估資金使用績效的主要工具。聯邦政府每年都要下撥大量的專項資金,資金的使用效果和好壞,往往是來年是否繼續撥款的決定性因素,聯邦政府目前最重要的衡量手段,也是社會調查。
以衛生部下屬的藥物濫用和精神健康管理局(SAMHSA)為例,每年,該局都有專項基金,用於社區的毒品防治工作,全國的基層政府、公益組織都可以申請。但這筆錢也很「燙手」,拿了之後,有大量的問卷調查工作要開展、要上報。
社區的毒品防治工作主要是政策宣講和培訓。申領了專項資金的單位,就要開展培訓,每個參加培訓的人都要參加4次問卷調查,分別在培訓開始前一次、培訓中間一次、培訓結束時一次,三個月以後還有一次。這些問卷調查的數據,基本都是通過互聯網匯總上報。該局通過對比分析4次調查結果的具體指標,評估該單位的資金使用效果,再決定下期資金是否下撥。
聯邦政府的這些調查,雖然目的不同、性質不同、方式不同,但最後產生的結果,無一例外,都同樣是數據。
普適計算:計算機本身將從人們的視線中消失
最高深的技術是那些令人無法覺察的技術,這些技術不停地把它們自己編織進日常生活,直到你無從發現為止。17
——馬克·韋澤,普適計算之父,1991年
1988年,互聯網的概念剛剛興起。這種新的信息共享方式,令全世界都興奮不已。當時,絕大部分科學家,都還在品味和研究網絡帶來的巨大便利,沉浸在欣喜當中。
這時候,美國施樂公司(Xerox)的一名計算機科學家,卻開創性地提出了「普適計算」(Ubiquitous Computing)的理論,為網絡在人類未來生活中的作用以及計算方式的改變作出了前瞻性的預測。
他就是馬克·韋澤(Mark Weiser)。
韋澤是密歇根大學畢業的計算機博士,青年時代就表現出傑出的天才。他畢業之後,曾經在馬裡蘭大學任教8年,其後加入了施樂公司的帕羅奧多研究中心(PARC)。
帕羅奧多研究中心是全世界著名的創新中心,鼠標、激光打印機、以太網、語音壓縮技術等等偉大的發明都在這裡誕生。
韋澤領導了帕羅奧多研究中心計算機科學實驗室的發展,1996年又擔任了該中心的首席技術官。
韋澤認為,自從計算機發明以後,人類的計算方式,先後經歷了兩個階段:一是主機型計算階段(Mainframe Computing),指的是很多人共享一台大型機;二是個人型計算階段(Personal Computing),指的是每一個人都可以擁有一台電腦。韋澤預測,由於網絡技術的興起,特別是無線網絡技術的發展,計算機本身將從人們的視線中消失,計算將最終和環境融為一體。人們能夠在任何時間和任何地點獲取、處理信息,這就是普適計算的階段,人類正在向這第三波計算浪潮邁進。
普適計算
通過在日常環境中廣泛部署微小的計算設備,人們能夠在任何時間和任何地點獲取並處理信息,計算將最終和環境融為一體。這就是普適計算,是人類的第三波計算浪潮。
一句話:萬事萬物,凡存在,皆聯網,凡聯網,皆計算。

馬克·韋澤(1952-1999)
曾為帕羅奧多研究中心首席技術官,被稱為普適計算之父。
韋澤還是一名搖滾樂隊的鼓手,在他的策劃下,其樂隊在1993年實現了美國互聯網歷史上的首次現場直播。他因此得名「搖滾樂隊當中最聰明的鼓手」。(圖片來源:維基百科)
實現普適計算的根本,是在人類生活的物理環境當中廣泛部署微小的計算設備。
無處不在的微小計算設備和無處不在的互聯網相結合,實現無處不在的信息自動採集、傳遞和計算。
這種微小的計算設備,就是傳感器。近年來流行的物聯網概念就是普適計算的最佳例子。
對於傳感器及其網絡的最早研究,始於美國國防部一個軍事項目的研究,後來技術日臻成熟,傳感器的應用逐漸從軍事領域擴大到民用領域。
這可以追溯到20世紀60年代。
1962年,一場代號為「聖灰星期三」(Ash Wednesday)的風暴席捲了美國東海岸600多英里的海岸線,這場風暴持續了3天,影響了全美6個州,最後造成了40人死亡、1000多人受傷,導致了幾億美元的經濟損失,被後人評為20世紀美國最嚴重的十大風暴之一。
由於損失慘重,美國國會對救災防災工作召開了專門的聽證會,最後促成了軍民聯手的「海浪監測計劃」:美國陸軍工程部和美國國家海洋與大氣管理局(NOAA)共同建設一個傳感器監測系統,對興風作浪的海洋進行監測。
這項計劃的實施結果,是在全美海岸線和五大湖區建立了一個定點的、連續的、實時的傳感器網絡,對海浪的大小進行監控。受限於當時的技術,最早的傳感器只能監測海浪的能量。從2005年起,美國國家海洋與大氣管理局在浮標上裝備了更高端的傳感器,開始監測海浪的方向。
2009年,系統再次升級。該局開始著手建立一個覆蓋全美海岸線、從淺水到深水的、精確的海浪監測網絡。這個網絡總共在近海、外大陸架、內大陸架和沿海設置了296個傳感器。新的傳感器不僅能監測海浪的能量和方向,還能計算它的傳播速度、偏度和峰度。18
這些傳感器以分秒為單位,將數據源源不斷地實時傳回到國家海洋數據中心(DODC)。
對海浪的監測,不僅能提高沿海地區對海嘯、風暴等自然災害的應急能力,還能極大地改善海上的交通安全。根據美國疾病防控中心(CDC)的統計,捕魚業是美國最危險的職業之一,全美所有行業的平均致死率為0.004%,而捕魚業的平均致死率高達0.155%,其中79%的死亡是天氣變化的原因導致的。19
除了安全,海浪的監測還能為利用大海能量進行發電提供關鍵的分析型數據。
海浪監測只是聯邦政府利用傳感器網絡自動採集數據、邁向普適計算的一個例子。事實上,由於無線傳感器的快速發展,普適計算已經在美國的農業、運輸、能源和建築等領域逐步鋪開。
2011年10月,聯邦政府商務部下屬的國家氣象局(NWS)宣佈,該局已經在全國2000輛客運大巴上裝備了傳感器,隨著巴士的移動,這些傳感器可以收集沿途所有地點的溫度、濕度、露水、光照度等數據,並立刻傳回國家氣象局的數據中心。數據採集是每10秒鐘一次,每天傳感器要採集10萬次以上的數據。這些數據是實時的、高精度的,這意味著,天氣預報將不再僅僅是「預」報,將逐漸走向「實」報、「精」報。
此外,聯邦政府國家郵政局(USPS)也宣佈,他們正規劃在全部郵車上安裝傳感器,在郵車投遞郵件的同時,實時採集社區的空氣質量、污染指數和噪聲等數據指標。
有評論家感歎道:誰也沒想到,汽車,這個工業時代的標誌和先鋒,如今又成為信息時代普適計算的「排頭兵」。
近年來,傳感器的發展可謂突飛猛進。一種新的無線傳感器:射頻識別標籤(Radio Frequency Identification,RFID),正異軍突起,也在美國聯邦政府得到了大規模的應用。

薄如紙張的RFID

RFID動物耳標

更小更薄的RFID
(圖片來源:網絡)
RFID精巧輕便,既可以薄如紙張,也可以小如豆粒,卻能無線存儲、發送、讀寫數據,目前的應用主要集中在身份標識領域。以農牧業為例,1990年以來,全球各地陸續爆發動物疫情,2003年12月,美國發現了第一宗瘋牛病病例。2004年起,聯邦政府農業部啟動了「全國動物身份識別系統」(National Animal Identification System)的項目,為全國的新生牲畜建檔立戶、配置射頻識別耳標。通過這個移動傳感器,對牲畜進行連續跟蹤,一旦家畜疫情爆發,就能通過數據庫追蹤溯源,快速確定傳染源和傳播範圍。美國現在已經裝備射頻識別耳標的家畜總數,無從得知,但可以肯定,這個數據庫,也是海量級的。
從2005年起,美國食品與藥品管理局(FDA)開始在藥品上推行配備RFID的做法,以打擊假藥。美國國務院也開始頒髮帶有RFID標識的護照,以打擊假護照,方便出入境的管理。
美國聯邦政府通過傳感器自動採集數據的例子,正在大幅增加。如果僅僅從數據量上來看,通過傳感器自動採集的數據,已經取代了人工收集的業務數據,成為其最大的數據來源。還可以肯定的是,隨著人類向普適計算不斷邁進,通過傳感器自動採集的數據將持續「爆炸」。
「大數據」戰略:爭奪全世界的下一個前沿
聯邦政府的每一個機構和部門,都需要制定一個應對「大數據」的戰略。20
——《規劃數字化的未來:美國總統科學技術顧問委員會給總統和國會的報告》2010年
業務工作的管理數據,民意社情的調查數據,以及對大自然、動植物的特點和變化進行監控而產生的環境數據,是聯邦政府的三大數據來源。這三種數據,其發展各有先後,收集方式各不相同,數據量也大小不一。它們之間,存在著一些交叉和重疊,有一些民意調查的數據,是業務數據,而一些因環境監控產生的數據,也可以是業務工作的數據。
聯邦政府三種數據源的關係和數據量的大小比較
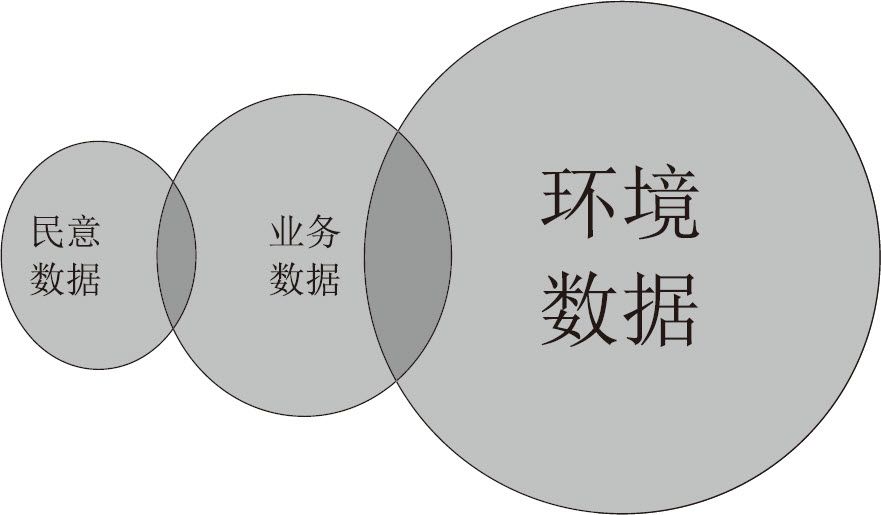
聯邦政府三種數據源以及收集方式的對比

由於無線傳感器的快速普及,環境數據增長得最快,成為聯邦政府數據量最大的來源。
雖然環境數據增長得最快,但這三種數據,其實都在爆炸。這種爆炸,並不僅僅是數量一個維度的。2001年,著名的高德納咨詢公司(Gartner)在一份研究報告21中指出,數據的爆炸是「三維的」、是立體的,這三個維度,主要表現在以下三個方面:
一是同一類型的數據量在快速增大;
二是數據增長的速度在加快;
三是數據的多樣性,即新的數據來源和新的數據種類在不斷增加。
數據的爆炸性增長,也不僅僅限於聯邦政府。如前文所述,2011年麥肯錫公司在其研究報告《大數據:下一個創新、競爭和生產率的前沿》中指出,在美國,僅僅製造行業就擁有比美國政府還多一倍的數據,此外,新聞業、銀行業、醫療業、投資業、零售業都擁有可以和美國政府相提並論的海量數據。
哈爾·范裡安(Hal Varian)是谷歌的首席經濟學家,也是美國研究信息經濟學的著名學者。2000年,他對數據和信息產生的速度進行了研究,他認為,人類社會每年產生的信息量,實在太大了,已經沒辦法用準確的方法來計算現有的數字信息總量,只能估算。他估計2000年新產生的數據量為1000拍到2000拍。但到2010年,僅僅全球企業一年新存儲的數據量就超過了7000拍,而全球消費者新存儲的數據量約為6000拍。
數據的三維增長
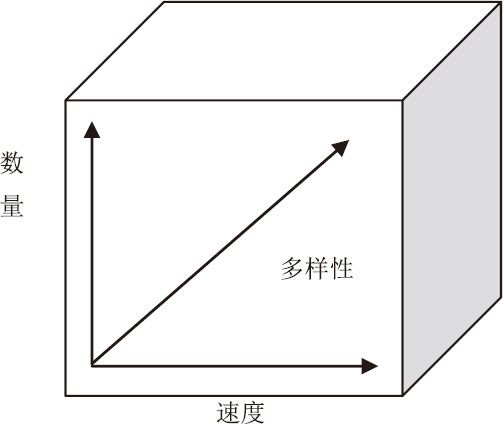
這種數據量的增長,已經大大超出了人類的預期和想像。時至今日,數據已經像「洪流」一樣,在全球的政治、經濟生活當中奔騰。而且,隨著信息技術的普及和進步,新的支流還在不斷產生,各個支流流動、交匯和整合的速度,還在繼續加快。
作為美國社會的信息樞紐,聯邦政府當然要正面迎對這個挑戰。
2010年12月,總統行政辦公室下屬的科學技術顧問委員會(PCAST)、信息技術顧問委員會(PITAC)向奧巴馬和國會提交了《規劃數字化未來》的專門報告,該報告把數據收集和使用的工作,提到了戰略的高度。
這個報告列舉了5個貫穿各個科技領域的共同挑戰,報告指出「每一個挑戰都至關重要」,而第一個挑戰就是「數據」問題。報告說:
「如何收集、保存、維護、管理、分析、共享正在呈指數級增長的數據是我們必須面對的一個重要挑戰。從網絡攝像頭、博客、天文望遠鏡到超級計算機的仿真,來自於不同渠道的數據以不同的形式如潮水一般向我們湧來。這些數據以不同的格式存儲在不同的環境中,有的在計算機的硬盤裡,有的在數據倉庫之內。
如何保證這些數據現在、將來的完整性和可用性,我們面臨著很多的問題和挑戰。如何使用這些數據,則是另外一個挑戰……應對好這些挑戰,將引導我們在科研、醫療、商業和國家安全方面開創新的成功。」
在報告中,兩個委員會還例舉了美國癌症研究所以及中央情報局如何通過收集海量數據、建立數據倉庫、實施以數據挖掘為核心的自動分析技術,獲得了出人意料的創新和成功。
委員會一致認為,如何有效地利用數據將貫穿所有科技領域的挑戰。最後,兩個委員會向奧巴馬建議:聯邦政府的每一個機構和部門,都需要制定一個「大數據」的戰略。
大數據(Big Data)
大數據是指那些大小已經超出了傳統意義上的尺度,一般的軟件工具難以捕捉、存儲、管理和分析的數據。
但是,具體多大的數據才能稱為「大」,並沒有普遍適用的定義。一般認為,大數據的數量級應該是「太字節」(240)的。麥肯錫全球研究所認為,我們並不需要給「什麼是大」定出一個具體的「尺寸」,因為隨著技術的進步,這個尺寸本身還在不斷地增大。此外,對於各個不同的領域,「大」的定義也是不同的,無需統一。
其實,「大數據」這個名詞並不新鮮,早在1980年代,美國就有人提出了「大數據」的概念。20多年來,各個領域的數據量都在迅猛增長,美國的企業界、學術界也不斷地對這個現象及其意義進行探討,「大數據」這個名詞變得越來越流行、越來越重要,最後成為了國家和政府層面的發展戰略。
之所以要稱之為戰略,是因為「大數據」之「大」,並不僅僅在於其「容量之大」。當然,由於數據容量的爆炸,數據的收集、保存、維護以及共享等等任務,都成為具有研究意義的現象和挑戰。但「大數據」之「大」,更多的意義在於:人類可以「分析和使用」的數據在大量增加,通過這些數據的交換、整合和分析,人類可以發現新的知識,創造新的價值,帶來「大知識」、「大科技」、「大利潤」和「大發展」。
如前文所述,數據,是記錄信息的載體,是知識的來源。數據的激增,意味著人類的記錄範圍、測量範圍和分析範圍在不斷擴大,知識的邊界在不斷延伸。
2007年,雅虎的首席科學家沃茨博士在《自然》上發表了一篇文章《21世紀的科學》22,他發現,得益於計算機技術和海量數據庫的發展,個人在真實世界的活動得到了前所未有的記錄,這種記錄的粒度23很高,頻度在不斷增加,為社會科學的定量分析提供了極為豐富的數據。由於能測得更准、計算得更加精確,他認為,社會科學將脫下「准科學」的外衣,在21世紀全面邁進科學的殿堂。例如,新聞的跟帖、網站的下載記錄、社交平台的互動記錄等等都為政治行為的研究提供了大量的數據,政治學這門古老的學科,將登堂入室,成為地道的「科學」。
麻省理工學院的教授布倫喬爾森(Erik Brynjolfsson)則比喻說,大數據的影響,就像4個世紀之前人類發明的顯微鏡一樣。顯微鏡把人類對自然界的觀察和測量水平推進到了「細胞」的級別,給人類社會帶來了歷史性的進步和革命。24而大數據,將成為我們下一個觀察人類自身社會行為的「顯微鏡」和監測大自然的「儀表盤」。
這個新的顯微鏡,將再一次擴大人類科學的範圍,推動人類知識的增長,引領新的經濟繁榮。麥肯錫全球研究所在其2011年的報告中最後概括說:大數據,將成為全世界下一個創新、競爭和生產率提高的前沿。
搶佔這個前沿,無異於搶佔下一個時代的「石油」和「金礦」。
2012年3月29日,奧巴馬政府又進一步推進了其「大數據」戰略。奧巴馬的高級顧問、總統科學技術顧問委員會(PCAST)的主席霍爾德倫(John Holdren)代表國防部、能源部等6個聯邦政府部門宣佈,將投入2億多美元立即啟動「大數據發展研究計劃」(Big Data Research and Development Initiative),以推動大數據的提取、存儲、分析、共享和可視化。霍爾德倫也是哈佛大學肯尼迪政府學院的知名教授,他在講話中表示:像美國歷史上對超級計算和互聯網的投資一樣,這個大數據發展研究計劃將對美國的創新、科研、教育和國防產生深遠的影響。
奧巴馬則強調聯邦政府必須和公司、大學結盟,全民動員(All Hands on Deck),來應對「大數據」時代的挑戰。
人類知識的三大種類與科學的關係
人類所有的知識,可以劃分為三個大類:自然科學、社會科學和人文藝術。
自然科學的研究對象是物理世界,講的是「精確」,絲毫不能含糊,衛星上天、潛艇下海,差之毫釐,就會謬以千里。
社會科學研究的是社會現象,探討的是人和社會的關係,如經濟學、政治學、社會學,它也追求精確,但因為關係到多變善變的人,導致了「測不准」,所以社會科學又被稱為「准科學」。
人文藝術則主要包括文學、藝術、哲學,它探討的是人的信仰、情感和價值,並不強調精確,有時候甚至模糊就是美,所以位於科學的最外圍。
在科學的譜系裡,社會科學正好介於自然科學和人文藝術之間。