
The Preg Functions
本節從最基本的「這個正則表達式能否在字符串中找到匹配」開始,詳細介紹各個函數。
preg_match
使用方法
preg_match(pattern,subject[,matches[,flags [,offset]]])
參數簡介
pattern 分隔符包圍起來的正則表達式,可能出現修飾符(☞444)。
subject 需要搜索的目標字符串。
matches 非強製出現,用來接受匹配數據。
flags 非強製出現,此標誌位會影響整個函數的行為。這裡只容許出現一個標誌位,
PREG_OFFSET_CAPTURE(☞452).
offset非強製出現,從0開始,表示匹配嘗試開始的位置(☞453)。
返回值
如果找到匹配,就返回true,否則返回false。
講解
最簡單的用法是:
preg_match($pattern,$subject)
如果$pattern在$subject中能找到匹配,就會返回true。下面有幾個簡單的例子:

捕獲匹配數據
preg_match的第3個參數如果出現,則會用來保存匹配結果的信息。用戶可以照自己的意願使用任何變量,不過最常用的名字是$matches。在本書中,如果我在特定的例子之外提到$matches,指的就是「preg_match接收的第3個參數」。
匹配成功之後,preg_match返回true,並按如下規則設置$matches:

如果使用了命名分組,$matches中也會保存對應的元素(下一節有這樣的例子)。
第5章中(☞191)曾出現過這個簡單的例子:
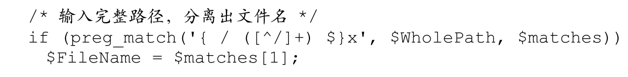
最好是在preg_match返回true的情況下用$matches(隨便你怎麼命名)。如果匹配不成功,會返回 false,或者錯誤(例如模式錯誤或函數標誌位設置錯誤)。有的錯誤發生之後,$matches 是空數組,但也有時候它的值不會變化,所以我們不能認為,$matches 不為空就表示匹配功。
下面這個例子使用了3組捕獲型括號:

數組結尾「未參與匹配」的元素會被忽略
如果一組捕獲型括號沒有參與最終匹配,它會在對應的$matches中生成一個空字符串(注2)。需要說明的是,$matches末尾的空字符串都會被忽略。在前面那段程序中,如果「(\d+)」參與了匹配,$matches[3]會保存一個數值,否則,$matches[3]根本就不會存在。
命名捕獲
如果我們用命名捕獲(☞138)重寫之前的例子,正則表達式會長一些,不過代碼更容易閱讀:

命名捕獲看起來更清晰,這樣我們不需要把$matches的內容複製給各個變量,就能直接使用變量名,而不是$matches,例如這樣:

如果使用了命名捕獲,按數字編號的捕獲仍然會插入$matches。例如,在匹配$url(值為『http://regex.info』)之後,之前例子中的$UrlInfo包含:

這樣的重複有點浪費,但這是獲得命名捕獲的便捷和清晰所必須付出的代價。為清晰起見,我不推薦同時使用命名和數字編號來訪問$matches的元素,當然用$matches[0]表示全局匹配例外。
請注意,數組中不包括編號為3和名稱為『port』的入口(entry),因為這一組捕獲型括號沒有參與到最終匹配中,而且處於最後(因此會被忽略☞450)。
還要提一點,儘管現在使用例如「(?P<2>…)」之類的數字命名並不會出錯,但這種做法並不可取。PHP4和PHP5在處理非正常情況時會有所區別,可能不會按照個人的意願發展,所以最好還是不要使用數字來命名捕獲分組。
更多的匹配細節:PREG_OFFSET_CAPTURE
如果設置了 preg_match 的第 4 個參數 flags,而且包含 PREG_OFFSET_CAPTURE(這也是preg_match目前能夠接受的唯一標誌位),則$matches的每個元素不再是普通字符串,而是由兩個元素構成的子數組,其中第1 個元素是匹配的文本,第2 個元素是這段文本在目標字符串中的偏移值(如果沒有參與匹配,則為-1)。
偏移值從0開始,表示這段文本相對目標字符串的偏移值,即使設置了第5個參數$offset,偏移值的計算也不會變化。它們通常按照字節來計數,即使使用了模式修飾符 u 也是如此(☞447)。
來看個從tag中提取HREF屬性的例子。HTML的屬性值兩邊可能是雙引號、單引號,或者乾脆沒有引號,這樣的值在下面這個正則表達式的第1組、第2組和第3組捕獲型括號中被捕獲:
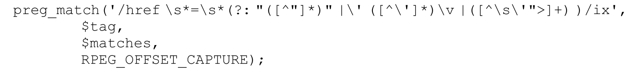
如果$tag包含:
<a name=bloglink href='http://regex.info/blog/'rel=〞nofollow〞>匹配成功之後,$matches的內容是:

$matches[0][0]包含正則表達式匹配的所有文本,$matches[0][1]表示匹配文本在目標字符串中的偏移值,按字節計數。
為了清晰起見,另一種獲得$matches[0][0]的辦法是:
substr($tag,$matches[0][1],strlen($matches[0][0]));
$matches[1][1]是-1,表示第1組捕獲括號沒有參與匹配。第3組也沒有參與,但是因為之前提到的理由(☞450),結尾未參與匹配的捕獲括號匹配的文本不會包含在$matches中。
offset參數
如果 preg_match中設置了 offset 參數,引擎會從目標字符串的對應位置開始(如果 offset是負數,則從字符串的末尾開始倒數)。默認情況下,offset是0(也就是說,從目標字符串的開頭開始)。
請注意,offset是按字節計數的,即使使用了模式修飾符u也是這樣。如果設置不正確(例如從某個多字節字符的「內部」開始)會導致匹配失敗。
即使offset不等於0,PHP也不會把這個位置標記為「^」——字符串的起始位置,它只表示正則引擎開始嘗試的位置。不過,逆序環視倒是可以檢查offset左邊的文本。
preg_match_all
使用方法
preg_match_all(pattern,subject,matches [,flags [,offset]])
參數簡介
pattern分隔符包圍起來的正則表達式,可能出現修飾符(☞444)。
subject需要檢索的目標字符串。
matches 用來保存匹配數據的變量(必須出現)。
flags非強製出現,標誌位設定整個函數的功能:
PREG_OFFSET_CAPTURE(☞456)
和/或任意:
PREG_PATTERN_ORDER(☞455) PREG_SET_ORDER(☞456)
offset非強製出現,從0開始,表示目標字符串中匹配嘗試開始的位置(與preg_match的offset參數相等☞453)。
返回值
preg_match_all返回匹配的次數。

講解
preg_match_all類似於preg_match,只是在找到第一個匹配之後,它會繼續搜索字符串,找到其他的匹配。每個匹配都會創建一個包含匹配數據的數組,所以最後 matches變量就是一個二維數組,其中的每個子數組對應一次匹配。
這裡有個簡單的例子:

preg_match_all要求必須出現第3個參數(也就是用來收集所有成功的匹配信息的變量)。所以,這個例子中雖然沒有用到$all_matches,但仍然必須設置這個變量。
收集匹配數據
preg_match和 preg_match_all的另一個主要區別是第3 個參數中的數據。preg_match進行至多一次匹配,所以它把匹配的數據存儲在matches變量中。與此不同的是,preg_match_all能匹配許多次,所以它的第3 個參數保存了多個單次匹配的 matches。為了說明這種區別,我使用$all_matches作為preg_match_all的變量名,而不是$preg_match中常用的$matches。
preg_match_all可以以兩種方式在$all_matches中存放數據,根據下面兩個互斥的第4個參數flag:PREG_PATTERN_ORDER或是PREG_SET_ORDER來決定。
默認的排列方式是 PREG_PATTERN_ORDER 下面有個例子(我稱其為「按分組編號的(collated)」——稍後將介紹)。如果沒有設置標誌位,這就是默認的配列方式:

$all_matches的結果為:
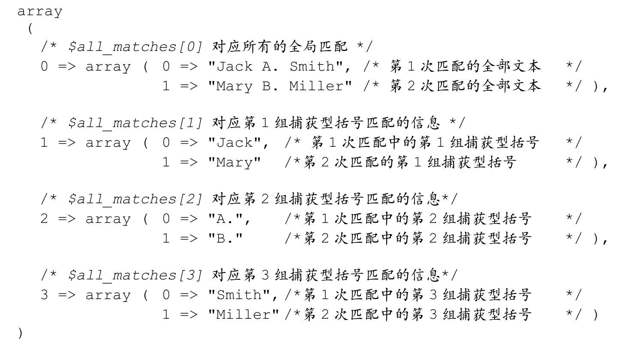
一共匹配了兩次,每次都包含一個「全局匹配」字符串,以及 3 個捕獲型括號對應的子字符串。我稱其為「按分組編號的(collated)」,因為所有的全局匹配都存放在一個數組裡(在$all_matches[0],每次匹配中,第1組括號配的文本存放在另一個數組$all_matches[1]中,依次類推。
默認情況下,$all_matches是按分組編號的,但我們可設置PREG_SET_ORDER來改變它。PREG_SET_ORDER 排列方式 如果設定了 PREG_SET_ORDER 標誌位,就會採用「堆疊(stacked)」的排列方式。它會把第 1 次匹配的所有數據保存在$all_matches[0] 中,第 2次匹配的所有數據保存在$all_matches[1] 中,依次類推。這就是我們檢索字符串的順序,把每次成功匹配的$matches放進$all_matches數組中。
下面是之前那個例子的PREG_SET_ORDER的版本:

結果是:

兩種排列方式的總結如下:

preg_match_all和PREG_OFFSET_CAPTURE標誌位
就像 preg_match 一樣,也可以在 preg_match_all 中使用 PREG_OFFSET_CAPTURE,讓$all_matches的每個末端元素(leaf element)成為一個兩個元素的數組(匹配的文本,以及按字節計算的偏移值)。也就是說,$all_matches 成為一個數組的數組的數組,這可真饒舌。如果你希望同時使用PREG_OFFSET_CAPTURE和PREG_SET_ORDER,請使用邏輯運算符「or」來連接:
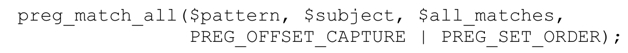
preg_match_all與命名分組
如果使用了命名分組,$all_matches將會多出命名元素(同preg_match一樣☞451)。這段程序:

$all_matches的結果是:

如果使用PREG_SET_ORDER:

結果就是:

我個人認為,在使用了命名分組之後,就應該去掉數字編號,因為這樣程序更清晰,效率更高,不過,如果它們被保留了,你可以當它們不存在。
preg_replace
使用方法
preg_replace(pattern,replacement,subject [,limit [,count]])
參數簡介
pattern分隔符包圍起來的正則表達式,可能出現修飾符。pattern也可能是一個pattern-argument字符串的數組。
replacement replacement字符串,如果pattern是一個數組,則replacement是包含多個字符串的數組。如果使用了模式修飾符 e,則字符串(或者是數組中的字符串)會被當作PHP代碼(☞459)。
subject需要搜索的目標字符串。也可能是字符串數組(按順序依次處理)。
limit非強製出現,是一個整數,表示替換發生的上限(☞460)。
count非強製出現,用來保存實際進行的替換次數(只有PHP5提供,☞460)。
返回值
如果 subject 是單個字符串,則返回值也是一個字符串(subject 的副本,可能經過修改)。
如果subject是字符串數組,返回值也是數組(包含subject的副本,可能經過修改)。
講解
PHP 提供了許多對文本進行查找-替換的辦法。如果查找部分可以用普通的字符串描述,str_replace或者 str_ireplace就更合適,但是如果查找比較複雜,就應該使用 preg_replace。
來看一個簡單的例子:在Web開發中經常會遇到這樣的任務,把信用卡號或電話號碼輸入一張表單。你是否經常看到「不要輸入空格和連字符」的提示?要求用戶按規則輸入數據,還是由程序員做一點小小的改進,讓用戶可以照自己的習慣輸入數據?哪種辦法更好(注3)?畢竟,這裡我們的要求就是「清理」這樣的輸入數據:
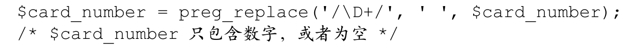
其中用 preg_replace 來去掉非數字字符。更確切的說,它用 preg_replace 來生成$card_number 的副本,將其中的非數字字符替換為空(空字符串),把這個經過修改的副本賦值給$card_number。
單字符串,單替換規則的preg_replace
前面三個元素(pattern,replacement 和 subject)都是既可以為字符串,也可以為字符串數組。通常這三者都是普通的字符串,preg_replace 首先生成 subject 的副本,在其中找到pattern的第1次匹配,將匹配的文本替換為replacement,然後重複這一過程,直到搜索到字符串的末尾。
在replacement字符串中,『$0』表示匹配的所有文本,『$1』表示第1組捕獲型括號匹配的文本,『$2』表示第2組,依次類推。請注意,美元符加數字的字符序列並不會引用變量,雖然它們在其他某些語言中有這種功能,但是 preg_replace 能識別簡單的序列,並進行特殊處理。你可以使用一對花括號來包圍數字,比如『${0}』和『${1}』,這樣就不會引起混淆。
這個簡單的例子把HTML的bold tag轉換為全部大寫:
$html=preg_replace('/\b[A-Z]{2,}\b/','<b>$0</b>',$html);
如果使用了模式修飾符e(它只能出現在preg_replace中),replacement字符串會作為PHP代碼,每次匹配時執行,結果作為replacement字符串。下面這個擴展的例子把bold tag裡的單詞變為小寫:

如果正則表達式匹配的單詞是『HEY』,replacement字符串中的$0會被替換為這個值。結果,replacement字符串就成了『strtolower(〞<b>HEY</b>〞)』,執行這段PHP代碼,結果就是『<b>hey</b>』。
如果使用模式修飾符 e,replacement 字符串中的捕獲引用會按照特殊的規定來插值:插值中的引號(單引號或雙引號)會轉義。如果不這樣處理,插入的數值中的引號會導致 PHP代碼出錯。
如果使用模式修飾符e,在replacement字符串中引用外部變量,最好是在replacement字符串文本中使用單引號,這樣變量就不會進行錯誤的插值。
這個例子類似於PHP內建的htmlspecialchars()函數:

$new_subject=preg_replace('/[&<〞>]/eS','$replacement[〞$0〞]',$subject);需要注意,這個例子中的replacement使用了單引號字符串來避免$replacement變量插值,直到將其作為PHP代碼執行。如果使用雙引號字符串,在傳遞給preg_replace之前,插值就會進行。
可以用模式修飾符S用來提高效率(☞478)。
preg_replace 的第 4 個參數用來設定替換操作次數的上限(單位是單個字符串-單個正則表達式,參見下一節)。默認值是-1,表示「沒有限制」。
如果設置了第5個參數count(PHP4沒有提供),它會用來保存preg_replace的實際替換的次數。如果你希望知道是否發生了替換,可以比較原來的目標字符串和結果,不過檢查count參數效率更高。
多字符串,多替換規則
前一節已經提到,目標字符串通常是普通字符串,至少我們目前看到的所有例子都是如此。不過,subject 也可以是一個字符串數組,這樣搜索和替換是對每個字符串依次進行的。返回值也是由每個字符串經過搜索和替換之後的數組。
無論使用的是字符串還是字符串數組,pattern和replacement參數也可以是字符串數組,下面是各種組合及其意義:
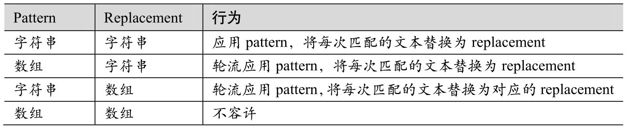
如果subject參數是數組,則依次處理數組中的每個元素,返回值也是字符串數組。
請注意limit參數是以單個pattern和單個subject為單位的。它不是對所有的pattern和subject生效。返回的$count則是所有pattern和subject字符串所進行操作次數的總合。
這裡有一個preg_replace的例子,其中pattern和replacement都是數組。其結果類似於PHP內建的htmlspecialchars()函數,它保證處理過的文本符合HTML規範:

如果輸入的文本是:
AT&T--> 〞baby Bells〞
$cooked的值就是:
AT&T-->"baby Bells"
當然也可以預先準備好這些數組,下面的程序運行結果相同:

preg_replace 能夠接收數組作為參數是很方便的(這樣程序員就不需要使用循環在各個pattern和subject中進行迭代),但是它的功能並沒有增強。比如,各個pattern並不是「並行」處理的。但是,相比自己寫PHP循環代碼,內建的處理效率更高,而且更容易閱讀。為了說清楚,請參考這個例子,其中所有的參數都是數組:
$result_array=preg_replace($regex_array,$replace_array,$subject_array);
它等價於:

數組參數的排序問題 如果pattern和replacement都是字符串,它們會根據數組的內部順序配對,這種順序通常就是它們添加到數組中的先後順序(pattern 數組中添加的第1 個元素對應replacement 數組中的第1 個元素,依次類推)。也就是說,對於 array()創建的「文本數組」來說,排序沒有問題,例如:

「[a-z]+」對應『word<$0>』,下面的「\d+」對應『num<$0>』,結果就是
result:word<this> word<has> num<7> word<words> word<and> num<31> word<letters>相反,如果 pattern 或 replacement 數組是多次填充的,數組的內部順序可能就不同於 keys的順序(也就是說,由 keys 表示的數字順序)。所以前一頁的程序使用數組模擬preg_replacement的程序要使用each來按照數組的內部順序遍歷整個數組,而不關心它們的keys如何。
如果 pattern 或 replacement 數組的內部順序不同於你希望匹配的順序,可以使用 ksort()函數來確保每個數組的實際順序和外表順序是相同的。
如果pattern和replacement都是數組,而pattern中元素的數目多於replacement中的元素,則會在replacement數組中產生對應的空字符串,來進行配對。
pattern 數組中的元素順序不同,結果可能大不相同,因為它們是按照數組中的順序來處理的。如果把例子中的pattern數組的順序顛倒過來(把replacement數組中的順序也顛倒過來),結果是什麼呢?也就是說,下面代碼的結果是什麼呢?

ϖ 請翻到下頁查看答案。
preg_replace_callback
使用方法
preg_replace_callback(pattern,callback,subject [,limit [,count]])參數簡介
pattern 分隔符包圍起來的正則表達式,可能出現修飾符(☞444)。也可能是字符串數組。
callback PHP回調函數,每次匹配成功,就執行它,生成replacement字符串。
subject 需要搜索的目標字符串。也可能是字符串數組(依次處理)。
limit非強製出現,設定替換操作的上限(☞460)。
count非強製出現,用來保存實際發生替換的次數(只在PHP 5.1.0中提供)。
返回值
如果subject是字符串,返回值就是字符串(其實是subject的一個副本,可能經過了修改)。如果subject是字符串數組,返回值就是數組(每個元素都是subject中對應元素的副本,可能發生了修改)。
講解
preg_replace_callback類似於 preg_replace,只是replacement 參數變成了PHP 回調函數,而不是字符串或是字符串數組。它有點像使用模式修飾符e的preg_replace(☞459),但是效率更高(如果replacement部分的代碼很複雜,這種辦法更易於閱讀)。
請參考PHP文檔獲得更多關於回調的知識,不過簡單地說,PHP回調引用(以許多種方式中的一種)一個預先規定的函數,以預先規定的參數,返回預先規定的值。在preg_replace_callback 中,每次成功匹配之後都會進行這種調用,參數是$matches 數組。函數的返回值用作preg_replace_callback作為replacement。
回調可以以三種方式引用函數。一種是直接以字符串形式給出函數名;另一種是用PHP內建的create_function生成一個匿名函數。稍後我們會看到使用這兩種方法的例子。第三種方式本書沒有提及,它採用面向對象的方式,由一個包含兩個元素(分別是類名和方法名)的數組構成。

下面這個例子用preg_replace_callback和輔助函數重寫了第460頁的程序。callback參數是一個字符串,包含輔助函數的名字:

如果$subject的值是:
〞AT&T〞 sounds like 〞ATNT〞
則$new_subject的值就是:
"AT&T"sounds like"ATNT"
本例中的text2html_callback是普通的PHP函數,用作preg_replace_callback中的回調函數,它的接收參數是$matches數組(當然,這個變量可以隨意命名,不過我選擇遵循之前使用$matches的慣例)。
為完整起見,下面我給出使用匿名函數的辦法(使用PHP內建的create_function函數)。這段程序產生的$replacement變量與上面一樣。函數體也相同,只是此時函數沒有名字,只能在preg_replace_callback中使用:

使用callback,還是模式修飾符e
如果處理不複雜,使用模式修飾符的程序比preg_replace_callback更容易看懂。但是,如果效率很重要,那麼請記住,如果使用模式修飾符e,每次匹配成功之後都需要檢查作為PHP代碼的replacement參數。相比之下,preg_replace_callback的效率就要高許多(如果使用回調,PHP代碼只需要審查1次)。
preg_split
使用方法
preg_split(pattern,subject [,limit,[flags]])
參數簡介
pattern 分隔符包圍起來的正則表達式,可能還有修飾符(☞444)。
subject 需要分割的目標字符串。
limit非強製出現,是一個整數,表示切分之後元素的上限。
flags非強製出現,此標誌位影響整個切割行為,以下三項可以隨意組合:

它們的講解從第468頁開始。多個標誌位使用二元運算符「或」來連接(與第456頁一樣)。
返回值
返回一個字符串數組。
講解
preg_split會把字符串的副本切分為多個片段,以數組的形式返回。非強製出現參數limit設定返回數組中元素數目的上限(如果需要,最後的元素包括「其他所有字符」)。可以設定不同的標誌位來調整返回的方式和內容。
從某種意義上來說,preg_split做的是與preg_match_all相反的事情:它找出目標字符串中不能由正則表達式匹配的部分。或者更傳統地說,preg_split返回的是,將目標字符串中正則表達式匹配的部分刪去之後的部分。preg_split 大概相當於 PHP 中內建的簡單explode函數,不過使用的是正則表達式,而且功能更強大。
來看個簡單的例子,如果某家金融網站需要接收用空格分隔的股票行情。可以使用explode拆分這些行情數據:
$tickers=explode('',$input);
不過,如果輸入數據時不小心輸入了不只一個空格,這個程序就不能處理了。更好的辦法是使用preg_split,用正則表達式「\s+」來切分:
$tickers=preg_split('/\s+/',$input);
除了明確運用「用空格切分」的規則之外,用戶也通常使用逗號(或者是逗號加空格)來分隔,比如『YHOO,MSFT,GOOG』。這些情況也很容易處理:
$tickers=preg_split('/[\s,]+/',$input);
針對上面的數據,$tickers得到的是包含3個元素的數組:『YHOO』、『MSFT』和『GOOG』。
如果輸入的數據是逗號分隔的(例如給照片標記 tag 時使用的「Web 2.0,」),就需要用「\s*,\s*」來處理:
$tags=preg_split('/\s*,\s*/',$input);
比較「\s*,\s*」和「[\s,]+」很能說明問題。前者用逗號來切分(逗號必須出現),但也會刪去逗號兩邊的空白字符。如果輸入『123,,,456』,則能夠進行3次匹配(每次匹配一個逗號),返回4個元素:『123』,兩個空字符串,最後是『456』。
另一方面,「[\s,]+」會使用任何逗號、連續的逗號、空白字符,或者是空白字符和逗號的結合來切分。在『123,,,456』中,它一次就能匹配3個逗號,返回兩個元素,『123』和『456』。
limit參數
limit 參數用來設定切分之後數組長度的上限。如果搜索尚未進行到字符串結尾時,切分的片段的數目已經達到limit,則之後的內容會全部保存到最後的元素當中。
來看個例子,我們需要手工解析服務器返回的 HTTP response。按照標準,header 和 body的分隔是四字符序列『\r\n\r\n』,不幸的是,有的服務器使用的卻是『\n\n』。幸好,我們有preg_split,很容易處理這兩種情況。假設整個response保存在$response中:
$parts=preg_split('/\r?\n\r?\n/x',$response,2);
header保存在$parts[0]中,而body保存在$parts[1]中(使用模式修飾符S是為了提高效率☞478)。
第3個參數,即limit的值等於2,表示subject字符串最多只能切分成兩個部分。如果找到了一個匹配,匹配之前的部分(也就是 header)會成為返回值的第一個元素。因為「字符串的其他部分」是第2個元素,這樣就到達了上限,它(我們知道是body)會原封不動地作為返回值中的第二個元素。
如果沒有limit(或者limit等於-1,這兩種情況是等價的),preg_split會盡可能多地切分subject字符串,這樣body可能也會被切分為許多段。設置上限並不能保證返回的數組中包含的元素就等於這個數,而只是保證最多包含這麼多元素(閱讀關於PREG_SPLIT_DELIM_CAPTURE的小節,你會發現甚至這種說法也不完全對)。
在兩種情況下,應該人為設置上限。我們已經見過一種情況:希望最後的元素包含「其他所有內容」。在前一個例子中,一旦第一段(header)被切分出來,我們就不希望再對其他部分(body)進行切分。所以,把上限設為2會保留body。
如果用戶知道自己不需要切割出來所有元素,也可以設定上限,提高效率。例如,如果$data字符串包含以「\s*,\s*」分隔的許多字段(比如姓名、地址、年齡,等等),而只需要前面兩個,就可以把limit 設置為3,這樣 preg_split在切分出前兩個字段之後就不會繼續工作:
$fields=preg_split('/\s*,\s*/x',$data,3);
這樣其他內容都保存在最後的第3個元素中,我們可以用array_pop來刪除,或者置之不理。
如果你希望在沒有設置上限的情況下使用任何preg_split標誌位(下一節討論),則必須提供一個佔位符,將limit設置為-1,它表示「沒有限制」。相反,如果limit等於 1,則表示「不需要切分」,所以它並不常用。上限等於0或者-1之外的任何負數都沒有定義,所以請不要使用它們。
flag參數
preg_split中可以使用的3個標誌位都會影響函數的功能。它們可以單獨使用,也可以用二元運算符「or」連接(參見第456頁的例子)。
PREG_SPLIT_OFFSET_CAPTURE 就像在 preg_match 和 preg_match_all 中使用 PREG_OFFSET_CAPTURE一樣,這個標誌位會修改結果數組,把每個元素變為包含兩個元素的數組(元素本身和它在字符串中的偏移值)。
PREG_SPLIT_NO_EMPTY 這個標誌位告訴preg_split忽略空字符串,不把它們放在返回數組中,也不記入limit的統計。對目標字符串的起始位置、結尾位置,或是空行的匹配,都會帶來空字符串。
下面來改進前面的「Web 2.0」的tag的例子(☞466),如果$input為『party,,fun』,那麼:
$tags=preg_split('/\s*,\s*/x',$input);
得到的$tags包含3個元素:『party』、空字符串,然後是『fun』。空字符串是逗號的兩次匹配之間的「空白」。
如果設置了PREG_SPLIT_NO_EMPTY 標誌位:
$tags=preg_split('/\s*,\s*/x',$input,-1,PREG_SPLIT_NO_EMPTY);
結果數組只包含『party』和『fun』。
PREG_SPLIT_DELIM_CAPTURE 這個標誌位在結果中包含匹配的文本,以及進行此次切分的正則表達式的捕獲括號匹配的文本。來看個簡單的例子,如果字符串中各個字段是以『and』和『or』來聯繫的,例如:
DLSR camera and Nikon D200 or Canon EOS 30D
如果不使用PREG_SPLIT_DELIM_CAPTURE,
$parts=preg_split('/\s+(and|or)\s+/x',$input);
得到的$parts是:
array ('DLSR camera','Nikon D200','Canon EOS 30D')
分隔符中的匹配內容被去掉了。不過,如果使用了PRE_SPLIT_DELIM_CAPTURE 標誌位(並且用-1作為limit參數的佔位符):

$parts包含了捕獲型括號匹配的分隔符:
array ('DLSR camera','and','Nikon D200','or','Canon EOS 30D')
此時,每次切分會在結果數組中增加一個元素,因為正則表達式中只有一組捕獲型括號。然後我們就能夠遍歷$parts中的元素,對找到的『and』和『or』進行特殊處理。
請注意,如果使用了非捕獲型括號(如果 pattern 參數為『/\s+(?:and|or)\s+/』),PREG_SPLIT_DELIM_CAPTURE 標誌位不會產生任何效果,因為它只對捕獲型括號有效。
來看另一個例子,第466頁分析股市行情的例子:
$tickers=preg_split('/[\s,]+/',$input);
如果我們添加捕獲型括號,以及PREG_SPLIT_DELIM_CAPTURE
$tickers=preg_split('/([\s,]+)/',$input,-1,PREG_SPLIT_DELIM_CAPTURE);結果$input 中的任何字符都沒有被拋棄,它只是切分之後保存在$tickers 中。處理$tickers數組時,你知道編號為奇數的元素是「([\s,]+)」匹配的。這可能很有用,如果在向用戶顯示錯誤信息時,可以對不同的部分分別進行處理,然後將它們合併起來,還原出輸入的字符串。
還有一點需要注意,通過PREG_SPLIT_DELIM_CAPTURE添加的元素不會影響切分上限。只有在這種情況下,結果數組中的元素數目才可能超過上限(如果正則表達式中的捕獲型括號很多,則元素就要更多)。
結尾的未參與匹配的捕獲型括號不會影響結果數組。也就是說,如果一組捕獲型括號沒有參與最終匹配(參見450頁),可能會也可能不會在結果數組中添加空字符串。如果編號更靠後的捕獲型括號參與了最終匹配,就會增加,否則就不會。請注意,如果使用了PREG_SPLIT_NO_EMTPY 標誌位,結果會有變化,因為空字符串肯定會被拋棄。
preg_grep
使用方法
preg_grep(pattern,input[,flags])
參數簡介
pattern 分隔符包圍起來的正則表達式,可能出現修飾符。
input 一個數組,如果它們的值能夠匹配pattern,則其值會複製到返回的數組中。
flags 非強製出現,此標誌位PREG_GREP_INVERT或者是0。
返回值
一個數組,包含input中能夠由pattern匹配的元素(如果使用了 PREG_GREP_INVERT標誌位,則包括不能匹配的元素)。
講解
preg_grep 用來生成 input 數組的副本,其中只保留了 value 能夠匹配(如果使用了PREG_GREP_INVERT標誌位,則不能匹配)pattern的元素。此value對應的key會保留。來看個簡單的例子
preg_grep('/\s/',$input);
它返回$input數組中的,由空白字符構成的元素。相反的例子是:
preg_grep('/\s/',$input,PREG_GREP_INVERT);
它返回不包含空白字符的元素。請注意,第二個例子不同於:
preg_grep('/^\S+$/',$input);
因為後者不包括空(長度為0)值元素。
preg_quote
使用方法
preg_quote(input [,delimiter])
參數簡介
input希望以文字方式用作pattern參數的字符串(☞444)。
delimiter 非強製出現的參數,包含1個字符的字符串,表示希望用在pattern參數中的分隔符。
返回值
preg_quote返回一個字符串,它是input 的副本,其中的正則表達式元字符進行了轉義。如果指定了分隔符,則分隔符本身也會被轉義。
講解
如果要在正則表達式中以文字方式使用某個字符串,可以用內建的preg_quote函數來轉義其中可能產生的正則表達式元字符。如果指定了創建pattern時使用的分隔符,字符串中的分隔符也會被轉義。
preg_quote是專門應對特殊情況的函數,在許多情況下沒有用,不過這裡有個例子:

如果$MailSubject包含下面的字符串
**Super Deal** (Act Now!)
最後$pattern就會是
/^Subject:\s+(Re:\s*)*\*\*Super Deal\*\*\(Act Now\!\)/mi
這樣就可以作為preg函數的pattern參數了。
如果指定的分隔符是『{』之類對稱的字符,那麼對應的字符(例如『}』)不會轉義,所以請務必使用非對稱的分隔符。
同樣,空白字符和『#』也不會轉義,所以結果可能不適於用x修飾符。
這樣說來,在把任意文本轉換為 PHP 正則表達式的問題上,preg_quote 並不是完善的解決辦法。它只解決了「文本到正則表達式」的問題,而沒有解決「正則表達式到pattern參數」的問題,任何preg函數都需要這一步。下一節給出了解決辦法。