
The Preg Function Interface
PHP正則引擎的處理方式完全是程序式的(☞95),包括表10-2頂端的6個函數,表格還列舉了4個有用的函數,將在本章後面提到。
表10-2:PHP Preg函數概覽
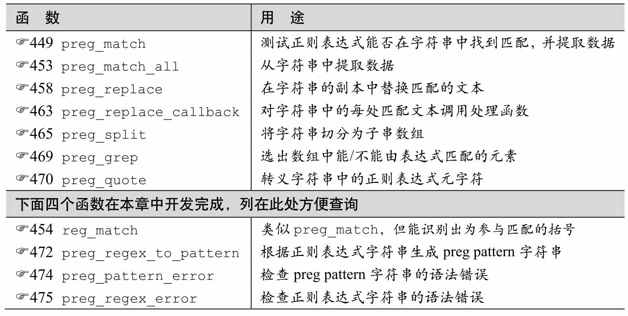
每個函數的具體功能都取決於參數的個數、標誌位(flag),以及正則表達式所使用的模式修飾符。在深入細節之前我們先通過幾個例子來看看PHP中的正則表達式的例子和處理方式。


最後的程序,如果輸入『Larry,·Curly,· Moe』,返回三個元素的數組:『Larry』,『Curly』和『Moe』。
「pattern」參數
\"Pattern\"Arguments
所有preg函數的第一個參數都是pattern,正則表達式包含在一對分隔符之內,可能還跟有模式修飾符。在上面的第一個例子中,pattern參數是『/<tableb/i』,也就是包含在一對斜線(分隔符)裡頭的「<tableb」,然後是模式修飾符i(不區分大小寫的匹配)。
PHP單引號字符串
因為正則表達式很有可能包含反斜線,,所以在以字符串文字方式提供pattern參數時,最好使用PHP的單引號字符串。第3章介紹了PHP的字符串文字(☞103),簡單地說,如果使用單引號字符串文本,正則表達式就可以省略許多額外的轉義。PHP 的單引號字符串只有兩個元序列,『』』和『\\』,分別代表單引號和反斜線。
有一種轉義需要特別注意,就是在正則表達式中使用「\\」匹配一個反斜線字符。在單引號字符串中,每個「」都應表示為\\,所以「\\」就成了\\\\。四個反斜線才能匹配一個反斜線字符,這真神奇!
(473頁有反斜線繁複到極端的例子。)
舉個具體的例子,用正則表達式匹配Windows系統中的分區名,例如『C:』。可以用正則表達式「^[A-Z]:\\$」,表示為單引號字符串文字就是『^[A-Z]:\\\\$』。
第5章第190頁有一個例子,「^.*\\」作為pattern字符串時應該寫成『/^.*\\/』,使用3個反斜線。照此類推,我找到這幾個例子:

頭兩個例子儘管方式不同,結果卻是一樣的。在第一個例子中,結尾的『/』\'對於單引號字符串文字並不是特殊文本,所以它就等於字符串的值。第二個例子中,『\\』對於字符串文字來說有特殊含義,所以輸出的字符串中出現單個『』。它與後面的字符(斜線)放在一起,得到與第一個例子同樣的『/』。同樣的道理,第三個和第四個例子也會得到同樣的結果。
當然,你也可以使用PHP的雙引號字符串文本,但是它們要麻煩許多。它們支持許多字符串元序列,這些在正則表達式字符串中都必須特殊處理。
分隔符
preg引擎要求正則表達式兩端必須有分隔符,因為設計者希望它看起來更像Perl,尤其在模式修飾符的使用方法上更是如此。有的程序員覺得在正則表達式兩端添加分隔符簡直是多此一舉,但是無論好還是不好,規定就是規定(第448也給出了一個「不好」的原因)。
常見的做法是使用斜線作為分隔符,不過我們還可以用除了字母、數字、反斜線和空白字符之外的任何ASCII字符做分隔符。最常見的是一對斜線,但兩個『!』和『#』也很常見。
如果第一個分隔符表示「開(opening)」:
{(< [
對應的「閉」分隔符就是:
}) >]
如果使用這樣「配對」的分隔符,分隔符就可能嵌套,所以『((d+))』也可以用作pattern字符串。其中,外面的括號是模式字符串分隔符,內部的括號屬於分隔符之內的正則表達式。為了清晰起見,我會避免這種情況,使用簡單易懂的『/(d+)/』。
pattern字符串內部可以出現轉義的分隔符,所以『/<B>(.*?)</B>/i』並沒有錯,不過換一組分隔符可能看得更清楚,例如『!<B>(.*?)</B>!i』使用『!…!』作為分隔符,而『{<B>(.*?)</B>}i』使用『{…}』。
模式修飾符
在結束分隔符之後可以跟隨多種模式修飾符(用PHP的術語來說,叫做pattern modifier),在某些情況下,修飾符也可以出現在正則表達式內部,修飾模式的某些性質。我們已經在一些例子中看到過表示不區分大小寫的模式修飾符i。下面簡要介紹模式修飾符:
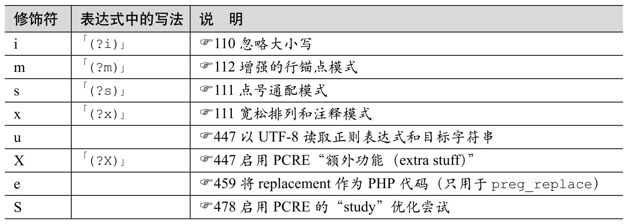
下面三個很少用到

表達式內部的模式修飾符 在正則表達式內部,模式修飾符可以單獨出現,來啟用或停用某些特性(例如用「(?i)」來啟用不區分大小寫的匹配,用「(?-i)」來停用☞135)。此時,它們的作用範圍持續到對應的結束括號,如果不存在,就持續到正則表達式的末尾。
他們也可以用作模式修飾範圍(☞135),例如「(?i:…)」表示對此括號內的內容進行不區分大小寫的匹配,「(?-sm:…)」表示在此範圍內停用s和m模式。
正則表達式之外,結束分隔符之後的模式修飾符可以以任何順序組織,下例中的『si』表示同時啟用不區分大小寫和點號通配模式:
if (preg_match(\'{<title>(.*?)</title>}si\',$html,$captures))
PHP特有的修飾符 列表最上端的4個模式修飾符屬於標準修飾符,在第3章(☞110)已經討論過。修飾符e只能在preg_replace中使用,詳細的討論見對應的小節(☞459)。
模式修飾符u告訴preg引擎,以UTF-8編碼處理正則表達式和目標字符串。此模式修飾符不會修改數據,只是更改正則引擎處理數據的方式。默認(也就是未使用模式修飾符u)的情況下,preg引擎認為接收的數據都是8位編碼的(☞87)。如果用戶知道數據是UTF-8編碼的,請使用此修飾符,否則請不要使用。在UTF-8編碼中,非ASCII字符以多個字節來存儲,使用u修飾符能夠確保多個字節會被作為單個字符來處理。
模式修飾符X啟用PCRE的「額外功能(extra stuff)」,目前它只有一個效果:如果出現了無法識別的反斜線序列,就報告錯誤。例如,默認情況下,「k」在PCRE中沒有特殊意義,就等價於「k」(因為這不是一個已知的元序列,所以反斜線會被忽略)。如果使用了模式修飾符X,就會報告「unrecognized character follows」。
未來版本的 PHP 可能包含更高版本的 PCRE,其中當前沒有特殊意義的反斜線組合可能被賦予新的意義,所以為了保持未來的兼容性(以及一般可讀性),最好是不要轉義不需要的字母,除非它們現在有特殊意義。從這個意義上說,模式修飾符X 意義重大,因為它可以發現這樣的錯誤。
模式修飾符S調用PCRE的「study(研究)」特性,預先分析正則表達式,在某些順利的情況下,在嘗試匹配時速度會大大提升。本章中關於效率的內容將對此有介紹,請參考第478頁。
剩下的模式修飾符實用價值不大,也不常用:
●模式修飾符A把匹配錨定在第一次嘗試的位置,就等於整個正則表達式以「G」開頭。如果用第4章的汽車的類比,這就是關閉傳動機構的「驅動過程」(☞148)。
●模式修飾符D會把每個「$」替換為「z」(☞112),即「$」匹配字符串的末尾,而不是字符串之內的換行符。
●模式修飾符 U 交換元字符的匹配優先含義:「*」和「*?」交換,「+」和「+?」交換,等等。我猜這個模式修飾符的主要作用在於製造混亂,所以我完全不推薦使用它。
