
Perl Efficiency Issues
在大多數情況下,Perl中正則表達式的效率問題與任何使用傳統NFA的工具一樣。第6章介紹的技巧——內部優化、消除循環,以及「開動你的大腦」,都適用於Perl。
當然,Perl也有專屬於自己的問題,這一節我們就來看看:
●辦法不止一種 Perl就像一個工具箱,同一種問題可以用許多辦法來解決。理解了Perl的思維方式,就會明白哪些問題是釘子,但是選擇合適的錘子還需要花很多工夫來編寫高效而易於理解的程序。有時候,效率和易於理解似乎是不相容的,不過一旦理解深入了,就能做出更好的選擇。
●表達式編譯、qr/…/、/o 修飾符和效率 正則運算符的編譯和插值,做得好的話能節省大量的時間。/o 修飾符還沒有詳細講解,它配合 regex 對像(qr/…/),能夠調控耗費時間的重編譯過程。
●$&的負面影響 伴隨效應設定的變量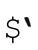 、$&和
、$&和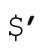 ,也許很方便,但存在不易發現的效率陷阱,哪怕只出現了一次,也可能帶來麻煩。所以並不是非得使用它們——只要腳本中出現了任意一個變量,負面影響就不可避免。
,也許很方便,但存在不易發現的效率陷阱,哪怕只出現了一次,也可能帶來麻煩。所以並不是非得使用它們——只要腳本中出現了任意一個變量,負面影響就不可避免。
●Study 函數 近年來,Perl 提供了 study(…)函數。按照預期,它能提高正則表達式的速度,但是似乎沒有人真正知道它是否能提高速度,以及背後的原因。
●性能測試 性能測試的規矩就是,越快的程序終止得越早(你可以引用我的話)。無論小型函數、大型函數,還是處理真實數據的整個程序,性能測試都是判斷速度的最終標準。儘管性能測試有各種各樣的辦法,Perl 中的性能測試卻是簡單而輕鬆的。我會給出我用的辦法,這個辦法在寫作本書時做過數百次性能測試。
●正則表達式調試 Perl的正則表達式調試標識位(debug flag)可以告訴我們,正則引擎和傳動裝置對正則表達式進行了哪些優化。下面會講解如何查看這些信息,以及 Perl包含了哪些秘密。
辦法不只一種
"There's More Than One Way to Do It"
通常,一個問題總是有許多種解法,所以在權衡效率和可讀性時,應該做的就是瞭解所有的辦法。來看個簡單的問題,修改一個IP地址,例如『18.181.0.24』,保證每一段都包含三位數字:『018.181.000.024』。簡單的辦法是:
$ip=sprintf(〞%03d.%03d.%03d.%03d〞,split(/\./,$ip));
這辦法當然沒錯,但顯然還有其他的解決辦法。表7-6列出了好幾種辦法,比較了它們的效率(按照效率排序,最上面的效率最高)。這個例子的目的很簡單,本身也沒有太多價值,但是它能代表簡單的文本處理任務,所以我鼓勵你花一點時間理解各種辦法。可能有些技巧你沒見過。
如果輸入格式正確的 IP,每個辦法都能到正確的結果,但是如果輸入別的數據則可能會出錯。如果數據是不規範的,可能就需要多花點心思。除此之外,實際差別在於效率和可讀性。就可讀性而言,#1和#13似乎是最好理解的(儘管效率上存在巨大的差異)。同樣易於理解的是#3和#4(類似#1),以及#8(類似#13)。其他解法都太過複雜了。
那麼效率呢?為什麼不同的解法有不同的效率?原因在於NFA的工作原理(第4章),Perl的各種正則優化措施(第 6 章),以及其他 Perl 結構的處理速度(例如 sprintf,以及substitution運算符的機制)。substitution運算符的/e修飾符,有時候雖然不可或缺,但效率低的解法似乎都使用了它。
比較#3和#4,#8和#14很有意義。這兩對正則表達式的區別只是在於括號——沒有括號的表達式要比有括號的稍快一點。#8使用$&來避免括號帶來的高昂代價,性能測試卻無法體現這一點(☞355)。
表達式編譯、/o修飾符、qr/…/和效率
Regex Compilation,the/o Modifier,qr/…/,and Efficiency
Perl中與表達式效率相關的另一個重點是,程序遇到正則運算符之後,在實際應用正則表達式前,Perl必須在幕後進行預處理工作。真正的準備工作依賴於正則運算元的類型。在大多數情況下,正則運算元是正則文字,例如m/…/、s/…/…/或qr/…/。Perl必須對它們進行幕後處理,而處理需要的時間,如果可能應該盡力避免。首先,讓我們來看要做的事情,然後講解如何避免。
表7-6:填補IP地址的若干解法

預處理正則表達式的內部機制
預處理正則運算元的機制在第6章有所涉及(241),不過Perl還有自己的處理。
Perl對正則運算符的預處理大致分為兩步:
1. 正則文字處理 如果運算符是正則文字,就按照「正則文字的解析方式」(☞292)中的描
述來處理。變量插值就發生在這一步。
2. 正則編譯 檢查正則表達式,如果符合規則,就將其編譯為適用於正則引擎實際應用的內
在狀態(如果不符合規則,則報錯)。
正則表達式編譯完成之後,就能夠實際應用到目標字符串中,參見第4到第6章。
並不是每使用一次正則運算符,就需要進行一次預處理。但是正則文字第一次使用時,必須進行預處理,但如果多次執行同樣的正則文字(例如在循環中,或是調用多次的函數),Perl 有時候能夠重用之前的工作。下一節說明了 Perl 如何做到這一點,以及程序員可以使用的提高效率的技巧。
減少正則編譯的步驟
下面幾節中我們會見到 Perl 避免某些正則文字相關預處理的兩種辦法:無條件緩存(unconditional caching)和按需重編譯(on-demand recompilation)。
無條件緩存
如果正則文字中沒有插值變量,Perl就知道這個正則表達式在兩次應用之間不會變化,所以第一次編譯完成之後,會保存編譯的形式(「緩存」),以備將來使用。無論正則表達式會執行多少次,只需要檢查和編譯一次。本書中的大多數正則表達式都沒有變量插值,因此從這個方面來說效率無可挑剔。
內嵌代碼和動態正則結構中的變量則不屬於此類,因為它們不會插值到正則表達式中,而是作為正則表達式執行的固定代碼的一部分。有時候,你可能希望每次執行都解釋內嵌代碼中引用的my變量,請不要忘記第338頁的忠告。
有一點要說清楚,緩存的持續時間與代碼的執行時間相同,下次運行同樣代碼時不會有任何的緩存。
按需重編譯
並不是所有的正則運算元都能夠直接緩存,比如下面的代碼:

m/^$today:/中的正則表達式需要插值,雖然在循環中使用,但每輪循環的插值結構是相同的。所以一再重複編譯同樣的表達式的效率很低,所以 Perl 會自動進行簡單的字符串檢查,比較本次和上次插值的結果。如果相同,就使用上次的緩存。如果不同,就重新編譯正則表達式。所以,對比緩存值並重新插值盡可能避免了相對更耗時的編譯。
這樣究竟能節省多少時間呢?非常多。舉例來說,我測試了第303頁的$HttpUrl(使用擴展的$HostnameRegex)的三種預處理方式。設計的性能測試能準確體現預處理的開銷(使用插值、字符串檢查、編譯,以及其他後台任務),而不是表達式應用的整體開銷,因為在任何情況下這種應用的時間都是一樣的。
結果非常有意思。我運行了沒有插值的版本(整個正則表達式都硬編碼在 m/…/中),用它作為比較的基礎。如果正則表達式每輪循環不會改變,比較並插值大概需要25倍的時間。完整的預處理(每輪循環都要重新編譯)大概需要1 000倍的時間,這數字真驚人!
應用到實際場合就會發現,完整的預處理即使比靜態正則文字預處理要慢1 000倍,在我的機器上也只需要大約0.00026秒(測試的速度是每秒3 846次,相反,靜態正則文字預處理的速度是每秒370萬次)。當然,不使用插值能夠節省的時間非常可觀,不進行重編譯節省的時間顯然也很可觀。下面幾節,我們會考察如何在更多情況下使用這些技巧。
表示「一次性編譯」的/o修飾符
簡單地說,如果正則文字運算元中使用了/o修飾符,它就會只會檢查和編譯一次,而無論是否包含插值。如果沒有插值,添加/o不會有任何改變,因為沒有插值的表達式總是會自動緩存。但如果使用了插值,程序執行第一次遇到正則文字時,會進行正常的完整的預處理,但因為/o的存在,內在狀態會存儲下來。如果之後又遇到這個正則運算元,就會直接調用緩存。
下面這個例子之前也出現過,只是現在添加了/o:

這個表達式要快得多,因為從第二次開始的每輪循環中,正則表達式都忽略了$today。不需要插值,也不需要預處理和重新編譯正則表達式,能夠節省大量的時間,而這是 Perl 無法自動完成的,因為使用了變量插值,$today可能會變化,所以為了安全,Perl必須每次都檢查。使用/o就告訴 Perl,在第一次預處理和編譯完成之後「鎖定」這個表達式。因為我們知道,插值變量是不變的,即使變化了,也不希望使用新值,所以這樣做完全沒問題。
/o的潛在「陷阱」
在使用/o時,有個重要的「陷阱」必須要注意。例如下面這個函數:

記住,/o表示正則運算元只需要編譯一次。第一次調用CheckLogfileForToday()時,代表當天日期的正則運算元就鎖定在其中。如果過了一段時間再次調用這個函數,即使$today變化了,也不會重新檢查;在程序執行過程中,每次使用的都是最開始鎖定在其中的正則表達式。
這個問題很嚴重,不過下一節中,regex對像提供了兩全其美的解決辦法。
用regex對像提高效率
迄今為止,我們看到的所有關於預處理的討論都適用於正則文字。其目的在於花盡可能少的工夫獲得編譯好的正則表達式。達到此目的的另一個辦法是使用regex對象,把編譯好的正則表達式封裝在變量內部供程序使用。可以使用qr/…/創建regex對像(☞303)。
下面是使用regex對象的例子:

每調用一次函數,就會創建一個新的regex對象,但是之後它只是直接用於log文件的每一行。如果regex對像用做運算元,它不會進行前面介紹的任何預處理。預處理是在regex對像創建而不是使用時進行的。可以把regex 對像想像為「自動設定的正則緩存」,這個編譯好的表達式可以在任何地方使用。
這個辦法兼具了兩方面的優點:它效率高,因為只有在每次函數調用(而不是log文件的每一行)時才會編譯,但是,與之前錯誤使用/o的例子不同,即使多次調用CheckLogfile-ForToday(),也沒有問題。
需要弄清楚的是,這個例子中出現了兩個正則運算元。正則運算元qr/…/並不是一個regex對象,但能從接收的正則文字創建 regex 對象。然後這個對象用作循環中 match 運算符=~的運算元。
regex對像配合m/…/
這段程序:
if ($_=~$RegexObj) {
也可以這樣寫:
if (m/$RegexObj/) {
此時已經不是普通的正則文字了,儘管看上去沒有區別。「正則文字」的內容就是regex 對象,它與直接使用regex 對像一樣。這種做法的好處在於:m/…/更為常見,更容易使用。也不用明確指定目標字符串$_,方便與其他使用同樣默認變量的運算符結合。最後一個原因是,這樣我們能夠對regex對像使用/g。
/o配合qr/…/
/o修飾符可以配合qr/…/,但在這裡你肯定不希望如此。就像用/o配合其他任何正則運算符一樣,qr/…/o在第一次使用正則表達式時就會進行鎖定,所以如果這樣寫,無論$today如何變化,每次調用這個函數$RegexObj使用的都是同樣的 regex 對象。這與第 352 頁的m/…/o的問題一樣。
依靠默認表達式提高效率
正則運算符的默認表達式(☞308)可以提高效率,儘管使用 regex 對象可能更划算。不過我還是會簡要介紹一番。例如:

使用默認正則表達式的關鍵在於,只有匹配成功才會設置默認值,所以$today設置之後還有長長的代碼。你已經看到,這相當不美觀,所以我不推薦這麼做。
理解「原文」副本
Understanding the"Pre-Match"Copy
在匹配和替換時,Perl 有時必須動用額外的空間和時間來保存目標字符串在匹配之前的副本。我們會看到,有時這個副本會用於支持重要特性,有時則不會。應該盡量避免不會用到的副本,提高效率,尤其是在目標字符串很長,或者速度非常重要的情況下更是如此。
下一節我們會講解何時以及為什麼 Perl 可能會保存目標字符串的原文副本,什麼時候用到副本,以及在效率極端重要時,如何取消這個副本來提高效率。
通過原文副本支持$1、$&、$'、$+…
對於match或者substitution操作的目標字符串,Perl會生成一個原文副本,以支持$1、$&之類匹配後的變量(☞299)。每次匹配完成之後,Perl不會實際生成這些變量,因為許多變量(還有可能是所有)根本不會被程序用到。相反,Perl只是保存原始字符串的副本,記住各種匹配發生在原來文本中的位置,在使用$1之類變量時通過位置來引用。這種辦法不錯,工作量小,因為多數情況下都不會用到某些甚至全部的匹配後的變量。這種「延遲求值(lazy evaluation)」能避免許多不必要的工作。
儘管延遲創建$1之類的變量能夠節省工作量,但保存目標字符串的副本仍然需要成本。而這是必要的嗎?為什麼不能直接使用原來的文本?請參考:
$Subject=~s/^(?:Re:\s*)+//;
這樣,$&正確地引用了$Subject 中刪除的文本,但因為它已經從$Subject 中刪除,在後面用到$&時,Perl不能從$Subject中引用這段文本。下面的代碼情況相同:

引用$1時,原來的$Subject已經刪除了。所以,Perl必須保存原文副本。
原文副本並非時時必須
在實踐中,原文副本的主要「用戶」是$1、$2、$3之類的變量。但是如果正則表達式不包含捕獲型括號呢?那樣就不必擔心$1之類了,所以完全不必考慮如何支持它們。所以至少,不包含捕獲型括號的正則表達式可以不必保存拷貝?答案是未必。
不宜使用的變量:
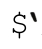 、$&和$
、$&和$
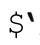 、$&、
、$&、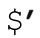 這三個變量與捕獲型括號無關。它們分別對應到匹配文本之前的部分,匹配文本和匹配之後的部分,其實可以應用於每一次match和substitution。Perl不能預先知道某個匹配中是否會用到這些變量,所以每次都必須保存原文副本。
這三個變量與捕獲型括號無關。它們分別對應到匹配文本之前的部分,匹配文本和匹配之後的部分,其實可以應用於每一次match和substitution。Perl不能預先知道某個匹配中是否會用到這些變量,所以每次都必須保存原文副本。
聽起來,似乎沒有辦法省略副本,但是 Perl 足夠聰明,它能夠認識到,如果這些變量不會出現在程序中,就根本沒必要(甚至在任何可能用到的library之中)保存副本來提供支持。所以,如果沒有用到捕獲型括號,再避免出現、$&和就能省略原文副本——這是很棒的優化!只要在程序中的任何一處用到了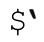 、$&和
、$&和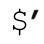 三者之一,整個優化即告失效。這可不夠意思!所以,我認為這些變量是「不宜使用(naughty)」的。
三者之一,整個優化即告失效。這可不夠意思!所以,我認為這些變量是「不宜使用(naughty)」的。
原文副本的代價有多高
我進行了簡單的性能測試,對Perl源代碼的130 000行C程序中的每一行檢查m/c/。這個性能測試僅僅檢測哪一行出現了字符『c』。測試的目的是衡量原文副本的影響。我用兩種方法進行測試:一種肯定沒有用到原文副本,一種肯定用到了。因此,唯一的區別就在於保存副本的開銷。
保存原文副本的程序所用的時間要長40%。這代表了「平均最差情況」,這樣說是因為性能測試並沒有進行什麼實質性的操作,否則二者之間的時間相對比例會減小(甚至顯得微不足道)。
另一方面,在真正的最壞情況下,額外副本可能真的佔據非常重要的比重。我對同樣的數據運行同樣的程序,但是這次將所有超過3.5MB的數據都放在一行中,而不是長度合適的130 000行。這樣就能比較單次匹配的相對表現。不使用原文副本的匹配幾乎是立刻就得到了結果,因為第一個『c』字符離開頭不遠,匹配之後程序就運行結束。而使用原文副本的程序運行原理差不多,只是它會首先拷貝整個字符串。它所用的時間大約是前者的7 000倍。因此我們知道,避免使用某些結構能夠提高效率。
避免使用原文副本
如果 Perl 能夠領會程序員的意圖,只在需要的情況下保存副本,當然很好。但請記住,這些副本並不是「敗筆」——Perl在幕後處理這些繁瑣事務是我們選擇Perl,而不是C或者彙編語言的原因。事實上,Perl最初只是為了把用戶從繁雜的機制中解放出來,這樣他們只需要關注問題的解決方案就好了。
永遠不要使用不宜使用的變量。同樣,盡可能避免額外的工作也是不錯的。首先想到的就是,永遠不要在代碼中使用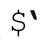 、$&和
、$&和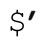 。通常,$&很容易消除——把正則表達式包圍在一個捕獲型括號內,然後使用$1 即可。舉例來說,把 HTML tag 轉換為小寫時,不使用s/<\w+>/\L$&\E/g,而使用s/(<\w+>)/\L$1\E/g。
。通常,$&很容易消除——把正則表達式包圍在一個捕獲型括號內,然後使用$1 即可。舉例來說,把 HTML tag 轉換為小寫時,不使用s/<\w+>/\L$&\E/g,而使用s/(<\w+>)/\L$1\E/g。
如果保存了原始目標字符串,就可以很容易地模擬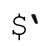 和
和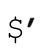 。匹配某個target字符串之後,可以按下面的規則來模擬:
。匹配某個target字符串之後,可以按下面的規則來模擬:

因為@-和@+(302)保存的是原始目標字符串中的位置,而不是確切的文本,使用它們不需要擔心效率問題。
我還給出了$&的模擬。相對使用捕獲型括號和$1的辦法,這可能是一個更好的辦法,這樣完全不必使用任何捕獲型括號。請記住,避免使用$&之類變量的目的就在於,如果表達式中沒有出現捕獲型括號,要避免保存原始副本。如果修改程序,去掉$&,再對每個匹配都增加捕獲型括號,就不會節省任何時間。
不要使用不宜使用的模塊。當然,避免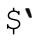 、$&、
、$&、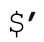 也意味著避免使用調用它們的模塊。Perl的核心模塊中,除English之外都沒有使用它們。如果你希望使用English模塊,可以這樣:
也意味著避免使用調用它們的模塊。Perl的核心模塊中,除English之外都沒有使用它們。如果你希望使用English模塊,可以這樣:
use English'-no_match_vars';
這樣就沒有問題了。如果你從 CPAN 或者其他地方下載了模塊,你可能需要檢查一番,看看它們是否使用了這些變量。請參考下一頁的補充內容,裡面有些訣竅,告訴你如何判斷程序是否用到了這些變量。

Study函數
The Study Function
與優化正則表達式本身不同,study(…)優化了對特定字符串的某些檢索。一個字符串在study 之後,應用到它的(一個或多個)正則表達式可以從緩存的分析數據中受益。一般是這樣使用的:

study 的作用很簡單,但是理解它什麼情況下有價值卻不簡單。它不會影響到程序的任何值和任何結果,唯一的影響就是,Perl會使用更多的內存,總的執行時間可能會增加,保持不變,或者減少(這是我們預期的)。
study一個字符串時,Perl會分配時間和內存來記錄字符串中的一系列位置(在大多數系統中,需要的內存是字符串大小的4倍)。在字符串修改之前,針對此字符串的每次匹配都可以從中受益。對字符串的任何修改都會導致study數據的失效,相當於study另一個字符串。
Study 能給目標字符串提供的幫助,很大程度上取決於用來匹配的正則表達式,以及 Perl能夠使用的優化。例如用m/foo/檢索文本,如果使用了study,速度會提升很多(如果字符串更長,甚至可能提高 10 000 倍)。但是,如果使用了/i,就不會有這種效果,因為/i不會利用study的結果(和其他優化)。
不應該使用study的情況
●如果只使用/i,或是所有正則文字都受「(?i)」或「(?i:…)」作用,就不應該對字符串使用study,因為它們不能從study中受益。
●如果目標字符串很短,也不應該使用 study。因為此時,正常的固定字符串識別優化(☞247)已經足夠了。那麼「短」究竟如何界定呢?字符串的長度沒有確切的標準,所以具體來說,只有進行性能測試才能判斷study是否有益。不過權衡利弊,我通常不使用study,除非字符串的長度為若干KB。
如果你只希望在修改之前,或是 study不同的字符串之前,對目標字符串進行少數幾次匹配,請不要使用 study。如果要獲得真正的性能提升,必須是多次匹配節省下來的時間長於study的時間。如果匹配次數較少,花在study身上的時間抵不上節省的時間,得不償失。
只對期望使用包含「獨立出來的」文字(☞255)的正則表達式搜索的字符串使用study。如果不知道匹配中必須出現的字符,study 就派不上用場(看了這幾條,也許你會認為,study對index函數有益,但事實並非如此)。
什麼時候使用study
最適合使用 study的情況就是,目標字符串很長,在修改之前會進行許多次匹配。一個簡單的例子就是我在寫作本書時所用的過濾器。我用自己的標記法寫稿,然後用過濾器轉換為SGML(再轉換為troff,再轉換為PostScript)。經過過濾器內部,一整章變為一個大字符串(例如,本章的大小為475KB)。在退出之前進行多項檢查來保證不會漏過錯誤的標記。這些檢查不會修改字符串,它們通常查找固定長度的字符串,所以它們很適合於study。
性能測試
Benchmarking
如果你真的關心效率,最好的辦法就是進行性能測試。Perl 自帶的 Benchmark模塊提供了詳細的文檔("perldoc Benchmark")。可能是習慣使然,我更喜歡從自己動手寫性能測試:
use Time::HiRes'time';
我把希望測試的內容簡單包裝成:

性能測試的重要問題包括,確保性能測試進行了足夠多的工作,顯示的時間真正有意義,盡可能多地測試希望的部分,盡可能少地測試不希望的部分。在第 6 章有詳細的講解(☞232)。找到正確的測試方法可能得花些時間,但是結果可能非常有價值,也很值得。
正則表達式調試信息
Regex Debugging Information
Perl提供了數量眾多的優化措施,期望能夠盡可能快地找到匹配;第6章的「常見優化措施」(☞204)介紹了基礎的措施,但還有許多其他的措施。大多數優化只能應用於專門的情況,所以特定正則表達式只能從其中的某一些(甚至是沒有)獲益。
Perl的調試模式(debugging mode)能提供優化的信息。在正則表達式第一次編譯時,Perl會選擇這個正則表達式所使用的優化措施,而調試模式會顯示其中的一部分。調試模式同樣可以告訴我們引擎是如何應用表達式的。仔細分析這些調試信息不屬於本書的範圍,但我會在這裡給出簡要介紹。
在程序中可以通過 use re'debug';來顯示調試信息,用 no re'debug';來關閉(上文曾出現過編譯指示use re,根據不同的參數,啟用或禁用插值變量中的內嵌代碼☞337)。
如果希望在整個腳本中啟用此功能,可以使用命令行參數-Mre=debug。這很適合檢查單個的正則表達式的編譯方法。下面是一個例子(只保留了相關的行):

在∂處從shell提示符啟動perl,使用命令行參數-c(意思是檢查腳本,而不是確切執行它),-w(如果Perl對代碼存有疑問,就會發出警報),以及-Mre=debug啟用調試。-e表示下面的參數『m/^Subject:·(.*)/』是一段Perl代碼,需要運行或者檢查。
÷行報告表達式固定長度的字符串中「出現頻率最低」的字符(由 Perl 猜測)。Perl 根據這一點進行某些優化(例如預查所需字符/子串☞245)。
第≠到≒行表示Perl編譯好的正則表達式。因為篇幅的原因,我們在這裡不會花太多的工夫。不過,即使是隨便看看,第≡行也不難理解。
第…行對應大多數行為。可能顯示的信息包括:
Anchored'string'at offset
它表示匹配必須包含某個字符串,此字符串在匹配中的偏移值為 offset。如果$緊跟在'String'之後,那麼string是匹配結尾的元素。
floating'string'at from..to
它表示匹配必須包含某個字符串,此字符串在匹配中處於從from(開始)到to(結束)中的任意位置。如果$緊跟在'String'之後,string是匹配結尾元素。
stclass'list'
它表示匹配可能的開始字符。
anchored(MBOL),anchored(BOL),anchored(SBOL)
說明表達式以「^」開頭。MBOL說明使用了/m修飾符,BOL和SBOL表示沒有使用(BOL和SBOL的區別在現代Perl中沒有意義。SBOL與$*變量有關,而此變量已被廢棄了)。
anchored(GPOS)
說明正則表達式以「\G」開頭。
implicit
說明anchored(MBOL)是由Perl隱式添加的,因為正則表達式以「.* 」開頭。minlen length
代表匹配成功的最小長度。
with eval
說明表達式包含「(?{…})」或是「(??{…})」。
第|行與正則表達式無關,只有當二進制代碼中的編譯啟用了-DDEBUGGING時才會出現。如果啟用,在載入整個程序之後,Perl會報告是否啟用了對$&等變量的支持(☞356)。
運行時調試信息
我們知道如何利用內嵌代碼獲得匹配的運行信息(☞331),但是 Perl 的正則表達式調試可以提供更多的信息。如果去掉表示「僅編譯」的-c選項,Perl 會提供更多關於匹配運行細節的信息。
出現「Match rejected by optimizer,」表示某種優化措施讓傳動裝置認識到,這個正則表達式永遠無法在目標字符串中匹配,所以會忽略任何嘗試,下面是一個例子:

如果啟用了調試功能,用戶可以看到所有用到的正則表達式的調試信息,而不只限於用戶提供的正則表達式。例如:

它沒有進行任何操作,只是裝載了 warning模塊,但是因為這個模塊包含正則表達式,我們仍然會見到許多調試信息。
顯示調試信息的其他辦法
我已經提到,可以使用「use re'debug';」或-Mre=debug來啟用正則表達式的調試。不過,如果把所有的 debug替換為 debugcolor,而終端又支持ANSI 轉義控制字符(ANSI terminal control escape sequences),輸出的信息就會以高亮標記,更容易閱讀。
另一個辦法是,如果 Perl 二進制代碼在編譯時啟用了調試支持,可以使用命令行參數-Dr來表示-Mre=debug。