
The Freeflowing Regex
我們花了不少時間來構建匹配 C 的註釋的正則表達式,但是沒有考慮如何避免字符串中的錯誤匹配。使用Perl的話,你可能會想到用下面的程序過濾註釋:
$prog=~s{/*[^*]**+(?:[^/*][^*]**+)*/}{}g;#去掉C語言註釋(但有錯誤!)
表達式中,變量$prog保存的文本會被刪除(也就是,被空文本替換掉)。問題在於,如果在字符串內部找到註釋的起始標記,正則表達式的匹配也不會停止,比如這段C代碼:
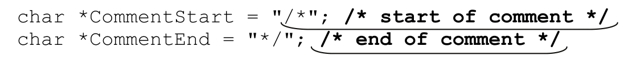
這裡,下畫線標注的部分是正則表達式的匹配結果,但是粗體標注的部分才是我們期望的。引擎尋找匹配時會在目標字符串的每個位置開始嘗試匹配表達式。因為這種嘗試只有在註釋開始的地方(或者是看起來有可能開始的地方)成功,所以在大部分位置都無法匹配,傳動裝置的驅動過程繼續向前,進入雙引號字符串,其內容似乎是註釋的開始。最好是能夠告訴正則引擎,遇見雙引號字符串時是應該嘗試匹配還是直接跳過。當然,我們確實能做到這一點。
引導匹配的工具
A Helping Hand to Guide the Match
看下面的程序:
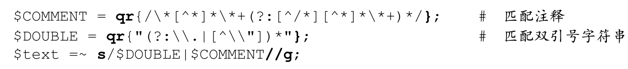
這裡出現了兩件新事物。其中之一是表達式「$DOUBLE|$COMMENT」,它由兩個變量組成,都使用了Perl特有的qr/…/正則表達式「雙引號字符串」操作符。我們曾在第3章仔細討論過(☞101),如果用字符串表示正則表達式,使用字符串的時候必須格外小心。Perl提供的qr/…/運算符解決了這個問題,它會把操作對像(operand)視為正則表達式,但不會實際應用它。我們在第2章(☞76)已經看到,這樣非常方便。與m/…/和s/…/…/一樣,我們可以自己選擇分隔符(☞71),上面使用的是花括號。
另一點是通過用$DOUBLE來匹配雙引號字符串。傳動裝置驅動到$DOUBLE能匹配的位置時,會一次性匹配整個雙引號字符串。這裡使用多選分支完全沒有問題,因為二者之間並沒有重疊。如果我們從左向右掃瞄這個正則表達式就會發現,應用到字符串時,存在三種可能:
●註釋部分能夠匹配,於是一次性匹配註釋部分,直接到達註釋的末尾,或者…
●雙引號字符串部分能夠匹配,於是一次性匹配雙引號字符串,直接到達其結尾,或者…
●上面兩者都不能匹配,本輪嘗試失敗。啟動驅動過程,跳過一個字符。
這樣,正則表達式永遠不會從雙引號字符串或者註釋內部開始嘗試,這就是成功的關鍵。實際上,到目前為止還不夠,因為這個表達式在刪除註釋的同時也會刪除雙引號字符串,不過我們只需要再修改一小點就可以了。
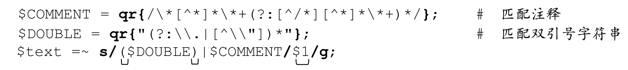
唯一的區別在於:
●設置了捕獲型括號,如果能夠匹配雙引號字符串對應的多選分支,則$1會保存對應的內容。如果匹配通過註釋多選分支,$1為空。
●把replacement的值設置為$1。結果就是,如果雙引號字符串匹配了,replacement就等於雙引號字符串——並沒有發生刪除操作,替換不會進行任何修改(不過存在伴隨效應,即一次性匹配這個雙引號字符串,直接到達其結尾,這就是把它放在多選結構首位的原因)。另一方面,如果匹配註釋的多選分支能夠匹配,$1 為空,所以會按照期望刪除註釋(注8)。
最後我們還必須小心對付單引號的C常量,例如\'t\'。這很容易——只需要在括號內添加另外一個多選分支。如果我們希望去掉 C++、Java、C#的//的註釋,就可以把「//[^n]*」作為第四個多選分支,列在括號外。
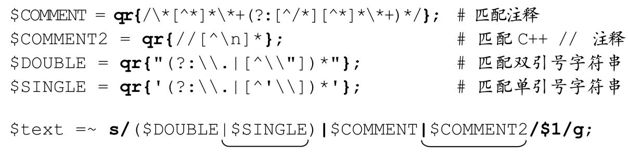
基本原理很好懂:引擎檢查文本,迅速捕獲(如果合適,則是刪除)這些特殊結果。在我的老機器(配置大概停留在1997年的水平)上,Perl腳本在16.4秒的時間內去掉了16MB,500 000行的測試文件中的註釋。這已經很快了,不過我們仍然需要提高速度。
引導良好的正則表達式速度很快
A Well-Guided Regex is a Fast Regex
暫停一會兒,我們能夠直接控制這個正則引擎的運轉,進一步提高匹配速度。來考慮註釋和字符串之間的普通 C 代碼。在每個位置,正則引擎都必須嘗試四個多選分支,才能確認是否能匹配,只有四個多選分支都匹配失敗,它才會前進到下一個位置,這些複雜工作其實是不必要的。
我們知道,如果其中任何一個多選分支有機會匹配,開頭的字符都必須是斜線、單引號或是雙引號。這些字符並不能保證能夠匹配,但是不滿足這些條件絕對不能匹配。所以,與其讓引擎緩慢而痛苦地認識到這一點,不如把「[^\'〞/]」作為多選分支,直接告訴引擎。實際上,同一行中任何數量的此類字符都能歸為一個單元,所以我們使用「[^\'〞/]+」。如果你記得無休止匹配,可能會為添加的加號擔心。確實,如果在某種(…)*循環中,它可能是很大的問題,但是在這個例子中,它完全沒有問題(之後沒有元素強迫它回溯),所以,添加:

出於某些我們即將要看到的原因,我把加號量詞放在$OTHER之後,而不是$OTHER的內容之中。
我重新進行了性能測試,出乎意料的是,這樣可以減少 75%的時間。通過改進,這個表達式節省了頻繁嘗試所有多選分支的大部分時間。仍然有些情況,所有多選分支都不能匹配(例如『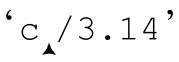 』),此時,我們只能接受驅動過程。
』),此時,我們只能接受驅動過程。
不過,事情還沒有結束,我們仍然可以讓表達式更快:
●在大多數情況下,最常用的多選分支可能是「$OTHER+」,所以我們把它排在第一位。POSIX NFA沒有這個問題,因為它總會檢查所有的多選分支,但是對於傳統型NFA,它只要找到匹配就會停止,為什麼不把最可能出現的多選分支放在第一位呢?
●一個引用字符串匹配之後,在其他字符串和註釋匹配之前,很可能出現的就是$OTHER的匹配。若在每個元素之後都添加「$OTHER*」,就能夠告訴引擎下面必須匹配$OTHER,而不用馬上進入下一輪/g循環。
這與消除循環的技巧是很相似的,此技巧之所以能提高速度,是因為它主導了正則引擎的匹配。這裡我們使用了關於全局匹配的知識來進行局部優化,給引擎提供快速運轉必須的條件。
非常重要是,「$OTHER*」是加在每個匹配引用字符串的子表達式之後的,而之前的$OTHER(排在多選結構最前面的)必須用加號量詞。如果你不清楚原因,請考慮下面的情況:添加的是$OTHER+,而某行中有兩個連在一起的雙引號字符串。同樣,如果開頭的$OTHER使用星號量詞,則任何情況都能匹配。
最終得到:
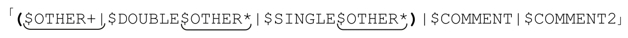
這個表達式能把時間再減少5%。
回過頭來想想最後兩個改動。如果每個添加的$OTHER*匹配了過多的內容,開頭的$OTHER+(我們將其作為第一個多選分支)只有兩種情況下能夠匹配:1)它匹配的文本在整個s/…/…/g的開頭,此時還輪不到引用字符串的匹配;2)在任意一段註釋之後。
你可能會想「從第二點考慮,我們不妨在註釋後添加$OTHER+」。這很不錯,只是我們希望用第一對括號內的表達式匹配所有希望保留的文本——不要把孩子連洗澡水一起倒掉。
那麼,如果$OTHER+出現在註釋之後,我們是否需要把它放在開頭呢?我覺得,這取決於所應用的數據——如果註釋比引用字符串更多,答案就是肯定的,把它放在第一位有意義。否則,我就會把它放後面。從測試數據來看,把它放在前面的效果更好。排在後面大約會損失最後的修改一半的效率。
完工
Wrapup
事情還沒有結束。不要忘記,每個匹配引號字符串的子表達式都應該消除循環,本章已經花了很長的篇幅講解這個問題。所以,最後我們要把這兩個子表達式替換為:
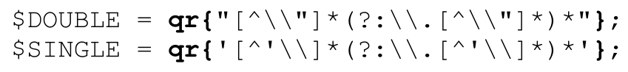
這樣修改節省了15%的時間。這些細小的修改把匹配的時間從16.4秒縮短到2.3秒,提升了7倍。
最後的修改還說明,用變量來構建正則表達式多麼方便。$DOUBLE 可以作為單獨的元素獨立出來,可以改變,而不需要修改整個正則表達式。雖然還會存在一些整體性問題(包括捕獲文本括號的計數),但這個技巧確實很方便。
這種便利是由 Perl 的 qr/…/操作符提供的,它表示與正則表達式相關的「字符串」。其他語言沒有提供相同的功能,但是大多數語言提供了便於構建正則表達式的字符串。請參見101頁的「作為正則表達式的字符串」。
下面是原始的正則表達式,看到它,你肯定會覺得上面的辦法非常方便。為了便於印刷,我把它分為兩行:
([^〞\'/]+|〞[^\\〞]*(?:\\.[^\\〞]*)*〞[^〞\'/]*|\'[^\'\\]*
(?:\\.[^\'\\]*)*\'[^〞\'/]*)|/*[^*]**+(?:[^/*][^*]**+)*/|//[^n]*