
Unrolling the Loop
無論系統本身支持怎樣的優化,最重要的收益或許還是來自於對引擎基本工作原理的理解,和編寫能夠配合引擎工作的表達式。所以,既然我們已經考察了繁瑣的細節,不妨登堂入室,學習我說的「消除循環」的技巧。對某些常用的表達式來說,它的加速效果很明顯。舉例來說,用它改造本章開頭(☞226)會進行無休止匹配的表達式,能夠在有限的時間內報告匹配失敗,而如果能夠匹配,速度也會更快。
此處說的「循環」採用的是「(this|that|…)*」之類問題中星號代表的意義。之前的無休止匹配「〞(\\.|[^\\〞]+)*〞」其實就屬於此類。如果無法匹配,這個表達式需要近乎無限的時間進行嘗試,所以必須改進。
此技巧有兩種不同的實現途徑:
1.我們可以檢查,在各種典型匹配中,「(\\.|[^\\〞]+)*」中的哪個部分真正匹配成功了,這樣就能留下子表達式的痕跡。再根據剛剛發現的模式,重新構建高效的表達式。這個(或許聯繫不那麼緊密的)概念模型就是一個大球,它表示表達式「(…)*」,球在某些文本上滾動。「(…)」內的元素總是能夠匹配某些文本,這樣就留下了痕跡,就好像是把髒兮兮的雪球在地毯上滾過去一樣。
2.另一個辦法是,從更高的層面考察我們期望用於匹配的結構。然後根據我們認為的常見情形,對可能出現的目標字符串做出非正式假設。從這個角度出發構建有效的表達式。
無論採取哪種辦法,得到的表達式都是一樣的。我首先講解第一種思路,然後介紹如何通過第二種思路取得同樣的結果。
為了保證例子容易看懂,並盡可能廣泛地使用,我會使用「(…)」來代替所有括號,如果程序支持非捕獲型括號「(?:…)」能夠支持,使用它們能提高效率。然後會講解固化分組(☞139)和佔有優先量詞(☞142)的使用。
方法1:依據經驗構建正則表達式
Method 1:Building a Regex From Past Experiences
在分析「〞(\\.|[^\\〞]+)*〞」時,用若干具體的字符串來檢驗全局匹配的具體情況是很自然的做法。舉例來說,如果目標字符串是『〞hi〞』,那麼使用的自表達式就是「〞[^\\〞]+〞」。這說明,全局匹配使用了最開始的「〞」,然後是多選分支「[^\\〞]+」,然後是末尾的「〞」。
如果目標字符串是:
〞he said\〞hi there\〞 and left〞
對應的表達式就是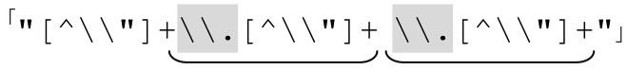 。在這個例子裡以及表6-2中,我標記了對應的正則表達式,讓模式更顯眼。如果我們能對每個輸入字符串構造特定的表達式當然很好。這不可能,但我們能夠找出一些常用的模式,構造效率更高,又不失通用性的正則表達式。
。在這個例子裡以及表6-2中,我標記了對應的正則表達式,讓模式更顯眼。如果我們能對每個輸入字符串構造特定的表達式當然很好。這不可能,但我們能夠找出一些常用的模式,構造效率更高,又不失通用性的正則表達式。
現在來看表6-2前面的四個例子。下畫線標注的部分表示「一個轉義元素,然後是更多的正常字符」。這就是關鍵:在每種情況下,開頭是引號,然後是「[^\\〞]+」,然後是若干個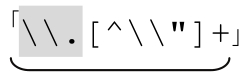 。綜合起來就得到
。綜合起來就得到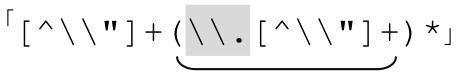 。這個特殊的例子說明,通用模式可以用來構建許多有用的表達式。
。這個特殊的例子說明,通用模式可以用來構建許多有用的表達式。
表6-2:消除循環的具體情況

構造通用的「消除循環」解法
在匹配雙引號字符串時,引號自身和轉義斜線是「特殊」的——因為引號能夠表示字符串的結尾,反斜線表示它之後的字符不會終結整個字符串。在其他情況下,「[^\\〞]」就是普通的點號。考察它們如何組合為 ,首先它符合通用的模式
,首先它符合通用的模式 。
。
再添加兩端的引號,就得到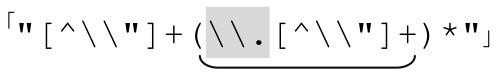 。不幸的是,表6-2中下面兩個例子無法由這個表達式匹配。癥結在於,目前這個正則表達式的兩個「[^\\〞]+」要求字符串以一個普通字符開始,然後是任何數目的特殊字符。從這個例子中我們可以看到,它並不能應付所有情況——字符串可能以轉義元素開頭和結尾,一行中間也可能包含兩個轉義元素。我們可以嘗試把兩個加號改成星號:
。不幸的是,表6-2中下面兩個例子無法由這個表達式匹配。癥結在於,目前這個正則表達式的兩個「[^\\〞]+」要求字符串以一個普通字符開始,然後是任何數目的特殊字符。從這個例子中我們可以看到,它並不能應付所有情況——字符串可能以轉義元素開頭和結尾,一行中間也可能包含兩個轉義元素。我們可以嘗試把兩個加號改成星號: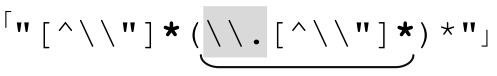 。這會達到我們期望的結果嗎?更重要的是,它是否會產生負面影響?
。這會達到我們期望的結果嗎?更重要的是,它是否會產生負面影響?
就期望的結果來說,很容易看到所有的例子都能匹配。事實上,即使是〞\〞\〞\〞〞這樣的字符串都能匹配。這當然很不錯。不過,我們還需要確認,這樣重大的改變,是否會導致預料之外的結果。格式不對的引號字符串能否匹配呢?格式正確的引號字符串是否可能無法匹配呢?效率又如何呢?
仔細看看 。開頭的「〞[^\\〞]*」只會應用一次,這沒有問題:它匹配開頭必須出現的引號,以及之後的任何普通字符。這沒有問題。接下來的「(\\.[^\\〞]*)*」是由星號限定的,所以不匹配任何字符也能夠成功。也就是說,去掉這一部分仍然會得到一個合法的表達式。這樣我們就得到「〞[^\\〞]*〞」,這顯然沒有問題——它代表了常見的,也就是沒有轉義元素的情形。
。開頭的「〞[^\\〞]*」只會應用一次,這沒有問題:它匹配開頭必須出現的引號,以及之後的任何普通字符。這沒有問題。接下來的「(\\.[^\\〞]*)*」是由星號限定的,所以不匹配任何字符也能夠成功。也就是說,去掉這一部分仍然會得到一個合法的表達式。這樣我們就得到「〞[^\\〞]*〞」,這顯然沒有問題——它代表了常見的,也就是沒有轉義元素的情形。
另一方面,如果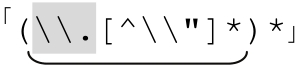 部分匹配了一次,其實就等價於
部分匹配了一次,其實就等價於 。即使結尾的「[^\\〞]*」沒有匹配任何文本(其實就是
。即使結尾的「[^\\〞]*」沒有匹配任何文本(其實就是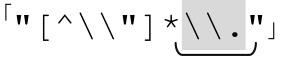 ),也沒有問題。照這樣分析下去(如果沒記錯的話,這就是高中代數中的「照此類推(by induction)」),我們發現,這樣的改動其實是沒有任何問題的。
),也沒有問題。照這樣分析下去(如果沒記錯的話,這就是高中代數中的「照此類推(by induction)」),我們發現,這樣的改動其實是沒有任何問題的。
所以,我們最後得到的,用來匹配包括轉義引號的引號字符串的正則表達式就是:

真正的「消除循環」解法
The Real"Unrolling-the-Loop"Pattern
綜合起來,匹配包括轉義引號的雙引號字符串正則表達式就是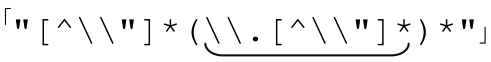 。這和原來的表達式能夠匹配的結果是完全一致的。但是循環消除之後,表達式能夠在有限的時間內結束匹配。不但效率高得多,並且避免了無休止匹配。
。這和原來的表達式能夠匹配的結果是完全一致的。但是循環消除之後,表達式能夠在有限的時間內結束匹配。不但效率高得多,並且避免了無休止匹配。
消除循環常用的解法是:
「opening normal*(special normal*)*closing」
避免無休止匹配
避免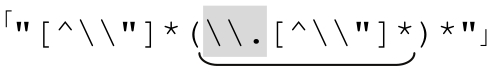 中的無休止匹配,有三點很重要:
中的無休止匹配,有三點很重要:
1)special部分和normal部分匹配的開頭不能重合。
special 和 normal 部分的子表達式不能從同一位置開始匹配。在上例中,normal 部分是「[^\\〞]」,special 部分是「\\.」,顯然它們不能匹配同樣的字符,因為後者要求以反斜線開頭,而前者不容許出現開頭的反斜線。
另一方面,「\\.」和「[^〞]」都能夠從『〞Hello☞\n〞』開始匹配,所以它們不符合這種解法。如果二者能夠從字符串中的同一位置開始匹配,就無法確定該使用哪一個,這種不確定就會造成無休止匹配。『 』的例子說明了這一點(☞227)。如果無法匹配(或是POSIX NFA引擎在任何情況下的匹配),就必須嘗試所有的可能性。這非常糟糕,因為改進這個表達式的首要原因就是為了避免這種情況。
』的例子說明了這一點(☞227)。如果無法匹配(或是POSIX NFA引擎在任何情況下的匹配),就必須嘗試所有的可能性。這非常糟糕,因為改進這個表達式的首要原因就是為了避免這種情況。
如果我們確信,special和normal部分不能匹配同樣的字符,就可以將special部分用作檢查點,消除normal部分在「(…)*」的各輪迭代時匹配同樣文本造成的不確定性。如果我們確信special部分和normal部分永遠不會匹配同樣的文本,則特定目標字符串的匹配中存在唯一的special部分和normal部分的「組合序列」。檢查這個序列比檢查成千上萬種可能要快得多,於是避免了無休止匹配。
2)normal部分必須匹配至少一個字符
第二點是,如果normal部分需要匹配字符才能成功,則它必須匹配至少一個字符。如果我們能夠匹配成功,而不佔用任何字符,那麼下面的字符仍然必須由「(special normal*)*」的不同迭代來匹配,這樣我們就回到了原來的(…*)*的問題。
選擇「(\\.)*」作為special部分就違背了這條規定。 注定是個糟糕的表達式,如果用它來匹配『〞Tubby』(會失敗),在得到匹配失敗的結論之前,引擎必須嘗試若干個「[^\\〞]*」匹配『Tubby』的每一種可能。因為special部分可以不匹配任何字符,所以它無法作為檢查點。
注定是個糟糕的表達式,如果用它來匹配『〞Tubby』(會失敗),在得到匹配失敗的結論之前,引擎必須嘗試若干個「[^\\〞]*」匹配『Tubby』的每一種可能。因為special部分可以不匹配任何字符,所以它無法作為檢查點。
3)special部分必須是固化的
special 部分匹配的文本不能由該部分的多次迭代完成。如果需要匹配Pascal中可能出現的註釋{…}和空白。能夠匹配註釋部分的正則表達式是「\{[^}]*\}」,所以整個正則表達式就是「(\{[^}]*\)|·+)*」(它永遠不會終止)。或許,你會這樣劃分normal和special部分:

使用我們學會的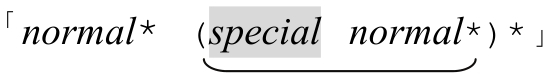 的解法,我們得到 「(\{[^]}*\})*
的解法,我們得到 「(\{[^]}*\})*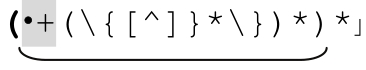 。現在來看這個字符串
。現在來看這個字符串
{comment}···{another}··
匹配連續空格的可能是單個「·+」,或多個「·+」匹配(每個匹配一個空格),或是多個「·+」的組合(每個匹配不同數目的空格)。這很像之前的『 的問題。
的問題。
此問題的根源在於,special部分既能夠匹配很長的文本,也能通過(…)*匹配其中的部分文本。非確定性開了「多種方式匹配同樣文本」的口子。
如果存在全局匹配,很可能「·+」只匹配一次,但是如果不存在全局匹配(例如把這個表達式作為另一個大的表達式的一部分),引擎就必須對每一段空格測試「(·+)*」所有的可能。這需要時間,但這對全局匹配無益。因為special部分應該作為檢查點,而這裡沒有任何需要檢查的非確定性。
解決的方法就是,保證special部分只能夠匹配固定長度的空格。因為它必須匹配至少一個空格,但可能匹配更多,我們用「·」作為special部分,用「(…)*」來保證special的多重應用能匹配多個空格。
這個例子很適合講解,但是實際應用起來,效率更高的辦法可能是交換 special 和 normal表達式:
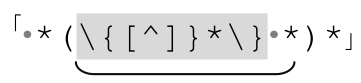
因為我估計Pascal程序的註釋不會比空格少,而且對常見情況來說更有效的辦法是用normal部分匹配常見的文本。
尋找通用套路
如果你真正掌握了這些規則(可能需要反覆閱讀和一些實踐),你就能把這幾條推廣開來,作為指導規則,用來識別可能造成無休止匹配的正則表達式。如果有若干個量詞存在於不同的層面,例如「(…*)*」,我們就必須小心對待,但是許多這樣的表達式卻是完全沒有問題的。例如:
●「(Re:·*)*」用來匹配任意數目的『Re:』序列(可以用來清除郵件主題中的『Subject:·Re:·Re:·Re:·hey』)。
●「(·*\$[0-9]+)*」用來匹配美元金額,可能有空格作分隔。
●「(.*\n)+」用來匹配一行或多行文本。(事實上,如果點號不能匹配換行符,而這個子表達式之後又有別的元素導致匹配失敗,就會造成無休止匹配)。
這些表達式都沒有問題,因為每一個都有檢查點,也就不會產生「多種方式匹配同樣文本」的問題。在第一個裡面是「Re:」,第二個裡面是「\$」,第三個(如果點號不能匹配換行符)是「\n」。
方法2:自頂向下的視角
Method 2:A Top-Down View
還記得嗎?我說過,「消除循環」有兩種辦法。如果採用第二種辦法,開始只匹配目標字符串中最常見的部分,然後增加對非常見情況的處理。讓我們來看會造成無休止匹配的表達式「(\\.|[^\\〞]+)*」期望匹配的文本以及它可能應用的場合。我認為,通常情況下引用字符串中的普通字符會比轉義字符更多,所以「 [^\\〞]+」承擔了大部分工作。「\\.」只需要用來處理偶然出現的轉義字符。我們可以使用多選結構來應付兩種情況,但糟糕的是,為了處理少部分(決不可能是大部分)轉義字符,這樣做會降低效率。
如果我們認為「[^\\〞]+」能夠匹配字符串中的絕大部分字符,就知道如果匹配停止,大概是遇到了閉引號或者是轉義字符。如果是轉義字符,後面容許出現更多的字符(無論是什麼),然後開始「[^\\〞]+」的新一輪匹配。每次[^\\〞]+的匹配終止,我們都回到相同的處境:期望出現一個閉引號或者是另一個轉義。
我們可以很自然地用一個表達式來表達它,得到與方法1同樣的結果:

我們知道,匹配每次進行到☞標記的位置時,應該出現一個反斜線或者閉雙引號。如果反斜線能匹配,就匹配它,然後是被轉義的字符,然後是更多的字符,直到下一次到達「閉引號或者反斜線」的位置。
和之前一樣,最開始的非引用內容或是引號內的文本可能為空。我們可以把兩個加號改成星號,這樣就得到與264頁相同的表達式。
方法3:匹配主機名
Method 3:An Internet Hostname
上面介紹了兩種消除循環的辦法,不過我還願意介紹另一種辦法。在用正則表達式匹配如www.yahoo.com這樣的主機名時,它令我震驚。主機名主要是用點號分隔的子域名的序列,準確地劃定子域名的匹配規範很麻煩(☞203),為了保證清晰,我們使用「[a-z]+」來匹配子域名。
如果子域名是「[a-z]+」,我們希望得到點號分隔的子域名序列,首先要匹配第一個子域名。之後其他的子域名以點號開頭。用正則表達式來表示,就是「[a-z]+(\.[a-z]+)*」。現在,如果我希望添加上前面出現的各種標記,就得到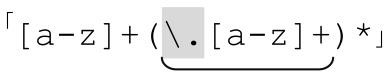 ,顯然它看起來非常熟悉,對嗎?
,顯然它看起來非常熟悉,對嗎?
為了說明這種相似性,我們嘗試把它對應到雙引號字符串的例子。如果我們認為字符串是『〞…〞』之內的文本,包括normal 部分「[^\\〞]」,由special 部分「\\.」分隔,就能套用消除循環的解法,得到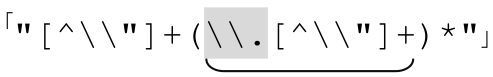 中,也就是在討論方法1中的某個地步。也就是說,從概念上講,我們能夠把由點號分隔的主機名的問題看成雙引號字符串的問題,也就是「由轉義元素分隔的非轉義元素構成的序列」。這可能不那麼直觀,但是我們可以使用前面用過的套路。
中,也就是在討論方法1中的某個地步。也就是說,從概念上講,我們能夠把由點號分隔的主機名的問題看成雙引號字符串的問題,也就是「由轉義元素分隔的非轉義元素構成的序列」。這可能不那麼直觀,但是我們可以使用前面用過的套路。
二者既存在相似性,也存在區別。在方法1中,我們改變正則表達式是為了容許normal部分和special部分之後出現空白,但是這裡不容許出現空白。所以雖然這個例子與之前的並非完全相同,但也屬於同一類,同樣可以用來證明消除循環的技巧的強大和便捷。
子域名的例子與之前的例子有兩大區別:
●域名的開始和結束沒有分界符。
●子域名的normal部分不可能為空(也就是說兩個點號不能緊挨在一起,點號也不能出現在整個域名的開頭或結尾)。對雙引號字符串來說,normal部分可以為空,即使按照我們的假設它們不太應該為空。所以我們需要把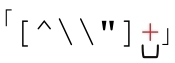 改為
改為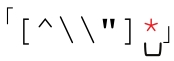 。而子域名的例子不能進行這種修改,因為special部分是分隔符,必須出現。
。而子域名的例子不能進行這種修改,因為special部分是分隔符,必須出現。
觀察
Observations
回過頭來看雙引號字符串的例子,表達式「〞[^\\〞]*(\\.[^\\〞]*)*〞」有許多優點,也存在一些陷阱。
陷阱:
●可讀性 這是最大的問題,原來的「〞([^\\〞]|\\.)*〞」可能更容易一眼看懂,我們放棄了可讀性來追求效率。
●可維護性 可維護性可能更複雜,因為任何改動都必須保持對兩個[^\\〞]相同。我們犧牲了可維護性來追求效率。
好處:
●速度 如果不能匹配,或是採用 POSIX NFA,這個正則表達式不會進入無休止匹配。因為進行了精心地調校,特定的文本只能以唯一的方式匹配,如果文本不能匹配,引擎會迅速發現它。
●還是速度 正則表達式「操作連續性(flow)」很好,這也是「流暢運轉的正則表達式」(☞277)的主題。我對傳統型 NFA 進行了檢測,消除循環之後的表達式總是比之前使用多選結構的表達式要快得多。即使匹配能夠成功,不會進入無休止匹配狀態時,也是如此。
使用固化分組和佔有優先量詞
Using Atomic Grouping and Possessive Quantifiers
表達式「〞(\\.|[^\\〞]+)*〞」之所以會進入無休止匹配的狀態,問題在於,如果無法匹配,它會陷入徒勞的嘗試。不過,如果存在匹配,就能很快結束,因為「[^\\〞]+」能夠匹配目標字符串中的大多數字符(也就是之前討論過的normal部分)。因為「[…]+」通常會為速度優化(☞247),而且能夠匹配大多數字符,外面的「(…)* 」量詞的開銷因此大為減少。
所以,「〞(\\.|[^\\〞]+)*〞」的問題就在於,不會在匹配時會陷入徒勞的嘗試,在我們知道毫無用處的備用狀態之中不斷回溯。我們知道這些狀態毫無價值,因為他們只是檢查同樣對象的不同排列(如果「abc」不能匹配『foo』,那麼「abc」或者「abc」(以及「abc」,「abc」或者無論什麼形式的「abc」)都不能匹配。如果我們能拋棄這些狀態,正則表達式就能迅速報告匹配失敗)。
拋棄(或者是忽略)這些狀態的方法有兩種:固化分組(☞139)或者佔有優先量詞(☞142)。
在我們著手消除回溯以前,我希望交換多選分支的順序,把「〞(\\.|[^\\〞]+)*〞」變為「〞([^\\〞]+|\\.)*〞」,這樣匹配「普通」文本的元素就出現在第一位。前幾章中我們已經數次提到過,如果兩個或兩個以上的多選分支能夠在同一位置匹配,排列順序的時候就要小心,因為順序可能影響到匹配的結果。但對於本例來說,不同多選分支匹配的是不同的文本(某個多選分支在一處能夠匹配,則其他多選分支在此處就不能匹配),從正確匹配的角度來看,順序就是無關緊要的,所以我們可以根據清晰或效率的要求來選擇順序。
使用佔有優先量詞避免無休止匹配
會造成無休止匹配的表達式「〞([^\\〞]+|\\.)*〞」有兩個量詞。我們可以把其中一個改為佔有優先量詞,或者兩個都改。這兩者有區別嗎?因為大多數回溯的麻煩源自「[…]+」留下的狀態,所以把它改成佔有優先是我的第一想法。這樣得到的表達式,即使找不到匹配,速度也很快。不過,把外面的「(…)*」改成佔有優先會拋棄括號內的所有備選狀態,其中包括「[…]+」和多選結構本身的備選狀態,所以如果我要從中選取一個的話,我會選取後者。
但我們並非只能選擇一個,因為我們可以把兩個都改為佔有優先量詞。具體哪種辦法最快,可能取決於佔有優先量詞的優化情況。現在,只有Sun的Java regex package支持這種表示法,所以我的測試只能在Java中進行,並且發現某些情形下其中一種組合更快。我原本期望,使用兩個佔有優先量詞是最快的,所以這些結果讓我相信,Sun的優化還不夠徹底。
使用固化分組避免無休止匹配
如果要對「〞([^\\〞]+|\\.)*〞」使用固化分組,最容易想到的辦法就是把普通括號改成固化分組括號:「〞(?>[^\\〞]+|\\.)*〞」。不過我們必須知道,在拋棄狀態的問題上,「(?>…|…)*」與佔有優先的「(…|…)*+」是迥然不同的。
「(…|…)*+」在完成時不會留下任何狀態,相反,「(?>…|…)*」只是消除多選結構每次迭代時保留的狀態。星號是獨立於固化分組的,所以不受影響,這個表達式仍然會保留「跳過本輪迭代」的備用狀態。也就是說,回溯中的狀態仍然不是確定的最終狀態。我們希望同時消除外面量詞的備用狀態,所以要把外面的括號也改成固化分組。也就是說模擬佔有優先「(…|…)*+」必須用到「(?>(…|…)*)」 。
解決無休止匹配的問題時,「(…|…)*+」和「(?>…|…)*」都很有用,但是它們在拋棄狀態的選擇和時間上卻是不同的(更多的差異,請參閱173頁)。
簡單的消除循環的例子
Short Unrolling Examples
現在我們大概瞭解了消除循環的思想,來看看書中曾經出現過的幾個例子,想想該如何消除循環。
消除「多字符」引文中的循環
在第4章第167頁,我們看到這個例子:

normal部分是「[^<]」,special部分是「(?!</?B>)<」,下面是改進的版本:

這裡固化分組並不是必須的,但如果只能部分匹配,使用固化分組能夠提高速度。
消除連續行匹配例子中的循環
連續行的例子出現在前一章的開頭(☞186),當時使用的表達式是「^\w+=([^\n\\]|\\.)*」。看起來這很適合應用這種技巧:

與上一個例子一樣,固化分組不是必須的,但它能讓引擎更快地報告匹配失敗。
消除CSV正則表達式中的循環
第5章用了很長的篇幅討論CSV的處理,最後得到第216頁的代碼:

當時的結論是,最好在開頭添加「\G」,這樣就能避免驅動過程帶來的麻煩,並且效率也會提高。現在我們知道如何消除循環,就可以此技巧來看看如何應用這個例子。
用來匹配微軟的CSV字符串的正則表達式是「(?:[^〞]|〞〞)*」,它看起來很不錯。其實,這個表達式已經區分了normal和special部分:「[^〞]」和「〞〞」。下面我們把這個表達式寫清楚,用原來的Perl代碼說明消除循環的過程:

如其他的例子一樣,固化分組不是必須的,但可以提高效率。
消除C語言註釋匹配的循環
Unrolling C Comments
現在來看個匹配更複雜字符串時消除循環的例子。在C語言中,註釋以/*開頭,*/結尾,可以有多行,但不能嵌套(C++、Java和C#也容許這種形式的註釋)。匹配此類註釋的正則表達式在許多情況下都有用,例如構建去掉註釋的過濾程序。寫這個程序時我首先想到的就是消除循環,而這個技巧現在已經成為我的正則表達式寶庫中的重要裝備。
真的需要消除嗎
我在20 世紀 90 年代早期就開始開發本節討論的這個正則表達式。在那之前,人們認為用正則表達式匹配 C 語言的註釋即使不是不可能,也是很困難的事情,所以一些可行的辦法由我開發出來之後,就成為匹配C語言註釋的標準方法。不過,在Perl引入忽略優先量詞之後,出現了簡單得多的辦法:使用能匹配所有字符的點號「/\*.*?\*/」。
在我寫程序的時候忽略優先量詞還沒有出現,如果當時有這種現成的特性,就不用費這麼多周折了。不過,我的解決辦法仍然是有效的,因為即使在首次支持忽略優先量詞的那一版 Perl 中,使用消除循環技巧的程序仍然要比使用忽略優先量詞的快得多(我做了許多種測試,有時快50%,也有時快360%)。
不過,Perl 現在綜合了各種優化措施,形勢就顛倒過來,忽略優先量詞的程序要快上 50%到550%。所以我現在使用「/\*.*?\*/」來匹配C語言的註釋。
這是否意味著,現在匹配 C 語言注視用不著消除循環的技巧了?如果引擎不支持忽略優先量詞,消除循環的價值就能體現出來。也不是所有的正則引擎都能綜合各種優化:在我測試的其他任何語言中,消除了循環的程序都要更快——最快的時候速度相差60倍!消除循環的技巧確實很有用,所以下文講解如何用它來匹配C語言註釋。
因為匹配C 語言註釋時不存在雙引號字符串中轉義字符\〞的問題,可能有人覺得事情會比較簡單,但問題其實更複雜。因為這裡的「結束雙引號」*/不止一個字符。直接用「/\*[^*]*\*/」可能看起來沒問題,但不能匹配/**some comment here**/,因為其中還有『*』,而這是必須匹配的,所以我們需要另外的辦法。
換更清晰的表示方法
你可能覺得「/\*[^*]*\*/」難以閱讀,即使本書的體例已經盡量做到容易看懂。但不幸的是,註釋部分的邊界符『*』本身就是正則表達式的元字符,所以得使用反斜線轉義,結果正則表達式看起來讓人頭疼。為了看得更清楚,我們在這個例子中使用/x…x/,而不是/*…*/。經過這個細微的改動,「/\*[^*]*\*/」變成了更容易看懂的「/x[^x]*x/」。這個表達式會隨著我們的講解變得越來越複雜,到時你會發現這個改動的價值。
直接的辦法
在第5章(☞196),我給出了匹配分隔符之內文本的公式:
1.匹配起始分隔符;
2.匹配正文:匹配「除結束分隔符之外的任何字符」;
3.匹配結束分隔符。
現在我們的程序以/x和x/作為開始和結束分隔符,它似乎很符合這個模式。難處在於匹配「除結束分隔符之外的任何字符」。如果結束分隔符是單個字符,我們可以用排除型字符組。但字符組不能用來進行多字符匹配,不過如果能使用否定型順序環視,我們就能使用「(?:(?!x/).)*」。這就是「除結束分隔符之外的任何字符」。
於是我們得到「/x(?:(?!x/).)*x/」。它沒有問題,但速度很慢(在我做的一些測試中,速度要比下面的表達式慢幾百倍)。這個思路很有用,但缺乏實用性,因為幾乎所有支持順序環視的流派都支持忽略優先量詞,所以效率並不是問題,你完全可以用「/x.*?x/」。
那麼,順著這種分三步走的思路,是否有其他辦法匹配第一個 x/之前的文本?能想到的辦法有兩個。之一是把 x作為開始分隔符和結束分隔符,也就是說,匹配除 x之外的任何字符,以及之後字符不為斜線的x。這樣,「除結束分隔符之外的任何字符」就成了:
●除x之外的任何字符:「[^x]」。
●之後字符不是斜線的x:「x[^/]」。
這樣得到「([^x]|x[^/])*」來匹配主體文本,「/x([^x]|x[^/])*x/」來匹配整個註釋。我們會發現這條路行不通。
另一種辦法是,把緊跟在 x 之後斜線當作結束分隔符。這樣「除結束分隔符之外的任何字符」就成了:
●除斜線外的任何字符:「[^/]」。
●緊跟在x之後的斜線:「[^x]/」。
於是用「([^/]|[^x]/)*」匹配主體文本,「/x([^/]|[^x]/)*x/」匹配整個註釋。
不幸的是,這同樣是死路。
如果用「/x([^x]|x[^/])*x/」來匹配『/xx·foo·xx/』,在『foo·』之後,第一個x由「x[^/]」匹配,這當然沒有問題。但是之後,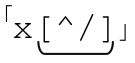 匹配
匹配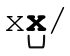 ,而這個 x 應該是標記註釋的結束。於是繼續下一輪迭代,「[^x]」匹配斜線,結果會匹配x/之後的文本。
,而這個 x 應該是標記註釋的結束。於是繼續下一輪迭代,「[^x]」匹配斜線,結果會匹配x/之後的文本。
「/x([^/]|[^x]/)*x/」也不能匹配『/x/·foo·/x/』(整個註釋都應該匹配)。如果註釋結尾後緊跟斜線,表達式匹配的內容會超過註釋的結束分職符(這也是其他解法的問題)。而在本例中,回溯可能有些令人迷惑,所以讀者最好弄明白「/x([^/]|[^x]/)*x/」為什麼能匹配
(可以在空餘時間好好想想這個問題。)
怎麼辦
讓我們來修正這些表達式。在第一種情況下,因為疏忽,「x[^/]」匹配了結尾的…xx/。如果我們用「/x([^x]|x+[^/])*x/」。我們認為,添加加號之後,「x+[^/]」匹配以非斜線字符結尾的一連串x。確實它能夠這樣匹配,但因為回溯「斜線之外的任意字符」仍然可以是x。首先,匹配優先的「x+」匹配我們需要的額外的x,但是如果全局匹配需要,回溯會逐個釋放它們。所以它仍然會匹配過多內容:
要解決這個問題,還得回到之前介紹的辦法:準確表達我們希望表達的意思。如果我們說的「緊跟字符不是斜線的一些 x」其實就是除 x之外的非斜線字符,就應該用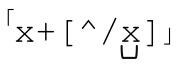 。它不會匹配
。它不會匹配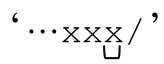 』,一連串x中表示註釋結束的那個x。事實上,它還有個問題,就是無法匹配註釋結束之前的任意多個 x,所以會在
』,一連串x中表示註釋結束的那個x。事實上,它還有個問題,就是無法匹配註釋結束之前的任意多個 x,所以會在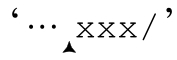 』停下來。因為我們預計結尾分隔符前只有一個x,所以必須加入「x+/」處理這種情況。
』停下來。因為我們預計結尾分隔符前只有一個x,所以必須加入「x+/」處理這種情況。
於是得到「/x([^x]|x+[^/x])*x+/」,匹配最終的註釋。

這看起來很迷惑,對嗎?真正的表達式(用*取代 x)就是「/\*([^*]|\*+[^/*])*\*+/」,這樣更複雜了,更不容易看懂,所以在理解複雜的正則表達式時,一定要保持清醒的思維。
消除C語言註釋的循環
為了提高表達式的效率,我們必須消除這個表達式的循環。下一頁的表6-3給出了我們能夠「消除循環」的表達式。
和子域名的例子一樣,「normal*」必須匹配至少一個字符。子域名的例子中是因為 normal 部分不能為空。本例中必須的結束分隔符包含兩個字符。我們確信,任何以結束分隔符的第一個字符結尾的任何normal序列,只有在緊跟字符不能組成結束分隔符的情況下,才會把控制權交給special部分。
表6-3:消除C語言註釋的循環

所以,按照通用的消除套路,我們得到:
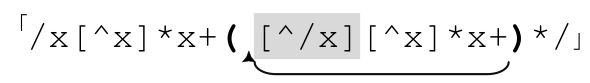
請注意☞標注的位置。正則引擎可能有兩種辦法到達此處(267頁的表達式也是如此)。第一個是在開頭的「/x[^x]*x+」匹配之後直接前進到此處,第二是在(…)*循環的某一輪中。無論哪種情況,只要到達此處,我們就知道已經匹配了x,到達關鍵位置(pivotal point),可已經進入了註釋的結尾分隔符。如果下面的字符是斜線,則匹配完成。如果是其他字符(當然不是x),我們知道之前的判斷是錯誤的,然後回到normal部分,等待下一個x。找到之後我們再一次回到標記位置。
回到現實
「/x[^x]*x+([^/x][^x]*x+)*/」還不能直接拿來用。首先,註釋是/*…*/而不是/x…x/。當然,我們可以很容易地把每個x替換為\x(字符組中的x替換為*):
「/\*[^*]*\*+([^/*][^*]*\*+)*/」
實際情況中,註釋通常會包括多行。如果匹配的註釋包括多行,這個表達式也應該能夠應付。如果是嚴格以行為處理單位的工具,例如egrep,當然沒辦法用一個正則表達式匹配所有的行。對本書中提到的大多數工具,我們的確可以用這個表達式來匹配多行,刪除它們。
在實際中,會遇到許多問題。這個正則表達式能夠識別C的註釋,但不能識別C語法的其他重要方面。例如,劃線的部分儘管不是註釋,也能夠匹配:
我們會在下一節接著討論這個例子。