NFA,DFA,and POSIX
最左最长规则
\"The Longest-Leftmost\"
之前我们说过:如果传动装置在文本的某个特定位置启动DFA引擎,而在此位置又有一个或多个匹配的可能,DFA 就会选择这些可能中最长的。因为在所有同样从最左边开始的可能的匹配文本中它是最长的,所以叫它“最左最长的(longest-leftmost)”匹配。
绝对最长
这里说的“最长”不限于多选结构。看看 NFA 如何用「one(self)?(selfsufficient)?」来匹配字符串 oneselfsufficient。NFA 首先匹配「one」,然后是匹配优先的「(self)?」,留下「(selfsufficient)?」来匹配sufficient。它显然无法匹配,但整个表达式并不会因此匹配失败,因为这个元素不是必须匹配的。所以,传统型NFA返回 ,放弃没有尝试的状态(POSIX NFA的情况与此不同,我们稍后将会看到)。
,放弃没有尝试的状态(POSIX NFA的情况与此不同,我们稍后将会看到)。
与此相反,DFA 会返回更长的结果: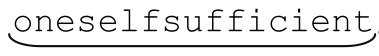 。如果最开始的「(self)?」因为某些原因无法匹配,NFA 也会返回跟 DFA 一样的结果,因为「(self)?」无法匹配,「(selfsufficient)?」就能成功匹配。传统型NFA不会这样,但是DFA则会这样,因为会选择最长的可能匹配。DFA 同时记录多个匹配,在任何时候都清楚所有的匹配可能,所以它能做到这一点。
。如果最开始的「(self)?」因为某些原因无法匹配,NFA 也会返回跟 DFA 一样的结果,因为「(self)?」无法匹配,「(selfsufficient)?」就能成功匹配。传统型NFA不会这样,但是DFA则会这样,因为会选择最长的可能匹配。DFA 同时记录多个匹配,在任何时候都清楚所有的匹配可能,所以它能做到这一点。
我选这个简单的例子是因为它很容易理解,但是我希望读者能够明白,这个问题在现实中很重要。举例来说,如果希望匹配连续多行文本,常见的情况是,一个逻辑行(logical line)可以分为许多现实的行,每一行以反斜线结尾,例如:

读者可能希望用「^w+=.*」来匹配这种“var=value”的数据,但是正则表达式无法识别连续的行(在这里我们假设点号无法匹配换行符)。为了匹配多行,读者可能需要在表达式最后添加「(\\n.*)*」,得到 。显然,这意味着任何后继的逻辑行都能匹配,只要他们以反斜线结尾。这看起来没错,但在传统型NFA中行不通。「.*」到达行尾的时候,已经匹配了反斜线,而表达式中后面的部分不会强迫进行回溯(☞152)。但是,DFA 能够匹配更长的多行文本,因为它确实是最长的。
。显然,这意味着任何后继的逻辑行都能匹配,只要他们以反斜线结尾。这看起来没错,但在传统型NFA中行不通。「.*」到达行尾的时候,已经匹配了反斜线,而表达式中后面的部分不会强迫进行回溯(☞152)。但是,DFA 能够匹配更长的多行文本,因为它确实是最长的。
如果能够使用忽略优先的量词,也许可以考虑用它们来解决问题,例如「^w+=.*?(\\n.*?)*」。这样点号每次实际匹配任何字符之前,都需要测试转义的换行符部分,这样「\\」就能够匹配换行符之前的反斜线。不过这也行不通。如果忽略优先量词匹配某些可选的部分,必然是在全局匹配必须的情况下发生。但是在本例中,「=」后面的所有部分都不是必须匹配的,所以没有东西会强迫忽略优先量词匹配任何字符。忽略优先的正则表达式只能匹配‘SRC=’,这显然不是我们期望的结果。
这个问题还有其他的解决办法,我们会在下一章继续这个问题(☞186)。
POSIX和最左最长规则
POSIX and the Longest-Leftmost Rule
POSIX标准规定,如果在字符串的某个位置存在多个可能的匹配,应当返回的是最长的匹配。
POSIX标准文档中使用了“最左边开始的最长匹配(longest of the leftmost)”。它并没有规定必须使用DFA,那么,如果希望使用NFA来实践POSIX,程序员应该如何做?如果你希望执行POSIX NFA,那么必须找到完整的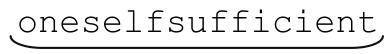 和所有的连续行,虽然这个结果是违反NFA“天性”的。
和所有的连续行,虽然这个结果是违反NFA“天性”的。
传统型NFA引擎会在第一次找到匹配时停下来,但是如果让它继续尝试其他分支(状态)会怎样呢?每次匹配到表达式的末尾时,它都会获得另一个可能的匹配结果。如果所有的分支都穷尽了,就能从中选择最长的匹配结果。这样,我们就得到了一台POSIX NFA。在上面的例子中,NFA 匹配「(self)?」时保存了一个备用状态: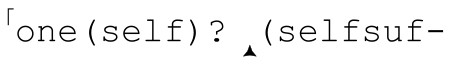 ficient)?」在
ficient)?」在 。传统型NFA在
。传统型NFA在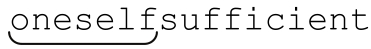 之后停止匹配,
之后停止匹配,
而POSIX NFA仍然会继续检查余下的所有状态,最终得到那个更长的结果(其实是最长的)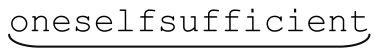 。
。
第7章有一个例子,可以让Perl模拟POSIX的做法,返回最长的匹配字符(☞225)。
速度和效率
Speed and Efficiency
如果传统型NFA的效率是我们应当关注的问题(对提供回溯的传统型NFA来说,这确实是一个问题),那么POSIX NFA的效率就更值得关注,因为它需要进行更多的回溯。POSIX NFA需要尝试正则表达式的所有变体(译注4)。第6章告诉我们,正则表达式写得糟糕的话,匹配的效率就会很低。
DFA的效率
文本主导的DFA巧妙地避免了回溯造成的效率问题。DFA同时记录了所有可能的匹配,这样来提高速度。它是如何做到这一切的呢?
DFA 引擎需要更多的时间和内存,它第一次遇见正则表达式时,在做出任何尝试之前会用比NFA详细得多的(也是截然不同的)办法来分析这个正则表达式。开始尝试匹配的时候,它已经内建了一张路线图(map),描述“遇到这个和这个字符,就该选择这个和那个可能的匹配”。字符串中的每个字符都会按照这张路线图来匹配。
有时候,构造这张路线图可能需要相当的时间和内存,不过只要建立了针对特定正则表达式的路线图,结果就可以应用到任意长度的文本。这就好像为你的电动车充电一样。首先,你得把车停到车库里面,插上电源等待一段时间,但只要发动了汽车,清洁的能源就会源源而来。

小结:NFA与DFA的比较
Summary:NFA and DFA in Comparison
NFA与DFA各有利弊。
DFA与NFA:在预编译阶段(pre-use compile)的区别
在使用正则表达式搜索之前,两种引擎都会编译表达式,得到一套内化形式,适应各自的匹配算法。NFA的编译过程通常要快一些,需要的内存也更少一些。传统型NFA和POSIX NFA之间并没有实质的差别。
DFA与NFA:匹配速度的差别
对于“正常”情况下的简单文本匹配测试,两种引擎的速度差不多。一般来说,DFA 的速度与正则表达式无关,而NFA中两者直接相关。
传统的NFA在报告无法匹配以前,必须尝试正则表达式的所有变体。这就是为什么我要用整章(第6章)来论述提高NFA表达式匹配速度的技巧。我们将会看到,有时候一个NFA永远无法结束匹配。传统型NFA如果能找到一个匹配,肯定会停止匹配。
相反,POSIX NFA必须尝试正则表达式的所有变体,确保获得最长的匹配文本,所以如果匹配失败,它所花的时间与传统型NFA一样(有可能很长)。因此,对POSIX NFA来说,表达式的效率问题更为重要。
在某种意义上,我说得绝对了一点,因为优化措施通常能够减少获得匹配结果的时间。我们已经看到,优化引擎不会在字符串开头之外的任何地方尝试带「^」锚点的表达式,我们会在第6章看到更多的优化措施。
DFA不需要做太多的优化,因为它的匹配速度很快,不过最重要的是,DFA在预编译阶段所作的工作提供的优化效果,要好于大多数NFA引擎复杂的优化措施。
现代DFA引擎经常会尝试在匹配需要时再进行预编译,减少所需的时间和内存。因为应用的文本各异,通常情况下大部分的预编译都是白费工夫。因此,如果在匹配过程确实需要的情况下再进行编译,有时候能节省相当的时间和内存(技术术语就是“延迟求值(lazy evaluation)”)。这样,正则表达式、待匹配的文本和匹配速度之间就建立了某种联系。
DFA与NFA:匹配结果的差别
DFA(或者POSIX NFA)返回最左边的最长的匹配文本。传统型NFA可能返回同样的结果,当然也可能是别的文本。针对某一型具体的引擎,同样的正则表达式,同样的文本,总是得到同样的结果,在这个意义上来说,它不是“随机”的,但是其他NFA引擎可能返回不一样的结果。事实上,我见过的所有传统型NFA返回的结果都是一样的,但并没有任何标准来硬性规定。
DFA与NFA:能力的差异
NFA引擎能提供一些DFA不支持的功能,例如:
●捕获由括号内的子表达式匹配的文本。相关的功能是反向引用和后匹配信息(after-match information),它们描述匹配的文本中每个括号内的子表达式所匹配文本的位置。
●环视,以及其他复杂的零长度确认(注8)(☞133)。
●非匹配优先的量词,以及有序的多选结构。DFA很容易就能支持选择最短的匹配文本(尽管因为某些原因,这个选项似乎从未向用户提供过),但是它无法实现我们讨论过的局部的忽略优先性和有序的多选结构。
●占有优先量词(☞142)和固化分组(☞139)。

DFA与NFA:实现难度的差异
尽管存在限制,但简单的DFA和NFA引擎都很容易理解和实现。对效率(包括时间和空间效率)和增强性能的追求,令实现越来越复杂。
用代码长度来衡量的话,支持NFA正则表达式的ed Version 7(1979年1月发布)只有不到350行的C代码(所以, 整个grep只有区区478行代码)。Henry Spencer1986年免费提供的Version 8正则程序差不多有1 900行C代码,1992年Tom Lord的POSIX NFA package rx(被GNU sed和其他工具采用)长达9 700行。
为了糅合DFA和NFA的优点,GNU egrep Version 2.4.2使用了两个功能完整的引擎(差不多8 900行代码),Tcl的DFA/NFA混合引擎(请看上一页的补充内容)更是长达9 500行。
某些实现很简单,但这并不是说它们支持的功能有限。我曾经想要用 Pascal 的正则表达式来处理某些文本。从毕业以后我就没用过Pascal了,但是写个简单的NFA引擎并不需要太多工夫。它并不追求花哨,也不追求速度,但是提供了相对全面的功能,非常实用。