More About Greediness and Backtracking
NFA和DFA都具備許多匹配優先相關的特性(也從中獲益)。(DFA不支持忽略優先,所以我們現在只關注匹配優先)。我將考察兩種引擎共同支持的匹配優先特性,但只會用 NFA來講解。這些內容對DFA也適用,但原因與NFA不同。DFA是匹配優先的,使用起來很方便,這一點我們只需要記住就夠了,而且介紹起來也很乏味。相反,NFA 的匹配優先就很值得一談,因為NFA是表達式主導的,所以匹配優先的特性能產生許多神奇的結果。除了忽略優先,NFA還提供了其他許多特性,比如環視、條件判斷(conditions)、反向引用,以及固化分組。最重要的是NFA能讓使用者直接操控匹配的過程,如果運用得當,這會帶來很大的方便,但也可能帶來某些性能問題(具體見第6章)。

不考慮這些差異的話,匹配的結果通常是相通的。我介紹的內容適用於兩種引擎,除了使用表達式主導的NFA引擎。讀完本章,讀者會明白,在什麼情況下兩種引擎的結果會不一樣,以及為什麼會不一致。
匹配優先的問題
Problems of Greediness
在上例中已經看到,「.*」經常會匹配到一行文本的末尾(注6)。這是因為「.*」匹配時只從自身出發,匹配盡可能多的內容,只有在全局匹配需要的情況下才會「被迫」交還一些字符。有些時候問題很嚴重。來看用一個匹配雙引號文本的例子。讀者首先想到的可能是「〞.*〞」,那麼,請運用我們剛剛學到的關於「.*」的知識,猜一猜用它匹配下面文本的結果:
The name 〞McDonald's〞 is said 〞makudonarudo〞 in Japanese.
既然知道了匹配原理,其實我們並不需要猜測,因為我們「知道」結果。在最開始的雙引號匹配之後,「.*」能夠匹配任何字符,所以它會一直匹配到字符串的末尾。為了讓最後的雙引號能夠匹配,「.*」會不斷交還字符(或者,更確切地說,是正則引擎強迫它回退),直到滿足為止。最後,這個正則表達式匹配的結果就是:

這顯然不是我們期望的結果。我之所以提醒讀者不要過分依賴「.*」,這就是原因之一,如果不注意匹配優先的特性,結果往往出乎意料。
那麼,我們如何能夠只取得〞McDonald's〞呢?關鍵的問題在於要認識到,我們希望匹配的不是雙引號之間的「任何文本」,而是「除雙引號以外的任何文本」。如果用「[^〞]*」取代「.*」,就不會出現上面的問題。
使用「〞[^〞]*〞」時,正則引擎的基本匹配過程跟上面是一樣的。第一個雙引號匹配之後,「[^〞]*」會匹配盡可能多的字符。在本例中,就是 McDonald's,因為「[^〞]」無法匹配之後的雙引號。此時,控制權轉移到正則表達式末尾的「〞」。而它剛好能夠匹配,所以獲得全局匹配:
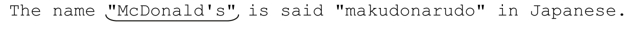
事實上,可能還存在一種出乎讀者預料的情況,因為在大多數流派中,「[^〞]」能夠匹配換行符,而點號則不能。如果不想讓表達式匹配換行符,可以使用「[^〞\n]」。
多字符「引文」
Multi-Character"Quotes"
第1章出現了對HTML tag的匹配,例如,瀏覽器會把<B>very</B>中的「very」渲染為粗體。對<B>…</B>的匹配嘗試看起來與對雙引號匹配的情形很相似,只是「雙引號」在這裡成了多字符構成的<B>和</B>。與雙引號字符串的例子一樣,使用「.*」匹配多字符「引文」也會出錯:
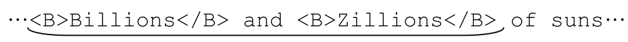
「<B>.*</B>」中匹配優先的「.*」會一直匹配該行結尾的字符,回溯只會進行到「</B>」能夠匹配為止,也就是最後一個</B>,而不是與匹配開頭的「<B>」對應的「</B>」。
不幸的是,因為結束tag不是單個字符,所以不能用之前的辦法,也就是「排除型字符組」來解決,即我們不能期望用「<B>[^</B>]*</B>」解決問題。字符組只能代表單個字符,而我們需要的「</B>」是一組字符。請不要被「[^</B>]」迷惑,它只是表示一個不等於<、>、/、B的字符,等價於「[^/<>B]」,而這顯然不是我們想要的「除</B>結構之外的任何內容」(當然,如果使用環視功能,我們可以規定,在某個位置不應該匹配「</B>」,下一節會出現這種應用)。
使用忽略優先量詞
Using Lazy Quantifiers
上面的問題之所以會出現,原因在於標準量詞是匹配優先的。某些NFA支持忽略優先的量詞(☞141),*?就是與 * 對應的忽略優先量詞。我們用「<B>.*?</B>」來匹配:
…<B>Billions</B> and <B>Zillions</B> of suns…
開始的「<B>」匹配之後,「.*?」首先決定不需要匹配任何字符,因為它是忽略優先的。於是,控制權交給後面的「<」符號:

此時「<」無法匹配,所以控制權交還給「.*?」,因為還有未嘗試過的匹配可能(事實上能夠進行多次匹配嘗試)。它的匹配嘗試是步步為營的(begrudgingly),先用點號來匹配…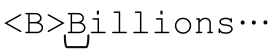 中帶下畫線的B。此時,*?又必須選擇,是繼續嘗試匹配,還是忽略?因為它是忽略優先的,會首先選擇忽略。接下來的「<」仍然無法匹配,所以「.*?」必須繼續嘗試未匹配的分支。在這個過程重複 8 次之後,「.*?」最終匹配了 Billions,此時,解下來的「<」(以及整個「</B>」)都能匹配:
中帶下畫線的B。此時,*?又必須選擇,是繼續嘗試匹配,還是忽略?因為它是忽略優先的,會首先選擇忽略。接下來的「<」仍然無法匹配,所以「.*?」必須繼續嘗試未匹配的分支。在這個過程重複 8 次之後,「.*?」最終匹配了 Billions,此時,解下來的「<」(以及整個「</B>」)都能匹配:
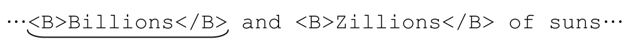
所以我們知道了,星號之類的匹配優先量詞有時候的確很方便,但有時候也會帶來大麻煩。這時候,忽略優先的量詞就能派上用場了,因為它們做到其他辦法很難做到(甚至無法做到)的事情。當然,缺乏經驗的程序員也可能錯誤地使用忽略優先量詞。事實上,我們剛剛做的或許就不正確。如果用「<B>.*?</B>」來匹配:
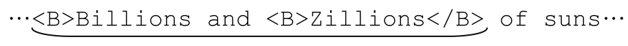
結果如上圖,雖然我假設匹配的結果取決於具體的需求,但我仍然認為,這種情況下的結果不是用戶期望的。不過,「.*?」必然會匹配Zillions左邊的<B>,一直到</B>。
這個例子很好地說明了,為什麼通常情況下,忽略優先量詞並不是排除類的完美替身。在「〞.*〞」的例子中,使用「[^〞]」替換點號能避免跨越引號的匹配——這正是我們希望實現的功能。
如果支持排除環視(☞133),我們就能得到與排除型字符組相當的結果。比如,「(?!<B>)」這個測試,只有當<B>不在字符串中的當前位置時才能成功。這也是「<B>.*?</B>」中的點號期望匹配的內容,所以把點號改為「((?!<B>).)」得到的正則表達式,就能準確匹配我們期望的內容。把這些綜合起來,結果有點兒難看懂,所以我選用帶註釋的寬鬆排列模式(☞111)來講解:

使用了環視功能之後,我們可以重新使用普通的匹配優先量詞,這樣看起來更清楚:

現在,環視功能會禁止正則表達式的主體(main body)匹配<B>和</B>之外的內容,這也是我們之前試圖用忽略優先量詞解決的問題,所以現在可以不用忽略優先功能了。這個表達式還有能夠改進的地方,我們將在第6章關於效率的討論中看到它(☞270)。
匹配優先和忽略優先都期望獲得匹配
Greediness and Laziness Always Favor a Match
回憶一下第2章中顯示價格的例子(☞51)。我們會在本章的多個地方仔細檢查這個例子,所以我先重申一下基本的問題:因為浮點數的顯示問題,「1.625」或者「3.00」有時候會變成「1.62500000002828」和「3.00000000028822」。為解決這個問題,我使用:
$price=~s/(\.\d\d[1-9]?)\d*/$1/;
來保存$price小數點後頭兩到三位十進制數字。「\.\d\d」匹配最開始兩位數字,而「[1-9]?」用來匹配可能出現的不等於零的第三個數字。
然後我寫道:
到現在,我們能夠匹配的任何內容都是希望保留的,所以用括號包圍起來,作為$1捕獲。然後就能在replacement字符串中使用$1。如果這個正則表達式能夠匹配的文本就等於$1,那麼我們就是用一個文本取代它本身——這沒有多少意義。然而,我們繼續匹配$1括號之外的部分。在替代字符串中它們並不出現,所以結果就是它們被刪掉了。在本例中,「要刪掉」的文本就是任何多餘的數字,也就是正則表達式中末尾的「\d*」匹配的部分。
到現在看起來一切正常,但是,如果$price的數據本身規範格式,會出現什麼問題呢?如果$price是27.625,那麼「\.\d\d[1-9]?」能夠匹配整個小數部分。因為「\d*」無法匹配任何字符,整個替換就是用『.625』替換『.625』——相當於白費工夫。
結果當然是我們需要的,但是否存在更有效率的辦法,只進行真正必要的替換(也就是,只有當「\d*」確實能夠匹配到某些字符的時候才替換)呢?當然,我們知道怎樣表示「至少一位數字」!只要把「\d*」替換為「\d+」就好了:
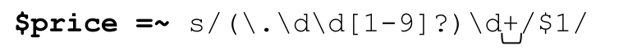
對於「1.62500000002828」這樣複雜的數字,正則表達式仍然有效;但是對於「9.43」這種數字,末尾的「\d+」不能匹配,所以不會替換。所以,這是個了不起的改動,對嗎?不!如果要處理的數字是27.625,情況如何呢?我們希望這個數字能夠被忽略,但是這不會發生。請仔細想想27.625的匹配過程,尤其是表達式如何處理『5』這個數字。
知道答案之後,這個問題就變得非常簡單了。在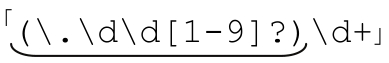 匹配
匹配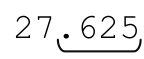 之後,「\d+」無法匹配。但這並不會影響整個表達式的匹配,因為就正則表達式而言,由「[1-9]」匹配『5』只是可選的分支之一,還有一個備用狀態尚未嘗試。它容許「[1-9]?」匹配一個空字符,而把5留給至少必須匹配一個字符的「\d+」。於是,我們得到的是錯誤的結果:.625被替換成了.62。
之後,「\d+」無法匹配。但這並不會影響整個表達式的匹配,因為就正則表達式而言,由「[1-9]」匹配『5』只是可選的分支之一,還有一個備用狀態尚未嘗試。它容許「[1-9]?」匹配一個空字符,而把5留給至少必須匹配一個字符的「\d+」。於是,我們得到的是錯誤的結果:.625被替換成了.62。
如果「[1-9]?」是忽略優先的又如何呢?我們會得到同樣的匹配結果,但不會有「先匹配 5再回溯」的過程,因為忽略優先的「[1-9]??」首先會忽略嘗試匹配的選項。所以,忽略優先量詞並不能解決這個問題。
匹配優先、忽略優先和回溯的要旨
The Essence of Greediness,Laziness,and Backtracking
之前的章節告訴我們,正則表達式中的某個元素,無論是匹配優先,還是忽略優先,都是為全局匹配服務的,在這一點上(對前面的例子來說)它們沒有區別。如果全局匹配需要,無論是匹配優先(或是忽略優先),在遇到「本地匹配失敗」時,引擎都會回歸到備用狀態(按照足跡返回找到麵包屑),然後嘗試尚未嘗試的路徑。無論匹配優先還是忽略優先,只要引擎報告匹配失敗,它就必然嘗試了所有的可能。
測試路徑的先後順序,在匹配優先和忽略優先的情況下是不同的(這就是兩者存在的理由),但是,只有在測試完所有可能的路徑之後,才會最終報告匹配失敗。
相反,如果只有一條可能的路徑,那麼使用匹配優先量詞和忽略優先量詞的正則表達式都能找到這個結果,只是他們嘗試路徑的次序不同。在這種情況下,選擇匹配優先還是忽略優先,並不會影響匹配的結果,受影響的只是引擎在達到最終匹配之前需要嘗試的次數(這是關於效率的問題,第6章將會談到)。
最後,如果存在不止一個可能的匹配結果,那麼理解匹配優先、忽略優先和回溯的讀者,就明白應該如何選擇。「〞.*〞」有3個可能的匹配結果:
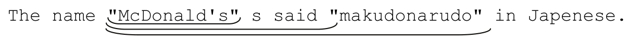
我們知道,使用匹配優先星號的「〞.*〞」匹配最長的結果,而使用忽略優先星號的「〞.*?〞」匹配最短的結果。
佔有優先量詞和固化分組
Possessive Quantifiers and Atomic Grouping
上一頁中『.625』的例子展示了關於NFA匹配的重要知識,也讓我們認識到,針對這個具體的例子,考慮不仔細就會帶來問題。針對某些流派提供了工具來幫助我們,但是在接觸它們以前,必須徹底弄明白「匹配優先、忽略優先和回溯的要旨」這一節。如果讀者還有不明白的地方,請務必仔細閱讀上一節。
那麼,仍然來考慮『.625』的例子,想想我們真正的目的。我們知道,如果匹配能夠進行到「(\.\d\d[1-9]?)☞\d+」中標記的位置,我們就不希望進行回溯。也就是說,我們希望的是,如果可能,「[1-9]」能夠一個字符,果真如此的話,我們不希望交還這個字符。或者說的更直白一些就是,如果需要的話,我們希望在「[1-9]」匹配的字符交還之前,整個表達式就匹配失敗。(這個正則表達式匹配『.625』時的問題在於,它不會匹配失敗,而是進行回溯,嘗試其他備用狀態)。
那麼,如果我們能夠避免這些備用狀態呢(也就是在[1-9]進行嘗試之前,放棄「?」保存的狀態,)?如果沒有退路,「[1-9]」的匹配就不會交還。而這就是我們需要的!但是,如果沒有了這個備用狀態會發生什麼?如果我們用這個表達式來匹配『.5000』呢?此時「[1-9]」不能匹配,就確實需要回溯,放棄「[1-9]」,讓之後的「\d+」能夠匹配需要刪除的數字。
聽起來,我們有兩種相反的要求,但是仔細考慮考慮就會發現,我們真正需要的是,只有在某個可選元素已經匹配成功的情況下才拋棄此元素的「忽略」狀態。也就是說,如果「[1-9]」能夠成功匹配,就必須拋棄對應的備用狀態,這樣就永遠也不會回退。如果正則表達式的流派支持固化分組「(?>…)」(☞139),或者佔有優先量詞「[1-9]?+」(☞142),就可以這麼做。首先來看固化分組。
用(?>…)實現固化分組
具體來說,使用「(?>…)」的匹配與正常的匹配並無差別,但是如果匹配進行到此結構之後(也就是,進行到閉括號之後),那麼此結構體中的所有備用狀態都會被放棄。也就是說,在固化分組匹配結束時,它已經匹配的文本已經固化為一個單元,只能作為整體而保留或放棄。括號內的子表達式中未嘗試過的備用狀態都不復存在了,所以回溯永遠也不能選擇其中的狀態(至少是,當此結構匹配完成時,「鎖定(locked in)」在其中的狀態)。
所以,讓我們來看「(\.\d\d(?>[1-9]?))\d+」。在固化分組內,量詞能夠正常工作,所以如果「[1-9]」不能匹配,正則表達式會返回「?」留下的備用狀態。然後匹配脫離固化分組,繼續前進到「\d+」。在這種情況下,當控制權離開固化分組時,沒有備用狀態需要放棄(因為在固化分組中沒有創建任何備用狀態)。
如果「[1-9]」能夠匹配,匹配脫離固化分組之後,「?」保存的備用狀態仍然存在。但是,因為它屬於已經結束的固化分組,所以會被拋棄。匹配『.625』或者『.625000』時就會發生這種情況。在後一種情況下,放棄那些狀態不會帶來任何麻煩,因為「\d+」匹配的是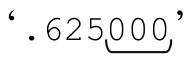 ,到這裡正則表達式已經完成匹配。但是對於『.625』來說,因為「\d+」無法匹配,正則引擎需要回溯,但回溯又無法進行,因為備用狀態已經不存在了。既然沒有能夠回溯的備用狀態,整體匹配也就失敗,『.625』不需要處理,而這正是我們期望的。
,到這裡正則表達式已經完成匹配。但是對於『.625』來說,因為「\d+」無法匹配,正則引擎需要回溯,但回溯又無法進行,因為備用狀態已經不存在了。既然沒有能夠回溯的備用狀態,整體匹配也就失敗,『.625』不需要處理,而這正是我們期望的。
固化分組的要旨
從第168頁開始的「匹配優先、忽略優先和回溯的要旨」這一節,說明了一個重要的事實,即匹配優先和忽略優先都不會影響需要檢測路徑的本身,而只會影響檢測的順序。如果不能匹配,無論是按照匹配優先還是忽略優先的順序,最終每條路徑都會被測試。
然而,固化分組與它們截然不同,因為固化分組會放棄某些可能的路徑。根據具體情況的不同,放棄備用狀態可能會導致不同的結果:
●毫無影響 如果在使用備用狀態之前能夠完成匹配,固化分組就不會影響匹配。我們剛剛看過『.625000』的匹配。全局匹配在備用狀態尚未起作用之前就已經完成。
●導致匹配失敗 放棄備用狀態可能意味著,本來有可能成功的匹配現在不可能成功了。『6.25』的例子就是如此。
●改變匹配結果 在某些情況下,放棄備用狀態可能得到不同的匹配結果。
●加快報告匹配失敗的速度 如果不能找到匹配對象,放棄備用狀態可能能讓正則引擎更快地報告匹配失敗。先做個小測驗,然後我們來談這點。
ϖ 小測驗:「(?>.*?)」是什麼意思?它能匹配什麼文本?請翻到下頁查看答案。
某些狀態可能保留 在匹配過程中,引擎退出固化分組時,放棄的只是固化分組中創建的狀態。而之前創建的狀態依然保留,所以,如果後來的回溯要求退回到之前的備用狀態,固化分組部分匹配的文本會全部交還。
使用固化分組加快匹配失敗的速度 我們一眼就能看出,「^\w+:」無法匹配『Subject』,因為『Subject』中不含冒號,但正則引擎必須經過嘗試才能得到這個結論。
第一次檢查「:」時,「\w+」已經匹配到了字符串的結尾,保存了若干狀態——「\w」匹配的每個字符,都對應有「忽略」的備用狀態(第一個除外,因為加號要求至少匹配一次)。「:」無法匹配字符串的末尾,所以正則引擎會回溯到最近的備用狀態:
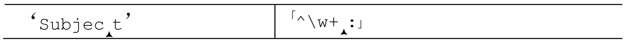
此處的字符是『t』,「:」仍然無法匹配。於是回溯-測試-失敗的循環會不斷發生,最終退回開始的狀態:
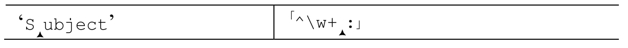
此處仍然無法匹配成功,所以報告整個表達式無法匹配。

我們只消看一眼就能知道,所有的回溯都是白費工夫。如果冒號無法匹配最後的字符,那麼它當然無法匹配「+」交還的任何字符。
既然我們知道,「\w+」匹配結束之後,從任何備用狀態開始測試都不能得到全局匹配,就可以命令正則引擎不必檢查它們:「^(?>\w+)」。我們已經全面瞭解了正則表達式的匹配過程,可以使用固化分組來控制「\w+」的匹配,放棄備用的狀態(因為我們知道它們沒有用),提高效率。如果存在可以匹配的文本,那麼固化分組不會有任何影響,但是如果不存在能夠匹配的文本,放棄這些無用的狀態會讓正則引擎更快地得出無法匹配的結論(先進的實現也許能夠自動進行這樣的優化,☞251)。
我們將在第6章看到(第269頁),固化分組非常有價值,我懷疑它可能會成為最常用的技巧。
佔有優先量詞,?+、*+、++和{m,n}+
Possessive Quantifiers,?+,++,++,and{m,n}+
佔有優先量詞與匹配優先量詞很相似,只是它們從來不交還已經匹配的字符。我們在「^\w+」的例子中看到,加號在匹配結束之前創建了很少的備用狀態,而佔有優先的加號會直接放棄這些狀態(或者,更形象地說,並不會創造這些狀態)。
你也許會想,佔有優先量詞和固化分組關係非常緊密。像「\w++」這樣的佔有優先量詞與「(?>\w+)」的匹配結果完全相同,只是寫起來更加方便而已(注 7)。使用佔有優先量詞,「^(?>\w+):」可以寫作「^\w++:」,「(\.\d\d(?>[1-9]?))\d+」寫做「(\.\d\d[1-9]?+)^\d+」。請務必區分「(?>M)+」和「(?M+)」。前者放棄「M」創建的備用狀態,因為「M」不會製造任何狀態,所以這樣做沒什麼價值。而後者放棄「M+」創造的未使用狀態,這樣做顯然有意義。
比較「(?>M)+」和「(?>M+)」,顯然後者就對應於「M++」,但如果表達式很複雜,例如「(\\〞|[^〞])*+」,從佔有優先量詞轉換為固化分組時大家往往會想到在括號中添加『?>』得到「 (?>\\〞|[^〞])*」。這個表達式或許有機會實現你的目的,但它顯然不等於那個使用佔有優先量詞的表達式;它就好像是把「M++」寫作「(?>M)+」一樣。正確的辦法是,去掉表示佔有優先的加號,用固化分組把餘下的部分包括起來:「(?>(\\〞|[^〞])*)」。
環視中的回溯
The Backtracking of Lookaround
初看時並不容易認識到,環視(見第 2 章,☞59)與固化分組和佔有優先量詞有緊密的聯繫。環視分為 4 種:肯定型(positive)和否定型(negative),順序環視與逆序環視。它們只是簡單地測試,其中表達式能否在當前位置匹配後面的文本(順序環視),或者前面的文本(逆序環視)。
深入點看,在NFA的世界中包含了備用狀態和回溯,環視是怎麼實現的?環視結構中的子表達式有自己的世界。它也會保存備用狀態,進行必要的回溯。如果整個子表達式能夠成功匹配,結果如何呢?肯定型環視會認為自己匹配成功;而否定環視會認為匹配失敗。在任何一種情況下,因為關注的只是匹配存在與否(在剛才的例子中,的確存在匹配),此匹配嘗試所在的「世界」,包括在嘗試中創造的所有備用狀態,都會被放棄。
如果環視中的子表達式無法匹配,結果如何呢?因為它只應用到這個「世界」中,所以回溯時只能選擇當前環視結構中的備用狀態。也就是說,如果正則表達式發現,需要進一步回溯到當前的環視結構的起點以前,它就認為當前的子表達式無法匹配。對肯定型環視來說,這就意味著失敗,而對於否定型環視來說,這意味著成功。在任何一種情況下,都沒有保留備用狀態(如果有,那麼子表達式的匹配嘗試就沒有結束),自然也談不上放棄。
所以我們知道,只要環視結構的匹配嘗試結束,它就不會留下任何備用狀態。任何備用狀態和例子中肯定環視成功時的情況一樣,都會被放棄。我們在其他什麼地方看到過放棄狀態?當然是固化分組和佔有優先量詞。
用肯定環視模擬固化分組
如果流派本身支持固化分組,這麼做可能有點多此一舉,但如果流派不支持固化分組,這麼做就很有用:如果所使用的工具支持肯定環視,同時可以在肯定環視中使用捕獲括號(大多數風格都支持,但也有些不支持,Tcl 就是如此),就能模擬實現固化分組和佔有優先量詞。「(?>regex)」可以用「(?=(regex))\1」來模擬。舉例來說,比較「(?>\w+):」和「^(?=(\w+))\1:」。
環視中的「\w+」是匹配優先的,它會匹配盡可能多的字符,也就是整個單詞。因為它在環視結構中,當環視結束之後,備用狀態都會放棄(和固化分組一樣)。但與固化分組不一樣的是,雖然此時確實捕獲了這個單詞,但它不是全局匹配的一部分(這就是環視的意義)。這裡的關鍵就是,後面的「\1」捕獲的就是環視結構捕獲的單詞,而這當然會匹配成功。在這裡使用「\1」並非多此一舉,而是為了把匹配從這個單詞結束的位置進行下去。
這個技巧比真正的固化分組要慢一些,因為需要額外的時間來重新匹配「\1」的文本。不過,因為環視結構可以放棄備用狀態,如果冒號無法匹配,它的失敗會來得更快一些。
多選結構也是匹配優先的嗎
Is Alternation Greedy?
多選分支的工作原理非常重要,因為在不同的正則引擎中它們是迥然不同的。如果遇到的多個多選分支都能夠匹配,究竟會選擇哪一個呢?或者說,如果不只一個多選分支能夠匹配,最後究竟應該選擇哪一個呢?如果選擇的是匹配文本最長的多選分支,有人也許會說多選結構也是匹配優先的;如果選擇的是匹配文本最短的多選分支,有人也許會說它是忽略優先的?那麼(如果只能是一個的話)究竟是哪個?
讓我們看看Perl、PHP、Java、.NET以及其他語言使用的傳統型NFA引擎。遇到多選結構時,這種引擎會按照從左到右的順序檢查表達式中的多選分支。拿正則表達式「^(Subject|Date):·」來說,遇到「Subject|Date」時,首先嘗試的是「Subject」。如果能夠匹配,就轉而處理接下來的部分(也就是後面的「:·」)。如果無法匹配,而此時又有其他多選分支(就是例子中的「Date」),正則引擎會回溯來嘗試它。這個例子同樣說明,正則引擎會回溯到存在尚未嘗試的多選分支的地方。這個過程會不斷重複,直到完成全局匹配,或者所有的分支(也就是本例中的所有多選分支)都嘗試窮盡為止。
所以,對於常見的傳統型NFA引擎,用「tour|to|tournament」來匹配『three·tournaments· won』時,會得到什麼結果呢?在嘗試到『three·☞tournaments·won』時,在每個位置進行的匹配嘗試都會失敗,而且每次嘗試時,都會檢查所有的多選分支(並且失敗)。而在這個位置,第一個多選分支「tour」能夠匹配。因為這個多選結構是正則表達式中的最後部分,「tour」匹配結束也就意味著整個表達式匹配完成。其他的多選分支就不會嘗試了。
因此我們知道,多選結構既不是匹配優先的,也不是忽略優先的,而是按順序排列的,至少對傳統型NFA來說是如此。這比匹配優先的多選結構更有用,因為這樣我們能夠對匹配的過程進行更多的控制——正則表達式的使用者可以用它下令:「先試這個,再試那個,最後試另一個,直到試出結果為止」。
不過,也不是所有的流派都支持按序排列的多選結構。DFA和POSIX NFA確實有匹配優先的多選結構,它們總是匹配所有多選分支中能匹配最多文本的那個(也就是本例中的「tournament」)。但是,如果你使用的是Perl、PHP、.NET、java.util.regex,或者其他使用傳統型NFA的工具,多選結構就是按序排列的。
發掘有序多選結構的價值
Taking Advantage of Ordered Alternation
回過頭來看第167頁「(\.\d\d[1-9]?)\d*」的例子。如果我們明白,「\.\d\d[1-9]?」其實等於「\.\d\d」或者「\.\d\d[1-9]」,我們就可以把整個表達式重新寫作「(\.\d\d|\.\d\d[1-9])\d*」。(這並非必須的改動,只是舉例說明)。這個表達式與之前的完全一樣嗎?如果多選結構是匹配優先的,那麼答案就是肯定的,但如果多選結構是有序的,兩者就完全不一樣。
我們來看多選結構有序的情形。首先選擇和測試的是第一個多選分支,如果能夠匹配,控制權就轉移到緊接的「\d*」那裡。如果還有其他的數字,「\d*」能夠匹配它們,也就是任何不為零的數字,它們是原來問題的根源(如果讀者還記得,當時的問題就在於,這位數字我們只希望在括號裡匹配,而不通過括號外面的「\d*」)。所以,如果第一個多選分支無法匹配,第二個多選分支同樣無法匹配,因為二者的開頭是一樣的。即使第一個多選結構無法匹配,正則引擎仍然會對第二個多選分支進行徒勞的嘗試。
不過,如果交換多選分支的順序,變成「(\.\d\d[1-9]|\.\d\d)\d*」,它就等價於匹配優先的「(\.\d\d[1-9]?)\d*」。如果第一個多選分支結尾的「[1-9]」匹配失敗,第二個多選分支仍然有機會成功。我們使用的仍然是有序排列的多選結構,但是通過變換順序,實現了匹配優先的功能。
第一次拆分「[1-9]?」成兩個多選分支時,我們把較短的分支放在了前面,得到了一個不具備匹配優先功能的「?」。在這個具體的例子中,這麼做沒有意義,因為如果第一個多選分支不能匹配,第二個肯定也無法匹配。我經常看到這樣沒有意義的多選結構,對傳統型 NFA來說,這肯定不對。我曾看到有一本書以「a((ab)*|b*)」為例講解傳統型NFA 正則表達式的括號。這個例子顯然沒有意義,因為第一個多選分支「(ab)*」永遠也不會匹配失敗,所以後面的其他多選分支毫無意義。你可以繼續添加:

這個正則表達式的意義都不會有絲毫的改變。要記住的是,如果多選分支是有序的,而能夠匹配同樣文本的多選分支又不只一個,就要小心安排多選分支的先後順序。
有序多選結構的陷阱
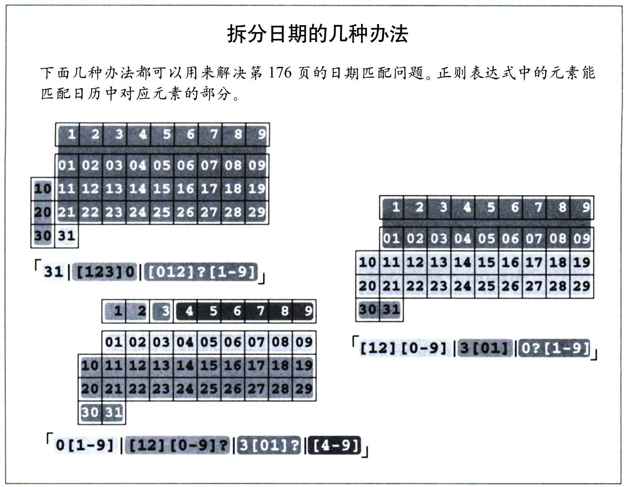
有序多選分支容許使用者控制期望的匹配,因此極為便利,但也會給不明就裡的人造成麻煩。如果需要匹配『Jan 31』之類的日期,我們需要的就不是簡單的「Jan·[0123][0-9]」,因為這樣的表達式能夠匹配『Jan·00』和『Jan·39』這樣的日期,卻無法匹配『Jan·7』。
一種辦法是把日期部分拆開。用「0?[1-9]」匹配可能以0開頭的前九天的日期。用「[12][0-9]」處理十號到二十九號,用「3[01]」處理最後兩天。把上面這些連起來,就是「Jan· (0?[1-9]|[12][0-9]|3[01])」。
如果用這個表達式來匹配『Jan 31 is Dad's birthday』,結果如何呢?我們希望獲得的當然是『Jan 31』,但是有序多選分支只會捕獲『Jan 3』。奇怪嗎?在匹配第一個多選分支「0?[1-9]」時,前面的「0?」無法匹配,但是這個多選分支仍然能夠匹配成功,因為「[1-9]」能夠匹配『3』。因為此多選分支位於正則表達式的末尾,所以匹配到此完成。
如果我們重新安排多選結構的順序環視,把能夠匹配的數字最短的放到最後,這個問題就解決了:「Jan·([12][0-9]|3[01]|0?[1-9])」。
另一種辦法是使用「Jan·(31|[123]0|[012]?[1-9])」。但這也要求我們仔細地安排多選分支的順序避免問題。還有一種辦法是「Jan·(0[1-9]|[12][0-9]?|3[01]?|[4-9])」,這樣不論順序環視如何都能獲得正確結果。比較和分析這 3 個不同的表達式,會有很多發現(我會給讀者一些時間來想這個問題,儘管下一頁的補充內容會有所幫助)。