
Expanding the Foundation
我希望,前面的例子和解釋已經幫助讀者牢固地打下了正則表達式的基礎,也請讀者明白,這些例子都很淺顯,我們需要掌握的還有很多。
語言的差異
Linguistic Diversification
我已經介紹過大多數版本的egrep支持的正則表達式的特性,這樣的特性還有很多,其中一些並不是所有的版本都支持,這個問題留到後面的章節講解。
任何語言中都存在不同的方言和口音,很不幸,正則表達式也一樣。情況似乎是,每一種支持正則表達式的語言都提供了自己的「改進」。正則表達式不斷發展,但多年的變化也造就了數目眾多的正則表達式「流派」(flavor)。我們會在下面的章節中見到各種例子。
正則表達式的目標
The Goal of a Regular Expression
從最宏觀的角度看,一個正則表達式要麼能夠匹配給定文本(對egrep來說,就是一行文本)中的某些字符,要麼不能匹配。在編寫正則表達式的時候,我們必須進行權衡:匹配符合要求的文本,同時忽略不符合要求的文本。
儘管egrep不關心匹配文本在行中的位置,但對正則表達式的其他應用來說,這個問題卻很重要。如果文本是這樣:
…zip is 44272.If you write,send $4.95 to cover postage and…
我們只希望找出包含「[0-9]+」的那些行,就不需要關心真正匹配的數字。相反,如果我們需要操作這些數字(例如保存到文件、添加、替換之類——我們會在下一章看到這樣的處理),就需要關心確切匹配的那些數字。
更多的例子
A Few More Examples
在任何語言中,經驗都是非常重要的,所以我會給出更多用正則表達式匹配常用文本結構的例子。
編寫正則表達式時,按照預期獲得成功的匹配要花去一半的工夫,另一半的工夫用來考慮如何忽略那些不符合要求的文本。在實踐中,這兩方面都非常重要,但是目前我們只關注「獲得成功匹配」的方面。即使我沒有對這些例子進行最全面徹底的解釋,它們仍然能夠提供有用的啟示。
變量名
許多程序設計語言都有標識符(identifier,例如變量名)的概念,標識符只包含字母、數字以及下畫線,但不能以數字開頭。我們可以用「[a-zA-Z_][a-zA-Z_0-9]*」來匹配標識符。第一個字符組匹配可能出現的第一個字符,第二個(包括對應的「*」)匹配餘下的字符。如果標識符的長度有限制,例如最長只能是32個字符,又能使用第20頁介紹的區間量詞「{min,max}」,我們可以用「{0,31}」來替代最後的「*」。
引號內的字符串
匹配引號內的字符串最簡單的辦法是使用這個表達式:「〞[^〞]*〞」。
兩端的引號用來匹配字符串開頭和結尾的引號。在這兩個引號之間的文本可以包括雙引號之外的任何字符。所以我們用「[^〞]」來匹配除雙引號之外的任何字符,用「*」來表示兩個引號之間可以存在任意數目的非雙引號字符。
關於引號字符串,更有用(也更複雜)的定義是,兩端的雙引號之間可以出現由反斜線轉義的雙引號,例如〞nail·the·2\〞x4\〞·plank〞。在後面的章節講解匹配實際進行的細節時,我們會多次遇到這個例子。
美元金額(可能包含小數)
「\$[0-9]+(\.[0-9][0-9])?」是一種匹配美元金額的辦法。
從整體上看,這個表達式很簡單,分為三部分:「\$」、「…+」和「(…)?」,可以大致理解為:一個美元符號,然後是一組字符,最後可能還有另一組字符。這裡的「字符」指的是數字(一組數字構成一個數值),「另一組字符」是由一個小數點和兩位數字構成的。
從幾個方面來看,這個表達式還很簡陋。比如,它只能接受$1000,而無法接受$1,000。它確實能接受可能出現的小數部分,但對於egrep來說意義不大。因為egrep從不關心匹配文字的內容,而只關心是否存在匹配。處理可能出現的小數部分對整個表達式能否匹配並沒有影響。
但是,如果我們需要找到只包含價格而不含其他字符的行,倒是可以在這個表達式兩端加上「^…$」。這樣一來,可選的小數部分就變得很重要了,因為在金額數值和換行符之間是否存在小數部分,決定了整個表達式的匹配結果是否存在差異。
另外,這個正則表達式還無法匹配『$.49』。你可能認為把加號換成星號能夠解決問題,不過這條路走不通。在這我先賣個關子,答案留待第5章(☞194)揭曉。
HTTP/HTML URL
Web URL的形式可能有很多種,所以構造一個能夠匹配所有形式的URL的正則表達式頗有難度。不過,稍微降低一點要求的話,我們能夠用一個相當簡單的正則表達式來匹配大多數常見的 URL。進行這種檢索的原因之一是,我只能大概記得在收到的某封郵件中有一個URL地址,不過一見到它我就能認出來。
常見的HTTP/HTML URL是下面這樣的:
http://hostname/path.html
當然,.htm的結尾也很常見。
hostname(主機名,例如www.yahoo.com)的規則比較複雜,但是我們知道,跟在『http://』之後的就有可能是主機名,所以這個正則表達式就很簡單,「[-a-z0-9_.]+」。path部分的變化更多,所以我們需要使用「[-a-z0-9_:@&?=+,.!/~*%$]*」。請注意,連字符必須放在字符組的開頭,保證它是一個普通字符,而不是用來表示範圍(☞9)。
綜合起來,我們第一次嘗試的正則表達式就是:
%egrep-i '\<http://[-a-z0-9_.:]+/[-a-z0-9_:@&?=+,.!/~*%$]*\.html?\>' files
因為我們降低了對匹配的要求,所以『http://..../foo.html』也能匹配,雖然它顯然不是一個合法的 URL。我們需要關心這一點嗎?這取決於具體的情況。如果我只是需要掃瞄自己的E-mail,得到一些錯誤結果並不算是問題。而且,我沒準會用更簡單的表達式:
%egrep-i '\<http://[^]*\.html?\>' files…
在深入瞭解如何調校正則表達式之後,讀者會明白,要想在複雜性和完整性之間求得平衡,一個重要的因素是瞭解待搜索的文本。下一章,我們會更詳細地考察這個例子。
HTML tag
對egrep這樣的工具來說,簡單地匹配包含HTML tag的行並不常見,也沒什麼用。但是,探索如何準確匹配一個HTML tag卻是相當有啟發的,在下一章深入接觸更高級的工具時,這一點尤其明顯。
簡單的例子包括『<TITLE>』和『<HR>』,我們可能會想到「<.*>」。這個簡單的表達式往往是最直接的想法,但它顯然是不對的。「<.*>」的意思是,「先匹配一個『<』,然後是任意多個任意字符,然後是『>』」。所以,它無疑能夠匹配不止一個tag的內容,例如『this example』中標記的內容。
example』中標記的內容。
也許結果有點出乎你的意料,但是我們目前還只在第 1 章,對正則表達式的理解也不夠深入。我之所以舉這個例子,是想說明正則表達式並不複雜,但是如果你不真正弄懂它們,可能會被搞得暈頭轉向。在下面的幾章中,我們會學習理解和解決這個問題需要的所有細節。
表示時刻的文字,例如「9:17 am」或者「12:30 pm」
匹配表示時刻的文字可能有不同的嚴格程度。
「[0-9]?[0-9]:[0-9][0-9]·(am|pm)」
能夠匹配9:17·am或者12:30·pm,但也能匹配無意義的時刻,如99:99·pm。
首先看小時數,我們知道,如果小時數是一個兩位數,第一位只能是 1。但是「1?[0-9] 」仍然能夠匹配19(也能夠匹配0),所以更好的辦法應該是把小時部分分為兩種情況來處理,「1[012] 」匹配兩位數,「[1-9]」匹配一位數,結果就是「(1[012]|[1-9])」。
分鐘數就簡單些。第一位數字應該是「[0-5]」,此時第二位數字應該是「[0-9]」。綜合起來就是「(1[012]|[1-9]):[0-5][0-9]·(am|pm)」。
舉一反三,你能夠處理24小時制的時間嗎?多動動腦筋,想想該如何處理以0開頭的情況,比如09:59呢?ϖ答案請見下頁。
正則表達式術語彙總
Regular Expression Nomenclature
正則(regex)
你或許已經猜到了,「正則表達式」(regular expression)這個全名念起來有點麻煩,寫出來就更麻煩。所以,我一般會採用「正則」(regex)的說法。這個單詞念起來很流暢(有點像聯邦快遞的FedEx,與regular一樣,g發重音,而不同於Regina),而且說「如果你寫一個正則」,「巧妙的正則」(budding regexers),甚至是「正則化」(regexification)(注10)(譯注4)。
匹配(matching)
一個正則表達式「匹配」一個字符串,其實是指這個正則表達式能在字符串中找到匹配文本。嚴格地說,正則表達式「a」不能匹配 cat,但是能匹配 cat中的 a。幾乎沒人會混淆這兩個概念,但澄清一下還是有必要的。
元字符(metacharacter)
一個字符是否元字符(或者是「元字符序列」(metasequence),這兩個概念是相等的),取決於應用的具體情況。例如,只有在字符組外部並且是在未轉義的情況下,「*」才是一個元字符。「轉義」(escaped)的意思是,通常情況下在這個字符之前有一個反斜線。「\*」是對「*」的轉義,而「\\*」則不是(第一個反斜線用來轉義第二個反斜線),雖然在兩個例子中,星號之前都有一個反斜線。
正則表達式的流派(flavor)不同,關於字符轉義的規定也不相同。第3章對此進行了詳細討論。
流派(flavor)
我已經說過,不同的工具使用不同的正則表達式完成不同的任務,每樣工具支持的元字符和其他特性各有不同。我們再舉單詞分界符的例子。某些版本的 egrep 支持我們曾見過的\<…\>表示法。而另一些版本不支持單獨的起始和結束邊界,只提供了統一的「\b」元字符(這個元字符我們還沒見過,下一章才會用到)。還有些工具同時支持這兩種表示法,另有許多工具哪種也不支持。
我用「流派(flavor)」這個詞來描述所有這些細微的實現規定。這就好像不同的人說不同的方言一樣。從表面上看,「流派」指的是關於元字符的規定,但它的內容遠遠不止這些。
即使兩個程序都支持「\<…\>」,它們可能對這兩個元字符的意義有不同的理解,對單詞的理解也不相同。在使用具體的工具軟件時,這個問題尤其重要。

請不要混淆「流派(flavor)」和「工具(tool)」這兩個概念。兩個人可以說同樣的方言,兩個完全不同的程序也可能屬於同樣的流派。同樣,兩個名字相同的程序(解決的任務也相同)所屬的流派可能有細微(有時可能並非細微)的差別。有許多程序都叫egrep,它們所屬的流派也五花八門。
由Perl語言的正則表達式開創的流派,在20世紀90年代中期因為其強大的表達能力廣為人們所知,其他語言緊隨其後,提供了汲取其中靈感的正則表達式(其中許多為了標明自己的思想來源,直接給自己貼上「兼容Perl(Perl-Compatible)」的標籤)。它們包括PHP、Python、Java的大量正則包,微軟的.NET Framework、Tcl,以及C的各種類庫。不過,所有這些語言在重要的方面各有不同。而且 Perl 的正則表達式也在不斷演化和發展(現在,有時候是受了其他語言的正則表達式的刺激)。像往常一樣,總的局面變得越來越複雜,讓人困惑。
子表達式(subexpression)
「子表達式」指的是整個正則表達式中的一部分,通常是括號內的表達式,或者是由「|」分隔的多選分支。例如,在「^(Subject|Date):·」中,「Subject|Date」通常被視為一個子表達式。其中的「Subject」和「Date」也算得上子表達式。而且,嚴格說起來,「S」、「u」、「b」、「j」這些字符,都算子表達式。
1-6 這樣的字符序列並不能算「H[1-6]·*」的子表達式,因為『1-6』所屬的字符組是不可分割的「單元(unit)」。但是,「H」、「[1-6]」、「·*」都是「H[1-6]·*」的子表達式。
與多選分支不同的是,量詞(星號、加號和問號)作用的對象是它們之前緊鄰的子表達式。所以「mis+pell」中的+作用的是「s」,而不是「mis」或者「is」。當然,如果量詞之前緊鄰的是一個括號包圍的子表達式,整個子表達式(無論多複雜)都被視為一個單元。
字符(character)
「字符」在計算機領域是一個有特殊意義的單詞。一個字節所代表的單詞取決於計算機如何解釋。單個字節的值不會變化,但這個值所代表的字符卻是由解釋所用的編碼來決定的。例如,值為64和53的字節,在ASCII編碼中分別代表了字符「@」和「5」,但在EBCDIC編碼中,則是完全不同的字符(一個是空格,一個是控制字符)。
另一方面,在流行的日文字符編碼中,這兩個字節代表一個字符正。如果換一種日文字符編碼,這個字就需要兩個完全不同的字節。那兩個字節,在通行的Latin-1編碼中,表示「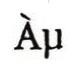 」,而在Unicode 編碼中又表示韓文的「
」,而在Unicode 編碼中又表示韓文的「 」(注11)。問題在於,字節如何解釋只是視角(稱為「編碼」encoding)的問題,我們要做的只是確保自己的視角和正在使用的工具的視角相同。
」(注11)。問題在於,字節如何解釋只是視角(稱為「編碼」encoding)的問題,我們要做的只是確保自己的視角和正在使用的工具的視角相同。
一直以來,文本處理軟件一般都把數據視為一些 ASCII 編碼的字節,而不考慮使用者期望採用的字符編碼。不過,近來已經有越來越多的系統在內部使用某些格式的Unicode編碼來處理數據(第3章介紹了Unicode,☞105)。如果這些系統中的正則表達式子系統的實現方式正確,使用者通常就不需要在編碼的問題上費太多工夫。這個「如果」相當複雜,所以第3章深入講解了這個問題。
改進現狀
Improving on the Status Quo
總的來說,正則表達式並不難。但是,如果你與使用過支持正則表達式的程序或語言的人交流過就會發現,某些人確實「會用」正則表達式,但如果需要解決複雜的問題,或是換用他們不熟悉的工具,就會出問題。
傳統的正則表達式文檔大都只包含一兩個元字符的簡略介紹,然後就給出關於其他元字符的表格。給出的例子通常也是無意義的「a*((ab)*|b*)」,文本則是『a·xxx·ce·xxxxxx· ci·xxx·d』。這些文檔大都忽略了細微但重要的知識點,總是聲稱自己與其他出名的工具屬於同一流派,而忘記提及必然存在的差異。它們缺乏實用價值。
當然,我的意思並不是,本章就能夠填補這道鴻溝,讓讀者掌握所有正則表達式,或是掌握egrep的正則表達式。相反,這一章只是為本書的其他內容鋪墊基礎。我希望本書能夠為讀者填補這道鴻溝,雖然這期望有點自負。很多讀者很滿意本書的第一版,我本人也為拓展這一版的深度和廣度付出了艱苦的努力。
或許是因為正則表達式的文檔一直都非常欠缺,我感到自己必須做出額外的努力,才能把知識梳理清楚。因為我希望保證讀者能夠充分運用正則表達式的潛力,我希望你們能夠真正精通正則表達式。
這既是件好事也是件壞事。
好處在於,你將學會如何以正則表達式的方式來思考問題。你將學習到,在面對屬於不同流派的新工具時,需要注意哪些差異和特性。你還將會學習到,如果某個流派的功能弱小、特性簡陋,該如何表達自己的意圖。你將會明白,一個正則表達式的效率優於其他表達式的原因所在,而且你將能夠在複雜性、效率和匹配準確性間進行取捨權衡。
面對特別複雜的任務,你將會知道如何通過程序容許的方式來構建和使用正則表達式。總的來說,你能夠得心應手地使用正則表達式的所有潛能。
問題在於,這種方法的學習曲線非常陡峭,而且還有幾大難點:
●正則表達式的使用 許多程序使用的正則表達式比egrep要複雜。在我們探討如何構造真正有用的正則表達式的細節之前,需要知道正則表達式的使用方法。下一章關注這一問題。
●正則表達式的特性(feature) 面對問題,選擇合適的工具是成功的一半,所以我會在全書中使用多種工具。不同的程序,甚至是同一個程序的不同版本,支持的特性和元字符都不一樣。在瞭解使用細節之前,我們必須搞清楚這個問題。這是第3章的主題。
●正則表達式的工作原理 在我們接觸有用(但通常也很複雜)的例子之前,我們必須「揭開蓋子」來瞭解正則表達式的工作原理。我們將會看到,對某些元字符進行嘗試匹配的次序是一個重要的問題。實際上,正則表達式引擎(regular expression engine)不同,工作原理也不同,所以對於同樣的正則表達式,不同的程序會得到不同的結果。我們將在第4、5、6章中探討這個複雜的問題。
正則表達式的工作原理是最重要同時也是最難以掌握的知識。研究這個問題有時的確很枯燥,更糟糕的是,讀者在接觸真正有趣的內容——解決實際問題——之前,不得不耐著性子看完它們。然而,弄懂正則表達式的工作原理,才是真正理解的關鍵。
你或許會想,如果只希望學會開車,是不需要瞭解汽車運行原理的。但是,學習開車與學習正則表達式之間並沒有多少相似性。我的目的是教會讀者如何使用正則表達式——也就是編寫正則表達式——來解決問題。更合適的比喻是,學習正則表達式就如同學習如何造車,而不是如何開車。在製造汽車以前,我們必須瞭解汽車的工作原理。
第2 章提供了更多的關於開車的經驗。第 3 章簡要回顧了開車的歷史,詳細考察了正則表達式流派的主要內容。第4 章介紹了正則表達式流派的重要的引擎。第5 章展示了一些更複雜的例子,第 6 章告訴你如何調校某種具體的引擎,之後的各章則是檢查具體的產品和模型。在第4、5、6章中,我們花了大量的篇幅來探討幕後的原理,所以請務必做好準備。
總結
Summary
表1-3總結了我們在本章中見過的egrep的元字符。
表1-3:egrep的元字符總結
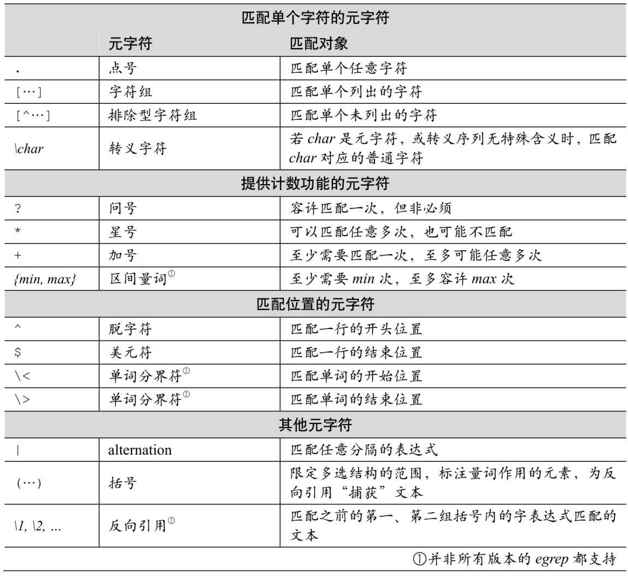
此外,請務必理解以下幾點:
●各個 egrep 程序是有差別的。它們支持的元字符,以及這些元字符的確切含義,通常都有差別——請參考相應的文檔(☞23)。
●使用括號的3個理由是:限制多選結構(☞13)、分組(☞14)和捕獲文本(☞21)。
●字符組的特殊性在於,關於元字符的規定是完全獨立於正則表達式語言「主體」的。
●多選結構和字符組是截然不同的,它們的功能完全不同,只是在有限的情況下,它們的表現相同(☞13)。
●排除型字符組同樣是一種「肯定斷言」(positive assertion)——即使它的名字裡包含了「排除」兩個字,它仍然需要匹配一個字符。只是因為列出的字符都會被排除,所以最終匹配的字符肯定不在列出的字符之內(☞12)。
●-i的參數很有用,它能進行忽略大小寫的匹配(☞15)。
●轉義有3種情況:
1.「\」加上元字符,表示匹配元字符所使用的普通字符(例如「\*」匹配普通的星號)。
2.「\」加上非元字符,組成一種由具體實現方式規定其意義的元字符序列(例如,「\<」表示「單詞的起始邊界」)。
3.「\」加上任意其他字符,默認情況就是匹配此字符(也就是說,反斜線被忽略了)。請記住,對大多數版本的egrep來說,字符組內部的反斜線沒有任何特殊意義,所以此時它並不是一個轉義字符。
●由星號和問號限定的對象在「匹配成功」時可能並沒有匹配任何字符。即使什麼字符都不能匹配到,它們仍然會報告「匹配成功」。