
Egrep Metacharacters
現在我們來看egrep中支持正則表達式功能的元字符。我會用幾個例子來簡要介紹它們,把詳細的例子和描述留到後面的章節。
印刷體例 在開始之前,請務必回顧前言第V頁上解釋的體例說明。本書使用了一些新的文字形式,所以某些體例讀者初次接觸可能並不熟悉。
行的起始和結束
Start and End of the Line
或許最容易理解的元字符就是脫字符號「^」和美元符號「$」了,在檢查一行文本時,「^」代表一行的開始,「$」代表結束。我們曾經看到,正則表達式「cat」尋找的是一行文本中任意位置的c·a·t,但是「^cat」只尋找行首的 c·a·t——「^」用來把匹配文本(這個表達式的其他部分匹配的字符)「錨定」(anchor)在這一行的開頭。同樣,「cat$」只尋找位於行末的c·a·t,例如以scat結尾的行。
讀者最好能養成按照字符來理解正則表達式的習慣。例如,不要這樣:
「^cat」匹配以cat開頭的行
而應該這樣理解:
「^cat」匹配的是以c作為一行的第一個字符,緊接一個a,緊接一個t的文本。
這兩種理解的結果並無差異,但按照字符來解讀更易於明白新遇到的正則表達式的內部邏輯。egrep會如何解釋「^cat$」、「^$」和單個的「^」呢?ϖ 請翻到下頁查看答案。
脫字符號和美元符號的特別之處就在於,它們匹配的是一個位置,而不是具體的文本。當然,有很多方式可以匹配具體文本。在正則表達式中,除了使用「cat」之類的普通字符,還可以使用下面幾節介紹的元字符。
字符組
Character Classes
匹配若干字符之一
如果我們需要搜索的是單詞「grey」,同時又不確定它是否寫作「gray」,就可以使用正則表達式結構體(construct)「[…]」。它容許使用者列出在某處期望匹配的字符,通常被稱作字符組(character class(譯注2))。「e」匹配字符e,「a」匹配字符a,而正則表達式「[ea]」能匹配a或者e。所以,「gr[ea]y」的意思是:先找到g,跟著是一個r,然後是一個a或者e,最後是一個y。我很不擅長拼寫,所以總是用正則表達式從一大堆英文單詞中找到正確的拼寫。我經常使用的一個正則表達式是「sep[ea]r[ea]te」,因為我從來都記不住這個單詞到底是寫作「seperate」,「separate」,「separete」,還是別的什麼樣子。匹配的結果的就是正確的拼法,而正則表達式就是我的領路人。
請注意,在字符組以外,普通字符(例如「gr[ae]y」中的「g」和「r」)都有「接下來是(and then)」的意思——「首先匹配「g」,接下來是「r」……」。這與字符組內部的情況是完全相反的。字符組的內容是在同一個位置能夠匹配的若干字符,所以它的意思是「或」。
來看另一個例子,我們還必須考慮單詞的第一個字母為大寫的情況,例如「[Ss]mith」。請記住,這個表達式仍然能夠匹配內嵌在其他單詞裡頭的 smith(或者是 Smith),例如blacksmith。在綜述階段,我不打算為這種情況費太多筆墨,但是這確實是某些新手遇到的問題的根源。等瞭解了更多的元字符以後,我會介紹一些辦法來解決單詞嵌套的問題。在一個字符組中可以列舉任意多個字符。例如「[123456]」匹配1到6中的任意一個數字。這個字符組可以作為「<H[123456]>」的一部分,用來匹配<H1>、<H2>、<H3>等等。在搜索HTML代碼的頭文件時這非常有用。
在字符組內部,字符組元字符(character-class metacharacter)『-』(連字符)表示一個範圍:「<H[1-6]>」與「<H[123456]>」是完全一樣的。「[0-9]」和「[a-z]」是常用的匹配數字和小寫字母的簡便方式。多重範圍也是容許的,例如「[0123456789abcdefABCDEF]」可以寫作「[0-9a-fA-F]」(或者也可以寫作「[A-Fa-f0-9]」,順序無所謂)。這3個正則表達式非常適用於處理十六進制數字。我們還可以隨心所欲地把字符範圍與普通文本結合起來:「[0-9A-Z_!.?]」能夠匹配一個數字、大寫字母、下畫線、驚歎號、點號,或者是問號。
請注意,只有在字符組內部,連字符才是元字符——否則它就只能匹配普通的連字符號。其實,即使在字符組內部,它也不一定就是元字符。如果連字符出現在字符組的開頭,它表示的就只是一個普通字符,而不是一個範圍。同樣的道理,問號和點號通常被當作元字符處理,但在字符組中則不是如此(說明白一點就是,「[0-9A-Z_!.?]」裡面,真正的特殊字符就只有那兩個連字符)。

不妨把字符組看作獨立的微型語言。在字符組內部和外部,關於元字符的規定(哪
些是元字符,以及它們的意義)是不同的。
我們很快就會看到更多的例子。
排除型字符組
用「[^…]」取代「[…]」,這個字符組就會匹配任何未列出的字符。例如,「[^1-6]」匹配除了1到 6 以外的任何字符。這個字符組中開頭的「^」表示「排除(negate)」,所以這裡列出的不是希望匹配的字符,而是不希望匹配的字符。
讀者可能注意到了,這裡的^和第8頁的表示行首的脫字符是一樣的。字符確實相同,但意義截然不同。英語裡的「wind」,根據情境的不同,可能表示一陣強烈的氣流(風),也可能表示給鐘錶上發條;元字符也是如此。我們已經看過用來表示範圍的連字符的例子。只有在字符組內部(而且不是第一個字符的情況下),連字符才能表示範圍。在字符組外部,^表示一個行錨點(line anchor),但是在字符組內部(而且必須是緊接在字符組的第一個方括號之後),它就是一個元字符。請不要擔心——這就是最複雜的情況,接下來的內容比這簡單。
來看另一個例子,我們需要在一堆英文單詞中搜索出一些特殊的單詞:在這些單詞中,字母 q後面的字母不是 u。用正則表達式來表示,就是「q[^u]」。用這個正則表達式來搜索我手頭的數據,確實得到了一些結果,但顯然不多,其中還有些是我沒見過的英文單詞。
下面是結果(我輸入的命令用粗體表示):

其中有兩個單詞值得注意:伊拉克「Iraq」和澳大利亞航空公司的名字「Qantas」。儘管它們都在word.list文件中,但都不包含在egrep結果中。為什麼呢?ϖ請動動腦筋,然後翻到下一頁來檢查你的答案。
請記住,排除型字符組表示「匹配一個未列出的字符(match a character that's not listed)」,而不是「不要匹配列出的字符(don't match what is listed)」。這兩種說法看起來一樣,但是Iraq的例子說明了其中的細微差異。有一種簡單的理解排除型字符組的辦法,就是把它們看作普通的字符組,裡面包含的是除了「排除型字符組中所有字符」以外的字符。
用點號匹配任意字符
Matching Any Character with Dot
元字符「.」(通常稱為點號dot或者小點point)是用來匹配任意字符的字符組的簡便寫法。如果我們需要在表達式中使用一個「匹配任何字符」的佔位符(placeholder),用點號就很方便。例如,如果我們需要搜索03/19/76、03-19-76或者03.19.76,不怕麻煩的話用一個明確容許『/』、『-』、『.』的字符組來構建正則表達式,例如「03[-./]19[-./]76」。也可以簡單地嘗試「03.19.76」。
讀者第一次接觸這個表達式時,可能還不清楚某些情況。在「03[-./]19[-./]76」中,點號並不是元字符,因為它們在字符組內部(記住,在字符組裡面和外面,元字符的定義和意義是不一樣的)。這裡的連字符同樣也不是元字符,因為它們都緊接在[或者[^之後。如果連字符不在字符組的開頭,例如「[.-/]」,就是用來表示範圍的,在本例中就是錯誤的用法。

在「03.19.76」中,點號是元字符——它能夠匹配任意字符(包括我們期望的連字符、句號和斜線)。不過,我們也需要明白,點號可以匹配任何字符,所以這個正則表達式也能夠匹配下面的字符串:『lottery numbers: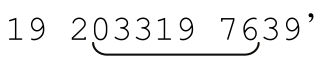
所以,「03[-./]19[-./]76」更加精確,但是更難讀,也更難寫。「03.19.76」更容易理解,但是不夠細緻。我們應該選擇哪一個呢?這取決於你對需要檢索的文本的瞭解,以及你需要達到的準確程度。一個重要但常見的問題是,寫正則表達式時,我們需要在對欲檢索文本的瞭解程度與檢索精確性之間求得平衡。例如,如果我們知道,針對某個檢索文本,「03.19.76」這個正則表達式基本不可能匹配不期望的結果,使用它就是合理的。要想正確使用正則表達式,清楚地瞭解目標文本是非常重要的。
多選結構
Alternation
匹配任意子表達式
「|」是一個非常簡捷的元字符,它的意思是「或」(or)。依靠它,我們能夠把不同的子表達式組合成一個總的表達式,而這個總的表達式又能夠匹配任意的子表達式。假如「Bob」和「Robert」是兩個表達式,但「Bob|Robert」就是能夠同時匹配其中任意一個的正則表達式。在這樣的組合中,子表達式稱為「多選分支(alternative)」。
回頭來看「gr[ea]y」的例子,有意思的是,它還可以寫作「grey|gray」,或者是「gr(a|e)y」。後者用括號來劃定多選結構的範圍(正常情況下,括號也是元字符)。請注意,「gr[a|e]y」不符合我們的要求——在這裡,『|』只是一個和「a」與「e」一樣的普通字符。
對表達式「gr(a|e)y」來說,括號是必須的,因為如果沒有括號,「gra|ey」的意思就成了「「gra」或者「ey」」,而這不符合我們的要求。多選結構可以包括很多字符,但不能超越括號的界限。另一個例子是「(First|1st)·[Ss]treet」(注 5)。事實上,因為「First」和「1st」都以「st」結尾,我們可以把這個結合體縮略表示為「(Fir|1)st·[Ss]treet」。這樣可能不容易看得清楚,但我們知道「(First|1st)」與「(fir|1)st」表示的是同一個意思。
下面是一些用多選結構來拼寫我名字的例子。這3個表達式是一樣的,請仔細比較:

英國拼寫法如下:

最後要注意的是,這 3 個表達式其實與下面這個更長(但是更簡單)的表達式是等價的:「Jeffrey|Geoffery|Jeffery|Geoffrey」。它們只是「殊途同歸」而已。
「gr[ea]y」與「gr(a|e)y」的例子可能會讓人覺得多選結構與字符組沒太大的區別,但是請留神不要混淆這兩個概念。一個字符組只能匹配目標文本中的單個字符,而每個多選結構自身都可能是完整的正則表達式,都可以匹配任意長度的文本。
字符組基本可以算是一門獨立的微型語言(例如,對於元字符,它們有自己的規定),而多選結構是「正則表達式語言主體(main regular expression language)」的一部分。你將會發現,這兩者都非常有用。
同樣,在一個包含多選結構的表達式中使用脫字符和美元符的時候也要小心。比較「^From|Subject|Date:·」和「^(From|Subject|Date):·」就會發現,雖然它們看起來與之前的E-mail的例子很相似,匹配結果(即它們的用處)卻大不相同。第一個表達式由3個多選分支構成,所以它能匹配「^From」或者「Subject」或者「Date:·」,實用性不大。我們希望在每一個多選分支之前都有脫字符,之後都有「:·」。所以應該使用括號來「限制」(constrain)這些多選分支:
「^(From|Subject|Date):·」
現在 3 個多選分支都受括號的限制,所以,這個正則表達式的意思是:匹配一行的起始位置,然後匹配「^From」、「Subject」或「Date」中的任意一個,然後匹配「:·」,所以,它能夠匹配的文本是:
1)行起始,然後是F·r·o·m,然後是『:·』,
或者 2)行起始,然後是S·u·b·j·e·c·t,然後是『:·』,
或者 3)行起始,然後是D·a·t·e,然後是『:·』。
簡單點說,就是匹配以『From:·』,『Subject:·』或者『Date:·』開頭的文本行,在提取E-mail文件中的信息時這很有用。
下面是一個例子:

忽略大小寫
Ignoring Differences in Capitalization
E-mail header的例子很適合用來說明不區分大小寫(case-insensitive)的匹配的概念。E-mail header中的字段類型(field type)通常是以大寫字母開頭的,例如「Subject」和「From」,但是E-mail標準並沒有對大小寫進行嚴格的規定,所以「DATE」或者「from」也是合法的字段類型。但是,之前使用的正則表達式無法處理這種情況。
一種辦法是用「[Ff][Rr][Oo][Mm]」取代「From」,這樣就能匹配任何形式的「from」,但缺點之一就是很不方便。幸好,我們有一種辦法告訴egrep在比較時忽略大小寫,也就是進行不區分大小寫的匹配,這樣就能忽略大小寫字母的差異。
該功能並不是正則表達式語言的一部分,卻是許多工具軟件提供的有用的相關特性。egrep的命令行參數「-i」表示進行忽略大小寫的匹配。把-i寫在正則表達式之前:
%egrep-i'^(From|Subject|Date):'mailbox
結果除了包括之前的內容外,還包含這一行:
SUBJECT:MAKE MONEY FAST
我使用-i參數的頻率很高(也許與第12頁的註解有關),所以我推薦讀者記住它。在下面的章節中我們還會見到其他的簡捷特性。
單詞分界符
Word Boundaries
使用正則表達式時經常會遇到的一個問題,期望匹配的「單詞」包含在另一個單詞之中。在cat、gray和Smith的例子中,我曾提到過這個問題。不過,某些版本的egrep對單詞識別提供了有限的支持:也就是單詞分界符(單詞開頭和結束的位置)的匹配。
如果你的egrep支持「元字符序列(metasequences)」 「\<」和「\>」,就可以使用它們來匹配單詞分界的位置。可以把它們想像為單詞版本的「^」和「$」,分別用來匹配單詞的開頭和結束位置。就像作為行錨點的脫字符和美元符一樣,它們錨定了正則表達式的其他部分,但在匹配過程中並不對應到任何字符。表達式「\<cat\>」的意思是「匹配單詞的開頭位置,然後是c·a·t這3個字母,然後是單詞的結束位置」。更直接點說就是「匹配cat這個單詞」。如果讀者願意,也可以用「\<cat」和「cat\>」來匹配以cat開頭和結束的單詞。
請注意,「<」和「>」本身並不是元字符——只有當它們與斜線結合起來的時候,整個序列才具有特殊意義。這就是我稱其為「元字符序列」的原因。重要的是它們的特殊意義,而不是字符的個數,所以我說的「元字符」和「元(字符)序列」大多數時候是等價的。
請記住,並不是所有版本的 egrep 都支持單詞分界符,即使是支持的版本也不見得聰明到能「認得出」英語單詞。「單詞的起始位置」只不過是一系列字母和數字符號(alphanumeric characters)開始的位置,而「結束位置」就是它們結尾的地方。下一頁的圖1-2說明了一行簡單文本中的單詞分界符。
(egrep 認定的)單詞開頭位置用向上的箭頭標識,單詞結束位置用向下的箭頭標識。我們看到,「單詞的開始和結束」準確地說是「字母數字符號的開始和結束」,不過這樣說太麻煩了。
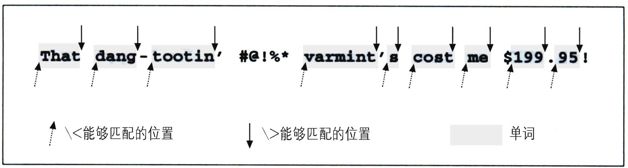
圖1-2:「單詞」的起始和結束位置
小結
In a Nutshell
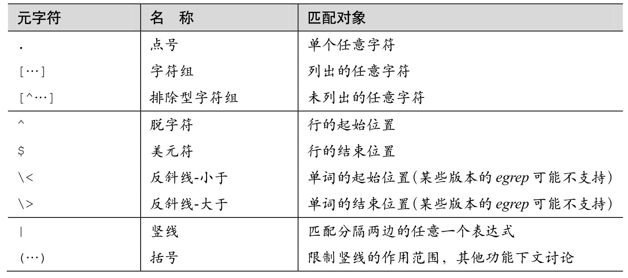
表1-1總結了我們已經介紹過的元字符。
表1-1:至今為止所見的元字符小結
另外還有幾點需要注意:
●在字符組內部,元字符的定義規則(及它們的意義)是不一樣的。例如,在字符組外部,點號是元字符,但是在內部則不是如此。相反,連字符只有在字符組內部(這是普遍情況)才是元字符,否則就不是。脫字符在字符組外部表示一個意思,在字符組內部緊接著[時表示另一個意思,其他情況下又表示別的意思。
●不要混淆多選項和字符組。字符組「[abc]」和多選項「(a|b|c)」固然表示同一個意思,但是這個例子中的相似性並不能推廣開來。無論列出的字符有多少,字符組只能匹配一個字符。相反,多選項可以匹配任意長度的文本,每個多選項可能匹配的文本都是獨立的,例如「\<(1,000,000|million|thousand·thou)\>」。不過,多選項沒有像字符組那樣的排除功能。
●排除型字符組是表示所有未列出字符的字符組的簡便方法。因此,「[^x]」的意思並不是「只有當這個位置不是x時才能匹配」,而是說「匹配一個不等於x的字符」。其中的差別很細微,但很重要。例如,前面的概念可以匹配一個空行,而「[^x]」則不行。
●
-i參數規定在匹配時不區分大小寫(☞15)(注6)。
●目前介紹過的知識都很有用,但「可選項(optional)」和「計數(counting)」元素更重要,下文將馬上介紹。
可選項元素
Optional Items
現在來看color和colour的匹配。它們的區別在於,後面的單詞比前面的多一個u,我們可以用「colou?r」來解決這個問題。元字符「?」(也就是問號)代表可選項。把它加在一個字符的後面,就表示此處容許出現這個字符,不過它的出現並非匹配成功的必要條件。
「u?」這個元字符與我們之前看到的元字符都不相同,它只作用於之前緊鄰的元素。因此,「colou?r」的意思是:「c」,然後是「o」,然後是「l」,然後是「o」,然後是「u?」,最後是「r」。
「u?」是必然能夠匹配成功的,有時它會匹配一個u,其他時候則不匹配任何字符。關鍵在於,無論 u 是否出現,匹配都是成功的。但這並不等於,任何包含?的正則表達式都永遠能匹配成功。例如,「colo」和「u?」都能在『semicolon』中匹配成功(前者匹配單詞中的colo,後者什麼字符都沒有匹配)。可是最後的「r」無法匹配,因此,最終「colou?r」無法匹配semicolon。
來看另一個例子,我們需要匹配表示7月4日(July fourth)的文本,其中月份可能寫作July或是 Jul,而日期可能寫作 fourth、4th 或者是 4。顯然,我們可以使用「(July|Jul)· (fourth|4th|4)」,但也可以找些其他的辦法來解決這個問題。
首先,我們把「(July|Jul)」縮短為「(July?)」。你明白這種等價變換嗎?刪除「|」之後,就沒必要保留括號了。當然保留也可以,但不保留括號顯得更整潔一些。於是我們得到「July?·(fourth|4th|4)」。
現在來看第二部分,我們可以把「4th|4」簡化為「4(th)?」。我們看到,現在「?」作用的元素是整個括號了。括號內的表達式可以任意複雜,但是「從括號外來看」它們是個整體。界定「?」的作用對像(還可以劃定我即將介紹的其他類似元字符的作用對像)是括號的主要用途之一。
我們的表達式現在成了「July?·(fourth|4(th)?)」。儘管它包含了許多元字符,而且有嵌套的括號,但理解起來並不困難。我們花了相當的工夫來講解這兩個簡單的例子,但同時也接觸到了一些相關的知識,它們相當有助於——或許你現在還意識不到——我們理解正則表達式。同樣,通過這些講解,我們也積累了依靠不同思路解決問題的經驗。在閱讀本書(同時也是在加深理解)尋找複雜問題的最優解決方案的過程中,你可能會發現靈感可能在不斷湧現。正則表達式不是死板的教條,它更像是門藝術。
其他量詞:重複出現
Other Quantifiers:Repetition
「+」(加號)和「*」(星號)的作用與問號類似。元字符「+」表示「之前緊鄰的元素出現一次或多次」,而「*」表示「之前緊鄰的元素出現任意多次,或者不出現」。換種說法就是,「…*」表示「匹配盡可能多的次數,如果實在無法匹配,也不要緊」。「…+」的意思與之類似,也是匹配盡可能多的次數,但如果連一次匹配都無法完成,就報告失敗。問號、加號和星號這 3個元字符,統稱為量詞(quantifiers),因為它們限定了所作用元素的匹配次數。
與「…?」一樣,正則表達式中的「…*」也是永遠不會匹配失敗的,區別只在於它們的匹配結果。而「…+」在無法進行任何一次匹配時,會報告匹配失敗。
舉例來說,「·?」能夠匹配一個可能出現的空格,但是「·*」能夠匹配任意多個空格。我們可以用這些量詞來簡化第9頁<H[1-6]>的例子。按照HTML規範(注7),在tag結尾的>字符之前,可以出現任意長度的空格,例如<H3·>或者<H4···>。把「·*」加入正則表達式中的可能出現(但不是必須)空格的位置,就得到「H[1-6]·*」。它仍然能夠匹配<H1>,因為空格並不是必須出現的,但其他形式的tag也能匹配。
接下來看類似<HR·SIZE=14>這樣的HTML tag,它表示一條高度為14像素的穿越屏幕的水平線。與<H3>的例子一樣,在最後的尖括號之前可以出現任意多個空格。此外,在等號兩邊也容許出現任意多個空格。最後,在 HR和 SIZE之間必須有至少一個空格。為了處理更多的空格,我們可以在「·」後添加「·*」,不過最好還是改寫為「·+」。加號確保至少有一個空格出現,所以它與「··*」是完全等價的,只不過更簡潔。所以我們得到「<HR·+SIZE·*=·*14·*>」。
儘管這個表達式不受空格數目的限制,但它仍然受tag中直線尺寸大小的約束。我們要找的不僅僅是高度為14的tag,而是所有這些tag。所以,我們必須用能匹配普通數值(general number)的表達式來替換「14」。在這裡,「數值」(number)是由一位或多位數字(digits)構成的。「[0-9]」可以匹配一個數字,因為「至少出現一次」,所以我們使用加號量詞,結果就是用「[0-9]+」替換「14」。(一個字符組是一個「元素」(unit),所以它可以直接加加號、星號等,而不需要用括號。)
這樣我們就得到了「<HR·+SIZE·*=·*[0-9]+·*>」,儘管我用了粗體標識元字符,用空格來分隔各個元素,而且使用了「看得見的空格符」『·』,這個表達式仍然不容易看懂(幸好,egrep提供了-i的參數☞15,這樣我就不需要用「[Hh][Rr]」來表示「HR」了)。否則,「<HR+SIZE*=*[0-9]+*>」更令人迷惑。這個表達式之所以看起來有些詭異,是因為星號和加號作用的對象大都是空格,而人眼習慣於把空格和普通字符區分開來。在閱讀正則表達式時,我們必須改變這種習慣,因為空格符也是普通字符之一,它與 j或者 4這樣的字符沒有任何差別(在後面的章節中,我們會看到,某些工具軟件支持忽略空格的特殊模式)。
我們繼續這個例子,如果尺寸這個屬性也是可選的,也就是說<HR>就代表默認高度的直線(同樣,在>之前也可能出現空格)。你能修改我們的正則表達式,讓它匹配這兩種類型的 tag 嗎?解決問題的關鍵在於明白表示尺寸的文本是可選出現的(這是個暗示)。ϖ請翻到下一頁查看答案。
請仔細觀察最後(答案中)的表達式,體會問號、星號和加號之間的差異,以及它們在實際應用中的真正作用。下一頁的表1-2總結了它們的意義。
請注意,每個量詞都規定了匹配成功至少需要的次數下限,以及嘗試匹配的次數上限。對某些量詞來說,下限是0,對某些量詞來說,上限是無窮大。

表1-2:「表示重複的元字符」含義小結

規定重現次數的範圍:區間
某些版本的egrep能夠使用元字符序列來自定義重現次數的區間:「…{min,max}」。這稱為「區間量詞(interval quantifier)」。例如,「…{3,12}」能夠容許的重現次數在3到12之間。有人可能會用「[a-zA-Z]{1,5}」來匹配美國的股票代碼(1 到5 個字母)。問號對應的區間量詞是{0,1}。
支持區間表示法的egrep的版本並不多,但有許多另外的工具支持它。在第3章我們會仔細考察目前經常使用的元字符,那時候會涉及區間的支持問題。
括號及反向引用
Parentheses and Backreferences
到目前為止,我們已經見過括號的兩種用途:限制多選項的範圍;將若干字符組合為一個單元,受問號或星號之類量詞的作用。現在我要介紹括號的另一種用途,雖然它在egrep中並不常見(不過流行的GNU版本確實支持這一功能),但在其他工具軟件中很常見。
在許多流派(flavor)的正則表達式中,括號能夠「記住」它們包含的子表達式匹配的文本。在解決本章開始提到的單詞重複問題時就會用到這個功能。如果我們確切知道重複單詞的第一個單詞(比方說這個單詞就是「the」),就能夠明確無誤地找到它,例如「the·the」。這樣或許還是會匹配到 的情況,但如果我們的egrep支持在第15頁提到的單詞分界符「\<the·the\>」,這個問題就很容易解決。我們可以添加「·+」把這個表達式變得更靈活。
的情況,但如果我們的egrep支持在第15頁提到的單詞分界符「\<the·the\>」,這個問題就很容易解決。我們可以添加「·+」把這個表達式變得更靈活。
然而,窮舉所有可能出現的重複單詞顯然是不可能完成的任務。如果我們先匹配任意一個單詞,接下來檢查「後面的單詞是否與它一樣」,就好辦多了。如果你的egrep支持「反向引用(backreference)」,就可以這麼做。反向引用是正則表達式的特性之一,它容許我們匹配與表達式先前部分匹配的同樣的文本。
我們先把「\<the·+the\>」中的第一個「the」替換為能夠匹配任意單詞的正則表達式「[A-Za-z]+」;然後在兩端加上括號(原因見下段);最後把後一個『the』替換為特殊的元字符序列「\1」,就得到了「\<([A-Za-z]+)·+\1\>」。
在支持反向引用的工具軟件中,括號能夠「記憶」其中的子表達式匹配的文本,不論這些文本是什麼,元字符序列「\1」都能記住它們。
當然,在一個表達式中我們可以使用多個括號。再用「\1」、「\2」、「\3」等來表示第一、第二、第三組括號匹配的文本。括號是按照開括號『(』從左至右的出現順序進行的,所以「([a-z])([0-9])\1\2」中的「\1」代表「[a-z]」匹配的內容,而「\2」代表「[0-9]」匹配的內容。
在『the·the』的例子中,「[A-Za-z]+」匹配第一個『the』。因為這個子表達式在括號中,所以「\1」代表的文本就是『the』。如果「·+」能夠匹配,後面的「\1」要匹配的文本就是『the』。如果「\1」也能成功匹配,最後的「\>」對應單詞的結尾(如果文本是『the·theft』,這一條就不滿足)。如果整個表達式能匹配成功,我們就得到一個重複單詞。有的重複單詞並不是錯誤,例如『that that』(譯注3),這並不是正則表達式的錯誤,真正的判斷還得靠人。我決定使用上面這個例子的時候,已經用這個表達式檢查過本書之前的內容了(我使用的是支持「\<…\>」和反向引用的egrep)。我還使用了第15頁提到的忽略大小寫的參數-i來拓寬它的適用範圍(注8),所以『The·the』這樣的單詞重複也能提取出來。
我使用的命令如下:
%egrep-i'\<([a-z]+)+\1\>'files…
結果令我驚奇,居然找到了14組重複單詞。我把它們全都改正了,而且把這個表達式添加到我用來檢查本書拼寫錯誤的工具中,保證從此以後全書中不會出現這樣的錯誤。
儘管這個表達式很有用,我們仍然需要重視它的局限。因為egrep把每行文字都當作一個獨立部分來看待,所以如果單詞重複的第一個單詞在某行末尾,第二個單詞在下一行的開頭,這個表達式就無法找到。所以,我們需要更加靈活的工具,下一章我們會看到這方面的例子。
神奇的轉義
The Great Escape
有個重要的問題我尚未提及,即:如果需要匹配的某個字符本身就是元字符,正則表達式會如何處理呢?例如,如果我想要檢索互聯網的主機名ega.att.com,使用「ega.att.com」可能得到 的結果。還記得嗎?「.」本身就是元字符,它可以匹配任何字符,包括空格。
的結果。還記得嗎?「.」本身就是元字符,它可以匹配任何字符,包括空格。
真正匹配文本中點號的元序列應該是反斜線(backslash)加上點號的組合:「ega\.att\.com」。「\.」稱為「轉義的點號」或者「轉義的句號」,這樣的辦法適用於所有的元字符,不過在字符組內部無效(注9)。
這樣使用的反斜線稱為「轉義符(escape)」——它作用的元字符會失去特殊含義,成了普通字符。如果你願意,也可以把轉義符和它之後的元字符看作特殊的元字符序列,這個元字符序列匹配的是元字符對應的普通字符。這兩種看法是等價的。
我們還可以用「\([a-zA-Z]+\)」來匹配一個括號內的單詞,例如『(very)』。在開閉括號之前的反斜線消除了開閉括號的特殊意義,於是他們能夠匹配文本中的開閉括號。
如果反斜線後緊跟的不是元字符,反斜線的意義就依程序的版本而定。例如,我們已經知道,某些版本的程序把「\<」、「\>」、「\1」當作元字符序列對待。在後面的章節中我們會看到更多的例子。