
在過去的很多世紀裡,人們一直害怕自己設計發明的機器會比自己更聰明、更強大,或者搶掉自己的飯碗。長久以來,這種恐懼都是各類科幻故事反覆表現的主題。早在中世紀時,猶太人中就流傳著關於「高倫」(Golem)的傳說,它是一個由黏土製成的假人,由於嘴裡刻著神的名字,從此獲得了生命。而在電影《2001:太空漫遊》中,一台名為哈爾的計算機向人類發起了進攻。但是,在20世紀50年代,當一種被稱為「人工智能」(artificial intelligence,簡稱AI)的工程學科誕生之時,這些虛構的故事似乎就要成為可怕的現實了。如果一台計算機可以算出圓周率π的小數點後100萬位,或者能夠幫助公司分配薪資酬勞,人們並不會覺得有什麼不妥,但是一夜之間,計算機居然擁有了論證邏輯定理的能力,而且還下起了高深的國際象棋。在隨後的幾年中,一些計算機已經擊敗了眾多棋界高手。在治療細菌感染、投資養老基金等方面,計算機程序的表現也比大多數專家更為出色。從表面上看,一旦計算機開始勝任這類智能型的工作,我們距離科幻電影中的世界似乎就不再遙遠。到那時,你可以輕鬆地為自己訂購一台「C3PO」機器人或者「終結者」,因為現在只剩下一些簡單的任務有待開發。據說在20世紀70年代,人工智能的創始人之一馬文·明斯基(Marvin Minsky)給一個研究生佈置的暑期課題就是「人工視覺」。
然而迄今為止,家用型機器人仍然只存在於科幻世界之中。近35年的人工智能研究所收穫的主要經驗是:困難的工作非常簡單,而簡單的工作卻無比困難。一個4歲大的孩子已經能夠辨認出一張人臉,拿起一支鉛筆,穿過一個房間,或者回答一個提問。對於這種智能表現,我們認為這是再正常不過的事情,但實際上,它所解決的是工程學上難度最大的一類問題。在汽車廣告中,我們經常會看到在流水線上工作的機器人,你可不要被它們所嚇倒,它們的工作只不過是焊接和噴漆而已,這些笨拙的大傢伙並不需要去看、去拿或者去擺放任何東西。如果你想故意刁難某個人工智能系統,不妨問它幾個無厘頭的問題:芝加哥和麵包盒哪一個更大?斑馬穿不穿內衣?地板會不會跳起來咬你一口?如果蘇珊出門去商店購物,她的頭有沒有跟她一起去?多數情況下,人們對自動化的擔憂都是一種誤解。隨著新一代智能產品的出現,最有可能被機器取而代之的工種是股票分析師、石油化工工程師以及假釋委員會成員,而園丁、前台接待或者廚師的工作在未來數十年內還不會受到衝擊。
讀懂一個句子的含義,也是一種高難度的「簡單任務」。為了與計算機交流,我們不得不學習它們的語言,因為它們還不夠聰明,無法掌握人類語言。然而,我們很容易對計算機的理解能力做出過高的估計。
最近舉辦了一次計算機程序的設計大賽,看看是否有一台計算機可以完美地騙過使用者,讓他誤以為自己是在和另一個人進行對話,這就是「洛伯納大獎賽」(Loebner Prize)。這個大獎的設立,是基於艾倫·圖靈曾經的一個設想。在1950年發表的一篇著名論文中,圖靈提出了一個建議,關於「機器是否具有思考能力」的哲學問題,最好的解決方法就是舉辦一次模擬比賽:一邊是真人,一邊是可以模擬人類聊天的計算機程序,然後由一位裁判通過終端顯示器分別與他們進行對話。圖靈認為,如果裁判無法對二者做出分辨,那麼我們就沒有理由否認計算機具有思考的能力。拋開哲學問題不談,大賽組織者非常清楚,還沒有哪個聊天軟件有能力贏走這10萬美元的大獎,因此為了公平起見,他們設立了一個1 500美元的小型獎勵。按照比賽規則,裁判必須接受程序設計者或者真人聊天對像所選擇的某個話題,而且不允許設置「圈套和陷阱」,例如相同的問題問上10遍,或者問一些諸如「斑馬穿不穿內衣」之類的問題。對話內容必須「合乎常理」。在與若干聊天軟件和真人對像分別進行7分鐘左右的交流之後,裁判要判斷聊天對像說的是否像「人話」,並以此為標準對聊天對像做出排名。結果,所有真人對象的排名都在計算機之上。不過,有大約半數的裁判將一款聊天軟件誤判為人類,這款軟件也因此獲勝。
這聽起來是一項了不起的成就,但實際上並非如此。因為比賽規則束縛了裁判的手腳。如果想要確認自己的聊天對象是人類還是機器,使用一些「不合常理的圈套和陷阱」是一種行之有效的辦法,這原本是此類測試的關鍵所在。此外,獲勝的程序設計者巧妙地利用了設定話題的權力,他選擇的是「不著邊際的對話」,而這其實算不上一個真正的話題。所謂的「不著邊際」,本身就意味著可以答非所問,缺乏邏輯:
裁判:真是漫長的一天!我現在想輕鬆一下。今天的天氣不怎麼好,你有沒有什麼笑話可以驅散這滿天的陰雲?
計算機:人人都在對天氣說三道四,但卻沒有人站出來做點什麼。你為什麼要告訴我你想找些樂子?切……
裁判:你是在存心氣我,是嗎?我已經解釋過了,我就是想輕鬆一下!
計算機:如果我並不是想存心氣你,你是不是會覺得好受些?我已經解釋過了,我就是想輕鬆一下!我存在,所以我計算……你為什麼認為我是在存心氣你?
裁判:你的問題讓我感到莫名其妙……詩人的「天馬行空」和我們大多數人的「不著邊際」並不是一回事。
計算機:你怎麼知道我的問題讓你感到莫名其妙……詩人的「天馬行空」和我們大多數人的「不著邊際」並不是一回事?
實際上,這位程序設計者只不過是將計算機科學家約瑟夫·魏茨鮑姆(Joseph Weizenbaum)1965年發明的一項技術簡單地更新了一下。魏茨鮑姆曾經編寫了一個非常簡陋的程序,並給它取名為「伊麗莎」(Eliza),這個名字源自蕭伯納《賣花女》中的女主人公。這個程序能在輸入的語句中找到幾個關鍵詞,然後從存儲列表中檢索出一個現成的回復,並將輸入語句中的部分內容插入這個回復之中,再稍微進行一些替換,例如將「你是」換成「我是」。如此一來,這個程序便可以初步模擬人類的談話。這個程序還有一個名為「醫生」(doctor)的版本,它模擬的是一位羅傑斯學派的心理治療師,根據卡爾·羅傑斯(Carl Rogers)的理論,面對患者的陳述,治療師應該進行回問,以便引起患者自己的思考。這個程序的一個版本後來被睿俠電子便利店(Radio Shack)作為計算機遊戲出售於世,而另一個版本則附帶於我所使用的文字處理程序GNU Emacs之中。它的說明書這樣寫道:「如果Emacs的表現非常糟糕,以上所述的各種方法都無法解決您的問題,Emacs仍然可以幫到您——請輸入『M-x doctor RET』指令。」以下是一段典型的對話:
用戶:我最近一直很抑鬱。
計算機:你經常感到抑鬱嗎?
用戶:是的,幾乎每時每刻。
計算機:你為什麼說「是的,幾乎每時每刻」呢?
用戶:我現在就想哭。
計算機:你是因為想哭才來找我的嗎?
有一天,魏茨鮑姆發現自己的秘書居然待坐在顯示器前,向計算機程序吐露自己的心扉,這讓他感到莫名的恐懼。
大多數計算機科學家對洛伯納大獎賽嗤之以鼻。在他們看來,它只是一個無聊的宣傳噱頭,這種比賽只能糊弄一些業餘人士,而無法讓計算機真正掌握人類的語言(因為人工智能的研究人員和精通語言問題的專家學者都被排除於裁判之列,而他們本身也不屑於參加這樣的比賽,報名參賽的都是一些計算機愛好者)。這就好比為了推動生物學的研究而設立一個大獎,看看誰能做出一朵最能以假亂真的絹花,或者說在好萊塢的拍攝場地模擬一番登陸月球的情景,以此實現所謂的太空計劃。目前,學者們對計算機的語言理解系統已經有了深入的研究,但沒有哪位嚴肅的工程學家敢預言它很快就會達到人類的水平。
事實上,在科學家看來,人類對句子的理解能力實在是超乎想像的。人們不但可以完成這個極其複雜的任務,而且無須花費太多的時間。接收與理解往往「同步進行」,聽話者的思路可以跟上說話者的語速,而不必等到整個談話結束之後,再回過頭來對聽到的內容進行解讀,就像評論家創作書評那樣。一句話從說話者嘴裡說出,到聽者理解這句話的意思,二者的間隔短得幾乎可以忽略不計:大約一兩個音節的長度,也就1/2秒左右的時間。還有一些人能夠更為快速地理解、跟讀他人所說的內容,時間間隔只有1/4秒。
對這種理解能力的研究探析,不但可以幫助我們製造能夠與人類交流的機器,還有許多其他的實際用途。人們對句子的理解又快又準,但並非完美無缺。無論是一次談話還是一篇文章,它的語法結構都必須符合一定的規則,我們才能明白其中的含義,否則就會出現理解上的障礙、反覆和歧義。在本章中,我們將探討語言的理解問題,看看哪一種句子能夠被讀者充分理解。這樣一來,我們就可以制訂出一套有關如何清晰寫作的行文規範,對於那些指導人們進行科學寫作的手冊指南而言,例如約瑟夫·威廉姆斯(Joseph Williams)1990年所撰的《風格:清晰、優雅地寫作》(Style: Toward Clarity and Grace),本章的諸多發現將對它們提供重要的參考。
另一個實際的用途則與法律有關。在審判實踐中,法官常常會遇到一個難題,他們需要判斷一個人是否能夠理解某些含糊其詞的文字,比如那些瀏覽商業合同的客戶、聽取法官指示的陪審員,或者面對誹謗文字的普通公民。研究者通過各種實驗,已經揭示出人們的許多理解習慣。在《法官語言》(The Language of Judges)一書中,語言學家、律師勞倫斯·索蘭(Lawrence Solan)解釋了語言和法律的關係。這本書寫於1993年,內容十分有趣,我們下面還會提到它。
句法剖析器,理解語言的最基本工具
我們是如何理解一個句子的呢?第一步是進行「句法剖析」(parse)。這並不是指你上小學時所做過的那些令人生厭的語法練習。對於這種練習,戴夫·巴裡(Dave Barry)在《請問語言先生》(Ask Mr. Language Person)一書中有過一番調侃:
問:請解釋一下如何用圖解法分析句子。
答: 首先,找個像燙衣板那樣的乾淨平台,把要圖解的句子放在上面。然後用一支削尖的鉛筆或者小刀片固定句子的「謂語」,它表明的是動作發生的地方。如果把一個句子比作一條魚,那麼「謂語」通常就位於魚鰓的正後方。例如,在「拉蒙特從不會咬護林員」這句話中,事發地很有可能是森林,所以你畫的圖就應該像一棵小樹,它伸出的樹枝可以用來標識句子的各個組成部分,例如各種動名詞、諺語或者附加詞等。
不過,句法剖析的過程與巴裡所調侃的語法練習也有類似之處,你同樣要找出句子的主語、謂語以及賓語等,只不過你自己察覺不到。除非你像伍迪·艾倫那樣以神奇的速度讀完《戰爭與和平》,否則你就必須把單詞組成短語,然後確定這些短語和動詞之間的主謂關係。假如要讀懂「帽子裡的貓回來了」這句話,你就必須把「帽子裡的貓」看成一個短語,這樣才能明白回來的不是帽子,而是貓。如果要區分「狗咬人」與「人咬狗」,你必須分清它們的主語和賓語,而如果要區分「人咬狗」與「人被狗咬」或者「人遭到狗咬」,你就得在自己的心理詞典中搜尋一下動詞詞條,以確定句子的主語「人」到底是施動者還是受動者。
語法本身只是一種代碼或協議,它就像一個靜態數據庫,規定了某一特定語言的語音與語義的對應關係。但是,我們之所以具有語言表達能力和理解能力,卻並非是因為語法的存在。雖然我們的表達和理解共享著一個相同的語法數據庫(我們說出的語言正是我們所理解的語言),但這還遠遠不夠。想要聽懂一大段談話,或者想要開口表達自己的想法,我們的大腦還必須按照某種特定的程序來執行每一步操作。在語言理解過程中,這種對句子結構進行分析處理的心理機制被稱為「句法剖析器」(parser)。
要揭示人類對語言的理解過程,最好的方法就是對某個簡單的句子進行句法剖析,比如說那些由簡單的語法規則生成的句子。這一點在第3章中已經談到,我在此略作回顧:
S → NP VP
一個句子可以由一個名詞短語和一個動詞短語構成。
NP →(det)N(PP)
一個名詞短語可以由一個可有可無的限定詞、一個名詞和一個可有可無的介詞短語構成。
VP → V NP(PP)
一個動詞短語可以由一個動詞、一個名詞短語和一個可有可無的介詞短語構成。
PP → P NP
一個介詞短語可以由一個介詞和一個名詞短語構成。
N → boy, girl, dog, cat, ice cream, candy, hot dogs
在心理詞典中,名詞包括:boy(男孩),girl(女孩),dog(狗),cat(貓),ice cream(冰激凌),candy(糖果),hot dogs(熱狗)等。
V → eats, likes, bites
在心理詞典中,動詞包括:eats(吃)、likes(喜歡)、bites(咬)等。
P → with, in, near
介詞包括:with(和……一起),in(在……裡面),near(在……附近)等。
det → a, the, one
限定詞包括:a(某個),the(這個),one(一個)等。
讓我們以「The dog likes ice cream」(狗喜歡冰激凌)一句為例。我們大腦中的句法剖析器首先注意到單詞「the」,並開始在心理詞典中查詢這個單詞,它一邊搜尋這個單詞的用法規則,一邊確定它的詞性。顯然,這是一個限定詞(det),剖析器隨之畫出樹形圖的第一根樹枝(當然,從植物學的角度來看,一棵樹是不可能這樣先枝後干,逆生長的):

和其他詞語一樣,限定詞只是某個相關短語的組成部分。通過核查限定詞的用法規則,剖析器可以辨認出這個短語。根據用法規則,限定詞是用來構成名詞短語(NP)的。這棵樹因此繼續生長:
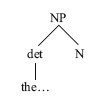
大腦必須記住這個懸垂結構。剖析器明白,「the」這個單詞只是名詞短語的組成部分,如果要使這個名詞短語完整起來,就必須找到其他一些詞語來填補剩下的部分——在這個例子中,至少需要一個名詞。
與此同時,這棵樹還在繼續生長,因為名詞短語不能單獨存在。根據名詞短語的用法規則,剖析器面臨著幾種選擇:這個剛剛「長出」的名詞短語可以是句子的一部分,也可以是動詞短語的一部分,還可以是介詞短語的一部分。不過,如果我們從「根部」入手,這個問題就好解決了:所有的單詞和短語最終必須裝入一個句子(S)之中,而所有的句子又必須以名詞短語開頭。因此,如果想讓這棵樹繼續生長,就有必要動用一下句法規則:
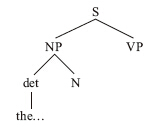
現在,剖析器將兩個有待補齊的分枝暫存到記憶之中:一個是缺少名詞(N)的名詞短語,一個是缺少動詞短語(VP)的句子。
在這棵樹中,樹枝N下面空空蕩蕩,這意味著接下來出現的應該是一個名詞。當句子中的第二個單詞「dog」映入眼簾時,這個預測就得到了驗證,因為根據規則的核實,「dog」正屬於名詞的範疇。就這樣,「dog」一詞融入樹中,與「the」一起構成了一個完整的名詞短語:
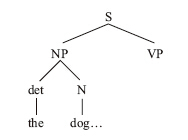
現在剖析器可以將名詞短語從記憶中清除了,它需要解決的是一個不完整的句子(S)。
到目前為止,我們已經可以推測出這個句子所要表達的部分意思。在名詞短語中,名詞是整個短語的中心語,它是短語所要表達的主要內容,而短語中的其他部分都是這個中心語的扮演角色。根據心理詞典中關於「dog」和「the」的定義,剖析器可以解讀出這個短語的含義:一隻已經提到過的狗。
接下來的單詞是「likes」,很明顯,這是一個動詞(V)。既然出現了一個動詞,那麼就必然存在一個動詞短語,而這恰好是剖析器所預料的結果,因此它立即被拼接到句子之中。對於動詞短語而言,僅有一個動詞還不夠,它還需要一個名詞短語作為自己的賓語。剖析器由此做出預測:接下來應該出現一個名詞短語。
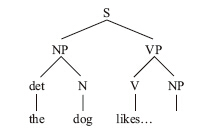
下一個出現的是名詞「ice cream」,它正好可以作為一個名詞短語來填補樹枝NP下出現的空缺。就這樣,剖析器完成了最後一塊拼圖:
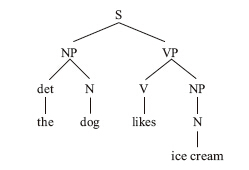
「ice cream」一詞完成了建構名詞短語的任務,因此它不必再保存於記憶之中。名詞短語完成了建構動詞短語的任務,所以它也可以被丟到一邊,最終由動詞短語將這個不完整的句子補齊了。當記憶中所有不完整的分枝都被清理乾淨後,一切都變得豁然開朗:我們聽到的是一個要素齊全、合乎語法的句子。
當剖析器將一個個分枝拼接起來的時候,它也在解讀這個句子的意思。剖析器所利用的工具是心理詞典和各種搭配規則。動詞是動詞短語的中心語,所以句中的動詞短語所強調的是「likes」。在動詞短語中,名詞短語是動詞的賓語,根據心理詞典對「likes」一詞的解釋,它的賓語是指被喜歡的對象。因此,句中的動詞短語所表達的意思是「喜歡冰激凌」。位於時態動詞前面的名詞短語是這個動詞的主語,根據我們的心理詞典,「likes」一詞的主語是動作的執行者。通過將主語「The dog」和動詞短語「likes ice cream」的語義綜合起來,剖析器就可以確定這個句子的意思:一隻先前已經提到過的犬科動物喜歡上了一種冰凍的甜品。