
我們從立體圖開始談起吧。它們是怎麼回事,為什麼它們對有些人就不起作用呢?儘管有那麼多張貼畫、書和拼圖遊戲,我還沒見過誰試圖將其中的原理向數百萬名好奇的消費者解釋。理解立體圖不僅是掌握知覺工作原理的良好方式,而且還是滿足心智好奇的一種方法。立體圖還是自然選擇傑出設計的又一個例子,只不過這一次是發生在我們自己的大腦裡。
立體圖利用了不止一個關於如何戲弄眼睛的發現,而是利用了四個。首先,說起來奇怪,是圖片本身戲弄了我們。攝影圖片、繪畫、電視還有電影把我們折騰得不勝厭煩,以至於都忘了它們本是一種有益的錯覺。墨跡或閃爍的磷光點能讓我們笑、讓我們哭甚至喚起我們的性慾。人類製作圖片的歷史至少已有3萬年,與某些社會科學的民間傳說恰恰相反,將圖片看作一種描述的能力是人類共通的。心理學家保羅·埃克曼(Paul Ekman)引發了一場人類學的狂熱,他證明了與世隔絕的新幾內亞高地人能夠辨認出照片中加州大學學生的面部表情。情緒像其他任何事情一樣,被認為是與文化相關的。而一個更基本的發現則被淹沒在喧囂中:新幾內亞高地人是在看照片上的內容而不是把它們當作斑駁的灰紙。
圖片利用了反射,這是一個令知覺成為難題的光學法則。當從平面反射的一個光子(光能的單位)沿著一條線收縮透過瞳孔,刺激眼球內曲面上的光感受器(桿狀體和錐狀體)時,視覺就產生了。感受器將神經符號上傳到大腦,大腦的首要任務就是弄清楚光子來自何處。然而,界定光子路徑的光線一直延伸到無窮,大腦所知的全部僅僅是那個光源就在光射線上的某一處。大腦所能判斷的,它或許是在一厘米遠,一公里遠,或者是許多光年那麼遠;關於第三維的信息,也就是光源到眼睛的距離,已經在投射的過程中遺失了。這種對物體距離上的不確定性,還會在上百個光感受器之間以排列組合的方式暴增——其中每一個感受器都無法刺激它的光源距離做出精準的預測。因此,任何視網膜圖像都可能是由世界上無限多種三維平面的組合排列而產生的。
當然,我們並沒有感知到無限的可能性;我們只確定一個,且通常是接近於正確的那個。這就是幻象產生的開端。如果佈置一些物體,使其投映在視網膜上的圖像與大腦的偏好中所識別物體的圖像相同,而大腦就沒有辦法分辨出它們的差異。一個簡單的例子是維多利亞時代的一項發明——通過房門窺視孔看到的是一個裝飾豪華的房間,然而當門打開時,卻發現房間裡空空如也,原來那個豪華房間是釘在房門窺視孔上的一個玩具屋。
開始是畫家,後來成為心理學家的埃德爾伯特·阿米斯(Adelbert Ames, Jr.),在其職業生涯的開創時建造了一個更為奇特的幻覺之屋。在一個這樣的屋子中,滿屋雜亂無章的線上懸掛著一些桿和板。但如果從外面通過牆上一個窺視孔看這個房間,這些桿和板連接起來投映為一把廚房椅子的映像。在另一個房間中,後牆從左到右逐漸傾斜,但它的角度非常古怪,使得左邊低得可以抵消它在視角上的擴展,而右邊高得足以抵消它在視角上的收縮。通過對面的窺視孔,這面牆投映出的是一個長方形。視覺系統不喜歡巧合:它推測一幅規則的圖像來源於一些真的、規則的東西,而不是由一個不規則形狀的偶然調整而產生的效果。阿米斯確實校準了一個不規則的形狀才得出一幅規則的圖像,他還用歪曲的窗戶和地板磚來強化他狡猾的把戲產生的效果。當一個小孩站在近角而她媽媽站在遠角時,這個孩子在視網膜上投映出更大的圖像(見圖4-1)。大腦在評估大小時也將深度考慮在內;這就是為什麼日常生活中近處學步的孩子看上去並不會比遠處的父母更大的原因。而現在,觀察者的深度感成了它不喜歡巧合的犧牲品。牆上的每一寸地方都似乎有著相同的距離,因此解釋視網膜上的物體圖像就根據表面的情況,故而小孩看上去就比媽媽高得多。當她們沿著那堵後牆交換位置後,小孩就縮成了哈巴狗的大小,而媽媽則變成了威爾特·張伯倫(Wilt Chamberlain)[11]的高度。阿米斯的房間已經建在了幾家科學博物館中,如舊金山的探索館,你可以親眼看到(或者親自體驗讓別人感受)這個令人驚歎的錯覺。
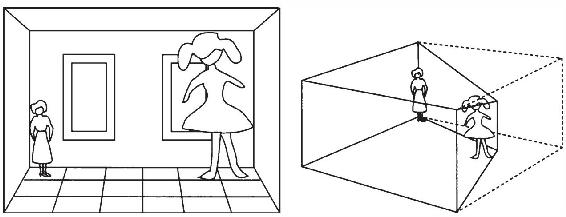
圖4-1
一張圖片不過是佈置東西的一種更方便的方式,這樣它可以投映出與實際物體相同的效果。模仿的東西是位於一個平面上的,不是在一個玩具屋中,或是由線懸掛著的,它是靠塗抹顏料而形成的,而不是將木頭切出形狀。即使沒有阿米斯式幻象,塗抹的形狀也能夠確定。達·芬奇曾簡潔地描述過這個把戲:“視角不過就是在一面很透明的玻璃後面看一處地方,在玻璃面上畫下後面的物體。”如果繪畫者是從一個固定的觀察位置來看風景,並忠實地複製出它的輪廓,一直到狗的最後一根毛髮,那麼從繪畫者位置觀看這幅畫的人眼中映入的就是原始景色投映的相同的一束光線。在那部分視覺域中的圖畫與世界是沒有區別的。無論什麼假設迫使大腦將世界看成世界而不是看作塗抹的顏料,它們也同樣會迫使大腦將圖畫看成世界,而不是看作塗抹的顏料。
這些假設是什麼呢?我們稍後會繼續探討,不過在這裡先做一個概覽。平面的色彩和質地都是均勻分佈的(即覆蓋著規則的顆粒、波浪或斑點形狀等),因此平面上點紋的逐漸變化是由光與視角造成的。世界上常有一些平行的、對稱的、規則的直角形狀位於平地之上,但它們看上去似乎是漸進遞減式的連續;這種漸進遞減的連續形成的就是視角的一種作用。物體有著規則、緊湊的輪廓,所以如果物體A的一小塊被拿掉而被物體B填滿那個空缺,那麼A就在B的後面;而不會是看起來B的凸出的部分湧入了A缺失的一塊。在圖4-2中,你能體會到這些假設的作用,它們傳達了一種深度的感覺。
圖4-2 深度的感覺
在實踐中,現實主義畫家們沒有在窗戶上塗抹作畫,而是使用記憶中的視覺圖像和神奇的大腦在畫布上完成作品。他們會使用的工具,包括了由細線或是刻印在玻璃板上的細痕而製成的方格坐標、穿越過畫布上針孔並緊緊綁在場景和一個觀察用標線裝置之間的細線,照相機暗箱,投影儀,還有現代的尼康相機。當然,沒有畫家能夠把狗的每根毛都一絲不落地畫下來。繪畫技巧、畫布質地,以及框架形狀都使得一幅畫達不到達·芬奇窗戶的理想狀態。此外,我們幾乎總是從一個與繪畫者在其窗前估測的觀察點不同的位置來看一幅畫,這就使得映入眼中的那束光不同於真實風景所散發出的光束。這就是為什麼繪畫只是部分的幻覺:我們看到了繪畫所描述的內容,但我們同時只把它看作一幅畫,而不是現實。畫布和邊框向我們洩漏了差異,值得注意的是,我們用這些線索來確定我們相對於這幅圖的觀察點,並彌補與繪畫者觀察點之間的差異。我們因此能去除觀看畫作時所看到的失真現象,而能從畫家的角度,去正確詮釋那些經過調整後的形狀。彌補工作僅限於此。我們去影院看電影遲到時坐到了前排,這時我們觀察點和攝影機觀察點(類比於透過達·芬奇窗戶的畫家)之間的差異被拉伸得過大,我們會看到歪歪扭扭的演員在不規則的四邊形上滑來滑去。
藝術與生活之間還有一點不同之處。畫家只能從一個觀察點來看景色,而觀看者從兩個觀察點來看世界:他左眼的觀察點和右眼的觀察點。伸出一隻手指,保持靜止,並閉上一隻眼睛,然後閉上另一隻。手指遮蔽了它背後世界的不同部分。兩隻眼睛有著略微不同的視覺,這種幾何現象被稱為雙目視差。
許多動物都有兩隻眼睛,這樣每當它們向前瞄準時,它們的視野會有所重疊(而不是為了向外看到全景),自然選擇一定曾面臨過將雙眼的圖畫組合成一幅統一圖像,使得大腦的其他部分都可以使用這幅圖的問題。這個假想圖像的名字是根據腦門中間長著唯一一隻眼睛的神話人物而得來的:獨眼巨人——奧德修斯在旅行中遇到的單眼巨人種族的一員。製作獨眼圖像的問題是,沒有直接的方式可以將兩隻眼的視域疊加起來。大多數物體落在兩個影像的不同位置,其不同視它們距離多遠而定:物體離得越近,它的模擬圖在兩眼中的各自映像就離得更遠。設想桌上有一個蘋果,蘋果後面有個檸檬,蘋果前面有串櫻桃(見圖4-3)。
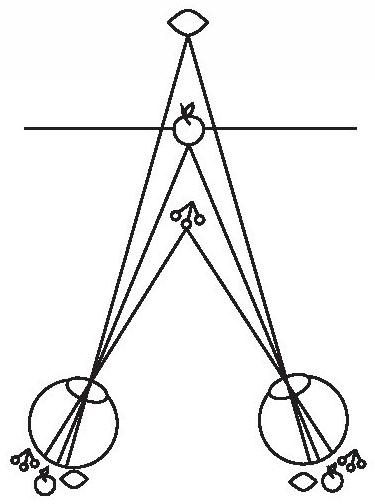
圖4-3
你的眼睛盯著蘋果,所以蘋果的圖像落在了每隻眼睛的凹處(視網膜的平滑中心,那裡的視覺是最敏銳的)。蘋果在兩隻眼睛的六點鐘方向。現在來看這串櫻桃的映像,它們與蘋果離得更近。在左眼,櫻桃在七點鐘方向,在右眼,它們在五點鐘方向,而不是七點鐘方向。與蘋果離得更遠的檸檬在左眼映像是在五點半方向,在右眼的映像是在六點半方向。比固定點離得更近的物體逐漸向著太陽穴外移;離得更遠的物體則向著鼻子內移。
但這個簡單疊加的不可能性為演化提供了一個機遇。只要學過一些高中的三角學,人們就可以用物體在兩隻眼睛上映像的差異,以及通過雙目注視和雙目在頭蓋骨中分處形成的角度,來計算物體距離有多遠。如果自然選擇能夠連接一個神經計算機來計算三角問題,一種雙眼的生物就可以粉碎達·芬奇的窗戶而感受到物體的深度。這種機制就被稱為立體視覺。
令人難以置信的是,幾千年來竟沒有人注意到這一點。科學家們認為,動物有兩隻眼睛的原因和有兩個腎的原因一樣:身體兩邊對稱方案的副產品,這樣也許當一個器官損壞了,另一個就可以備用。歐幾里得、阿基米德和牛頓都沒有注意到立體視覺的可能性,甚至連達·芬奇也沒有完全理解它。達·芬奇沒注意到,兩隻眼睛會看到一個球體的不同部分,左眼對它左邊看得稍遠些,而右眼對它右邊看得稍遠些。要是他用一個立方體而不是球來作例子,他就會注意到,視網膜上的投影是不同的。立體視覺直到1838年才被物理學家查爾斯·惠斯頓(Charles Wheatstone)發現。惠斯頓還是一位發明家,惠斯頓電橋就是以他的名字命名的。惠斯頓寫道:
為什麼藝術家不可能對任何近乎固態的物體進行忠實的描繪,答案是顯而易見的了。所謂忠實描繪是指,心智對於圖畫和原物體本身無法區分。當用兩隻眼睛來看畫和物體時,對於畫,視網膜上投映的是兩張類似的圖像;而對於固態物體,兩幅圖像則是不相似的。在這兩種情況下,感覺器官上留下的印跡,以及由此在大腦中形成的知覺都是有根本差別的。因此,畫不可能與固態物體相混淆。
這麼晚才發現立體視覺有些令人奇怪,因為它在日常生活經驗中並不難發現。你走路的時候,將一隻眼睛閉上幾分鐘,世界就變成了更平的地方,你可能會被門廊蹭著,或將一勺糖舀到膝蓋上。當然,世界並沒有完全變平,腦中仍然有著圖片和電視裡呈現的那種信息,比如遞減、咬合、是否置於地面和質地成分。最重要的是,還有位移運動。當你移動時,你的觀察點在連續改變,使得近處的物體呼嘯而過,而遠處的物體動得較慢。大腦將這種流態模式理解為經過一個三維世界。光學流態對結構的知覺在《星際迷航》《星球大戰》中都有明顯的體現,還有在一些流行的計算機屏幕保護中:逐漸離開顯示屏中心的白點顯示的是飛向太空(儘管真正的星星離得太過遙遠,沒辦法令真實世界的星際艦隊成員產生這樣的印象)。所有這些對深度的單目線索使得單眼盲人生活不大受影響,其中包括飛行員威利·普斯特(Wiley Post)和20世紀70年代紐約巨人橄欖球隊的一位外接手。大腦是一個機會主義者,還是一個數學很好的信息消費者,或許這就是為什麼雙目視差能長久以來一直避開科學家們審視的原因。
惠斯頓設計了第一幅完全三維的圖畫——立體圖,這樣他就證明了,心智將三角學納入了意識。惠斯頓的想法很簡單,他用達·芬奇的兩扇窗戶,或者實際點兒,用兩台照相機來捕捉一幅圖景,每台相機的位置就和一隻眼睛要看的位置一樣(如圖4-4)。將右邊的照片放在右眼前,左邊的照片放在左眼前。如果大腦推測兩眼在看一個三維世界,與雙目視差看到的有所不同,它就會被照片所愚弄,將兩張照片組合成一幅單眼圖景,其中物體看上去有著不同的深度。
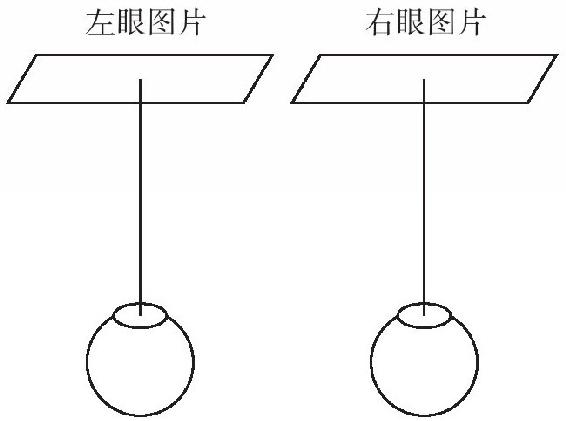
圖4-4
不過,在這裡惠斯頓遇到了一個問題,一個仍挑戰著所有立體圖的問題。大腦對一個平面的深度用兩種方式從物理上調整眼睛。首先,儘管我一直將瞳孔描述成好像是一個小孔,但事實上它有一個晶體來彙集發散自世界上某個點的許多束光,並將這些光聚焦到視網膜上的一點。物體離得越近,光線就彎折得越多,這樣才可以將光匯聚成一個點而不是匯聚成一個模糊的圓盤,眼睛的晶體也就需要越扁平。眼球內部的肌肉需要加厚晶體來聚焦近處的物體,使晶體扁平來聚焦遠處的物體(見圖4-5)。
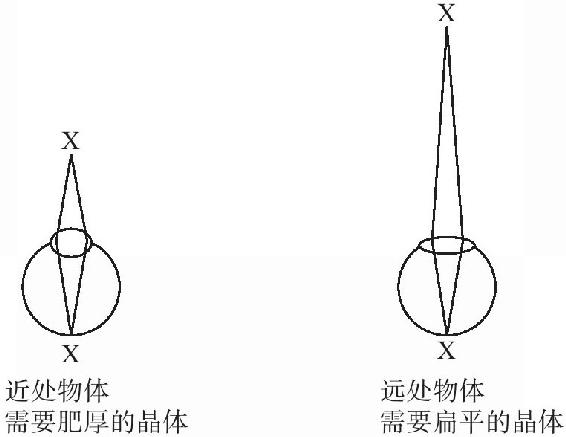
圖4-5
這種對晶體的擠壓過程是由一個能調整焦距的反射動作加以控制的:這種反饋回路能夠對晶體的形狀進行調整,直到視網膜上成像的清晰度到達最高為止。這種回路與一些自動調焦照相機的原理很類似。聚焦不清的電影看起來很讓人心煩,因為大腦不停地試圖調整晶體來減少模糊感,但這是一種徒勞無功的做法。
第二種物理調整是為了將隔著約6厘米的兩隻眼睛將目標調整到世界的相同一處。物體離得越近,兩隻眼睛的目光勢必交叉得越多(見圖4-6)。
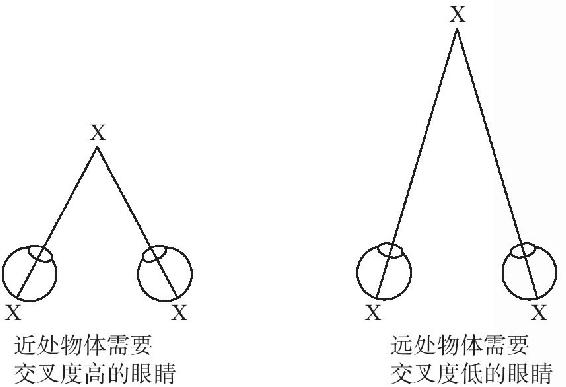
圖4-6
目光交叉與否由附著在眼邊的肌肉實現。控制這些肌肉的是一個努力減少重疊影像的大腦回路。看到重影往往是腦中毒、腦窒息或損傷的一個徵兆。這個回路類似於舊式相機中的測距儀:稜鏡從兩個取景框中取景,攝影師調整稜鏡角度(使它適合於照相機鏡頭),直到圖像排列好為止。大腦將測距儀原則作為深度的另一種信息來源,它或許是一個不可缺少的信息源。立體視覺只給出了有關相對深度的信息——在眼睛聚合點之前或之後的深度。眼球方向的反饋必須錨定絕對深度的感覺。
這就是立體圖設計者所面臨的問題:聚焦反射和眼交叉反射是連在一起的。如果你聚焦到附近一點來減少模糊,目光就逐漸聚合;如果你聚焦到遠處一點,目光就變得平行。如果你將目光聚合到附近一點來減少重影,眼睛就壓縮晶體從而近距離對焦;如果你將目光分岔到遠方一點,晶體就會放鬆到遠處聚焦。這種搭配超過了對立體圖最簡潔的設計,立體圖將一張小圖放在每隻眼的前面,雙眼目光都直視前方,各自看各自的圖片。你在看遠處物體時,目光直視前方,它將每隻眼的聚焦點拖至遠方,從而模糊了圖片。聚焦圖片接著又將目光拉在一起,這樣兩隻眼睛都看著同一張圖片,而不是每隻眼睛各看一張圖片,而且那也沒有用處。目光內外擺動、晶體變厚變薄,但時機不對。要想得到立體視圖的錯覺,還需要其他條件。
一種方法是拆開這對反應。許多實驗心理學家都像苦行僧一樣訓練自己,竭力控制他們的生理反射並用意志力來“自由-融匯”立體視圖。有些人將目光交叉到圖片前方想像的一點,這樣左眼能看著右邊的圖片,右眼則看著左邊的圖片,並將每隻眼看圖片的目光聚焦到後方想像的點。另外一些人將目光鎖定到正前方無限遠處,同時仍保持著聚焦。在我得知威廉·詹姆斯說過這是每個好的心理學家都應該掌握的一項技能後,我曾經花了一下午時間來訓練自己做到這點。不過,一般過著平凡生活的人,卻不見得能有這樣的決心和毅力。
惠斯頓的發明有些拙劣,因為他還面臨著第二個問題:他那個年代的繪畫和銀板照相都太大,在眼前沒法做到不重疊。人們做不到目光向外看,像魚一樣一隻眼睛看一邊。於是他在兩邊各放一張圖片,兩張圖片彼此相對,像書擋一樣,他還在照片之間放了兩面粘在一起的鏡子,就像一本打開的書的封面,每面鏡子都反射出一幅圖片。然後他在每面鏡子前放一個稜鏡,調整後使得兩面鏡子看上去像是疊加上去的。當人們透過稜鏡看到疊加上去兩幅圖片的反射時,圖片中的景色就變成三維的了。更好的照相機和更小的電影膠片催生了更簡便的手持型設計,我們現在仍然在用這些設計。更小的照片——同以往一樣,是從兩個同雙眼間距相同的觀察點拍攝的——被並排放置,中間有一個垂直信號燈,每隻眼睛前面還放著一個玻璃鏡頭。玻璃鏡頭使得眼睛無須聚焦於近處的圖片,目光可以放鬆到無限延伸的遠方。這使得目光發散,從而可以直視前方,一隻眼睛看一幅圖片,圖片就自然地融匯在一起。
立體圖成為19世紀的電視機。維多利亞時代的人們與家人和朋友一起愉快地花上幾個小時輪流來看巴黎林蔭大道、埃及金字塔或者尼亞加拉大瀑布的立體照片。漂亮的木質立體圖現在在一些古玩商店裡仍有銷售,供熱心的收藏者淘寶。現代的版本是三維魔景,在世界各地的旅遊景點都有:一個不貴的觀看器,展示了當地風景名勝的立體視圖幻燈片。
一種不同的技術——立體影片,是將兩張圖片蓋在一個平面上並運用了巧妙的手法,這樣每隻眼睛只會看到想看到的圖片。一個熟悉的例子是與20世紀50年代早期風靡一時的三維立體電影有關的,就是聲名狼藉的紅綠色紙板眼鏡。左眼的圖像投映為紅色,右眼圖像投映為綠色,映像都照在一塊白色屏幕上。左眼看屏幕時通過一個綠色的濾光鏡,使得白色背景看上去是綠色的,而為另一隻眼睛準備的綠線則看不到,為左眼準備的紅線則像黑線一樣凸顯出來。與之類似,右眼前面紅色的濾光鏡使得背景呈現紅色,紅線看不見,綠線變成黑線。每隻眼睛都得到它自己的圖像,於是阿爾法半人馬座的污泥怪獸便躍然屏幕之上。一個不幸的副作用是,當眼睛看到非常不同的模式,比如紅色和綠色的背景時,大腦就沒辦法融匯它們了。大腦將視域雕刻成一塊拼湊品,將每個拼湊小塊交替看作綠色或紅色,這種令人不安的效應被稱為雙目競爭。當你將一根手指保持在眼前幾厘米的距離,同時睜開雙目注視遠方,你就會看到雙重影像,這就是一種輕微的雙目競爭體驗。如果你集中注意於其中一個影像,你會發現,那部分逐漸變得不透明,然後透明,再度填實,如此往復。
一種更好的立體照片是將偏振濾光片,而不是帶色的濾光片,放到兩個投映鏡頭上和紙板眼鏡裡。用左邊的投影儀來投映為左眼準備的圖像,在像“/”這樣的對角平面中振蕩的光波中投映。光可以穿過左眼前面的濾光片,濾光片中有一些細微的裂隙也是同樣方向,但光卻穿不透右眼前面的濾光片,它的裂隙是反方向的,像“\”這樣。相反,右眼前面的濾光片只允許來自右邊投影儀的光穿過。疊加的圖像可以是彩色的,它們不會造成雙目競爭。阿爾弗雷德·希區柯克(Alfred Hitch-cock)在《電話謀殺案》(Dial“M”for Murder)利用這種技術創造了極好的效果,影片場景中,格蕾絲·凱利摸到剪刀刺向就要掐死她的人。而跟據科爾·波特(Cole Porter)的《野蠻公主》(Kiss Me Kace)改編的電影則有些不同之處,影片中一個舞者一邊起勁兒地在咖啡桌上表演著“太熱了”,一邊卻朝著攝像機拋甩著圍巾。
現代的立體眼鏡有用液晶顯示屏做的方格(像電子錶中的數字一樣),起到靜音的、電子控制快門的作用。在任何時刻,一個快門是透明的,另一個是不透明的,這迫使眼睛依次看著它們前面的計算機屏幕。眼鏡與屏幕是同步的,當左快門張開時顯示出左眼的圖像,右快門張開時顯示出右眼的圖像。圖像交替很快,眼睛都注意不到閃爍變化。這種技術可以用在一些虛擬現實顯示中。不過虛擬現實的最先進水平其實就是高科技版本的維多利亞時代立體視圖。計算機在一個小液晶顯示屏上顯示每張圖像,屏幕前面有一個鏡頭,鏡頭裝在每隻眼睛前面頭盔的內側。
這些技術都迫使觀看者戴上或通過某種儀器來觀看某種神奇的景象。魔術師的夢想是一種可以用裸眼看到的立體視圖——自動立體視圖。
這個原理是由蘇格蘭物理學家戴維·布魯斯特(David Brewster)在19世紀發現的,他還研究偏振光,並發明了萬花筒和維多利亞時代的立體視鏡。布魯斯特發現,牆紙上重複的模式可以令人注意到深度。緊挨著的重複模式(見圖4-7),比如說花朵,可以讓每朵花都吸引一隻眼睛盯在那朵花上。這是因為相同的花處在兩個視網膜的相同位置,所以雙重影像看上去就像只有一個影像。事實上,就像一件扣錯紐扣的襯衫,整個雙重影像的排列可以錯誤地編織成一張圖像,除了兩端沒有配對的單個影像之外。大腦則看不到雙重影像,它過早地滿足於雙眼已經恰當地聚合,並將目光鎖定在錯誤的校準中。這使得目光瞄準於牆後面想像中的一點,花朵似乎在這個距離飄浮在空中。它們還似乎長大了一些,因為大腦進行了三角運算,計算出花在那個深度需要多大才能投映出當前的視網膜圖像。
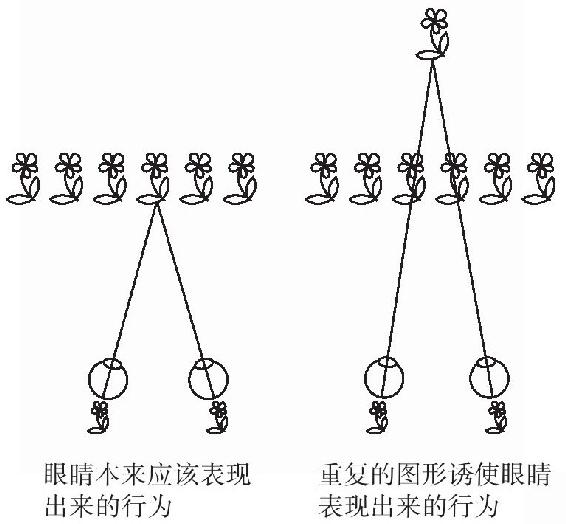
圖4-7
一種體驗牆紙效應的簡便方法是眼睛盯著幾厘米遠的瓷磚牆,距離近得無法使目光輕易聚焦和匯合。(許多男人是站在小便池前才又發現這個效應的。)每隻眼前的小瓷磚很容易就融匯在一起,產生出一種很遠處有一面很大瓷磚牆的超現實印象。牆向外彎曲,隨著腦袋從一邊移動到另一邊,牆向著相反方向擺動。如果牆真是在那個距離的話,實際情況也會是如此,將在視網膜上投映出同樣的影像。大腦輕率地創造了這種錯覺,是為了保持整個幻覺幾何形狀的一致性。
布魯斯特還注意到,將一對完全相同的東西在空間裡不規則地擺放,都會使它們比起其餘的更凸顯或陷入。設想圖4-7中被視線穿過的花朵之間的距離被打印得更為接近些。視線被聚在一起,彼此交叉,離眼睛也更為接近。視網膜上的圖像會朝太陽穴方向展開,大腦會看到想像中的花朵離得更近了。類似地,如果花朵的間距被打印得更遠些,視線則會交匯在更遠處,在視網膜上的投映則會擠到鼻子的方向。大腦會認為這個虛幻物體距離更遠了。
現在我們談到了一種簡單的“電眼”錯覺——牆紙自動立體視圖。一些書和賀卡中的立體視圖顯示了多列重複的東西——樹、雲、山和人。當你看這些立體視圖時,感到每一層物體在漂進漂出著,都有著自己的深度(儘管在這些自動立體視圖中,並沒有出現新的形狀,我們稍後會談到那些七拐八扭的立體圖。)這有個例子(見圖4-8),是伊拉維涅爾·薩比亞(Ilavenil Subbiah)設計的。
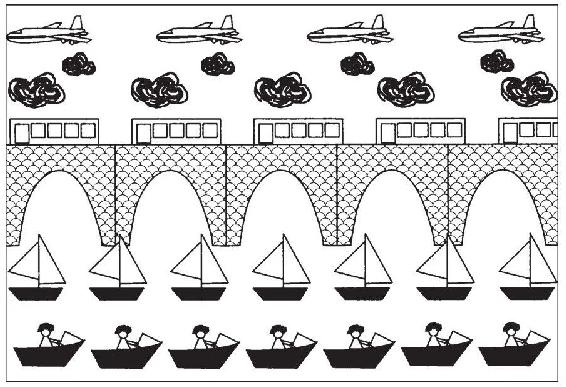
圖4-8
圖4-8有些像布魯斯特的牆紙,但它刻意有一些不均等的分隔,這並不是出於裱糊工人的草率之舉。圖片中包括了7艘緊密排列的小船,但只有5座間距疏鬆一些的橋拱,當你向圖片後方看時,小船似乎比橋拱離得更近,因為它們錯誤交匯的視線聚到了一架更近的飛機上。
如果你還不知道如何融匯看到立體視圖,請把這本書舉到你眼睛的正前方。使書的距離近得目光無法聚焦,令你的眼睛直視前方,看到重影。然後慢慢將書離遠些,同時保持眼睛放鬆,“穿透”書看到書後面想像的一點。有些人將一片玻璃或一張幻燈片放在立體視圖頂部,這樣他們就能聚焦到遠處物體的反射光了。你應該還能看到重影。這個手法是讓重影中一個圖像漂到另一個的頂端,然後就像磁石一樣,將它們保持在那裡。試著校準圖像。疊在一起的輪廓應當逐漸聚焦,然後彈進彈出不同的深度。正如泰勒所說,立體視覺就像愛情:如果你不能確定,你就還沒有體驗到。
有些運氣不錯的人能做到這點,他們把一根手指放在立體視圖前面幾厘米處,聚焦於這根手指,然後慢慢移開它,同時目光仍保持那個深度。用這種技巧,目光交叉帶來的錯誤融匯使得左眼看到右邊的一隻船,而右眼看到左邊的一隻船。別擔心你媽媽說的話;你的眼睛不會永遠僵死在那個位置的。你能否對眼看到融匯的立體視圖還是對眼程度不夠,這依賴於你是否能將目光略微交叉或盯著牆斜視。
通過練習,大多數人都可以目光融匯看到牆紙立體視圖。他們不需要像心理學家目光自由融匯來看二圖立體視圖那樣,做瑜伽般的精神高度集中,因為他們不需要將他們的聚焦投影從匯聚投影中以同等程度分離出來。看到自由融匯的二圖立體視圖需要雙眼目光分開,各自保持直視其中一幅圖片。而看到融匯的牆紙立體視圖則只需要雙眼目光分開,保持直視同一幅圖中的鄰近相同物體。相同物體之間的距離非常接近,會聚角只在聚焦投影想要的地方那條線之外的不遠處。在兩個投影之間的網絡中通過小小的擺動,聚焦於比你目光會聚處稍近一點的地方,這對你來說應該並不太難。如果確實難的話,艾倫·德詹尼絲可能會把你拉到她的輔助小組中。
牆紙立體視圖背後的手法——相同圖畫吸引目光產生了錯誤的視覺配對——揭示了大腦要看到立體圖所必須解決的一個基本問題。在大腦能夠測量雙目視網膜上某一點的位置之前,它需要確定一隻視網膜上的一點與另一隻視網膜上的那點都是來自現實世界的同一個標誌。如果現實世界只有這一個標誌,那就容易了。但如果有兩個標誌,視網膜的圖像就可能以兩種方式匹配(見圖4-9):左眼中的1點在右眼中也是1點,左眼中的2點在右眼中也是2點——這是正確的匹配;或者,左眼中的1點在右眼中是2點,左眼中的2點在右眼中是1點——這種錯誤的匹配會導致兩個虛擬標誌的幻覺。
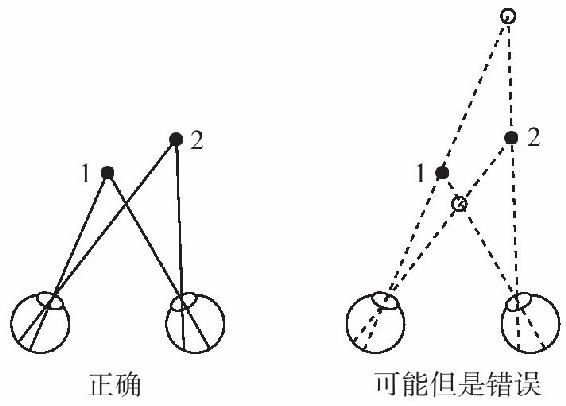
圖4-9
如果增加更多的標誌,匹配錯誤就會增倍。有3個標誌,就有6個錯誤匹配;10個標誌,90個;100個標誌,幾乎10000個錯誤匹配。早在16世紀,天文學家約翰內斯·開普勒(Johannes Kepler)就注意到了這個“匹配問題”,他思考了凝望星空的眼睛如何與數以千計的白點相匹配的問題,以及一個物體在空間中的位置如何能夠根據它的多重映像而被確定的問題。牆紙立體視圖的效果是依靠誘騙大腦接受一個貌似正確但實際錯誤的方法來解決匹配問題的。
直到最近,每個人都認為大腦解決了日常生活中匹配的問題。大腦首先通過識別出每隻眼睛中的物體,然後將相同物體的影像利用匹配的方式加以匹配。左眼中的檸檬與右眼中的檸檬匹配,左眼中的櫻桃與右眼中的櫻桃相匹配。在智能的指導下,立體視覺可以只把來自同種物體的點連在一起,從而避免錯誤匹配。一個典型的情景或許包含幾百萬個點,但包含的檸檬卻少得多,也許只有一個。所以如果大腦對整個物體匹配的話,出錯的機會就會變少。
但自然並沒有選擇這種解決方法。第一個線索來自阿米斯的另一個古怪屋子。這一次,不知疲倦的阿米斯建了一座普通的長方形房間,但在每厘米地板、牆壁和天花板上都粘貼了樹葉。用一隻眼睛通過窺視孔來看這間屋子時,就好像是模糊的綠色海洋。但當用雙眼來看時,它又恢復成正確的三維形狀了。阿米斯構建了一個只能用神奇的中央獨視眼來看而不能單用左眼或右眼看的世界。但如果大腦必須依賴於識別出每隻眼中的物體並將之聯繫起來,它又如何將兩隻眼睛看到的情形匹配起來呢?左眼看到的是“葉子葉子葉子葉子葉子葉子葉子葉子”,右眼看到的也是“葉子葉子葉子葉子葉子葉子葉子葉子”。大腦面臨著能想像到的最困難的匹配問題。儘管如此,它還是輕鬆地將雙眼看到的物體匹配在一起,顯現出中央獨視眼的視覺。
這個例子並非無懈可擊。如果房間的邊和角沒有被葉子蓋好怎麼辦?也許,每隻眼睛都對房屋的形狀有一個大概的認識,當大腦將兩幅圖像融匯在一起時,它就更加確信這種認識是準確的了。大腦無須識別物體即可解決匹配問題的證據來自心理學家貝拉·朱利斯(Bela Julesz)早些時候巧妙運用的計算機圖像。在1956年逃離匈牙利來到美國之前,朱利斯是一名對空中偵察感興趣的雷達工程師。空中偵察採用了一種巧妙的手法:立體視覺穿透偽裝。偽裝的物體表面覆蓋著一些與周圍背景環境相一致的標誌物,使物體與背景的邊界不那麼明顯。但只要物體不像烙餅那麼平,當從兩個觀察點看時,雙眼看到的標誌物就會呈現出略微不同的位置,而背景標誌則不會怎麼移動,因為它們離得更遠。空中偵察的手法是拍攝陸地的照片,然後讓飛機飛一小會兒,再拍張照片。將兩張照片並排放在一起,然後將它們輸入一個對這兩張照片的差異超級敏感的探測器:一個人。人實際上是在用一個立體圖觀看器來看圖片的,就好像他是一個巨人,將他的兩隻眼睛放在當初飛機照相機上的兩個位置一樣,於是偽裝的物體就在深度上呈現出來了。因為根據定義,一個偽裝的物體用單眼幾乎是看不到的,我們有另外一個例子來說明神奇中央獨視眼能夠看到任何一隻真眼都看不到的東西。
證據要來自完美的偽裝,這一次朱利斯使用了計算機。對於左眼的視覺,他在計算機上做了一個正方形,上面蓋著隨意分佈的點,就像電視機的雪花點一樣(見圖4-10)。然後朱利斯讓計算機又為右眼做了一個完全相同的正方形,只有一處做了調整的正方形:他將一小片點略微向左挪了一些,將新的一條隨意分佈的點插入了右邊的縫隙,這樣移走的點就偽裝得非常好了。每張圖片自己都像散亂的胡椒籽一樣。但當用立體視圖觀看時,那一片就躍然浮現出來。
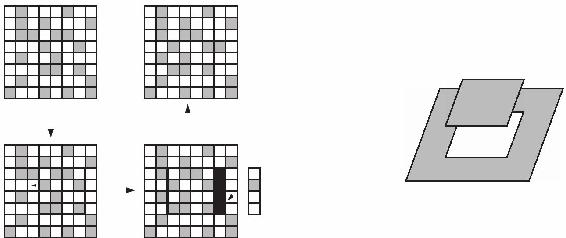
圖4-10
許多當時的立體視圖權威拒絕相信這一點,因為大腦要解決的匹配問題太難了。他們懷疑,朱利斯是不是在一幅圖背後劃下了小標記。不過計算機當然沒有作弊。任何看了隨機散點立體視圖的人都會立刻信服朱利斯的實驗。
與朱利斯偶爾會合作的克裡斯托弗·泰勒,發明神奇眼立體視圖所用的只是將牆紙自動立體視圖與隨機散點立體視圖組合起來而已。計算機得出了垂直的一條散點,然後把複製後的小條並排放在一起,這樣就製作了隨機散點牆紙。假設每一條有十個點那麼寬,我們將點從1數到10……用“0”代表10就如圖4-11所示。

圖4-11
任何一簇點——比如說,“5678”——每隔10個空格就重複一次。當目光凝視到鄰近條的時候,這些長條圖便會在我們的視線裡結合起來,就像我們在牆紙立體視圖裡體驗到的一樣,只不過我們的大腦是把兩片點圖而不是把兩個花朵圖案重疊在一起罷了。那些相距較近的重複圖案會帶給我們較其他的立體影像更為接近的幻象,這是因為兩眼放在其上的視線會在距離我們更近的地方相交的緣故。要在電眼立體視圖裡讓某一片圖案浮在其他幻象之前,設計者就必須先決定好該片區域的範圍,再讓其內的每一圈黑點都能與距離它最近的相同黑點靠得更近。在圖4-12中我想做一個漂浮的長方形。所以我從兩個箭頭之間的長條中剪出兩個點4;你能找到被剪的那幾排,因為它們要比其他排短兩個空格。在長方形中,每一簇點,比如“5678”,都每隔9個而不是10個空格就重複一次。大腦把彼此更加鄰近的複製點簇解釋為來自更為接近的物體,這樣長方體就漂浮起來了。順便提一句,圖4-12不僅展示了自動立體視圖是如何製作的,而且它本身就產生了一個自動立體視圖效果。如果你把它像牆紙一樣看得融匯在一起,一個長方形就會浮現出來。頂部的星形是為了幫助你得到立體幻象而準備的;讓你的目光飄移直到看見重影有4個星形,然後慢慢地將圖像聚在一起,直到中間兩個星形融匯在一起,這樣你就看到了一排3個星形而不是4個星形。小心地看圖4-12,同時目光不做重新調整,你就可以看到飄浮的長方形。

圖4-12 飄浮的長方形
你還應當能看到圖4-12下端有一個切開的窗口。我切窗口是通過選出一個長方形小塊,並做了與我以前做的相反的事情:我在這小塊裡的每一個點4旁邊塞進去額外一點(標誌為“X”)。這將散點簇推開得更遠,它們變成每隔11個空格才重複一次。你會注意到,被添加的行比其餘的要長。間隔空間更寬的各相同點簇相當於更遠的一個平面。當然,一個真正的隨機散點自動立體視圖是用點而不是用數字做的,所以你不會注意到被剪出或塞進的東西,參差不齊的線被填滿了額外的點。這裡有個例子(圖4-13)。看一個真正的隨機散點自動立體視圖的樂趣在於,令觀看者驚訝的那一刻呈現出的是觀看者先前看不到的形狀。

圖4-13
當自動立體視圖風靡日本時,它很快發展為一種藝術形式。點並不是必要的;任何掛毯類的裝飾,只要包含著很多的小輪廓,足以迷惑大腦將目光鎖定到鄰近條格,就會產生立體視圖效果。第一個商業化自動立體視圖使用了彩色的彎曲線,日本的自動立體視圖使用了花朵、海洋波浪,還有從阿米斯的書中取下的一片葉子,組成的無數片樹葉。多虧了計算機,立體圖像裡浮現的形狀也不再只局限於死板的鏤空形狀而已。通過讀取平面上三維坐標的點,計算機能夠以略微不同的數量來更迭每一個點,從而在中央獨視空間中塑造固定形狀,而不是嚴格地變換整個小塊。浮現出來的是光滑、球莖的形狀,看上去好像它們是用葉子或花朵形成的。
為什麼自然選擇為我們配設的裝備是真正的中央獨眼視覺(能夠雙眼共同看到形狀,但任何一隻單眼卻不行),而不是一個更簡單的雙眼立體機制呢?(這樣任何一隻眼看到的檸檬和櫻桃都會一致)泰勒指出,我們的祖先確實生活在阿米斯的樹葉屋裡。靈長目在樹上演化,需要識別認清樹葉掩蓋下的樹枝網絡。認不清的代價就是從高高的樹枝上跌落到森林的地面上。為這些雙眼生物構建一個雙眼立體計算機系統一定是自然選擇所無法抗拒的,但它之所以能夠實現,也是基於對數千個視覺組織進行過計算。能夠清晰匹配一致的單個物體太少了,彼此之間也隔得太遠。
朱利斯指出了中央獨眼視覺的另一個優點。動物們使用偽裝要比軍隊早得多。最早的靈長目動物就類似於今天的猿猴亞目、馬達加斯加的狐猿和眼鏡猴,它們抓樹上的昆蟲吃。許多昆蟲躲避捕獵者的方式是紋絲不動(這樣捕獵者的移動探測器就派不上用場了),或者通過偽裝(這樣捕獵者的外形輪廓探測器也就失靈了)。中央獨眼視覺是一種有效的反抵抗措施,就像空中偵察發現坦克和飛機一樣發現了獵物。武器的技術發展催生了軍備競賽,這在自然界中和在戰爭中一樣。一些昆蟲瞞住捕獵者立體視覺的方式是通過將身體扁平化,並與地面齊平,或者變成活的樹葉和樹枝雕塑——一種三維的偽裝。
中央獨視眼是如何工作的呢?匹配問題,即將一隻眼中的標誌與另一隻眼中的對應物彼此匹配的問題,是一個複雜的雞與蛋的困惑。只有你選擇了一對要測量的標誌,你才能衡量一對標誌的立體差異。但在一個樹葉屋或隨機散點立體視圖中,有數千個能夠作為標誌的候選物體。如果你知道表面有多遠,你就會知道向左眼視網膜的什麼地方看,從而找到右眼中對應的標誌。但如果你知道這個,就沒必要進行立體計算了——你已經有了答案。心智是怎麼做到的呢?
戴維·馬爾表示,對我們所演化世界的預置前提假設能夠有所幫助。在n個點的n2個可能匹配中,並不是所有的匹配都有可能出現在我們所處的美妙環境——地球上。一個設計良好的匹配者應該只考慮那些在物理上可能的匹配點。
第一,世界上的每個標誌都是被錨定在某個時間某個平面的某個位置上的。因此,一個合理的匹配必須將兩眼中相同的點進行配對,而這兩點來自真實世界的一個點。一隻眼中的一個黑點應與另一隻眼中的一個黑點匹配,而不是與一個白點匹配,因為所謂匹配要表示某個平面的單獨一個位置,而那個位置不可能同時既是一個黑點又是一個白點。反過來說,如果一個黑點與一個黑點匹配,它們一定來自真實世界某個平面的一個位置。這就是自動立體視圖所違背的假設:在立體視圖中,每一個定點的影像都是被分散到了幾個不同的位置。
第二,一隻眼中的一個點應當與另一隻眼中不超過一個點相匹配。這就是說,一隻眼的視線應當會與真實世界中一個且僅僅一個平面的一點終結。乍一看,這個假設好像是排除了穿過一個透明平面到一個不透明平面的視線(像一個淺湖的底部)。但這個假設實際上更為微妙;它只排除了一種巧合情況,即兩個相同點(一個點在湖面,一個點在湖底)從左眼觀察點角度看一個排在另一個後面,而從右眼的角度看兩點則都能看見。
第三,物質是內聚而且光滑的。大多數時候,一條視線所終結的真實世界平面不會比臨近視線所接觸的平面離得更近或更遠。也就是說,真實世界的臨近點一般會位於同一個光滑平面。當然,這個假設在物體的邊緣位置就被違背了:本書封底的邊緣就在離你四五厘米近的地方,但如果你只向它的右邊瞥一眼,你也許就是在看38萬公里之外的月亮。但邊緣只組成了視域的很小一部分(你畫一幅線性畫所需的顏料比為這幅畫填色所需的顏料要少得多),因此這些例外能夠被忽略。這個假設排除的是一個由沙塵暴、大群蚊蟲、團團細線、陡峭山峰間的深深裂隙及星星點點的釘床組成的世界。
這些假設在理論上聽起來似乎都是言之成理,但還需要找到一些滿足這些假設的匹配。雞和蛋的問題有時可以用被稱為“限制性滿意”的技術來解決,我們在第2章談論內克爾立方體和帶口音的講話時曾提到過這種技術。當一個謎的幾部分不能一次都解決時,解謎者可以一次猜幾個,再比較這個謎不同部分的猜測,來看看哪些是相互一致的。一個很好的類比就是用鉛筆和橡皮來做填字遊戲。一個水平單詞的線索往往太模糊,好幾個單詞都可以填進去;一個垂直單詞的線索也很模糊,好幾個單詞也可以填進去。但如果這些猜測的垂直單詞中,只有一個與任何猜測的水平單詞共用一個字母,這對單詞就被保留下來,其他的就被擦掉了。設想對所有的線索和方格即刻做此處理,你這樣的做法就是限制性滿意。在解決立體視覺的匹配問題時,散點就是線索,匹配和深度是猜測,關於世界的3個假設就像是這條規則:每個單詞的每個字母都必須佔據一個方格,每個方格裡必須有一個字母,所有的字母必須能組合成單詞。
限制性滿意有時可以在一個像我在圖2-8中提供的限制性網絡中實行。馬爾和理論神經學家托馬索·伯吉奧(Tomaso Poggio)設計了一個立體視覺限制性網絡。輸入單位代表點,就像隨機散點立體視圖的黑白方塊。他們用右眼的一些其他點輸入到代表左眼中一點的所有n×n可能匹配的單位排列。當其中一個單位開啟時,這個網絡在猜測,在世界的特定深度有一塊斑點(相對於目光匯聚的地方)。圖4-14是這個網絡一個平面的鳥瞰圖,顯示了一部分這些單位。
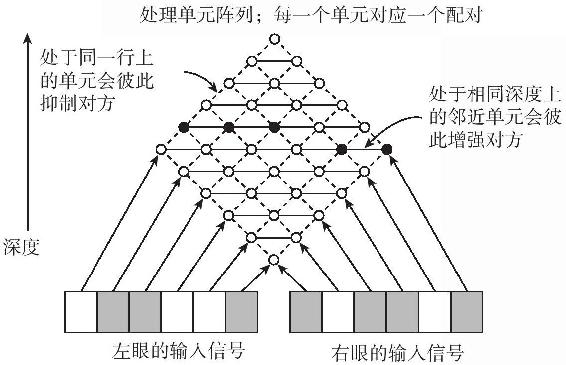
圖4-14
這個模型是這樣工作的:當陣列中的某一個單元由兩眼獲得了相同的輸入信號時,它會呈現開啟的狀態(黑的或白的),這包含了第一個假設(每個標誌錨定於一個平面)。由於各單位是相互作用的,激活一個單位會促使其上下臨近單位的激活。排列在相同視線的不同匹配單位彼此相互約束,這包含了第二個假設(沒有沿著一條視線而校準一致的標誌)。在附近深度的臨近點單位彼此相互激活,這包含了第三個假設(物質是具有內聚性的)。這些被激活的單位圍繞著網絡迴盪著,網絡最終穩定下來,那些激活的單位描繪出一個具有深度的輪廓。在圖4-14中,那些填入的單位呈現出懸在背景之上的一道邊緣。
在限制性滿意技術中,數千個處理器做了許多臨時的猜測,在眾多猜測中甄選出一個整體答案,這種技術是與認為大腦的工作是許多個相互作用的處理器平行計算的一般性觀點相一致的。它也抓住了一些心理學的要旨。在看一個複雜的隨機散點立體視圖時,你往往不能看到隱藏的圖像同時顯現出來。雜亂無章的圖案中會跳出一些邊緣,然後逐漸凸顯為一片圖案,從而使得另一側的模糊邊緣變得清晰明確,直到整個形狀結合而成。我們體會到最後圖案的出現,卻沒有感受到處理器實現這一結果的努力過程。這種體會很好地提醒了我們:在我們觀看和思考時,許多信息加工處理都在我們意識水平之下反覆進行著。
馬爾·伯吉奧模型抓住了大腦對立體視覺計算的要旨,但我們真正的大腦回路要複雜得多。實驗已經證明了,當人們被置於違背了唯一性和平滑性假設的人工操控的世界中時,他們觀察的能力並不像模型預測得那麼差。大腦一定在運用其他信息來幫助解決匹配問題,比方說,眼中的世界就不是散點組成的。大腦能夠將所有小斜紋、T形、鋸齒形、墨跡斑點以及兩眼視覺中的其他點點劃劃都匹配在一起(這些東西即使對於一個隨機散點立體圖來說也綽綽有餘)。點劃之間的錯誤匹配要比點與點之間的錯誤匹配少得多,因此需要被排除的匹配數量就顯著減少了。
另一種匹配方式是,利用兩隻眼睛在幾何意義上會給我們帶來不同效果的原理,這是達·芬奇注意到的:一個物體有一些部分是一隻眼睛能看到而另一隻眼看不到的。垂直拿著一支鋼筆放在面前,鋼筆的夾子朝外呈11點鐘方向。當你輪番閉上每隻眼睛時,你會發現,只有左眼能看到鋼筆夾;右眼看不到,這是因為鋼筆夾隱藏到了鋼筆其餘部分之後。自然選擇在設計大腦時是像達·芬奇那麼精明,讓大腦用這個重要線索來確定物體邊緣嗎?還是大腦忽略了這個線索,不情願地將每個錯誤匹配都記錄為物質內聚性假設的例外情況?心理學家肯·中山(Ken Nakayama)和下條紳介(Shinsuke Shimojo)證明了自然選擇並沒有忽視這條線索。他們設計了一個隨機散點立體視圖,其深度信息不是以更迭散點排列,而是以一隻眼睛能看見而另一隻眼睛看不見的位置排列的。那些點位於一個想像中的正方形的四角,一些點只在右眼圖像的右上角和右下角,一些點只在左眼圖像的左上角和左下角。當人們看這個立體圖時,他們看到一個由四點界定的懸浮正方形,這說明大腦確實將只有一隻眼能看到的圖像解釋為空中的邊緣。中山與心理學家巴頓·安德森(Barton Anderson)認為,有一些神經元發現了這些阻隔;它們會對一隻眼睛見到的一對標記做出反應——其中一個標記能夠和另一隻眼見到的標記加以匹配,而另一個標記卻無法找到配對。這些三維立體的邊界探測器會幫助立體網絡在懸浮的碎片輪廓中確定位置。
立體視覺不是兩隻眼睛憑空具有的,這種回路必須在大腦中布線。我們知道這個情況,因為大約有2%的人每隻眼都看得很清楚,但用中央獨視眼卻看不到;隨機散點立體視圖對他們來說仍然是平的。另外4%的人只能很模糊地看到立體圖。還有更多的一些少數人群有著更特別的欠缺:一些人看不到固定點後的立體深度;另一些人看不到固定點前的立體深度。惠特曼·理查德(Whitman Richards)發現了這些立體視盲形式,他提出假說認為,大腦有三組神經元來檢測雙眼中點位的差異。一組神經元負責完全巧合或幾乎完全巧合的成對的點,為了達到在聚焦點的細緻深度知覺。另一組負責鼻子側面的成對點,這是為了看到更遠的物體。第三組神經元則是負責視網膜上接近太陽穴部分的影像,也就是由較近物體所產生的投影。具有所有這些特性的神經元在猴子和貓的腦中都已經被找到了。不同種類的立體視盲似乎是遺傳性的,這說明,每組神經元都是由不同的基因組合設置的。
立體視覺並不是生來就有的,如果在兒童時期或動物幼年時一隻眼睛由於白內障或戴眼罩而得不到信息輸入,就可能永遠不能形成立體視覺。到此為止,這聽起來就像一堂乏味的課程,講述立體視覺就像其他任何東西一樣,是先天與後天的混合物。但一個更好的理解方式是:大腦需要組合加工,這種組合加工需要各個項目根據展開的時間表來排程。這個時間表不在乎生物體何時從子宮中脫胎而出;佈置順序可以在出生後再進行。這個過程在關鍵結合點處還需要基因所無法預測的信息輸入。
立體視覺似乎是在嬰兒時期突然出現的。當新生兒按照規律的時間間隔被帶到實驗室時,他們一周接一周都對立體視圖無動於衷,然後突然他們就被吸引住了。在接近那個創紀元式的星期,通常是出生3~4個月後,嬰兒開始自然、適當地做出對眼狀(例如,當他們自然地跟蹤一個放到鼻子前面的玩具時),他們還會覺得彼此衝突的視覺——每隻眼睛看到的模式不同——很困惑,而在之前他們會覺得那些很有趣。
這不是說嬰幼兒“學會了立體視覺”。心理學家理查德·海爾德(Richard Held)給出了一個更簡單的解釋。當嬰兒剛出生時,視覺皮質接受層的每個神經元將雙眼相應位置的輸入累加起來,而不是將這些輸入分隔開來。大腦沒辦法區分某一點的模式來自哪只眼,而只是以一種二維平面的方式,將一隻眼睛看到的融匯到另一隻眼睛看到的上面去。如果沒有關於一個彎曲線來自哪只眼睛這樣的信息,立體視覺、會聚性以及對斥性在邏輯上都是不可能的。大約以3個月為界,每個神經元都確定了一隻回應的主導眼睛。連接下端的神經元現在可以知曉,一個標誌何時落入一隻眼睛的一個區域和另一隻眼睛的相同區域,或是略微有所轉移的區域——這對立體視覺是有利的東西。
這種情況在貓和猴子身上都是確定發生的,它們的大腦可以得到直接的研究。動物的皮質一旦可以區分兩隻眼睛,動物就能看到有深度的立體視覺。這說明當輸入開始被貼上“左眼”或“右眼”的標籤加以區分時,下游一層的立體計算回路其實已經安裝好並開始工作了。對於猴子來說,所有這些在兩個月內就都結束了:那時每個神經元都有了主導眼,幼猴可以看到立體深度。與其他靈長類動物相比,人類有些“晚熟”:嬰兒出生得早,而且出生時沒有任何能力,要在子宮外完成他們的發育。按照幼兒期的時間長度比例,人類嬰兒比猴子要出生得早,因此從出生日開始測算,人類雙眼腦回路配置的出現時間要稍晚。更一般地講,生物學家比較了不同動物視覺系統的成熟階段時間,這些動物有些出生得早且無助,另一些稍晚而且一出生就能看見。他們發現,無論之後的發育是在子宮內進行還是在出生後的世界上進行,其順序都是基本一致的。
關鍵左眼神經元和關鍵右眼神經元的出現可能會為具體經歷所打斷。生物學家戴維·胡貝爾(David Hubel)和托斯滕·韋塞爾(Torsten Wiesel)養育了一隻眼睛被蒙著的小貓和小猴子,它們腦皮質的輸入神經元全部調向了另外一隻眼,使得這些動物那只被蒙上的眼睛在功能上等同於視盲。如果眼睛是在動物發育的關鍵期被蒙上的,那麼即使只是短暫剝奪視覺輸入,這種損害也是永久性的。對於猴子來說,視覺系統在出生後的前兩周尤其脆弱,這種脆弱性在第一年內逐漸減弱直至停止。而蒙上成年猴子的眼睛即使長達4年之久,也不會有所損害。
乍一看,這好像是“用進廢退”的一個例子,但是我們還有另外的發現。當胡貝爾和韋塞爾給小動物蒙上雙眼時,大腦並沒有顯示出雙倍的損害——一半的細胞顯示根本沒有被損害。單眼蒙罩實驗的摧殘不是由於被蒙眼睛的神經元得不到輸入,而是由於來自未蒙眼的輸入信號在途中擠走了被蒙眼的輸入信號。兩隻眼睛是同時在爭奪著視覺皮層中處理輸入信號層面裡的神經元的。每個神經元在開始時具有對這隻眼或那隻眼的細微偏向,而眼睛的輸入擴大了這一偏向,直到神經元可以獨自做出反應。輸入甚至無須來自外部世界,來自中途中間站的激活波——一種內部產生的測試模式,就能起到這個作用。若把學習理解為吸收錄入來自外部世界信息的話,成長髮育的長篇歷程儘管對動物經歷的變化很敏感,但還不完全是“學習”。就像一個建築師將一個粗略的毛坯交給一個低級的工匠來雕琢外觀輪廓一樣,基因構建了原始的具有眼睛偏向的神經元,然後啟動了一個確保可以將之明確化的過程,除非一個神經生物學家插手多事。
一旦大腦將左眼影像與右眼影像分隔開來,隨後的神經元層就可以比較它們表示深度的細微差異了。儘管仍然是以令人驚奇的方式進行的,這些回路也可以由於動物的經歷而得到修改。如果實驗者通過切掉一塊眼部肌肉而使得動物變得對眼或斜視,其目光就會指向不同的方向,永遠也不會同時在兩個視網膜上看到相同的東西了。當然,目光朝向並沒有分開180度,所以在理論上大腦能夠學習匹配那些確實重疊的不正常的分隔部分。但很顯然,它沒有具備能夠對雙眼交叉較大度數進行匹配的能力;這樣的動物長大後會成為立體視盲,而且往往兩眼中會有一隻在功能上視盲,這種狀況被稱為弱視。弱視有時被稱為“懶惰眼”,但其實這是誤導。不敏感的是大腦,而非眼睛;而這種不敏感性是由於大腦以一種恆久的競爭去主動壓抑一隻眼的輸入,而不是由於大腦懶散地忽略它。
同樣的情況也可以發生在孩子身上。如果一隻眼睛比另一隻眼睛更加遠視些,孩子會習慣上努力去聚焦於近處的物體,而連接聚焦和會聚的反射會使得眼睛內曲。兩隻眼睛指向不同的方向(這種情況被稱為斜視),它們的視界校準得不夠貼近,使大腦無法使用其中的差異信息。這種孩子長大後會患斜視和伴隨立體視盲,除非及早對眼部肌肉做手術調整眼部肌肉好讓兩眼能協調運作。直到胡貝爾和韋塞爾在猴子身上發現了這些結果,以及海爾德在孩子們身上發現了類似的情況,人們之前一直認為對斜視的手術僅供外表美觀所用,而且只限於學齡兒童。但對雙眼神經元的適當校準有一個關鍵期,它要比單眼神經元的校準關鍵期稍長些,但大概快到一兩歲時會逐漸消退。在這個時間之後做手術往往已經太晚了。
為什麼會有一個關鍵期,而不是天生設定或終身都會因經歷而改變呢?對於小貓、猴子和人類嬰兒,臉部出生後都一直在生長,眼睛之間的距離被迫越來越遠。眼睛的相對觀察點也在變化,神經元必須持續不斷地調整檢測到的雙眼間差距幅度。基因無法預測觀察點的擴展度,因為擴展度有賴於其他基因、營養和各種意外事件。所以,神經元會在個體成長的一定期間內對不斷相互分離的雙眼進行著追蹤。當眼睛移動到它們在成年個體的頭骨上應有的位置時,這種需求就消失了,也就是說,關鍵期在這時結束了。有些動物,比如像兔子,它們的眼睛已經確定在成年的臉部位置中,臉也幾乎不怎麼生長了。這些一般會是獵食動物,它們不能享受奢侈而漫長的無助的童年期。從兩眼中接收輸入的神經元不需要重新調整自己,事實上這些動物在出生時就已完成布線,而無須一個對輸入敏感的關鍵期。
對不同物種雙眼視覺可調性的發現,為一般意義的學習提供了一種新的思考方式。學習往往被描述為對模糊腦組織有著不可或缺的塑造作用。然而事實上這個過程存在的原因,卻有可能只是為了讓那些需要進行自我組裝的動物,能滿足它們在適應過程中所發展出對排定組裝時刻表的需求而已。基因組盡其所能構建了這個動物,對無法提前確定的動物構造部分(比如對雙眼以不可預知的速率逐漸分開的適當設置),基因組在成長髮育中最需要的時候開啟了一種信息搜集機制。在《語言本能》一書中,我闡述了一種對兒童語言學習關鍵期的類似解釋。
我帶著你瞭解了神奇眼立體視圖,不僅僅是因為理解魔術很有趣。我認為立體視覺是一個自然的榮耀,也是心智其他部分可能會如何工作的一個範式。立體視覺是我們體會一種特別意識的信息處理,一個心智計算與意識之間的連接,這種連接非常合乎規則,計算機程序員能夠將它操控並迷倒數百萬人。它是一個幾種意義上的模塊:它無須心智的其他部分而獨立工作(不需要可識別的物體),心智的其他部分沒有它也同樣可以工作(如果必須的話,可以用其他深度分析法來獲知),它在大腦的回路佈置上強加了特別的需求,它還有賴於針對其問題的具體原則(雙目平行的幾何學)。儘管立體視覺的發展是在兒童期進行的,而且對個人經歷很敏感,但它並不能被深刻地描述為“學習得到的”或是“先天與後天的混合產物”;這個發展過程只不過是一個組裝時刻表裡的一部分而已,對經驗體會的敏感性是一個結構化的系統對信息的外接納入。立體視覺展示了自然選擇的工程設計智慧,它利用了精妙的光學定理,這些定理在數百萬年後又被如達·芬奇、開普勒、惠特斯通以及空中偵察的工程師們重新發現。這種能力會出現的原因,是因為個體要適應存在於我們祖先生態環境中特定的選擇壓力。它通過做出關於世界的前提假設而解決了本不可解決的問題,這些假設在我們演化時是正確的,但現在卻不總是正確。
光、影、形:景物轉圖像3法則
立體視覺是辨別平面深度和材質的視力發育關鍵早期的一部分,但並不是唯一的部分。看到三維並不需要兩隻眼睛。你可以從一幅圖片的最簡單線索中獲得對形狀和材質的豐富感覺。下面我們來看看這些由心理學家愛德華·埃德爾森(Edward Adelson)設計的圖案(見圖4-15)。
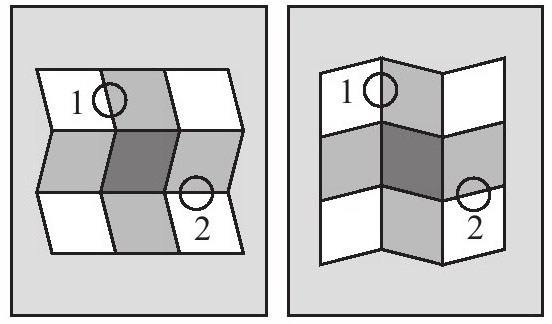
圖4-15
圖4-15左邊這個圖案看上去是有豎直灰條的白紙板,水平折疊,光從上面照下來。右邊那個看上去是有水平灰條的白紙板,豎直折疊,光從側面照過來。如果你盯的時間足夠長,兩幅圖都會在深度上翻轉,像內克爾立方體一樣;我們先忽略這點。但兩幅圖中的用墨(以及在你的視網膜上的映像)實際上卻是相同的。每幅都是一個鋸齒形井字方格,其中一些方格中有陰影。在兩幅圖中,各角的方格都是白色的,頂端和側面的方格是淺灰色的,中間的方格是深灰色的。陰影和鋸齒的組合不知為何形成了第三維空間,而且給每個方格著了色,只是以不同的方式而已。標注“1”的邊界實際上在兩幅圖中都一樣。但在左圖中,這條線看起來就像是一條區分了不同色彩的分界線——也就是介於白色條紋和灰色條紋之間的邊界;而在右圖中,這條線看起來則像是由形狀和陰影所造成的分界線——也就是一條白色條紋落入褶紋另一條陰影中所造成的邊界線。以數字“2”標注的兩條邊界線其實也是相同的邊界,只是我們對它們進行詮釋的方式剛好與上述相反:那就是左圖當中的邊線是陰影和褶紋造成的邊線,而右圖當中的邊線則是由不同色彩的條紋所造成的邊線。所有這些差異,都是由兩個圖當中以不同方向扭曲的方塊所製造出來的!
要想瞭解小小圖片中的萬千乾坤,你需要解釋區分圖片與現實世界的3條定律。每條定律都需要一位心智“專家”來進行解釋。像立體視覺一樣,這些專家的工作是為了讓我們精確地掌握現實世界的平面,但它們是依靠不同信息來運行的、它們對世界做出不同的假設,解決不同的問題。
第一個問題是視角問題:一個三維的物體如何在視網膜上被投映為二維的形狀。不幸的是,任何投映都可能來自無限多個物體,所以沒辦法只從一個映像來恢復其形狀(正如阿米斯提醒他的觀察者那樣)。“所以說,”演化似乎斷言了,“沒有什麼是十全十美的。”我們的形狀分析器在碰運氣,在給定視網膜圖像的情況下,令我們看到最有可能的世界的狀態。
一個視覺系統怎麼能根據視網膜的映像來計算出世界最有可能的狀態呢?概率理論提供了一個簡單的答案:貝葉斯定理(Bayes'theorem)也就是一種能由搜集到的證據進而計算出特定假設為真的概率的方法。貝葉斯定理說,一個假設優先於另一個假設的概率可以只需通過針對每個假設的兩個數字而求得。一個是先驗概率:在看到證據前,你對該假設的確信程度。另一個是可能性:如果該假設為真,你現在所看到的證據會出現的概率是多少。將假設1的先驗概率與假設1證據的可能性相乘,將假設2的先驗概率與假設2證據的可能性相乘,算得兩個數的比率。現在你就得到了優先第一假設的概率了。
我們的三維線性分析器又是如何使用貝葉斯定理的呢?要找出某一線段究竟是由哪一物件所產生的,它會先假設特定物件是真的出現在該場景裡,再找出最有可能產生所見線段的物體——也就是計算出每個物件產生證據的可能性;此外該物件還得在一般的狀況下最有可能出現才行——也就是事前概率夠大。正如愛因斯坦曾這樣談論上帝一樣,我們的三維線性分析器推測,這個世界是難以捉摸的,但它沒有惡意。
因此,形狀分析器一定具備了一些有關映像的概率信息(從各個角度物體如何顯現)和一些有關世界的概率信息(這個世界有著什麼樣的物體)。一些關於映像的概率確實是非常好的。從理論上講,一分硬幣能夠投映為很細的一條線,但只有從它邊上看的時候才會這樣。如果實景中有一分錢,你從邊上看它的概率有多少呢?除非有人專門安排你和硬幣,否則概率不會太高。絕大多數視角會使這枚硬幣投映出一個橢圓形。形狀分析系統假設目前雙眼所見的只是一個一般的場景——不是與阿米斯所呈現出的風格一樣,會將物件精確安排以便讓它們呈現出特別樣式的場景——並依此來估測各種假設為真的概率。另一方面,一根火柴幾乎總是會投映出一條直線,所以如果圖像中有一條線,而其他條件相同的話,猜它是一根火柴比猜它是盤子要有把握得多。
一幅圖像中的一堆線可以進一步縮小概率,例如,一組平行或近乎平行的線不可能是巧合。世界上的非平行線幾乎不會在圖像上投映出接近平行的線來:絕大多數散落在地板上的棍條會彼此交叉,角度或大或小。但世界上平行的線,比如電線桿,幾乎總是投映出近似平行的線。所以如果一個圖像中有接近平行的線條,那麼它們反映世界中平行邊稜的可能性就比較大。還有許多其他的經驗法則告訴我們,真實世界裡的哪些形狀會投射出特定的影像標記。小T、Y、角、箭頭、魚尾紋狀、平行彎曲線是各種直邊、角、直角和對稱形狀的印記。漫畫家幾千年來一直在運用這些法則。一個機靈的形狀分析器可以運用反向思維,來推測它們在真實世界中是什麼。
不過當然進行反向可能性逆推是缺乏依據的——比方說平行的東西通常投映出近似平行的圖像,所以近似平行的圖像就暗示是平行的東西。就好像你聽到窗外有馬蹄聲,就斷言它們來自一匹斑馬,因為斑馬常常發出馬蹄聲。認為世界包含有某個實體的先驗概率——有多少匹斑馬,有多少個平行的條稜——必須考慮進來。要想使一個玩賠率的形狀分析器得以運行,這個世界最好包括許多直的、規則的、對稱的、緊密的之類的物體,這樣才好猜。真的是這樣嗎?一個浪漫主義者或許會認為,自然世界是有機的和柔性的,它的硬性邊緣是被美國陸軍工程兵用推土機推出來的。正如一位教文學的教授在他的課堂上說:“風景中的直線是人為設置的。”一個心存懷疑的學生蓋爾·詹森·桑福德(Gail Jensen Sanford)出版了一組自然中的直線,最近被《哈潑氏》雜誌轉載:
在即將碎裂的波浪上緣的線條;草原的遙遠邊界;暴雨瓢潑、冰雹肆虐、白雪覆蓋的原野中的小徑;晶體的模式;花崗石表面中的白石英線;冰柱、鐘乳石、石筍;平靜的湖面;斑馬和老虎的標誌;鴨子嘴;鷸的腿;候鳥群的角度;猛禽的俯衝;一種蕨類植物的新葉子;仙人掌的刺;生長迅速的小樹樹幹;松針;蜘蛛織的絲束;冰表面的裂紋;變質岩的層;火山的側面;風吹的高積云云束;半個月亮的邊緣。
這當中有一些有爭議,另一些對一個形狀猜測器來說弊大於利。湖的水平面或草原的地平線,還有半個月亮的邊緣不是來自世界固有的線條。但這個論點是正確的。世界的許多法則給了心智很好的、可分析的形狀。運動、張力和重力造就了直線。重力造就了直角。內聚力造就了光滑的輪廓。那些能夠移動的生命形式通常都會演化出對稱的模樣。自然選擇將它們的身體部件塑造為工具,來複製人類工程師對製造精良部件的要求。大平面收集模式時以大致相同的大小、形狀和間距:裂紋、樹葉、細礫、沙子、漣漪、針。這些世界上似乎是由能工巧匠雕鑿出來的部分不僅是形狀分析器最能夠恢復的部分,而且也是最值得恢復的部分。它們是那些充斥和塑造周圍環境的強大力量的提示符,比那些成堆的碎石屑更值得關注。
即使是最好的線條分析器,其裝備也只適合於一個卡通世界。平面並不只是由線條圈起來的,它們是由材料組成的。我們對光和色彩的感覺是一種鑒定材料的方式。我們不會去咬一個塑料蘋果,因為色澤已經提示我們,它不是由新鮮果肉組成的。
根據反射光來分析物質是光反射分析師的工作。不同種類的物質反射回不同波長、不同數量的光。為了簡明些,我會只介紹黑白兩色;彩色大致上是同樣的問題再乘3即可。不幸的是,給定數量的反射光可能來自無限多種物質和光照方式的組合。100個單位的光可能來自煤塊反射的1000支蠟燭10%的光,也可能來自雪堆反射的111根蠟燭的90%的光,因此沒有簡單的方法來根據物體反射光來推導物體的材質。光分析器一定設法解析出了照明度的因素。這又是一個不確定問題,完全等價於:我給你一個數,你告訴我哪兩個數相乘可以得到它。要想解決這個問題,只能增加新的假設條件。
照相機面臨著同樣的問題——無論雪球是在室內還是室外,如何將它表現為白色。照相機控制膠片曝光程度的儀表包含了兩個假設。第一個假設是光照的一致性:在陽光下、樹蔭中或燈泡下均是一致的。當這個假設被違背後,拍快照者會很失望。站在蔚藍天空下的阿姨,拍攝出來的效果很可能會像一團漆黑的剪影,因為照相機被它所見到的場景迷惑了:它見到的是整個被陰影給籠罩住的阿姨的臉,以及被陽光照射得明亮無比的藍天。第二個假設是景物一般來說是中度灰色的。如果你隨意拼湊一堆物體,它們的多種顏色和光亮度通常會平均化為一種中度的灰色陰影,它會反射18%的光。照相機“估計”它在看一個一般的景物,就曝了剛剛足夠量的光,使得景物中光亮度範圍的中值呈現為膠片中的中度灰。比中間範圍淡的小色塊表現為淺灰和白;較深的小色塊,表現為深灰和黑。但當假設錯誤,景物事實上並沒有平均表現為灰色時,照相機就被欺騙了。黑色絲絨上的黑貓照片呈現為中度灰,雪地上的北極熊呈現為中度灰等。熟練的攝影師會分析一個景物如何與一般景物不同,並使用各種技巧來進行彌補。一個原始但有效的方式是,帶一張標準的中度灰色卡(它能準確地反射18%的光),將它挨近物體,將對光儀表對準這張卡片。照相機對真實世界的假設就這樣得到了滿足,它對於周圍照明度水平的估計(從卡片反射的光再除以18%即可得到)也確定會是正確的。
埃德溫·蘭德(Edwin Land)是偏光過濾器和寶麗萊·蘭德易拍得相機的發明人,他也遭到了這個問題的挑戰,這個問題在彩色攝影中格外令人頭疼。燈泡的光是橘黃色的;螢光燈的光是橄欖色的;太陽光是黃色的;天空的光是藍色的。我們的大腦設法解析出了照明色彩的因子,就像它解析出照明強度因子一樣,在所有這些光下,都能正確地辨別物體的顏色。而照相機不行。除非它們發出自己閃光燈的白光,否則它們在表現室內景物時呈現一種厚重、似乎生銹的色調,表現有陰影的景物時像呈現漿狀藍色等。一個見多識廣的攝影師會購買特殊的膠卷或是在鏡頭上加一個濾光鏡做光補償,優秀的實驗室技術人員能夠在沖印照片時修正顏色,但易拍得相機顯然做不到這點。因此蘭德產生一個基於實際應用的需要,就是如何去掉照明的強度和色彩,我們稱之為色彩恆常性問題。
不過蘭德還是一個自學成才的、卓越的知覺科學家,他對大腦是如何解決這個問題心懷好奇。他建立了一個色彩知覺實驗室並提出了一個充滿智慧的色彩恆常性理論。他的觀點被稱為視網膜層次理論,為知覺者提出了幾個假設。第一個假設是地球的照明系統是波長的豐富混合。這一法則的例外情況是鈉汽燈,即停車場裡設置的節能燈。它發出很窄的波長範圍,我們的知覺系統無法解析出因子來,因此汽車和臉都被染上了一抹令人感覺陰森森的黃色。第二個假設是視域中亮度和色彩的逐漸變化很可能源自於景物被照亮的方式,而猝然變換則很可能是由於到了邊界,即一個物體的終結和另一個物體的開始。為了讓事情變得簡單些,蘭德對人們和他的模型在由二維矩形塊組成的人造世界中進行了測試,他稱那個世界為蒙德裡安,以紀念荷蘭著名畫家。在一個光從側面照過來的蒙德裡安世界裡,一邊的一塊黃色小塊反射的光會與另一邊一個相同黃色小塊反射的光很不相同。但人們把它們都看作是黃色的,而視網膜層次模型去除了邊到邊之間光的梯度,所以也同樣把它們看作是黃色的。
視網膜層次理論是個很好的開端,不過實踐證明,它過於簡單了。一個問題是將世界設定為一個蒙德裡安式的大平面的這個假設本身。回到圖4-15中埃德爾森的圖畫,那就是鋸齒形的蒙德裡安平面。視網膜層次模型會處理所有鮮明邊界之類的東西,將左圖中邊緣1闡釋為類似右圖中的邊緣1。但對你來說,左邊的看上去像不同顏色的兩條之間的分界,右邊的則像同一根條被折疊,而一部分在陰影中。這種差異出於你對三維形狀的解釋。你的形狀分析器將蒙德裡安平面彎成了分隔房間的屏風,但視網膜層次模型還是把它們看作同樣的舊棋盤。很顯然,它缺失了什麼東西。
缺失的東西就是陰影部分傾斜的效果,也就是將某一個實際場景變成一個影像的第三條法則。正對光源的平面會反射回許多光,因為光正照在平面上就彈了回去。與光源角度幾乎平行的平面反射的光要少得多,因為絕大多數光擦過平面繼續它的軌跡。如果你的位置離光源比較近,當平面正對你時,你的眼睛能捕捉到更多的光(相比於平面幾乎在你的側面時)。你會看到用手電筒直照一張灰紙片與側著照這張紙片之間的差異。
我們的陰影分析器又是如何反向運用這條法則,根據平面反射光的數量來計算平面的傾斜度的呢?結果絕不僅僅是估算平板的傾斜度。許多物體,如立方體和寶石都是由傾斜平面組成的,所以恢復其斜度是一種確定其形狀的方式。事實上,任何形狀都可以被認為是由數百萬個小平面組成的雕刻物。即使當平面是光滑彎曲的,可以理解為每個“小面”都縮成了點,陰影法則同樣適用於離開每個點的光。如果這條定律可以被反向運用,我們的陰影分析器就可以通過記錄每點切面的傾斜度,而理解平面的形狀了。
不幸的是,一小塊反射的給定數量的光可能來自正對光的深暗平面,也可能來自光源角度很小的明亮平面。所以,如果不做額外的假設,是沒有簡便方法來恢復光從平面反射的角度的。
第一個假設是平面的光亮度是一致的:假設世界是由石膏做的。當平面顏料塗抹不均勻時,這條假設就違背了,我們的陰影分析器也就被愚弄了。情況就是如此。繪畫和攝影照片是最明顯的例子。一個不太典型的例子是動物偽裝中的反隱蔽。許多動物獸皮的光亮度從背部到肚皮是逐漸變化的,這樣就抵消了光照在它們身上產生三維立體形狀上的效果。這使得動物看起來變得扁平化,令捕食者腦中做出假設、根據陰影分析形狀的設備更加難以檢測到目標物。化妝也是一個例子。稍諳化妝之道,塗抹皮膚的化妝品就會令觀察者感覺看到形神俱佳的理想形狀。鼻子兩側的深紅色使它看上去似乎與光呈現更淺的角度,這令鼻子看起來顯得更窄。上嘴唇上的白粉底起到相反的作用:嘴唇看起來更加豐滿,像是以更好看的撅嘴形狀阻截了迎面而來的光。
這些必須從光影現象來推斷物體形狀的分析系統,還必須對世界做出其他的假設才行。世界上的平面由數千種材料組成,光以非常不同的方式從它們傾斜的平面彈回來。褪光平面像粉筆或無光紙一樣遵循簡單的法則,大腦的陰影分析器往往推測世界就是褪了光的。而有古木光澤的、毛絨的、有凹陷的以及有刺條的表面則隨著光產生其他更奇怪的效果,它們能夠愚弄眼睛。
一個著名的例子是滿月。它看上去像個扁平的盤子,不過,當然它是個球體。我們毫無障礙地可以根據陰影部分看到其他的球體,比如乒乓球,任何不錯的藝術家也都能用炭筆畫一個球。月亮的問題在於,它上面密密麻麻佈滿了各種大小的環形火山口,絕大多數小得從地球上看都看不到,它們組合在一起形成了平面,其效果與我們陰影分析器中想當然的理想褪光平面大不相同。滿月的中心正對著觀察者,所以它應該是最亮的,不過它有些坑窪和裂縫,其裂壁是斜對著地球觀察者的視角的,這使得月球中心顯得更暗。月亮周圍邊緣附近的平面與視線斜掠而過,應當顯得更暗,但其峽谷壁呈現的角度剛好正對著觀察點並反射回很多光,這使得周邊顯得更亮了。對於整個月亮來說,平面的角度和環形山側面的角度相互抵消了。所有的部分都反射回了相同數量的光,所以眼睛就把它看作是一個盤子。
如果我們不依賴這其中任何的分析器,我們將會啃樹皮並跌落懸崖。每個分析器都做出假設,但這些假設往往與其他分析器相衝突。角度、形狀、材質、光照——它們都聚攏到一起,但我們設法把它們整理清楚,並看到一個形狀,具有一種顏色,呈現一個角度,使用一種光照。訣竅是什麼?
埃德爾森與心理學家阿歷克斯·彭特蘭德(Alex Pentland)在一個比喻中使用了他的鋸齒形幻象。你是一個設計師,必須要建一個看上去就像圖4-15中右圖那樣的舞台佈置。你去了一家作坊,那裡的專業人員為戲劇舞台演出搭建場景。一個是燈光設計師,另一個是畫師,第三個是金屬板工人。你給他們看了圖,請他們搭建一個像圖一樣的場景。實際上,他們需要做視覺系統所做的工作:給定一幅圖像,弄明白東西的佈置和能夠呈現出這樣效果的光照。
專業人員有許多種方法能夠滿足你的要求。每種幾乎都能夠單獨奏效。畫師只需在一個扁平金屬板上畫出平行四邊形的佈置,然後請燈光設計師用一束探照燈照亮即可(見圖4-16)。

圖4-16 畫師的方法
燈光設計師可以取一張空白板,然後安裝9盞設置好的聚光燈,每盞都有特殊的燈罩和濾光器,目的就是為了在白板上投映出9個平行四邊形,圖4-17顯示了其中6盞聚光燈。
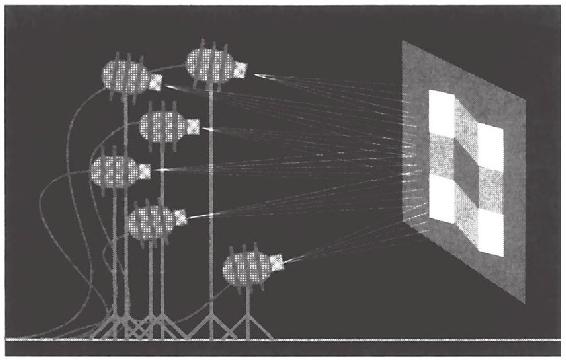
圖4-17 燈光師的方法
金屬板工人可以將一些金屬弄彎成特殊的形狀,當它被照亮並從合適的角度看時,就呈現出圖4-18的圖像。
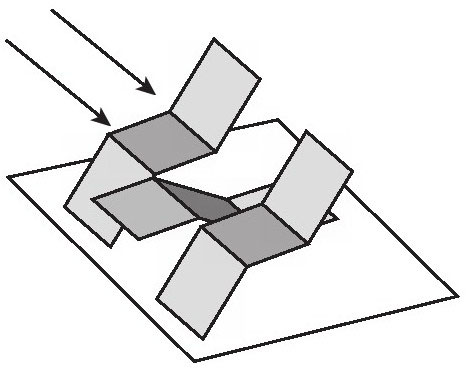
圖4-18 金屬板工人的方法
最後,這個形狀還可以由眾專業人員合作而得之。畫師在一個方塊金屬板的中央畫出一條,金屬板工人將它彎成鋸齒形,燈光設計師用一束光來照亮這件作品。當然,這就是一個人在解釋這幅圖時所做的。
我們的大腦就像這個比喻中的舞台設計師一樣,同樣面臨著由於豐富性帶來的困擾。一旦我們允許一個心智“專家”假設顏料塗抹的平面,它就能夠將圖像中的所有東西都解釋為繪畫:世界看起來將會是一幅錯視畫的傑作。類似地,大腦裡的照明專家會告訴我們,世界是一部電影。因為這些解釋不大令人滿意,所以心智應當設法阻止專家們那樣做。一種方式是,強迫它們堅持它們的假設,是什麼就呈現什麼(顏色和照明是均勻的,形狀是規則的和平行的),但這樣太極端了。世界不總是晴朗日子裡的一堆方塊;有些時候它確實有複雜的顏色和照明,而且我們能看到。我們不想讓專家們否認,世界可以是複雜的。我們想讓它們呈現出世界中原本擁有的那麼多複雜性,不多也不少。現在的問題是如何讓它們去做。
回到那個比喻。假設舞台設計部門預算有限。專家們的服務是要收取費用的,他們用一張費用清單反映出一項要求的難易和尋常程度。簡單尋常的工作是便宜的;複雜、特殊的操作是昂貴的。


我們還需要一個專家:管理人員。他來決定如何外包這項工作。

4個解決方案的價格會不同。估算如下:
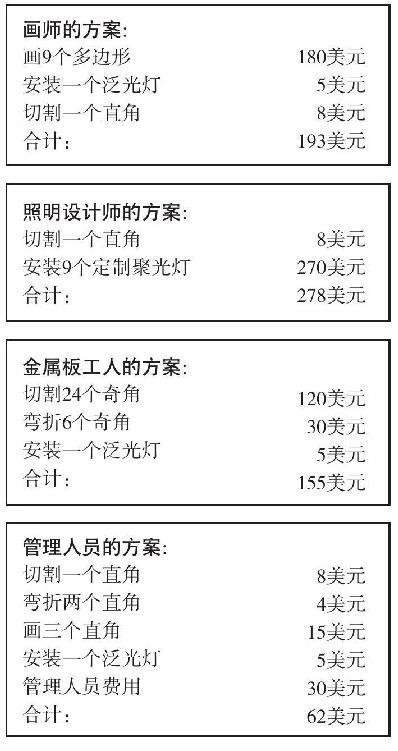
管理人員的方案是最便宜的,因為它優化地使用了每一位專家,節省的部分彌補了管理人員的費用。這裡的寓意在於,專家們必須要彼此協調合作,不一定需要一個小人來協調,但要通過安排最小化成本,盡可能地便宜和簡單。在這個比喻中,簡單工作容易做;在視覺系統中,較簡單的描述對應於世界中較可能的安排。
埃德爾森和彭特蘭德將這個比喻付諸實施,他們設計了一個計算機視覺仿真程序,它在很大程度上像我們那樣解釋塗漆的多邊形景物。首先,一個形狀分析器(一個軟件版的金屬板工人)努力還原一個最規則的形狀,並複製這幅圖(見圖4-19)。要得到圖4-19左圖中的簡單形狀,人們把它看作是一張折疊的板,就像一本側面拿著的書一樣。
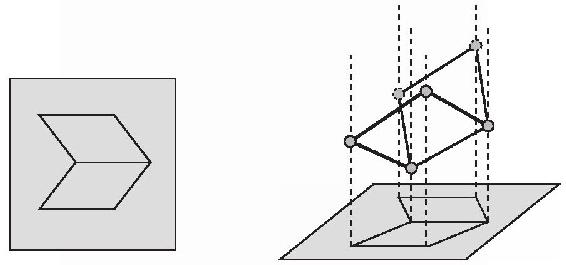
圖4-19
形狀專家試圖組裝一個輸入形狀的三維模型,如圖4-19右圖所示。開始時,他所知道的只是需要將模型的角和邊與圖像中的點和線連在一起;他不知道它們之間距離的深度。模型的外端是桿上滑動的小珠(像投映光線一樣),小珠之間的線段是具有無限彈性的帶子。專家滑動小珠,直到它到達符合圖4-19中右圖下方需要的形狀。每個構成形狀的多邊形應當盡可能地規則;也就是說,多邊形的角度不應當有太大差異。例如,如果多邊形有四條邊,專家將努力做一個正方形。多邊形應盡量在一個二維平面上,就好像多邊形被填塞了一個很難折彎的塑料板。而且多邊形應當盡量地緊密,而不是沿著視線一直伸長,就好像塑料板很難拉伸一樣。
當形狀專家完成工作後,他交給照明專家的是一個組裝嚴絲合縫的白板。照明專家知道,反射光如何依賴於照明、平面的光亮度和平面角度的指導法則。照明專家可以移動一個遠處的光源從各個方向照亮這個模型。最優的方向就是,使得每對板盡可能地交匯於一個側面的視角,就像圖4-19中左圖的那樣,使得操作者盡可能少地塗抹灰色顏料,即可完成工作。
最後,反射專家——畫師——得到了模型。他是最後一個要依靠的專家,他的任務是負責處理剩餘的任何圖像與模型間的差異之處。他完成任務的方法是,通過在各個平面上塗抹不同陰影的顏料。
這個程序有用嗎?埃德爾森和彭特蘭德給了它一張扇折讓它來研究。程序顯示了它對物體形狀的猜測(圖4-20第一列),它對光源方向的猜測(圖4-20第二列),它對陰影位置的猜測(圖4-20第三列)和它對物體如何被塗色的猜測(圖4-20第四列)。程序最初的猜測顯示在圖4-20最上面一行。
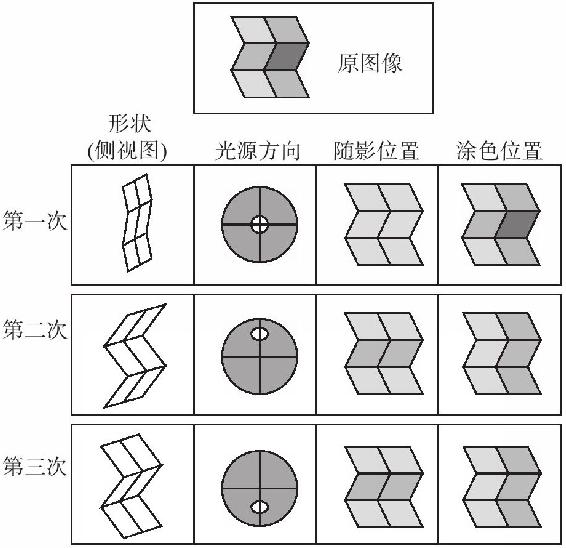
圖4-20
程序最初估計物體是扁平的,像一幅二維繪畫一樣平置在桌子上,如圖4-20第一列頂端所示。很難向你描述這個,因為你的大腦堅持認為看到了一個鋸齒形被折疊為具有不同深度的形狀。概略圖試著顯示一些平置在書頁上的線條。程序推測光源是從眼睛的方向正對而來(圖4-20第二列的頂端)。有了這樣平的光照,就沒有陰影了(圖4-20第三列頂端)。反射專家承擔起所有的責任來複製圖像,把它畫了上去。程序認為它在看一幅畫。
一旦程序有機會調整它的猜測,它調整後的解釋如圖4-20中間那行所示。形狀專家找到了最規則的三維形狀(如圖4-20左列的側視圖):方板以合適的角度連接在一起。照明專家發現,從上面照光,這使得影子的效果看起來有些像圖像一樣。最後,反射專家塗抹些顏料對模型做些潤色。圖4-20中的第四列——鋸齒形三維形狀、從上面照光,影子在中間,亮條挨著暗條——對應著人們如何解釋最初的圖像。
程序還做了任何像人所做的一樣的嗎?還記得扇折的深度像一個內克爾立方體一樣閃變吧。外折變成內折,內折變成外折。程序以一種方式也可以看到這種閃變;閃變的解釋顯示在最下面一行。程序對兩種程序分配了相同的成本,隨機到達了其中一種。當人們看到一個三維形狀閃變時,他們通常也會看到光源的方向在閃變:頂端向外折,光來自上方;底端向外折,光來自下方。程序也是一樣的。不像一個人,程序並不在兩種解釋之間閃變,但如果埃德爾森和彭特蘭德使專家們在一個限制性網絡內相互傳遞它們的猜測(圖2-8內克爾立方體網絡或是立體視覺模型),而不是像放在一條工廠生產線上一樣地單方向傳遞下來的話,那麼這個程序或許也能表現出這樣的行為。
這個作坊的比喻闡明了這個觀點:心智是一個模塊集合,器官系統或是一個專家社會。專家是需要的,因為專業技能是需要的:心智的問題技術性很強,也太專業化,無法由一個“萬金油”來解決。而且一名專家所需的絕大多數信息與另一名專家所需的無甚關聯,而是只與他的工作相關。但一名專家獨自工作,他會考慮太多的解決方法或是固執地探究一個不可能的方法;在一定程度上,專家們必須協商。許多專家在試圖解釋一個世界,這個世界與他們的辛苦工作是不相互作用的,既不提供容易的解決方法,也不會製造迷惑偏離軌跡。所以協調管理的主旨在於,將專家們約束到一個預算之內,使不可能的猜測更為昂貴。這就會迫使他們合作做出對世界狀態最為可能的綜合猜測。
從二維到三維
一旦專家們完成了他們的工作,他們會在心智的公告板上貼出什麼樣的信息,以便大腦的其他部位能夠對這些信息進行存取呢?如果我們能夠設法從大腦其餘部分的視角顯示視域,就像假想照相機一樣,那會是什麼樣子呢?這個問題聽起來好像一個愚蠢的腦中小人的謬論,但其實不是。它是關於大腦的一個數據表徵中的信息和信息所採取的形式。的確,認真考慮這個問題會讓我們對心智眼睛的幼稚直覺全新審視。
立體視覺、動作位移、外形輪廓和陰影方面的專家都努力工作來恢復第三維度。利用他們的勞動果實來構建對世界的三維立體表徵,這很自然。我們可以從視網膜上所出現足以描述場景的馬賽克信息,來推得有關心智產生這種信息方式的蛛絲馬跡。圖片變成了比例模型。一個三維模型對應著我們對世界的最終理解。當一個孩子隱隱出現在我們面前時,然後逐漸縮小不見,我們知道,我們不是在奇妙仙境,吃一粒藥丸可以讓你長大,吃一粒可以讓你縮小。我們不像是諺語中的鴕鳥(諺語的真實性有待求證),會以為物體在我們不看或我們被掩蓋時就會消失。我們處理現實,因為我們的思想和行動是受一個龐大、穩定而堅實的世界的知識所指導的。或許視覺以一個比例模型的形式給予我們這樣的知識。
比例模型理論本身並沒有什麼可以質疑的地方。許多計算機輔助設計程序都使用固體物體的軟件模型,CAT掃瞄和MRI儀器使用了複雜的運算來加工信息。一個描述了特定物件的三維空間模型,其內可能擁有一大串為數好幾百萬的坐標值,而每一組坐標值所描述的,是構成物體的單一迷你方塊的位置,這稱為方塊元素或“體素”來對應於製作圖片的圖像元素或“像素”。每組三重坐標都對應一對信息,比如在身體某個位置的組織密度。當然,如果大腦中儲存了體素,它們就不必被安置在大腦中的三維立方體裡,任何更多的體素都被放置在電腦中的三維立方體裡。重要的是,每個體素都有一組穩定的神經元專供使用,這樣激活模式就能夠記錄體素的內容了。
不過,現在是提防小幽靈的時候了。一些軟件守護程序、查詢運算或神經網絡從比例模型中獲得信息,這種觀點沒有問題,只要我們清楚它是直接獲得信息的:輸入體素的坐標,輸出體素的內容。只是不要認為查詢運算會看到比例模型,那裡漆黑一片,查詢者沒有晶體、視網膜,甚至沒有一個觀察點;他在任何地方、也在每個地方。沒有投映、沒有視角、沒有視域也沒有嚙合。的確,比例模型的存在意義就是為了減少這些惱人的東西。如果你設想一個幽靈,想像在黑暗中一個城市的一個屋子那麼大的比例模型。你可以進出其中,從任何方向來到一個大樓,觸摸它的外部或將指頭伸進窗戶或門裡探究其中。當你抓住一個大樓,它的側面總是平行的,無論它伸臂可及還是離得更近。或是想想感覺你手裡有一個小玩具的形狀,或是嘴裡的一塊糖果。
但視覺——即使是大腦千辛萬苦才實現的,三維的沒有錯覺的視覺——卻一點兒都不像這樣。至多,我們有一個對週遭世界穩定結構的抽像理解;在我們眼睛睜開時,填充我們感知的、旋即而輝煌的色彩感和形式感是完全不同的。
第一,視覺不是環幕電影院。我們能形象體驗到的只是我們眼前的景物;視域周圍以外的世界和腦袋後面的世界只是以一種模糊的印象、幾乎是用思想推理的方式為我們所知的。我知道我身後有一個書架,面前有一個窗戶,但我只看到了窗戶,卻沒看到書架。更糟糕的是,眼睛一秒鐘從一點掃過另一點好幾次,中央凹瞄準器之外所看到的事物其實非常粗糙。將手舉到視線前幾厘米處,你根本無法數指頭。我不只是在溫習眼球構造的解剖學。人們可以想像,大腦根據每一瞥得到的快照來拼一個拼貼畫,就像一個全景相機曝光一幀膠卷一樣,攝下精確的一部分景物,曝光到鄰接的一段膠卷,再繼續下去,最後得到一幅無縫的寬角度照片。但大腦不是一台全景相機。實驗室研究表明,當人們移動眼睛或頭部時,他們立刻就失去了他們剛看到的圖像細節。
第二,我們沒有X光的視覺。我們看表面而不是看體積。如果你看到我將一個物體放進一個盒子裡或放到一棵樹後面,你知道它在哪兒,但卻看不到它,也說不出它的細節。同樣,這也不只是為了提醒你說你不是超人。我們凡人本可以裝備上一個照相機般的記憶,將之前看到的有關信息與現在看到的粘貼在一起來更新三維模型。但我們沒有這樣的裝備。看不到有關具體的視覺細節就不在大腦裡了。
第三,我們看物體時有視角。當你站在兩根鐵軌之間時,它們似乎交匯於地平線。當然你知道它們沒有真的交匯,如果交匯的話,火車就會脫軌。但你不可能看不到它們交匯,儘管你的深度感覺提供了足夠的信息使你的大腦能夠抵消這個效果。我們還知道,移動的東西會放大和收縮。在一個真正的比例模型中,這些都不會發生。為了準確,視覺系統將視角減少到一定程度。除藝術家之外,其他人很難將桌子的近角投映為銳角,遠角投映為鈍角;現實中它們看起來都是直角。但鐵軌顯示視角並沒有完全消除。
第四,在嚴格的幾何意義上,我們看到的是二維,而不是三維。數學家亨利·龐加萊(Henri Poincaré)得出一種確定某個物體維數的簡單方法。找一個東西能夠將該物體分為兩部分,然後數數這個分隔東西的維數再加一。一個點不能被分割,所以它是零維的。一條線有一維,因為它能被一個點分割。一個面有二維,因為它可以被一條線分開,儘管它不能被點分開。一個球有三維,因為任何少於二維的刀片都無法劈開它;一個小球或一根針不能分開它。那麼視域呢?它可以被一條線分開。例如,地平線將視域一分為二。當我們站在一條繃緊的電纜前面時,我們所看到每件東西要麼在這一邊,要麼在另一邊。圓桌的周長線也分隔了視域:每個點要麼在裡面,要麼在外面。給一條線加一維度你就得到了二維。根據這條標準,視域是二維的。順便說一句,這並不意味著視域是扁平的。二維平面可以在第三維被彎曲,就像一個橡膠模具或是一個吸塑包裝一樣。
第五,我們沒有立刻看到“物體”,即那些我們來計數、分類,並冠以名詞標籤的可移動物質塊。就視覺而言,它甚至不清楚物體是什麼。當戴維·馬爾考慮如何設計一個能夠發現物體的計算機視覺系統時,他不得不問:
鼻子是一個物體嗎?腦袋算嗎?如果它接到身體上還算嗎?一個騎在馬背上的人呢?這些問題說明,劃分影像區域是一個多麼困難的問題,其困難程度幾乎與哲學問題不相上下。其實這些問題沒有答案——所有這些東西可以是一個物體,如果你願意那樣想它們的話,或者它們也可以是一個更大物體的一部分。
一滴強力膠可以將兩個物體變成一個,但視覺系統沒辦法知道這一點。
然而,我們對它們之間的表面和邊界卻有著非常明顯的感覺。心理學中最著名的錯覺來自大腦永無止境地竭力將視域雕刻為平面,並決定哪一個在另一個的前面。一個例子是魯賓的人臉-花瓶(Rubin face-vase,見圖4-21),圖像在一個高腳杯和一對兩人面對面的輪廓之間閃變。人臉與花瓶不能被同時看到(即使有人想像兩人用他們的鼻子舉起高腳杯也不行),無論哪個形狀主導“擁有”了區分界線,都將另一片限製作為模糊的背景。

圖4-21
另一個例子是卡尼莎三角形(Kanisza triangle,見圖4-22),本來什麼都沒有,卻組成了一個像真的,彷彿用墨水銘刻在其中的形狀。

圖4-22
人臉、花瓶和三角形都是熟悉的物體,但錯覺並不依賴於它們的熟悉性;毫無意義的斑塊同樣具有震撼力(見圖4-23)。
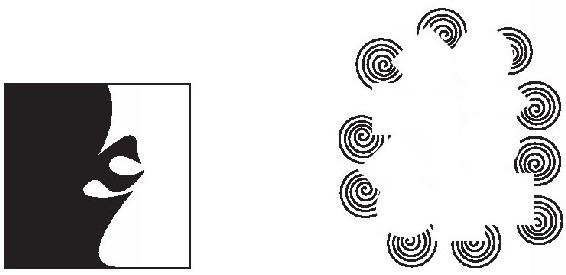
圖4-23
我們並不是主動地感知到平面,而是被我們視網膜中湧現出的信息所驅使的;與流行的觀點恰恰相反,我們並不是看到我們所希望看到的。
那麼視覺的產品是什麼呢?馬爾稱之為二維半草圖;其他人叫它能看到的平面表徵。深度被降級為半維,因為它沒有界定所帶視覺信息的介質(不像左右和高低維度),而只是那個介質中所攜帶的一條信息。想想用幾百個滑栓組成的玩具,你將這些滑扣按到一個三維表面上(比如說一張臉),在另一面就形成了一個栓扣輪廓組成的平面模板。這個輪廓有三維,但這三維不是相等的。從邊至邊和從上至下的位置是由特定的栓扣界定的;深度位置則是由栓扣突出多少決定的。對於任何一個深度都有許多栓扣;而對於任何栓扣則只有一個深度。
這個二維半草圖看上去有些像圖4-24。
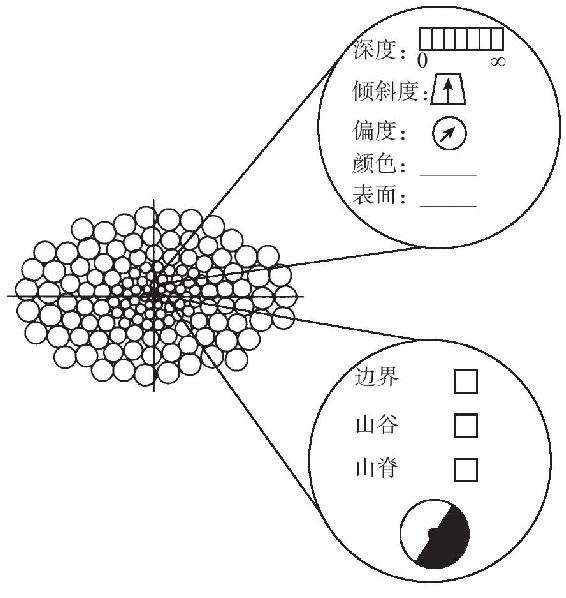
圖4-24
它是一個單元或像素的拼製圖,每個單元或像素表示從中央獨視眼觀察點的一道視線。它的寬度比高度更長,因為我們的兩隻眼睛是並排安置在我們的頭蓋骨上,而不是一隻在另一隻的上方。視域中心的單位要比外圍的更小,因為我們的解析度在中心更高。每個單元可以代表一個平面或一道邊的信息,就好像它有兩種空白表格需要填寫。一塊平面的表格中,有關於深度、傾斜度(平面向後或向前傾斜多少)、偏度(向左或向右偏斜多少)以及顏色的空格,還有一個標籤表示它被看作屬於哪塊平面。一道邊的表格中則有備選的方框,表示它是否是一個物體、溝槽或一道隆脊的邊界,還有一個表示其方向的刻度盤,也顯示(如果是物體邊界的話)哪一邊屬於“擁有”邊界的表面和哪一邊只充當背景。當然,我們大腦中並不會真正發現這種表格。這個圖形是一個描述二維半度草圖中信息種類的混合物。大腦估計會利用神經元簇和它們的活動來保留信息,這些信息會作為記錄時得到的地圖集合,被分配到不同的皮層片區。
為什麼我們會看到兩個半維度?為什麼不是大腦中的一個模型?儲存的成本和收益給出了部分答案。任何計算機使用者都知道,圖形文件會佔用大量儲存空間。大腦沒有將進來的千兆字節集聚成一個混合模型,這樣的話一旦任何東西一移動,這個模型就會失效;大腦讓世界自己來儲存一眼無法分類的信息。我們的腦袋伸直了,我們的眼睛快速轉動,一個全新的、最新式的草圖就加載下來了。至於第三維度的次級地位,這幾乎是無法避免的。不像其他兩種維度,它們能在當時激活的視桿和視錐細胞中顯示出來,深度則必須從數據中痛苦地提煉。嘗試計算深度的立體圖、輪廓、陰影和位移專家們具有能力,來傳遞有關相對於觀看者的距離、傾斜度、偏度和咬合度的信息,而不是世界的三維坐標。它們至多能做的是聚集它們的努力,給我們提供一個與二維半似曾相識的東西,其表面就呈現在我們眼前。這就要靠大腦其餘的部分來弄明白如何使用它了。
參考框架
這個二維半草圖是視覺系統巧妙設計、協調運轉設備的傑作。它只有一個問題:這個作品在交貨時是沒有用的。
二維半草圖中的信息是被列注在一個視網膜的參考框架中的,這是一個以觀看者為中心的坐標系統。如果一個特定單元說,“這兒有一個邊緣”,“這兒”的意思是視網膜上那個單元的位置——比方說,當你正對著這條線觀看的時候,這個位置指的就是你的正前方。如果你是一棵樹,在看另一棵樹,那沒問題,但只要有東西一動——你的眼睛、你的頭、你的身體、一個看到的物體——原有的信息便會悄悄地移動到陣列上的另一個位置棲息。排列中信息引導的任何大腦的部分會發現,現在信息失效了。如果你的手被引導著伸向視域中心,因為那個地方有一個蘋果,現在這隻手伸向的地方只是一片空地。如果昨天你在看你車門把手時會記起你的車的圖像,今天你所看到的車擋板將不符合這個圖像;這兩幅圖景幾乎不會重疊。你甚至無法做出簡單的判斷,比如兩條線是否是平行的。還記得交匯在一起的鐵軌吧。
這些問題令人渴望在腦海中有一個刻度模型,但那不是視覺所提供的。使用視覺信息的關鍵不在於重塑它,而在於適當地獲取它,這就要求有一個有用的參考框架或坐標系統。參考框架與位置的觀念是糾纏在一起的。你如何回答“它在哪裡”這個問題呢?通過命名一個提問者已經知道的物體——參考框架——並描述“它”相對於這個框架距離有多遠,在什麼方向。一個如“冰箱旁邊”的語言描述、一個街道地址、指南針方向、經度緯度、全球定位系統衛星坐標——這些都表示相對於一個參考框架的距離和方向。愛因斯坦構建他的相對論是憑借質疑牛頓假定的參考框架,這個參考框架在某種程度上像空中樓閣一樣,與其中任何東西都不相關聯。
用二維半草圖包裝的參考框架是視網膜上的位置。因為視網膜在不斷地旋轉,它就像描述方向時說“在停在燈這兒的米色龐提亞克旁邊與我會面”一樣沒有用處。我們需要一個在眼睛四處亂逛時,仍靜止不動的參考框架。假設有一個回路能夠將一個無形的參考框架滑過視域,就好像是配備在步槍的准心裝置裡可以在前景上來回滑動十字標記一樣。再假設從視域中淘取信息的任何機制都被鎖定在來復槍瞄準視線界定的位置(例如在瞄準中心上面兩個槽口或是左邊一個槽口)。計算機顯示器有一個有些類似的裝置——光標。讀寫信息的命令相對於一個特定點來這樣做,這個點可以在屏幕上被任意定位,當屏幕上的資料向上翻時,光標也隨之移動,好與它原來所指向的圖畫或是文字資料保持在一起的狀態。為了讓大腦使用二維半草圖的內容,它必須採用一個類似的機制,確切地說,是一些機制。
越過二維半草圖移動的最簡單參考框架是根植在大腦裡的一個。感謝光學定律,當眼睛向右移動時,蘋果的圖像迅速溜到了左邊。但是,讓我們假想大腦將有關神經系統的命令傳送給眼球肌肉的時候,同時也送了一份命令的副本給我們的視域,好讓後者能夠使用這些信息,將十字標記往相反的方向移動,與眼球移動相同的距離,如此一來,十字標記便能夠持續停留在蘋果上,而那些依靠這個標記由視域獲得信息的心智過程也能持續得到正確的資料。這個過程可以自然地持續下去,就好像什麼事也沒發生過,儘管視域的內容已經滑轉過來了。
這有一個對這種抄送的簡單演示。移動你的眼睛,而世界沒有移動。現在閉上一隻眼睛,用你的指頭輕觸另一隻眼睛;世界開始跳動。在這兩種情況下,眼睛都在移動,視網膜圖像都在移動,但只有當眼睛被指頭輕推時,你才看到了移動。當你決定看某個地方而移動眼睛時,給眼睛肌肉的指令被抄送至一個將參考框架與滑動圖像一起移動的裝置,這樣就抵消了你主觀上對移動的感覺。但當你用手指推眼睛移動時,框架轉換裝置被繞過了,框架沒有被轉換,於是你把劇烈跳動的圖像解釋為來自一個劇烈跳動的世界。
或許還有補償頭部和身體移動的參考框架。它們為視域中每一小塊平面,賦予了一個相對於房間或地面的固定位置;這個位置在身體移動時仍保持不變。這些框架轉換或許是由對頸部或身體肌肉的指令拷貝所驅動的,它們也可能是由跟蹤視域內容滑動的回路所驅動的。
另一個便利的覆蓋是標出世界上大小相等區域的不規則心理格子。一個我們雙腳附近的格子標記會覆蓋一大片視域;一個地平線附近的格子標記會覆蓋一小片視域,但如果沿著地面測量的話,其實這兩片視域具有相同的範圍。因為二維半草圖的每一點都包含了深度信息,格子標記對大腦來說比較容易計算。這個世界校準的參考框架使我們能夠判斷我們皮膚之外的事物的真實角度和範圍。知覺心理學家吉布森(J.J.Gibson)認為,我們在視網膜映像上的確附加有這種真實世界的度量感覺,我們能夠在心理上在使用它與不使用它之間迅速跳轉。站在兩根鐵軌之間,我們能夠推測到一個會看到鐵軌交匯的心理框架,或是另一個將之看作平行的框架。這兩種態度被吉布森稱為“視域”和“視界”,它們源於利用視網膜框架或世界校準的框架來獲得相同的信息。
而另一個無形框架是重力的方向。心智的鉛錘來自內耳的前庭系統,它是一個包括3個半圓形的、彼此定位角度適中的細管。如果任何人懷疑自然選擇利用了人類後來才重新發現的設計原則,讓他去觀察刻畫頭蓋骨的笛卡兒XYZ坐標軸吧!隨著頭的下垂、擺動和搖晃,管腔中的液體四處攪動,觸發了記錄移動的神經信號。大量的小顆粒貼到了其他膜上,它們記錄了線性移動和重力方向。這些符號可以被用來旋轉心理瞄準器,這樣它們就總是正確地指向“上方”。這就是為什麼世界似乎並沒有傾斜,儘管人們的頭幾乎沒有鉛錘般筆直。眼睛在頭上向順時針或逆時針方向偏斜,但偏斜度只能抵消頭的小幅偏斜而已。奇怪的是,我們的大腦並沒有對重力做出多少補償。如果補償是完全的,當我們側躺下甚至頭朝下倒立時,世界看起來仍是正常的樣子。當然,事實並非如此。你側躺時,幾乎無法看電視,除非你用手把頭支起來;你也不可能看書,除非你把書斜著拿。或許因為我們是生活在陸地上的生物,我們在大多數情況下是用重力信號來使自己的身體保持直立,而不是把重力信號當作視覺輸入不均衡時的補償。
視網膜框架與內耳框架的協調以一種令人驚訝的方式影響了我們的生活:它導致移動眩暈。在通常情況下,你移動時,兩個信號同步作用:視域中傳來質地和色彩的衝擊,內耳中傳來的關於重力和慣性的信息。但如果你在一個像汽車、輪船或轎子一樣的代步工具中移動時——這在演化意義上是前所未有的移動方式——內耳會說,“你在移動”,但牆壁和地面會說,“你靜止不動”。移動眩暈就是因為這種不匹配引發的,常規的處理方式會使你減輕這種感覺:不看書;看窗外;注視地平線。
許多宇航員會有長期太空眩暈,因為太空中沒有重力信號,這時重力和視覺極度不匹配。太空眩暈用加恩(Garn)來度量,這個單位是以來自猶他州的共和黨參議員傑克·加恩(Jake Garn)來命名的,他利用他在NASA經費分組委員會的職位,爭取到超級公款旅遊——一次太空之旅。年輕的宇航員加恩創造了歷史,成為古往今來無出其右的“嘔吐狀元”。更糟糕的是,航天器的內部並沒有給宇航員提供一個世界校準的參考框架。因為設計者認為,在沒有重力的情況下,“地板”“天花板”和“牆壁”都是沒有意義的,因此他們還會將儀器放在所有6個平面上。不幸的是,宇航員帶著他們的陸生大腦,因而就徹底迷惑了,除非他們停下來對自己說,“我將假裝那個方向是‘上’,那個方向是‘前’”等。這會起一定作用,但如果他們向窗外看,看到他們上面的陸地,或是瞥見一個同事正大頭衝下在漂浮,一陣噁心就會猛衝上來。太空眩暈對於NASA來說是一個值得關注的問題,不僅因為這導致了成本高昂的飛行期間工作效率的降低;你完全可以想像零重力下嘔吐的複雜情況。它還會影響虛擬現實的萌芽技術,這種技術讓人們戴上一個寬視野頭盔,向人們展示一個呼嘯而過的合成世界。《新聞週刊》評價道:“這是自過山車以來最讓人反胃的發明了。我們更喜歡百威啤酒。”
為什麼在地球上或在太空中,視覺與重力或慣性的不匹配會導致所有生物噁心呢?上下倒置是怎麼影響腸子的呢?心理學家米歇爾·特雷斯曼(Michel Treisman)得出了一個很有說服力、但未被驗證的解釋。動物嘔吐是為了在吃了的毒素還沒對它們造成進一步損害之前將毒素驅除。許多自然形成的毒素作用於神經系統。這就提出了英格麗·褒曼(Ingrid Bergman)在《美人計》(Notorious)中面臨的問題:你怎麼知道你什麼時候中毒的?你的判斷力會被損害,但這會影響你關於你的判斷力是否已被損害的判斷!更一般地說,一個功能失常的監測器怎麼能區分是大腦功能失常,還是大腦準確記錄了一次不尋常的情況?古老的保險槓貼紙上寫道:世界正經歷著技術困境。不要調整你的思想。重力,當然是世界上最穩定的和可預測的特徵了。如果大腦的兩部分對它有不同意見,那麼要麼是其中一部分或兩部分都功能失常,要麼是它們得到的信號被延誤或歪曲了。規則將是:如果你認為重力運轉不正常,那麼你已經中毒了;現在就驅除其餘的毒素吧。
心理的上-下軸對我們感覺形狀的功能發揮著有力的組織作用。看一下圖4-25是什麼?
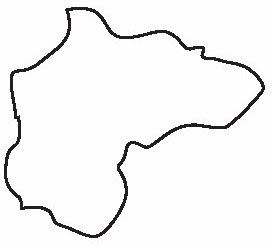
圖4-25
很少有人能認出它是一個旋轉了90度的非洲輪廓圖,即使他們把頭逆時針偏過來也很難看出來。一個形狀的心理表徵——我們的心智如何“描述”它——不僅僅反映了它的歐式幾何,也就是當形狀旋轉時,它的輪廓並不變化,它還反映了相對於我們上-下參考框架的幾何。我們的心智認為,非洲是一個“頂上”有些扁平,“底端”有些偏瘦的東西。頂上和底端如果改變的話,它就不再是非洲了,即使不變動地圖上任何一寸海岸線的形狀,我們還是認不出它就是非洲。
心理學家埃爾文·羅克(Irvin Rock)找到了許多其他的例子,包括圖4-26所示的這個簡單的圖形。
圖4-26
人們將這兩幅圖看作是兩個不同的形狀,一個正方形,一個菱形。但對一個幾何學者而言,它們是相同的形狀。它們是符合相同小洞口的木栓;每個角度和線段都是相同的。唯一的差別是,它們如何相對於觀看者的上-下參考框架而進行校準,而這個差異就足以使它們在英語語言中獲得不同的詞彙。正方形頂部是平的,菱形頂部是尖的;我們沒法迴避“頂部”的問題,甚至很難看出這個菱形是由幾個直角組成的。
最後,物體自身可以得出參考框架(見圖4-27)。

圖4-27
圖4-27頂端右邊的圖形在看上去像一個正方形和看上去像一個菱形之間跳轉,這依賴於你在心理上是將它與左邊3個圖形歸為一組,還是與下面8個圖形歸為一組。與圖形排列相校準的想像直線成為笛卡兒參考框架——一個框架與視網膜上-下框架校準,另一個呈對角線傾斜——一個圖形的心理描述是在一個框架中還是在另一個框架中,會導致它看起來有所不同。
如果你仍然對所有這些覆蓋整個視域的、無色無味的參考框架心存懷疑,我給你一個心理學家弗雷德·阿滕尼夫(Fred Attneave)做過的巧妙和簡單的展示。圖4-28中左邊的三角形怎麼了?

圖4-28
如果你盯它們的時間足夠長,它們會從一種樣子迅速轉變成另一種樣子。它們沒有移動,也沒有在深度上翻轉,但有些東西變了。人們將這種變化稱之為“它們指向哪個方向”。躍上紙面的不是三角形本身,而是覆蓋這些三角形的一個心理參考框架。這個框架不是來自視網膜、頭、身體、房間、書頁或重力,而是來自這些三角形的一個對稱軸。這些三角形有3個這樣的對稱軸,它們依次發揮主導作用。每條軸都有一個等價於南北極的東西,它賦予了人們對三角形指向的感覺。這些三角形一同跳轉,好像是在一個合唱團裡一樣;大腦希望它的參考框架會包含整個周邊的圖形。圖4-28右邊的三角形變化更為急劇,它們在6種印象之間急速變換。它們可以被解釋為平躺在書面上的鈍角三角形,或是在深度上直立的直角三角形,每種情況都有一個參考框架,它可以用3種形式來放置。
形狀是識別物體的重要線索
物體將參考框架引向自己的能力有助於解決視覺中的一個重大問題,也就是我們由基本的視網膜成像向上探索到抽像思考的過程裡,必須面對的下一個問題——人們如何識別形狀。一個普通成年人知道大約一萬個物品的名字,其中絕大多數是憑借形狀來區分的。甚至一個6歲的小孩也能叫出幾千個物品的名字,學習效率為每幾個小時就學會一個(從0~6歲)。當然,物體可以用許多線索來識別。有些可以用聲音和味道來識別。而另一些,比如籃子裡的襯衫,則只能根據它們的顏色和質地來識別。但大多數物體能夠根據它們的形狀來識別。我們在識別物體形狀時,我們就像是一個純粹的幾何學家,研究空間中物質的分佈並找到記憶中最接近的匹配。心理幾何學家一定足夠精明,因為一個3歲的孩子就能夠仔細檢查一盒動物餅乾或是一堆鮮艷的塑料片,並根據它們的外形輪廓滔滔不絕地念叨出這些奇異動物的名稱。
圖1-6說明了為什麼這是一個難度很高的問題。當物體或觀看者移動時,二維半草圖中的輪廓就變化了。如果你對形狀的記憶——比如說箱子——是你最初看時的那個二維半草圖的拷貝,那麼移動後的版本就不再匹配了。你對箱子的記憶是“一個長方形的厚板和一個處於12點鐘方向的水平把手”,但你現在看的把手不是水平的,也不在12點鐘方向。你會目光茫然,不知道它是什麼(見圖4-29)。
圖4-29
但假定你的記憶文件沒有使用視網膜參考框架,而使用的是與物體本身校準的一個框架。你對箱子的記憶會是“一個長方形的厚板,有一個與厚板邊緣平行且在厚板頂端的把手”。“厚板頂端的”部分意味著你記著那部分相對於物體本身的位置,而不是相對於視域的位置。然後,當你看到一個不認識的物體時,你的視覺系統會自動在上面校準一個三維參考框架,就像在阿滕尼夫的正方形和三角形合唱團式排列中所做的一樣。現在當你看到的與你所記得的匹配一致時,這兩個就符合了,無論箱子的方向如何。你認出了你的箱子(見圖4-30)。
圖4-30
簡而言之,這是馬爾如何解釋形狀識別的。他的核心想法是,形狀記憶不是一個二維半草圖的拷貝,而是以一種與之有兩方面不同的格式加以儲存的。首先,坐標系統以物體為中心——而不是像在二維半草圖中一樣,以觀看者為中心。要識別一個物體,大腦要根據它的延長線和對稱軸校準一個參考框架,並測量在這個參考框架中那部分的位置和角度。只有那時,視覺和記憶才得以匹配。第二處不同是,匹配者並不是將視覺和記憶一個像素一個像素地比較,就好像將一個拼圖片放到一個縫隙中一樣。如果那樣的話,本該匹配的形狀仍舊可能匹配不上。真正的物體有凹痕和擺動,而且有著不同的風格和模式。任何兩個箱子的大小都不會完全相同,有的是圓角,有的是扁平把手或細長把手。所以要匹配的形狀表徵不應當是死板地記錄下物體表面的每一個起伏。它應當歸於較寬大的類別如“厚板”和“U形的東西”。附屬件也不能確切到毫米,而應當允許一些和稀泥的情況:不同杯子的把手都在“側面”,但可能有的杯子把手高些,有的低些。
心理學家埃爾夫·比耶德曼(Irv Biederman)將馬爾的兩個觀點形象化為一些簡單的幾何部件,他稱其為“幾何離子”,類比組成原子的質子和電子。圖4-31展示了5個幾何離子和它們的一些組合。
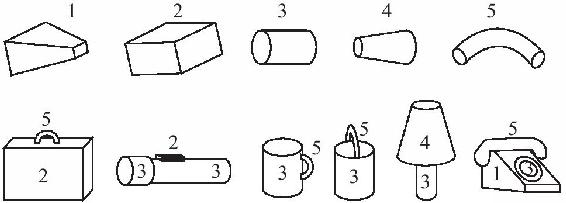
圖4-31 幾何離子
比耶德曼一共列出了24個幾何離子,包括一個圓錐、一個喇叭筒、一個橄欖球、一根管子、一個立方體和一段通心粉狀彎件。從技術上講,它們都是不同種類的錐體。如果一個冰激凌錐體是由一個其中心沿著一條直線移動的擴展圓掃出的平面,那幾何離子就是由其他二維形狀在沿著直線或曲線移動時,擴展或收縮而掃出的平面。幾何離子用幾個附加的關係如“上面”“旁邊”“端對端”“端到偏離中心”以及“平行”就可以組合成物體。這些關係由以物體為中心的參考框架來界定(當然不是視域);“上面”意為“主要幾何離子的上面”,而不是“凹槽的上面”。所以當物體或觀看者移動時,關係仍保持不變。
幾何離子是組合的,就像語法一樣。顯然我們並不是用語言來向自己描述形狀的,但幾何離子組合是一種內部語言,是一種心理語言的方言。一些固定詞彙的元素組合在一起構成了更大的結構,就像單詞構成了詞組和句子。句子不是單詞的累加,而是要根據它們的句法進行組合;人咬狗不等同於狗咬人。與之類似,物體也不是它的幾何離子的累加,而是要依賴於它的空間佈局;一個圓筒邊上有個彎手就是茶杯,一個圓筒頂上有個彎手就是提桶。就像少量的單詞和規則組合成的句子數量是個天文數字一樣,少量的幾何離子和附件也組合成具有天文數字數量的物體。根據比耶德曼的說法,每24個幾何離子分別有著15種大小和構造(有扁平的,有細長的),有81種方式組合它們。這就使得兩個幾何離子可以構成10497600種物體,3個幾何離子可以構成3060億種物體。從理論上講,這足以超過我們所知道的幾萬種形狀了。在實踐中,僅用3個,甚至常常是兩個幾何離子,就很容易建成可以即刻識別出的日常物體的模型。
語言與複雜形狀看起來更像是大腦中的鄰居。左半腦不僅負責語言功能,還具有識別和想像由佈置各部件而界定形狀的能力。一位左半腦中風的神經系統患病者報告說:“當我試著想像一棵植物、一種動物或一個物體時,我只能回憶起一部分。我的內部視覺短暫且支離破碎;如果讓我想像一頭牛的頭,我知道它有耳朵和角,但卻想像不出它們的具體位置。”相對而言,右半腦負責測量整個形狀;它能夠輕易判斷出一個長方形的高是否比寬更長,或者一個點在一個物體的一厘米之外還是之內。
幾何離子理論的一個優點是,它對二維半草圖的要求不是不合理的。將物體雕刻成部件、給部件貼上幾何離子的標籤,以及確定它們的佈置,這些並不是不可克服的問題,而且視覺研究者已開發出了大腦如何來解決這些問題的模型。它的另一個優點是,對物體結構的描述有助於心智來考慮物體,而不僅是為了脫口叫出它們的名字。人們通過分析物體部件的形狀和排列方式,從而理解物體運行的方式以及它們的作用。
幾何離子理論認為,心智在最高水平的知覺,是將物體和部件“看”作理想化的幾何固體。這就解釋了人類視覺審美中一個長期被注意到的、令人好奇的事實。任何曾經參加過人體繪畫班或去過裸體海灘的人都會迅速明白,真實的人體不像我們想像中的那樣甜美。我們絕大多數人穿上衣服會更好看些。藝術史學家奎恩廷(Quentin Bell)在他的時尚史課程中給出的解釋可能就是源自於幾何離子理論:
如果我們將一個物體包在某種紙袋中,這樣憑借眼睛推斷而非看到封存其中的物體,這個推斷或想像的形式很可能比它被拆封後顯現的樣子更加完美。因此,一個用棕色紙蓋著的方盒子可能會被想像成一個完美的正方形。除非心智得到了一些非常有力的線索,否則它不會想像到小洞、凹陷、裂紋或是其他一些特殊的質地。同樣,如果我們將一塊綢緞搭在大腿、腿部、胳膊或乳房上,它會被想像成具有完美的形態;一般不會想像到我們根據經驗應當估計出的不規則形狀和不完美之處。
我們知道,根據經驗身體大概會是什麼樣子,但我們願意擱置我們的懷疑,而傾向於人類的服裝所虛構的想像。我認為,我們確實在自我欺騙的行為上付出了更多的心力。當我們套上我們最好的夾克,看到我們乏善可陳的肩膀被很藝術化地放大並具有了理想的形狀時,我們的確,至少在短時間內提升了自己的自尊。
幾何離子也不是萬靈丹。許多自然的物體,比如山和樹,有著複雜的不規則分形形狀,但幾何離子將它們變作金字塔和棒棒糖。還有,儘管幾何離子能夠被構建為一個還湊合的普通人臉,像個雪人,但它幾乎不可能構建一張特定臉的模型——約翰的臉,你奶奶的臉——這張臉有充分的不同,也不至於和其他臉混淆,但無論是微笑還是皺眉,發福還是衰老,這張臉都足夠穩定,使得這個人總可以被認出來。許多心理學家認為,面部識別是特殊的。在我們這樣的社會性物種中,面部非常重要,因而自然選擇賦予了我們一個處理器,可以來記錄所需的各種幾何輪廓和比例,從而將之區分開來。嬰兒在僅僅剛出生30分鐘後,就會被臉部模樣的模式所吸引,但對其他複雜和對稱的佈置安排卻沒什麼興趣,他們還迅速學會了認出母親,大概早在生命的第二天就能做到了。
面部識別甚至可能使用大腦的專門部件。失去識別面部的能力被稱為面容失認症。這和奧利弗·薩克斯(Oliver Sacks)著名的“錯把老婆當帽子”的病例還不同:面容失認症患者能夠將帽子和臉部區分開來;他們只是說不出它是誰的臉。但他們中的許多人都能認出帽子和幾乎其他任何東西。例如,患者LH由心理學家南希·埃特科夫(Nancy Etcoff)和凱勒·凱夫(Kyle Cave)及神經病學家羅伊·弗裡曼(Roy Freeman)進行測試。LH是一個聰明、知識淵博的人,他在測試前20年發生的一次車禍中頭部遭到創傷。自那次事故後,他就完全認不出人臉了。他認不出他的妻子和孩子(除非通過聲音、氣味或者步態),他也認不出鏡子中他自己的臉,或是照片中的明星(除非他們有個像愛因斯坦、希特勒和披頭士樂隊在其全盛時期那樣的標誌性視覺特徵)。他並不是辨別不出面部細節;他能夠將他們的特徵與整個面容對上號,即使在朦朧的側光下也能做到,他還可以判斷他們的年齡、性別和美麗程度。他實際上可以正常地認出不是臉的複雜物體,包括單詞、衣服、髮型、車輛、工具、蔬菜、樂器、辦公座椅、眼鏡、光點圖形和像電視天線一樣的形狀。只有兩種形狀對他來說有些困難。他感到很尷尬,他不能叫出他孩子的動物餅乾的名稱;與之類似,在實驗室中,他識別動物圖畫的水平也位居下游。他還在識別諸如皺眉、譏笑、恐懼神情等面部表情時感到困難。但無論是動物還是面部表情,對他來說,都不像識別臉那樣困難,臉對於他來說完全是空白的。
臉對於我們的大腦來說並不是識別起來最困難的東西,以至於大腦一旦出現故障,臉部識別會最先受損。心理學家瑪蘭妮·伯赫曼(Marlene Behrmann)、莫裡斯·莫斯克布維奇(Morris Moscovitch)和戈登·維納克(Gordon Winocur)研究了一個頭部被一輛經過卡車的後視鏡擊中的年輕人。他識別日常事物有困難,但識別臉卻沒問題,即使臉上有眼鏡、假髮、鬍鬚做遮蓋也可以被他認出。他的症狀與面容失認症剛好相反,這說明臉部識別只是與物體識別有所不同,而非更加困難。
那麼面容失認症是因為面部識別模塊受損了嗎?一些心理學家注意到,LH和其他面容失認症患者在識別其他一些形狀時有些困難,所以他們認為,面容失認症患者處理一些對於識別面部很關鍵的幾何特徵有困難,而這些幾何特徵對於識別某些其他形狀也有作用。我覺得,區分識別面部和識別具有面部幾何特徵的物體是沒有意義的。從大腦的角度來說,沒有什麼東西是一張臉,直到它被識別出來時它才是一張臉。有關一個知覺模塊唯一特殊的東西是它要注意的幾何特徵,比如對稱的兩團泡泡的距離,或是撐在一個三維支架上的、裡面塞著下層軟墊和連接管的、兩維彈性表面的彎曲模式。如果除了臉之外的其他物體(動物、面部表情甚至汽車)也具有一些這種特徵,這個模塊就只能分析它們了,即使它們對於臉是最有用的。將一個模塊稱為臉部識別器,並不是說它只能夠處理臉部;而是說它是根據區分臉的幾何特徵而優化設計的,因為這個器官在演化歷史中被選擇具有了識別它們的能力。
幾何離子理論很有意思,但它是事實嗎?當然不可能是以它最純粹的形式所闡述的:每個物體都有一個三維幾何的描述,不受觀察點推測的影響。大多數物體是模糊的,一些表面遮蓋了另外一些。這使得幾乎不可能從每個觀察點得到對物體相同的描述。例如,當你站在房子前面時,你不可能知道房子的後面是什麼樣的。馬爾迴避了這個問題,他忽略了所有的表面而去分析動物的形狀,就好像這些形狀都是用水管建造的一樣。比耶德曼的解釋承認了這個問題,他在心理形狀目錄中為每個物體分配了幾個幾何離子模型,每個模型反映所有表面所需的視角。
但這個觀點打開了通往形狀識別的全然不同方式的那扇門。為什麼不直接給每個形狀許多內存文件,一個文件表示一個觀察點呢?那樣就不需要一個以物體為中心的參考框架了;它們可以用二維半草圖中免費提供的視網膜坐標,只要有足夠的文件涵蓋所有的觀看角度就可以。許多年來,科學家一直沒有考慮這個想法。如果觀看角度的連續體被切割成每隔一度的差異,每個物體就需要4萬個文件來包括所有觀看角度(這還只是為了包括觀看角度;它們沒有包含物體不是正中間的觀看位置或不同的觀看距離)。不能只列出一些視域就敷衍了事,就像建築師的方案和立視圖一樣,因為從原則上講,任何視域都有可能是關鍵的。這裡有一個簡單的證明:設想一個中空的球,裡面用膠水粘著一個玩具,球對面鑽了一個小孔。只有通過小孔看這個玩具,才能看到它的整個形狀。但最近這個觀點又捲土重來。通過審慎地選擇視域,並在視域之間插入一個模式關聯器神經網絡,當一個物體與現場看到的不匹配時,一個人可以只儲存可數的易於管理的視域,至多40個。
但這好像依舊不大可能,人們只是從40個不同的角度看一個物體才能認出它來,不過我們還有另外一個竅門。還記得人們是依賴於上下方向來分析形狀的吧:正方形不是菱形,橫著的非洲就認不出來。這引出了純粹幾何離子理論的另一個延伸:像“在……上面”和“在……頂部”的關係一定來自視網膜(根據重力做一些調整),而不是來自物體。這個讓步可能是無法避免的,因為往往在認出一個物體之前,沒辦法指出這個物體的“頂部”。但真正的問題是,人們如何處理最初不認識的橫著的物體。如果你告訴人們,一個形狀被轉到橫的方向,他們立刻就認出來了,就像我告訴你非洲那幅畫是側著放的一樣。人們能夠在心裡把一個形狀旋轉到直立的位置,然後認出旋轉後的圖像。有一個心理意象旋轉器可供使用,以物體為中心的幾何離子理論框架就變得不那麼必要了。人們能夠儲存從幾個標準觀察點看的一些二維半視域,就像警方查找嫌疑犯圖片,如果他們前面的物體不符合其中一個圖片,他們會在心理上旋轉它,直到匹配為止。多重視域的一些組合和一個心理旋轉器會使得以物體為中心的參考框架中的幾何離子模型不太必要。
形狀識別有這麼多備選方法,我們怎麼能弄清楚心智實際上究竟是怎麼做的呢?唯一的方法是研究真正的人類在實驗室中是如何識別形狀的。一組著名的實驗指向心理旋轉是一個關鍵。心理學家林·庫珀(Lynn Cooper)和羅傑·夏珀德(Roger Shepard)給人們看不同方向的字母——直立的、傾斜45°的、橫向的、傾斜135°的,還有顛倒的。庫珀和夏珀德沒有讓人們脫口說出字母的名稱,因為他們擔心有捷徑:像圓圈或尾巴一樣扭曲的獨特筆跡無論是什麼方向,可能都會被認出來。所以他們要求被試分析每個字母的整個幾何特徵,給被試看字母或字母在鏡子中的影像,如果字母是正常的,就讓被試按一個鍵;如果字母是在鏡中的影像,就按另一個鍵。
當庫珀和夏珀德測量人們需要花多長時間按下按鈕時,他們觀察到,心理旋轉的一個清晰符號。字母與它直立的形狀偏離的方向越遠,人們就需要花越長的時間。這正是如果人們逐漸將一個字母圖像轉回直立形狀時可能發生的:它需要轉得越多,轉的時間就越長。那麼或許人們識別形狀就是依靠在心理上旋轉它才做到的。
但也許不是。人們不只是在識別形狀;他們在將這些形狀與其鏡中影像區分開來。鏡中影像是特殊的。《愛麗絲漫遊仙境》的續集叫作《愛麗絲魔鏡之旅》,這是很合適的。形狀與其鏡中影像的關係在許多科學分支中引發了熱議、甚至是悖論。馬丁·加德納、邁克爾·科波利斯和伊萬·比勒所著的書對此都有精彩的深入探討。想想服裝模型上安裝的左手和右手。從一種意義上講,它們都是相同的:每隻手上都有四根指頭和一根拇指附在手掌上和一個手腕上。從另一種意義上講,它們則完全不同:一個不能疊加到另一個上。差異僅在於其部件是如何相對於一個參考框架而校準的,這個參考框架中3條軸標有3個方向:上下、前後、左右。當右手指頭向上、手掌向前時(就像“停止”的手勢),它的拇指是指向左邊的;當左手指頭向上、手掌向前時,它的拇指是指向右邊的。這是唯一的差別,但卻是真正的差別。生命的分子有對左手或右手的習慣傾向;它們的鏡中影像往往在自然中並不存在,它們也沒辦法在我們的身體裡正常地運作。
20世紀物理學的一個重要發現是,宇宙也有一個左右的習慣傾向性。乍一聽這很荒謬。對茫茫宇宙中的任何物體和事件而言,你都沒辦法知道自己是看到了實際的事件,還是看到了它在鏡中的映像。你可能會抗議說,有機分子和人造物體就是個特例,如字母表中的字母。標準版本隨處可見而且人們都很熟悉;鏡像則很少見,但會很容易被認出來。然而,對一個物理學家來說,那些都不算數,因為它們的左右傾向性是一個歷史巧合,而不是被物理法則排除在外的東西。在另一個星球上,或者在這個星球上,如果我們能使演化的時光倒流,讓它再重新來一次,它們很可能沿著另一條路徑走下去。物理學家過去常認為,這對宇宙萬物均是如此。沃爾夫岡·保利寫道:“我不相信上帝是個虛弱的左撇子。”理查德·菲耶恩曼與一個人賭50美元(對方不願意賭100美元),他認為沒有任何實驗會揭示出一條自然法則,證明自然定律在鏡子裡會表現出不一樣的效果。但是最後他還是輸了。鈷60原子核據說會逆時針旋轉,如果你從它的北極向下看的話就會看到。但這個說法本身就是循環論證,因為“北極”就是我們對那個旋轉看起來像逆時針的軸端點的稱謂。如果另有一些東西將所謂的“北極”與所謂的“南極”區分開來,這個邏輯圈就會破碎。這就是另外一些東西:當原子衰變時,電子更可能會被拋向我們稱之為“南”的那一端。“北”對“南”和“順時針”對“逆時針”就不再是任意的標籤,而是可以相對於電子噴射而區分開來的。這種衰變,以及宇宙,會在鏡中看起來有所不同。上帝畢竟不是左右手同樣靈巧的。
因此,右手版和左手版的東西,從亞原子粒子到生命原始物質再到地球的旋轉,都是從根本上不同的。但心智通常把它們當作是相同的,且同等對待:
小熊看了看它的兩個爪子。它知道其中一個是右爪,它還知道當你確定哪一隻是右爪時,另一隻就是左爪了,但它永遠也記不得該如何開始。
我們都不善於記住如何開始。左右鞋看上去非常相似,所以必須得教給孩子們區分它們的竅門,比如將鞋子並排放好並估算間隔。一美分硬幣上林肯面朝哪個方向?你答對的概率只有50%,這和你拋硬幣賭運氣的概率一樣。惠斯勒的著名油畫如何呢?我指的是那幅《黑與灰的協奏曲:畫的母親肖像》。甚至英語對於左右也常常描述不清:beside和next to表示並排的,而沒有明確說明誰在左邊,但沒有像behove或是aneath這樣的詞表示上和下,而不說明誰在頂上的。我們對左-右的不在意與我們對上-下以及前-後的超級敏感形成了鮮明的對比。很顯然,人類心智沒有一個預設標籤供它以物體為中心參考框架的第三個維度來使用。當它看一隻手時,它可以用“下-上”來校準手腕-指尖的軸向,用“後-前”校準手背-手掌的軸向,但小指-拇指的軸向還空缺著。心智稱其為“拇指朝向”,左右手在心理上成為同義語。我們對左右的不確定性需要一個解釋,因為幾何學家會說,它們從上還是下或從前還是後沒有什麼不同。
這個解釋是,鏡像困惑對於一個雙邊對稱的動物來說很自然就形成了。從邏輯上講,一個完全對稱的生物是不能區分左右的(除非它能對鈷60的衰變做出反應)。自然選擇對於構建不對稱的動物沒什麼激勵因素,以至於它們能夠在心理上表徵與其映像不同的形狀。事實上,這個可以反向推理為:自然選擇的每個激勵都是為了構建對稱的動物,這樣它們就不會表徵與其映像不同的形狀了。在一個動物生存的中觀世界裡(比亞原子粒子和有機分子要大,比天氣雲團要小),左和右沒什麼不同。從蒲公英到大山這樣的物體,它們的頂端都與其底部明顯不同;而絕大多數移動的東西,其前面也與後面有顯著不同。但沒有任何自然的物體,其左邊會與右邊有非隨機性的差異,從而使其鏡像版有所不同。如果一個獵食者第一次從右邊來,下一次它可能會從左邊過來。對於動物們來說,它們在第一次學習到的所有經驗,都應該要自動地被歸納到與原來情境互為鏡像的環境中才是。另一個表述的方式是,你拿來一張任意自然景致的攝影幻燈片,如果有人把它上下顛倒了,這會很明顯;但如果有人把它左右翻轉一下,你就不會注意到,除非這個景致中包含了一個人造的物體,比如汽車或文件。
這又將我們帶回字母和心理旋轉。在幾項人類活動中,如駕駛和書寫,左和右確實有差別,我們學會了區分它們。怎樣做到的呢?人腦和身體都略微有些不對稱。一隻手是主導的,這要歸功於大腦的不對稱,我們也能夠感受到這種差異。早期的字典中曾經將“右”定義為身體具有更強壯的手的那一側,這是基於人們都是右利手的假設。晚近些的字典,可能是出於對被壓迫的少數人群的尊敬,使用了一個不同的非對稱物體——地球,將“右”定義為你面朝北時處於東邊的那一側。人們區分物體及其鏡像的通常方式是,將它的面轉向上方和前方,來看看有區別的那部分正指向他們身體的哪一側——主導手的那一側還是非主導手的那一側。人的身體被用來作為非對稱的參考框架,使得形狀與其鏡像之間的區分在邏輯上成為可能。現在,庫珀和夏珀德的被試幾乎就是在做相同的事情,他們是在心理上旋轉形狀而不是在世界中旋轉。為了確定他們是看到了一個正常的R還是一個反轉的R,他們在心理上旋轉了這個圖像,直到它直立起來,然後再判斷那個想像的圓圈是在他們的右側還是在左側。
所以庫珀和夏珀德證明了心智能夠旋轉物體,他們還證明了物體內在形狀的一個特點——它的慣用手傾向性——不是儲存在一個三維幾何離子模型中的。儘管有這個奇妙之處,慣用手傾向性仍是宇宙的一個特殊性質,因此我們還不能根據心理旋轉的實驗就對一般意義上的形狀識別過多下結論。從我們目前所知的證據來看,人類的心智在觀察一個物體的時候,可能是把一個三維空間的參考坐標系統覆蓋在物體之上(以便進行對幾何離子的查找工作),然後找出所有有關該物體的特徵——但是這卻不包括該物體在左右坐標軸上所呈現出的方向性。正如庫珀和夏珀德所說,還需要更多的研究。
心理學家邁克爾·塔爾(Michael Tarr)和我做了更進一步的研究。我們創造了我們自己的形狀小世界,並刻意地控制著人們對這些形狀的接觸程度,目的是為了對3個假設做出清晰的驗證(見圖4-32)。

圖4-32
這些形狀非常類似,人們無法利用像彎曲線那樣的捷徑。沒有一個形狀是其他任何一個的鏡像,所以我們不會因鏡子中世界的奇形怪狀而被干擾。每個形狀都有一個獨特的小腳,這樣人們在尋找頂端和底部的時候就不會有問題。我們讓每個人學習3個形狀,然後請他們識別:每當電腦屏幕上閃現一個形狀時,就按3個按鈕中的一個。每個形狀以不同的方向不斷出現。例如,形狀3顯現的形狀可能有幾百次是頂部處於四點鐘方向的位置,而頂部處於七點鐘方向的位置也可能出現幾百次。所有的形狀和傾斜度都是以隨機的順序打亂混在一起的。因而人們有機會在觀看幾次後會知道每個形狀看起來像什麼。最後,我們呈現給他們一些新實驗:每個形狀都以均勻直立的方向顯現出來(同樣隨機排序)。我們想要看看,人們如何處理處於新方向上的舊形狀。每個按鈕時間被設定為1/1000秒。
根據多重視域理論,人們通常應當為物體呈現的每個朝向的情況分別創建一個記憶文件。例如,他們會建立一個文件,顯示形狀3右側朝上時看起來像什麼(這就是他們如何習得的),然後再創建一個文件,顯示其在四點鐘方向的位置時會是什麼樣的,以及創建顯示在七點鐘方向位置時的樣子的文件。人們應當不久後能很快認出這些方向下的形狀3。但是當我們再用一些新方向下的相同形狀讓他們看時,他們應該要花長得多的時間才能認出,因為他們得在熟悉的形狀之間插入新的物體並對之做出適應。所有新的方向都應當會花費更長的一段時間。
根據心理旋轉理論,人們應當迅速認出直立的形狀,越偏離方向的形狀,識別的時間就越慢。顛倒的形狀會花費最長的時間,因為它需要一個180°的旋轉;四點鐘方向的位置的形狀應該會快一些,因為它只需要旋轉120°,以此類推。
根據幾何離子理論,朝向不會有任何影響。人們將學會這個物體,在心理上描述以這個物體為中心的坐標系統中的各個枝幹和交叉。然後,當一個測試形狀閃現在屏幕上時,無論它是橫向的、傾斜的還是顛倒的,應當都沒有什麼不同。人們應該都能以快速且萬無一失的方式將一個坐標系統覆蓋在物件的身上,而他們由相對於該坐標系統所得到的物件的描述,也應該總是能夠與他們記憶中的物件模型相匹配才是。
快給我信封。最終優勝者是……
所有的候選者。人們一定儲存了幾個視域:當形狀以一種習慣的朝向顯現時,人們很快就認了出來。
人們也一定在心理上對形狀做了旋轉。當形狀以一種新的、不熟悉的朝向出現時,把這個形狀旋轉到與過去常見方向相同的樣子所需要的角度愈大,人們就需要花費越多的時間才能認出。
至少對於一些形狀,人們使用一種以物體為中心的參考框架,就像幾何離子理論中論述的一樣。塔爾和我做了一個稍微有些變化的實驗,其中的形狀有著更為簡單的幾何特徵(見圖4-33)。
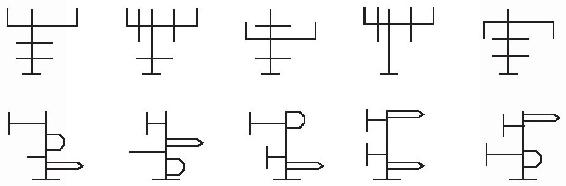
圖4-33
這些形狀是對稱的或幾乎對稱的,或是在每一側都總有同種的褶邊,這樣人們就不需要在相同參考框架中描述這些部件的上-下和一側-另一側的佈局了。有了這些形狀,無論它們是朝哪個方向的,人們就都會迅速認出它們;顛倒的並不比右側朝上的認得更慢。
這樣看來,人們的確會用上所有可能的技巧來辨認形狀。如果形狀的兩側差異不大,他們就把它儲存為以物體自身軸為中心的三維幾何離子模型。如果形狀更複雜些,他們就把看到的每個方向下的形狀的樣子都儲存一個副本。當形狀以一種不熟悉的朝向出現時,他們在心理上把它旋轉到最接近的熟悉的形狀。或許我們不應當感到奇怪,形狀識別是個非常困難的問題,單一通用目標的算法不可能適合於每種觀看條件下的每個形狀。
作為實驗者,讓我在最快樂的時刻結束這個故事。你可能還對心理旋轉心存懷疑。所有我們所知道的只是傾斜的形狀認起來更慢。在前面,我只是隨隨便便地寫到人們能在腦中旋轉圖像,但也許事實上,傾斜的形狀更難分析或許有其他原因。有任何證據能表明人們事實上是在一度度地實時模擬實物旋轉嗎?他們的行為顯示了一些旋轉的幾何特徵,從而讓我們確信他們是在腦中播放著一個有關這種過程的電影嗎?
塔爾和我對我們的一項研究結果頗為困惑。在一項實驗中,我們對人們的測試涉及在各種朝向下人們所研究的形狀以及它們的鏡像(見圖4-34)。
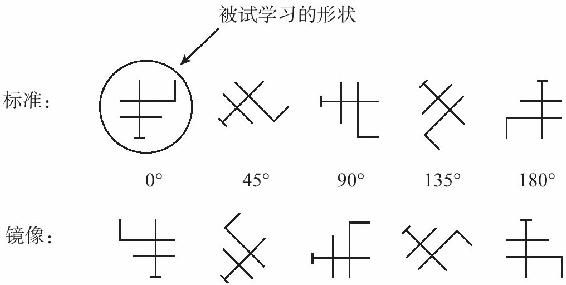
圖4-34
這不是一個鏡像測試,與庫珀和夏珀德的實驗不同:人們被告知要把兩種版本視為相同的,就像他們叫左手手套和右手手套都用同樣的單詞“手套”一樣。這當然只是人們的自然傾向。但不知為何,我們的被試在對待它們時卻有些不同。對於標準版(上面一行),他們會在傾斜程度較大的形狀上花上較長的時間來完成辨識的工作:上面那行的每幅圖片都比前一張花更長一點的時間。但對於鏡像版(下面一行),傾斜則沒有什麼差異:每個朝向都花相同的時間。看上去似乎是人們在心理上旋轉標準形狀,而不是它們的鏡像。塔爾和我心不甘情不願地寫出一篇文章,請求讀者相信,人們使用不同的策略來識別鏡像。在心理學中,使用“策略”來解釋奇怪的數據是無能的最後庇護。但就在我們為最後的版本修改潤色準備出版時,一個想法冒了出來。
我們記起一個關於幾何運動的定律:一個二維形狀總是可以通過旋轉不超過180°而與其鏡像相校準,只要這個旋轉可以是在第三維度裡圍繞著一根特定的假想軸進行的。從原則上講,任何我們在鏡中逆向的形狀都能夠在深度上翻轉以匹配標準直立的形狀,而這種翻轉將花費同樣長的時間。0°的鏡像就像一扇回轉的門一樣,圍繞著一根縱軸來迴旋轉。橫向的形狀會繞著一根橫軸來旋轉,就像這樣:看看你的右手手背,指尖朝上;現在再看你的手掌,指尖朝左。不同的傾斜軸可以發揮為其他不同朝向形狀的鉸鏈作用;在每種情況下,旋轉都是剛好180°。它會完美地符合數據:人們可以在心理上旋轉所有的形狀,但使用的是最適合的旋轉器,它在圖片平面上旋轉標準的形狀,並圍繞著最佳樞軸在深度上翻轉鏡中逆向的形狀。
我們幾乎不能相信它。人們能在知道形狀之前就找到最適宜的軸嗎?我們知道,這在數學上是可能的:對於特定形狀的正常影像和鏡像來說,我們只要在每個影像中給定三個不落在同一直線上的定點,人們就可以計算兩個形狀相互校準的旋轉軸。但人們真的可以做這種計算嗎?我們用計算機動畫讓自己信服了。羅傑·夏珀德曾展示,如果人們看到一個形狀與一個傾斜的副本在不斷交替,他們看到的是,它在來回擺動。所以我們給自己看的是標準的直立形狀與它的一個鏡像之間不斷交替,每秒鐘來回一次。大腦對翻轉的知覺特別明顯,我們都不必再去費事徵召志願者來確認了。當形狀與它的直立映像來回交替時,它旋轉起來就好像是洗衣機的攪拌器一樣。當它與其顛倒映像來回交替時,它像在做後空翻。當它與其橫向映像來回交替時,它圍繞著一根水平軸來回迅速翻騰,諸如此類。大腦在每次的試驗裡總是能夠找出最佳的旋轉軸,實驗裡的被試比我們自己更加聰明。
塔爾在畢業論文中給出了定論。他用三維形狀及其鏡像複製了我們的實驗,在圖片平面上和深度上進行旋轉(見圖4-35)。
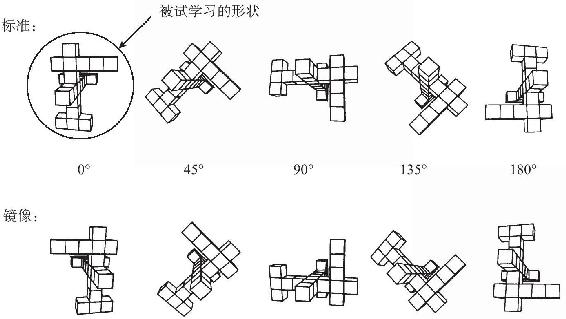
圖4-35
除了人們對鏡像的處理,所有情況都與二維形狀中的一樣。正如一個朝向錯誤的二維形狀可以通過在二維圖片平面上加以旋轉而與標準朝向匹配一樣,它的鏡像可以通過在第三維做180°的翻轉而旋轉到標準的朝向,一個朝向錯誤的三維形狀(上面一行)也可以在三維空間中旋轉到標準的朝向,而它的鏡像(下面一行)也可以在第四維做180°翻轉而旋轉到標準位置。在H.G.威爾斯所著的《普拉特納的故事》一書中,一次爆炸將英雄吹到了四維空間。當他回來時,他的心臟位於身體右側,他的書寫習慣也變為用左手由右向左倒著進行。唯一的差別是,真正的凡人應當不能在心理上在第四維旋轉形狀,我們的心理空間是嚴格的三維空間。所有的版本應當顯示出一種傾斜效果,不像我們在二維形狀中發現的鏡像那樣並不傾斜。情況就是如此。二維和三維物體之間的微妙差異解釋了這個情況:大腦在三個維度中圍繞一個最佳樞軸旋轉形狀,但不超過三個維度。心理旋轉很顯然是我們識別物體背後的一個技巧。
心理旋轉是我們天才視覺系統的又一稟賦。它不只分析來自世界的外形輪廓,還以鬼魅般移動的圖像形式創造了一些自己的輪廓。這將我們帶到了視覺心理學中的最後一個主題。
心理意象,空間想像的引擎
獵犬的耳朵是什麼形狀的?你的客廳有幾扇窗戶?聖誕樹和凍豆子,哪個顏色更暗些?豚鼠和沙鼠,哪個體型更大?龍蝦有嘴嗎?一個人筆直站立時,他肚臍高度是比手腕的高度還高嗎?如果字母D被翻轉過來放到字母J的頂部,這個組合會讓你想起什麼?
絕大多數人說他們使用“心理意象”來回答這些問題。他們將形狀視覺化,感覺上就像想像一幅圖像以供心智之目檢測。這種感覺與回答抽像問題的體驗大不相同,比如:“你母親的家族姓氏是什麼?”或者:“公民自由和較低的犯罪率,哪個更重要些?”
心理意像是驅動我們思考空間中物體的引擎。要往車上裝箱子或重新佈置傢俱,我們在嘗試之前要想像不同的空間佈置。人類學家拿破侖·夏格儂(Napoleon Chagnon)描述了亞馬孫雨林的雅諾馬馬印第安人對心理意象的巧妙運用。他們將煙向下吹進犰狳洞的開口處令其窒息,然後再弄清楚在哪裡挖掘,把它從坑道裡刨出來,但這有可能會深達地下數十米。一個雅諾馬馬人琢磨出的想法是,搓出一根長籐,在頂端繫個結,然後順著洞口伸進去直到最遠處。其餘的人把他們的耳朵都伏在地面上,傾聽籐結碰到洞穴側面的聲音,這樣他們就能獲得一種方向感,瞭解洞穴往哪個方向延伸。第一個人扯斷長籐並拉出來,將籐沿著地面放好,然後開始挖掘長籐末端放置的地方。在幾米之下,他們就抓到了犰狳。如果沒有想像坑道、長籐和裡面犰狳的能力,人們就不會連接這一系列的搓捻、傾聽、猛拉、弄斷、測量和挖掘行動,來試圖找到一具動物屍體。在我們小時候常講的一個笑話中,兩個木匠在向房子側面釘釘子,一個人問另一個人,為什麼他從盒子裡取出釘子時要檢查一番並扔掉其中的一半,另一個木匠回答:“它們有缺陷。”說著拿起一根說:“尖的那一端的朝向錯了。”“你這個傻瓜!”第一個木匠大聲說,“那些是用在房子另一側的釘子!”
但人們並不只是用想像來重新佈置傢俱或是挖出犰狳。著名心理學家D.O.赫布(D.O.Hebb)曾寫道:“在心理學中,你很難轉個身而不碰到圖像。”如果讓人們記住一組名詞,他們會將這些詞與怪異的圖像相聯繫。給他們支離破碎的問題,比如:“跳蚤有嘴嗎?”他們會想像跳蚤並“尋找”它的嘴。當然,給他們一個朝向不熟悉的複雜形狀,他們會將其映像旋轉成一個熟悉的圖像。
許多有創造力的人自稱在圖像中“看到”了問題解決的方法。法拉第和麥克斯韋將電磁場想像為充滿液體的小管子。凱庫勒看苯環時幻想成蛇在咬自己的尾巴。沃森和克裡克的心理旋轉的模型後來成了雙螺旋。愛因斯坦想像乘坐一束光或是將一枚硬幣掉進正在迅速跌落的電梯中會怎樣。他曾這樣寫道:“我特別的能力不在於數學計算,而是在於對效果、可能性和結果的想像。”畫家和雕塑家在腦海中嘗試其想法,甚至小說家動筆之前也在心中想像場景和情節。
想像不但驅動著情緒,也驅動著智力。海明威寫道:“怯懦與惶恐不同,它幾乎總是因為對幻想缺乏遏制的能力造成的。”野心、焦慮、性喚起以及忌恨全都可以由圖像所引發。在一個實驗中,實驗人員將志願者連上電極,然後請他們想像自己配偶的不忠誠。實驗人員報告說:“被試的皮膚導電度增加了1.5微西門子,他們眉頭的皺眉肌顯示出7.75微伏單位的收縮,他們的心律每分鐘加速了5次,相當於坐在那兒喝了3杯咖啡。”當然,想像這種行為會讓人在同一時間內重溫諸多體驗(包括非視覺方面的),但是心理意象特別能夠將心智運作的模擬過程,轉變得栩栩如生。
想像是一個產業。關於如何改善你的記憶力的課程教授一些古老的竅門,比如想像你家房間的物什,然後在心理上進行巡察,或者在一個人的名字中找到一個視覺暗示並將其連接到他的臉部(如果把你介紹給我,你會想像我穿著一件淡紅色的休閒服裝)。恐懼症的治療常用一種心理上的巴甫洛夫式條件反射法,其中圖像替代了鈴鐺。患者深度放鬆,然後想像蛇或蜘蛛,直到這個圖像及其延伸的實物與放鬆建立關聯。收入頗豐的“運動心理學家”讓運動員在舒服的椅子上放鬆,並想像自己在運動中發揮出最佳狀態的情形。許多技巧有效,儘管有一些極為怪誕。我對癌症治療中患者想像他們的抗體奮力咀嚼腫瘤的作用心存懷疑。一位女士曾來電詢問我,是否認為通過互聯網這樣做仍然有效。
那麼,什麼是心理意象呢?許多有行為主義者傾向的哲學家認為,這整個想法就是一個天大的錯誤。圖像應該是大腦中的圖片,但那樣你就需要一個腦中小人。事實上,心智計算理論將這個概念闡述得非常明瞭了。我們已經知道,視覺系統使用的二維半草圖在幾個方面都像圖片。它是一個鑲嵌圖,其中各元素代表視域中的點。元素是在二維中安排的,這樣排列中的鄰近元素代表著視域中的鄰接點。形狀的表徵是通過以與形狀投映輪廓相匹配的模式來填入一些元素而實現的。形狀分析機制——不是腦中小人——通過加入參考框架、找到幾何離子等來處理草圖上的信息。一個心理意象只不過是二維半草圖中的一個模式,它是從長期記憶中讀取的,而非來自眼睛。一些推理空間的人工智能程序正是以這種方式設計的。
像二維半草圖這樣的描述與像幾何離子模型、語義網絡、英語句子或心語等提法有著鮮明的對比。在“一個對稱三角形在一個圓的上邊”這樣的提法中,單詞不代表視域中的點。像“對稱”和“在……上面”這樣的詞無法對應視域中的任何部分,它們表示的是填入部分的複雜關係。
人們甚至可以訓練有素地猜測心理意象的解剖結構。神經元中二維半草圖的化身被稱為地形上有組織的皮質圖:一片皮質中,每個神經元對應於視域中的一部分輪廓,鄰近神經元對應鄰近的部分。靈長目動物的大腦至少有15張這樣的圖,從非常實際的意義上說,它們是大腦中的圖片。神經學家可以在猴子盯著一個靶心的時候,給它注射放射性葡萄糖同位素。葡萄糖被活躍的神經元所吸收,這樣人們實際上可以顯影猴子的腦,就好像它是一幅膠卷一樣。它源自於一個在視覺皮層上攤著個扭曲靶心的暗室。當然,沒有任何東西從上面“看”這個皮層;連接性是唯一重要的,而活動模式是由插入每幅皮層圖的神經元網絡來解釋的。大概世界上的空間是由皮層中的空間所代表的,因為神經元與它們的鄰近部分相連接,而將世界附近的一些東西一同來分析是很便利的事情。例如,邊緣並不像大米一樣散佈在視域中,而是沿著一條線彎曲延伸,絕大多數表面並不是散落的群島,而是連續的物質。在皮質圖中,線和表面可以由相互緊密連接的神經元來處理。
大腦還準備好了應付想像系統的第二個計算要求,信息從記憶中流下來而不是從眼睛中流上來。通往腦視覺區域的光纖通道是雙向的。它們從更高級、概念性的層面向下所攜帶的信息,與從更低級、感官性的層面向上所攜帶的信息一樣多。沒有人知道為什麼這些上-下連接會這樣,但它們可能是為了將記憶圖像下載到視覺地圖中。
一些心理意象可能是大腦裡的圖片。是嗎?有兩種方式可以找出答案。一種方法是,是看看用圖像來思考是否適用於大腦的視覺部分。另一種方法是,看看用圖像來思考是更像用圖形來計算,還是更像用一個命題數據庫來計算。
在《理查二世》的第一幕中,被流放的博林布魯克渴望回到他的祖國英格蘭。朋友建議他幻想自己處於田園詩般的環境中,但他沒有從中得到安慰:
哦,誰能只需想想嚴寒的高加索,
手中便握有火炬?
或是,僅僅想像一頓盛宴,
便填滿轆轆飢腸?
又或,幻想著夏日的酷熱,
即可赤身在臘月的雪中翻滾?
很顯然,圖像與真實事物體驗是不同的。威廉·詹姆斯說,圖像“缺乏辛辣和氣味”。但在1910年的博士畢業論文中,心理學家謝弗斯·珀奇(Cheves W.Perky)試圖證明,圖像非常像微弱的體驗。她請她的被試在一面空牆上形成一幅心理意象,比如一根香蕉。這面牆實際上是一個後部投影屏幕,珀奇偷偷地將一個真正的但卻比較朦朧的幻燈片投映在上面。任何來到房間那個位置的人都看到了幻燈片,但沒有一個被試注意到它。珀奇稱,他們已經將這幅幻燈片融入了他們的心理意象中,確實,被試報告他們圖像的細節時,有些只能來自於那張幻燈片,比如香蕉頭朝下立著。從現代標準來看,這並不是一個很棒的實驗,但最新的方法證實了這個發現的要點,現在它被稱為珀奇效應:保持一個與看到微弱的具體視覺細節相互干擾的心理意象。
想像也能夠以顯著的方式影響知覺。當人們回答關於源自記憶的形狀的問題時,比如在大寫字母中挑出直角,他們的視覺-運動協調會頗覺費力。自從學習了這些實驗後,我駕車時盡量不去專心收聽冰球比賽的廣播。有關線條的心理意象會像真正的線條一樣影響知覺:它們使得判斷校準更為容易,甚至可以導致視覺幻象產生。當人們看到一些形狀並想像其他形狀時,他們之後有時會很難記起哪個是哪個。
所以想像和視覺在大腦中共用空間嗎?神經心理學家愛德華多·比夏克(Edoardo Bisiach)和克勞迪奧·盧扎蒂(Claudio Luzzatti)研究了兩個右頂葉受損的米蘭病人,他們罹患視覺忽略症狀。他們的眼睛記錄了整個視域,但他們只注意到右半部分:他們忽略了盤子左邊的餐具,畫一張臉沒有左眼或左鼻孔,描述一個房間時,忽略了左面的細節——比如放有一架鋼琴。比夏克和盧扎蒂請患者想像自己站在米蘭大教堂廣場上,面對大教堂,讓他們叫出廣場上建築的名字。病人們只能叫出右側能看到的建築——卻忽略了左半邊想像空間!然後研究人員要求病人們心想著步行穿過廣場,站在大教堂的台階上,面對廣場,描述廣場上的景物。這次病人們提到了最初遺漏的那些建築,卻遺漏了他們提到過的建築。每個心理意象都描述了從一個觀察點看到的景致,患者不平衡的注意之窗對圖像的檢驗就像他檢驗真的視覺輸入一樣。
這些發現暗指視覺腦就是想像的溫床,近來對此有了一個正面鑒定。心理學家斯蒂芬·考斯林(Stephen Kosslyn)及其同事使用正電子發射斷層成像技術(PET),觀察當人們有心理意象時,哪部分腦最為活躍。每個被試在頭上箍一圈監測器,閉上眼睛,回答關於字母表中大寫字母的問題,比如字母B是否有曲線。枕葉或視覺皮層,即處理視覺輸入的基本灰質亮了起來。視覺皮層根據高低形狀繪製了出來——你可以說,它形成了圖片。在一些測試中,被試們想像到了大字母,另一些時候,想像到小字母。默想大字母激活了表徵視域周圍區域的皮層部分;默想小字母激活了表徵凹陷的部分。圖像真的好像被放置在皮層表面一樣。
激活會是大腦其他部分活動(在那裡進行著真正的計算)的溢出效應嗎?心理學家馬莎·法拉(Martha Farah)證明並非如此。她測試了一位婦女在做手術摘除一個腦半球的視覺皮層後,術前和術後形成心理意象的能力。手術後,病人的心理意象萎縮至通常心理意象寬度的一半。心理意象存活在視覺皮層;確實,部分圖像佔據了部分皮層,就像部分景致佔據了部分圖片一樣。
誠然,圖像還不是一種即刻重放。它缺少辛辣和氣味,儘管這不是因為它被漂白或沖淡:想像紅色並不像是看到粉色。而且令人好奇的是,在PET研究中,心理意像有時比實際顯示導致了更多的視覺皮層激活。視覺圖像儘管與知覺共用大腦區域,但它們還是有些不同,或許這並不令人驚訝。唐納德·西蒙斯注意到,重新激活視覺體驗會有更多好處,但它也有成本,即將想像與現實混淆的風險。我們一從睡夢中醒來,就很快忘掉了對夢中情節的記憶,大概就是為了避免怪誕虛構對自傳體記憶的影響吧。類似地,我們自發、清醒時的心理意象可能會誘使自傳體記憶成為幻覺或錯誤記憶。
知道心理意像在哪裡,對瞭解它們是什麼或它們如何工作無甚幫助。心理意象真的是二維半草圖中的像素模式嗎(或是皮層圖中的活躍神經元模式)?如果是的話,我們如何用它們來思考呢,又是什麼令想像與其他形式的思維有所不同呢?
讓我們來對排列或草圖與其作為想像模型的另一方案——心語的符號性命題(類似於幾何離子模型和語義網絡)做個比較。圖4-36的左邊是排列或草圖,右邊是命題模型。圖4-36將許多命題,如“熊有個腦袋”和“這個熊的尺寸是XL號”綜合到了一個網絡裡。
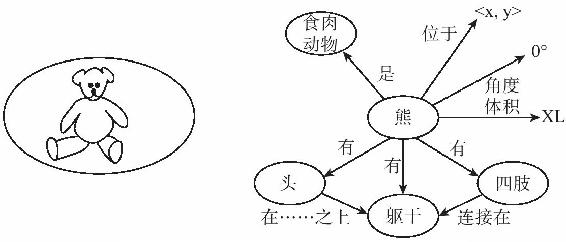
圖4-36
這個安排簡單明瞭。每個像素代表一小片表面或者邊界;任何更為綜合或抽像的東西在填滿像素的模式中只是隱含的。命題式表徵則大不相同。第一,它是綱要式的,充滿了像“附著於”這樣定性的關係,而且不是所有的幾何細節特徵都得到表徵。第二,空間特徵被分開並清晰地列明。形狀(物體各部分或幾何離子的佈置安排)、大小、位置和朝向都有它們自己的符號,查詢每個符號都與其他符號獨立。第三,這些命題會將有關空間的信息——如組件及其相對位置——與概念性信息——如是否屬於熊這個物種,以及是否為食肉動物等——混合了起來。
在這兩種數據結構中,圖像排列最好地抓住了想像的特徵。首先,圖像是極其具體的。想想這個要求:想像一個檸檬和一根香蕉彼此挨著,但不要想像檸檬在左邊或右邊,只想著它挨著香蕉。你會抗議說,這個要求是不可能實現的;如果檸檬和香蕉在一幅圖像中彼此挨著的話,其中一個只能在另一個的左邊。命題式和排列式的對比是很嚴格的。命題式可以表徵沒有咧嘴笑的貓、咧嘴笑而沒有貓或者其他任何不具形體的抽像概念:沒有特定大小的廣場,沒有特定形狀的對稱,沒有特定位置的附著物等。這就是命題式的好處:它是對某個抽像事實的嚴格陳述,不雜帶無關細節。空間排列式因為只包括填充和非填充的小片,所以它們的數據結構是事物在空間上的具體安排。心理意象也是如此:形成一個“對稱”的圖像,而不想像其中相互對稱的東西,是無法做到的。
心理意象的具體性令它們能夠像一台便利的模擬計算機一樣得以指派。艾米比阿比蓋爾有錢;阿麗西亞沒有阿比蓋爾有錢;誰是最有錢的?許多人解決這種三段論是通過在一幅心理意象中,將人物從沒錢到有錢進行排列。為什麼這樣會有用呢?想像背後的媒介中在每個位置都分配單元,並固定為二維的佈置。這種排列方式,能夠為我們在思考的過程中免費提供許多幾何上的現象加以應用。例如,空間中從左到右的佈置是可傳遞的:如果A在B的左邊,B在C的左邊,那麼A就在C的左邊。任何在排列中找到形狀位置的查詢機制都會自動注意到可傳遞性;媒介的架構使其別無選擇。
假設大腦的推理中心能夠作用於將形狀放在排列中的機制,這個機制還可以從中讀取它們的位置。那些推理守護程序可以利用排列的幾何特徵作為孵化室,來記住某些邏輯約束。財富就像線上的位置一樣,是可以傳遞的:如果A比B有錢,B比C有錢,那麼A比C有錢。通過用圖像中的位置來將財富符號化,思考者利用了排列中位置可傳遞性的優勢,而不必將其放入推導的連續步驟中。問題轉變成放置和查找的過程。這是一個很好的例子,說明心理表徵的形式如何確定什麼思考起來比較簡單或比較困難。
心理意象與排列式的類似之處還在於將大小、形狀、位置和朝向糅合為一個輪廓模式,而不是清晰地將它們分解為分隔的論斷。心理旋轉是一個很好的例子。在評估物體的形狀時,不能忽視它的朝向——假如這項信息能夠被分離出來,並且明確地被標注在一個屬於自己的陳述裡的話,那麼這會是一件簡單的事情。相反,人們必須慢慢地輕移朝向,並觀察形狀的變化。朝向並不像數字電腦中的矩陣連乘一樣需要重新計算;形狀轉得越遠,所需轉的時間就越長。排列上一定覆蓋著一個旋轉器網絡,將單元內容圍繞其中心轉換幾度。大一些的旋轉需要反覆旋轉器,類似救火時救火的人排成一隊傳遞水桶。關於人們如何解決空間問題的實驗,打開了儲備頗佳的圖像操作心理工具箱,比如變焦、收縮、淘篩、掃瞄、跟蹤和著色,判斷兩個物體是否位於同一條線,或兩團不同大小的東西是否有同樣的形狀,這樣的視覺思考將這些操作串到了心理動畫序列。
最後,圖像抓住的是物體的幾何特徵,而不是它的含義。讓人們體驗想像的可靠方法就是問他們一個物體形狀或著色的模糊細節——獵犬的耳朵、B的曲線或凍豆子的陰影。當存在一個值得注意的特點時——貓有爪子,蜜蜂有刺針——我們將它單列出來作為我們概念數據庫中的顯性陳述,以供日後即刻查詢。但如果該特點不值得注意,我們就喚起對物體表象的記憶,並運行我們對圖像的形狀分析器。檢查缺失物體先前未注意到的幾何特性是想像的一個主要功能。考斯林還證明了,這個心理過程不同於撈取明顯的事實。當我們問人們有關反覆講述事實的問題時,比如貓有沒有爪子或龍蝦有沒有尾巴,回答的速度會依賴於物體與其部分在記憶中關聯的強度。人們必須從心理數據庫中提取答案。但當問題不太尋常時,比如貓是否有腦袋或龍蝦是否有嘴,人們會尋求一個心理意象,回答速度依賴於該部分的大小;小的部分驗證起來更慢些。由於大小和形狀在圖像中被混在一起,小形狀的細節就更加難以分解。
十幾年來,哲學家們一直認為,對“心理意像是描繪還是敘述的最佳測試”就是人們能否重新解讀模糊圖像,比如鴨-兔圖(見圖4-37)。
圖4-37
如果心智只儲存描述,那麼將鴨-兔圖看成兔子的人應當只收藏了“兔子”的標籤。他的標籤中沒有任何東西涉及有關鴨子的內容,所以之後,當被問及這個形狀中是否潛伏著其他動物時,只看到兔子的人應當會感到困惑;因為模糊的幾何信息已經被拋棄了。但如果心智中儲存著圖像,幾何信息就還存在,人們應當能夠回憶起圖像來,並檢查是否有新的解釋。鴨-兔圖本身其實是一個困難的情況,因為人們儲存的形狀有一個附加的前-後參考框架,要重新解釋鴨-兔圖需要翻轉這個框架。但只要略微有一些外力(比如鼓勵人們將注意集中於腦袋後的曲線),許多人確實在兔子的圖像中看到了鴨子,相反亦然。幾乎每個人都能翻轉簡單一些的模糊圖像。心理學家羅納德·芬克(Ronald Finke)、瑪莎·法拉和我讓人們僅憑口頭語言描述就重新解讀圖像,也就是在他們閉著眼的時候,我們大聲讀出來。在下面每個描述中,你“看到”了什麼物體?
想像字母D,向右旋轉90°。在上面放上數字4。現在將這個4的水平線段移動至垂直線的右側。
想像字母B,向左旋轉90°。將一個三角形直接放在它的下面,其寬度相同、尖角朝下。移除水平線。
想像字母K,將一個正方形挨著放在它的左側。在正方形中放一個圓,再向左旋轉90°。
大多數人沒什麼困難就能說出,隱含在這些囉嗦的語言裡的信息分別是帆船、愛心和電視機。
想像是一種美妙的能力,但我們一定不要因為腦袋裡有圖像,就忘乎所以。
第一,人們不能重構一幅整個視域的圖像。圖像是殘缺的,不連續的。我們回想起模糊的部分,將它們安置在一個心理場景中,然後做一些修復的工作,在每個部分消退時進行恢復。更糟的是,每個模糊部分只記錄了從一個觀察點能看到的表面,而這是被視角所扭曲的。鐵軌悖論就是一個簡單的展示——大多數人不只在真實生活中看到軌道交匯,而且在心理意象中也看到了交匯。如果要記住一個物體,我們需要把它翻轉過來或者繞著它走一圈,這意味著我們對它的記憶是一組從不同視角觀看的照片集。整個物體的圖像是一個幻燈片展示,或是東拼西湊的大雜燴。
這就解釋了為什麼在藝術中花了那麼長的時間才發明出透視畫法,每個人都以不同的視角看東西。沒有文藝復興式技藝的繪畫看上去是不現實的,但不是因為它們完全缺乏透視角度。即使是克羅馬農人的洞穴繪畫也有對準確角度的度量。在通常情況下,遠處的物體更小,不透明的物體將背景掩蓋住,並遮住了背後的物體,而許多傾斜的表面則將透視縮短。問題是,繪畫中不同的部分看上去像是從不同的觀察點看時顯現出的樣子,而不是像從達·芬奇之窗後面的固定視覺標線所看到的樣子。人類知覺者注定一次只能看一個地方,沒有人能夠體驗到同時從幾個觀察點看一個景物,所以繪畫並不完全符合人所看到的任何東西。當然,想像並不局限於一次一個地方,沒有真實視角的繪畫或許是對我們心理意象引人回味的再現,這倒有些奇怪。立體畫派和超現實主義的畫家們是心理學的狂熱消費者,他們刻意在一幅繪畫中運用多重視角,這或許喚起了厭倦攝影的觀看者和幻滅的心智之目。
第二,圖像是記憶組織的奴隸。我們對於世界的認識不可能符合一張大圖片或地圖。這好比將太多的層級(從高山到跳蚤)塞進一個固定米粒大小的載體裡。而我們的視覺記憶也不是一個能夠很好填塞照片的鞋盒。因為那樣你會無法找到你所需要的東西,除非你逐個檢查認出裡面究竟是什麼。照片和視頻檔案也具有類似的問題。記憶圖像必須貼上標籤並在一個命題式超級結構中加以組織,或許有點兒像在超媒體中的那樣,在超媒體中圖形文件被連接到一個大文本或數據庫中的附屬點上。
視覺思考在由我們用來組織圖像的概念性知識所驅動時,往往比由圖像本身的內容所驅動更為有力。國際象棋大師們以其對棋盤上棋子的出色記憶而聞名於世,但不是有著圖像記憶的人都會成為國際象棋大師。大師們在記憶一盤隨意佈局的棋子方面並不比初學者更好。他們的記憶是抓住了棋子之間有意義的聯繫,比如棋子間的進攻和防衛,而不僅僅是棋子在空間上的分佈。
另一個例子來自心理學家雷蒙德·尼克爾森(Raymond Nickerson)和瑪麗蓮·亞當斯(Marilyn Adams)所做的一次絕妙而低技術含量的實驗。他們請人們根據記憶畫出一美分的正反兩面,這是每個人都看過幾千遍的,都應有深刻的記憶。實驗結果卻發人深省。一美分硬幣有8個特徵:一面是林肯的頭像、“我們信仰上帝”、年份和“自由”,另一面是林肯紀念堂、“美利堅合眾國”、“合眾為一”和“一分”。只有5%的被試把8個特徵全部都畫對了。特徵被記住的中數是3,而一半特徵都被畫錯了。被胡亂塞進畫中的有“一美分”、桂冠、麥束、華盛頓紀念碑,還有坐在椅子上的林肯。當被要求從一個清單中勾劃選擇一美分的特徵時,人們的表現好了一些。但當展示給他們15種可能的一美分繪圖時,只有不到一半的人選擇出了正確的那個。很顯然,視覺記憶不是記住了整個物體的準確圖像。
如果你確實畫出了正確的一美分,再來試試下面這個測試。下面5個陳述中,哪些是正確的呢?
馬德里比華盛頓特區更靠北。
西雅圖比蒙特利爾更靠北。
俄勒岡州的波特蘭比多倫多更靠北。
裡諾比聖迭戈更靠西。
巴拿馬運河的大西洋入口比它的太平洋入口更靠西。
這些陳述都是對的。但幾乎每個人都答錯了,他們的邏輯方式是這樣的:內華達在加州的東邊;聖迭戈在加州;裡諾在內華達州,所以裡諾在聖迭戈的東邊。當然,這種推論式是無效的,無論什麼時候各地區域都不會組成一個棋盤。我們的地理知識不是一個巨大的心理地圖,而是一組小地圖,根據它們如何關聯的陳述而組織起來。
第三,圖像既不能作為我們的概念,也不能作為心理字典中詞彙的含義。經驗主義哲學和心理學的悠久傳統試圖主張,圖像能夠履行這種職能,因為它符合這樣的原則:思想中沒有什麼不是來源於先前的感覺的。圖像應當是退化或附加的視覺感受拷貝、打磨鋒利的邊緣和混在一起的顏色,這樣它們就能夠代表整個類別,而不是僅代表單個物體。只要你沒有太努力思考這些復合圖像看上去如何,這個觀點就有一些可取之處。但那樣的話,人該如何表徵抽像的想法呢,即使是像三角形概念這樣簡單的東西?三角形是任何有三條邊的多邊形。但三角形的任何圖像必須是等腰的、不等邊的或者等邊的。約翰·洛克神秘地宣稱,我們對一個三角形的圖像是“同時既全是又全不是這樣”。柏克萊質疑這一點,他要求讀者形成一個三角形的心理意象,這個三角形同時既是等腰的、不等邊的和等邊的,又都不是上述任何一種。但柏克萊沒有拋棄“抽像觀點是圖像”這個理論,而是下結論說,我們沒有抽像的想法!
20世紀早期,美國最早的一位實驗心理學家愛德華·鐵欽納(Edward Titchener)對此提出了挑戰。通過仔細地內省他自己的圖像,他認為它們可以表徵任何想法,無論這個想法有多抽像:
我完全可以得到洛克的圖片,也就是一個不和任何三角形相同、卻在同時又和所有三角形相同的三角形。它是一個曇花一現的東西,轉瞬即逝;它提示了兩個或三個紅角,用紅線在黑線基礎上加深,並用暗綠色作為背景。我還不能斷定是否是這些角聯合起來形成了這個圖形,甚至也不知道是否所有這三個必要的角都是給定的。
對我來說,馬是一個雙曲線和直立姿勢,並有著可觸摸的鬃毛;奶牛是一個略長的長方形,有著某種面部表情——一種誇張的噘嘴。
我這輩子都在思考意義。不僅是意義,還有內涵。一般的意義在我意識中是由另一個印象主義圖畫表徵的。我把內涵看作是一種鏟子的藍-灰尖端,上面有一點兒黃(大概是把手的一部分),它剛剛挖到一種似乎是塑料的深色物質。我是接受古典式教育的;可以看出,這幅圖畫是對反覆訓誡要“挖掘出”一些古希臘或拉丁章節“內涵”的回音。
確實是誇張的噘嘴!鐵欽納的柴郡奶牛,他帶著的甚至沒有連在一起的紅角的三角形,還有他的內涵鏟子,都不可能是他思想背後的基礎概念。他當然不相信奶牛是長方形的或三角形的,沒有其中一個角也可以。他腦袋中的其他一些不是圖像的東西,一定包含在那個知識之中。
這就是其他認為“所有思想都是圖像”的說法的問題所在。假設我試圖用一個原型人的圖像來表示概念“男人”——比方說,弗雷德·麥克穆雷(Fred Mac Murray)。問題是,什麼使得這個圖像會履行概念“男人”的作用,而不是概念“弗雷德·麥克穆雷”的作用?或是概念“高個男人”“成年人”“人”“美國人”或是“扮演一位受巴巴拉-斯坦威克誘惑而去殺人的保險推銷員的男演員”?你區分某個人、一般意義上的人、一般意義上的美國人等都沒有困難,所以你腦袋裡一定有比一幅原型人圖片更多的東西。
另外,一個具體的圖像怎麼能表示一個抽像的概念,比如“自由”?自由女神像已經被用了;大概它可以表示“自由女神像”的概念。你用什麼來表示否定的概念,比如“不是長頸鹿”?長頸鹿的圖像上畫個紅叉嗎?那又用什麼來表示“有一個紅叉穿過的長頸鹿”的概念?選擇性的概念(比如“貓或鳥”)或命題(比如“所有人終有一死”)又該如何表示呢?
圖片是模糊的,而根據定義,思想是不會模糊的。你的常識所做的區分是圖片自身做不到的;因此你的常識不僅是圖片組成的集合。如果心理圖片被用來表示一個思想,它需要伴有文字說明,即一組關於如何解讀這幅圖片的指示說明——要注意什麼和忽略什麼。指示說明本身不能是圖片,否則我們又會兜回原點。當視覺褪去、思想開始時,我們是無法不去使用一些抽像的符號和命題,來將特定物件的部分信息提供給心智使用,以便讓它能夠對該物件進行操控。
順便說一句,圖片的模糊性已經在圖形化計算機界面和其他圖標鑲嵌的消費產品的設計者的設計中消失了。我的計算機屏幕是由一些小卡通裝飾的,它們只需鼠標點擊選擇就可以做各種事情。在我的生命中,我記不起小雙筒望遠鏡、滴管和銀盤子是用來做什麼的了。一圖抵千言,但這並不總是件好事情。在凝視和思考之間的某一點,圖像應該讓位於思想。