
僅僅幾年以前,這種被稱為「商務智能」的技術,還是大公司的專利。但隨著計算機處理器、存儲器的價格不斷下降和軟件質量的不斷上升,這種技術成了商業界的主流。大大小小的公司,都收集了前所未有的大量數據。過去,這些數據存儲在不同的系統當中,如財務系統、人力資源系統和客戶管理系統,老死不相往來。現在,這些系統彼此相連,通過「數據挖掘」的技術,可以獲得一幅關於企業運營的完整圖景,這被稱為:一致的真相(A single version of the truth)。商務智能提高了商業運營的效率,幫助了企業總結髮展過程中的模式,並改善了企業預測未來的能力。
信息技術產業把商務智能視為對20世紀上半葉企業會計服務、下半葉計算機服務的一個自然承接,正在爭相湧入這個領域。愛森哲、普華永道、IBM、SAP都在這個領域投入巨資。技術平台的提供商甲骨文、Informatica、TIBCO、SAS、EMC也從中贏利。IBM更是相信:隨著傳感器在城市交通、醫療健康中的應用,商務智能將成為其業務增長的頂樑柱。01
——《經濟學人》,2010年2月25日特別報道
聯邦政府這個數據帝國,雖然擁有的數據比任何公司、企業都多,但和私營領域相比,在信息技術的應用上,還是明顯落後一步、慢了幾拍。
2009年3月,奧巴馬就任後的第二個月,就在聯邦政府之內設立了一個全新的職位:首席信息官(Chief Information Officer),並任命來自印度的移民昆德拉(Vivek Kundra)為第一任聯邦政府首席信息官。昆德拉在公共和私營兩個領域都有廣泛的經歷,他走馬上任之後,曾發表過第一感受:聯邦政府信息技術的裝備和應用,和一流的商業公司相比,就好像手搖電話擺在了線條圓潤、光彩照人的蘋果手機旁邊,不可同日而語。
當然,這並不奇怪。現代政治學的基本常識告訴我們:由於無法引入有效的競爭機制,政府注定難逃低效的命運。美國聯邦政府也不例外。
收集數據、分析數據、發佈數據,這一系列和數據有關的信息技術,在商業界其實有個更時尚、更響亮的名字:商務智能。
在商務智能的技術大潮當中,美國聯邦政府的做法,只是幾朵小小的浪花,公司、大學才是這個領域真正的弄潮兒和領航人。
這股技術浪潮,也在美國起源。
起源:從數據到知識的挑戰和跨越
信息消費了什麼是很明顯的:它消費的是信息接受者的注意力。信息越豐富,就會導致注意力越匱乏……信息並不匱乏,匱乏的是我們處理信息的能力。我們有限的注意力是組織活動的主要瓶頸。02
——赫伯特·西蒙
美國經濟學家、政治學家、人工智能的創始人之一,1973年
1946年,人類歷史上第一台電子計算機在美國費城問世。03來自匈牙利的移民馮·諾伊曼是這台計算機的主要設計者,他被後世稱為「計算機之父」。

赫伯特·西蒙(1916-2001)
20世紀全世界最具影響力的科學家之一,他橫跨多個學科和領域,曾獲得1975年的圖靈獎、1978年的諾貝爾經濟學獎、1993年的美國心理協會終身成就獎。(圖片來源:卡內基梅隆大學圖書館)
僅一年之後,卡內基梅隆大學的赫伯特·西蒙(Herbert Simon)教授出版了《行政組織的決策過程》一書。在這本被後世視為經典的著作裡,他指出,人類的理性是有限的,因此所有的決策都是基於有限理性(Bounded Rationality)的結果。這位天才科學家繼而提出,如果能利用存儲在計算機裡的信息來輔助決策,人類理性的範圍將會擴大,決策的質量就能提高。
他進而預測:在後工業時代,也就是信息時代,人類社會面臨的中心問題將從如何提高生產率轉變為如何更好地利用信息來輔助決策。
西蒙教授畢業於芝加哥大學,1943年獲得政治學博士學位,此後半個多世紀,他長期在卡內基梅隆大學任教。
卡內基梅隆大學,是美國信息技術研究的「火車頭」,它以計算機科學和「交叉性研究」聞名於世。西蒙的整個學術生涯都浸潤著卡內基梅隆的色彩,他從政治、經濟出發,把畢生的精力都集中在對決策和信息的研究上,將不同學科之間的「交叉性」應用得爐火純青,也碩果纍纍。1975年,由於對人工智能的貢獻,他獲得了計算機學界的最高獎項:圖靈獎;1978年,他又因為對「商務決策過程」的出色研究戴上了諾貝爾經濟學獎的桂冠。
追本溯源,學界普遍認為,西蒙對決策支持系統的研究,是現代商務智能概念最早的源頭和起點。04但西蒙可能沒有想到,他播下的「決策支持」的種子,在半個世紀以後,卻結出了「商務智能」的果實,並成為信息時代的一朵奇葩。
從決策支持系統到商務智能,名字變了,但新瓶裝的還是舊酒。現代商務智能技術回答的還是決策支持系統面對的老問題:如何將數據、信息轉化為知識,擴大人類的理性,輔助決策?
從數據到知識,這個跨越,人類用了半個多世紀。
在半個多世紀的漫長過程中,決策支持系統曾經一度因為缺乏有效的數據組織方式而徘徊不前。直到上世紀90年代,由於若干新技術的出現,打破了瓶頸,「商務智能」的概念才橫空出世。隨後,其發展取得了前所未有的加速度,在本世紀第一個十年蓬勃向上。今天,回頭考察這些新技術的一一出現,可以清楚地看到商務智能的產業鏈條不斷向前延伸的軌跡。
從數據、信息到知識的演變

數據、信息和知識的區別和聯繫
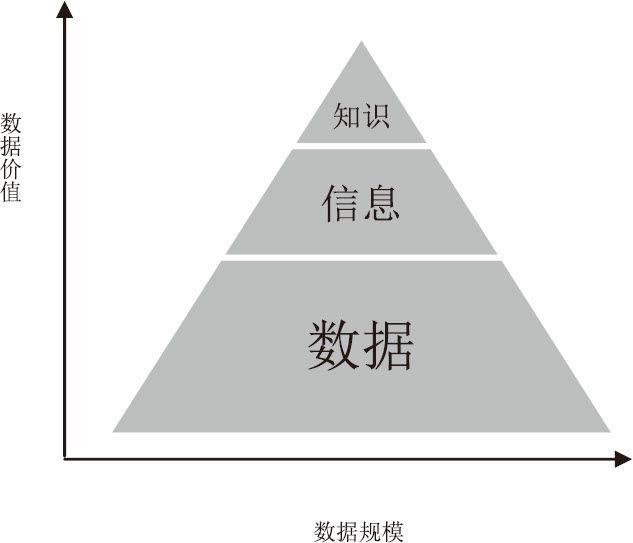
這個軌跡的起點當然就是計算機。計算機,是硬件和軟件相結合的產物。它的發明,是諸多不同領域的科學家共同努力的結果。馮·諾伊曼其實是一名數學家,他之所以被稱為「計算機之父」,其最大的貢獻之一,在於他明確了計算機內部的數據組織形式:二進制。
二進制的引進,解決了在沒有「情感、智能和生命」的物理機器中表達、計算、傳送數據的最大難題,有了二進制,軟件的運行才有了支點。
如前文所述,軟件是由程序和數據組成的。二進制的確定,解決了數據在計算機內部傳送「理解」和「流動」的問題,但當數據在計算機內部累積得越來越多的時候,如何快速地組織、存儲和讀取數據又成為新的挑戰。
計算機科學家一直在研究數據在軟件內部的最佳組織方式。1970年,IBM的研究員埃德加·科德(Edgar Codd)發明了關係型數據庫,成為軟件發展歷史上一個跨越性的里程碑。
此前,數據庫的組織結構以網狀、層級制為主,複雜多變,程序和數據之間你中有我、我中有你,彼此有很強的依賴性。科德提出的關係型數據庫具有結構化高、冗余度低、獨立性強等優點,徹底把軟件中的程序和數據分立開來。從此,軟件的發展成了「兩條腿」走路,程序和數據在各自的軌道上自由奔跑。
科德後來又總結出構建關係型數據庫的「黃金十二定律」,把理論扎扎實實地推向了實踐,關係型數據庫開始得到大範圍地推廣,引發了一場軟件領域的革命。科德也因此獲得1981年的圖靈獎。
此後,大型軟件,即大型信息管理系統的應用一日千里、遍地開花。
這些信息系統的建立和運行,使人類從繁雜的重複性勞動當中解放出來,大大提高了商業效率。但這些信息系統,都是針對特定的業務過程、處理離散事務的「運營式」信息系統。
所謂「運營式系統」,是指為提高日常工作的效率而設計的系統,數據在其中的作用,是一個個商務流程的記錄,數據在這些系統內不斷累積的結果,僅僅用於查詢,而不是分析。
上個世紀90年代,面對信息管理系統的普及、各行各業數據記錄的激增,管理大師彼得·德魯克(Peter Drucker)曾發出慨歎:迄今為止,我們的系統產生的還僅僅是數據,而不是信息,更不是知識!05
怎樣從各個獨立的信息系統中提取、整合有價值的數據,從而實現從數據到信息、從信息到知識、從知識到利潤的轉化?這個要求,隨著信息管理系統的普及,變得越來越迫切。企業的規模越來越龐大、組織越來越複雜,市場更加多變、競爭更加激烈,信息是否及時準確、決策是否正確合理,對組織的興衰存亡影響越來越大,一步走錯,可能全盤皆輸。
由於實業界這些迫切的需要,決策支持系統的舊問題又重新佔據了頂尖科學家的大腦。
商務智能的「幽靈」開始徘徊……
結蛹:數據倉庫之厚積薄發
岳不群歎了口氣,緩緩地道:「三十多年前,咱們氣宗是少數,劍宗中的師伯、師叔佔了大多數。再者,劍宗功夫易於速成,見效極快。大家都練十年,定是劍宗佔上風;各練二十年,那便是各擅勝場,難分上下;要到二十年之後,練氣宗功夫的才漸漸地越來越強;到得三十年時,練劍宗功夫的便再也不能望氣宗之項背了。然而要到二十餘年之後,才真正分出高下,這二十餘年中雙方爭鬥之烈,可想而知。」
——金庸,《笑傲江湖》第九章,1967年
決策支持系統面臨的「瓶頸式」難題,是如何有機地聚集、整合多個不同運營信息系統產生的數據。對這個問題的關注起源於美國計算機科學研究的另一所重鎮:麻省理工學院。和卡內基梅隆大學一起,這兩所大學先後為現代商務智能的發展奠定了主要的基石。
20世紀70年代,麻省理工學院的研究人員第一次提出,決策支持系統和運營信息系統截然不同,必須分開,這意味著要為前者設計獨立的數據存儲結構。但受限於當時的數據存儲能力,該研究在確立了這一論點後便停滯不前。
但這個研究如燈塔般為實業界指明了方向。1979年,一家以決策支持系統為己任、致力於構建獨立數據存儲結構的公司Teradata誕生了。Tera,是太字節,其大小為240,Teradata的命名表明了公司處理海量數據的決心。1983年,該公司利用並行處理技術為美國富國銀行(Wells Fargo Bank)建立了第一個決策支持系統。這種先發優勢令Teradata至今一直雄踞在數據行業的龍頭榜首。
另一家信息技術的巨頭——國際商業機器公司(IBM)也在為集成企業內不同的運營系統大傷腦筋。越來越多的IBM客戶要面對多個分立系統的數據整合問題,這些處理不同事務的系統,由於不同的編碼方式和數據結構,像一個個信息孤島,處於老死不相往來的狀態。1988年,為解決企業的數據集成問題,IBM公司的兩名研究員(Barry Devlin和Paul Murphy)創造性地提出了一個新的術語:數據倉庫(Data Warehouse)。
一聲驚雷,似乎宣告了數據倉庫的誕生。可惜IBM在首創這個概念之後,也停步不前,只把它當做一個花哨的新名詞用於市場宣傳,而沒有乘勝追擊、進一步提出實際的架構和設計。IBM很快在這個領域喪失其領先地位;2008年,IBM甚至通過兼併Cognos才使自己在商務智能的市場上重佔一席之地,這是後話。
但這之後,更多的信息技術企業垂涎於數據倉庫的「第一桶金」,紛紛開始嘗試搭建實驗性的數據倉庫。
又是幾年過去,1992年,塵埃終於落定。比爾·恩門(Bill Inmon)出版了《數據倉庫之構建》(Building the Data Warehouse)一書,第一次給出了數據倉庫的清晰定義和操作性很強的實戰法則,真正拉開了數據倉庫走向大規模應用的序幕。恩門不僅是長期活躍在這個領域的理論領軍人物,還是一名企業家。此後,他的「江湖地位」也得以確定,被譽為「數據倉庫之父」。
恩門所提出的定義至今仍被廣泛地接受:
「數據倉庫是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用於支持管理中的決策制定。」

比爾·恩門:數據倉庫之父
2007年曾被《計算機世界》評為近40年計算機產業最具影響力的十大人物之一,目前還活躍在數據倉庫領域,他的最新成果是將「非結構化的文本數據」通過特定的工具裝入數據倉庫。
數據倉庫和數據庫的最大差別在於,前者是以數據分析、決策支持為目的來組織存儲數據,而數據庫的主要目的則是為運營性系統保存、查詢數據。
江山代有才人出。
恩門一統江湖沒多久,風頭又被拉爾夫·金博爾(Ralph Kimball)搶了去。金博爾是斯坦福大學畢業的博士,長期在決策支持系統的軟件公司工作。1996年,他也出版了一本書:《數據倉庫的工具》(The Data Warehouse Toolkit),金博爾在書裡認同了比爾·恩門對於數據倉庫的定義,但卻在具體的構建方法上和他分庭抗禮。

拉爾夫·金博爾
他的數據倉庫構建方法目前在市場上佔據了主流。和普適計算的創始人馬克·韋澤一樣,他也曾經在施樂公司的帕羅奧多研究中心(PARC)長期工作過。(圖片來源:datamgmt.com網站)
恩門強調數據的一致性,主張由頂至底的構建方法,一上來,就要先創建企業級的數據倉庫。金博爾卻說:不!務實的數據倉庫應該從下往上,從部門到企業,並把部門級的數據倉庫叫做「數據集市」(Data Mart)。兩人針鋒相對,各自的追隨者也唇舌相向,很快形成了明顯對立的兩派。
兩派的異同,就好比華山劍法的氣宗和劍宗。主張練「氣」的著眼全面和長遠,耗資大,見效慢;主張練「劍」的強調短、平、快,效果可能立竿見影。
如金庸在《笑傲江湖》中描寫的劍氣之爭一樣,兩派華山論劍的結果不難猜測,金博爾「從易到難」的架構迎合了人類的普遍心理,大受歡迎,商務界隨即掀起了一股創建數據集市的狂潮。「吃螃蟹」的結果,有大面積的企業碰壁撞牆,也有不少企業嘗到了甜頭,賺了個盆滿缽盈。
潮起潮落中,兩派又有新的融合和紛爭。油燈越撥越亮,道理越辯越明,數據倉庫的理論和技術,在爭論中不斷地得以豐富,到2000年,其理念和架構,已經完全成熟,並被業界所接受。
如蠶之蛹,數據倉庫是商務智能的依托,是對海量數據進行分析的核心物理構架。它可以形象地理解為一種格式一致的多源數據存儲中心,數據源可以來自多個不同的系統,如企業內部的財務系統、客戶管理系統、人力資源系統,甚至是企業外部的系統;這些系統,即使運行的平台不同、編製的語言不同、所處的物理位置不同,但其數據可以按統一定義的格式被提取出來,再通過清洗、轉換、集成,最後百流歸海,加載進入數據倉庫。這個提取、轉換、裝載的主要過程,可以通過專門的ETL(Extraction, Transformation, Load)工具來實現,這種工具,如今已是數據倉庫領域的主打產品。
ETL工具和數據倉庫理論的成熟,突破了決策支持系統的瓶頸。從此,商務智能的發展走上了順風順水的「快車道」,接下來,好戲連台上演。
蠶動:聯機分析之驚艷
當越來越多的組織認識到聯機分析的需要以及其帶來的巨大收益的時候,分析型的用戶就會增加。在人類的歷史上,只有很少一部分運籌學專家曾經負有這樣的責任:為企業開展如此高端的分析。06
——埃德加·科德,關係型數據庫之父,1993年
數據倉庫的物理結構出現以後,活躍在前沿的科學家一下子找到了自己的專屬「陣地」,商務智能的下一個產業鏈:聯機分析,如水到渠成般迅速形成。數據倉庫開始散發真正的魅力。
聯機分析(Online Analytical Processing),也稱多維分析,本意是把分立的數據庫「相聯」,進行多維度地分析。
「維」是聯機分析的核心概念,指的是人們觀察事物、計算數據的特定角度。例如,跨國零售商沃爾瑪如果要分析自己的銷售量,它可以按時間序列分析、商品門類分析、地區國別分析,也可以按進貨渠道分析、客戶群體分析,這些不同的分析角度,就叫「維度」。
分析問題的任何角度,都可以視為一個或多個維度的交叉。例如:
沃爾瑪2011年在美國紐約州的銷售量是多少?這是個「地區」和「時間」兩個維度交叉的問題。
沃爾瑪2011年在紐約州奶製品的銷售量是多少?這是個「地區」、「時間」和「產品類別」三個維度交叉的問題。
沃爾瑪2011年在紐約州進口奶製品的銷售量是多少?這是個「地區」、「時間」、「產品類別」及「供貨渠道」四個維度交叉的問題。
隨著維度的不斷增多,問題可能變得很複雜。三個維度就是三度空間,也可以想像成一個立方體。一旦超過了三個維度,人類的思維和想像能力就受到了很大的限制。
理解一個維度或兩個維度的交叉
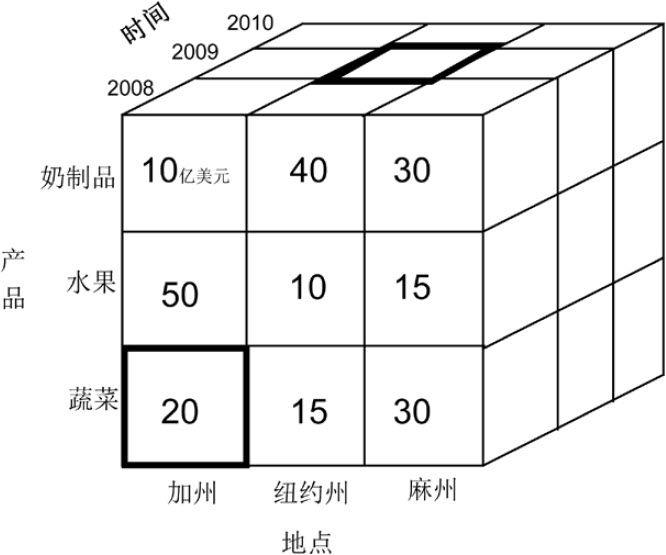
加粗方塊(上):表示2009年紐約州奶製品的銷售量
加粗方塊(下):2008年加州蔬菜的銷售量為20億美元
理解時間、產品和地點三個維度的交叉
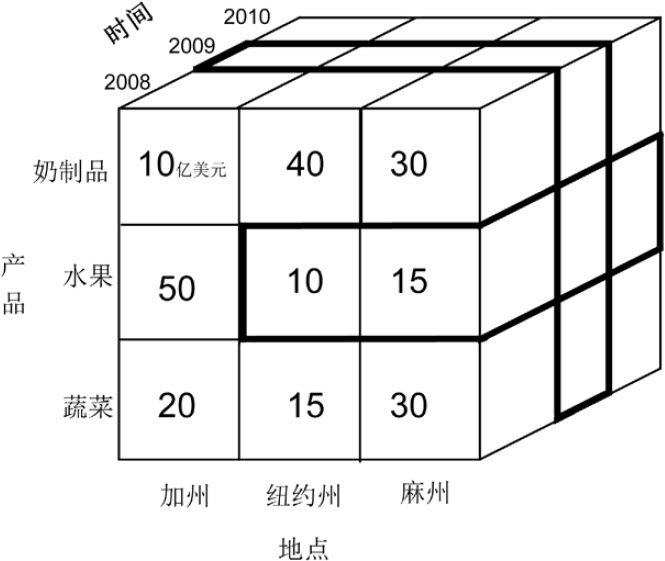
橫割(地點和產品兩個維度的交叉):所有年份(本圖只有2008年至2010年)紐約州和麻州水果的總銷量,為橫向加粗部分
豎切(時間一個維度):所有州、所有產品(本圖只有3個州、3種產品)在2009年的總銷量,為縱向加粗部分
說明:為了繪圖的方便,這個例子每一個維度只取了3個值。事實上,每個維度的值都可以無限制增加,例如,年份可以增加2005、2006、2007年等,產品可以增加甜點、咖啡等,地點可以增加佛州等。
同時,一個維度,還可以下鑽細分(drill down)。例如,就時間的維度而言,問完了一年的銷量,分析人員可能會對半年的、一個季度的銷量,甚至每個月、每一天的銷量感興趣;又如,就地點的維度而言,知道了紐約州的銷量,分析人員可能又立刻想知道某個地區、某個城市甚至某個小區的銷量。
和下鑽相對應的,是上卷(roll up),例如,從各個州的銷量,加總到全美國的銷量,就是一個典型的上卷。
理解下鑽和上卷
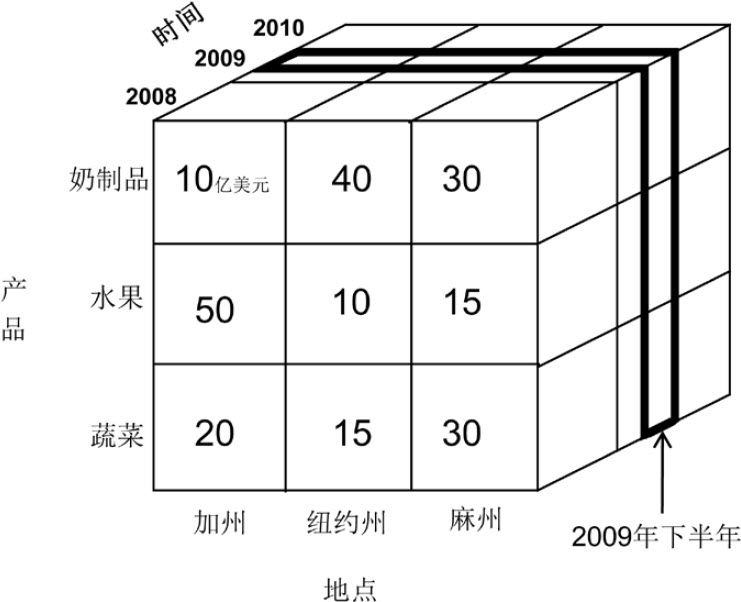
下鑽:可以按「年—半年—季度—月—日」的層級一直下鑽到每一天加粗部分:下鑽到半年——2009年下半年3個州、3種產品的總銷量
上卷:這個例子裡只有3個州,如果有50個州,就可以上捲到全國
以關係型數據庫為基礎的運營式信息系統,事實上,也可以回答以上任何一個問題,但它回答問題的方式,是通過事先設計的報表,也就是說,根據用戶指定的條件,由軟件開發人員事先一一定制,通過「一對一」的查詢,將結果通過報表的形式返回給用戶。
報表,是關係型數據庫時代將數據轉化為信息和知識最主要的手段。
基於一或兩個維度的分析,是簡單報表;交叉的維度越多,報表就越複雜,而且不同維度的組合將產生不同的報表,對一個立足於決策的用戶來說,他的需要是「動態」的:他可能問出任意維度交叉和細分的問題,但軟件開發人員只能將最常見的問題定制在軟件中。沒有定制的問題,系統就無法回答。所以,在聯機分析技術出現之前,這種靜態的、固定的報表根本無法滿足決策分析人員的全部需要。

埃德加·科德(1923-2003)
英國人,1948年移居美國,加盟IBM,因提出關係型數據庫,獲得1981年圖靈獎。1993又率先定義了「聯機分析」(OLAP)。(圖片來源:維基百科)
早在1960年代,研究人員就意識到了這種「動態」決策需求和「靜態」報表之間的矛盾,決策支持系統的先行者就開始探索聯機分析的方法。1970年,第一個聯機分析的產品就已經問世。它通過建立一個複雜的、中介性的「數據綜合引擎」,把分佈在不同系統的數據庫人為地聯結起來,實現了聯機分析。
1993年,發明關係型數據庫的科德再一次站到了創新的潮頭。他發表了論文《信息技術的必然:給分析用戶提供聯機分析》(Providing OLAP to User-Analysts: An IT Mandate),在這篇文章中,他詳盡地闡述了聯機分析的定義,並為如何構建聯機分析提出了「黃金十二定律」。他形象地比喻說:
「用關係型數據庫來分析數據,是試圖用『錘子』把一個『螺絲釘』硬生生地『敲』進牆,雖然最後可以勉強完成任務,但很費勁,為什麼不用『螺絲刀』呢?」
科德認為,聯機分析就是解決「數據分析」問題的「螺絲刀」。其驚艷之美在於用戶可以根據自己的需要隨時創建「萬維」動態報表,也就是說,報表的定制權由後台的開發人員直接轉移到了前端的用戶。
有了聯機分析,用戶可以自己隨時創建自己所需要的報表,開發人員只需要預先為用戶在後台構建多維的數據立方體(Cube)。一旦多維立方體建模完成,用戶可以在前端的各個維度之間自由切換,並可以從不同的維度、不同的粒度對數據進行分析,從而獲得全面、動態、可隨時加總或細分的分析結果。在多維立方體的構建和運算方面,曾在IBM和微軟工作過的詹姆斯·格雷(James Gray)多有貢獻,他也於1998年獲得了圖靈獎。
因為有了數據倉庫,不再需要不同數據庫之間的人為「聯機」,聯機分析找到了真正的用武之地,如有源之水,活力四射。任何複雜的報表,都可以在鼠標的瞬間點擊之下從用戶的指尖彈出,數據盡在手中,如玲瓏剔透的水晶體,任意橫切豎割,流暢的美感令人歎為觀止。
破繭:數據挖掘之智能生命的產生
每天早上一醒來,我就要問自己:怎麼才能讓數據流動得更好、管理得更好、分析得更好?07
——羅林·福特,沃爾瑪首席信息官
數據倉庫、聯機分析技術的發展和成熟,為商務智能奠定了框架,但真正給商務智能賦予「智能」生命的是它的下一個產業鏈:數據挖掘。
一開始,數據挖掘曾一度被稱為「基於數據庫的知識發現」(Knowledge discovery in database)。隨著數據倉庫的產生,「數據挖掘」的叫法開始被廣泛接受。也正是因為有了數據倉庫的依托,數據挖掘如虎添翼,如「巧婦」走進了「米倉」,在實業界不斷創造點「數」成金的故事。其中,最為經典的例子當屬啤酒和尿布。
這是一個關於零售帝國沃爾瑪的故事。
沃爾瑪,是全世界最大的零售商,擁有8400多家分店、200多萬僱員;它的人數,和美國聯邦政府的僱員等量齊觀;它的收入,2010年突破了4000億美元,超過了很多國家的GDP總值。
沃爾瑪擁有世界上數一數二的數據倉庫,是最早應用數據挖掘技術的企業之一,也是數據挖掘技術的集大成者。在一次例行的數據分析之後,研究人員突然發現:跟尿布一起搭配購買最多的商品竟是啤酒!
數據挖掘(Data Mining)
數據挖掘是指通過特定的計算機算法對大量的數據進行自動分析,從而揭示數據之間隱藏的關係、模式和趨勢,為決策者提供新的知識。
之所以稱之為「挖掘」,是比喻在海量數據中尋找知識,就像開礦掘金一樣困難。
尿布和啤酒,聽起來風馬牛不相及,但這是對歷史數據進行挖掘的結果,反映的是數據層面的規律。
這種關係令人費解,這是一個真正的規律嗎?
經過跟蹤調查,研究人員終於發現事出有因:一些年輕的爸爸經常要到超市去購買嬰兒尿布,有30%到40%的新爸爸會順便買點啤酒犒勞自己。沃爾瑪隨後對啤酒和尿布進行了捆綁銷售,不出意料,銷售量雙雙增加。
沃爾瑪還有很多利用數據挖掘擴大銷售的故事。2004年,分析人員發現,每次颶風來臨,一種袋裝小食品「Pop-Tarts」的銷售量都會明顯上升。手電筒、電池、水,這些商品的銷量會隨著颶風的到來而上升,很容易理解,但Pop-Tarts的上升是不是必然的呢?
研究人員後來發現,這也是一個有用的規律:Pop-Tarts的銷量上升,一是因為美國人喜歡甜食,二是因為它在停電時吃起來非常方便。此後,颶風來襲之前,沃爾瑪也會提高Pop-Tarts的倉儲量,以防脫銷,並把它和水捆綁起來銷售。
如果沒有數據挖掘,Pop-Tarts和颶風的微妙關係就難以被發現。
1989年,可謂數據挖掘技術興起的元年。
這一年,圖靈獎的主辦單位計算機協會(ACM)下屬的知識發現和數據挖掘小組(SIGKDD)舉辦了第一屆數據挖掘的學術年會,出版了專門期刊。此後,數據挖掘一直被熱捧,其發展如火如荼,甚至成為一門獨立的課目走進了大學課堂;在美國的不少大學,還先後設立了專門的數據挖掘碩士學位。
也正是1989年,高德納咨詢公司的德斯納(Howard Dresner)在商業界為「商務智能」給出了一個正式的定義:
「商務智能(Business Intelligence),指的是一系列以事實為支持、輔助商業決策的技術和方法。」
這個定義,強調了商務智能是一系列技術的集合,獲得了業界的廣泛認同。
商務智能的概念在1989年完全破繭而出,並不是歷史的巧合,而是因為數據挖掘這種新技術的出現,使商務智能真正具備了「智能」的內涵,也標誌著商務智能完整產業鏈的形成。
如果說聯機分析是對數據的一種透視性的探測,數據挖掘則是對數據進行挖山鑿礦式的開採。它的主要目的,一是要發現潛藏在數據表面之下的歷史規律,二是對未來進行預測,前者稱為描述性分析,後者稱為預測性分析。沃爾瑪發現的啤酒和尿布的銷售關聯性就是一種典型的描述性分析;考察所有歷史數據,以特定的算法對下個月啤酒的銷售量進行估測以確定進貨量,則是一種預測性分析。
數據挖掘把數據分析的範圍從「已知」擴大到了「未知」,從「過去」推向了「將來」,是商務智能真正的生命力和「靈魂」所在。它的發展和成熟,最終推動了商務智能在各行各業的廣泛應用。
數據挖掘的兩個側重點
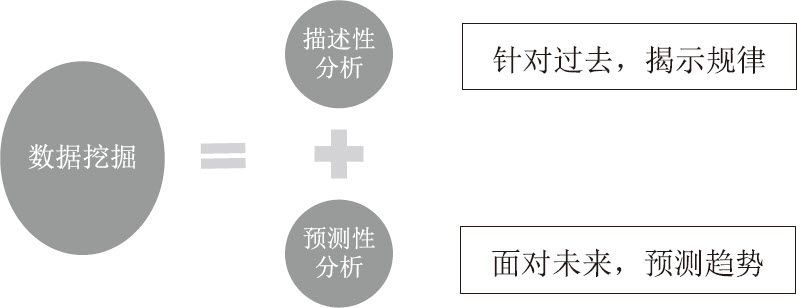
通過十多年的發展,數據挖掘的範圍正在不斷擴大。傳統的數據挖掘是指在結構化的數據當中發現潛在的關係和規律,但隨著商業競爭的白熱化,更加高端的數據挖掘也開始初現端倪。例如,通過網絡留言挖掘顧客的意見。顧客在博客、論壇、社交網站和微博上用文字記錄的消費體驗,對商品和服務發表的看法和評價,是一種非結構化的數據。如何把散佈在網絡上的這些資源整合起來,並從中自動挖掘有價值的信息和知識,正是當前數據挖掘面臨的最大挑戰之一。數據倉庫之父比爾·恩門近年來就在這個領域多有建樹。
結構化數據和非結構化數據
按結構,數據可以劃分為兩類:結構化數據和非結構化數據。
結構化數據是指存儲在數據庫當中、有統一結構和格式的數據,這種數據,比較容易分析和處理。非結構化數據是指無法用數字或統一的結構來表示的信息,包括各種文檔、圖像、音頻和視頻等,這種數據,沒有統一的大小和格式,給分析和挖掘帶來了更大的挑戰。
從結構化數據到非結構化數據的推進,也代表著可供挖掘的數據在大幅增加。
化蝶:數據可視化的華麗上演
圖形是解決邏輯問題的視覺方法。08
——傑克·伯廷(1918-2010),法國統計學家,1977年
隨著數據倉庫、聯機分析和數據挖掘技術的不斷完善,業界曾一度認為,商務智能系統已經功德圓滿,很好地完成了智能分析的使命,因此早期商務智能的產業鏈條只含有這三塊。
但技術無止境。
進入21世紀之後,風生水起,新的技術浪潮又使商務智能的產業鏈條向前延伸了一大步:數據可視化。
數據可視化(Data Visualization)
數據可視化是指以圖形、圖像、地圖、動畫等更為生動、易為理解的方式來展現數據的大小,詮釋數據之間的關係和發展的趨勢,以期更好地理解、使用數據分析的結果。
數據可視化也是幾代統計學家上百年的夢想。
故事可以追溯到19世紀中期。1850年代,土耳其、英、法等國與俄羅斯之間爆發了克里米亞戰爭。這場戰爭共死亡50多萬人,異常慘烈。弗羅倫斯·南丁格爾(Florence Nightingale)是英國的一名戰地護士,也是一名自學成才的統計專家。她在考察了英國士兵的死亡情況之後,發現由於醫療衛生條件惡劣導致的死亡人數,大大超出了前線的直接陣亡人數。南丁格爾將她的統計結果製成一個圖表,該圖表清晰地反映了「戰鬥死亡」和「非戰鬥死亡」兩種原因死亡人數的懸殊對比,強烈的視覺效果引起了英國社會的極大反響,最後直接促成了英國政府出台建立野戰醫院的決定。
南丁格爾後來被譽為現代護理業之母,她的這份圖形,是歷史上第一份「極區圖」(Polar Area Diagram),也是統計學家對利用圖形來展示數據進行的早期探索。
1854年4月至1855年3月,英國軍隊士兵的死亡原因
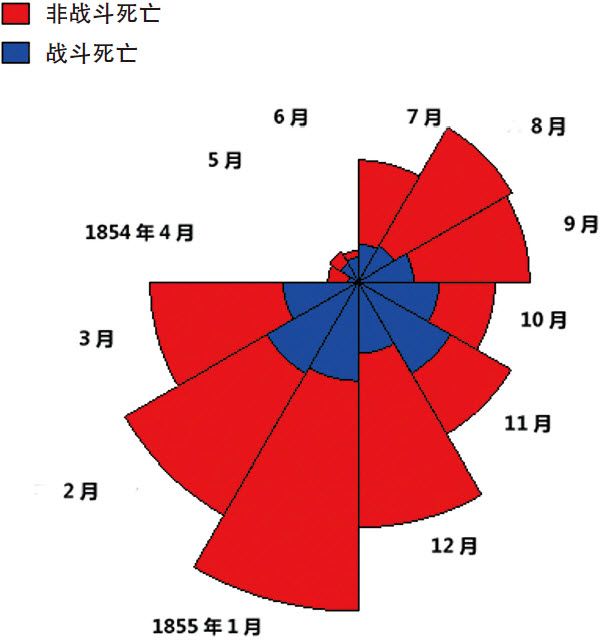
圖形說明:每月的死亡人數以30°的扇形面積表示,內環藍色代表因戰鬥死亡的人數,外環紅色代表非戰鬥死亡的人數,也就是可以預防、改善的醫療衛生原因。(圖片來源:SAS公司)
一份圖表催生了一座醫院,改變了一個制度。
南丁格爾的貢獻,充分證明了數據可視化的價值,特別是在公共領域的價值。官僚們麻木的神經尤其需要強烈的視覺效果來衝擊、來刺激。生理學也證明,人的大腦皮層當中,有40%是視覺反應區,人類的神經系統天生就對圖像化的信息最為敏感。通過圖像,信息的表達和傳遞將更加直觀、快捷、有效。
更重要的原因在於:人的創造力不僅僅取決於邏輯思維,還取決於形象思維。數據可視化的技術,可以通過圖像在邏輯思維的基礎上進一步激發人的形象思維和空間想像能力,吸引、幫助用戶洞察數據之間隱藏的關係和規律。
到了20世紀70年代,由於計算機技術的興起,美國一批有遠見卓識的學者都看到了這個領域巨大的潛力。耶魯大學的統計學教授弗朗西斯·安斯科姆(F. J. Anscombe)就是其中的先驅人物。1973年,他發表論文《統計分析中的圖形》,專門闡述了圖形在統計研究當中不可替代的作用。他認為:
「未來的計算機不僅要能計算,還要能將計算結果轉變為直觀的圖形。我們應該研究這兩種結果,因為每一種都有助於我們理解問題。」09
在這篇文章中,安斯科姆教授提出了「安斯科姆四重奏」,通過這個例子,他強調:在研究數據、使用數據的時候,圖形和計算同等重要,有的時候,圖形甚至是解決邏輯問題更為直接有效的方法。
這個著名的「四重奏」,是4組同時呈現在你面前的數據(X,Y)。
當你粗略瀏覽這4組數據之後,你會感覺其數值大多在5到11之間,比較雜亂。稍做對比,你會發現:
X1=X2=X3
X4的值,除一個之外,全部都等於8
Y1≠Y2≠Y3≠Y4
如果再進行簡單的統計學計算,很容易得到以下結果:
X1、X2、X3和X4的平均值都等於9,其方差等於10
Y1、Y2、Y3和Y4的平均值都等於7.50,其方差等於3.75
4組數據都符合線性回歸:y=3+0.5x
第一組數據

第二組數據

第三組數據

第四組數據

也就是說:
4組數據當中,X和Y之間的關係都是相同的,個別數據的偏離,可以視為隨機產生的干擾。
但當我們用散點圖把它們在坐標中標出來之後,面對圖形,就會立刻發現,統計學「欺騙」了我們:
4組數據當中,僅僅只有第一組數據嚴格符合利用統計學作出的線性回歸結論;
圖形是解決邏輯問題的視覺方法:安斯科姆四重奏的真實分佈
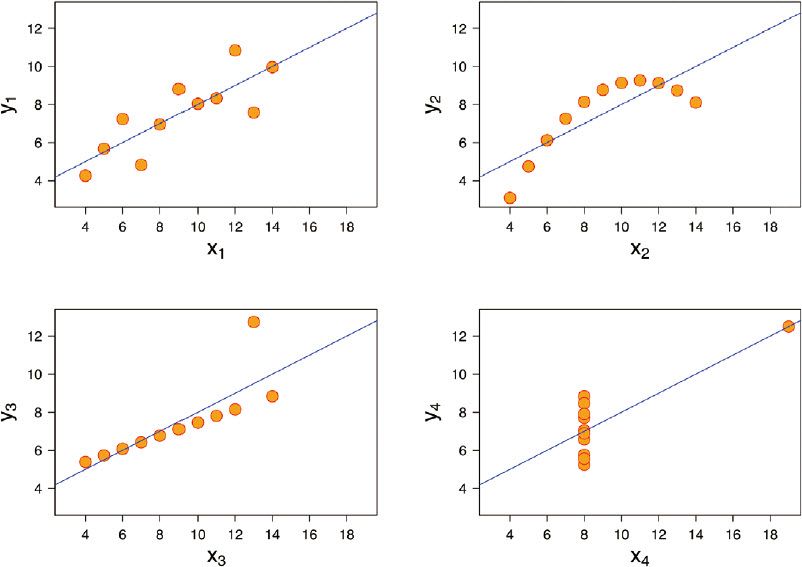
(圖片來源:維基百科)
第二組數據存在某種規律,但顯然不是線性的;
第三組數據大部分符合線性回歸的模型,但有一對數據明顯異常,它是第三對數據(13.0,12.74);
第四組數據則呈垂直分佈,其之所以貌似符合線性回歸的分佈,是因為其第8對數據(19.0,12.50)在其中起了很大的扭曲作用。
1983年,耶魯大學的政治學教授愛德華·塔夫特(Edward Tufte)率先奠基了數據可視化這門學科。塔夫特系統地考證了人類用「圖形」表達「數據」和「思想」的淵源,整理了種種歷史古籍中的圖形瑰寶,並結合計算機的發展給統計領域帶來的革命,出版了《定量信息的視覺展示》(The Visual Display of Quantitative Information)一書。這本書後來被公認為「數據可視化」作為一門學科的開山之作。
這本書的出版,也有一段曲折。因為塔夫特整理了從古到今很多優秀的圖表,他堅持要在新書中使用高質量、高精度的彩色插圖,幾乎所有的出版商都認為這是賠本買賣,沒人願意出版。塔夫特最後無計可施,用自己的房子做了抵押,自費出版了這本書。
結果當然令出版商大跌眼鏡:這本書最終獲得了很大的商業成功,塔夫特教授也由「政治學」專家成功轉型為「信息學」專家。近十多年來,他又先後出版了《視覺解釋》(Visual Explanations)、《美麗的證據》(Beautiful Evidence)等幾本重量級的著作,本本都洛陽紙貴,造成了不小的轟動。他本人也成了數據可視化領域當仁不讓的掌門人。2010年3月,奧巴馬任命塔夫特為顧問,要求他運用「數據可視化」的技術推進聯邦政府專項資金使用情況的透明度。
塔夫特教授強調數據可視化的關鍵在於「設計」,他認為:
「信息過載這回事並不存在,問題出在糟糕的設計,如果你用來表達數據的圖形讓人感覺雜亂不解,那就要修改你的設計。」10
進入21世紀之後,大數據的爆炸使人們急需展示數據、理解數據、演繹數據的工具。這種需求,刺激了數據可視化專業市場的形成,其產品迅速增多,使現在的市場可謂絢麗多彩、百花齊放。從最早的點線圖、直方圖、餅圖、網狀圖等簡單圖表,發展到以監控商務績效為主的儀表盤(dashboard)、記分板(scorecard),到以交互式的三維地圖、動態模擬、動畫技術等等更加直覺化、趣味化的表現方法,曾經冰冷堅硬、枯燥乏味的數據開始「動」了起來、「舞」了起來,變得「性感」!
數據可視化把美學的元素帶進了商務智能,給它錦上添花。一幅好的數據圖像不僅能有效地傳達數據背後的知識和思想,而且華美精緻,如一隻隻振動翅膀的彩蝶,刺激視覺神經,調動美學意識,令人過目不忘,留下栩栩如生的印象。
2010年2月,奧巴馬宣佈了聯邦政府新的年度預算。《華盛頓郵報》立即對這份新鮮出爐的預算進行了分析報道,它利用數據可視化的技術,抓住了讀者的眼球。在圖形中以線條的粗細表明各項收支金額的大小,左邊是收,右邊是支,中間的紅色部分是赤字缺口,形象貼切。奧巴馬政府收入多少錢,要辦哪些事,各項收入與支出的輕重大小,一目瞭然。
奧巴馬政府2011年度預算開支的可視化展示
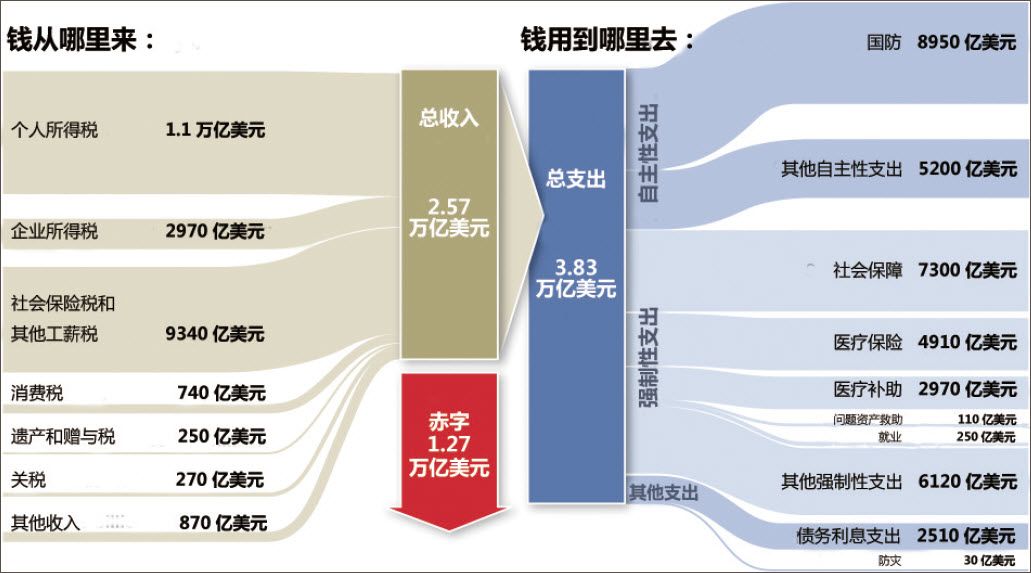
說明:一眼就可以看出,赤字約占美國總支出的1/3,個人所得稅是美國政府最大的財政來源,而國防支出是其最大的支出。(圖片來源:《華盛頓郵報》,2010年2月1日11)
2012年2月,《紐約時報》又用另外一種形式對2013年聯邦政府的預算進行了可視化展示。他們用圓形的大小表示金額的多少,顏色表示增減,綠色代表增加,紅色代表縮減,變化額度越大,則顏色越深,而且整個圖形是動態的,會放大、縮小、移動,也引起了很多讀者的興趣和轉載。12
每年的10月,諾貝爾獎花落誰家是全世界的熱門話題。2011年10月,《福布斯》(Forbes)對100多年來各項諾貝爾獎的獲得情況做了一個可視化的展示。這是一個以時間為橫坐標、以大獎得主的國籍為縱坐標的散點圖。不難看出,1940年以前,德國是世界科學和文化的中心,但二次世界大戰之後,這個中心毫無疑問轉移到了美國。還能看到,美國人的崛起首先在物理領域,其次是醫學領域,再次是經濟學領域。1969年,開始設立了諾貝爾經濟學獎。這之後,美國人幾乎囊括了全部的諾貝爾經濟學獎。
2013年度聯邦政府預算開支的可視化展示
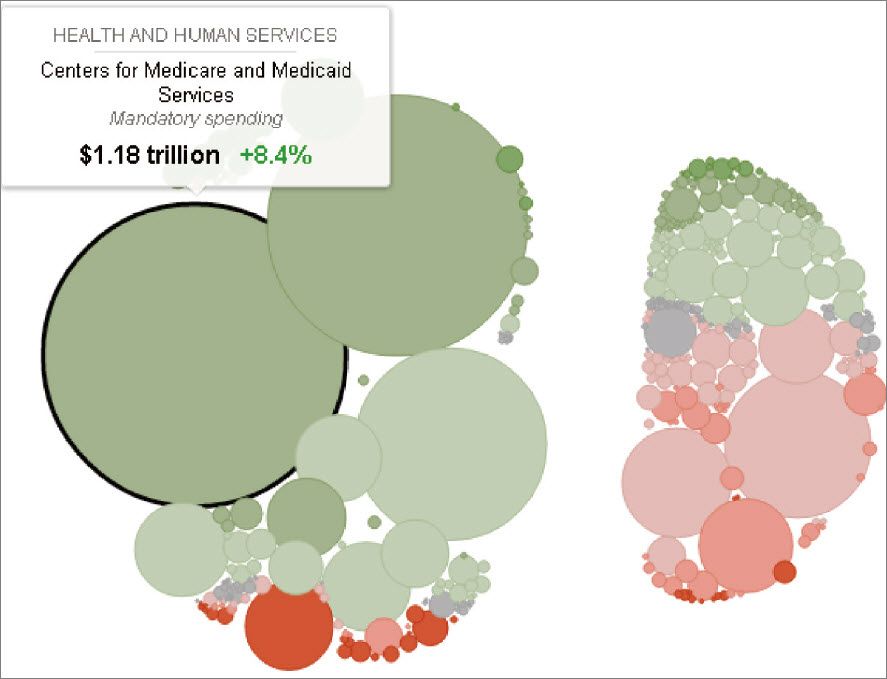
說明:左邊為強制性開支,右邊為自主性開支。強制開支中最大的圓為醫療保險和醫療補助,其為綠色,表示較去年增加了,鼠標停留處顯示其大小為1.18萬億,較去年增加了8.4%,是強制性開支中最大的一塊。圖為網站截屏。
百年諾貝爾獎得主的分佈(按國別和獎項)
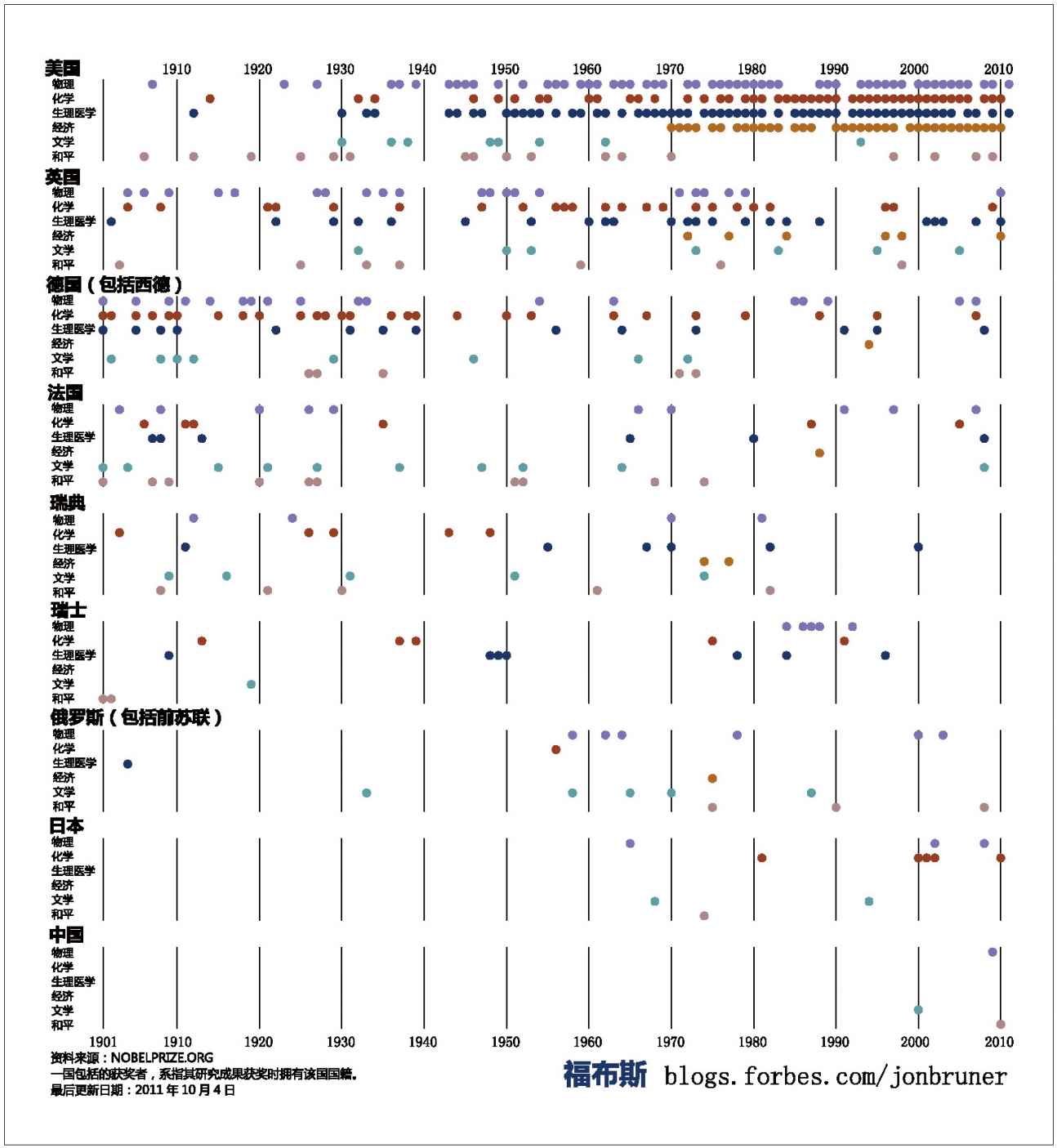
說明:獲獎人的國籍,有時候難以甄別,例如,歷史上曾出現以難民身份獲獎者。又比如,2009年,高錕獲物理學獎時,為英國國籍,但持有香港身份證並居住在香港,製作者將他歸入中國。製作者還指出:在美國的314位獲得者中,有102位(32%)是在美國本土之外出生的,其中有德裔15位、加拿大裔12位、英國裔10位、俄裔6位、華裔6位;而德國的65位獲獎者中,只有11位出生在海外;日本的獲獎者,則全是在本土出生的。(圖片來源:《福布斯》,2011年10月5日)13
作為一個新興的行業,數據可視化的發展潛力不容小覷。2010年起,谷歌的首席經濟學家范裡安(Hal Varian)就一直在多種場合強調,下一個十年,將出現一類新的專業人才:數據科學家。其中一種,正是數據可視化工程師,這種人才既懂得數據分析,又精通構圖的藝術,集故事講述和藝術家的特質於一身,將是我們大數據時代的導航員。
數據可視化的這種「導航」作用也極大地推動了商務智能的大眾化。通過把複雜的數據轉化為直觀的圖形,並呈現給最普通的用戶,商務智能已經不再是少部分高級分析人員的專利,而是貼近大眾生活、淺顯易懂、人皆可用的工具和手段。
美國聯邦政府也意識到「數據可視化」的戰略意義。2004年,聯邦政府在國土安全部成立了國家可視化分析中心(NVAC),專門推動該項技術在政府部門的應用,特別是在情報分析領域的應用。
可視化技術的出現,使商務智能的產業鏈形成了一個從數據整合、分析、挖掘到展示的完整閉環。它的起點是多個獨立的關係型數據庫,經過數據整合之後形成統一的、多源的數據倉庫,再根據用戶的需要,重新取出若干數據子集,或構造多維立方體(Cube)進行聯機分析,或進行數據挖掘,發現潛藏的規律和趨勢。如果挖掘的結果經得起現實的檢驗,那就形成了新的知識,這種知識,還可以通過數據可視化來表達、展示和傳遞。
商務智能的這四個產業鏈,每一塊都相當複雜,彼此的獨立性也很強。一個好的商務智能產品,並不見得一定要面面俱到,時下不少公司,都專注在一個鏈條上大做文章。
商務智能的歷史,是一個漸進的、複雜的演進過程。至今為止,它的內涵和外延,還處於動態的發展之中。它的各個產業鏈條,還有不斷豐富擴大的趨勢。特別是作為其「智能靈魂」的數據挖掘技術,潛力非常巨大,可以預見,將對人類社會的發展產生深遠的影響。
大數據時代的競爭,將是知識生產率的競爭。以發現新知識為使命的商務智能,無疑是這個時代最為矚目的競爭利器。
完整的商務智能流程
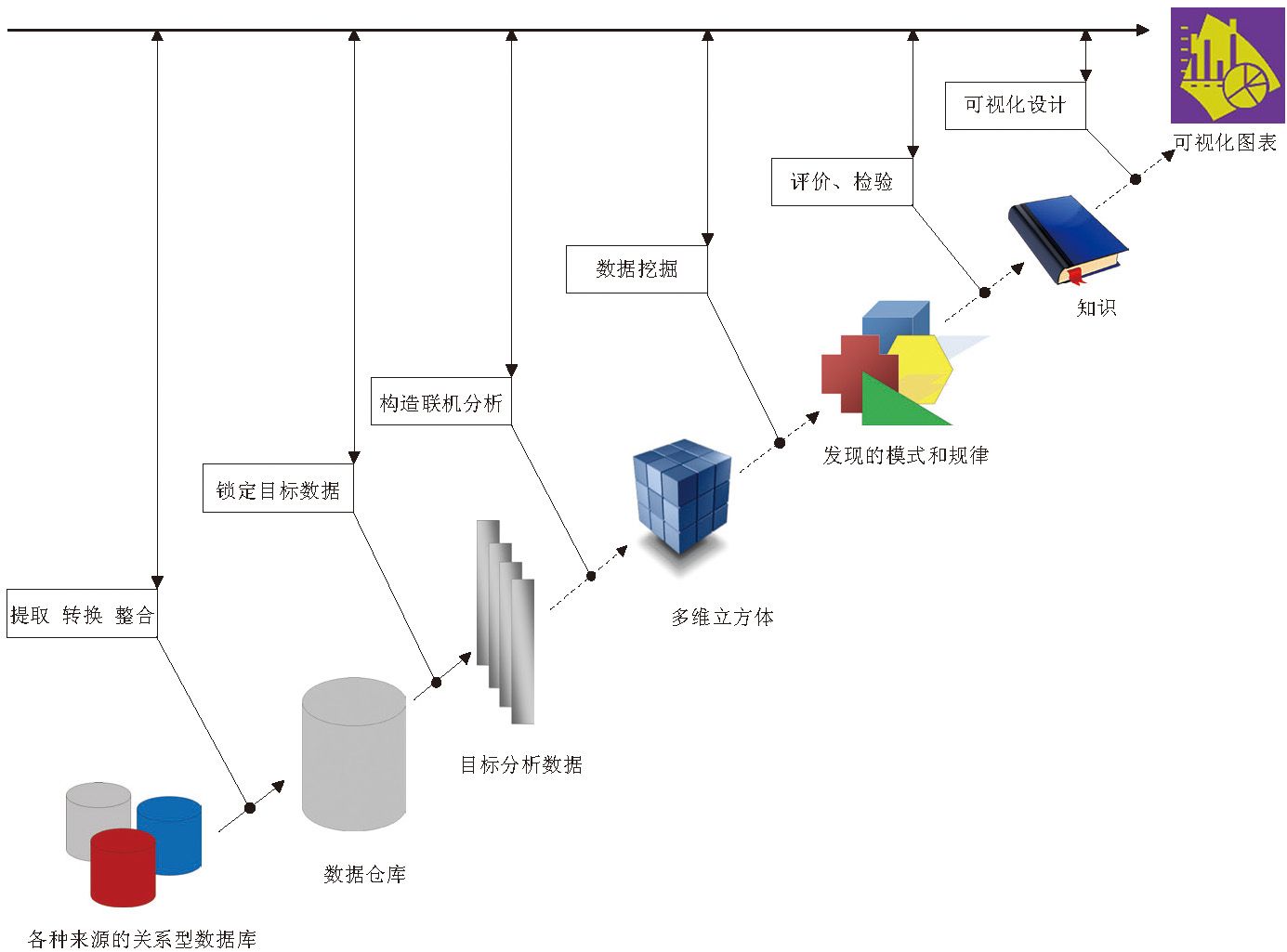
說明:虛線代表可選擇路徑