
第2章 定義數據結構
第3章 管理數據庫對像
第4章 規格化過程
第5章 操作數據
第6章 管理數據庫事務
第2章 定義數據結構
本章的重點包括:
概述表的底層數據
簡介基本的數據類型
使用不同類型的數據
展示不同數據類型之間的區別
在本章中,我們將進一步研究前一章結尾時所展示的數據,討論數據本身的特徵及其如何保存在關係型數據庫裡。數據類型有多種,稍後就會介紹。
2.1 數據是什麼
數據是一個信息集合,以某種數據類型保存在數據庫裡。數據包括姓名、數字、貨幣、文本、圖形、小數、計算、統計等,幾乎涵蓋能夠想像到的任何東西。數據可以保存為大寫、小寫或大小寫混合,數據可以被操作或修改,大多數數據在其生存週期內不會保持不變。
數據類型用於指定特定列所包含數據的規則,它決定了數據保存在列裡的方式,包括分配給列的寬度,以及值是否可以是字母、數字、日期和時間等。任何數據或數據的組合都有對應的數據類型,這些數據類型用於存儲像字母、數字、日期和時間、圖像、二進制數據等。更詳細地說,數據可以包括姓名、描述、數字、計算、圖像、圖像描述、文檔等。
數據是數據庫的意義所在,必須受到保護。數據的保護者就是數據庫管理員(DBA),但每個數據庫用戶也有責任採取必要手段來保護數據。關於數據安全的內容將在第 18 章和第19章詳細討論。
2.2 基本數據類型
本節將介紹ANSI SQL支持的基本數據類型。數據類型是數據本身的特徵,其特性被設置到表裡的字段。舉例來說,我們可以指定某個字段必須包含數字值,不允許輸入由數字或字母組成的字符串;我們也不希望在保存貨幣數值的字段裡輸入字母。為數據庫裡每個字段定義數據類型可以大幅減少數據庫裡由於輸入錯誤而產生的錯誤數據。字段定義(數據類型定義)是一種數據檢驗方式,控制了每個字段裡可以輸入的數據。
在一些RDBMS實現裡,一些數據類型可以根據其格式自動轉化為其他數據類型,這種轉換被稱為隱式轉換,表示數據庫會自動完成轉換。舉例來說,從一個數值字段取出一個數值1000.92,把它輸入到一個字符串字段裡,此時數據庫就會完成自動轉換。其他一些數據類型不能由主機 RDBMS 隱式轉換,就必須經過顯式轉換,這通常需要調用 SQL 函數,比如CAST或CONVERT,如下所示:

像其他大多數語言一樣,最基本的數據類型是:
字符串類型;
數值類型;
日期和時間類型。
提示:SQL數據類型
SQL 的每個實現都具有自己的數據類型集。使用某個實現所特有的數據類型是必要的,以支持每個實現處理存儲數據的方式策略。但基本數據類型在不同實現之間還是相同的。
2.2.1 定長字符串
定長字符串通常具有相同的長度,是使用定長數據類型保存的。下面是 SQL 定長字符串的標準:

n是一個數字,定義了字段裡能夠保存的最多字符數量。
有些SQL實現使用CHAR數據類型來保存定長數據。字母可以保存到這種數據類型裡。州名縮寫就是定長數據類型的一個例子,因為所有的縮寫都由兩個字母組成。
在定長數據類型裡,通常使用空格來填充數量不足的字符。舉例來說,如果字段長度是10,而輸入的數據只有5位,那麼剩餘5位就會被記錄為空格。填充空格確保了字段裡每個值都具有相同的長度。
警告:定長數據類型
不要使用定長數據類型來保存長度不定的數據,比如姓名。如果不恰當地使用定長數據類型,可能會導致浪費可用空間,以及影響對不同的數據進行精確比較。
應該使用變長數據類型來保存長度不定的字符串,從而節省數據庫空間。
2.2.2 變長字符串
SQL支持變長字符串,也就是長度不固定的字符串。下面是SQL變長字符串的標準:

n是一個數字,表示字段裡能夠保存的最多字符數量。
常見的變長字符串數據類型有VARCHAR、VARINARY和VARCHAR2。VARCHAR是ANSI標準,Microsoft SQL Server和MySQL也使用它;VARINARY和VARCHAR2都是由Oracle 使用的。定義為字符的字段裡可以保存數字和字母,這意味著數據中可能包含數字字符。VARBINARY類似於VARCHAR和VARCHAR2,只是它包含的是長度不定的字節。這種數據類型通常被用來保存數字式數據,例如圖像文件。
定長數據類型利用空格來填充字段裡的空白,但變長字符串不這樣做。舉例來說,如果某個變長字段的長度定義為10,而輸入的字符串長度為5,那麼這個值的總長度也就是5,這時並不會使用空格來填充字段裡的空白。
2.2.3 大對像類型
有些變長數據類型需要保存更長的數據,超過了一般情況下為VARCHAR字段所保留的長度,比如現在常見的BLOB和TEXT數據類型。這些數據類型是專門用於保存大數據集的。BLOB是二進制大對象,它的數據是很長的二進制字符串(字節串)。BLOB適合在數據庫裡存儲二進制媒體文件,比如圖像和MP3。
TEXT數據類型是一種長字符串類型,可以被看作一個大VARCHAR字段,通常用於在數據庫裡保存大字符集,比如博客站點的HTML輸入。在數據庫裡保存這種類型的數據可以實現站點的動態更新。
2.2.4 數值類型
數值被保存在定義為某種數值類型的字段裡,一般包括NUMBER、INTEGER、REAL、DECIMAL等。
下面是SQL數值的標準:

p表示字段的最大長度。
s表示小數點後面的位數。
SQL實現中一個通用的數值類型是NUMERIC,它符合ANSI標準。數值可以是0、正值、負值、定點數和浮點數。下面是使用NUMERIC的一個範例:
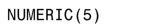
這個命令把字段能夠接受的最大值限制為 99 999。在本書範例所涉及的數據庫實現中, NUMERIC都是以DECIMAL類型實現的。
2.2.5 小數類型
小數類型是指包含小數點的數值。SQL 的小數標準如下所示,其中 p 表示有效位數,s表示標度。
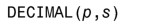
有效位數是數值的總體長度。舉例來說,在數值定義DECIMAL(4,2)裡,有效位數是4,也就是說數值總位數是4。標度是小數點後面的位數,在前例中是2。如果實際數值的小數碼數超出了定義的位數,數值就會被四捨五入。比如34.33寫入到定義為DECIMAL(3,1)的字段時,會被四捨五入為34.3。
如果數值按照如下方式被定義,其最大值就是99.99:
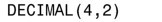
有效位數是4,表示數值的總體長度是4;標度是2,表示小數點後面保留2位。小數點本身並不算作一個字符。
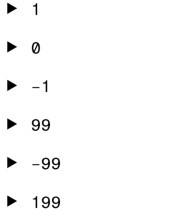
定義為DECIMAL(4,2)的字段允許輸入的數值包括:

最後一個值 12.449 在保存到字段時會被四捨五入為 12.45。在這種定義下,任何12.445~12.449之間的數值都會被四捨五入為12.45。
2.2.6 整數
整數是不包含小數點的數值(包括正數和負數)。
下面是一些有效的整數:
2.2.7 浮點數
浮點數是有效位數和標度都可變並且沒有限制的小數數值,任何有效位數和標度都是可以的。數據類型REAL代表單精度浮點數值,而DOUBLE PRECISION表示雙精度浮點數值。單精度浮點數值的有效位數為1~21(包含),雙精度浮點數值的有效位數為22~53(包含)。下面是一些FLOAT數據類型的範例:

2.2.8 日期和時間類型
日期和時間數據類型很顯然是用於保存日期和時間信息的。標準 SQL 支持 DATETIME數據類型,它包含以下類型:
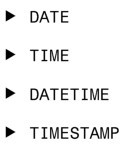
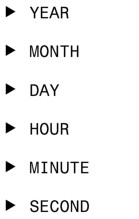
DATETIME數據類型的元素包括:
注意:日期和時間類型
SECOND元素還可以再分解為幾分之一秒,其範圍是00.000~61.999,但並不是所有SQL實現都支持這個範圍。多出來的1.999秒是用於實現閏秒的。
每種SQL實現可能都具有自定義的數據類型來保存日期和時間。前面介紹的數據類型和元素是每個 SQL 廠商都應該遵守的標準,但大多數實現都具有自己的數據類型來保存日期值,其形式與實際存儲方式有所不同。
日期數據一般不指定長度。稍後我們會更詳細地介紹日期類型,包括日期信息在某些實現裡的保存方式、如何使用轉換函數操作日期和時間,並且用範例展示在實際工作中如何使用日期和時間。
2.2.9 直義字符串
直義字符串就是一系列字符,比如姓名或電話號碼,這是由用戶或程序明確指定的。直義字符串包含的數據與前面介紹的數據類型具有一樣的屬性,但字符串的值是已知的。列本身的值通常是不能確定的,因為每一列通常包含了字段在全部記錄裡的不同值。
實際上並不需要把字段指定為直義字符串數據類型,而是指定字符串。直義字符串的範例如下所示:

字符型的字符串由單引號包圍,數值45000沒有用單引號包圍,而第二個45000用雙引號包圍了。一般來說,字符型字符串需要使用單引號,而數值型不需要。
將一個數據轉換成數值類型的過程屬於隱式轉換。在這個過程中,數據庫會自動判斷應該使用哪種數據類型。所以,如果一個數據沒有使用單引號包圍起來,那麼SQL程序就會將其認定為數值類型。因此,必須要特別留意數據的形式。否則,存儲結果可能出現偏差,或者報錯。稍後將介紹如何在數據庫查詢裡使用直義字符串。
2.2.10 NULL數據類型
第1章已經介紹過,NULL值表示沒有值。NULL值在SQL裡有廣泛的應用,包括表的創建、查詢的搜索條件,甚至是在直義字符串裡。
下面是兩種引用NULL值的方法:
NULL(關鍵字NULL本身);
下面這種形式並不代表NULL值,它只是一個包含字符N-U-L-L的直義字符串:

在使用NULL數據類型時,需要明確它表示相應字段不是必須要輸入數據的。如果某個字段必須包含數據,就把它設置為NOT NULL。只要字段有可能不包含數據,最好就把它設置為NULL。
2.2.11 布爾值
布爾值的取值範圍是TRUE、FALSE和NULL,用於進行數據比較。舉例來說,在查詢中設置條件時,每個條件都會被求值,得到TRUE、FALSE或NULL。如果查詢中所有條件的值都是TRUE,數據就會被返回;如果某個條件的值是FALSE或NULL,數據就不會返回。
比如下面這個範例:
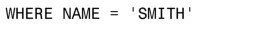
這可能是查詢裡的一個條件,目標表裡每行數據都根據這個條件進行求值。如果表裡某行的NAME字段值是SMITH,條件的值就是TRUE,相應的記錄就會被返回。
大多數數據庫實現並沒有一個嚴格意義上的BOOLEAN類型,而是代之以各自不同的實現方法。MySQL擁有BOOLEAN類型,但實質上與其現有的TINYINT類型相同。Oracle傾向於讓用戶使用一個CHAR(1)值來代替布爾值,而SQL Server則使用BIT來代替。
注意:數據類型實現上的差異
前面介紹的這些數據類型在不同的 SQL 實現裡可能具有不同的名稱,但其概念是通用的。其中大多數數據類型得到了大多數關係型數據庫的支持。
2.2.12 自定義類型
自定義類型是由用戶定義的類型,它允許用戶根據已有的數據類型來定制自己的數據類型,從而滿足數據存儲的需要。自定義類型極大地豐富了數據存儲的可能性,使開發人員在數據庫程序開發過程中具有更大的靈活性。語句CREATE TYPE用於創建自定義類型。
舉例來說,在MySQL和Oracle中,可以像下面這樣創建一個類型:

然後可以像下面這樣引用自定義類型:

表EMP_PAY第一列EMPLOYEE的類型是PERSON,這正是在前面創建的自定義類型。
2.2.13 域
域是能夠被使用的有效數據類型的集合。域與數據相關聯,從而只接受特定的數據。在域創建之後,我們可以向域添加約束。約束與數據類型共同發揮作用,從而進一步限制字段能夠接受的數據。域的使用類似於自定義類型。
像下面這樣就可以創建域:
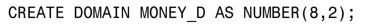
像下面這樣為域添加約束:

然後像下面這樣引用域:

2.3 小結
SQL具有多種數據類型,對於使用過其他編程語言的人來說,這些都不算陌生。數據類型允許不同類型的數據保存到數據庫,比如單個字符、小數、日期和時間。無論是使用像 C這樣的第三代編程語言,還是使用關係型數據庫實現SQL編碼,數據類型的概念都是一樣的。當然,不同實現中數據類型的名稱可能有所不同,但其工作方式基本上是一樣的。另外,關係型數據庫管理系統並不是一定要實現 ANSI 標準裡規定的全部數據類型才會被認為是與ANSI兼容的,因此最好查看具體實現的文檔來瞭解可以使用的數據類型。
在考慮數據類型、長度、標度和精度時,一定要仔細地進行短期和長遠的規劃。另外,公司制度和希望用戶以什麼方式訪問數據也是要考慮的因素。開發人員應該瞭解數據的本質,以及數據在數據庫裡是如何相互關聯的,從而使用恰當的數據類型。
2.4 問與答
問:當字段被定義為字符類型時,為什麼還可以保存像個人社會保險號碼這樣的數字值呢?
答:字符串數據類型允許輸入字母數字,而數字值當然是屬於這個範圍內的。這個過程被稱為隱式轉換,它是由數據庫系統自動完成的。一般來說,只有用於計算的數字才以數值類型保存。但從另一方面來說,把全部數值字段都設置為數值類型有助於控制字段的輸入數據。
問:定長和變長數據類型之間到底有什麼區別呢?
答:假設我們把個人姓名裡的姓字段定義為長度為20B的定義數據類型,而某人的姓是Smith。當這個數據進入表之後,會佔據20B的空間,其中5B用於保存Smith,另外15B是額外的空格(因為這是定長數據類型)。如果使用長度為 20B 的變長數據類型,並且也輸入Smith作為數據,那麼它只會佔據 5B。想像一下,如果要添加 100 000條記錄,那麼使用變長數據類型也許就會節省1.5MB。
問:數據類型的長度有限制嗎?
答:當然有,而且不同實現中對此限制也是有所區別的。
2.5 實踐
下面的內容包含一些測試問題和實戰練習。這些測試問題的目的在於檢驗對學習內容的理解程度。實戰練習有助於把學習的內容應用於實踐,並且鞏固對知識的掌握。在繼續學習之前請先完成測試與練習,答案請見附錄C。
2.5.1 測驗
1.判斷對錯:個人社會保險號碼,輸入格式為 '1111111111',它可以是下面任何一種數據類型:定長字符、變長字符、數值。
2.判斷對錯:數值類型的標度是指數值的總體長度。
3.所有的SQL實現都使用同樣的數據類型嗎?
4.下面定義的有效位數和標度分別是多少?

5.下面哪個數值能夠輸入到定義為DECIMAL(4,1)的字段裡?
A.16.2
B.116.2
C.16.21
D.1116.2
E.1116.21
6.什麼是數據?
2.5.2 練習
1.考慮以下字段名稱,為它們設置適當的數據類型,確定恰當的長度,並給出一些示範數據:
a)ssn
b)state
c)city
d)phone_number
e)zip
f)last_name
g)first_name
h)middle_name
i)salary
j)hourly_pay_rate
k)date_hired
2.同樣是這些字段,判斷它們應該是NULL或NOT NULL。體會在不同的應用場合,有些一般是NOT NULL的字段可能應該是NULL,反之亦然。
a)ssn
b)state
c)city
d)phone_number
e)zip
f)last_name
g)first_name
h)middle_name
i)salary
j)hourly_pay_rate
k)date_hired
3.現在要為後面的課程創建一個數據庫。在此之前,先要安裝一種數據庫實現——MySQL、Oracle或者Microsoft SQL Server。
MySQL
在Windows操作系統下,找到MySQL的安裝目錄,雙擊bin目錄,再雙擊名為mysql.exe的可執行文件。如果看到錯誤消息說“server could not be found”,就首先從 bin 目錄裡執行winmysqladmin.exe,然後輸入用戶名和密碼。在服務程序啟動之後,再從bin目錄裡執行mysql.exe。
在mysql>提示符下,輸入如下命令來創建本書練習所用的數據庫:
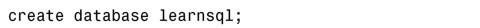
命令輸入後要按掉頭鍵。在進行本書後續的練習時,我們先要運行mysql.exe,然後在命令提示符下輸入如下命令來使用剛才創建的數據庫:

Oracle
打開網頁瀏覽器並進入管理主頁,通常管理主頁的網址是 http://127.0.0.1:8080/apex。此時會出現登錄界面,如果是第一次登錄系統,用戶名為system,密碼為安裝系統時,由用戶所設置的密碼。在管理界面中,有SQL、SQL Commands和Enter Command三種運行方式可供選擇。在命令行界面輸入以下命令並按運行鍵:

在 Oracle 中創建一個用戶後,系統會自動創建一個對應的規劃(schema)。因此,運行上述命令後,在創建了一個用戶的同時,也創建了一個名為learnsql的規劃(schema)。Oracle中的規劃(schema),相當於MySQL和Microsoft SQL Server中的數據庫。退出系統以後,以新創建的用戶身份重新登錄系統,就可以看到規劃(schema)。
Microsoft
在“開始”菜單的“運行”窗口中,輸入 SSMS.exe 並按“確定”按鈕。此時,開始運行SQL Server Management Studio。彈出的第一個對話框用於連接數據庫。此處的服務器名稱應該為“localhost”,如果系統沒有自動顯示出來,則可以手工輸入。其餘選項保持不變,單擊“連接”按鈕。此時,在界面的左側會顯示出用戶的本地數據庫實例。用鼠標右鍵單擊“localhost”,在彈出的快捷菜單中選擇“新建查詢”選項後,界面右側會打開一個查詢窗口。輸入以下命令並按F5鍵:

用鼠標右鍵單擊“localhost”下名為“數據庫”的文件夾,在彈出的快捷菜單中選擇“刷新”選項。之後單擊文件夾前面的“+”符號展開文件夾,即可看到剛剛創建的名為“learnsql”的數據庫。
第3章 管理數據庫對像
本章重點包括:
數據庫對像簡介
規劃簡介
表簡介
討論表的實質與屬性
創建和操作表的範例
討論表存儲選項
引用完整性和數據一致性的概念
本章將介紹數據庫對像:它們是什麼、它們的作用、它們如何存儲、它們之間的關係。數據庫對象是關係型數據庫的底層構架,是數據庫裡保存信息的邏輯單元。本章介紹的內容主要是圍繞表的,其他數據庫對像將在後面的章節討論。
3.1 什麼是數據庫對像
數據庫對象是數據庫裡定義的、用於存儲或引用數據的對象,比如表、視圖、簇、序列、索引和異名。本章的內容以表為主,因為它是關係型數據庫裡最主要、最簡單的數據存儲形式。
3.2 什麼是規劃
規劃是與數據庫某個用戶名相關聯的數據庫對像集合。相應的用戶名被稱為規劃所有人,或是關聯對像組的所有人。數據庫裡可以有一個或多個規劃。用戶只與同名規劃相關聯,通常情況下反之亦然。一般來說,當用戶創建一個對像時,就是在自己的規劃裡創建了它,除非明確指定在另一個規劃裡創建它。因此,根據在數據庫裡的權限,用戶可以創建、操作和刪除對象。規劃可以只包含一個表,也可以包含無數個對象,其上限由具體的SQL實現決定。
假設我們從管理員獲得了一個數據庫用戶名和密碼,用戶名是USER1。我們登錄到數據庫並創建一個名為 EMPLOYEE_TBL 的表,這時對於數據庫來說,表的實際名稱是USER1.EMPLOYEE_TBL,這個表的規劃名是USER1,也就是這個表的所有者。這樣,我們就為這個規劃創建了第一個表。
當我們訪問自己所擁有的表時(在自己的規劃裡),不必引用規劃名稱。舉例來說,使用下面兩種方式都可以引用剛才創建的表:

我們當然喜歡使用第一種方法,因為它簡單,需要敲擊鍵盤的次數比較少。如果其他用戶要訪問這個表,就必須指定規劃名稱,如下所示:

第 20 章將介紹如何分配權限,從而讓其他用戶訪問我們的表。還會介紹異名的概念,也就是讓表具有另一個名稱,使我們在訪問表時不必指定規劃名。圖3.1 展示了關係型數據庫裡的兩個規劃。
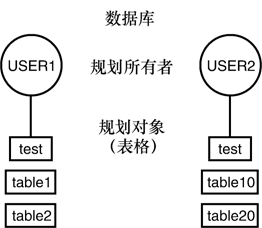
圖3.1 數據庫裡的規劃
圖3.1里的數據庫有兩個用戶賬戶:USER1和USER2。每個用戶都有自己的規劃,他們訪問自己的表和對方的表的方式如下所示:
USER1訪問自己的TABLE1: TABLE1
USER1訪問自己的TEST: TEST
USER1訪問USER2的TABLE10: USER2.TABLE10
USER1訪問USER2的TEST: USER2.TEST
在這個範例裡,兩個用戶都有一個名為TEST的表。在數據庫裡,不同的規劃中可以具有名稱相同的表。從另一個角度來說,表的名稱裡實際上包含著規劃名,所以不同規劃裡表面上同名的表實際上具有不同的名稱。比如USER1.TEST與USER2.TEST顯然是不同的。如果在訪問表時沒有指定規劃名,數據庫服務程序會默認選擇用戶所擁有的表。也就是說,如果USER1要訪問表TEST,數據庫服務程序會先查找USER1擁有的名為TEST的表,然後再查找USER1擁有的其他對象,比如指向另一個規劃裡的表的異名。第21章會詳細介紹異名的概念。用戶必須明確理解自己規劃內對像和規劃外對象的區別,如果在執行修改表的操作時沒有指定規劃名,比如使用DROP命令,數據庫會認為用戶要操作自己規劃裡的表,這可能會導致意外刪除錯誤的對象。因此,在進行數據庫操作時,一定要注意自己是以什麼身份登錄到數據庫的。
注意:對像命名規則在不同的數據庫服務程序中有所差異
每個數據庫服務程序都有命名對像和對像元素(比如字段)的規則,請查看具體實現的說明文檔來瞭解詳細要求。
3.3 表:數據的主要存儲方式
表是關係型數據庫裡最主要的數據存儲對象,其最簡單形式是由行和列組成,分別都包含著數據。表在數據庫佔據實際的物理空間,可以是永久的或是臨時的。
3.3.1 列
字段在關係型數據庫也被稱為列,它是表的組成部分,被設置為特定的數據類型。數據類型決定了什麼樣的數據可以保存在相應的列中,從而確保了數據的完整性。
每個數據庫表都至少要包含一列。列元素在表裡用於保存特定類型的數據,比如人名或地址。舉例來說,姓名就可以作為顧客表裡一個有效的列。圖3.2展示了表裡的列。

圖3.2 列的範例
一般來說,列的名稱應該是連續的字符串,其長度在不同SQL實現中都有明確規定。我們一般使用下劃線作為分隔符,比如表示顧客姓名的列可以命名為CUSTOMER_NAME,它比CUSTOMERNAME更好一些。這樣做可以提高數據庫對象的可讀性。讀者也可以使用其他命名規則,例如駝峰匹配,以滿足特定的需求。對於一個數據庫開發團隊來說,明確一個命名規則,並在開發的全過程中嚴格遵守這一規則,是非常重要的。
列中最常見的數據類型是字符串。這種數據可以保存為大寫或小寫字符,應該根據數據的使用方式具體選擇。在大多數情況下,出於簡化和一致的目的,數據是以大寫存儲的。如果數據庫裡存儲的數據具有不同的大小寫,我們可以根據需要利用函數把數據轉化為大寫或小寫,具體函數將在第11章介紹。
列也可以指定為NULL或NOT NULL,當設置為NOT NULL時,表示其中必須包含數據;設置為NULL時,就表示可以不包含數據。NULL不是空白,而是類似於一個空的字符串,在數據庫中佔據了一個特殊的位置。因此,如果某一個位置缺少數據,就可以使用NULL。
3.3.2 行
行是數據庫表裡的一條記錄。舉例來說,顧客表裡的一行數據可能包含顧客的標識號碼、姓名、地址、電話號碼、傳真號碼等。行由字段組成,表最少可以包含一行數據,也可以包含數以百萬計的記錄。圖3.3展示了表裡的行。

圖3.3 行的範例
3.3.3 CREATE TABLE語句
SQL裡的CREATE TABLE語句用於創建表。雖然創建表的實際操作十分簡單,但在執行CREATE TABLE命令之前,應該花更多的時間和精力來設計表的結構,這樣可以節省反覆修改表結構而浪費的時間。
注意:本章所使用的數據類型
在本章的範例裡,我們使用流行的數據類型CHAR(定長字符)、VARCHAR (變長字符)、NUMBER(數值,小數和整數)和DATE(日期和時間值)。
在創建表時,需要考慮以下一些基本問題。
表裡會包含什麼類型的數據?
表的名稱是什麼?
哪個(或哪些)列組成主鍵?
列(字段)的名稱是什麼?
每一列的數據類型是什麼?
每一列的長度是多少?
表裡哪些列可以是NULL?
注意:不同的系統往往有不同的命名規則
在命名對像和其他數據庫元素時,一定要查看具體實現的規則。數據庫管理員通常會採用某種“命名規範”來決定如何命名數據庫裡的對象,以便區分它們的用途。
在考慮了這些問題之後,實際的CREATE TABLE命令就很簡單了。
創建表的基本語法如下所示:

在這個語句裡,最後一個字符是分號。此外,括號是可選的。大多數SQL實現都以某些字符來結束命令,或是把命令發送到數據庫服務程序。Oracle、Microsoft SQL Server和MySQL使用分號;而Transact-SQL、Microsoft SQL Server的ANSI SQL版本卻不強制要求。不過,最好還是使用這樣的字符來結束命令。在本書中,我們使用分號。
要創建一個名為EMPLOYEE_TBL的表,使用MySQL語法規則的代碼如下:
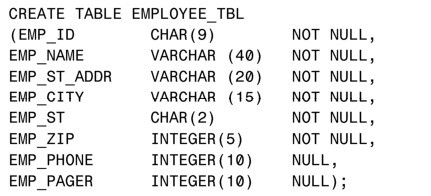
下述代碼同時適用於Oracle和Microsoft SQL Server:

這個表包含8列。列的名稱中利用下劃線對單詞進行分隔(EMPLOYEE_ID被縮寫為EMP_ID),這種方式可以讓表和列的名稱具有更好的易讀性。每一個列都設置了數據類型和長度。同時,通過使用 NULL/NOT NULL,指定了哪些字段必須包含內容。EMP_PHONE被定義為NULL,表示它的內容可以為空,因為有的人可能沒有電話號碼。各個列定義之間以逗號分隔,全部列定義都在一對圓括號裡(左括號在第一列之前,右括號在最後一列之後)。
注意:不同的實現對數據類型的規定有所不同
不同實現對於名稱長度與可使用的字符具有不同的規定。
這個表裡的每條記錄,也就是每一行數據,會包含以下內容:

在這個表裡,每個字段就是一列。列EMP_ID可能包含一個僱員的標識號碼,也可能包含多個,這取決於數據庫查詢或業務的需要。
3.3.4 命名規範
在為對像選擇名稱時,特別是表和列的名稱,應該讓名稱反應出所保存的數據。比如說,保存僱員信息的表可以命名為EMPLOYEE_TBL。列的名稱也是如此,比如保存僱員電話號碼的列,顯然命名為PHONE_NUMBER是比較合適的。
3.3.5 ALTER TABLE命令
在表被創建之後,我們可以使用ALTER TABLE命令對其進行修改。可以添加列、刪除列、修改列定義、添加和去除約束,在某些實現中還可以修改表STORAGE值。ALTER TABLE命令的標準如下所示:

一、修改表的元素
列的屬性是其所包含數據的規則和行為。利用ALTER TABLE命令可以修改列的屬性,在此“屬性”的含義是:
列的數據類型;
列的長度、有效位數或標度;
列值能否為空。
下面的範例使用ALTER TABLE命令修改表EMPLOYEE_TBL的EMP_ID列:

這一列定義的數據類型沒有變,但是長度從9變為10。
二、添加列
如果表已經包含數據,這時添加的列就不能定義為NOT NULL,這是一條基本規則。NOT NULL意味著這一列在每條記錄裡都必須包含數據。所以,在添加一條定義為NOT NULL的列時,如果現有的記錄沒有包含新列所需要的數據,我們就會陷入到自相矛盾的境地。
因此,強行向表添加一列的方法如下:
1.添加一列,把它定義為NULL(這一行不一定要包含數據);
2.給這個新列在每條記錄裡都插入數據;
3.把列的定義修改為NOT NULL。
三、添加自動增加的列
有時我們需要一列的數據能夠自動增加,從而讓每一行都具有不同的序號。在很多情況下都需要這樣做,比如數據中如果沒有適合充當主鍵的值,或是我們想利用序列號對數據進行排序。創建自動增加的列是相當簡單的。MySQL 提供了 SERIAL 方法為表生成真正的唯一值,如下所示:

注意:在創建表時使用NULL
列的默認屬性是NULL,所以在CREATE TABLE語句裡不必明確設置。但NOT NULL必須明確指定。
Microsoft SQL Server中可以使用 IDENTITY類型,代碼如下:

Oracle 沒有提供直接的方法來創建自動增加的列。但卻可以使用 SEQUENCE 對像和一個觸發器來實現類似的效果。相關內容將在第22章介紹。
下面,我們可以向新創建的表中插入記錄,而不用為自動增加的列指定值:

四、修改列
在修改現有表裡的列時,需要考慮很多因素。下面是修改列的一些通用規則:
列的長度可以增加到特定數據類型所允許的最大長度;
如果想縮短某列的長度,則必須要求這一列在表裡所有數據的長度都小於或等於新長度;
數值數據的位數可以增加;
如果要縮短數值數據的位數,則必須要求這一列在表裡所有數值的位數小於或等於新指定的位數;
數值裡的小數碼數可以增加或減少;
列的數據類型一般是可以改變的。
有些實現會限制用戶使用ALTER TABLE的某些選項。舉例來說,可能不允許從表裡撤銷列。為了繞過這種限制,我們可以撤銷整個表,然後重建新的表。如果某一列是依賴於其他表的列,或是被其他表的列所引用,在撤銷這一列時就可能發生問題。詳細情況請查看具體實現的文檔。
注意:創建練習表
在本章後面的練習裡會創建這些表。在第5章裡會向這些表填充數據。
3.3.6 從現有表新建另一個表
警告:修改或刪除表時務必小心
在修改或刪除表時一定要小心。如果在發佈這些命令時出現邏輯或輸入錯誤,就可能導致丟失重要數據。
利用CREATE TABLE語句與SELECT語句的組合可以複製現有的表。新表具有同樣的列定義,我們可以選擇任何列或全部列。由函數或多列組合創建出來的列會自動保持數據所需的大小。從另一個表創建新表的基本語法如下所示:

注意其中的一些新關鍵字,特別是SELECT。SELECT是數據庫查詢語句,將在第7章詳細介紹。現在需要掌握的就是我們可以利用查詢的結果創建一個表。
MySQL和Oracle都支持使用CREATE TABLE AS SELECT方法,在一個表的基礎上創建另一個表。但是Microsoft SQL Server卻不一樣,它使用SELECT…INTO方法來實現相同的效果。示例如下所示:

下面有一些示例使用了這種方法。
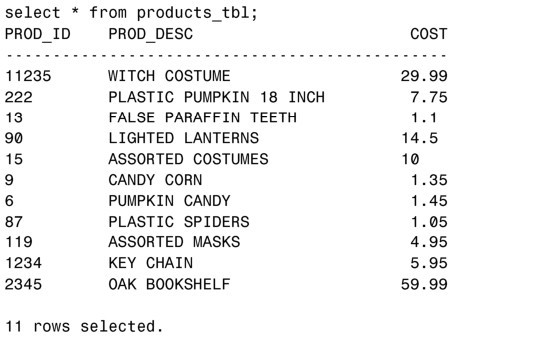
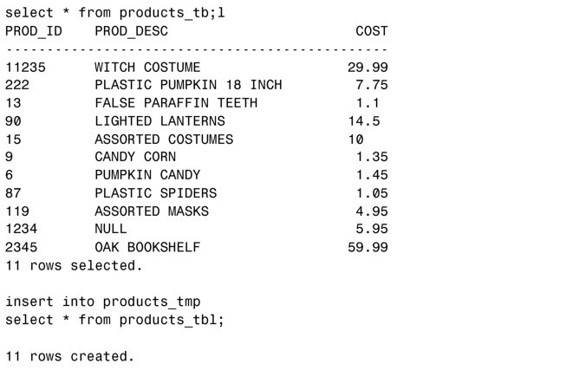
首先,我們進行一個簡單的查詢來瞭解表PRODUCTS_TBL裡的內容。
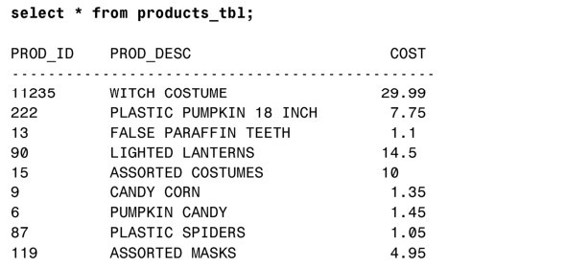
接下來,基於前面這個查詢創建名為PRODUCTS_TMP的表:

在SQL Server中,需要使用如下命令:

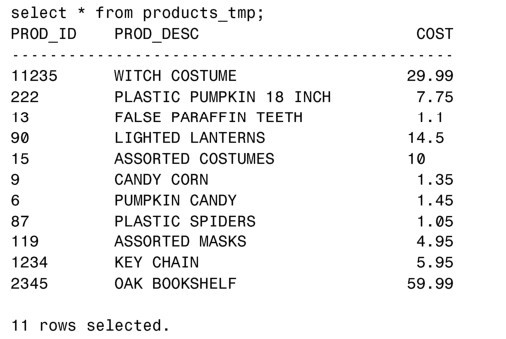
現在,如果對表PRODUCTS_TMP進行查詢,得到的數據與原始表是一樣的。
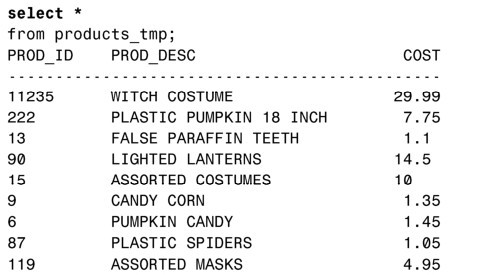
注意:“*”的意義
SELECT *會選擇指定表裡全部字段的數據。“*”表示表裡的一行完整數據,也就是一條完整記錄。
注意:默認使用相同的STORAGE屬性
從現有表創建新表,新表與原始表具有一樣的屬性。
3.3.7 刪除表
刪除表是一種相當簡單的操作。如果使用了RESTRICT選項,並且表被視圖或約束所引用,DROP語句就會返回一個錯誤。當使用了CASCADE選項時,刪除操作會成功執行,而且全部引用視圖和約束都被刪除。刪除表的語法如下所示:

在SQL Server中,不能使用CASCADE選項。因此,要在SQL Server中刪除表,必須同時刪除與該表有引用關係的所有對象,以避免系統中遺留無效對象。
下面這個範例刪除剛才創建的表:

警告:刪除表的操作務必指向準確
在刪除表時,在提交命令之前要確保指定了表的規劃名或所有者,否則可能誤刪除其他的表。如果使用多用戶賬戶,在刪除表之前一定要確定使用了適當的用戶名連接數據庫。
3.4 完整性約束
完整性約束用於確定關係型數據庫裡數據的準確性和一致性。在關係型數據庫裡,數據完整性是通過引用完整性的概念實現的,而在引用完整性裡包含了很多類型。
3.4.1 主鍵約束
主鍵是表裡一個或多個用於實現記錄唯一性的字段。雖然主鍵通常是由一個字段構成的,但也可以由多個字段組成。舉例來說,僱員的社會保險號碼或僱員被分配的標識號碼都可以在僱員表裡作為主鍵。主鍵的作用在於表裡每條記錄都具有唯一的值。由於在僱員表裡一般不會出現用多條記錄表示一個僱員的情況,所以僱員的標識號碼可以作為主鍵。主鍵是在創建表時指定的。
下面的範例把字段EMP_ID指定為表EMPLOYEES_TBL的主鍵(PRIMARY KEY):
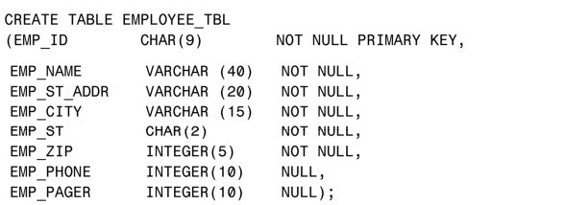
這種定義主鍵的方法是在創建表的過程中完成的,這時主鍵是個隱含約束。我們還可以在創建表時明確地指定主鍵作為一個約束,如下所示:
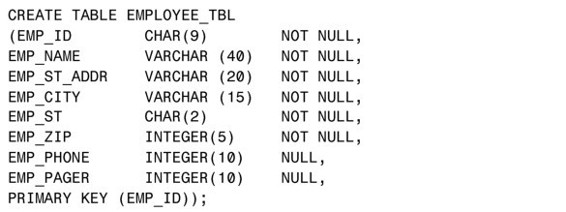
在這個範例裡,主鍵約束是在CREATE TABLE語句裡的字段列表之後定義的。
包含多個字段的主鍵可以用如下兩種方法之一來定義,以下示例適用於Oracle數據庫:
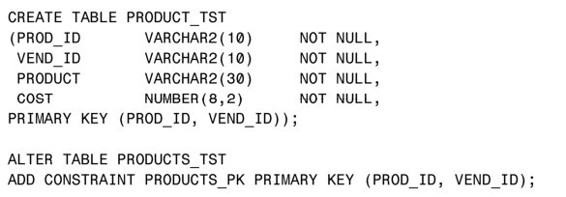
3.4.2 唯一性約束
唯一性約束要求表裡某個字段的值在每條記錄裡都是唯一的,這一點與主鍵類似。即使我們對一個字段設置了主鍵約束,也可以對另一個字段設置唯一性約束,儘管它不會被當作主鍵使用。
研究下面這個範例:

在這個範例裡,主鍵是EMP_ID字段,表示僱員標識號碼,用於確保表裡的每條記錄都是唯一的。主鍵通常是在查詢裡引用的字段,特別是用於結合表時。字段EMP_PHONE也會定義為UNIQUE,表示任意兩個僱員都不能有相同的電話號碼。這兩個都具有唯一性的字段之間沒有太多的區別,只是主鍵讓表具有了一定的秩序,並且可以用於結合相互關聯的表。
3.4.3 外鍵約束
外鍵是子表裡的一個字段,引用父表裡的主鍵。外鍵約束是確保表與表之間引用完整性的主要機制。一個被定義為外鍵的字段用於引用另一個表裡的主鍵。
研究下面範例裡外鍵的創建:

在這個範例裡,EMP_ID 字段被定義為表 EMPLOYEE_PAY_TBL 的外鍵,它引用了表EMPLOYEE_TBL 裡的 EMP_ID 字段。這個外鍵確保了表 EMPLOYEE_PAY_TBL 裡的每個EMP_ID 都在表 EMPLOYEE_TBL 裡有對應的 EMP_ID。這被稱為父/子關係,其中父表是EMPLOYEE_TBL,子表是EMPLOYEE_PAY_TBL。請觀察表3.4來更好地理解父子表的關係。
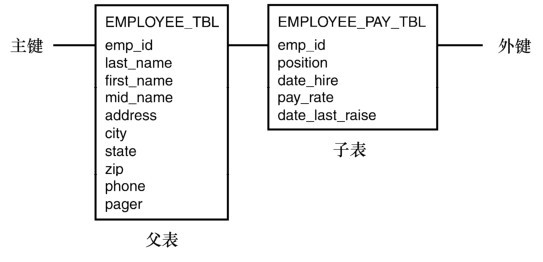
圖3.4 父/子表關係
在這個圖裡,子表裡的EMP_ID字段引用父表裡的EMP_ID字段。為了在子表裡插入一個EMP_ID的值,它首先要存在於父表的EMP_ID裡。類似地,父表裡刪除一個EMP_ID的值,子表裡相應的EMP_ID值必須全部被刪除。這就是引用完整性的概念。
利用ALTER TABLE命令可以向表裡添加外鍵,比如下面這個範例:

注意:ALTER TABLE命令在不同的SQL實現中有所不同
ALTER TABLE命令的選項在不同SQL實現裡是不同的,特別是關於約束的選項。另外,約束的實際使用與定義也有所不同,但引用完整性的概念在任何關係型數據庫裡都是一樣的。
3.4.4 NOT NULL約束
前面的範例在每個字段的數據類型之後使用了關鍵字NULL和NOT NULL。NOT NULL也是一個可以用於字段的約束,它不允許字段包含NULL值;換句話說,定義為NOT NULL的字段在每條記錄裡都必須有值。在沒有指定NOT NULL時,字段默認為NULL,也就是可以是NULL值。
3.4.5 檢查約束
檢查(CHK)約束用於檢查輸入到特定字段的數據的有效性,可以提供後端的數據庫編輯,雖然編輯通常是在前端程序裡完成的。一般情況下,編輯功能限制了能夠輸入到字段或對象的值,無論這個功能是在數據庫還是在前端程序裡實現的。檢查約束為數據提供了另一層保護。
下面的範例展示了在Oracle中,檢查約束的使用:
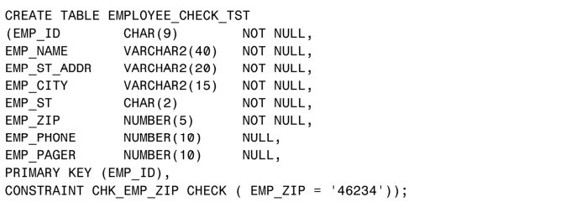
表裡的 EMP_ZIP 字段設置了檢查約束,確保了輸入到這個表裡的全部僱員的 ZIP 代碼都是“46234”。雖然這顯得有些過於嚴格,但這不要緊,足以展示如何使用檢查約束了。
如果想利用檢查約束來確保ZIP代碼屬於某個值列表,可以像下面這樣使用檢查約束:
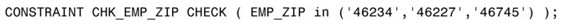
如果想指定僱員的最低小時工資,可以像下面這樣設置約束:

在這個範例裡,表裡的任何僱員的小時工資都不能低於$12.50。在檢查約束裡可以使用幾乎任何條件,就像在SQL查詢裡一樣。第5章和第7章將更詳細地介紹這些條件。
3.4.6 去除約束
利用ALTER TABLE命令的DROP CONSTRAINT選項可以去除已經定義的約束。舉例來說,如果想去除表EMPLOYEES裡的主鍵約束,可以使用下面的命令:

有些SQL實現還提供了去除特定約束的快捷方式。舉例來說,在MySQL裡可以使用下面這樣的命令來去除主鍵約束:

注意:有些實現允許中止約束,這樣我們可以選擇暫時中止它,而不是從數據庫裡去除它,稍後還可以再啟動它。
3.5 小結
本章概述了數據庫對象的基本知識,主要介紹了表。表是關係型數據庫裡最簡單的數據存儲方式,它包含成組的邏輯信息,比如僱員、顧客或產品信息。表由各種字段組成,每個字段都有自己的屬性,主要包括數據類型和約束,比如NOT NULL、主鍵、外鍵和唯一值。
本章介紹了 CREATE TABLE命令和選項,比如存儲參數。還介紹了如何使用 ALTER TABLE命令調整已有表的結構。雖然管理數據庫表的過程並不是SQL裡最基本的過程,但如果首先學習了表的結構與本質,我們就能更容易地掌握通過數據操作或數據庫查詢來訪問表的概念。下一章將介紹SQL對其他對象的管理,比如表的索引和視圖。
3.6 問與答
問:在創建表的過程中給表命名時,一定要使用像_TBL這樣的後綴嗎?
答:當然不是。沒有規定必須使用。舉例來說,保存僱員信息的表可以具有下面這些名稱,或是任何能夠說明表裡保存了何種數據的名稱:

問:在刪除表時,為什麼使用規劃名稱是非常重要的?
答:有一個 DBA 新手刪除表的真實故事:一個程序員在他的規劃下創建了一個表,其名稱與一個產品表是一樣的。這名程序員後來離開了公司,他在數據庫裡的賬戶也要被刪除,但DROP USER命令報告出錯,因為還有他擁有的對象沒有被刪除。在經過一些調查之後,這名程序員創建的表被認定是沒有用的,於是就要使用DROP TABLE命令了。
問題在於當執行DROP TABLE命令時,DBA以產品規劃登錄到數據庫。這名DBA在刪除表時,應該指定規劃名稱或所有者,但是他沒有,結果是刪除了另一個規劃裡不該刪除的表。而恢復這個表花掉了大約8個小時。
3.7 實踐
下面的內容包含一些測試問題和實戰練習。這些測試問題的目的在於檢驗對學習內容的理解程度。實戰練習是為了把學習的內容應用於實踐,並且鞏固對知識的掌握。在繼續學習之前請先完成測試與練習,答案請見附錄C。
3.7.1 測驗
1.下面這個CREATE TABLE命令能夠正常執行嗎?需要做什麼修改?在不同的數據庫(MySQL、Oracle、SQL Server)中執行,有什麼限制嗎?

2.能從表裡刪除一個字段嗎?
3.在前面的表EMPLOYEE_TBL裡創建一個主鍵約束應該使用什麼語句?
4.為了讓前面的表EMPLOYEE_TBL裡的MIDDLE_NAME字段可以接受NULL值,應該使用什麼語句?
5.為了讓前面的表 EMPLOYEE_TBL 裡添加的人員記錄只能位於紐約州(‘NY’),應該使用什麼語句?
6.要在前面的表EMPLOYEE_TBL裡添加一個名為EMPID的自動增量字段,應該使用什麼語句,才能同時符合MySQL和SQL Server的語法結構?
3.7.2 練習
通過下面的練習,讀者將創建出數據庫中所有的表,以便為後續章節提供練習環境。此外,還需要執行一些命令,來檢查表結構。為了確保準確無誤,我們分別介紹三種數據庫實現(MySQL、Microsoft SQL Server、Oracle)的操作方法,這些方法在具體的實現上會有微小的差異。
Mysql
打開命令行窗口,使用下面的命令語法登錄到本地的 MySQL,用實際的用戶名替換username,用實際的密碼替換password。注意在-p與密碼之間沒有空格。

在mysql>提示符下,輸入以下命令,告訴MySQL我們要使用哪個數據庫:

現在轉到附錄 D 來瞭解本書中所使用的 DDL。在 mysql>提示符下輸入每個 CREATE TABLE命令,注意要包含每個命令之後的分號。這些命令創建的表將用於整本書的學習。
在mysql>提示符下,輸入以下命令來列出所有的表:

在mysql>提示符下,使用DESCRIBE命令(縮寫為desc)列出每個表的全部字段和它們的屬性,如下所示:

如果遇到任何錯誤提示或輸入錯誤,只需要重新創建相應的表即可。如果表成功創建了,但有輸入錯誤(比如沒有正確地定義字段,或是漏掉了某個字段),就刪除表,再使用CREATE TABLE命令。DROP TABLE命令的語法如下所示:
Microsoft SQL Server
打開命令行窗口,使用下面的命令語法登錄到本地的SQL Server,用實際的用戶名替換username,用實際的密碼替換password。注意在-p與密碼之間沒有空格。
在1>提示符下,輸入以下命令,告訴SQL Server我們要使用哪個數據庫。在使用SQLCMD時,需要用關鍵字GO來執行輸入的命令。

現在轉到附錄D來瞭解本書中所使用的DDL。在 1>提示符下輸入每個CREATE TABLE命令,注意要包含每個命令之後的分號,最後還要使用關鍵字GO來執行命令。這些命令創建的表將用於整本書的學習。
在1>提示符下,輸入以下命令來列出所有的表。在命令後面加上關鍵字GO來執行:

在1>提示符下,使用存儲過程sp_help列出每個表的全部字段和它們的屬性,如下所示:

如果遇到任何錯誤提示或輸入錯誤,只需要重新創建相應的表即可。如果表成功創建了,但有輸入錯誤(比如沒有正確地定義字段,或是漏掉了某個字段),就刪除表,再使用CREATE TABLE命令。DROP TABLE命令的語法如下所示:
Oracle
打開命令行窗口,使用下面的命令語法登錄到本地的Oracle。輸入用戶名和密碼。

現在轉到附錄 D 來瞭解本書中所使用的 DDL。在 SQL>提示符下輸入每個 CREATE TABLE命令,注意要包含每個命令之後的分號。這些命令創建的表將用於整本書的學習。
在SQL>提示符下,輸入以下命令來列出所有的表:

在SQL>提示符下,使用DESCRIBE命令(縮寫為desc)列出每個表的全部字段和它們的屬性,如下所示:

如果遇到任何錯誤提示或輸入錯誤,只需要重新創建相應的表即可。如果表成功創建了,但有輸入錯誤(比如沒有正確地定義字段,或是漏掉了某個字段),就刪除表,再使用CREATE TABLE命令。DROP TABLE命令的語法如下所示:

第4章 規格化過程
本章的重點包括:
什麼是規格化
規格化的優點
去規格化的優點
規格化技術
規格化的方針
數據庫設計
本章介紹把原始數據庫分解為表的過程,這被稱為規格化。數據庫開發人員利用規格化過程來設計數據庫,使其更便於組織和管理,同時確保數據在整個數據庫裡的正確性。這一過程在各種RDBMS中都是一樣的。
本章會介紹規格化與去規格化的優缺點,以及規格化帶來的數據完整性與性能之間的矛盾。
4.1 規格化數據庫
規格化是去除數據庫裡冗餘數據的過程,在設計和重新設計數據庫時使用。它是一組減少數據冗余來優化數據庫的指導方針,具體的方針被稱為規格形式,稍後將詳細介紹。在本書中是否應該包含介紹規格化的內容是個兩難的決定,因為其規則對於 SQL 初學者來說過於複雜了。然而,規格化是個十分重要的過程,對它的理解會加深我們對 SQL 的掌握。本章盡量簡化對規格化的介紹,不會過於關注規格化的細節,而且著重於讓讀者理解其基本概念。
4.1.1 原始數據庫
在沒有經過規格化的數據庫裡,有些數據可能會出現在多個不同的表裡,而且沒有什麼明顯的原因。這樣對安全、磁盤利用、查詢速度、數據庫更新都不好,特別是可能產生數據完整性的問題。在規格化之前,數據庫裡的數據並沒有從邏輯上被分解到較小的、更易於管理的表裡,圖4.1展示了本書所使用的數據庫在規格化之前的狀態。

圖4.1 原始數據庫
在數據庫邏輯設計過程中,確定原始數據庫裡的信息由什麼組成是第一個也是最重要的步驟,我們必須瞭解組成數據庫的全部數據元素,才能有效地使用規格化技術。只有用必要的時間收集所需的數據集,才能避免因為丟失數據元素而重新設計數據庫。
4.1.2 數據庫邏輯設計
任何數據庫設計都要考慮到終端用戶。數據庫邏輯設計,也被稱為邏輯建模,是把數據安排到邏輯的、有組織的對象組,以便於維護的過程。數據庫的邏輯設計應該減少數據重複,甚至是完全消除這種現象。畢竟,為什麼要把數據存儲兩遍呢?另外,數據庫邏輯設計應該努力讓數據庫易於維護和更新,同時也要保持數據庫裡的命名規範與邏輯。
一、什麼是終端用戶的需求
在設計數據庫時,終端用戶的需求應該是最重要的考慮因素。記住,終端用戶是最終使用數據庫的人。利用用戶的前端工具(允許用戶訪問數據庫的客戶程序),數據庫的使用應該是相當簡單的,但是在設計數據庫時如果沒有考慮到用戶的需求,這也許就不能達到。性能優化也是如此。
在設計時要考慮的與用戶相關的因素包括:
數據庫裡應該保存什麼數據?
用戶如何訪問數據庫?
用戶需要什麼權限?
數據庫裡的數據如何分組?
哪些數據最經常被訪問?
全部數據與數據庫如何關聯?
採取什麼措施保證數據的正確性?
採取什麼措施減少數據冗余?
採取什麼措施讓負責維護數據的用戶更易於使用數據庫?
二、數據冗余
數據應該沒有冗余;這意味著重複的數據應該保持到最少,其原因有很多。舉例來說,把僱員的家庭住址保存到多個表裡就沒有意義。重複數據會佔據額外的存儲空間,而且經常會產生混亂,比如如果僱員的地址在一個表裡的內容與在另一個表裡的內容不相符時,哪一個是正確的呢?能不能找到文檔資料來確定僱員當前的地址?數據管理已經很困難了,冗餘數據會導致災難。減少冗餘數據還能簡化數據庫的更新操作。如果只有一個表保存了僱員的地址,那麼在用新地址更新了這個表之後,我們就可以確保所有人都會看到這個更新的數據。
4.1.3 規格形式
這一章討論規格形式,這是數據庫規格化過程中必不可少的一個概念。
規格形式是衡量數據庫被規格化級別(或深度)的一種方式。數據庫的規格化級別是由規格形式決定的。
下面是規格化過程中最常見的3種規格形式:
第一規格形式;
第二規格形式;
第三規格形式。
除此之外,還有其他規格形式,但都不常用。在這3種主要的規格形式中,每一種都依賴於前一種形式所採用的規格化步驟。舉例來說,如果想以第二規格形式對數據庫進行規格化,數據庫必須處於第一種規格形式。
一、第一規格形式
第一規格形式的目標是把原始數據分解到表中。在所有表都設計完成之後,給大多數表或全部表設置一個主鍵。從第3章中可以知道,主鍵必須是個唯一的值,所以在選擇主鍵時應該盡量選擇能夠從本質上唯一區別數據的元素。圖4.2展示了圖4.1所示原始數據庫使用第一規格形式重新設計之後的情況。
從圖中可以看出,為了達到第一規格形式,數據被分解為包含相關信息的邏輯單元,每個邏輯單元都有一個主鍵,而且任何表裡都沒有重複的數據組。現在的數據庫不再是一個大表,而是被分解為較小的、更易於管理的表:EMPLOYEE_TBL、CUSTOMER_TBL 和PRODUCTS_TBL。主鍵通常是表裡的第一列,本例中分別是EMP_ID、CUST_ID和PROD_ID。這種命名方式是在設計數據庫時常用的規範,確保了各種名稱的可讀性。
主鍵也可以由表中的多個列構成。這類主鍵所涉及的數據通常不是數據庫自動生成的數字,而是有邏輯意義的數據,例如生產商的名稱或者一本書的 ISBN 編號。這類數據被稱為自然主鍵,即使不在數據庫中,也可以通過它們來區分不同的對象。在為表選擇主鍵的時候,需要注意的一點就是,主鍵必須能夠唯一地定義表中的一條記錄。否則,查詢的結果可能會返回重複的記錄,而且也無法通過主鍵來刪除一條特定的記錄。
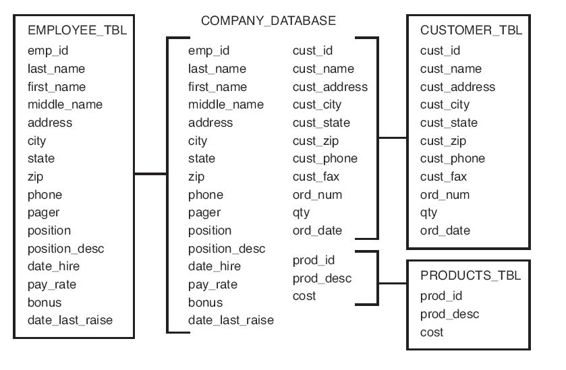
圖4.2 第一規格形式
二、第二規格形式
第二規格形式的目標是提取對主鍵僅有部分依賴的數據,把它們保存到另一個表裡。圖4.3展示了第二規格形式。
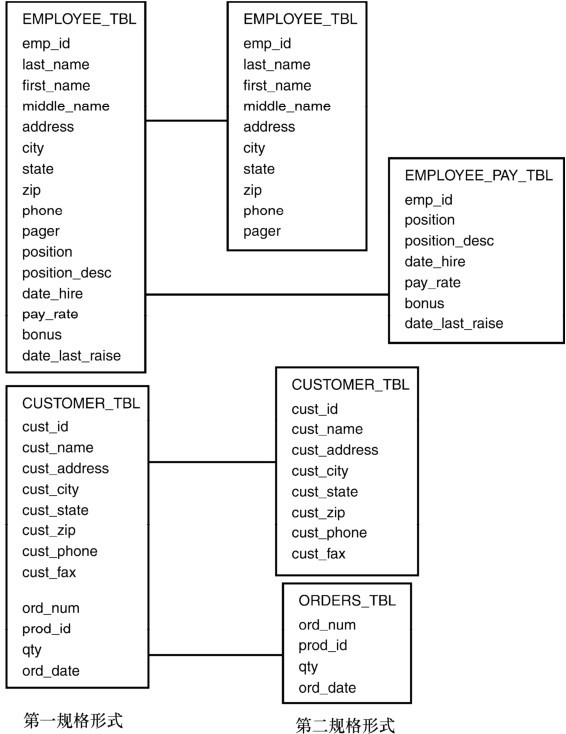
圖4.3 第二規格形式
從圖中可以看出,第二規格形式以第一規格形式為基礎,把兩個表進一步劃分為更明確的單元。
EMPLOYEE_TBL被分解為兩個表,分別是EMPLOYEE_TBL和EMPLOYEE_PAY_TBL。僱員個人信息是依賴於主鍵(EMP_ID)的,保留在EMPLOYEE_TBL表裡的都是如此(EMP_ID、LAST_NAME、FIRST_NAME、MIDDLE_NAME、ADDRESS、CITY、STATE、ZIP、PHONE和PAGER)。而在另一方面,與EMP_ID僅部分依賴的信息被轉移到EMPLOYEE_PAY_TBL(包括EMP_ID、POSITION、POSITION_DESC、DATE_HIRE、PAY_RATE和DATE_LAST_RAISE)。注意到兩個表都包含列EMP_ID,這是每個表的主鍵,用於在兩個表之間匹配對應的數據。
CUSTOMER_TBL被分解為兩個表,分別是CUSTOMER_TBL和ORDERS_TBL,具體情況類似於EMPLOYEE_TBL,僅部分依賴於主鍵的列被轉移到另一個表。顧客的訂單信息依賴於每一個CUST_ID,但與顧客的一般信息沒有直接依賴關係。
三、第三規格形式
第三規格形式的目標是刪除表裡不依賴於主鍵的數據。圖4.4展示了第三規格形式。
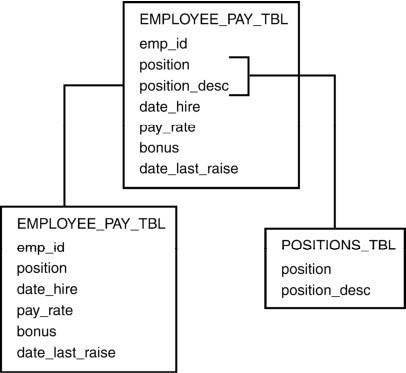
圖4.4 第三規格形式
這裡又創建了一個新表來實現第三規格形式。EMPLOYEE_PAY_TBL被分解為兩個表:一個表保存僱員的實際支付信息,另一個表保存職位描述。這的確不需要保存在EMPLOYEE_PAY_TBL裡,列POSITION_DESC與主鍵EMP_ID完全不相關。從上述介紹可以看出,規格化過程就是採取一系列步驟,把原始數據分解為由關聯數據形成的多個表。
4.1.4 命名規範
命名規範是在數據庫規格化過程中最重要的考慮因素之一。名稱是我們引用數據庫對象的方式。表的名稱應該能夠描述所保存信息的類型,以便於我們找到需要的數據。對於沒有參加數據庫設計而需要查詢數據庫的用戶來說,具有描述性的名稱更為重要。
應該在公司範圍內統一命名規範,不僅是數據庫裡表的命名,而是用戶、文件和其他相關對象的命名都應該遵守。命名規範還讓我們更容易判斷表的用途和數據庫系統裡文件的位置,從而有助於數據庫管理。設計和堅持命名規範是公司開發成功數據庫實現的第一步。
4.1.5 規格化的優點
規格化為數據庫帶來了很多好處,主要包括以下幾點:
更好的數據庫整體組織性;
減少冗餘數據;
數據庫內部的數據一致性;
更靈活的數據庫設計;
更好地處理數據庫安全;
加強引用整體性的概念。
組織性是由規格化過程所產生的,讓從訪問數據庫的用戶到負責管理數據庫所有對象的管理員(DBA)的所有人都感到更輕鬆。數據冗余被減少了,從而簡化了數據結構,節約了磁盤空間。由於重複數據被盡量減少了,所以數據不一致的可能大大降低。舉例來說,某人在一個表的姓名可能是STEVE SMITH,而在另一個表裡是STEPHEN R. SMITH。減少重複數據提高了數據完整性,或者說數據庫裡數據的一致性和準確性。數據庫規格化之後,分解為較小的表,便於我們更靈活地修改現有的結構。顯然,修改包含較少數據的小表,要比修改包含數據庫全部重要數據的一個大表要輕鬆得多。最後,DBA能夠控制特定用戶對特定表的訪問,從而提高了安全性。在進行了規格化之後,安全就更容易控制了。
引用完整性表示一個表裡某列的值依賴於另一個表裡某列的值。舉例來說,如果某個顧客要在表ORDERS_TBL裡有一條記錄,則必須首先在表CUSTOMER_TBL裡有一條記錄。完整性約束還可以限制列的取值範圍,它應該在創建表時設置。引用完整性一般是通過使用主鍵和外鍵來控制的。
在一個表裡,外鍵(通常是一個字段)直接引用另一個表裡的主鍵來實現引用完整性。在前一個圖裡,表ORDERS_TBL裡的CUST_ID就是一個外鍵,它引用表CUSTOMER_TBL裡的CUST_ID。規格化過程把數據從邏輯上分解為由主鍵引用的子集,從而有助於加強和堅持這些約束。
4.1.6 規格化的缺點
雖然大多數成功的數據庫都在一定程度上進行了規格化,但規格化的確有一個不可迴避的缺點:降低數據庫性能。性能降低的程度取決於查詢或事務被提交給數據庫的時機,其中涉及多個因素,比如 CPU 使用率、內存使用率和輸入/輸出(I/O)。簡單來說,規格化的數據庫比非規格化的數據庫需要更多的CPU、內存和I/O來處理事務和查詢。規格化的數據庫必須找到所需的表,然後把這些表的數據結合起來,從而得到需要的信息或處理相應的數據。關於數據庫性能的更詳細討論請見第18章。
4.2 去規格化數據庫
去規格化是修改規格化數據庫的表的構成,在可控制的數據冗余範圍內提高數據庫性能。嘗試提高性能是進行去規格化數據庫的唯一原因。去規格化的數據庫與沒有進行規格化的數據庫不一樣,去規格化是在數據庫規格化基礎上進行一些調整,因為規格化的數據庫需要頻繁地進行表的結合而降低了性能(關於表的結合請見第13章)。去規格化會把一些獨立的表合成在一起,或是創建重複的數據,從而減少在數據檢索時需要結合的表的數量,進而減少所需的I/O和CPU時間。這在較大的數據倉庫程序中會有明顯的好處,其中的計算可能會涉及表裡數以百萬行的數據。
去規格化也是有代價的。它增加了數據冗余,雖然提高了性能,但需要付出更多的精力來處理相關的數據。程序代碼會更加複雜,因為數據被分散到多個表,而且可能更難於定位。另外,引用完整性更加瑣碎,因為相關數據存在於多個表裡。規格化與去規格化都有好處,但都需要我們對實際的數據和公司的詳細業務需求有全面的瞭解。在確定要著手進行去規格化時,一定要仔細記錄所採取的過程,以便於更好地處理像數據冗余這樣的問題,維護系統內部的數據完整性。
4.3 小結
在進行數據庫設計時,必須做出一個困難的決定——規格化或去規格化,這的確是個問題。一般來說,數據庫問題需要進行一定程度的規格化,但到什麼程度才不至於嚴重影響性能呢?答案取決於程序本身。數據庫有多大?其用途是什麼?什麼樣的用戶要訪問數據?本章介紹了3種最常見的規格形式、規格化過程的底層概念、數據的完整性。規格化過程包含多個步驟,大多數都不是必需的,但對於數據庫的功能和性能來說都是很重要的。無論決定進行什麼程度的規格化,總是會存在便於維護與性能降低,或複雜維護與更好性能之間的平衡。最終,設計數據庫的個人(或團隊)必須做出決定,並對此負責。
4.4 問與答
問:在設計數據庫時為什麼要考慮最終用戶的需求?
答:最終用戶才是真正使用數據庫的人,從這種角度來說,他們應該是任何數據庫設計的中心。數據庫設計人員只不過是幫助組織數據而已。
問:規格化要比去規格化好嗎?
答:可能是這樣的,但是到達一定程度時,去規格化可能會更好,這其中受到很多因素的影響。我們會對數據庫進行規格化來減少其中的重複數據,到達一定程度之後可能又會轉回頭來,通過去規格化來改善性能。
4.5 實踐
下面的內容包含一些測試問題和實戰練習。這些測試問題的目的在於檢驗對學習內容的理解程度。實戰練習是為了把學習的內容應用於實踐,並且鞏固對知識的掌握。在繼續學習之前請先完成測試與練習,答案請見附錄C。
4.5.1 測驗
1.判斷正誤:規格化是把數據劃分為邏輯相關組的過程。
2.判斷正誤:讓數據庫裡沒有重複或冗餘數據,讓數據庫裡所有內容都規格化,總是最好的方式。
3.判斷正誤:如果數據是第三規格形式,它會自動屬於第一和第二規格形式。
4.與規格化數據庫相比,去規格化數據庫的主要優點是什麼?
5.去規格化的主要缺點是什麼?
6.在對數據庫進行規格化時,如何決定數據是否需要轉移到單獨的表?
7.對數據庫設計進行過度規格化的缺點是什麼?
4.5.2 練習
1.為一家小公司開發一個新數據庫,使用如下數據,對其進行規格化。記住,即使是一家小公司,其數據庫的複雜程度也會超過這裡給出的範例。
僱員:

顧客:

顧客訂單:

2.像第 3 章介紹的那樣登錄到你新建的數據庫。可以輸入以下命令來確保使用的是learnsql數據庫:

在Oracle中,這條命令意味著進入規劃。默認情況下,用戶在自己的規劃中創建對象。
進入數據庫後,根據練習 1中定義的信息,用CREATE TABLE命令創建相應的表。
第5章 操作數據
本章的重點包括:
數據操作語言概述
介紹如何操作表裡的數據
數據填充背後的概念
如何從表裡刪除數據
如何修改表裡的數據
本章介紹SQL裡的數據操作語言(DML),它用於修改關係型數據庫裡的數據和表。
5.1 數據操作概述
數據操作語言使數據庫用戶能夠對關係型數據庫裡的數據進行修改,包括用新數據填充表、更新現有表裡的數據、刪除表裡的數據。利用DML命令還可以進行簡單的數據庫查詢。
SQL裡3個基本的DML命令是:
INSERT;
UPDATE;
DELETE。
SELECT命令可以與DML命令配合使用,將在第7章詳細介紹。SELECT命令是基本的查詢命令,在 INSERT 命令把數據輸入到數據庫之後使用。所以在本章中,我們會向表中插入數據,以便能夠更好地使用SELECT命令。
5.2 用新數據填充表
用數據填充表就是把新數據輸入到表的過程,無論是使用單個命令的手工過程,還是使用程序或其他相關軟件的批處理過程。手工數據填充是指通過鍵盤輸入數據,自動填充通常是從外部數據源(比如其他數據庫或一個平面文件)獲得數據,再把得到的數據加載到數據庫。
在用數據填充表時,有很多因素會影響什麼數據以及多少數據可以輸入到表裡。主要因素包括現有的表約束、表的物理尺寸、列的數據類型、列的長度和其他完整性約束(比如主鍵和外鍵)。下面將介紹向表輸入新數據的基本知識,並且說明什麼是可以做的,而什麼是不能做的。
5.2.1 把數據插入到表
INSERT語句可以把數據插入到表,它具有一些選項,其基本語法如下所示:

注意:數據是區分大小寫的
不要忘了SQL語句無所謂是大寫的或小寫的,而數據永遠都是區分大小寫的。舉例來說,如果數據以大寫方式輸入到數據庫,它就必須以大寫方式被引用。這些範例使用了大寫和小寫字母,只是為了展示這樣做並不影響結果。
在使用這種語法時,必須在VALUES列表裡包含表裡的每個列。在這個列表裡,每個值之間是以逗號分隔的。字符、日期和時間數據類型的值必須以單引號包圍,而數值或 NULL值就不必了。表裡的每一列都應該有值,並且值的順序與列在表裡的次序一致。在後續章節中,我們會介紹如何指定列的順序。但是現階段,讀者只需要知道SQL會默認用戶在插入數據的時候,使用的是與創建列時相同的順序。
下面的範例將把一條新記錄插入到表PRODUCTS_TBL裡。
表的結構如下所示:

下面是插入語句的範例:

在這個範例裡,3個值被插入到一個具有3列的表裡,值的順序與列在表裡的次序一致。前兩個值使用了單引號包圍,因為與之對應的列的數據類型為字符型。第 3 個值對應的列COST 是數值型的,不需要使用單引號;當然,也可以使用單引號,而且不會對結果產生影響。
注意:引號的使用
數值型數據不必使用單引號,但其他數據類型都需要使用。換句話說,單引號對於數據庫裡的數值型數據來說是可選的,而對於其他數據類型來說是必需的。作為一種習慣,大多數 SQL 用戶對數值型數據不使用單引號,這樣可以提高查詢命令的可讀性。
5.2.2 給表裡指定列插入數據
有一種方法可以把數據插入到指定的列。舉例來說,我們想插入除尋呼機號碼之外的所有與僱員相關的數據,這時就必須在INSERT命令指定字段列表與值列表,如下所示:

給表中特定列插入數據的語法如下所示:

在下面的範例裡,我們向表ORDER_TBL裡的某些列插入數據。
表的結構如下所示:

INSERT的範例語句如下:

在INSERT語句裡的表名稱之後,我們在一對圓括號裡指定了要插入數據的字段列表,其中只是沒有包含ORD_DATE。通過查看表定義可以看出,表裡每條記錄的ORD_DATE字段都需要有值,這是因為它沒有被設置為NOT NULL,說明它可以是空的。注意,插入值的次序要與字段列表的次序相同。
注意:字段列表次序可以有差異
INSERT語句裡的字段列表次序並不一定要與表定義中的字段次序相同,但插入值的次序要與字段列表的次序相同。除此之外,可以不用為列指定NULL,因為大部分RDBMS在默認情況下,允許列中出現NULL值。
5.2.3 從另一個表插入數據
利用INSERT語句和SELECT語句的組合,我們可以根據對另一個表的查詢結果把數據插入到表裡。簡單來說,查詢是對數據庫的一個質詢,希望返回或不返回某些數據。關於查詢的詳細介紹請見第7章。查詢就是用戶向數據庫提出的一個問題,而返回的數據就是答案。通過組合使用INSERT和SELECT語句,我們可以把從一個表的查詢結果插入到另一個表裡。
從另一個表插入數據的語法如下所示:

這裡有3個新的關鍵字,分別是SELECT、FROM和WHERE,在此做一簡要介紹。SELECT是SQL裡執行查詢的主要命令;FROM是查詢中的一個子句,用於指定要進行查詢的表的名稱;WHERE 子句也是查詢的一部分,用於設置查詢的條件。條件用於設置一個標準,從而決定哪些數據會受到影響,比如:WHERE NAME = 'SMITH'。這 3個關鍵字將在第 7章和第8章詳細介紹。
下面的範例使用一個簡單的查詢來查看表 PRODUCTS_TBL裡的全部數據。SELECT *告訴數據庫服務程序返回表裡所有字段的數據。在此沒有使用WHERE子句,所以會得到表裡的全部記錄。
現在基於上述查詢向表PRODUCTS_TMP裡插入數據,可以看到這個表裡創建了11條記錄。

在採用這種語法時,必須確保查詢返回的字段與表裡的字段或INSERT語句裡指定的字段列表具有相同的次序。另外,還要確定SELECT語句返回的數據與要插入數據的表的字段具有兼容的數據類型。舉例來說,如果想把一個值為'ABC'的 VARCHAR 字段插入到一個數值字段,就會導致語句失敗。
下面的查詢顯示出表PRODUCTS_TMP裡剛剛插入的數據:
5.2.4 插入NULL值
向表裡的字段插入NULL值是相當簡單的。當某一列的值不能確定時,我們可能需要向它插入一個NULL值。舉例來說,不是每個人都有尋呼機,輸入一個錯誤尋呼號碼是不正確的,更何況這樣會浪費存儲空間。利用關鍵字NULL可以在列裡插入NULL值。
插入NULL值的語法如下所示:
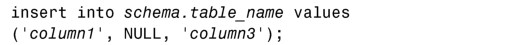
關鍵字NULL應該位於正確的次序上,相應的字段會沒有值的。在上面這個範例裡,第二列的值會是NULL。
看一看下面這個範例:

在這個範例裡,所有要插入數據的字段都列出來了,這也恰好是表ORDERS_TBL裡的全部字段。在此,NULL 值被插入到 ORD_DATE 字段,表示或者不知道訂購日期,或者目前還沒有被訂購。再來看一個範例:

這條語句與前一條語句有兩處不同,但結果是一樣的。首先,這裡沒有字段列表。在向全部字段插入數據時,不必使用字段列表。其次,沒有向ORD_DATE字段插入NULL值,而是根本沒有給它賦值,這意味著應該添加一個NULL值。記住,NULL值表示字段沒有值,與空字符串是不同的。
最後,考慮這樣一種情況,PRODUCTS_TBL表中保存有NULL值,而用戶需要將該表中的值插入PRODUCTS_TMP表中,範例如下:
在這個範例中,如果數據即將插入的列允許接受NULL值,那麼NULL值就可以直接插入該列。在後續章節中,我們會介紹如何為列指定默認值,這樣,如果有NULL值被插入,就可以被自動轉換成默認值。
5.3 更新現有數據
利用UPDATE命令可以修改表裡的現有數據。這個命令不向表裡添加新記錄,也不刪除記錄,它只是修改現有的數據。它一般每次只更新數據庫裡的一個表,但可以同時更新表裡的多個字段。根據需要,我們可以只更新表裡的一行數據,也可以用一條語句就更新很多行數據。
5.3.1 更新一列的數據
UPDATE語句最簡單的形式是用於更新表裡的一列數據。在更新一列數據時,被更新的記錄可以是一條,也可以是很多條。
更新一列的語法如下所示:

下面的範例把表ORDERS_TBL裡ORD_NUM值為'23A16'的記錄(用WHERE子句指定)的QTY字段更新為1。

下面這個範例與前面相同,只是沒有了WHERE子句:

注意到在這個範例裡,11 條記錄被更新了。這個語句把字段 QTY 設置為 1,更新了表ORDERS_TBL 裡的全部記錄。這是我們想要的結果嗎?有時是的,但一般我們很少使用沒有WHERE子句的UPDATE語句。檢查目標數據集是否正確的一種簡單方式是對同一個表使用SELECT語句,其中包含要在UPDATE語句裡使用的WHERE子句,判斷返回的結果是否是我們要更新的記錄。
警告:小心使用UPDATE和DELETE命令
在使用沒有 WHERE 子句的 UPDATE 命令時要特別小心。如果沒有使用WHERE子句設置條件,表裡所有記錄的相應字段都會被更新。在大多數情況下,DML命令都需要使用WHERE子句。
5.3.2 更新一條或多記錄裡的多個字段
下面來介紹如何使用一條UPDATE語句更新多個字段,其語法如下所示:

注意其中使用的SET——這裡只有一個SET,但是有多個列,每個列之間以逗號分隔。可以看出SQL裡的一種趨勢:通常使用逗號來分隔不同類型的參數。下面的代碼使用逗號分隔要更新的兩列。同樣,WHERE子句是可選的,但通常是必要的。

注意:如何使用SET關鍵字
在每個UPDATE語句裡,關鍵字SET只能使用一次。如果需要一次更新多個字段,就要使用逗號來分隔這些字段。
本書的後續章節將介紹如何使用更複雜的命令,利用一個或多個外部表來更新當前表中的字段,這需要使用JOIN命令。
5.4 從表裡刪除數據
DELETE命令用於從表裡刪除整行數據。它不能刪除某一列的數據,而是刪除行裡全部字段的數據。使用DELETE語句一定要謹慎,因為它一向很有效。