
Fun with Perl Enhancements
最先由 Perl 提供的許多正則表達式概念,現在其他語言也提供了。包括非捕獲型括號、環視(以及之後的逆序環視)、寬鬆排列模式(其實是大多數模式,實際上還包括配套的「\A」、「\z」和「\Z」)、固化分組、「\G」和條件判斷結構。這些概念不再是Perl獨有的,所以我把它們挪到本書的通用部分。
不過Perl者也沒有停止創新,所以現在還有些重要的概念只有Perl提供。其中最有意思的是在匹配嘗試中執行任意代碼的功能。長期起來,Perl的特點之一就是正則表達式與代碼的緊密集成,但是此特性把集成提升到了新的高度。
我們先來簡單看看這個特性和目前Perl獨有的其他特性,然後詳細講解。
動態正則結構 「(??{perl code})」
應用正則表達式時,每次遇到表達式中的這個結構,就會執行其中的Perl代碼。執行的結果(或者是 regex 對象,或者是解釋為正則表達式的字符串)會作為當前匹配的一部分即刻被應用。
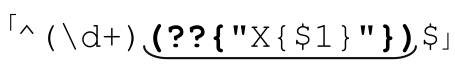 中的動態正則結構以下畫線標注,這個正則表達式匹配的行開頭是一個數,然後是字符『X』必須重現對應的次數,直到行末尾。
中的動態正則結構以下畫線標注,這個正則表達式匹配的行開頭是一個數,然後是字符『X』必須重現對應的次數,直到行末尾。
它能匹配『3XXX』和『12XXXXXXXXXXXX』,但不能匹配『3X』或『7XXXX』。
仔細看『3XXX』就會發現,開頭的「(\d+)」匹配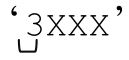 』,把$1設為『3』。之後正則引擎遇到動態正則結構,執行「X{$1}」,得到『X{3}』,解釋得到的「X{3}」作為當前正
』,把$1設為『3』。之後正則引擎遇到動態正則結構,執行「X{$1}」,得到『X{3}』,解釋得到的「X{3}」作為當前正
則表達式的一部分(匹配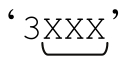 ),末尾的「$」匹配『3XXX☞』,得到整體匹配。
),末尾的「$」匹配『3XXX☞』,得到整體匹配。
下面我們會看到,匹配任意深度的嵌套結構時,動態正則結構尤其有用。
嵌套代碼結構 「 (?{arbitrary perl code}) 」
與動態正則結構一樣,在正則表達式的應用過程中,遇到此結構也會執行其中的 Perl代碼,但是這個結構更為通用,因為代碼不需要返回任何特定的值。通常也不會用到返回值(不過如果表達式之後的部分需要,可以通過變量$^R得到☞302)。
有一種情況會用到這段代碼的執行結果:如果內嵌的代碼結構用作「(?if then|else)」中的if條件(☞140)。此時,結果會解釋為布爾值,根據它來決定執行then還是else分支。
內嵌代碼可以干許多事情,相當有用的就是調試。下面這段程序會在每次應用正則表達式時顯示一條信息,內嵌的代碼結構用下畫線標註:

測試中,正則表達式只匹配1次,但是信息會顯示6次,說明傳動裝置在第6次嘗試之前已經在5個位置應用了正則表達式,第6次可以完全匹配。
正則文字重載
正則文字重載能夠讓程序員先自行處理正則文字,再將它們交給正則引擎。它可以用來為Perl的正則流派擴展新的功能。例如,Perl沒有提供單獨的單詞起始和結束分隔符(只有「\b」),不過你可能希望使用\<和\>,讓Perl能夠識別這些結構。
正則重載有些重要的限制,嚴格制約了它的用途。在講解\<與\>的例子時我們會看到這一點。
如果正則表達式中內嵌了Perl代碼(無論是動態正則結構還是內嵌代碼結構),最好是只使用全局變量,除非你明白關於338頁講解的 my變量的重要知識。關於 my變量的討論,請參閱第338頁。
用動態正則表達式結構匹配嵌套結構
Using a Dynamic Regex to Match Nested Pairs
動態正則表達式的主要用途之一是匹配任意深度的嵌套結構(長久以來人們認為正則表達式對此無能為力)。匹配任意深度的嵌套括號是個重要的例子。為了說明白動態正則如何解決這個問題,我們首先必須知道傳統結構為什麼不能解決這個問題。
匹配括號文本的簡單表達式是「\(([^()])*\)」。在外層括號內不容許出現括號,所以不能容許嵌套(也就是,只容許深度為0的嵌套)。用regex對像來表示就是:

這能夠匹配「substr($str,0,3)」,但不能配「substr($str,0,(3+2))」,因為它包含嵌套的括號。現在修改正則表達式來處理它,也就是需要能夠處理深度為1的嵌套。
容許深度為 1 的嵌套意味著,外部的括號裡頭可以出現括號。所以,我們需要修改匹配外層括號內文本的表達式「[^()]」,添加一個子表達式匹配內層括號裡的文本。我們可以這樣,$Level0保存這樣一個正則表達式,再從此往上疊加:
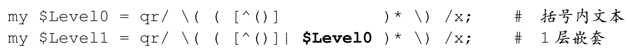
這裡的$Level0與之前的相同,新出現了$Level1,匹配對應深度的括號,加上$Level0,就得到深度為1的嵌套。
為了增加嵌套的深度,我們可以用同樣的方法,通過$Level1(仍然使用$Level0)得到$Level2:
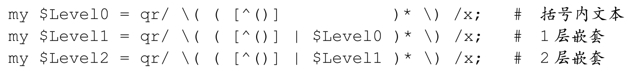
繼續下去就是:

圖7-1說明了開始幾層的情況:
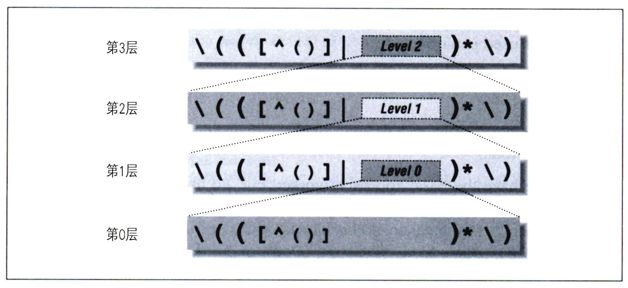
圖7-1:層數較少的嵌套
把這些層級加起來的結果很複雜,下面是$Level13:
\(([^]|\(([^]|\(([^]|\(([^])*\))*\))*\))*\)
這相當難看。
幸運的是,我們不需要直接解釋它(那是正則引擎的工作)。使用$Level變量很容易處理,但問題是,嵌套的深度是由$Level變量的數目決定的。這種辦法不夠靈活(用墨非定律來說就是,如果程序能處理深度為X的嵌套,則遇到的數據的嵌套深度必定會是X+1)。
幸運的是,動態正則可以應付任意深度的嵌套。你只需要想明白,除第一個之外,每個$Level變量的構建方式都是相同的:需要增加一級嵌套深度時,只需要包含上一級的$Level變量即可。但如果$Level變量都是相同的,它就同樣能包含更深級別的$Level。事實上,它還可以包括自身。如果在匹配更深層的嵌套時它可以用某種方式包含自身,就能遞歸地處理任意深度的嵌套。
這就是動態正則的威力所在。如果我們創建一個regex 對像——比如$Level變量,就可以在動態正則中引用它(動態正則結構可以包含任意的 Perl 代碼,只要結果能被解釋為正則表達式,返回已存在的regex對象的Perl代碼當然符合要求)。如果我們能把$Level之類的regex對像放入$LevelN,就可以用「(??{$LevelN})」來引用它:

它就能匹配任意深度的嵌套括號,用法同之前的$Level0:

哈!想明白其中的道理可不是件容易的事情,不過一旦用過,就會發現這個工具的價值。
現在我們已經有了基本的辦法,我希望做些修改提高效率。我會替換捕獲型括號為固化分組(這裡既不需要捕獲文本,也不需要回溯),之後可以把「[^()]」 改為「[^()]+」提高效率。(不要在固化分組中這樣做,否則會造成無休止匹配☞226)。
最後,我希望把「\()和「\)」移動到動態正則表達式兩端。這樣,在確實需要用到之前,引擎不會直接調用動態正則結構。下面是修改之後的版本:
$LevelN=qr/(?> [^]+|\((??{$LevelN})\))*/x;
因為它不包含外部的「\(…\)」,調用$LevelN時必須手動添加。
這樣一來,表達式就十分靈活,可以在任何可能出現嵌套括號的地方使用,而不僅僅是出現了嵌套括號的地方:

第343頁還有一個關於$LevelN的例子。
使用內嵌代碼結構
Using the Embedded-Code Construct
內嵌代碼結構很適合調試正則表達式,以及積累正在進行的匹配的信息。下面幾頁詳細給出了一組例子,最終得到模擬POSIX匹配的方法。講解的過程可能比真正的答案更有意思(除非你只需要POSIX的匹配語意),因為在講解中我們會收穫有用的技巧和啟發。
先從簡單的正則表達式調試技巧開始。
用內嵌代碼顯示匹配進行信息
這段程序:

的結果是:

正則表達式的開頭就是內嵌代碼結構,所以只要正則表達式開始新一輪匹配,就會執行:
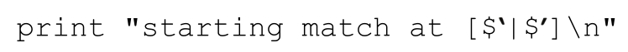
它用變量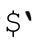 和
和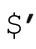 (☞300)(注9)表示目標字符串,用『|』標記當前的匹配位置(在這裡就是匹配開始的位置)。從結果中我們可以知道,傳動裝置(☞148)進行了 4 次應用,才匹配成功。
(☞300)(注9)表示目標字符串,用『|』標記當前的匹配位置(在這裡就是匹配開始的位置)。從結果中我們可以知道,傳動裝置(☞148)進行了 4 次應用,才匹配成功。
事實上,如果我們添加:
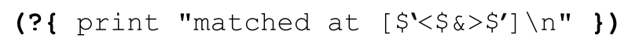
在正則表達式末尾,則結果是:
matched at [abc<d>efgh]
現在來看下面的程序,除了「主」正則表達式是「[def]」而不是「(?:d|e|f)」之外,其他部分與開頭的例子是一樣的:

從理論上說,結果應該是一樣的,實際情況卻是:
starting match at [abc|defgh]
為什麼呢?Perl 足夠聰明,對這個以「[def]」開頭的正則表達式進行開頭字符/字符組/字串識別優化(☞247),這樣傳動裝置就能略過那些它認為必然會失敗的嘗試。結果是忽略了其他所有嘗試,只進行了可能導致匹配的嘗試,我們可以通過內嵌代碼結構觀察到這種現象。

用內嵌代碼顯示所有匹配
Perl使用的是傳統型NFA引擎,所以一旦找到匹配就會停下來,即使還存在其他的匹配也是如此。如果巧妙地使用內嵌代碼,我們能夠讓Perl顯示所有的匹配。我們仍然以177頁的『onself』為例來說明。

結果如我們所料:
matched at [<oneself>sufficient]
表示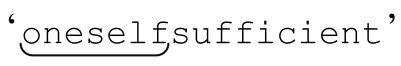 』已經被正則表達式匹配。
』已經被正則表達式匹配。
重要的是認識到,結果中的「matched」的部分並不是所有「能夠匹配」的文本,只是到目前獲得的匹配。在這個例子中談論其中的區別意義不大,因為內嵌代碼結構位於正則表達式的最後。我們知道,內嵌代碼結構完成時,整個正則表達式的所有匹配嘗試都已結束,實際匹配的結果就是如此。
不過,在內嵌代碼結構之後添加「(?!)」的情況如何呢?「(?!)」是否定型順序環視,它必然會失敗。如果它在內嵌代碼執行之後生效(也就是在「matched」信息打印之後),就會強迫引擎回溯,查找新的匹配。每次輸出「matched」信息之後,「(?!)」都會強迫引擎回溯,最終試遍所有的可能。

我們所做的修改確保正則表達式必然不能完整匹配,但是這樣做卻能讓引擎報告顯示所有可能的匹配。如果不使用「(?!)」,Perl只會返回第一個匹配,使用「(?!)」則可以見到其他可能。
瞭解了這一點之後,來看看下面的代碼:
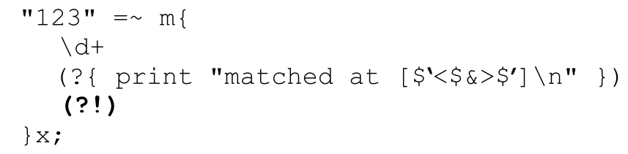
結果是:

前三行是我們能夠想像的,但如果不仔細動動腦筋,可能沒法理解後三行。「(?!)」強迫進行的回溯對應第二行和第三行。在開始位置的嘗試失敗之後,傳動裝置會啟動驅動過程,從第二個字符開始(第4章對此有詳細介紹)。第四行和第五行對應第二輪嘗試,最後一行對應第三輪。
所以,添加(?!)之後確實能顯示出所有可能的匹配,而不是從某個特定位置開始的所有匹配。不過,有時候只需要從特定位置開始的所有匹配,下面我們將會看到。
尋找最長匹配
如果我們不希望找到所有匹配,而是希望找到並保存最長的匹配,應該如何做呢?我們可以用一個變量來保存「到目前為止」最長的匹配,比較每一個「當前匹配」和它。下面是『onself』的例子:

毫不奇怪,結果是『longest match=[oneselfsufficient]』。這一段內嵌代碼很長,不過將來我們可能會使用,所以我們把它和「(?!)」封裝起來,作為單獨的regex對像:

下面這個簡單例子會找到最長的匹配『9938』:

尋找最左最長的匹配
我們已經能找到最長的全局匹配,現在需要找到出現在最前邊的最長匹配。POSIX NFA就是這樣做的(☞177)。所以,如果找到一個匹配,就要禁止傳動裝置的驅動過程。這樣,一旦我們找到某個匹配,正常的回溯會起作用,在同一位置尋找其他可能的匹配(同時需要保存最長的匹配),但是禁用驅動過程保證不會從其他位置尋找匹配。
Perl 不容許我們直接操作傳動裝置,所以我們不能直接禁用驅動過程,但如果$longest_match已經定義,我們能夠達到實現禁用驅動過程的效果。測試定義的代碼是「(?{defined$longest_match})」,但這還不夠,因為它只測試變量是否定義。重要的是根據測試結果進行判斷。
在條件判斷中使用內嵌代碼
為了讓正則引擎根據測試結果改變行為,我們把測試代碼作為「(?if then|else)」中的if部分(☞140)。如果我們希望測試結果為真時正則表達式停下來,就把必然失敗的「(?!)」作為then部分。(這裡不需要else部分,所以沒有出現)。下面是封裝了條件判斷的regex對像:
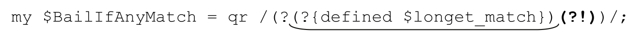
if部分以下畫線標注,then部分以粗體標注。下面是它的應用實例,其中結合了前一頁定義的$RecordPossibleMatch:
〞800-998-9938〞=~m{$BailIfAnyMatch\d+$RecordPossibleMatch}x;
得到『800』,它符合POSIX標準——「所有最左位置開始的匹配中最長的匹配」。
在內嵌代碼結構中使用local函數
Using localin an Embedded-Code Construct
local在內嵌代碼結構中有特殊的意義。理解它需要充分掌握動態作用域(☞295)的概念和第4章講解表達式主導的NFA引擎工作原理時所做的「麵包渣比喻」(☞158)。下面這段專門設計(我們會看到,它有缺陷)的程序沒有太多複雜的東西,但有助於理解local的意義。它檢查一行文本是否只包含「\w+」和「\s+」,以及有多少「\w+」是「\d+\b」:
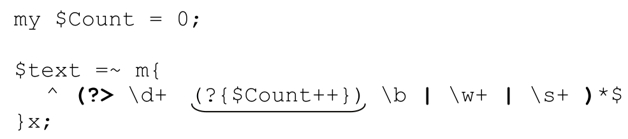
如果用它來匹配字符串『123·abc·73·9271·xyz』,$Count 的值是 3。不過,如果匹配字符串『123·abc·73xyz』,結果就是2,雖然應該是1。問題在於,『73』匹配之後,$Count的值會發生變化,因為後面的「\b」無法匹配,「\d+」當時匹配的內容需要通過回溯「交還」,內嵌結構的代碼卻不能恢復到「未執行」的狀態。
如果你還不完全瞭解固化分組「(?>…)」(☞139)和上面發生的回溯也沒關係,固化分組用於避免無休止匹配(☞269),但不會影響結構內部的回溯,只會影響重新進入此結構的回溯。所以如果接下來的「\b」不能匹配,「\d+」的「交還」就完全沒有問題。
簡單的解決辦法是,在$Count 增加之前添加「\b」,保證它的值只有在不進行「交還」操作的情況下才會變化。不過我更願意在這裡使用 local,來說明應用正則表達式期間這個函數對Perl代碼的影響。來看這段程序:
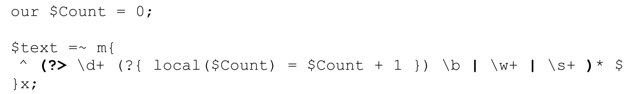
要注意的第一點是,$Count從my變量變為全局變量(我推薦使用use strict,如果這麼做了,就必須使用our來「聲明」全局變量)。
另一點要注意的是,$Count的修改已經本地化了。關鍵在於:對正則表達式內部的本地化變量來說,如果因為回溯需要「交還」local 的代碼,它會恢復到之前的值(新設定的值會被放棄)。所以,即使 local($Count)=$Count+1 在「\d+」匹配『73』之後執行,把$Count的值從1改為2,這個修改也只會是調用local時的「本地化到(當前正則表達式的)成功路徑」。如果「\b」匹配失敗,正則引擎會回溯到local之前,$Count恢復到1。這也就是正則表達式結束時的值。

所以,為了保證$Count的記數不發生錯誤,必須使用local。如果把「(?{print 〞Final count is $Count.\n〞})」放在正則表達式的末尾,它會顯示正確的計數值。因為我們希望在匹配完成之後使用$Count,就必須在匹配正式結束之前把它保存到一個非本地化的變量中。因為匹配完成之後,所有在匹配過程中本地化的變量都會丟失。
下面是一個例子:

看起來這麼做有點兒折騰,但這個例子的目的是說明正則表達式中本地化變量的工作機制。我們會在第344頁的「模擬命名捕獲」中見到實際的應用。
關於內嵌代碼和my變量的忠告
A Warning About Embedded Code and myVariables
如果my變量在正則表達式之外聲明,那麼在正則表達式之中的內嵌代碼引用,就必須非常小心,Perl中變量綁定的詳細規定可能會產生重大的影響。在講解這個問題之前,我必須指出,如果正則表達式的內嵌代碼中使用的都是全局變量就沒有這種問題,完全可以跳過這一節。忠告:這一節難度不小。
下面的例子說明了問題:

程序中包含3個my變量,但是只有$start與此問題有關(因為其他兩個並沒有在內嵌代碼中引用)。程序首先把$start 設為未定義的值,然後應用開頭元素為內嵌代碼的匹配,只是在$start未設定時,內嵌代碼結構才會把$start設置到嘗試開始位置。「本次嘗試的起始位置」取自$-[0](@-的第1個元素☞302)。
所以,如果調用:
CheckOptimizer(〞test 123〞);
結果就是:
The optimizer started the match at character 5.
這沒有問題,但如果我們再運行一次,結果就成了:

即使正則表達式檢查的文本沒有變化(而且正則表達式本身也沒有變化),結果卻不一樣了,你發現問題了嗎?問題就在於,在第二次調用中編譯正則表達式時,內嵌代碼中的$start取的是第一次運行之後設置的值。此函數的其他部分使用的$start其實是一個新的變量——每次函數調用的開始,執行my都會重新設置這個值。
問題的關鍵就在於,內嵌代碼中的my變量「鎖定」(用術語來說就是:綁定bound)在具體的 my變量的實例中,此實例在正則表達式編譯時激活。(正則表達式的編譯詳見 348 頁)每次調用 CheckOptimizer,都會創造一個新的$start實例,但是用戶很難以察覺,內嵌代碼中的$start仍然指向之前的值。這樣,函數其他部分使用的$start實例並沒有接收到正則表達式中傳遞給它的值。
這種類型的實例綁定稱為「閉包(closure)」,Programming Perl和Object Oriented Perl之類的書中介紹了這種特性的價值所在。關於閉包,Perl社群中存在爭議,比如本例中閉包究竟是不是一種「特性」,就有不同看法。對大多數人來說,這很難理解。
解決的辦法是,不要在正則表達式內部引用 my變量,除非你知道正則文字的編譯與 my實例的更新是一致的。比如我們知道,第 345 頁 SimpleConvert 子程序中使用的 my 變量$NestedStuffRegex 沒有這個問題,因為$NestedStuffRegex 只有一個實例。這裡的 my不在函數或者循環之中,所以它只會在腳本載入時創建一次,然後一直存在,直到程序終止。
使用內嵌代碼匹配嵌套結構
Matching Nested Constructs with Embedded Code
328頁的程序講解了如何使用動態表達式匹配任意深度的嵌套結構。一般來說,這都是最簡單的方法,但是來看看只使用內嵌代碼的辦法也沒壞處,所以接下來我會給出這種辦法。
辦法很簡單:記錄已經遇到的未配對開括號的數量,只有此數量大於 0 時,才容許出現閉括號。在匹配文本的過程中,我們使用內嵌代碼來計數,不過在這之前必須得看看(目前還不能運行的)正則表達式的框架。

為了保證效率,我們使用了固化分組,因為如果$NestedGuts 用於更大的正則表達式,就可能導致回溯,這樣「([…]+|…)*」就會造成無休止匹配(☞226)。舉例來說,如果我們將其作為「m/^\($NestedGuts\)$/x」的一部分,應用到『(this·is·missing·the·close』中,如果沒有使用固化分組,就得在記錄和回溯上花費漫長的時間。
為了配合計數,我們需要4步:
∂ 計數必須從0開始:
(?{local $OpenParens=0})
● 遇到開括號,就把記數器加1,表示有一對括號沒有匹配。
(?{$OpenParens++})
÷遇到閉括號,就檢查記數器,如果大於 0,就減去 1,表示已經匹配了一對括號。如果等於0,就停止匹配(因為閉括號與開括號不匹配),所以用「(?!)」強迫匹配失敗。
(?(?{$OpenParens}) (?{$OpenParens--})|(?!))
這裡使用了「(?if then|else)」條件判斷(☞140),用內嵌代碼判斷記數器,作為if部分。≠ 一旦匹配結束就檢查記數器,確保它等於 0,否則說明仍然有未匹配的開括號,因此匹配失敗。
(?(?{$OpenParens!=0})(?!))
綜合起來就得到:

這段程序的使用方法與第330頁的$LevelN完全相同。
為了分離正則表達式中的$OpenParens 和程序中可能出現的其他全局變量,這裡使用了local。但local的用法與之前的不同,這裡不需要避免回溯,因為正則表達式使用了固化分組,一旦某個多選分支能夠匹配,就不會變為「交還」。這樣,固化分組既保證了效率,又保證了內嵌代碼結構附近匹配的文本不會在回溯中交還(這樣$OpenParens 就與實際匹配的開括號數目一致)。
正則文字重載
Overloading Regex Literals
通過重載,用戶可以通過自己喜歡的方式預先處理正則文字中的文字部分。下面幾節給出了例子。
添加單詞起始/結束元字符
Perl沒有提供作為單詞起始/結束元字符的「\<」和「\>」,可能是因為絕大多數情況下「\b」已經夠用了。不過,如果我們希望使用這兩個元字符,我們可以通過重載,將表達式中的『\<』和『\>』分別替換為「(?<!\w)(?=\w)」和「(?<=\w)(?!\w)」。
先創建一個函數,MungeRegexLiteral,進行需要的預處理:

如果給此函數傳遞字符串『…\<…』,它會將其轉化為『…(?<!\w)(?=\w)…』。記住,因為replacement部分類似雙引號字符串,所以需要用『\\w』表示『\w』。
為了讓它能夠自動處理正則文字的每個文字部分,我們將其存入文件 MyRegexStuff.pm,供Perl重載:

將MyRegexStuff.pm放在Perl的庫路徑(library path,請參考Perl文檔中的PERLLIB)下,所有需要使用此功能的 Perl 腳本都可調用。如果只是為了測試,可以將其放在測試腳本同一目錄內,這樣調用:

每個需要這樣處理正則文字的程序文件都必須使用MyRegexStuff,但是MyRegexStuff.pm只需要構建一次(此功能在 MyRegexStuff.pm 內部不可用,因為它沒有 use MyRegexStuff——我們肯定不會這樣做)。
添加佔有優先量詞
我們繼續完善MyRegexStuff.pm,讓它支持佔有優先量詞——例如「x++」(☞142)。佔有優先量詞的作用類似普通的匹配優先量詞,只是它們永遠不會釋放(也就是「交還」)任何已經匹配的內容。用固化分組來模擬的話,只需要去掉最後的『+』,把量詞修飾的所有內容放到固化分組裡,「regex*+」就成了「(?>regex*)」(173)。
佔有優先量詞限定的部分可以是括號內的表達式,也可以是「\w」或者「\x{1234}」之類的元序列,或是普通字符。要處理所有情況並不容易,所以為簡便起見,我們只關注作用於括號的?+、*+和++。有了330頁的$LevelN,我們可以把這段程序:
$RegexLiteral=~s/(\($LevelN\)[*+?])\+/(?>$1)/gx;
添加到MungeRegexLiteral函數。
現在,它成為overload package的一部分,我們可以在正則文字中使用佔有優先量詞,例如第198頁的這個例子:
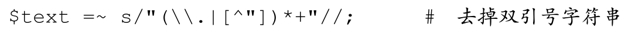
如果要處理的情況不只是括號,就要複雜很多,因為正則表達式中的變數很多,下面是一種嘗試:

這個表達式的大體形式和之前一樣:使用佔有優先量詞匹配一些內容,去掉最後的『+』,將整個表達式用「(?>…)」圍起來。要想識別 Perl 正則表達式的複雜語法,這樣還很不夠。匹配字符組的部分亟需改進,因為它並不能識別字符組內部的轉義。更糟糕的是,這個表達式的基本思路有問題,因為它不能完整識別 Perl 的正則表達式。比如,它就不能正確處理『\(blah\)++』中作為普通字符的開括號,而是認為「++」僅僅限定「\)」。
解決這個問題得花許多工夫,或許得想辦法從前往後仔細遍歷整個正則表達式(類似第132頁的補充內容中的辦法)。我本來希望改善處理字符組的元素,但是最後覺得沒必要處理其他複雜情況,原因有兩個。第一個是,這個表達式能應付大部分正常的情況,所以修正處理字符組的元素就能滿足實用要求了。更重要的一點是,目前 Perl 的正則表達式重載有嚴重問題,結果它的用途大打折扣,討論見下一節。
正則文字重載的問題
Problems with Regex-Literal Overloading
正則文字重載的功能非常有用,至少在理論上是如此,不幸的是實際情況並非如此。問題在於,它只對正則文字中的文字部分有效,而不會影響插值部分。例如,在m/($MyStuff)*+/中 MungeRegexLiteral 函數調用了兩次,一次是在變量插值之前(「(」);另一次是插值之後(「)*+」)。(它永遠不會影響$MyStuff 的值)。因為重載必須同時找到兩個部分,而插入的值又是不確定的,所以實際上重載不會生效。
對之前添加的\<和\>來說,這不是個問題,因為變量替換不太可能把它們切段。但是因為重載不會影響插值變量,包含『\<』或『\>』的字符串或regex對象就不會受重載影響。上一節已經提到,如果由重載來處理正則文字,就很難每次都保證完整性和準確性。即使是與\>一樣簡單也會出問題,例如『\\>』,它表示反斜線『\』之後緊跟尖括號『>』。
另一個問題是,重載不知道正則表達式所使用的修飾符。表達式是否使用了/x是很重要的問題,但重載沒有確切的辦法知道。
最後還必須指出,使用重載會禁止根據Unicode命名指定字符的功能(「\N{name}」☞290)。
模擬命名捕獲
Mimicking Named Capture
講完了重載的不便之後,我們來看看綜合了許多特殊結構的複雜例子。Perl沒有提供命名捕獲(☞138)的功能,但是我們可以使用捕獲型括號和$^N變量(☞301)來模擬,這個變量引用的是最近結束的捕獲型括號匹配的內容(現在我假扮Perl開發人員,使用$^N,特意為Perl增加命名捕獲的功能)。
來看個簡單的例子:
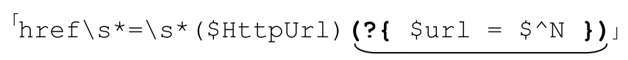
這裡使用了303頁的regex對像$HttpUrl。下畫線部分是一段內嵌代碼,把$HttpUrl匹配的內容保存到$url中。在這裡用$^N取代$1似乎有些多此一舉,甚至不必要使用內嵌代碼,因為在匹配之後使用$1 更加方便。但是如果把其中一部分封裝到 regex 對象,然後多次使用:

無論$HttpUrl是怎麼匹配的,$url都會被設置為 URL。在這個簡單應用中可以使用其他辦法(例如$+變量☞301),但是在更複雜的情況中,$SaveUrl之外的辦法更難維護,所以將它保存到命名變量中方便得多。
這裡有一個問題,如果設定$url的結構在回溯中被「交還」,已設定的值卻不會「撤銷保存(unwritten)」。所以要在初始匹配時修改本地化的臨時變量,只有在整體匹配真正確認之後才保存「真正」的變量,就像第338頁的例子一樣。
下面給出了一種解決辦法。從用戶的角度來看,在「(?<Num>\d+)」之後,「\d+」匹配的數值仍然可以以$^N{Num}訪問。儘管未來版本的Perl可能會把%^N轉換為某種特殊的系統變量,現在仍然不是特殊的,所以我們可以隨意使用。
我們可以使用%NamedCapture之類的名字,但選擇%^N是有理由的。之一是它類似$^N。另一個理由是,如果寫明了use strict,它不需要預聲明。最後,我希望Perl最終會內建對命名捕獲的支持,所以我認為%^N是個好辦法。如果果真如此,%^N就能夠和正則表達式的其他變量(☞299)一樣,自動使用動態作用域。但是目前,它只是普通的全局變量,所以不會自動使用動態作用域。
當然,即便是這個程序也會出現正則文字重載的辦法所具有的問題,例如不能處理插值變量。

