
Extended Examples
用這兩個例子作為本章的結束。
用PHP解析CSV
CSV Parsing with PHP
這裡有一個用PHP解析CSV(逗號分隔值)的程序,原來的例子在第6章(☞271)。這個正則表達式使用了佔有優先量詞(☞142),而不是固化分組括號,因為它們看起來更清晰。首先,這是我們將要使用的正則表達式:

然後,我們用它來解析$CSV文件中的一行:

檢查tagged data的嵌套正確性
Checking Tagged Data for Proper Nesting
這個例子有點複雜,它用到了許多有意思的知識:檢查XML(或者是XHTML,或者任何標記的數據)是否包含孤立的或者錯誤匹配的標籤。我的辦法是檢查正確匹配的tag,非tag文本,以及自封閉tag(self-closing tag,例如<br/>,用XML的語言來說就是一個「空元素tag」),希望我能找到整個字符串。
下面是完整的正則表達式:
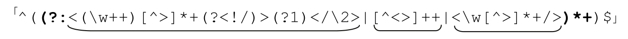
能夠匹配的字符串不會包含錯誤匹配的tag(稍後會給出若干告誡)。
這可能相當複雜,但是如果分解為各個部分,就可以掌握了。外層的「^(…)$」包圍表達式的主體,保證在返回success之前匹配整個目標字符串。主體包含在一組捕獲型括號之內,我們馬上會看到,這組括號容許在之後遞歸引用「主體」。
正則表達式的主體
正則表達式的主體,就是這三個多選分支(在正則表達式中的下畫線標注,以便觀察),它們包含在「(?:…)*+」中,容許任意的混合都能匹配。這三個多選分支匹配的分別是:tags、非tag文本,以及自封閉tag。
因為每個多選分支能夠匹配的文本之間是沒有衝突的(也就是說,如果一個多選分支能夠匹配,另兩個就不能匹配),我知道稍後的回溯永遠不會容許另一個多選分支匹配同樣的文本。利用這一點,我們可以使用佔有優先的星號,提高「容許任何混合」括號的匹配效率。它告訴正則引擎,不要徒勞地回溯,如果找不到匹配,就很快出結果。
因為同樣的原因,三個多選分支可以以任何順序出現,我把最可能匹配的多選分支放在最前面(☞260)。
現在逐個看這些多選分支:
第2個多選分支 非tag文本 我從它開始講,因為「[^<>]++」很簡單。這個多選分支匹配非tag 文本。在這裡使用佔有優先量詞可能有點多此一舉——外面的「(?:…)*+)」也是佔有優先的,但是為了安全起見,我希望在我知道不會帶來負面影響的地方使用佔有優先量詞。(通常使用佔有優先量詞是為了提高效率,但是它也會改變匹配的語意。這種修改可能有幫助,不過你必須清楚它的後果☞259)。
第3個多選分支 自封閉tag 第3個多選分支「<w[^>]*+/>」匹配自封閉tag,例如<br/>和<img…/>(自封閉tag在後面的尖括號之前有反斜線)。與之前一樣,佔有優先量詞可能有點多餘,但它肯定不會帶來負面影響。
第1個多選分支 一對匹配的tags。最後我們來看第1個多選分支: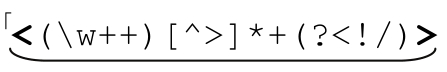 (?1)</2>」
(?1)</2>」
這個子表達式的第一部分(以下畫線標注)匹配開頭的tag,用「(w++)」,也就是整個正則表達式的第 2 組捕獲型括號(在「w++」中使用佔有優先量詞是很重要的,我們將會看到)匹配tag名稱。
「(?<!/)」是否定型逆序環視(☞133),確保沒有匹配斜線。我們把它放在匹配開頭tag的子表達式中的「>」之前,確保沒有匹配自封閉 tag,例如<hr/>(我們已經看到,自封閉的 tag由第3個多選分支處理)。
在開頭 tag匹配之後,「(?1)」會遞歸地應用到第一組捕獲型括號內的子表達式。它是之前提到的「主體」,也就是一塊只包含對稱tag的文本。它匹配之後應該匹配對應的結尾tag(closing tag),就是這個多選分支的第一部分匹配的(tag的名字捕獲到第二組捕獲型括號)。「</2>」開頭的「</」確保它是一個結尾tag,「2>」中的反向引用確保是一個正確的結尾tag。
如果是檢查HTML或者其他tag名不區分大小寫的數據,請在正則表達式之前添加「(?i)」,或者使用模式修飾符i。
完成了!
佔有優先量詞
關於第1個多選分支「<(w++)[^>]*+(?<!/)>」中的「w++」的佔有優先,我希望多說幾句。如果流派的功能不夠強大,不能使用佔有優先量詞或者固化分組(☞139),我會在這個多選分支的(w+)之後加上b:「<(w+)b[^>]*(?<!/)>」。
b很重要,它能夠停止(w+)的匹配,例如,『<link>…</li>』中第一個『li』的匹配。這樣會將『nk』單獨留在捕獲型括號外面,導致後面的反向引用「2」引用的tag名不完整。
正常情況下這些都不會發生,因為w+是匹配優先的,會匹配整個tag名。不過,如果正則表達式應用到嵌套結構糟糕的文本中,它應該匹配失敗,搜索中的回溯會強迫「w+」匹配不完整的tag名,例如『<link>…</li>』。「b」能解決這個問題。
謝天謝地,PHP的強大的preg引擎支持佔有優先量詞,使用「(w++)」與附加「b」的意義一樣:不容許回溯切割tag名,但是效率更高。
真實世界的XML
真實世界的XML比簡單的匹配tag要複雜得多。我們還必須考慮XML註釋、CDATA部分、處理指令和其他。
添加對XML註釋的支持是很容易的,只需要增加第4個多選分支,「<!--.*?-->」,請務必使用「(?s)」或者是模式修飾符S,這樣點號能夠匹配換行符。
同樣,CDATA 部分的格式是<![CDATA[…]]>,可以用另一個多選分支「<![CDATA[.*?]]>」來處理,『<?xml·version=〞1.0〞?>』之類的處理指令需要再添加一個多選分支:「<?.*??>」。
entity 聲明的形式是<!ENTITY…>,可以用「<!ENTITYb.*?>」來處理。XML 中有許多類似的結構,他們中的大部分可以用「<![A-Z].*?>」取代「<!ENTITYb.*?>」來處理。
雖然還有些問題,不過上面的辦法應該能夠應付絕大多數XML。下面是完整的PHP代碼:

HTML
常見的情況是,真實世界的HTML有各種各樣的問題,這樣的檢測幾乎沒有實用價值,例如孤立元素或者失配的tag,以及獨立出現的『<』和『>』字符。不過,即使是正確配對的HTML也有些特殊情況我們必須處理,註釋和<script>tag。
HTML註釋規範與XML註釋一樣:「<!--.*?-->」,使用模式修飾符s。
<script>部分是重要的,因為它可能包含『<』和『>』,所以必須容許<script…>和</script>之間出現任何字符。我們可以這樣處理:「<scriptb[^>]*>.*?</script>」。有趣的是,不包含禁止出現的『<』和『>』的字符的script序列會被第1個多選分支捕獲,因為它走的也是「匹配的一組tag」的套路。如果<script>不包含任何其他字符,第1個多選分支會失敗,這些文本留給新增的多選分支。
這裡是HTML版本的PHP程序:
