
Core Object Details
概覽完畢,來看細節。首先,我們來看如何創建 Regex 對象,然後來看如何將其應用到字符串,生成Match對象,以及如何處理這個Match對像和它的Group對象。
在實踐中,很多時候不必明確創建 Regex 對象,不過明確創建看起來更順眼,所以在講解核心對像時,每次都會創建它們。稍後我會告訴你.NET提供的簡便方法。
在下面的列表中,我會忽略從Object類繼承而來的,很少用到的方法。
創建Regex對像
Creating RegexObjects
Regex的構造函數並不複雜。它可以接收一個參數(作為正則表達式的字符串),或者是兩個參數(一個正則表達式和一組選項)。下面是一個參數的例子:
Dim StripTrailWS=new Regex(〞s+$〞)\'去掉結尾的空白字符
它只是創建Regex,做好應用前的準備;而沒有進行任何匹配。
下面是使用兩個參數的例子:
Dim GetSubject=new Regex(〞^subject:(.*)〞,RegexOptions.IgnoreCase)
這裡多出了一個RegexOptions選項,不過可以用OR運算符連接多個選項,例如:

捕獲異常
如果正則表達式包含了元字符的非法組合,就會拋出ArgumentException。通常,如果用戶知道所使用的正則表達式能夠正常工作,就不需要捕獲這個異常,不過如果使用程序「之外」(例如由用戶輸入,或者從配置文件讀入)的正則表達式,就必須捕獲這個異常。

顯然,根據情況的不同,在檢測到異常之後可能需要不同的處理:你可能需要進行其他的處理,而不僅僅是向控制台輸出報錯信息。
Regex選項
在創建Regex對像時,可以使用下面的選項:
RegexOptions.IgnoreCase
此選項表示,在應用正則表達式時,不區分大小寫(☞110)。
RegexOptions.IgnorePatternWhitespace
此選項表示,正則表達式應該按照自由格式和註釋模式(☞111)來解析。如果使用單純的「#…」註釋,請確認在每一個邏輯行的末尾都有換行符,否則第一處註釋會「註釋掉」之後的整個正則表達式。
在VB.NET中,我們可以用chr(10)來實現,例如:

這樣很累贅;VB.NET提供了更簡便的「(?#…)」註釋:

此選項表示,正則表達式在應用時應採用增強的行錨點模式(☞112)。也就是說,「^」和「$」能夠匹配字符串內部的換行符,而不僅僅是匹配整個字符串的開頭和結尾。
RegexOptions.Singleline
此選項表示,正則表達式使用點號通配模式(☞111)。此時點號能夠匹配任意字符,也包括換行符。
RegexOptions.ExplicitCapture
此選項表示,普通括號「(…)」,在正常情況下是捕獲型括號,但此時不捕獲文本,而是與「(?:…)」一樣,只分組,不捕獲。此時只有命名捕獲括號「(?<name>…)」能夠捕獲文本。
如果使用了命名分組,又希望使用非捕獲型括號來分組,就可以使用正常的「(…)」括號和此選項,這樣程序看起來更清晰。
RegexOptions.RightToLeft
此選項表示,進行從右向左的匹配(☞411)。
RegexOptions.Compiled
此選項表示,正則表達式應該在實際應用時被編譯,成為高度優化的格式,這樣通常會大大提高匹配速度。不過這樣會增加第一次使用時的編譯時間,以及程序執行期間的內存佔用。
如果正則表達式只需要應用一次,或者應用並不是很頻繁,就沒必要使用Regex Options.Compiled,因為即使這個Regex對像已經被回收,多佔的內存也不會釋放。不過如果正則表達式在對時間要求很高的場合應用,這個選項可能非常有價值。
在第237 頁的例子中,使用這個選項減少了大約一半的測試時間。還可以參考關於編譯到裝配件(assembly)的討論(☞434)。
RegexOptions.ECMAScript
此選項表示,正則表達式應該按照 ECMAScript(☞412)兼容方式來解析。如果不清楚ECMAScript,或者不需要兼容它,可以直接忽略。
RegexOptions.None
它表示「沒有額外的選項」,在初始化RegexOptions變量時,如果需要指定選項,可以使用它。也可以用OR來連接其他希望使用的選項。
使用Regex對像
Using RegexObjects
在沒有實際應用之前,Regex是沒有意義的,下面的程序示範了實際的應用:

IsMatch方法把目標正則表達式應用到目標字符串,返回一個 Boolean值,表示匹配嘗試是否成功,這裡有個例子:

如果提供了offset(一個整數),則第一次嘗試會從對應的偏移值開始。
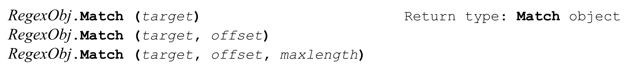
Match方法把正則表達式應用到目標字符串中,返回一個Match對象。通過這個Match對象可以查詢匹配結果的信息(是否匹配成功,捕獲的文本等等),初始化此正則表達式的「下一次」匹配。Match對象的細節見第427頁。
如果提供了offset(一個整數),則第一次嘗試會從對應的偏移值開始。
如果提供了maxlength參數,會進行特殊模式的匹配,從offset開始的字符開始計算,正則引擎會把maxlength長度的文本當作整個目標字符串,假設此範圍之外的字符都不存在,所以此時「^」能夠匹配原來的目標字符串中的offset位置,「$」能夠匹配之後maxlength個字符的位置。同樣,環視結構不能「感覺到」此範圍之外的字符。這與提供offset有很大不同,如果只提供了offset,受影響的只是傳動裝置開始應用正則表達式的位置——正則引擎仍然能夠「看到」完整的目標字符串。
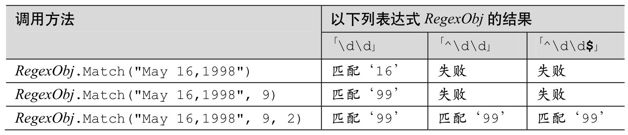
下面表格中的例子比較了offset和maxlength的意義:
Matches方法類似Match方法,只是Matches方法返回一組Match對象,代表目標字符串中的所有匹配結果,而不是第一次的匹配結果。返回的對象為MatchCollection。
例如,初始化代碼如下:
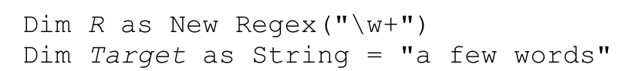
下面的程序:

運行結果是:
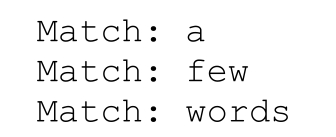
下面的程序輸出同樣的結果,它說明,MatchCollection 對象可以一次分配整個 Match-Collection。

作為比較,下面的代碼也可以達到同樣的效果,使用Match(而不是Matches)方法:

Replace方法會在目標字符串中進行查找-替換,返回(有可能已經變化的)字符串副本。它應用的是Regex對象的正則表達式,返回的不是Match對象,而是替換的結果。匹配的文本被什麼內容替換,取決於replacement參數。replacement參數可以重載:它可以是一個字符串,也可以是MatchEvaluator委託(delegate)。如果replacement是一個字符串,它會按照下一頁補充內容的說明進行處理。例如:

把每一個大寫單詞兩邊加上<B>…</B>。
如果設置了count,就只會進行count次替換(默認情況是進行所有的替換)。如果只希望替換第一次匹配,可以將count設置為1。如果我們知道只會有一次匹配,把count明確設置為 1 的效率會更高,因為不需要對字符串的其他部分進行查找和處理。把 count 設置為-1表示「所有匹配都必須替換」(它等價於沒有設置count)。
如果設置了 offset(一個整數),則應用正則表達式時,目標字符串中對應數目的字符會被忽略。這些忽略的字符會直接被複製到結果中。
例如,這段代碼會去掉多餘的空白字符(也就是將連續的多個空白字符替換為單個空格):

『some·····random·····spacing』被替換為『some·random·spacing』。下面代碼的結果相同,只是它會保留行開頭任意數目的空白字符。
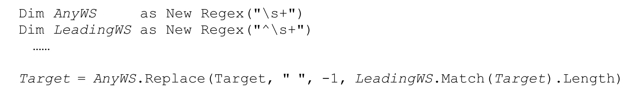
它會把『····some···random·····spacing』轉化為『····some·random·spacing』,在查找和替換時,它使用LeadingWS匹配文本的長度作為偏移值(就是要跳過的字符數目)。這裡用到了Match對象的簡便特性,即LeadingWS.Match(Target)的Length屬性(即便失敗也沒問題,此時Length的值為0,也就是說我們需要對整個目標字符串應用AnyWS)。
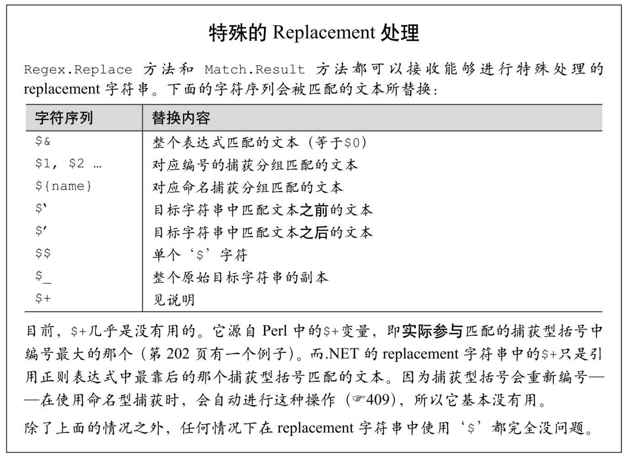
使用replacement委託
replacement 參數不只能用簡單字符串,還可以是委託(delegate,簡單說就是函數指針)。代理函數在每次匹配之後調用,生成作為replacement的文本。因為這個函數能夠進行我們需要的任何處理,這種查找替換的機制功能非常強大。
委託的類型是 MatchEvaluator,每次匹配都會調用。它所引用的函數必須接受 Match 對象,進行你所需要的任何處理,返回作為replacement的文本。
做個比較,下面兩段程序輸出同樣的結果:

兩段程序都用<<…>>標注匹配的文本。使用委託的好處在於,在計算replacement時我們可以進行任意複雜的操作。下面的例子把攝氏溫度轉換為華氏溫度:

如果目標字符串中包含『Temp is 37C.』,它會被替換為『Temp is 98.6F.』。

Split 方法將目標正則表達式應用於目標字符串,返回由各匹配分隔的字符串數組。如下面這個例子所示:
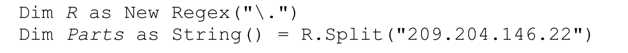
R.Split返回包含四個字符串的數組(『209』、『204』、『146』和『22』),它們由「.」在目標字符串中的三次匹配來分隔。
如果提供了count參數,則至多返回count個字符串(除非使用了捕獲型括號,一會兒會說到這個問題)。如果沒有提供count,Split返回所有匹配分隔的字符串。提供count的意思是,正則表達式可能在找到最終匹配之前停止應用,若果真如此,數組中最後的元素就是目標字符串中餘下的部分。
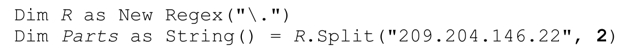
此時,Parts得到兩個字符串,『209』和『204.146.22』。
如果設置了 offset(一個整數),則正則表達式的匹配嘗試從對應編號的字符開始。前面的offset個字符會作為數組的第一個元素返回(如果設置了RegexOptions.RightToLeft,就會作為最後一個元素)。
在Split中使用捕獲型括號
如果出現了任何形式的捕獲型括號,數組中通常會包含額外的捕獲文本(也有些情況下根本不會包含)。來看個簡單的例子,要拆分字符串『2006-12-31』或是『04/12/2007』,你可能會使用「[-/]」:

結果包含 3 個元素(均為字符串)。不過,使用捕獲型括號的正則表達式「([-/,])」,則會返回5個字符串:如果MyDate包含『2006-12-31』,這5個元素是『2006』、『-』、『12』、『-』、『31』。多出來的『-』是每次捕獲的$1。
如果有多組捕獲型括號,它們會按照編號排序(也就是說,所有的命名捕獲跟隨在未命名捕獲之後☞409)。
只要實際參與了匹配捕獲型括號的捕獲型括號,都會包含在 Split的結果中。不過,目前的.NET 有一個bug,即如果某組捕獲型括號沒有參與匹配,它和所有編號更靠後的捕獲型括號都不會包含在返回的結果中。
來看個極端點的例子,如果需要以左右可能出現空白字符的逗號作為分隔,而且空白字符必須包含在返回結果中。用「(s+)?,(s+)?」分隔『this·,··that』,得到四個字符串『this』、『·』、『··』和『that』。但是,如果目標字符串為『this,·that』,因為第一組捕獲型括號沒有參與最終匹配,所有的捕獲型括號都不包含在最終結果中,所以只會返回兩個字符串『this』和『that』。無法預知到底會返回多少字符串,是當前版本的.NET 的一個重大問題。
在這個例子中,我們可以使用「(s*),(s*)」繞開這個問題(這樣兩個分組一定都能參與匹配)。不過,更複雜的表達式就沒這麼容易改寫了。

這幾個方法容許用戶查詢對應編號(可以用數字,如果是命名捕獲,也可以用名字)的捕獲型分組的信息。它們引用的不是特定的匹配內容,只是正則表達式中存在的分組的名字和編號。下面的補充內容說明了使用方法。

這幾個方法容許用戶查詢 Regex 對像本身(而不是將此對像應用到字符串上)的信息。ToString()方法返回正則表達式構造函數接收的字符串。RightToLeft 屬性返回一個Boolean 值,表明它是否啟用了 RegexOptions.RightToLeft選項。Options屬性返回與此正則表達式相關的RegexOptions。下面說明了各個選項的值,把對應選項的值相加,就得到返回結果。

這裡沒有128,因為它用於微軟內部的調試,沒有出現在最終產品中。
補充內容給出了這些方法的應用實例。
使用Match對像
Using MatchObjects
有三種方法創建Match對像:Regex的Match方法、靜態函數Regex.Match(稍後介紹)和Match對像自己的NextMatch方法。它封裝某個正則表達式的單次應用的所有相關信息。其屬性和方法如下:
MatchObj.Success
返回一個 Boolean 值,表示匹配是否成功。如果不成功,則返回一個靜態的 Match.Empty對像(☞433)。

它返回實際匹配文本的副本。

MatchObj.Length
返回實際匹配文本的長度。
MatchObj.Index
返回一個整數,顯示匹配文本在目標中的起始位置。編號從 0 開始,所以這個數字表示從目標字符串的開頭(最左邊)到匹配文本的開頭(最左邊)的長度。即使在創建 Match對像時設置了RegexOptions.RightToLeft,回值也不會變化。
MatchObj.Groups
此屬性是一個GroupCollection對象,其中封裝了多個Group對象。它是一個普通的集合類(collection),包含了Count和Item屬性,但是最常用的辦法還是按照索引值訪問,取出對應的Group對象。例如,M.Groups(3)對應第3組捕獲型括號,M.Groups(〞HostName〞)對應命名捕獲「HostName」(正則表達式中的「(?<HostName>…)」)。
在C#中,使用M.Groups[3]和M.Groups[〞HostName〞]。
編號為0的分組表示整個正則表達式匹配的所有文本。MatchObj.Groups(0).Value等價於MatchObj.Value。
MatchObj.NextMatch
NextMatch()方法將正則表達式應用於目標字符串,尋找下一個匹配,返回新的 Match 對象。
MatchObj.Result(string)
string是一個特殊的序列,按照第424頁補充內容的介紹來處理,返回結果文本。這裡有個簡單例子:

下面的程序可以依次匹配內容左側和右側文本的副本

調試時可能需要顯示某些和行有關的信息:
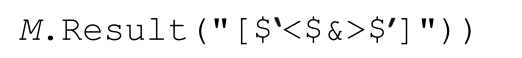
如果把「d+」應用到『May 16,1998』得到的Match對象,返回的是『May <16>,1998』,這清楚地體現了匹配文本。
MatchObj.Synchronized
它返回一個新的,與當前Match完全一樣的Match對象,只是它適合於多線程使用。MatchObj.Captures
Captures屬性並不常用,參見第437頁的介紹。
使用Group對像
Using GroupObjects
Group對像包含一組捕獲型括號(如果編號是0,就表示整個匹配)的信息。其屬性和方法如下:
GroupObj.Success
它返回一個Boolean值,表明此分組是否參與了匹配。並不是所有的分組都必須「參與」成功的全局匹配。如果「(this)|(that)」能夠成功匹配,肯定有一個分組能參與匹配,另一個不能。第139頁的腳注中有另一個例子。
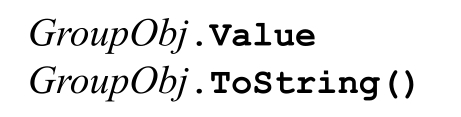
它們都返回本分組捕獲文本的副本。如果匹配不成功,則返回空字符串。
GroupObj.Length
返回本分組捕獲文本的長度。如果匹配不成功,則返回0。
GroupObj.Index
返回一個整數,表示本分組捕獲的文本在目標字符串中的位置。編號從 0 開始,所以它就是從目標字符串的開頭(最左邊)到捕獲文本的開頭(最左邊)的長度(即使在創建Match對像時設置了RegexOptions.RightToLeft,結果仍然不變)。
GroupObj.Captures
請參考第437頁Group對象的Capture屬性。