
.NET\'s Regex Flavor
.NET使用的是傳統型NFA引擎,所以第4、5、6章講解的NFA的知識都適用於.NET。下一頁的表9-1簡要說明了.NET的正則流派,其中大部分已經在第3章介紹過。
在接收正則表達式的函數和結構中設置標誌位(flag),或是在正則表達式之內使用「(?modes-modes)」和「(?mods-mods:…)」結構,可以使用不同的匹配模式,流派的許多方面也會因此發生變化(☞110)。408頁的表9-2列出了這些模式。
其中包括了「w」之類的「純」轉義。它們可以直接用到 VB.NET 的字符串文字(〞w〞)和C#的verbatim字符串(@〞w〞)中。C++的語言沒有提供針對正則表達式的字符串文字,所以正則表達式中的反斜線在字符串文本中需要雙寫(〞\\w〞)。請參考「作為正則表達式的字符串」(☞101)。
下面是對表9-1的補充說明:
1b只有在字符組內部才作為退格符。在字符組之外,b匹配單詞分界符(☞133)。
x##容許出現兩位十六進制數字,例如「xFCber」匹配『uber』。
u####容許且只容許四位十六進制數字,例如「u00FCber」匹配『uber』,「u20AC」匹配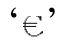 。
。
2.NET Framework Version 2.0中的字符組支持集合減法,例如「[a-z-[aeiou]]」表示小寫的非元音ASCII字母(☞125)。在字符組內部,連字符之後又跟著字符組表示字符組的減法運算,減去後面字符組內部的字符。
3w、d和s(以及對應的W、D和S)通常能處理所有合適的Unicode字符,但是如果啟用了RegexOptions.ECMAScript(☞412),就只能處理ASCII字符。
在此默認模式下,w 匹配 Unicode 屬性p{Ll}、p{Lu}、p{Lt}、p{Lo}、p{Nd}和p{Pc}。請注意,其中並沒有p{Lm}(請參考第123頁的屬性列表)。
表9-1:NET正則表達式流派概覽

在默認模式下,s匹配「[·fnrtvx85p{Z}]」,U+0085是Unicode 中的NEXT LINE控制字符,p{Z}匹配Unicode的「分隔符」字符(☞122)。
4p{…}和P{…}支持標準的Unicode屬性和區塊(針對Unicode Version 4.0.1)。不支持Unicode字母表。
區塊名要求出現『Is』前綴(參考第125頁的表格),只能夠使用含有空格或者下畫線的格式。例如,p{Is_Greek_Extended}和p{Is Greek Extended}是不容許的,正確的只有p{IsGreekExtended}。
.NET只支持p{Lu}之類的短名稱,而不支持p{Lowercase_Letter}之類的長名稱。單字母屬性也要求使用花括號(也就是說,不能把p{L}簡記為pL)。請參考第 122和第123頁的表格。
.NET 也不支持特殊的復合屬性p{L&},以及特殊屬性p{All}、p{Assigned}和p{Unassigned}。相反,你可以使用「(?s:.)」、「P{Cn}」、「p{Cn}」分別來代替。
5G表示上一次匹配的結束位置,雖然文檔介紹說它表示本次匹配的開頭位置(☞130)。
6 順序環視和逆序環視中都可以使用任意形式的正則表達式。就我所知,.NET正則引擎是唯一容許在逆序環視中出現能夠匹配任意長度文本表達式的引擎(☞133)。
7 RegexOptions.ExplicitCapture選項(也可通過模式修飾符(?n)設定)會禁止普通的「(…)」括號的捕獲功能。不過明確命名的捕獲型括號——例如「(?<num>d+)」——仍然有效(☞138)。如果使用了命名分組,此選項容許你使用更加美觀的「(…)」,而不是「(?:…)」,來進行純粹的分組。
表9-2:NET的匹配模式和正則表達式模式
對於流派的補充
Additional Comments on the Flavor
下面介紹一些其他的相關細節。
命名捕獲
.NET支持命名捕獲(☞138),它通過「(?<name>…)」或是「(?\'name\'…)」實現。這兩種辦法是等價的,可以隨意選用其中一種,不過我更喜歡<…>,因為我相信使用它的人多一些。
要反向引用命名捕獲匹配的文本,可以使用「k<name>」或是「k\'name\'」。
在匹配之後(也就是Match對像生成之後;下文從第416頁開始概要介紹.NET的對象模型),命名捕獲匹配的文本可以通過 Match 對象的 Groups(name)屬性來訪問(C#使用Groups[name])。
在replacement字符串中(☞424),命名捕獲的結果通過${name}來訪問。
某些情況下,可能需要按數字順序訪問所有的分組,所以命名捕獲的分組也會被標上序號。它們的編號從所有未命名的分組之後開始:

本例中,我們可以用Groups(〞Num〞)或Groups(3)來訪問「d+」匹配的文本。這兩個名字對應同一個分組。
不幸的結果
一般情況下不應該把正常的捕獲型括號和命名捕獲混合起來,不過如果你這樣做了,就必須徹底理解捕獲分組的編號順序。如果捕獲型括號用於Split(☞425),或者在replacement字符串中使用了『$+』(☞424),編號就很重要。
條件測試
如果「(?if then|else)」中的if部分(☞140)可以使用任意類型的環視結構,也可以在括號中使用捕獲分組的編號,或者是命名分組的名字。這裡出現的純文本(或者純正則表達式)會被自動當作肯定型順序環視來處理(也就是說,可以將其看作「(?=…)」包圍的結構)。這可能帶來麻煩:例如,「…(?(Num) then|else)…」中的「(Num)」會變為「(?=Num)」(也就是順序環視的『Num』),如果在正則表達式的其他地方沒有出現「(?<Num>…)」時會這樣。如果存在這樣的命名捕獲,if判斷的就是它是否捕獲成功。
我推薦不要依賴這種「自動化順序環視(auto-lookaheadfication)」,而明確使用「(?=…)」把意圖傳達給看程序的人,這樣如果正則引擎在未來修改了if語法,也不會帶來意外。
「編譯好的」正則表達式
在前面幾章,我使用「編譯(compile)」這個詞來描述所有正則表達式系統中,在應用正則表達式之前必須做的準備工作,它們用來檢查正則表達式是否格式規範,並將其轉換為能夠實際應用的內部形式。在.NET 的正則表達式中,它的術語是「解析(parsing)」。.NET使用兩種意義的「編譯」來指涉解析階段的優化。
下面是增進優化效果的細節:
●解析(Parsing) 程序在執行過程中,第一次遇到正則表達式時必須檢查它是否格式規範,並將其轉換為適於正則引擎實際應用的內部形式。此過程在本書的其他部分稱為「編譯(compile)」。
●即用即編譯(On-the-Fly Compilation)在構建正則表達式時,可以指定RegexOptions.Compiled選項。它告訴正則引擎,要做的不僅是此表達式轉換為某種默認的內部形式,而是編譯為底層的MSIL(Microsoft Intermediate Language)代碼,在正則表達式實際應用時,可以由JIT(「Just-In-Time」編譯器)優化為更快的本地機器代碼。
這樣做需要花費更多的時間和空間,但這樣得到的正則表達式速度更快。本節之後會討論這樣的權衡。
●預編譯的正則表達式 一個(或多個)Regex對像能夠封裝到DLL(Dynamically Loaded Library,例如共享的庫文件)中,保存在磁盤上。這樣其他的程序也可以直接調用它。稱為「編譯裝配件(assembly)」。請參考「正則表達式裝配件」(☞434)獲得更多信息。
如果使用RegexOptions.Compiled來進行「即用即編譯」的編譯,在啟動速度,持續內存佔用和匹配速度之間,存在此消彼長的關係:

在程序第一次遇到正則表達式時進行初始的正則表達式解析(默認情況,即不用RegexOp-tions.Compiled)相對來說是很快的。即使在我這台有年頭的550MHz NT的機器上,每秒鐘也能進行大約1 500次複雜編譯。如果使用RegexOptions.Compiled,則速度下降到每秒25次,每個正則表達式需要多佔用大約10KB內存。
更重要的是,在程序的執行過程中,這塊內存會一直佔用——它無法釋放。
在對時間要求不嚴格的場合使用RegexOptions.Compiled無疑是很有意義的,在這裡,速度是很重要的,尤其是需要處理大量的文本時更是如此。另一方面,如果正則表達式很簡單,需要處理的文本也不是很多,這樣做就沒有意義。如果情況不是這樣黑白分明,該如何選擇就不那麼容易了——必須具體情況具體分析,以進行取捨。
某些情況下,把編譯的正則表達式作為「編譯好的」正則對像封裝到DLL中是很有價值的。最終的程序所佔的內存更少(因為不必裝載編譯正則表達式所需的包),裝載速度更快(因為在 DLL 生成時它們已經編譯好了,只需要直接使用即可)。另一個不錯的副產品就是,表達式還可以供其他需要的程序使用,所以這是一種組建個人正則表達式庫的好辦法。請參考第435頁的「使用裝配件構建自己的正則表達式庫」。
從右向左的匹配
長期以來,正則表達式的開發人員一直覬覦著「反向(backwards)」匹配(即從右向左,而不是從左向右)。對開發人員來說,最大的問題可能是,「從右向左」的匹配到底是什麼意思?是整個正則表達式都需要反過來嗎?還是說,這個正則表達式仍然在目標字符串中進行嘗試,只是傳動裝置從結尾開始,驅動過程從右向左進行?
拋開這些純粹的概念,看個具體的例子:用「d+」匹配字符串『123·and·456』。我們知道正常情況下結果是『123』,根據直覺,從右向左匹配的結果應該是『456』。不過,如果正則引擎使用的規則是,從字符串末尾開始,驅動過程從左向右進行,結果可能就會出乎意料。在某些語意下,正則引擎能夠正常工作(從開始的位置向右「看」),所以第一次嘗試「d+」是在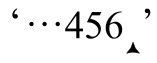 』,這裡無法匹配。第二次嘗試在
』,這裡無法匹配。第二次嘗試在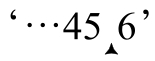 』,這裡能夠匹配,所以驅動過程開始「考察」位置『6』,這當然可以匹配「d+」,所以最後的結果是『6』。
』,這裡能夠匹配,所以驅動過程開始「考察」位置『6』,這當然可以匹配「d+」,所以最後的結果是『6』。
.NET的正則表達式提供了RegexOptions.RightToLeft的選項。但它究竟是什麼意義呢?答案是:「這問題值得思索。」它的語意沒有文檔,我測試了也無法找到規律。在許多情況下——例如『123·and·456』,它給出符合直覺的結果(也就是『456』)。
不過,有時候也會報告沒有匹配結果,或是匹配跟其他結果相比毫無意義的文本。
如果需要進行從右向左的匹配,你可能會發現,RegexOptions.RightToLeft 似乎能得到你期望的結果,但是最後,你會發現這樣做得冒風險。
反斜線-數字的二義性
數字跟在反斜線之後,可能表示十進制數的轉義,也可能是反向引用。到底應該如何處理,取決於是否指定了RegexOptions.ECMAScript選項。如果你不關心其中的細微差別,不妨一直用「k<num>」表示反向引用,或者在表示十進制數時以0開頭(例如「\08」)。這兩種辦法不受RegexOptions.ECMAScript的影響。
如果沒有使用RegexOptions.ECMASCript,從「1」到「9」的單個轉義數字通常代表反向引用,而以 0 開頭的轉義數字通常代表十進制轉義(例如,「\012」匹配 ASCII 的進紙符linefeed),除此之外的所有情況下,如果「有意義」(也就是說某個正則表達式中有足夠多的捕獲型括號),數字都會被作為反向引用來處理。否則,如果數字的值處於\000和377之間,就作為十進制轉義。例如,如果捕獲型括號的數目多於12,則「12」會作為反向引用,否則就會作為十進制數字。
下一節詳細講解RegexOptions.ECMAScript的語意。
ECMAScript模式
ECMAScript的基礎是一種標準版本的JavaScript(注2),還包含了它自己的解析和應用正則表達式的語意。如果使用 RegexOptions.ECMAScript 選項,.NET 的正則表達式就會模擬這些語意。如果你不明白ECMASCript的含義,或者不需要兼容它,就完全可以忽略該節。
如果啟用了RegexOptions.ECMASCript,將會應用下面的規則:
●RegexOptions.ECMAScript只能與下面的選項同時使用:

●w、d、s、W、D、S只能匹配ASCII字符。
●正則表達式中的反斜線-數字的序列不會有反向引用和十進制轉義的二義性,它只能表示反向引用,即使這樣需要截斷結尾的數字。例如,「(…)10」中的「10」會被處理為,第1組捕獲性括號匹配的文本,然後是文字『0』。