Java's Regex Flavor
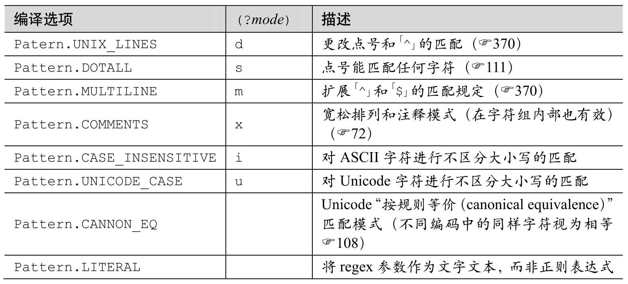
java.util.regex使用傳統型NFA,所以第4、5、6章介紹的豐富特性都適用於它。下頁的表8-2總結了它的元字符。此流派的某些方面已經發生了變化,原因是各種匹配模式,匹配模式的啟用通過各種 method 和 factory 來設定標誌位,或者內嵌在表達式中的「(?mods-mods)」和「(?mods-mods:…)」修飾符。這些模式在第368頁的表8-3中有列出。下面是對表8-2的說明:
1 只有在字符組內部,\b才代表退格字符。在其他場合,\b都代表單詞分界符。
表中給出的是「純(raw)」反斜線,但是用作Java正則表達式的字符串時必須使用雙反斜線。例如,表中的「\n」在Java的字符串中必須寫作「\\n」。請參考「作為正則表達式的字符串」(☞101)。
\x##容許且只容許出現兩位十六進制數字,所以「\xFCber」匹配『uber』。
表8-2:java.util.regex的正則流派
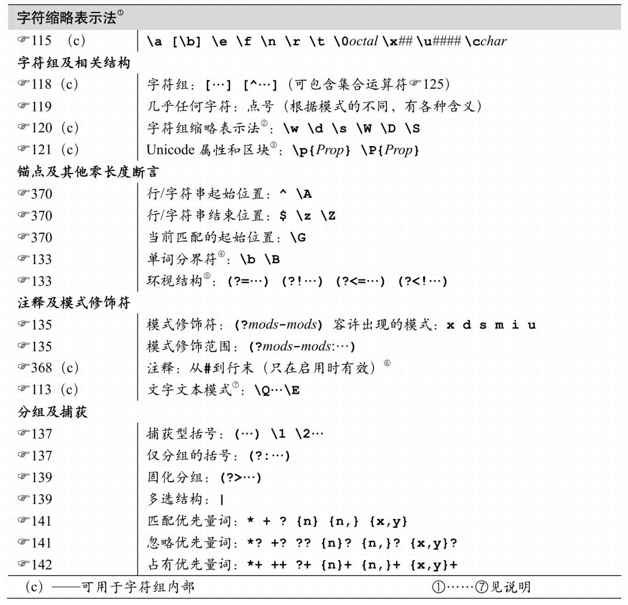
\u####容許且只容許四位十六進制數字,例如,「\u00FCber」匹配『uber』,「\u20AC」匹配『』。
\0octal要求開頭為0,後接1到3位十進制數字。
\cchar是區分大小寫的,直接對後面字符的十進制編碼進行異或(xoring)操作。與我見過的任何流派都不一樣,在這裡\cA和\ca是不同的。\cA等於傳統意義上的\x01,\ca則等價於\x21,匹配『!』。
2\w、\d和\s(以及對應的大寫縮略法)只適用於ASCII字符,而不包括其他的字母、數字或者 Unicode 空白字符。也就是說,\d 等價於[0-9],\w 等價於[0-9a-zA-Z],\s等價於[·\t\n\f\r\x0B](\x0B是ASCII中基本不用的VT字符)。
要覆蓋完整的Unicode字符,可以使用Unicode屬性(☞121):用\p{L}表示\w,\p{Nd}表示\d,用\p{Z}表示\s。(把小寫的p替換為大寫的P,就可以對應\W、\D和\S)。
3\p{…}和\P{…}支持 Unicode 屬性和區塊,以及某些額外的「Java 屬性」。它不支持Unicode字母表。詳細信息在下一頁。
4 對單詞分界符元字符\b和\B來說,「單詞字符」的規定不同於\w和\W。單詞分界符能夠識別Unicode字符,而\w和\W只能識別ASCII字符。
5 順序環視結構中可以使用任意正則表達式,但是逆序環視中的子表達式只能匹配長度
有限的文本。也就是說,「?」可以出現在逆序環視中,但「*」和「+」則不行。請參考第3章133頁開始的內容。
6 只有在使用/x修飾符,或者使用Pattern.COMMENTS選項(☞368)(請不要忘記在多
行文本字符串中添加換行符,如第401頁的例子)時,#… 才算註釋。沒有轉義的ASCII字空白字符會被忽略。注意:這一點與大多數支持此模式的正則引擎不同,在 Java 中字符組內部的註釋和空白字符也會被忽略。
才算註釋。沒有轉義的ASCII字空白字符會被忽略。注意:這一點與大多數支持此模式的正則引擎不同,在 Java 中字符組內部的註釋和空白字符也會被忽略。
7\Q…\E一直是被支持的,但在Java 1.6之前,字符組內部的此種結構是不可靠的。
表8-3:java.util.regex中Match和Regex的方法