
The Split Operator
功能多樣的split運算符(在不那麼嚴格的時候,人們通常稱其為函數)常被視為list context中m/…/g (☞311)的對立物。後者返回表達式匹配的文本,而split返回由表達式匹配的文本分隔的文本。把$text=~m/:/g應用到\'IO.SYS:225558:95-10-03:-a-sh:optional\'中,返回四個元素的list:
(\':\',\':\',\':\',\':\')
這似乎沒什麼用,但是split(/:/,$text)返回5個元素的list:
(\'IO.SYS\',\'225558\',\'95-10-03\',\'-a-sh\',\'optional\')
兩個例子都告訴我們,「:」匹配了4次。使用split,這4次匹配把目標字符串的副本分隔為5段,返回包含5個字符串的list。
這個例子只用單個字符分隔目標字符串,其實我們可以使用任何正則表達式:
@Paragraphs=split(m/s*<p>s*/i,$html);
它會按照<p>或者<P>(兩邊可能有空白字符)把$html中的HTML代碼分隔開來。你甚至可以按位置分隔:
@Lines=split(m/^/m,$lines);
把字符串按行切分。
對最簡單形式的數據來說,split非常有用也很容易理解。不過,因為存在許多參數、特殊情況和特殊情形,事情會變得複雜。在深入這些細節之前,先給出兩個特別有用的例子:
●特殊的 match 運算符//,會把目標字符串切分為單個字符,也就是說,split(//,〞short test〞)得到10個元素的list:(〞s〞,〞h〞,〞o〞,...,〞s〞,〞t〞)。
●特殊的 match 運算符〞·〞 (包含單個空格的普通字符串)把目標字符串按照空白字符切分,等於使用 m/s+/,只是會忽略開頭和結尾的空白字符。這樣,split(〞·〞,〞···a·short···test···〞) 得到三個字符串:『a』、『short』和『test』。
稍後討論各種特殊情況,我們先來看基礎的部分。
Split基礎知識
Basic Split
split運算符看起來像函數,它接收3個參數:
split(match operand,target string,chunk-limit operand)
括號是可選的,未提供的運算元會設置為默認值(本節稍後討論)。
split總是在list context中使用,常用的模式包括:

match運算元
運算元match有幾種特殊情況,不過它通常等價於match操作中的 regex運算元。也就是說,你可以使用/…/和m{…}之類的形式,它可以是regex對象,或者任何能夠求值為字符串的表達式。它只支持第292頁介紹的核心修飾符。
如果繼續要用括號來分組,請務必使用非捕獲型括號「(?:…)」。我們稍後將會看到,在split中使用捕獲型括號會觸發極特殊的功能。
target string運算元
target string只用於檢測,絕不會被修改。如果沒有設定,默認使用$_。
chunk-limit運算元
chunk-limit 運算元的主要功能是設定 split切分字符串的數目上限。對上面的例子中同樣的目標字符串調用split(/:/,$text,3)得到:
(\'IO.SYS\',\'225558\',\'95-10-03:-a-sh:optional\')
這告訴我們,/:/匹配兩次之後split會終止,產生所需的3段。它可能可以匹配更多的次數,但這裡不需要,因為存在段的數目限制。設定的數目將作為上限,所以最多只能返回規定數目的元素(除非正則表達式包含捕獲型括號,後文會論及)。得到的元素數目可能少於上限,如果得到的分段少於規定的數目,也不會有多餘的內容來「填充」。對於示例所用的數據,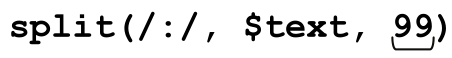 返回的list只有5個元素。不過,split(/:/,$text)和
返回的list只有5個元素。不過,split(/:/,$text)和 有重要的區別,這裡暫時還看不出來——請記住這一點,稍後我們會仔細講解。
有重要的區別,這裡暫時還看不出來——請記住這一點,稍後我們會仔細講解。
記住,chunk-limit運算元指向的是各匹配之間的分段,而不是匹配的數目本身。否則,前面那個上限為3的例子就應該得到這個:
(\'IO.SYS\',\'225558\',\'95-10-03\',\'-a-sh:optional\')
這不是程序運行的結果。
這裡談談效率:假設只希望取開頭的幾個元素,例如:
($filename,$size,$date)=split(/:/,$text);
為了提高效率,在需要的元素賦值之後,Perl 會停止 split操作。它會自動把 chunk-limit設置為list的元素個數+1。
深入split
從我們接觸過的例子來看,split 很容易使用,但有三個特殊的問題增加了它實踐起來的複雜程度:
●返回空元素。
●特殊的regex運算符。
●包含捕獲型括號的regex。
下面分別討論。
返回空元素
Returning Empty Elements
split的基本功能是返回由各個匹配分隔的分本,但有的時候,返回的文本是空字符串(長度為0的字符串,例如〞〞),比如:
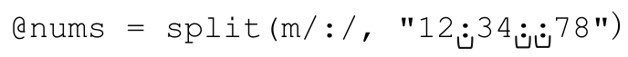
它返回:
(〞12〞,〞34〞,〞〞,〞78〞)
正則表達式「:」匹配了3次,所以應當返回4個元素。第3個元素為空,表示正則表達式在一行中匹配了兩次,它們之間沒有文本。
結尾的空元素
通常情況下,結尾的空元素不會返回,例如:
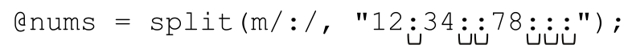
同樣會返回4個元素:
(〞12〞,〞34〞,〞〞,〞78〞)
即使這個正則表達式在字符串的末尾能匹配更多的次數,結果也沒有變化。在默認情況下,split不會返回list末尾的空元素。不過,我們可以通過設定chunk-limit運算元,讓split返回所有的末尾元素。
chunk-limit運算元的次要職能
chunk-limit的主要用途是設定分段數目的上限,任何不等於0的chunk-limit都會保留末尾的空元素(chunk-limit設置為零等價於不設置chunk-limit)。如果你不希望限制返回的chunk的數目,但是希望保留末尾的空元素,只需要設置一個非常大的限制即可。或者更好的辦法是,設置為-1,因為chunk-limit為負數表示一個足夠大的上限:split(/:/,$text,-1)會返回所有的元素,包括末尾的空元素。
另一個極端是,如果你不希望保留任何空元素,可以在split之前使用grep{length}。使用grep之後,只會返回長度不為0的元素(也就是說,非空元素)。
my@NonEmpty=grep {length} split(/:/,$text);
字符串末尾的特殊匹配
在字符串開頭的匹配會產生一個空元素:
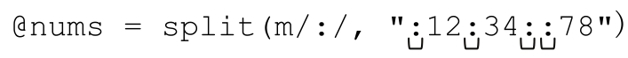
@num的值為:
(〞〞,〞12〞,〞34〞,〞〞,〞78〞)
開始的空元素表明,正則表達式在字符串的開頭能夠匹配。不過也有例外,如果一個正則表達式沒有匹配任何文本,如果它在字符串的開頭或者結尾匹配,那麼開頭和/或結尾的空元素將不會生成。來看個簡單的例子:split(/b/,〞a simple test〞),它能夠匹配其中的6個位置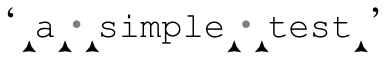 』。即使它能匹配6次,也不會返回7個元素,而是5個元素:(〞a〞,〞·〞,〞simple〞,〞·〞,〞test〞)。其實,這種特殊情況我們已經見過,即第321頁的@Lines=split(m/^/m,$lines)。
』。即使它能匹配6次,也不會返回7個元素,而是5個元素:(〞a〞,〞·〞,〞simple〞,〞·〞,〞test〞)。其實,這種特殊情況我們已經見過,即第321頁的@Lines=split(m/^/m,$lines)。
Split中的特殊Regex運算元
Split\'s Special Regex Operands
split的match運算元通常就是正則文字或者regex對象,這與match運算符的情況一樣,不過也有例外:
●regex為空的意思不是「使用當前的默認正則表達式」,而是把目標字符串分割為字符。在剛開始討論 split 的時候我們見過這個例子,split(//,〞short test〞)返回 10個元素的list:(〞s〞,〞h〞,〞o〞,…,〞s〞,〞t〞)。
●如果match運算元是由單個空格構成的字符串(而不是正則表達式),則是另一種特殊情況。它基本等同與/s+/,只是會忽略開頭的空白字符。這主要是為了模擬 awk 對輸入進行的默認的輸入-記錄-分隔(input-record-separator)操作,儘管對普通情況來說它也很有用。
如果希望保留開頭的空白字符,可以直接使用m/s+/。如果希望保留末尾的空白字符,只需要把chunk-limit設置為-1。
●如果沒有設置regex運算元,則默認使用一個空格符(上面提到的特殊情況)。這樣,不帶任何運算元的split就等價於split(\'·\',$_,0)。
●如果regex為「^」,會自動使用修飾符/m(增強型行錨點匹配模式)。(因為某些原因,「$」則不行)。因為明確使用m/^/m非常容易,我推薦這種更清晰的寫法。m/^/m是把包含多行文本的字符串按行切分的簡便方法。
Split不產生伴隨效應
請注意,split的match運算元看起來很像普通的match運算符,但是它沒有任何伴隨效應。split中的正則表達式不會影響到之後的match或是substitution操作所用的默認正則表達式,也不會設置$&、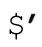 、$1 之類的變量。split 在伴隨效應上完全獨立於程序的其他部分(注8)。
、$1 之類的變量。split 在伴隨效應上完全獨立於程序的其他部分(注8)。
Split中帶捕獲型括號的match運算元
Split\'s Match Operand with Capturing Parentheses
捕獲型括號會從整體上改變split。一旦使用了捕獲型括號,返回的list中會多出些獨立的元素,它們對應於括號捕獲的元素。也就是說,split 沒有返回的部分或全部的文本,會包含在返回的list中。
例如,在處理HTML時,對下面的文本調用split(/(<[^>]*>)/):
…·and·<B>very·<FONT·color=red>very</FONT>·much</B>·effort…
返回:

如果去掉捕獲型括號,split(/<[^>]*>/)返回:
(\'...·and·\',\'very·\',\'very\',\'·much\',\'·effort...\')
多出來的元素不受分段上限的限制(chunk-limit 限制原來字符串切分之後的分段數目,而不是返回元素的數目)。
如果包含多個捕獲型括號,每次匹配之後,list會多出多個元素。如果某個捕獲型括號沒有參與匹配,對應的元素為undef。