
The Match Operator
基本的匹配操作:
$text=~m/regex/
是Perl的正則表達式應用的核心。在Perl中,正則表達式匹配操作需要兩個運算元,其一是目標字符串,其二是正則表達式,返回一個值。
匹配如何進行,返回什麼值,取決於匹配的應用場合(☞294)及其他因素。match 運算符非常方便——它可以用來測試某個正則表達式能否匹配一個字符串,或者從字符串中提取數據,甚至是與其他匹配運算符一起將字符串拆分為各個部分。雖然功能強大,這種便捷也增加了掌握的難度。需要關注的內容包括:
●如何指定正則運算元。
●如何指定匹配修飾符,以及它們的意義。
●如何指定目標字符串。
●匹配的伴隨效應。
●匹配的返回值。
●能影響匹配的外部因素。
匹配的常見形式是:
StringOperand=~RegexOperand
還有許多簡便方式,值得注意的是,某些簡便形式下,兩個運算元都不是必須出現的。本節中我們會看到各種形式的例子。
Match的正則運算元
Match's Regex Operand
正則運算元可以是正則文字或者regex對像(其實可以是字符串或者任意的表達式,但是這樣做沒什麼好處)。如果使用正則文字,可以指定修飾符。
使用正則文字
正則運算元通常是m/…/或者就是/…/內的正則文字。如果正則文字的分隔符是斜線或問號(以問號做分隔符的情況很特殊,稍後討論)則可以省略開頭的m。為保持一致,我不管是否必要都使用m。之前介紹過,如果使用m,你可以使用自己的分隔符(☞291)。
使用正則文字時,可以結合第 292 頁介紹的任何核心修飾符。匹配運算符還支持兩個另外的運算符,/c和/g,下面馬上介紹。
使用regex對像
正則運算元也可以是qr/…/生成的regex對象,例如:
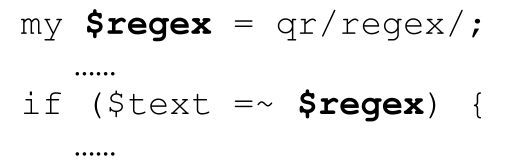
可以在m/…/中使用regex對象。特殊的情況是,如果「正則文字」中只包含一個regex對象的插值,那麼它就完全等同於使用此regex對象。上面這個例子也可以寫作:
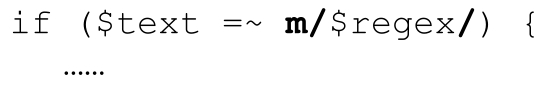
這很方便,因為它看起來更熟悉,也容許我們對regex對像使用/g修飾符(還可以使用m/…/支持的其他的修飾符,但這在本例中沒有意義,因為它們不能覆蓋regex對像內鎖定的模式修飾符☞304)。
默認的正則表達式
如果沒有指定正則表達式,例如m//(或者m/$SomeVar/而變量$SomeVar為空字符串或未定義),則Perl會使用此代碼所在的動態作用域範圍內最近應用成功的正則表達式。以前這樣很有用,因為可以提高效率,後來因為regex對象的發展(☞303),已經沒什麼意義了。
?…?的特殊匹配
除了之前介紹的正則文字的各種分隔符,match運算符還可以使用一種特殊的分隔符——問號。問號分隔符(例如 m?…?)提供的是相當生僻的功能,m?…?匹配成功之後,除非在同樣的package中調用reset函數,否則不會再次匹配。按照Perl Version 1的手冊上的說法,這「是有用的優化措施,用於在一組文件中查找某段信息的第一次出現」,但是不知何故,我在現代Perl中從未見過。
問號分隔符的特殊情況類似斜線分隔符,m也不是必須出現的:?…?完全等價於m?…?。
指定目標運算元
Specifying the Match Target Operand
常用來指定「搜索字符串」的做法是=~,例如$text=~m/…/。請記住,=~既不是賦值運算符,也不是比較運算符,只是一個看來有趣的運算符,用來連接運算元(這個表示法改編自awk)。
因為整個「expr=~m/…/」本身就是一個表達式,我們可以在任何容許出現表達式的地方使用,例如(以連線分隔):

默認的目標字符串
如果目標字符串是變量$_,則可以省略整個「$_=~」。也就是說,默認的目標字符串就是$_。
$text=~m/regex/;
的意思是,「把regex應用到$text中的文本,忽略返回值,獲取伴隨效應」。如果忘了寫『~』,結果就是:
$text=m/regex/;
它的意思是「對$_中的文本應用正則表達式,獲取伴隨效應,把返回的 true/false 值賦給$text」。也就是說,下面兩者是等價的:
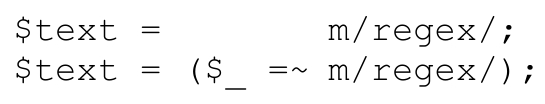
有時候使用默認目標字符串很方便,尤其是與其他默認情況的結構(許多結構都有默認值)結合時。下面的代碼就很常見:

總的來說,依賴默認運算元會增加無經驗程序員閱讀代碼的難度。
顛倒match的意義
可以用!~來取代=~,對返回值進行邏輯非操作(馬上會介紹這麼做的返回值和伴隨效應,但是對於!~,返回值就是true或者false),下面三種辦法是等價的:

從我個人出發,我喜歡中間的辦法。無論選用哪種辦法,都會產生設置$1等的伴隨效應。!~只是判斷「如果不能匹配」的簡便方式。
Match運算符的不同用途
Different Uses of the Match Operator
可以從match運算符返回的true/false判斷匹配是否成功,也可以從成功匹配中獲取其他的信息,與其他match運算符結合起來。match運算符的行為主要取決於它的應用場合(☞294),以及是否使用了/g修飾符。
普通的「匹配與否」——scalar context,不使用/g
在scalar context中(例如if測試),match運算符返回的就是true/false:

也可以把結果賦值給一個scalar變量,然後檢查

普通的「從字符串中提取數據」——list context,不使用/g
不使用/g的list context,是字符串中提取數據的常用做法。返回值是一個list,每個元素是正則表達式中捕獲型括號內的表達式捕獲的內容。下面這個簡單的例子用來從 69/8/31中提取日期:
my ($year,$month,$day)=$date=~m{^(\d+)/(\d+)/(\d+) $}x;匹配的3個數作為3個變量(當然還包括$1、$2和$3等)。每一組捕獲型括號都對應到返回序列中的一個元素,空序列表示匹配失敗。
有時候,某組捕獲括號沒有參與最終的成功匹配。例如,m/(this)|(that)/必然有一組括號不會參與匹配。這樣的括號返回未定義的值 undef。如果匹配成功,又沒有使用捕獲型括號,在不使用/g的list context中,會返回list(1)。
List context可以以各種方式指定,包括把結果賦值給一個數組,例如:
my@parts=$text=~m/^(\d+)-(\d+)-(\d+)$/;
如果match的接收參數是scalar變量,請將匹配的應用場合指定為list context,這樣才能獲得匹配的某些捕獲內容,而不是表示匹配成功與否的Boolean值。比較這兩個測試:
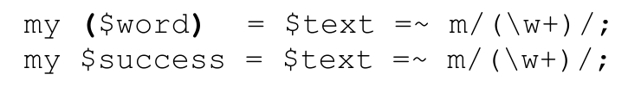
第一個例子中,變量外的括號導致my函數為賦值指定list context。第二個例子沒有括號,所以應用場合為scalar context,$success只得到true/false值。
下面給出了一個更簡單的做法:

這次匹配發生在list context中(由「my (…)=」提供),所以序列中的變量會根據對應的$1、$2之類進行賦值。不過,匹配完成之後,因為整個組合是在if條件語句的scalar context中,Perl把list轉換為一個scalar變量。它接收的是list的長度,如果匹配不成功,長度為0,如果不為0,則表示匹配成功。
「提取所有匹配」——list context,使用/g
此結構的用處在於,它返回一個文本序列,每個元素對應捕獲型括號匹配的文本(如果沒有捕獲型括號,就返回整個表達式匹配的文本),但上一節的例子只能針對一次匹配,而這種結構針對所有匹配。
下面這個簡單的例子用來提取字符串中的所有整數:
my@nums=$text=~m/\d+/g;
如果$text包含IP地址『64.156.215.240』,@num會接收4個元素,『64』、『156』、『215』、『240』。與其他結構相結合,就能很方便地把 IP 地址轉換為 8 位 16 進制數字,例如『409cd7f0』,如果需要創建緊湊的log文件,這很方便:
my $hex_ip=join'',map {sprintf(〞%02x〞,$_)} $ip=~m/\d+/g;
下面的代碼可以把它轉換回來:
my $ip=join'.',map {hex($_)} $hex_ip=~m/../g
另一個例子是匹配一行中的所有浮點數:
my@nums=$text=~m/\d+(?:\.\d+)?|\.\d+/g;
一定要使用非捕獲型括號,因為捕獲型括號會改變返回的結果。下面的例子說明了捕獲型括號的價值:
my@Tags=$Html=~m/<(\w+)/g;
@Tags會保存$Html中依次出現的各個tag,這裡假設每一個『<』都有對應的『>』。
下面的例子使用了多個捕獲型括號:把Unix中郵箱聯繫人的alias文件的內容存放在一個字符串中,數據格式是:

為了提取每一行中的暱稱(alias)和完整地址,我們可以使用m/^alias\s+(\S+)\s+(.+)/m (不使用/g)。在list context中,返回的序列包括兩個元素,例如('Jeff','[email protected]')。現在用/g匹配所有這樣的組合,得到的序列是:
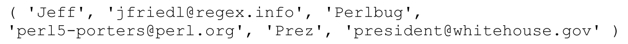
如果這個序列恰好符合key/value的形式,我們可以直接把它存入一個關聯數組(associative array)。
my%alias=$text=~m/^alias\s+(\S+)\s+(.+)/mg;
返回之後,可以用$alias{Jeff}訪問'Jeff'的完整地址。
迭代匹配:Scalar Context,使用/g
Iterative Matching:Scalar Context,with/g
scalar context中,m/…/g是個特殊的結構。和正常的m/…/一樣,它只進行一次匹配,但是和list context中的m/…/g一樣,它會檢查之前匹配的發生位置。每次在scalar context中使用 m/…/g——例如在循環中,它會尋找「下一個」匹配。如果失敗,就會重置「當前位置(current position)」,於是下一次應用從字符串的開頭開始。
這裡有個簡單的例子:

有兩次匹配是在scalar context中使用/g進行的,結果為:

後兩次匹配配合起來,前者把「當前位置」設置到匹配的小寫字母單詞之後,第二個讀取這個位置,在後面尋找大寫字母單詞。對兩個匹配來說,/g都是必須的,這樣匹配才能注意到「當前位置」,所以如果任何一個沒有使用/g,第二行會指向『WOW』。
scalar context 中的/g匹配非常適合用作while循環的條件:

最終會找到所有的匹配,但是 while的循環體是在匹配之間(或者說,在每次匹配之後)執行。一旦某次匹配失敗,結果就是false,然後while循環結束。同樣,一旦失敗,/g狀態會重置,也就是循環結束之後的/g匹配會從字符串的開頭開始。
比較:
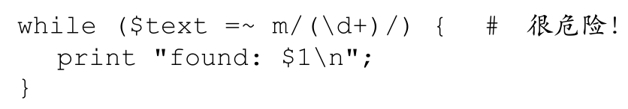
和

唯一的區別是/g,但是這區別不可小視。如果$text包含之前那個IP地址,第二個程序輸出我們期望的結果:

相反,第一個程序不斷地打印「found:64」,不會終止。不使用/g,就意味著「找到$text中第一個「(\d+)」」,也就是『64』,無論匹配多少次都是如此。添加/g之後,它變成了「找到$text中的下一個「(\d+)」」,依次找到各個數字。
「當前匹配位置」和pos()函數
Perl中每個字符串都有對應的「當前匹配位置(current match position)」,傳動裝置會從這裡開始第一次匹配的嘗試。這是字符串的屬性之一,而與正則表達式無關。在字符串創建或者修改時,「當前匹配位置」會指向字符串的開頭,但是如果/g匹配成功,它就會指向本次匹配的結束位置。下一次對字符串應用/g匹配時,匹配會從同樣的「當前匹配位置」開始。可以通過pos(…)函數得到目標字符串的「當前匹配位置」,例如:

結果是:

(記住,字符串的下標是從0開始的,所以「location 2」就是第3個字符之前的位置)。在/g匹配成功之後,$+[0](@+的第一個元素☞302)就等於目標字符串中的pos。
pos()函數的默認參數是match運算符的默認參數:變量$_。
預設定字符串的pos
pos()的真正能力在於,我們可以通過它來指定正則引擎從什麼位置開始匹配(當然是針對/g的下一次匹配)。我在Yahoo!的時候,要處理的Web服務器log文件的格式是,包含32字節的定長數據,然後是請求的頁面,然後是其他信息。提取請求頁面的辦法是「^.{32}」,跳過開頭的定長數據:
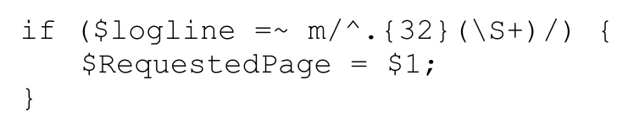
這種硬辦法不夠美觀,而且要強迫正則引擎處理前32個字節。如果我們親自動手,代碼會好看得多,效率也高得多:

這個程序好些,但還不夠好。這個正則表達式從我們規定的位置開始,而在此之前不需要匹配,這一點與上個程序不同。如果因為某些原因,第32個字符不能由「\S」匹配,前面那個程序就會匹配失敗,但是新程序因為沒有錨定到字符串的特殊位置,會由傳動裝置啟動驅動過程。也就是說,它會錯誤地返回一個「\S+」在字符串後面部分的匹配。幸好,在下一節我們會看到,這個問題很容易修復。
使用\G
元字符\G的意思是「錨定到上一次匹配結束位置」。這正是上一節中我們希望解決的問題。

\G告訴傳動裝置,「不要啟動驅動過程,如果在此處匹配不能成功,就報告失敗」。
前面幾章曾經介紹過「\G」:第3章有簡單介紹(☞130),更複雜的例子在第5章(☞212)。
請注意,在Perl中,只有「\G」出現在正則表達式開頭,而且沒有全局性多選結構的情況下,結果才是可預測的。第 6 章的優化 CSV 解析程序的例子中(☞271),正則表達式以「\G(?:^|,)…」開頭。如果更嚴格的「^」能夠匹配,就沒必要檢查「\G」,所以你可能會把它改為「(?:^|\G,)…」。不幸的是,在Perl中這樣行不通;其結果不可預測(注7)。
使用/gc進行「Tag-team」匹配
正常情況下,m/…/g匹配失敗會把目標字符串的pos重置到字符串的開頭,但給/g添加/c之後會造成一種特殊的效果:匹配失敗不會重置目標字符串的 pos(/c離不開/g,所以我一般使用/gc)。
m/…/gc最常見的用法是與「\G」一起,創建「詞法分析器」,把字符串解析為各個記號(token)。下例簡要說明了如何解析$html中的HTML代碼:

每個正則表達式的粗體部分匹配一種類型的HTML結構。從當前位置開始,依次檢查每一個正則表達式(使用/gc),但是只能在當前位置嘗試匹配(因為使用了「\G」)。按照順序依次檢查各個正則表達式,直到找到能夠匹配的結構為止,然後報告。之後把$html 的 pos指向下一個記號的開始,進入下一輪循環的搜索。
循環終止的條件是m/\G\z/gc能夠匹配,即當前位置(「\G」)指向字符串的末尾(「\z」)。
有一點要注意,每輪循環必須有一個匹配。否則(而且我們不希望退出)就會進入無窮循環,因為$html的 pos既不會變化也不會重置。對現在的程序來說,最終的else分支永遠不會調用,但是如果我們希望修改這個程序(馬上就會這麼做),或許會引入錯誤,所以else分支是有必要保留的。對目前這個程序來說,如果接收預料之外的數據(例如『<>』),會在每次遇到預料之外的字符時,就發出一條警報。
另一點需要注意的是各表達式的檢查順序,例如把「\G(.)」作為最後的檢查。也可以來看下面這個識別<script>代碼的例子:
$html=~m/\G (<script[^>]*>.*?</script>)/xgcsi
哇,這裡使用了 5 個修飾符!為了正常運行,我們必須把它放在對字符串進行第一次「<[^>]+>」的匹配之前。否則「<[^>]+>」會匹配開頭的<script>標籤,這個表達式就沒法運行了。
第3章還介紹了關於/gc的更高級的例子(☞132)。
Pos相關問題總結
下面是match運算符與目標字符串的pos之間互相作用的總結:

同樣,只要修改了字符串,pos就會重置為undef(也就是初始值,指向字符串的起始位置)。
Match運算符與環境的關係
The Match Operator's Environmental Relations
下面幾節將總結我們已經見到的,match運算符與Perl環境之間的互相影響。
match運算符的伴隨效應
通常,成功匹配的伴隨效應比返回值更重要。事實上,在void context中使用match運算符(這樣甚至不必檢查返回值),只是為了獲取伴隨效應(這種情況類似scalar context)。下面總結了成功匹配的伴隨效應:
●匹配之後會設置$1和@+之類變量,供當前語法塊內其他代碼使用(☞299)。
●設置默認正則表達式,供當前語法塊內其他代碼使用(☞308)。
●如果m?…?能夠匹配,它(也就是m?…?運算符)會被標記為無法繼續匹配,至少在同樣的package中,不調用reset就無法繼續匹配(☞308)。
當然,這些伴隨效應只能在匹配成功時發生,不成功的匹配不會影響它們。相反,下面的伴隨效應在任何匹配中都會發生:
●目標字符串的pos會指定或者重置(☞313)。
●如果使用了/o,正則表達式會與這個運算符「融為一體(fuse)」,不會重新求值(evaluate,☞352)。
match運算符的外部影響
match運算符的行為會受到運算元和修飾符的影響。下面總結了影響match運算符的外部因素:
應用場合context
match運算符的應用場合(scalar、list,或者void)對匹配的進行、返回值和伴隨效應有重要影響。
pos(…)
目標字符串的pos(由前一次匹配顯式或隱式設定)表示下一次/g匹配應該開始的位置,同時也是「\G」匹配的位置。
默認表達式
如果提供的正則表達式為空,就使用默認的表達式(☞308)。
study
對匹配的內容或返回值沒有任何影響,但如果對目標字符串調用此函數,匹配所花的時間更少(也可能更多)。參考「Study函數」(☞359)。
m?…?和reset
m?…?運算符有一個看不見的「已/未匹配」狀態,在使用 m?…?匹配或者 reset 時設定(☞308)。
在context中思考(不要忘記context)
在match運算符講解結束之前,我要提幾個問題。尤其是,在while、if和foreach控制結構中發生變化時,確實需要保持頭腦清醒。請問,運行下面的程序會得到什麼結果?

這有點兒難度,ϖ 請翻到下頁查看答案。