
Common Optimizations
聰明的正則表達式實現(implementation)有許多辦法來優化,提高取得結果的速度。優化通常有兩種辦法:
●加速某些操作。某些類型的匹配,例如「\d+」,極為常見,引擎可能對此有特殊的處理方案,執行速度比通用的處理機制要快。
●避免冗余操作。如果引擎認為,對於產生正確結果來說,某些特殊的操作是不必要的,或者某些操作能夠應用到比之前更少的文本,忽略這些操作能夠節省時間。例如,一個以「\A」(行開頭)開頭的正則表達式只有在字符串的開頭位置才能匹配,如果在此處無法匹配,傳動裝置不會徒勞地嘗試其他位置(進行無謂的嘗試)。
在下面的十幾頁中,我會講解自己見過的許多種不同的天才優化措施。沒有任何一種語言或者工具提供了所有這些措施,或者只是與其他語言和工具相同的優化措施;我也確信,還有許多我沒見過的優化措施,但看完本章的讀者,應該能夠合理利用自己所用工具提供的任何優化措施。
有得必有失
No Free Lunch
通常來說優化能節省時間,但並非永遠如此。只有在檢測優化措施是否可行所需的時間少於節省下來的匹配時間的情況下,優化才是有益的。事實上,如果引擎檢查之後認為不可能進行優化,結果總是會更慢,因為最開始的檢查需要花費時間。所以,在優化所需的時間,節省的時間,以及更重要的因素——優化的可能性之間,存在互相制約的關係。
來看一個例子。表達式「\b\B」(某個位置既是單詞分隔符又不是單詞分隔符)是不可能匹配的。如果引擎發現提供的表達式包含「\b\B」就知道整個表達式都無法匹配,因而不會進行任何匹配操作。它會立刻報告匹配失敗。如果匹配的文本很長,節省的時間就非常可觀。
不過,我所知的正則引擎都沒有進行這樣的優化。為什麼?首先,很難判斷這條規則是否適用於某個特定的表達式。某個包含「\b\B」的正則表達式很可能可以匹配,所以引擎必須做一些額外的工作來預先確認。當然,節省的時間確實很可觀,所以如果預計到「\b\B」經常出現,這樣做還是值得的。
不幸的是,這並不常見(而且愚蠢)(注4),雖然在極少數情況下這樣做可以節省大量的時間,但其他情況下速度降低的代價比這高得多。
優化各有不同
Everyone's Lunch is Different
在講解各種優化措施時,請務必記住一點「優化各有不同(everyone』s lunch is different)」。雖然我盡量使用簡單清晰的名字來命名每種措施,但不同的引擎必然可能以不同的方式來優化。對某個正則表達式進行細微的改動,在某個實現方式中可能會帶來速度的大幅提升,而在另一個實現方式中大大降低速度。
正則表達式的應用原理
The Mechanics of Regex Application
我們必須先掌握正則表達式應用的基本知識,然後講解先進系統的優化原理及利用方式。之前已經瞭解了回溯的細節,在本節我們要進行更全面地學習。
正則表達式應用到目標字符串的過程大致分為下面幾步:
1. 正則表達式編譯 檢查正則表達式的語法正確性,如果正確,就將其編譯為內部形式(internal form)。
2. 傳動開始 傳動裝置將正則引擎「定位」到目標字符串的起始位置。
3. 元素檢測 引擎開始測試正則表達式和文本,依次測試正則表達式的各個元素(comp-onent),如第4章所說的那樣。我們已經詳細考察了NFA的回溯,但是還有幾點需要補充:
●相連元素,例如「Subject」中的「S」、「u」、「b」、「j」、「e」等等,會依次嘗試,只有當某個元素匹配失敗時才會停止。
●量詞修飾的元素,控制權在量詞(檢查量詞是否應該繼續匹配)和被限定的元素(測試能否匹配)之間輪換。
●控制權在捕獲型括號內外進行切換會帶來一些開銷。括號內的表達式匹配的文本必須保留,這樣才能通過$1來引用。因為一對括號可能屬於某個回溯分支,括號的狀態就是用於回溯的狀態的一部分,所以進入和退出捕獲型括號時需要修改狀態。
4. 尋找匹配結果 如果找到一個匹配結果,傳統型 NFA 會「鎖定」在當前狀態,報告匹配成功。而對POSIX NFA來說,如果這個匹配是迄今為止最長的,它會記住這個可能的匹配,然後從可用的保存狀態繼續下去。保存的狀態都測試完畢之後返回最長的匹配。
5. 傳動裝置的驅動過程 如果沒有找到匹配,傳動裝置就會驅動引擎,從文本中的下一個字符開始新一輪的嘗試(回到步驟3)。
6. 匹配徹底失敗 如果從目標字符串的每一個字符(包括最後一個字符之後的位置)開始的嘗試都失敗了,就會報告匹配徹底失敗。
下面幾節講解高級的實現方式如何減少這些處理,以及如何應用這些技巧。
應用之前的優化措施
Pre-Application Optimizations
優秀的正則引擎實現方式能夠在正則表達式實際應用之前就進行優化,它有時候甚至能迅速判斷出,某個正則表達式無論如何也無法匹配,所以根本不必應用這個表達式。
編譯緩存
第2章的E-mail處理程序中,用於處理header各行的主循環體中是這樣的:

正則表達式使用之前要做的第一件事情是進行錯誤檢查,如果沒有問題則編譯為內部形式。編譯之後的內部形式能用來檢查各種字符串,但是這段程序的情況如何?顯然,每次循環都要重新編譯所有正則表達式,這很浪費時間。相反,在第一次編譯之後就把內部形式保存或緩存下來,在此後的循環中重複使用它們,顯然會提高速度(只是要消耗些內存)。
具體做法取決於應用程序提供的正則表達式處理方式。93頁已經說過,有3種處理方式:集成式、程序式和面向對像式。
集成式處理中的編譯緩存
Perl 和 awk 使用的就是集成式處理方法,非常容易進行編譯緩存。從內部來說,每個正則表達式都關聯到代碼的某一部分,第一次執行時在編譯結果與代碼之間建立關聯,下次執行時只需要引用即可。這樣最節省時間,代價就是需要一部分內存來保存緩存的表達式。

變量插值功能(variable interpolation,即將變量的值作為正則表達式的一部分)可能會給緩存造成麻煩。例如對 m/^Subject:·\Q $DesiredSubject\E\s*$/來說,每次循環中正則表達式的內容可能會發生改變,因為它取決於插值變量,而這個變量的值可能會變化。如果每次都會不同,那麼正則表達式每次都需要編譯,完全不能重複利用。
儘管正則表達式可能每次循環都會變化,但這並不是說任何時候都需要重新編譯。折中的優化措施就是檢查插值後的結果(也就是正則表達式的具體值),只有當具體值發生變化時才重新編譯。不過,如果變化的幾率很小,大多數時候就只需要檢查(而不需要編譯),優化效果很明顯。
程序式處理中的編譯緩存
在集成式處理中,正則表達式的使用與其在程序中所處的具體位置相關,所以再次執行這段代碼時,編譯好的正則表達式就能夠緩存和重複使用。但是,程序式處理中只有通用的「應用此表達式」的函數。也就是說,編譯形式並不與程序的具體位置相連,下次調用此函數時,正則表達式必須重新編譯。從理論上來說就是如此,但是在實際應用中,禁止嘗試緩存的效率無疑很低。相反,優化通常是把最近使用的正則表達式模式(regex pattern)保存下來,關聯到最終的編譯形式。
調用「應用此表達式」函數之後,作為參數的正則表達式模式會與保存的正則表達式相比較,如果存在於緩存中,就使用緩存的版本。如果沒有,就直接編譯這個正則表達式,將其存入緩存(如果緩存有容量限制,可能會替換一個舊的表達式)。如果緩存用完了,就必須放棄(thrown out)一個編譯形式,通常是最久未使用的那個。
GNU Emacs的緩存能夠保存最多20個正則表達式,Tcl能保存30個。PHP能保存四千多個。.NET Framework在默認情況下能保存15個表達式,不過數量可以動態設置,也可以禁止此功能(☞432)。
緩存的大小很重要,因為如果緩存裝不下循環中用到的所有正則表達式,在循環重新開始時,最開始的正則表達式會被清除出緩存,結果每個正則表達式都需要重新編譯。
面向對像式處理中的編譯緩存
在面向對像式處理中,正則表達式何時編譯完全由程序員決定。正則表達式的編譯是用戶通過New Regex、re.compile和Pattern.compile(分別對應.NET、Python和java.util.regex)之類的構造函數來進行的。第3章的簡單示例對此做了介紹(從第95頁開始),編譯在正則表達式實際應用之前完成,但是它們也可以更早完成(有時候可以在循環之前,或者是程序的初始化階段),然後可以隨意使用。在第 235、237 和238 頁的性能測試中體現了這一點。
在面向對像式處理中,程序員通過對像析構函數拋棄(thrown away)編譯好的正則表達式。及時拋棄不需要的編譯形式能夠節省內存。
預查必須字符/子字符串優化
相比正則表達式的完整應用,在字符串中搜索某個字符(或者是一串字符)是更加「輕量級」的操作,所以某些系統會在編譯階段做些額外的分析,判斷是否存在成功匹配必須的字符或者字符串。在實際應用正則表達式之前,在目標字符串中快速掃瞄,檢查所需的字符或者字符串——如果不存在,根本就不需要進行任何嘗試。
舉例來說,「^Subject:·(.*)」的『Subject:·』是必須出現的。程序可以檢查整個字符串,或者使用Boyer-Moore搜索算法(這是一種很快的文件檢索算法,字符串越長,效率越高)。沒有採用 Boyer-Moore 算法的程序進行逐個字符檢查也可以提高效率。選擇目標字符串中不太可能出現的字符(例如『Subject:·』中的『t』之後的『:』)能夠進一步提高效率。
正則引擎必須能識別出,「^Subject:·(.*)」的一部分是固定的文本字符串,對任意匹配來說,識別出「this|that|other」中『th』是必須的,需要更多的工夫,而且大多數正則引擎不會這樣做。此問題的答案並不是黑白分明的,某個實現方式或許不能識別出『th』是必須的,但能夠識別出『h』和『t』都是必須的,所以至少可以檢查一個字符。
不同的應用程序能夠識別出的必須字符和字符串有很大差別。許多系統會受到多選結構的干擾。在這種系統中,使用「th(is|at)」的表現好於「this|that」。同樣,請參考第 247 頁的「開頭字符/字符組/子串識別優化」。
長度判斷優化
「^Subject:·(.*)」能匹配文本的長度是不固定的,但是至少必須包含 9 個字符。所以,如果目標字符串的長度小於 9 則根本不必嘗試。當然,需要匹配的字符更長優化的效果才更明顯,例如「:\d{79}:」(至少需要81個字符)。
請參見第247頁的「長度識別傳動優化」。
通過傳動裝置進行優化
Optimizations with the Transmission
即使正則引擎無法預知某個字符串能否匹配,也能夠減少傳動裝置真正應用正則表達式的位置。
字符串起始/行錨點優化
這種優化措施能夠判斷,任何以「^」開頭的正則表達式只能在「^」能夠匹配的情況下才可能匹配,所以只需要在這些位置應用即可。
在「預查必須字符/子字符串優化」中提到,正則引擎必須判斷對某個正則表達式來說有哪些可行的優化,在這裡同樣有效。任何使用此優化的實現方式都必須能夠識別:如果「^(this|that)」匹配成功,「^」必須能夠匹配,但許多實現方式不能識別「^this|^that」。此時,用「^(this|that)」或者「^(?:this|that)」能夠提高匹配的速度。
同樣的優化措施還對「\A」有效,如果匹配多次進行,對「\G」也有效。
隱式錨點優化
能使用此種優化的引擎知道,如果正則表達式以「.*」或「.+」開頭,而且沒有全局性多選結構(global alternation),則可以認為此正則表達式的開頭有一個看不見的「^」。這樣就能使用上一節的「字符串起始/行錨點優化」,節省大量的時間。
更聰明的系統能夠認識到,即使開頭的「.*」或「.+」在括號內,也可以進行同樣的優化,但是在遇到捕獲括號時必須小心。例如,「(.+)X\1」期望匹配的是字符串在『X』兩側是相同的,添加「^」就不能匹配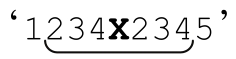 (注5)。
(注5)。
字符串結束/行錨點優化
這種優化遇到末尾為「$」或者其他結束錨點(☞129)的正則表達式時,能夠從字符串末尾倒數若干字符的位置開始嘗試匹配。例如正則表達式「regex(es)?$」匹配只可能從字符串末尾倒數的第8個字符(注6)開始,所以傳動裝置能夠跳到那個位置,略過目標字符串中許多可能的字符。
開頭字符/字符組/子串識別優化
這是「預查必須字符/子字符串優化」的更一般的版本,這種優化使用同樣的信息(正則表達式的任何匹配必須以特定字符或文字子字符串開頭),容許傳動裝置進行快速子字符串檢查,所以它能夠在字符串中合適的位置應用正則表達式。例如,「this|that|other」只能從「[ot]」的位置開始匹配,所以傳動裝置預先檢查字符串中的每個字符,只在可能匹配的位置進行應用,這樣能節省大量的時間。能夠預先檢查的子串越長,「錯誤的開始位置」就越少。
內嵌文字字符串檢查優化
這有點類似初始字符串識別優化,不過更加高級,它針對的是在匹配中固定位置出現的文字字符串。如果正則表達式是「\b(perl|java)\.regex\.info\b」,那麼任何匹配中都要有『.regex.info』,所以智能的傳動裝置能夠使用高速的Boyer-Moore字符串檢索算法尋找『.regex.info』,然後往前數4個字符,開始實際應用正則表達式。
一般來說,這種優化只有在內嵌文字字符串與表達式起始位置的距離固定時才能進行。因此它不能用於「\b(vb|java)\.regex\.info\b」,這個表達式雖然包含文字字符串,但此字符串與匹配文本起始位置的距離是不確定的(2個或4個字符)。這種優化同樣也不能用於「\b(\w+)\.regex\.info\b」,因為「(\w+)」可能匹配任意數目的字符。
長度識別傳動優化
此優化與 245 頁的長度識別優化直接相關,如果當前位置距離字符串末尾的長度小於成功匹配所需最小長度,傳動裝置會停止匹配嘗試。
優化正則表達式本身
Optimizations of the Regex Itself
文字字符串連接優化
也許最基本的優化就是,引擎可以把「abc」當作「一個元素」,而不是三個元素「「a」,然後是「b」,然後是「c」」。如果能夠這樣,整個部分就可以作為匹配迭代的一個單元,而不需要進行三次迭代。
化簡量詞優化
約束普通元素——例如文字字符或者字符組——的加號、星號之類的量詞,通常要經過優化,避免普通NFA引擎的大部分逐步處理開銷(step-by-step overhead)。正則引擎內的主循環必須通用(general),能夠處理引擎支持的所有結構。而在程序設計中,「通用」意味著「速度慢」,所以此種優化把「.*」之類的簡單量詞作為一個「整體」,正則引擎便不必按照通用的辦法處理,而使用高速的,專門化的處理程序。這樣,通用引擎就繞過(short-circuit)了這些結構。
舉例來說,「.*」和「(?:.)*」在邏輯上是相等的,但是在進行此優化的系統中,「.*」實際上更快。舉一些例子:在java.util.regex中,性能提升在10%左右,但是在Ruby和.NET中,大概是2.5倍。在Python中,大概是50倍。在PHP/PCRE中,大概是150倍。因為Perl實現了下一節介紹的優化措施,「.*」和「(?:.)*」的速度是一樣的(請參考下一頁的補充內容,瞭解如何解釋這些數據)。
消除無必要括號
如果某種實現方式認為「(?:.)*」與「.*」是完全等價的,那麼它就會用後者替換前者。
消除不需要的字符組
只包含單個字符的字符組有點兒多餘,因為它要按照字符組來處理,而這麼做完全沒有必要。所以,聰明的實現方式會在內部把「[.]」轉換為「\.」。
忽略優先量詞之後的字符優化
忽略優先量詞,例如「〞(.*?)〞」中的『*?』,在處理時,引擎通常必須在量詞作用的對象(點號)和「〞」之後的字符之間切換。因為種種原因,忽略優先量詞通常比匹配優先量詞要慢,尤其是對上文中「化簡量詞優化」的匹配優先限定結構來說,更是如此。另一個原因是,如果忽略優先量詞在捕獲型括號之內,控制權就必須在括號內外切換,這樣會帶來額外的開銷。
所以這種優化的原理是,如果文字字符跟在忽略優先量詞之後,只要引擎沒有觸及那個文字字符,忽略優先量詞可以作為普通的匹配優先量詞來處理。所以,包含此優化的實現方式在這種情況下會切換到特殊的忽略優先量詞,迅速檢測目標文本中的文字字符,在遇到此文字字符之前,跳過常規的「忽略」狀態。
此優化還有各種其他形式,例如預查一組字符,而不是特殊的一個字符(例如,檢查「['〞] (.*?)[〞']」中的「['〞]」,這有點類似前面介紹的開頭字符識別優化)。

「過度」回溯檢測
第226頁的「實測」揭示的問題是,「(.+)*」之類的量詞結合結構,能夠製造指數級的回溯。避免這種情況的簡單辦法就是限定回溯的次數,在「超限」時停止匹配。在某些實際情況中這非常有用,但是它也為正則表達式能夠應用的文本人為設置了限制。
例如,如果上限是10 000次回溯,「.*?」就不能匹配長於10 000的字符,因為每個匹配的字符都對應一次回溯。這種情況並不罕見,尤其在處理Web頁時更是如此,所以這種限制非常糟糕。
出於不同的原因,某些實現方式限制了回溯堆棧的大小(也就是同時能夠保存的狀態的上限)。例如,Python的上限是10 000。就像回溯上限一樣,這也會限制正則表達式所能處理的文本的長度。
因為存在這個問題,本書中的某些性能測試構建起來非常困難。為了獲得最準確的結果,性能測試中計時部分應該盡可能多地完成正則表達式的匹配,所以我創建了極長的字符串,比較例如「〞(.*)〞」,「〞(.)*〞」,「〞(.)*?〞」和「〞([^〞])*?〞」的執行時間。為了保證結果有意義,我必須限制字符串的長度,以避免回溯計數或者堆棧大小的限制。你可以在 239 頁看到這個例子。
避免指數級(也就是超線性super-linear)匹配
避免無休止的指數級匹配的更好辦法是,在匹配嘗試進入超線性狀態時進行檢測。這樣就能做些額外的工作,來記錄每個量詞對應的子表達式嘗試匹配的位置,繞過重複嘗試。
實際上,超線性匹配發生時是很容易檢測出來的。單個量詞「迭代」(循環)的次數不應該比目標字符串的字符數量更多。否則肯定發生了指數級匹配。如果根據這個線索發現匹配已經無法終止,檢測和消除冗余的匹配是更複雜的問題,但是因為多選分支匹配次數太多,這麼做或許值得。
檢測超線性匹配並迅速報告匹配失敗的副作用(side effect)之一就是,真正缺乏效率的正則表達式並不會體現出效率的低下。即使使用這種優化,避免了指數級匹配,所花的時間也遠遠高於真正需要的時間,但是不會慢到很容易被用戶發現(不像是等到太陽落山一樣漫長,而可能是多消耗1/100s,對我們來說這很快,但對計算機來說很漫長)。
當然,總的來看可能還是利大於弊。許多人不關心正則表達式的效率——它們對正則表達式懷著一種恐懼心理,只希望能完成任務,而不關心如何完成。(你可能沒見過這種情況,但是我希望這本書能夠加強你的信心,就像標題說的那樣,精通正則表達式)。
使用佔有優先量詞削減狀態
由正常量詞約束的對象匹配之後,會保留若干「在此處不進行匹配」的狀態(量詞每一輪迭代創建一個狀態)。佔有優先量詞(☞142)則不會保留這些狀態。具體做法有兩種,一
種是在量詞全部嘗試完成之後拋棄所有備用狀態,效率更高的辦法是每一輪迭代時拋棄上一輪的備用狀態(匹配時總需要保存一個狀態,這樣在量詞無法繼續匹配的時候引擎還能繼續運轉)。
在迭代中即時拋棄狀態的做法效率更高,因為所佔的內存更少。應用「.* 」會在匹配每個字符時創造一個狀態,如果字符串很長,會佔用大量的內存。

量詞等價轉換
有人習慣用「\d\d\d\d」,也有人則習慣使用量詞「\d{4}」。兩者的效率有差別嗎?對NFA來說,答案幾乎是肯定的,但工具不同,結果也不同。如果對量詞做了優化,則「\d{4}」會更快一些,除非未使用量詞的正則表達式能夠進行更多的優化。聽起來有點迷惑?但事實確實如此。
我的測試結果表明,Perl、Python、PHP/PCRE和.NET中,「\d{4}」大概要快20%。但是,如果使用Ruby和Sun的Java regex package,「\d\d\d\d」則要快上好幾倍。所以,看起來量詞在某些工具中要更好一些,在另一些工具中則要差一些。不過,情況遠非如此簡單。
比較「====」和「={4}」。這個例子與上面的截然不同,因為此時重複的是確定的文字字符,而直接使用「====」引擎更容易將其識別為一個文字字符串。如果是,支持的高效的開頭字符/字符組/子串識別優化(☞247)就可以派上用場。對Python和Sun的Java regex package來說,情況正是如此,「====」比「={4}」快上100倍。
Perl、Ruby和.NET的優化手段更高級,它們不會區分「====」和「={4}」,結果,兩者是一樣快的(而且都比「\d\d\d\d」和「\d{4}」的例子快成百上千倍)。
需求識別
另一種簡單的優化措施是,引擎會預先取消它認為對匹配結果沒有價值的(例如,在不必捕獲文本的地方使用了捕獲型括號)工作。識別能力在很大程度上依賴於編程語言,不過這種優化實現起來也可以很容易,如果在匹配時能夠指定某些選項,就能禁止某些代價高昂的特性。
Tcl就能夠進行這種優化。除非用戶明確要求,否則它的捕獲型括號並不會真正捕獲文本。而.NET的正則表達式提供了一個選項,容許程序員指定捕獲型括號是否需要捕獲。