
Extended Examples
下面的幾個例子講解了一些關於正則表達式的重要訣竅。討論會稍微多一些,關於解決辦法和錯誤思路的著墨也會更多一些,最終會給出正確答案。

保持數據的協調性
Keeping in Sync with Your Data
我們來看一個長一點的例子,它有點極端,但很清楚地說明了保持協調的重要性(同時提供了一些保持協調的方法)。
假設,需要處理的數據是一系列連續的5位數美國郵政編碼(ZIP Codes),而需要提取的是以44開頭的那些編碼。下面是一點抽樣,我們需要提取的數值用粗體表示:
03824531449411615213441829505344272752010217443235
最容易想到的「ddddd」,它能匹配所有的郵政編碼。在 Perl 中可以用@zips=m/ddddd/g;來生成以郵政編碼為元素的list(為了讓這些例子看起來更整潔,我們假設需要處理的文本在Perl的默認目標變量$_中,見☞79)。如果使用其他語言,也只需要循環調用正則表達式的 find 方法。我們關注的是正則表達式本身,而不是語言的實現機制,所以下面繼續使用Perl。
回到「ddddd」,下面提到的這一點很快就會體現出其價值;在整個解析過程中,這個正則表達式任何時候都能夠匹配——絕對沒有傳動裝置的驅動和重試(我假設所有的數據都是規範的,此假設與具體情況密切相關)。
很明顯,把「ddddd」改為「44ddd」來查找以 44 開頭的郵政編碼不是個好辦法——匹配失敗之後,傳動裝置會驅動前進一個字符,對「44…」的匹配不再是從每個郵政編碼的第一位開始。「44ddd」會錯誤地匹配『…5314494116…』。
當然,我們可以在正則表達式的開頭添加「A」,但是這樣只能對付一行文本中的第一個郵政編碼。我們需要手動保持正則引擎的協調,才能忽略不需要的郵政編碼。這裡的關鍵是,要跳過完整的郵政編碼,而不是使用傳動裝置的驅動過程(bump-along)來進行單個字符的移動。
根據期望保持匹配的協調性
下面列舉了幾種辦法用來跳過不需要的郵政編碼。把它們添加到正則表達式「44ddd」之前,可以獲得期望的結果。非捕獲型括號用來匹配不期望的郵政編碼,這樣能夠快速地略過它們,找到匹配的郵政編碼,在第一個$1的捕獲括號中:
「(?:[^4]dddd|d[^4]ddd)*…」
這種硬辦法(brute-force method)主動略過非44開頭的郵政編碼(當然,用「[1235-9]」替代「[^4]」可能更合適,但我之前說過,假設處理的是規範的數據)。注意,我們不能使用「(?:[^4][^4]ddd)*」,因為它不會匹配(也就無法略過)43210 這樣不期望的郵政編碼。
「(?:(?!44)ddddd)*…」
這個辦法跳過非44開頭的郵政編碼。其中的想法與之前並無差別,但用正則表達式寫出來就顯得大不一樣。比較這兩段描述和相關的正則表達式就會發現,在這裡,期望的郵政編碼(以44開頭)導致逆序環視(?!44)失敗,於是略過停止。
「(?:ddddd)*?…」
這個辦法使用忽略優先量詞,只有在需要的時候才略過某些文本。我們把它放在真正需要匹配的正則表達式前面,所以如果那個表達式失敗,它就會匹配一個郵政編碼。忽略優先「(…)*?」導致這一切的發生。因為存在忽略優先量詞,「(?:ddddd)」甚至都不會嘗試匹配,在後面的表達式失敗之前。星號確保了,它會重複失敗,直到最終找到匹配文本,這樣就能只跳過我們希望跳過的文本。
把這個表達式和「(44ddd)」合起來,就得到:
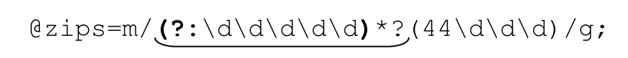
它能夠提取以44開頭的郵編,而主動跳過其他的郵編(在「@array=m/…/g」的情況下,Perl會用每次嘗試中找到的匹配文本來填充這個數組,☞311)。這個表達式能夠重複應用於字符串,因為我們知道每次匹配的「起始匹配位置」都是某個郵政編碼的開頭位置,也就保證下一次匹配是從一個郵政編碼的開始,這正是正則表達式期望的。
不匹配時也應當保證協調性
我們是否能保證,每次正則表達式都在郵政編碼字符串的開頭位置應用?顯然不是!我們手動跳過了不符合要求的郵政編碼,可一旦不需要繼續匹配,本輪匹配失敗之後自然就是驅動過程和重試,這樣就會從郵政編碼字符串之中的某個位置開始——我們的方法不能處理這種情況。
再來看數據樣本:
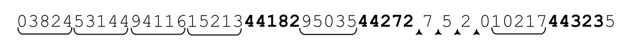
匹配的代碼以粗體標注(第三組不符合要求),主動跳過的代碼以下畫線標注,通過驅動過程-重試略過的字符也標記出來。在44272匹配之後,目標文本中再也找不到匹配,所以本輪嘗試宣告失敗。但總的嘗試並沒有宣告失敗。傳動機構會進行驅動,從字符串的下一個字符開始應用正則表達式,這樣就破壞了協調性。在第四次驅動之後,正則表達式略過10217,錯誤地匹配44323。
如果在字符串的開頭應用,這三個表達式都沒有問題,但是傳動裝置的驅動過程會破壞協調性。如果我們能取消驅動過程,或者保證驅動過程不會添麻煩,問題就解決了。
辦法之一是禁止驅動過程,即在前兩種辦法中的「(44ddd)」之後添加「?」,將其改為匹配優先的可選項。這樣,刻意安排的「(?:(?!44)ddddd)*…」或「(?:[^4]dddd|d[^4]ddd)*…」就只會在兩種情況下停止:發生符合要求的匹配,或者郵政編碼字符串結束(這也是此方法不適用於第三個表達式的原因)。這樣,如果存在符合要求的郵政編碼,「(44ddd)?」就能匹配,而不會強迫回溯。
這個辦法仍然不夠完善。原因之一是,即便目標字符串中沒有符合要求的郵政編碼,也會匹配成功,接下來的處理程序會變得更複雜。不過,其優點在於速度很快,因為不需要回溯,也不需要傳動裝置進行任何驅動過程。
使用G保證協調
更通用的辦法是在這三個表達式末尾添加「G」(☞130)。因為每個表達式的每次匹配都以符合要求的郵政編碼結尾,下次匹配開始時就不會進行驅動。而如果有驅動過程,開頭的「G」會立刻導致匹配失敗,因為在大多數流派中,只有在未發生驅動過程的情況下,它才能成功匹配(但在Ruby和其他規定「G」表示「本次匹配起始位置」的流派中不成立☞131)
所以第二個表達式就變成了:
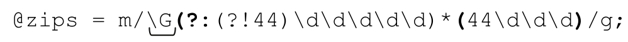
匹配之後不需要進行任何特殊檢查。
本例的意義
我首先承認,這個例子有點極端,不過,它包含了許多保證正則表達式與數據協調性的知識。如果現實生活中需要處理這樣的問題,我可能不會完全用正則表達式來解決。我會直接用「ddddd」來提出每個郵政編碼,然後檢查它是否以『44』開頭。在Perl中是這樣:

對「G」有興趣的讀者請參考132頁的補充內容,儘管本書寫作時只能舉Perl的例子。
解析CSV文件
Parsing CSV Files
解析CSV(逗號分隔值)文件有點麻煩,因為每個程序都有自己的CSV文件格式。首先來看如何解析Microsoft Excel生成的CSV文件,然後再看其他格式(注3)。幸運的是,Microsoft的格式是最簡單的。以逗號分隔的值要麼是「純粹的」(僅僅包含在括號之前),要麼是在雙引號之間(這時數據中的雙引號以一對雙引號表示)。
下面是個例子:
Ten Thousand,10000,2710,,〞10,000〞,〞It\'s 〞〞10 Grand〞〞,baby〞,10K這一行包含七個字段(fields):

為了從此行解析出各個字段,我們的正則表達式需要能夠處理兩種格式。非引號格式包含引號和逗號之外的任何字符,可以用「[^〞,]+」匹配。
雙引號字段可以包含逗號、空格,以及雙引號之外的任何字符。還可以包含連在一起的兩個雙引號。所以,雙引號字段可以由「〞…〞」之間任意數量的「[^〞]|〞〞」匹配,也就是「〞(?:[^〞]|〞〞)*〞」(為效率考慮,我們可以使用固化分組「(?>…)」來替代「(?:…)」,不過這個話題留到下一章☞259)。
綜合起來,「[^〞,]+|〞(?:[^〞]|〞〞)*〞」能夠匹配一個字段。這可能有點難看懂,下面我們給出寬鬆排列(☞111)格式:

現在這個表達式可以實際應用到包含CSV文本行的字符串上了,但如果我們希望真正利用匹配結果,就應該知道具體是哪個多選分支匹配了。如果是雙引號字符串,就需要去掉首尾兩端的雙引號,把其中緊挨著的兩個雙引號替換為單個雙引號。
我能想到的辦法有兩個。其一是檢查匹配結果的第一個字符是否雙引號,如果是,則去掉第一個和最後一個字符(雙引號),然後把中間的『〞〞』替換為『〞』。這辦法夠簡單,但如果使用捕獲型括號會更簡單。如果我們給捕獲字段的每個子表達式添加捕獲型括號,可以在匹配之後檢查各個分組的值:

如果是第一個分組捕獲,則不需要進行任何處理,如果是第二個分組,則只需要把『〞〞』替換為『〞』即可。
下面給出Perl的程序,稍後(找出某些bug之後)給出Java和VB.NET(在第10章給出PHP 的程序☞480)。下面是Perl 程序,假設數據位於$line中,而且已經去掉了結尾的換行符(換行符不屬於最後的字段!):

將其應用於測試數據,結果為:
[Ten·Thousand][10000][·2710·][10,000][It\'s·〞10·Grand〞,·baby][10K]
看來沒問題,但不幸的是它不會輸出為空的第四個字段。如果「處理$field」是將字段的值存入數組,完成後訪問數組的第五個元素得到第五個字段(「10,000」)。這顯然不對,因為數組的元素與空字段不對應。
想到的第一個辦法是把「[^〞,]+」改為「[^〞,]*」,這看來是顯而易見的,但它正確嗎?
測試一下,下面是結果:
[Ten·Thousand][10000][·2710·][10,000][It\'s·〞10·Grand〞,…
哇,現在出來了一堆空字段!仔細檢查檢查,就不會這麼吃驚。「(…)*」的匹配可以不佔用任何字符。如果真的遇到空字段,確實能匹配,那麼考慮第一個字段匹配之後的情況呢,此時正則表達式從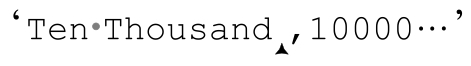 開始應用。如果表達式中沒有元素可以匹配逗號(就本例來說),就會發生長度為0的成功匹配。實際上,這樣的匹配可能有無窮多次,因為正則引擎可能在同一位置重複這樣的匹配,現代的正則引擎會強迫進行驅動過程,所以同一位置不會發生兩次長度為 0 的匹配(☞131)。所以每個有效匹配之間還有一個空匹配,在每個引號字段之前會多出一個空匹配(而且數組末尾還會有一個空匹配,只是此處沒有列出來)。
開始應用。如果表達式中沒有元素可以匹配逗號(就本例來說),就會發生長度為0的成功匹配。實際上,這樣的匹配可能有無窮多次,因為正則引擎可能在同一位置重複這樣的匹配,現代的正則引擎會強迫進行驅動過程,所以同一位置不會發生兩次長度為 0 的匹配(☞131)。所以每個有效匹配之間還有一個空匹配,在每個引號字段之前會多出一個空匹配(而且數組末尾還會有一個空匹配,只是此處沒有列出來)。
分解驅動過程
要解決問題,我們就不能依賴傳動機構的驅動過程來越過逗號。所以,我們需要手工來控制。能想到的辦法有兩個:
1.手工匹配逗號。如果採取此辦法,需要把逗號作為普通字段匹配的一部分,在字符串中「邁步(pace ourselves)」。
2.確保每次匹配都從字段能夠開始的位置開始。字段可以從行首,或者是逗號開始。
可能更好的辦法是把兩者結合起來。從第一種辦法(匹配逗號本身)出發,只需要保證逗號出現在第一個字段之外的所有字段開頭。或者,保證逗號出現在最後一個字段之外的所有字段的末尾。可以在表達式前面添加「^|,」,或者後面添加「$|,」,用括號控制範圍。
在前面添加,就得到:

看起來它應當沒錯,但實際的結果卻是:
[Ten·Thousand][10000][·2710·][000][·baby][10K]
而我們期望的是:
[Ten·Thousand][10000][·2710·][10,000][It\'s·〞10‧Grand〞,·baby][10K]
問題出在哪裡呢?似乎是雙引號字段沒有正確處理,所以問題出在它身上,對嗎?不對,問題在前面。或許 176 頁的告誡有所幫助:如果多個多選分支能夠在同一位置匹配,必須小心地排列順序。第一個多選分支「[^〞,]*」不需要匹配任何字符就能成功,除非之後的元素強迫,否則第二個多選分支不會獲得嘗試的機會。而這兩個多選分支之後沒有任何元素,所以第二個多選分支永遠不會得到嘗試的機會,這就是問題所在!
哇,現在我們已經找到了問題所在。OK,交換一下多選分支的順序:

對了!至少對測試數據來說是對了。如果數據變了,還是這樣嗎?本節的標題是「分解驅動過程」,而最保險的辦法就是以完整測試作為基礎的思考,故可以用「G」來確保每次匹配從上一次匹配結束的位置開始。考慮到構建和應用正則表達式的過程,這樣做應該絕對沒問題。如果在表達式開始添加「G」,就會禁止引擎的驅動過程。我們希望這樣修改不會出問題,但是結果並非如此。之前輸出
[Ten·Thousand][10000][·2710·][000][·baby][10K]
的正則表達式添加G之後,得到
[Ten·Thousand][10000][·2710·]
如果起初沒看明白,這樣看會更明顯。

另一個辦法
本節的開頭提到有兩種辦法正確匹配各個字段。之二是確保匹配只能在容許出現字段的地方開始。從表面上看,這類似於添加「^|,」,只是使用了逆序環視「(?<=^|,)」。
不幸的是,按照第3章(☞133)的解釋,即使可以使用逆序環視,也不見得能夠使用變長的逆序環視,所以此方法可能無法使用。如果問題在於長度可變,我們可以把「(?<=^|,)」替換為「(?:^|(?<=,))」,但是相比第一種辦法,它太麻煩了。而且,它仍然依賴傳動裝置的驅動過程來越過逗號,如果別的地方出了什麼差錯,它會容許在『…〞10,☞000〞…』處的匹配。總的來說就是,不如第一種辦法保險。
不過我們可以略施小計——要求匹配在逗號之前(或者是一行結束之前)結束。在表達式結尾添加「(?=$|,)」可以確保它不會進行錯誤的匹配。實際生活中,我會這樣做嗎?直率地說我覺得第一種方法很合用,所以遇到這種情況我可能不會採取第二種辦法,不過如果需要,這技巧卻是很有用的。
進一步提高效率
儘管在下一章之前都不會談論效率,但對於支持固化分組(☞139)的系統,我還是願意在這裡給出提高效率的修改:把匹配雙引號字段的子表達式從「(?:[^〞]|〞〞)*」改為「(?>[^〞]+|〞〞)*」。下一頁用VB.NET的例子做了說明。
如果像Sun的Java regex package那樣支持佔有優先量詞(☞142),也可以使用佔有優先量詞。Java CSV程序的補充內容說明了這一點。
這些修改背後的道理會在下一章講解,最終我們會在271頁給出效率最高的辦法。
其他CSV格式
Micorsoft的CSV格式很流行,因為它是Microsoft的CSV格式,但其他程序可能有不同格式,我見過的情況還有:
●使用任意字符,例如\';\'或者製表符作為分隔。(不過這樣名字還能叫「逗號分隔值」嗎?)
●容許分隔符之後出現空格,但不把它們作為值的一部分。
●用反斜線轉義引號(例如用『〞』而不是『〞〞』類表示值內部的引號)。通常這意味著反斜線可以在任何字符前出現(並忽略)。
這些變化都很容易處理。第一種情況只需要把逗號替換為對應的分隔符,第二種只需要在第一個分隔符之後添加「s*」,例如以「(?:^|,s*)」開頭。
第三種情況,我們可以用之前的辦法(☞198),把「[^〞]+|〞〞」替換為「[^\\〞]+|\\.」。當然,我們必須把後面的s/〞〞/〞/g改為更通用的s/\\(.)/$1/g,或者對應語言中的代碼。
