
A Few Short Examples
匹配連續行(續前)
Continuing with Continuation Lines
繼續前一章中匹配連續行的例子(☞178),我們發現(在傳統型NFA中使用「^\w+=.*(\\\n.*)*」並不能匹配下面的兩行文本:

問題在於,第一個「.*」一直匹配到反斜線之後,這樣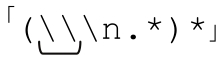 就不能按照預期匹配反斜線了。所以,本章出現的第一條經驗就是:如果不需要點號匹配反斜線,就應該在正則表達式中做這樣的規定。我們可以把每個點號替換成「[^\n\\]」(請注意,\n包含在排除性字符組中。你應該記得,原來的正則表達式的假設之一就是,點號不會匹配換行符,我們也不希望它的替代品能夠匹配換行符☞119頁)。
就不能按照預期匹配反斜線了。所以,本章出現的第一條經驗就是:如果不需要點號匹配反斜線,就應該在正則表達式中做這樣的規定。我們可以把每個點號替換成「[^\n\\]」(請注意,\n包含在排除性字符組中。你應該記得,原來的正則表達式的假設之一就是,點號不會匹配換行符,我們也不希望它的替代品能夠匹配換行符☞119頁)。
於是,我們得到:
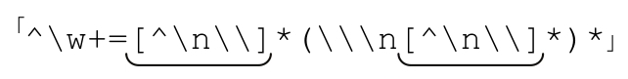
它確實能夠匹配連續行,但因此也產生了一個新的問題:這樣反斜線就不能出現在一行的非結尾位置。如果需要匹配的文本中包含其他的反斜線,這個正則表達式就會出問題。現在我們假設它會包含,所以需要繼續改進正則表達式。
迄今為止,我們的思路都是,「匹配一行,如果還有連續行,就繼續匹配」。現在換另一種思路,這種思路我覺得通常都會奏效:集中關注在特定時刻真正容許匹配的字符。在匹配一行文本時,我們期望匹配的要麼是普通(除反斜線和換行符之外)字符,要麼是反斜線與其他任何字符的結合體。在點號通配模式中,「\\.」能匹配反斜線加換行符的結合體。
所以,正則表達式就變成了「^\w+=([^\n\\]|\\.)*」,在點號通配模式下。因為開頭是「^」,如果需要,可能得使用增強的文本行錨點匹配模式(☞112)。
但是,這個答案仍然不夠完美——我們會在下一章講解效率問題時再次看到它(☞270)。
匹配IP地址
Matching an IP Address
來看個複雜點的例子,匹配一個IP(Internet Protocol,因特網協議)地址:用點號分開的四個數,例如1.2.3.4。通常情況下,每個數都有三位,例如001.002.003.004。你可能會想到用「[0-9]*\.[0-9]*\.[0-9]*\.[0-9]*」從文本中提取一個IP地址,但是這個表達式顯然不夠精緻,它甚至會匹配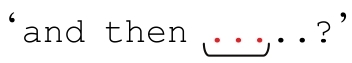 』。仔細看看就會發現,這個表達式甚至不需要匹配任何數字——它只需要三個點號(當然也可能包括其間的數字)。
』。仔細看看就會發現,這個表達式甚至不需要匹配任何數字——它只需要三個點號(當然也可能包括其間的數字)。
為解決這個問題,我們首先把星號改成加號,因為我們知道,每一段必須有至少一位數字。為確保整個字符串的內容就是一個IP地址,我們可以在首尾加上「^...$」,於是我們得到:
「^[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+$」
如果用「\d」替換「[0-9]」,就得到「^\d+\.\d+\.\d+\.\d+$」,這樣可能更好看一些(注1),但是,這個表達式仍然會捕獲一些並非IP地址的數據,例如『1234.5678.9101112.131415』(IP地址的每個字段都在0-255以內)。那麼,你可以強行規定每個字段必須包含三位數字,就是「^\d\d\d\.\d\d\d\.\d\d\d\.\d\d\d$」,但這樣未免太不靈活(too specific)了。即使某個字段只有一位或者兩位數字(例如 1.234.5.67),也應該匹配。如果流派支持區間量詞{min,max},就可以這麼寫「^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$」。如果不支持,則可以用「\d\d?\d?」或者「\d(\d\d?)?」。這兩種方式略有不同,但都能匹配一到三個數字。
現在,正則表達式中的匹配精度可能已經滿足需求了。如果要更精確,就必須考慮到,「\d{1,3}」能夠匹配999,而它超過了255,所以它不是一個合法的IP地址。
我們有好幾種辦法來匹配0和255之間的數字。最笨的辦法就是「0|1|2|3|…253|254|255」。不過這又不能處理以0開頭的數字,所以必須寫成「0|00|000|1|01|001…」,這樣一來,正則表達式就長得過分了。對於DFA引擎來說,問題還只是它太長太繁雜——但匹配的速度與其他等價正則表達式是一樣的。但對於NFA引擎,太多的多選分支簡直就是效率殺手。
實際的解決辦法是,關注字段中什麼位置可以出現哪些數字。如果一個字段只包含一個或者兩個數字,就無需擔心這個字段的值是否合法,所以「\d|\d\d」就能應付。也不比擔心那些以0或者1開頭的三位數,因為000-199都是合法的IP地址。所以我們加上「[01]\d\d」,得到「\d|\d\d|[01]\d\d」。你可能覺得這有點像第1章裡匹配時間的例子(☞28),和前一章中匹配日期的例子(☞177)。
繼續看這個正則表達式,以 2開頭的三位數字,如果小於 255就是合法的,所以第二位數字小於5就代表整個數也是合法的。如果第二位數字是5,第三位數字就必須小於6。這可以表示為「2[0-4]\d|25[0-5]」。
現在這個正則表達式有點看不懂了,但分析之後還是能夠理解其中包含的思路。結果就是「\d|\d\d|[01]\d\d|2[0-4]\d|25[0-5]」。其實我們可以合併前面三個多選分支,得到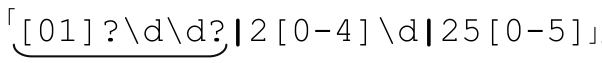 。在NFA中,這樣做的效率更高,因為任何多選分支匹配失敗都會導致回溯。請注意,第一個多選分支中用的是「\d\d?」,而不是「\d?\d」,這樣,如果根本不存在數字,NFA 會更快地報告匹配失敗。我把這個問題的分析留給讀者——通過一個簡單的驗證就能發現二者的區別。我們還可以做些修改進一步提高這個表達式的效率,不過這要留待下一章討論了。
。在NFA中,這樣做的效率更高,因為任何多選分支匹配失敗都會導致回溯。請注意,第一個多選分支中用的是「\d\d?」,而不是「\d?\d」,這樣,如果根本不存在數字,NFA 會更快地報告匹配失敗。我把這個問題的分析留給讀者——通過一個簡單的驗證就能發現二者的區別。我們還可以做些修改進一步提高這個表達式的效率,不過這要留待下一章討論了。
現在這個表達式能夠匹配0 到255 之間的數,我們用括號把它包起來,用來取代之前表達式中的「\d{1,3}」,就得到:
「^([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])$」
這可真叫複雜!需要這麼麻煩嗎?這得根據具體需求來決定。這個表達式只會匹配合法的IP地址,但是它也會匹配一些語意不正確的IP地址,例如0.0.0.0(所有字段都為零的IP地址是非法的)。使用環視功能(☞133)可以在「^」後添加「(?!0+\.0+\.0+\.0+$)」,但是某些時候,處理各種極端情形會降低成本/收益的比例。某些情況下,更合適的做法就是不依賴正則表達式完成全部工作。例如,你可以只使用「^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$」,用括號把每個字段括起來,把數字變成程序中的$1、$2、$3、$4,這樣就可以用其他程序來驗證了。
確定應用場合(context)
這個正則表達式必須借助錨點「^」和「$」才能正常工作,認識到這一點很重要。否則,它就可能匹配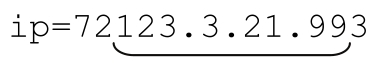 ,如果使用傳統型NFA,則可能匹配
,如果使用傳統型NFA,則可能匹配 。
。
在第二個例子中,這個表達式甚至連最後的 223 都無法完整匹配。但是,問題並不在於表達式本身,因為沒有東西(例如分隔符,或者末尾的錨點)強迫它匹配223。最後那個分組的第一個多選分支「[01]?\d\d?」,匹配了前面兩位數字,如果末尾沒有「$」,匹配到此就結束了。在前一章日期匹配的例子中,我們可以安排多選分支的次序來達到期望的目的。現在我們也把能把匹配三位數字的多選分支放在最前面,這樣在匹配兩位數的多選分支獲得嘗試機會之前,任何三位數都能完全匹配(DFA和POSIX NFA當然不需要這樣安排,因為它們總是返回最長的匹配文本)。
無論是否重新排序,第一個錯誤仍然不可避免。「啊哈!」,你可能會想,「我可以用單詞分界符錨點來解決這個問題。」不幸的是,這也不能奏效,因為這樣的正則表達式仍然能夠匹配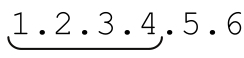 。為了避免匹配這樣內嵌的文本,我們必須確保匹配文本兩側至少沒有數字或者點號。如果使用環視,可以在原來表達式的首尾添加「(?<![\w.])…(?![\w.])」來保證匹配文本之前(以及之後)不出現「[\w.]」能匹配的字符。如果不支持環視,在首尾添加「(^|·)…(·|$)」也能夠應付某些情況。
。為了避免匹配這樣內嵌的文本,我們必須確保匹配文本兩側至少沒有數字或者點號。如果使用環視,可以在原來表達式的首尾添加「(?<![\w.])…(?![\w.])」來保證匹配文本之前(以及之後)不出現「[\w.]」能匹配的字符。如果不支持環視,在首尾添加「(^|·)…(·|$)」也能夠應付某些情況。
處理文件名
Working with Filenames
處理文件名和路徑,例如 Unix 下的/usr/local/bin/Perl 或者 Windows 下的\Program Files\Yahoo!\Messenger,很適合用來講解正則表達式的應用。因為「動手(using)」比「觀摩(reading)」更有意思,我會同時用Perl、PHP(preg程序)、Java和VB.NET來講解。如果你對其中的某些語言不感興趣,不妨完全跳過那些代碼——其中蘊含的思想才是最重要的。
去掉文件名開頭的路徑
第一個例子是去掉文件名開始的路徑,例如把/usr/local/bin/gcc變成gcc。從本質層面來考慮問題是成功的一半。在本例中,我們希望去掉在最後的斜線(含)之前(在Windows中是反斜線)的任何字符。如果沒有斜線最好,因為什麼也不用干。我曾說過,「.* 」常常被濫用,但是此處我們需要匹配優先的特性。「^.*/」中的「.*」可以匹配一整行,然後回退(也就是回溯)到最後的斜線,來完成匹配。
下面是四種語言的代碼,去掉變量f中的文件名中開頭的路徑。對於Unix的文件名:

正則表達式(或者說用來表示正則表達式的字符串)以下畫線標注,正則表達式相關的組件則由粗體標注。
下面是處理Windows文件名的代碼,Windows中的分隔符是反斜線而不是斜線,所以要用正則表達式「^.*\\」。在正則表達式中,我們需要在反斜線前再加一個反斜線,才能表示轉義的反斜線,不過,在中間兩段程序中添加的這個反斜線本身也需要轉義:

從中很容易看出各種語言的差異,尤其是Java中那4個反斜線(☞101)。
有一點請務必記住:別忘了時常想想匹配失敗的情形。在本例中,匹配失敗意味著字符串中沒有斜線,所以不會替換,字符串也不會變化,而這正是我們需要的。
為了保證效率,我們需要記住NFA引擎的工作原理。設想下面這種情況:我們忘記在正則表達式的開頭添加「^」符號(這個符號很容易忘記),用來匹配一個恰好沒有斜線的字符串。同樣,正則引擎會在字符串的起始位置開始搜索。「.* 」抵達字符串的末尾,但必須不斷回退,以找到斜線或者反斜線。直到最後它交還了匹配的所有字符,仍然無法匹配。所以,正則引擎知道,在字符串的起始位置不存在匹配,但這遠遠沒有結束。
接下來傳動裝置開始工作,從在目標字符串的第 2 個字符開始,依次嘗試匹配整個正則表達式。事實上,它需要在字符串的每個位置(從理論上說)進行掃瞄-回溯。文件名通常很短,因此這不是一個問題,但原理確實如此。如果字符串很長,就可能存在大量的回溯(當然,DFA不存在這個問題)。
在實踐中,經過合理優化的傳動裝置能夠認識到,對幾乎所有以「.*」開頭的正則表達式來說,如果在某個字符串的起始位置不能匹配,也就不能在其他任何位置匹配,所以它只會在字符串的起始位置(☞246)嘗試一次。不過,在正則表達式中寫明這一點更加明智,在例子中我們正是這樣做的。
從路徑中獲取文件名
另一種辦法是忽略路徑,簡單地匹配最後的文件名部分。最終的文件名就是從最後一個斜線開始的所有內容:「[^/]*$」。這一次,錨點不僅僅是一種優化措施,我們確實需要在結尾設置一個錨點。現在我們可以這樣做,以Perl來說明:
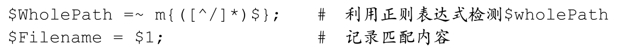
你也許注意到了,這裡並沒有檢查這個正則表達式能否匹配,因為它總是能匹配。這個表達式的唯一要求就是,字符串有$能夠匹配的結束位置,而即使是空字符串也有一個結束位置。因此,我用$1來引用括號內的表達式匹配的文本,因為它必定包括某些字符(如果文件名以斜線結尾,結果就是空字符)。
這裡還需要考慮到效率:在NFA中,「[^/]*$」的效率很低。仔細想想NFA引擎的匹配過程,你會明白它包括了太多的回溯。即使是短短的『/usr/local/bin/perl』,在獲得匹配結果之前,也要進行四十多次回溯。考慮從 開始的嘗試。「[^/]*」一直匹配到第二個l,之後匹配失敗,然後對l、a、c、o、l的存儲狀態依次嘗試「$」(都無法匹配)。如果這還不夠,又會從
開始的嘗試。「[^/]*」一直匹配到第二個l,之後匹配失敗,然後對l、a、c、o、l的存儲狀態依次嘗試「$」(都無法匹配)。如果這還不夠,又會從 開始重複這個過程,接著從
開始重複這個過程,接著從 開始,不斷重複。
開始,不斷重複。
這個例子不應該消耗我們太多的精力,因為文件名一般都很短(40 次回溯幾乎可以忽略不計——4 000萬次回溯才真正要緊)。再一次,重要的是理解問題本身,這樣才能選擇合適的通用規則來解決具體的問題。
需要指出的是,縱然本書是關於正則表達式的,但正則表達式也不總是最優解。例如,大多數程序設計語言都提供了處理文件名的非正則表達式函數。不過為了講解正則表達式,我仍會繼續下去。
所在路徑和文件名
下一步是把完整的路徑分為所在路徑和文件名兩部分。有許多辦法做到這一點,這取決於我們的要求。開始,你可能想要用「^(.*)/(.*)$」的$1和$2來提取這兩者。看起來這個正則表達式非常直觀,但知道了匹配優先量詞的工作原理之後,我們知道第一個「.*」會首先捕獲所有的文本,而不給「/」和$2留下任何字符。第一個「.*」能交還字符的唯一原因,就是在嘗試匹配「/(.*)$」時進行的回溯。這會把「交還的」部分留給後面的「.*」。因此,$1 就是文件所在的路徑,$2就是文件的名字。
需要注意的是,我們依靠開頭的「(.*)/」來確保第二個「(.*)」不會匹配任何斜線。理解匹配優先之後,我們知道這沒問題。如果要做的更精確,可以使用「[^/]*」來捕捉文件名。於是我們得到「^(.*)/([^/]*)$」。這個表達式準確地表達了我們的意圖,一眼就能看明白。
這個表達式有個問題,它要求字符串中必須出現一個斜線,如果我們用它來匹配file.txt,因為無法匹配,所以沒有結果。如果我們希望精益求精,可以這樣:

匹配對稱的括號
Matching Balanced Sets of Parentheses
對稱的圓括號、方括號之類的符號匹配起來非常麻煩。在處理配置文件和源代碼時,經常需要匹配對稱的括號。例如,解析 C 語言代碼時可能需要處理某個函數的所有參數。函數的參數包含在函數名稱之後的括號裡,而這些參數本身又有可能包含嵌套的函數調用或是算式中的括號。我們先不考慮嵌套的括號,你或許會想到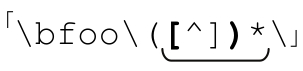 ,但這行不通。
,但這行不通。
秉承 C 的光榮傳統,我把示範函數命名為 foo。表達式中的標記部分是用來捕獲參數的。對於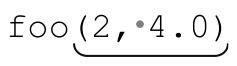 和
和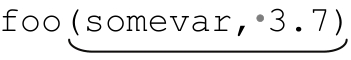 之類的參數,這個表達式完全沒問題。但是,它也可以匹配
之類的參數,這個表達式完全沒問題。但是,它也可以匹配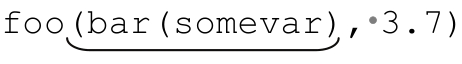 ,這可不是我們需要的。所以要用到比「[^)]*」更聰明的辦法。
,這可不是我們需要的。所以要用到比「[^)]*」更聰明的辦法。
為了匹配括號部分,我們可以嘗試下面的這些正則表達式:
1.\(.*\)括號及括號內部的任何字符。
2.\([^)]*\)從一個開括號到最近的閉括號。
3.\([^()]*\)從一個開括號到最近的閉括號,但是不容許其中包含開括號。
圖5-1顯示了對一行簡單代碼應用這些表達式的結果。
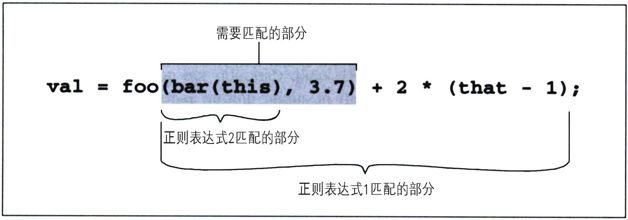
圖5-1:三個表達式的匹配位置
我們看到,第一個正則表達式匹配的內容太多(注2),第二個正則表達式匹配的內容太少,第三個正則表達式無法匹配。孤立地看,第三個正則表達式能夠匹配『(this)』,但是因為表達式要求它必須緊接在foo之後,所以無法匹配。所以,這三個表達式都不合格。
真正的問題在於,大多數系統中,正則表達式無法匹配任意深度的嵌套結構。在很長的時間內,這是放之四海而皆准的規則,但是現在Perl、.NET和PCRE/PHP都提供了解決的辦法(參見第328、436、475頁)。但是,即使不用這些功能,我們也可以用正則表達式來匹配特定深度的嵌套括號,但不是任意深度的嵌套括號。處理單層嵌套的正則表達式是:
「\[^]*(\([^]*\)[^]*)*\)」
這樣類推下去,更深層次的嵌套就複雜得可怕。但是,下面的 Perl 程序,在指定嵌套深度$depth之後,生成的正則表達式可以匹配最大深度為$depth的嵌套括號。它使用的是Perl的「string x count」運算符,這個運算符會把string重複count次:
$regex='\('.'(?:[^()]|\('x $depth.'[^()]*'.'\))*'x $depth.'\)';這個表達式留給讀者分析。
防備不期望的匹配
Watching Out for Unwanted Matches
有個問題很容易忘記,即,如果待分析的文本不符合使用者的預期,會發生什麼。假設你需要編寫一個過濾程序,把普通文本轉換為 HTML,你希望把一行連字符號轉換為 HTML中代表一條水平線的<HR>。如果使用搜索-替換命令 s/-*/<HR>/,它能替換期望替換的文本,但只限於它們在行開頭的情況。很奇怪嗎?事實上,s/-*/<HR>/會把<HR>添加到每一行的開頭,而無論這些行是否以連字符開頭。
請記住,如果某個元素的匹配沒有硬性規定任何必須出現的字符,那麼它總能匹配成功。「-*」從字符串的起始位置開始嘗試匹配,它會匹配可能的任何連字符。但是,如果沒有連字符,它仍然能匹配成功,這完全符合星號的定義。
在某位我非常尊重的作者的作品中出現過類似的例子,他用這個例子來講解正則表達式匹配一個數,或者是整數或者是浮點數。在它的正則表達式中,這個數可能以負數符號開頭,然後是任意多個數字,然後是可能的小數點,再是任何多的數字。他的正則表達式是「-?[0-9]*\.?[0-9]*」。
確實,這個正則表達式可以匹配1、-272.37、129238843.、.191919,甚至是-.0這樣的數。這樣看來,它的確是個不錯的正則表達式。
但是,你想過這個表達式如何匹配『this·has·no·number』『nothing·here』或是空字符串嗎?仔細看看這個正則表達式——每一個部分都不是匹配必須的。如果存在一個數,如果正則表達式從在字符串的起始位置開始,的確能夠匹配,但是因為匹配沒有任何必須元素。此正則表達式可以匹配每個例子中字符串開頭的空字符。實際上它甚至可以匹配『num·123』開頭的空字符,因為這個空字符比數字出現得更早。
所以,把真正意圖表達清楚是非常重要的。一個浮點數必須要有至少一位數字,否則就不是一個合法的值。我們首先假設,在小數點之前至少有一位數字(之後我們會去掉這個條件)。如果是,我們需要用加號來控制這些數字「-?[0-9]+」。
如果要用正則表達式來匹配可能存在的小數點(及其後的數字),就必須認識到,小數部分必須緊接在小數點之後。如果我們簡單地用「\.?[0-9]*」,那麼無論小數點是否存在,「[0-9]*」都可能匹配。
解決的辦法還是釐清我們的意圖:小數點(以及之後的數字)是可能出現的:「(\.[0-9]*)?」。這裡,問號限定(也可以叫「統治governs」或者「控制controls」)的不再是小數點,而是小數點和後面的小數部分。在這個結合體內部,小數點是必須出現的,如果沒有小數點,「[0-9]*」根本談不上匹配。
把它們結合起來,就得到「-?[0-9]+(\.[0-9]*)?」。這個表達式不能匹配『.007』,因為它要求整數部分必須有一位數字。如果我們作些修改,容許整數部分為空,就必須同時修改小數部分,否則這個表達式就可以匹配空字符(這是我們一開始就準備解決的問題)。
解決的辦法是為無法覆蓋的情況添加多選分支: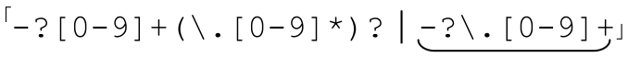 。這樣就能匹配以小數點開頭的小數(小數點是必須的)。仔細看看,仔細看看。你注意到了嗎?第二個多選分支同樣能夠匹配負數符號開頭的小數?這很容易忘記。當然,你也可以把「-?」提出來,放到所有多選結構的外面:「-?([0-9]+(\.[0-9]*)?|\.[0-9]+)」。
。這樣就能匹配以小數點開頭的小數(小數點是必須的)。仔細看看,仔細看看。你注意到了嗎?第二個多選分支同樣能夠匹配負數符號開頭的小數?這很容易忘記。當然,你也可以把「-?」提出來,放到所有多選結構的外面:「-?([0-9]+(\.[0-9]*)?|\.[0-9]+)」。
雖然這個表達式比最開始的好得多,但它仍然會匹配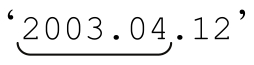 這樣的數字。要想真正匹配期望的文本,同時忽略不期望的文本,求得平衡,就必須瞭解實際的待匹配文本。我們用來提取浮點數的正則表達式必須包含在一個大的正則表達式內部,例如用「^…$」或者「num\s*=\s*…$」。
這樣的數字。要想真正匹配期望的文本,同時忽略不期望的文本,求得平衡,就必須瞭解實際的待匹配文本。我們用來提取浮點數的正則表達式必須包含在一個大的正則表達式內部,例如用「^…$」或者「num\s*=\s*…$」。
匹配分隔符之內的文本
Matching Delimited Text
匹配用分隔符(以某些字符表示)之類的文本是常見的任務,之前的匹配雙引號內的文本和IP地址只是這類問題中的兩個典型例子。其他的例子還包括:
●匹配『/*』和『*/』之間的C語言註釋。
●匹配一個HTML tag,也就是尖括號之內的文本,例如<CODE>。
●提取HTML tag標注的文本,例如在HTML代碼『a<I>super exciting</I>offer!』中的『super exciting』。
●匹配.mailrc文件中的一行內容。這個文件的每一行都按下面的數據格式來組織:
alias 簡稱 電子郵件地址
例如 『alias jeff [email protected]』(在這裡,分隔符是每個部分之間的空白和換行符)。
●匹配引文字符串(quoted string),但是容許其中包含轉義的引號,例如『a passport needs a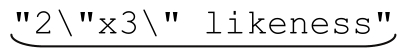 of the holder』。
of the holder』。
●解析CSV(逗號分隔值,comma-separated values)文件。
總的來說,處理這些任務的步驟是:
1.匹配起始分隔符(opening delimiter)。
2.匹配正文(main text,即結束分隔符之前的所有文本)。
3.匹配結束分隔符。
我曾經說過,如果結束分隔符不只一個字符,或者結束分隔符能夠出現在正文中,這種任務就很難完成。
容許引文字符串中出現轉義引號
來看2\〞x3\〞的例子,這裡的結束分隔符是一個引號,但正文也可能包含轉義之後的引號。匹配開始和結束分隔符很容易,訣竅就在於,匹配正文的時候不要超越結束分隔符。
仔細想想正文裡能夠出現的字符,我們知道,如果一個字符不是引號,也就是說如果這個字符能由「[^〞]」匹配,那麼它肯定屬於正文。不過,如果這個字符是一個引號,而它前面又有一個反斜線,那麼這個引號也屬於正文。把這個意思表達出來,使用環視(☞133)功能來處理「如果之前有反斜線」的情況,就得到「〞([^〞]|(?<=\\)〞)*〞」,這個表達式完全能夠匹配2\〞x3\〞。
不過,這個例子也能用來說明,看起來正確的正則表達式如何會匹配意料之外的文本,它雖然看起來正確,但不是任何情況下都正確。我們希望它匹配下面這個無聊的例子中的劃線部分:
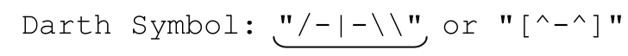
但它匹配的是:
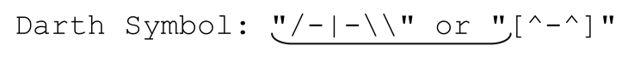
這是因為,第一個閉引號之前的確存在一個反斜線。但這個反斜線本身是被轉義的,它不是用來轉義之後的雙引號的(也就是說這個引號其實是表示引用文本的結束)。而逆序環視無法識別這個被轉義的反斜線,如果在這個引號之前有任意多個『\\』,用逆序環視只會把事情弄得更糟。原來的表達式的真正問題在於,如果反斜線是用來轉義引號的,在我們第一次處理它時,不會認為它是表示轉義的反斜線。所以,我們得用別的辦法來解決。
仔細想想我們想要匹配的位於開始分隔符和結束分隔符之間的文本,我們知道,其中可以包括轉義的字符(「\\.」),也可以包括非引號的任何字符「[^〞]」。於是我們得到「〞(\\.|[^〞])*〞」。不錯,現在這個問題解決了。不幸的是,這個表達式還有問題。不期望的匹配仍然會發生,比如對這個文本,它應該是無法匹配的,因為其中沒有結束分隔符。
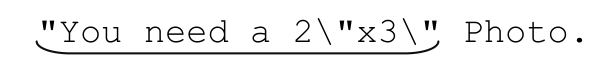
為什麼能匹配呢?回憶一下「匹配優先和忽略優先都期望獲得匹配」(☞167)。即使這個表達式一開始匹配到了引號之後的文本,如果找不到結束的引號,它就會回溯,到達

從這裡開始,「[^〞]」匹配到反斜線,之後的那個引號被認為是一個結束的引號。
這個例子給我們的重要啟示是:
如果回溯會導致不期望,與多選結構有關的匹配結果,問題很可能在於,任何成功的匹配都不過是多選分支的排列順序造成的偶然結果。
實際上,如果我們把這個正則表達式的多選分支反過來排列,它就會錯誤地匹配任何包含轉義雙引號的字符串。真正的問題在於,各個多選分支能夠匹配的內容發生了重疊。
那麼,應該如何解決這個問題呢?就像第186頁的那個連續行的例子一樣,我們必須確保,這個反斜線不能以其他的方式匹配,也就是說把「[^〞]」改為「[^\\〞]」。這樣就能識別雙引號和文本中的「特殊」反斜線,必須根據情況分別處理。結果就是「〞(\\.|[^\\〞])*〞」,它工作得很好(儘管這個正則表達式能夠正常工作,但對於NFA引擎來說,仍然有提升效率的改進,我們會在下一章更詳細地看這個例子,☞222)。
這個例子告訴我們一條重要的原理:
不應該忘記考慮這樣的「特殊」情形:例如針對「糟糕(bad)」的數據,正則表達式不應該能夠匹配。
我們的修改是正確的,但是有意思的是,如果有佔有優先量詞(☞142)或者是固化分組(☞139),這個正則表達式可以重新寫作「〞(\\.|[^〞])*+〞」和「〞(?>(\\.|[^〞])*)〞」。這兩個正則表達式禁止引擎回溯到可能出問題的地方,所以它們都可以滿足要求。
理解佔有優先量詞和固化分組解決此問題的原理非常有價值,但是我仍然要繼續之前的修正,因為對讀者來說它更具描述性(更直觀)。其實在這個問題上,我也願意使用佔有優先量詞和固化分組——不是為了解決之前的問題,而是為了效率,因為這樣報告匹配失敗的速度更快。
瞭解數據,做出假設
Knowing Your Data and Making Assumptions
現在是時候強調我曾經數次提到過的關於構建和使用正則表達式的一般規則了。知道正則表達式會在什麼情況中應用,關於目標數據又有什麼樣的假設,這非常重要。即使簡單如「a」這樣的數據也假設目標數據使用的是作者預期的字符編碼(☞105)。這都是一些很基本的常識,所以我一直沒有過分細緻地介紹。
但是,許多對某個人來說明顯的常識,可能對其他人來說並不明顯。例如,前一節的解決辦法假設轉義的換行符不會被匹配,或者會被應用於點號通配模式(☞111)。如果我們真的想要保證點號可以匹配換行符,同時流派也支持,我們應該使用「(?s:.)」。
前一節中我們還假設了正則表達式將應用的數據類型,它不能處理表示其他用途的雙引號。如果用這個正則表達式來處理任何程序的源代碼,就可能出錯,因為註釋中可能包括雙引號。
對數據做出假設,對正則表達式的應用方式做出假設,都無可厚非。問題在於,假設如果存在,通常會過分樂觀,也會低估了作者的意圖和正則表達式最終應用間的差異。記錄下這些假設會有幫助。
去除文本首尾的空白字符
Stripping Leading and Trailing Whitespace
去除文本首尾的空白字符並不難做到,這是經常要完成的任務。總的來說最好的辦法是使用下面兩個替換:
s/^\s+//;
s/\s+$//;
為了增加效率,我們用「+」而不是「*」,因為如果事實上沒有需要刪除的空白字符,就不用做替換。
出於某些考慮,人們似乎更希望用一個正則表達式來解決整個問題,所以我會提供一些方法供比較。我不推薦這些辦法,但對理解這些正則表達式的工作原理及其問題所在,非常有意義。
s/\s*(.*?)\s*$/$1/s
這個正則表達式曾被用作降解忽略優先量詞的絕佳例子,但現在不是了,因為人們認識到它比普通的辦法慢得多(在Perl中要慢5倍)。之所以效率這麼低,是因為忽略優先約束的點號每次應用時都要檢查「\s*$」。這需要大量的回溯。
s/^\s*((?:.*\S)?)\s*$/$1/s
這個表達式看起來比上一個要複雜,不過它的匹配倒是很容易理解,而且所花的時間也只是普通方法的2倍。在「^\s*」匹配了文本開頭的空格之後,「.*」馬上匹配到文本的末尾。後面的「\S」強迫它回溯直到找到一個非空的字符,把剩下的空白字符留給最後的「\s*$」,捕獲括號之外的。
問號在這裡是必須的,因為如果一行數據只包含空白字符的行,必須出現問號,表達式才能正常工作。如果沒有問號,可能會無法匹配,錯過這種只有空白字符的行。
s/^\s+|\s+$//g
這是最容易想到的正則表達式,但它不正確(其實這三個正則表達式都不正確),這種頂極的(top-leveled)多選分支排列嚴重影響本來可能使用的優化措施(參見下一章)。/g這個修飾符是必須的,它容許每個多選分支匹配,去掉開始和結束的空格。看起來,用/g是多此一舉,因為我們知道我們只希望去掉最多兩部分空白字符,每部分對應單獨的子表達式。這個正則表達式所用的時間是簡單辦法的4倍。
測試時我提到了相對速度,但是實際的相對速度取決於所用的軟件和數據。例如,如果目標文本非常非常長,而且在首尾只有很少的空格,中間的那個表達式甚至會比簡單的方法更快。不過,我自己在程序中仍然使用下面兩種形式的正則表達式:
s/^\s+//;s/\s+$//;
因為它幾乎總是最快的,而且顯然最容易理解。