
Match Basics
在瞭解不同引擎的差異之前,我們先看看它們的相似之處。汽車的各種動力系統在某些方面是一樣的(或者說,從實用的角度考慮,它們是一樣的),所以,下面的範例也能夠適用於所有的引擎。
關於範例
About the Examples
本章關注的是一般的提供所有功能的正則引擎,所以,某些程序並不能完全支持它們。在本書所說的汽車裡,機油油尺(dipstick)可能挨在機油濾清器(oil filter)的左邊,而在讀者那裡,它卻裝在分電盤蓋(distributor cap)的後面。不過,讀者要做的只是理解這些概念,能夠使用和維護自己最喜歡(以及他們最感興趣)的正則表達式包。
在大部分例子中,我仍然使用Perl表示法,雖然我偶爾會用一些其他的表示法來提醒讀者,表示法並不重要,我們討論的問題與程序和表示法不屬於一個層次。為節省篇幅,如果讀者遇到不熟悉的構建方式,請查閱第3章(☞114)。
本章詳細闡釋了匹配執行的實際流程。理想的情況是,所有的知識都能歸納為幾條容易記憶的簡單規則,使用者不需要瞭解這些規則包含的原理。很不幸,事實並非如此。整個第4章只能列出兩條普適的原則:
1.優先選擇最左端(最靠開頭)的匹配結果。
2.標準的匹配量詞(「*」、「+」、「?」和「{m,n}」)是匹配優先的。
在本章中,我們將考察這些規則,它們的結果,以及其他許多內容。首先我們詳細討論第一條規則。
規則1:優先選擇最左端的匹配結果
Rule 1:The Match That Begins Earliest Wins
根據這條規則,起始位置最靠左的匹配結果總是優先於其他可能的匹配結果。這條規則並沒有規定優先的匹配結果的長度(稍後將會討論),而只是規定,在所有可能的匹配結果中,優先選擇開始位置最左端的。實際上,因為可能有多個匹配結果的起始位置都在最左端,也許我們應該把這條規則中的「某個匹配結果(a match)」改為「該匹配結果(the match)」,不過這聽起來有些彆扭。
這條規則的由來是:匹配先從需要查找的字符串的起始位置嘗試匹配。在這裡,「嘗試匹配(attempt)」的意思是,在當前位置測試整個正則表達式(可能很複雜)能匹配的每樣文本。如果在當前位置測試了所有的可能之後不能找到匹配結果,就需要從字符串的第二個字符之前的位置開始重新嘗試。在找到匹配結果以前必須在所有的位置重複此過程。只有在嘗試過所有的起始位置(直到字符串的最後一個字符)都不能找到匹配結果的情況下,才會報告「匹配失敗」。
所以,如果要用「ORA」來匹配FLORAL,從字符串左邊開始第一輪嘗試會失敗(因為「ORA」不能匹配 FLO),第二輪嘗試也會失敗(「ORA」同樣不能匹配 LOR),從第三個字符開始的嘗試能夠成功,所以引擎會停下來,報告匹配結果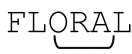 。
。
如果不瞭解這條規則,有時候就不能理解匹配的結果。例如,用「cat」來匹配:
The dragging belly indicates that your cat is too fat.
結果是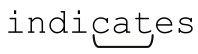 ,而不是後來出現的cat。單詞cat是能夠被匹配的,但indicates中的cat出現的更早,所以得到匹配的是它。對於egrep之類的程序來說,這種差別是無關緊要的,因為它只關心「是否」能夠匹配,而不是「在哪裡」匹配。但如果是進行其他的應用,例如查找和替換,這種差別就很重要了。
,而不是後來出現的cat。單詞cat是能夠被匹配的,但indicates中的cat出現的更早,所以得到匹配的是它。對於egrep之類的程序來說,這種差別是無關緊要的,因為它只關心「是否」能夠匹配,而不是「在哪裡」匹配。但如果是進行其他的應用,例如查找和替換,這種差別就很重要了。
這裡有一個小測驗(應該不困難):如果用「fat|cat|belly|your」來匹配字符串『The dragging belly indicates that your cat is too fat.』,結果是什麼呢?ϖ請看下一頁。
「傳動裝置(transmission)」和驅動過程(bump-along)
或許汽車變速箱(譯注1)的例子有助於理解這條規則,駕駛員在換檔時,變速箱負責連接引擎和動力系統。引擎是真正產生動力的地方(它驅動曲軸),而變速箱把動力傳送到車輪。
傳動裝置的主要功能:驅動
如果引擎不能在字符串開始的位置找到匹配的結果,傳動裝置就會推動引擎,從字符串的下一個位置開始嘗試,然後是下一個,再下一個,如此繼續。不過,如果某個正則表達式是以「字符串起始位置錨點(start-of-string anchor)」開頭的,傳動裝置就會知道,不需要更多的嘗試,因為如果能夠匹配,結果肯定是從字符串的頭部開始的。在第 6 章中,我們會講解這一點,以及更多的內部優化措施。
引擎的構造
Engine Pieces and Parts
所有的引擎都是由不同的零部件組合而成的。如果對這些零件缺乏瞭解,也就不可能真正理解引擎的工作原理。正則引擎中的這些零件分為幾類——文字字符(literal characters)、量詞(qualifiers)、字符組(character classes)、括號,等等,我們在第3章介紹過(☞114)。這些零件的組合方式(以及正則引擎對它們的處理方式)決定了引擎的特性,所以,這些零件的組合方式,以及它們之間的配合,是我們主要關注的東西。首先,讓我們來看看這些零件:
文字文本(Literal Text)例如a、*、!、枝…
對於非元字符的文字字符,嘗試匹配時需要考慮就是「這個字符與當前嘗試的字符相同嗎?」。如果一個正則表達式只包含純文本字符,例如「usa」,那麼正則引擎會將其視為:一個「u」,接著一個「s」,接著一個「a」。進行不區分大小寫的匹配時的情況要複雜一點,因為「b」能夠匹配 B,而「B」也能匹配 b,不過這仍然不難理解(Unicode的情況稍微複雜一些☞110)。
字符組、點號、Unicode屬性及其他
通常情況下,字符組、點號、Unicode屬性及其他的匹配是比較簡單的:無論字符組的長度是多少,它都只能匹配一個字符(注2)。
點號可以很方便地表示複雜的字符組,它幾乎能匹配所有字符,所以它的作用也很簡單,其他的簡便方式還包括「w」,「W」和「d」。
捕獲型括號
用於捕獲文本的括號(而不是用於分組的括號)不會影響匹配的過程。

錨點(e.g.,「^」 「z」 「(?<=d)」…)
錨點可以分為兩大類:簡單錨點(^、$、G、b、…☞129)和複雜錨點(例如順序環視和逆序環視☞133)。簡單錨點之所以得名,就在於它們只是檢查目標字符串中的特定位置的情況(^、Z…),或者是比較兩個相鄰的字符(<、b、…)。相反,複雜錨點(環視)能包含任意複雜的子表達式,所以它們也可以任意複雜。
非「電動」的括號、反向引用和忽略優先量詞
雖然本章希望講解的是引擎之間的相似之處,但為了方便讀者理解本章餘下的內容,這裡必須指出一些有意義的差異。捕獲括號(以及相應的反向引用和$1表示法)就像汽油添加劑一樣——它們只對汽油機(NFA)起作用,對電動機(DFA)不起作用。忽略優先量詞也是如此。這種情況是由DFA的工作原理決定的(注3)。這解釋了,為什麼DFA引擎不支持這些特性。讀者會看到,awk、lex和egrep都不支持反向引用和$1功能(表示法)。
也許讀者會注意到,GNU 版本的egrep 確實支持反向引用。這是因為它包含了兩台不同的引擎。它首先使用DFA查找可能的匹配結果,再用NFA(支持包括反向引用在內的所有特性)來確認這些結果。接下來,我們將看到DFA不能支持反向引用及捕獲括號的原因,以及這種引擎能夠存在的理由(DFA有很多顯著的優勢,例如匹配速度非常快)。
規則2:標準量詞是匹配優先的
Rule 2:The Standard Quantifiers Are Greedy
至今為止,我們看到的特性都非常易懂。但僅僅靠它們還很不夠——要完成複雜點的任務,就需要使用星號、加號、多選結構之類功能更強大的元字符。要徹底理解這些功能,需要學習更多的知識。
讀者首先需要記住的是,標準匹配量詞(?、*、+,以及{min,max})都是「匹配優先(greedy)」的。如果用這些量詞來約束某個表達式,例如「(expr)*」中的「(expr)」、「a?」中的「a」和「[0-9]+」中的「[0-9]」,在匹配成功之前,進行嘗試的次數是存在上限和下限的。在前面的章節中我們已經提到過這一點——而規則 2 表明,這些嘗試總是希望獲得最長的匹配(一些工具提供了其他的匹配量詞,但是本節只討論標準的匹配優先量詞)。
簡而言之,標準匹配量詞的結果「可能」並非所有可能中最長的,但它們總是嘗試匹配盡可能多的字符,直到匹配上限為止。如果最終結果並非該表達式的所有可能中最長的,原因肯定是匹配字符過多導致匹配失敗。舉個簡單的例子:用「bw+sb」來匹配包含『s』的字符串,比如說『regexes』,「w+」完全能夠匹配整個單詞,但如果用「w+」來匹配整個單詞,「s」就無法匹配了。為了完成匹配,「w+」必須匹配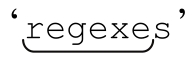 』,把最後的「sb」留出來。
』,把最後的「sb」留出來。
如果表達式的其他部分能夠成功匹配的唯一條件是,匹配優先的結構不匹配任何字符,在容許零匹配(譯注2)的情況下(例如使用星號、問號,或者{0,max},這是沒有問題的。不過,這種情況只有在表達式的後續部分強迫下才能發生。匹配優先量詞之所以得名,是因為它們總是(或者,至少是嘗試)匹配多於匹配成功下限的字符。
匹配優先的性質可以非常有用(有時候也非常討厭)。它可以用來解釋「[0-9]+」為什麼能匹配March·1998中的所有數字。1匹配之後,實際上已經滿足了成功的下限,但此正則表達式是匹配優先的,所以它不會停在此處,而會繼續下去,繼續匹配『998』,直到這個字符串的末尾(因為「[0-9]」不能匹配字符串最後的空檔,所以會停下來)。
郵件主題
顯然,這種匹配方式並非只能用於匹配數字。舉例來說,如果我們需要判斷E-mail的header中的某行字符是否標題行(subject line)。前面(☞55)我們已經說過,可以用「^Subject:」來實現。不過,如果使用 ,我們就能在之後的程序中使用捕獲型括號來訪問主題的內容(例如Perl中的$1)(譯注3)。
,我們就能在之後的程序中使用捕獲型括號來訪問主題的內容(例如Perl中的$1)(譯注3)。
在探討「.*」匹配郵件主題之前,請讀者記住,一旦「^Subject:·」能夠部分匹配,整個正則表達式就一定能夠全部匹配。因為「^Subject:·」之後沒有字符會導致表達式匹配失敗:「.*」永遠不會失敗,因為「不匹配任何字符」也是「.*」的可能結果之一。
那麼,為什麼要添加「.*」呢?這是因為我們知道,星號是匹配優先的,它會用點號匹配盡可能多的字符,所以我們用它來「填充」$1。事實上,括號並沒有影響正則表達式的匹配過程,在本例中,我們只是用它們來包括「.*」匹配的字符。
「.*」到達字符串的末尾之後點號不能繼續匹配,所以星號最終停下來,嘗試匹配表達式中的下一個元素(儘管「.*」無法繼續匹配了,但下面的子表達式或許能夠繼續匹配)。不過,因為本例中不存在後面的元素,到達表達式的末尾之後,我們就獲得了成功的匹配結果。
過度的匹配優先
現在讓我們回過頭去看「盡可能匹配」的匹配優先量詞。如果我們在上面的例子中增加一個「.*」,把正則表達式寫作 ,結果會是如何呢?答案是,沒有變化。開頭的「.*」(括號中的)會霸佔整個標題的文本,而不給第二個「.*」留下任何字符。而第二個「.*」的匹配失敗並不要緊,因為「.*」不匹配任何字符也能成功。如果我們給第二個「.*」也加上括號,$2將會是空白。
,結果會是如何呢?答案是,沒有變化。開頭的「.*」(括號中的)會霸佔整個標題的文本,而不給第二個「.*」留下任何字符。而第二個「.*」的匹配失敗並不要緊,因為「.*」不匹配任何字符也能成功。如果我們給第二個「.*」也加上括號,$2將會是空白。
這是否說明,在正則表達式中,「.*」的部分沒有機會匹配任何字符呢?答案顯然是否定的。就像我們在「w+s」這個例子中看到的,如果進行全部匹配必須這樣做,表達式中的某些部分可能「強迫」之前匹配優先的部分「釋放」(或者說「交還(unmatch)」)某些字符。
「^.*([0-9][0-9])」或許是個有用的正則表達式,它能夠匹配一行字符的最後兩位數字,如果有的話,然後將它們存儲在$1 中。下面是匹配的過程:「.*」首先匹配整行,而「[0-9] [0-9]」是必須匹配的,在嘗試匹配行末的時候會失敗,這樣它會通知「.*」:「嗨,你佔的太多了,交出一些字符來吧,這樣我沒準能匹配。」匹配優先組件首先會匹配盡可能多的字符,但為了整個表達式的匹配,它們通常需要「釋放」一些字符(抑制自己的天性)。當然,它們並不「願意」這樣做,只是不得已而為之。當然,「交還」絕不能破壞匹配成立必須的條件,比如加號的第一次匹配。
明白了這一點,我們來看「^.*([0-9][0-9])」匹配『about·24·characters·long』的過程。「.*」匹配整個字符串以後,第一個「[0-9]」的匹配要求「.*」釋放一個字符『g』(最後的字符)。但是這並不能讓「[0-9]」匹配,所以「.*」必須繼續「交還」字符,接下來交還的字符是『n』。如此循環15次,直到「.*」最終釋放『4』為止。
不幸的是,即使第一個「[0-9]」能夠匹配『4』,第二個「[0-9]」仍然不能匹配。為了匹配整個正則表達式,「.*」必須再次釋放一個字符,這次是『2』,由第一個「[0-9]」匹配。現在,『4』能夠由第二個「[0-9]」匹配,所以整個表達式匹配的是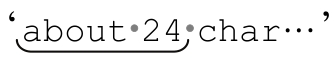 』,$1的值是『24』。
』,$1的值是『24』。
先來先服務
如果用「^.*[0-9]+」來匹配一行的最後兩個數字,期望匹配的不止是最後兩位數字,而是最後的整個數,結果會是多長呢?如果用它來匹配『Copyright 2003.』,結果是什麼?ϖ答案在下一頁。
深入細節
在這裡必須澄清一些東西。因為「「.*」必須交還…」或者「「[0-9]」迫使…」之類的說法或許容易引起混淆。我使用這些說法是因為它們易於理解,而且跟實際的結果一致。不過,事情的真相是由基本的引擎類型決定——是DFA,還是NFA。現在我們就來看這些。