
Strings,Character Encodings,and Modes
在深入講解常見的各類元字符之前,還需要瞭解一些重要的問題:作為正則表達式的字符串,字符編碼和匹配模式。
這些概念並不複雜,在理論和實踐中都是如此。不過,對其中的大多數來說,因為各種實現方式之間存在細小差異,我們很難預先知道它們準確的實際使用方式。下一節涵蓋了若干你將面對的常見問題,以及一些複雜的問題。
作為正則表達式的字符串
Strings as Regular Expressions
這個概念並不複雜:對除 Perl、awk、sed 之外的大多數語言來說,正則引擎接收的是以普通字符串形式提供的正則表達式,這些字符串文字類似「^From:(.*)」。對大多數程序員,尤其新入行的程序員來說,有一點難以理解:在構造作為正則表達式的字符串時,他們還需要留意編程語言定義的字符串元字符。
每種語言的字符串文字都規定了自己的元字符,有些語言甚至包含了多種字符串文字,所以不存在普適性的規則,不過背後的概念是一樣的。許多語言的字符串文字能夠識別轉義序列,例如\t、\\和\x2A,在生成字符串對應的數據時,會正確地解釋這些記號。與正則表達式相關的最常見的一點就是,在字符串文字中,必須使用兩個緊挨在一起的反斜線才能表示正則表達式中的反斜線。例如,為了表示正則表達式中的「\n」,必須在字符串中使用〞\\n〞。
如果忘了添加反斜線,而只是使用〞\n〞,在大多數語言中,結果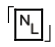 恰好等於「\n」(譯注2)。不過,事實上,如果正則表達式是寬鬆排列格式的/x 類型,
恰好等於「\n」(譯注2)。不過,事實上,如果正則表達式是寬鬆排列格式的/x 類型, 被解釋為空,「\n」仍然留在正則表達式中,匹配一個空行。忘記這一點的程序員真該打。下面的表3-4列出了一些包括\t和\x2A(2A是『*』符號的ASCII編碼)的例子。表格中的第二對例子展示了忽略字符串文字元字符會導致的意外結果。
被解釋為空,「\n」仍然留在正則表達式中,匹配一個空行。忘記這一點的程序員真該打。下面的表3-4列出了一些包括\t和\x2A(2A是『*』符號的ASCII編碼)的例子。表格中的第二對例子展示了忽略字符串文字元字符會導致的意外結果。
表3-4:關於字符串文字的若干例子

語言不同,字符串文字也不相同,不過有的差異大到連『\』都不算元字符。例如,VB.NET的字符串文字只有一個元字符,就是雙引號。下一節介紹了幾種常用語言的字符串文字。無論規定如何,我們在使用時都不要忘記考慮「在編程語言的字符串處理結束之後,正則引擎接收到的是什麼?」
Java的字符串
Java 的字符串跟上面提到的很類似,它們由雙引號標注,反斜線是元字符。支持常見的字符組合,例如『\t』(製表符)、『\n』(換行符)、『\\』(反斜線本身)。字符串中出現未獲支持的反斜線轉義序列會出錯。
VB.NET的字符串
VB.NET中的字符串同樣是由雙引號標注的,不過它們與Java的字符串有很大差別。VB.NET的字符串只能識別一個元字符:兩個連續的雙引號,代表字符串中的雙引號。例如〞he said〞〞hi〞〞\.〞的值就是「he said 〞hi〞\.」。
C#的字符串
儘管微軟的.NET Framework中所有語言在內部共享同一台正則引擎,但創建正則表達式時它們有各自的規定。我們剛剛看到,Visual Basic的字符串文字非常簡單。與之不同,C#語言有兩種類型的字符串文字。
C#支持與導論中類似的常見的雙引號字符串,只是用 〞〞 而不是\〞 來表示雙引號。不過,C#也支持「原生字符串(verbatim strings)」(譯注3),其形式為@〞…〞。原生字符串不能識別反斜線序列,不過其中也有一個特殊的轉義序列:一對雙引號表示目標字符串中的一個雙引號。也就是說,你可以使用〞\\t\\x2A〞或者@〞\t\x2A〞來生成「\t\x2A」。因為這種方式很簡單,一般都用@〞…〞的原生字符串來表示正則表達式。
PHP的字符串
PHP也提供了兩種類型的字符串,不過無一與C#中的相同。在PHP的雙引號字符串中可以使用常見的反斜線序列——例如『\n』,但也可以像 Perl 那樣進行變量插值(☞77),還可以使用特殊的序列{…},把執行花括號內代碼的執行結果插入字符串。
PHP 的雙引號字符串的獨特性在於,你可能傾向於在正則表達式中加入多餘的反斜線,不過PHP的另一種特性能夠緩解這種現象。對Java和C#的字符串文字來說,字符串中如果出現不能明確識別為特殊字符的反斜線序列會導致錯誤,而在PHP的雙引號字符串中,這種序列會原封不動地從字符串中傳過來。PHP的字符串能夠識別\t,所以你需要用「\\t」來表示「\t」,不過如果使用「\w」,我們仍然得到「\w」,因為\w不屬於PHP的字符串能夠識別的轉義序列。這個額外的特性,雖然有時候很順手,也增加了PHP雙引號字符串的複雜程度,所以PHP提供了更加簡單的單引號字符串。
PHP的單引號字符串類似VB.NET字符串和C#的@〞…〞字符串,都屬於「格式整齊的(unclut-tered)」字符串,不過稍有不同。在PHP的單引號字符串中,\'表示單引號,\\表示反斜線。任何其他字符(包括任何反斜線)都不會被識別為特殊字符,而會被當作字符的值。也就是說,'\t\x2A'創建「\t\x2A」。因為單引號字符串很簡單,用它來表示PHP的正則表達式非常方便。
PHP的單引號字符串在第10章有詳細講解(☞445)。
Python的字符串
Python提供了好幾種字符串文字。單引號和雙引號都可以用來創建字符串,不過與PHP不同的是,這兩種方法沒有區別。Python也提供了「三重引用(triple-quoted)」的字符串,也就是'''…'''或者〞〞〞…〞〞〞,它們可以包含未轉義的換行符。這4 種類型都支持常用的反斜線序列,例如\n,不過和PHP一樣,它們也會把不能識別的反斜線序列作為純字符序列來對待。而在Java和C#中,這些序列會被出錯。
與PHP和C#一樣,Python也提供了另一種字符串文字,也就是「原字符串(raw string)」。它類似 C#中的@〞…〞,Python 在以上 4 種表示法前添加'r'來表示純字符串。例如,r〞\t\x2A〞表示「\t\x2A」。與其他語言不同的是,在 Python 的原字符串中,所有的反斜線都會保留,即使是用來轉義雙引號的(所以雙引號可以保存在字符串中)也是如此:r〞he said\〞hi\〞\.〞表示「he said\〞hi\〞\.」在使用正則表達式時,這並不是一個真正的問題,因為Python的正則表達式流派把「\〞」識別為「〞」,不過如果你喜歡,你可以忽略這些細節,使用這4種純字符串中的任意一種:r'he said 〞hi〞\.'。
Tcl中的字符串
Tcl與其他語言都不一樣,因為它沒有真正的字符串變量。相反,命令行被分解成「單詞」,Tcl的命令把這些單詞作為字符串、變量名和正則表達式,或者其他適合的類型。因為命令行被分解成單詞,常見的反斜線序列,例如\n,能夠識別和轉換,而無法識別的反斜線序列則被忽略。如果願意,你可以在單詞兩端添加雙引號,不過這並不是必須的,除非中間存在空格。
Tcl同樣也有和類似Python的純字符串類似的原字符串類型,不過Tcl使用花括號{…},而不是r'…'。在花括號之間,除\n之外的所有內容都會原封不動地保存下來,所以{\t\x2A}表示「\t\x2A」。
在花括號之內,你可以按自己的意願添加多組括號。非嵌套的括號必須用反斜線轉義,不過反斜線會保留在字符串之中。
Perl的正則表達式文字
至今為止,我們曾看到過的Perl的例子中,正則表達式都是以文字方式提供的(「正則表達式文字(regular expression literals)」)。不過,我們也可以用字符串變量提交正則表達式,例如:
$str=~m/(\w+)/;
也可以這樣:
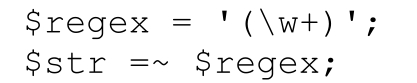
或者是這樣
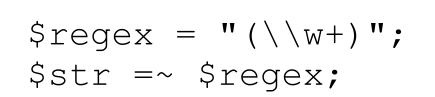
(不過,使用字符串可能會大大降低效率,☞242,348)。
對於以文字方式提交的正則表達式,Perl會提供一些額外的特性,包括:
●變量插值(把變量的值寫入正則表達式)。
●通過「\Q…\E」(☞113)支持文字文本。
●能夠(optional)支持\N{name}結構,這樣就能通過正式的Unicode名來指定字符。例
如,「\N{INVERTED EXCLAMATION MARK}Hola!」能夠匹配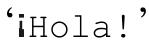 。
。
在Perl中,正則表達式文字會作為特殊的字符串進行解析。實際上,這些特性在Perl雙引號字符串中也有提供。必須說明的一點是,這些特性不是由正則引擎提供的。因為 Perl 中使用的絕大多數正則表達式都是作為正則表達式文本的,許多人認為「\Q…\E」屬於 Perl 的正則表達式語言,不過如果你用正則表達式從一個配置文件(或者命令行)讀入數據,知道哪些特性是由語言的哪些部分提供的就很重要了。
更多細節,請參考第7章第288頁。
字符編碼
Character-Encoding Issues
字符編碼是一種寫明的共識,它規定不同數值的字節應該如何解釋。在 ASCII 編碼中,值為十進制110的字節代表字符『n』,不過在EBCDIC編碼中代表『>』。為什麼會這樣?因為這是由不同的人規定的,沒有明確的標準判斷各種編碼的優劣。字節的值是一樣的,不一樣的是解釋。
ASCII只定義了單個字節能夠代表的所有數值的一半,ISO-8859-1編碼(通常稱為「Latin-1編碼」)填補了下面的空間,其中增加了讀音字符(accented character)和特殊符號,因而能夠被更多的語言所使用。對這種編碼來說,值為十進制數 234 的字節被解釋為e^,而在ASCII中沒有定義。
對我們來說,重要的問題在於:如果我們期望使用某種特定編碼的數據,程序是否會這樣做?例如,如果我們使用Latin-1編碼中值分別為234、116、101和115的4個字節(表示法語單詞「etes」),我們期望使用正則表達式「^\w+$」或者「^\b」來匹配。如果程序中的\w或者\b能夠支持Latin-1字符,就可以正常工作,否則不行。
編碼的支持程度
編碼有許多種,當你需要關注一種具體的編碼時,你需要考慮的重要問題包括:
●程序能夠識別這種編碼嗎?
●程序如何決定採用哪種編碼來處理這些數據?
●正則表達式對這種編碼的支持程度如何?
編碼的支持程度包括若干重要的問題:
● 是否能夠支持多字節字符?點號和[^x]之類的表達式是匹配單個字符,還是單個字節?
●\w、\d、\s、\b之類的元字符,是否能識別編碼中的所有字符?例如,雖然e也是一個字符,\w和\b能處理嗎?
●程序是否會擴展對字符組的解釋?[a-z]能否匹配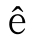 ?
?
●不區分大小寫的匹配是否能對所有字符有效?例如,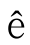 和
和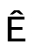 是否一樣?
是否一樣?
有時候事情不像看起來那麼簡單。例如,java.util.regex包的\b能夠正確識別Unicode中所有與單詞相關的字符,\w則不能(它只能匹配ASCII中的字符)。我們會在本章的其他部分看到更多的例子。
Unicode
Unicode
Unicode究竟是什麼,似乎存在許多誤解。從最基本的意義上說,Unicode是一組字符設定,或者是從數字和字符之間的邏輯映射的概念編碼。例如,韓語字符 對應數字 49,333。這個數值,稱為一個「代碼點(code point)」,通常用十六進制來表示,以「U+」開頭。49,333換算成十六進制是C0B5,所以
對應數字 49,333。這個數值,稱為一個「代碼點(code point)」,通常用十六進制來表示,以「U+」開頭。49,333換算成十六進制是C0B5,所以 的代碼就是U+C0B5。針對許多字符,Unicode還定義了一組屬性,例如3是一個數字,而
的代碼就是U+C0B5。針對許多字符,Unicode還定義了一組屬性,例如3是一個數字,而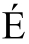 是與
是與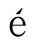 對應的大寫字母。
對應的大寫字母。
目前,我們還沒有談到這些數值在計算機上是如何編碼為數據的。這樣的編碼方式有許多,包括UCS-2編碼(所有的字符都佔用兩個字節),UCS-4編碼(所有字符佔用4個字節),UTF-16(大部分字符都佔用兩個字節,有一些字符佔用4個字節),以及UTF-8編碼(用1到6個字節來編碼字符)。具體的程序內部到底使用哪種編碼通常不需要用戶來關心。用戶只需要關心如何將外部數據(例如從文件讀入的數據)從已知的編碼(ASCII、Latin-1、UTF-8等)轉換給具體的程序。支持Unicode的程序通常提供了多種編碼和解碼程序來進行這些轉換。
支持Unicode的程序中的正則表達式通常支持\unum元序列,用來匹配一個具體的Unicode字符(☞117)。這個數值通常是一個4位的十六進制數,所以\uC0B5表示 。一定要弄清楚的是,\uC0B5的意思是「匹配編號為U+C0B5的Unicode字符」,而沒有說具體需要比較哪些字節,因為具體的字節是由代表這個Unicode代碼點的編碼方式在內部決定的。如果程序內部使用的是UTF-8編碼,這個字符就用3個字節表示。不過使用支持Unicode程序的用戶,並不需要關心這個(也有時候需要,例如使用PHP的preg套件和模式修飾符u☞447)。
。一定要弄清楚的是,\uC0B5的意思是「匹配編號為U+C0B5的Unicode字符」,而沒有說具體需要比較哪些字節,因為具體的字節是由代表這個Unicode代碼點的編碼方式在內部決定的。如果程序內部使用的是UTF-8編碼,這個字符就用3個字節表示。不過使用支持Unicode程序的用戶,並不需要關心這個(也有時候需要,例如使用PHP的preg套件和模式修飾符u☞447)。
還有一些你或許需要知道的相關知識……
字符,還是組合字符序列
一般人眼裡的「字符」(character)並不都會被 Unicode 或者支持 Unicode 的程序(或者正則引擎)看作一個字符。例如,有人或許認為 a是一個字符,但是在 Unicode 中,它可能由兩個代碼點構成,U+0061(a)和鈍重音(grave accent)U+0300 (')。Unicode提供了許多組合字符(combining character),用來修飾(結合)一個基本字符。這會給正則引擎帶來些麻煩,例如,點號是應該匹配單個代碼點呢,還是整個U+0061和U+0300?
在實踐中,許多程序似乎把「字符」和「代碼點」視為等價,也就是說,點號可以匹配單個的代碼點,無論是基本字符還是組合字符。所以,a(U+0061加上U+0300)能夠由「^..$」匹配,而不是「^.$」。
Perl和PCRE(以及PHP的preg套件)支持\X元序列,這樣點號(「匹配單個字符」)就能夠匹配一個結合了組合字符的基本字符。詳見第120頁。
在支持Unicode的編輯器中輸入正則表達式時,一定要記住組合字符的概念。如果一個帶音調的字符,例如 A,被正則表達式當作『A』和『。』,很可能無法匹配字符串中單個代碼點表示的 A(下一節討論單代碼點的情況)。同樣,對正則引擎來說它是兩個不同的字符,所以「[…A…]」在字符組中添加了兩個字符,等於「[…A。…]」 。
同樣,如果兩個代碼點的字符——例如A——後面跟有一個量詞,量詞作用的其實是第二個代碼點,也就是「A°+」。
用多個代碼點表示同一個字符
從理論上說,Unicode應該是代碼點和字符之間的一一映射(譯注4),不過在許多情況下,一個字符可能有多種表現方式。前一節中我們看到a可以表示為U+0061加上U+0300。不過,它也可以用單個代碼點U+00E0。為什麼會出現這種情況?是為了保證Unicode和Latin-1之間轉換的簡易性。如果我們有需要轉換為Unicode的Latin-1文本,a可能被轉換為U+00E0。不過,也可以轉換為U+0061和U+0300的組合。通常,這種轉換是自動的,用戶無法干預,不過Sun的java.util.regex包提供了一種特殊的匹配符,CANON_EQ,保證能夠匹配「在規則中等價(canonically equivalent)」的字符,無論它們在 Unicode 中使用什麼存儲方式(☞368)。
與此相關的問題是,不同的字符可能無法從外觀上區分,如果需要檢查生成的文本,這會帶來混亂。例如,羅馬字母Ⅰ(U+0049)可能與I,也就是希臘字母Iota(U+0399)混淆。這個字符添加希臘語冒號之後得到I或者I,編碼也增加到4種(U+00CF;U+03AA;U+0049 U+0308;U+0399 U+0308)。也就是說,如果需要匹配I,你可能需要手動指定這4種可能。類似的例子還有許多。
還有許多單個字符看起來不只一個字符。例如 Unicode 定義了一個叫做「SQUARE HZ」(U+3390)的字符。這很像兩個普通字符Hz的組合(U+0048 U+007A)。
儘管Hz之類的特殊字符的用途在目前非常有限,但在將來,它們的應用肯定會增加文本處理程序的複雜性,所以在處理Unicode時不應忘記這些問題。用戶可能會期望,處理這樣的數據時,必須能夠處理正常空格(U+0020)和非換行空格(no-break spaces)(U+00A0),或許還需要包括Unicode中其他的成打的空白字符之中的任意一個。
Unicode 3.1+和U+FFFF之後的代碼點
Unicode Version 3.1誕生於2001年中期,增加了U+FFFF之後的代碼點(之前版本的Unicode也支持這些代碼點,但是在Version 3.1以前,它們都是沒有定義的)。例如,代表音樂譜號C(Clef)的字符對應代碼點 U+1D121。之前那些僅支持低於 U+FFFF字符的程序無法處理這種情況。大多數程序的\unum只能支持最多4位十六進制數值。
能夠處理這類新字符的程序通常提供了\x{num}序列,num可以為任意多位數字(這是為了增強只支持4位數字的\unum表示法)。你可以使用\x{1D121}來匹配這類「譜號C」之類的字符。
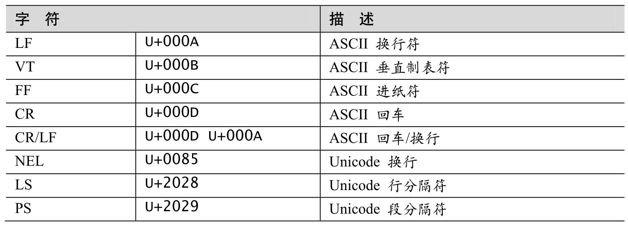
Unicode中的行終止符
Unicode定義了多個用於表示行終止符的字符(以及一個雙字符序列),詳見表3-5。
表3-5:Unicode行終止符
如果行終止符獲得了完全的支持,它會影響文本行從文件(在腳本語言中,還包括程序讀取的文件)讀入的方式。在使用正則表達式時,它們影響點號(☞111),以及「^」、「$」和「\Z」的匹配(☞112)。
正則模式和匹配模式
Regex Modes and Match Modes
許多正則引擎都支持多種不同的模式,它們規定了正則表達式應該如何解釋和應用。我們已經看過Perl的/x修飾符(容許自由空格和註釋的正則模式☞72)和/i修飾符(進行不區分大小寫匹配的模式☞47)。
在許多流派中,模式可以完全作用於整個表達式,也可以單獨應用於某個子表達式。整體應用是通過修飾符或者選項(options)來決定的,例如 Perl 的/i,PHP 的模式修飾符 i (☞446),和java.util.regex的Pattern.CASE_INSENSITIVE標誌(☞99)。如果支持,應用到目標字符串中部分文本的模式是通過一個正則結構來實現的,例如用「(?i)」來開啟不區分大小寫的匹配,「(?-i)」來停用該匹配。有的流派也支持「(?i:…)」和「(?-i:…)」來啟用或者停用對括號內的子表達式進行不區分大小寫匹配的功能。
本章後面部分會介紹(☞135)如何在正則表達式中設置這些模式。在本節,我們只看看大多數系統提供的常見模式。
不區分大小寫的匹配模式
此模式很常見,它在匹配過程中會忽略字母的大小寫,所以「b」可以匹配『b』和『B』。此功能也必須依賴於正確的字符編碼支持,所以之前我們提到的注意事項對它都適用。
在歷史上,不區分大小寫的匹配支持一直不太令人滿意,被 bug 困擾,好在如今大部分已經修正了。不過,Ruby不區分大小寫的匹配仍然不能處理八進制和十六進制的轉義字符。不區分大小寫的匹配存在特殊的與Unicode相關的問題(在Unicode中稱為「粗略匹配(loose matching)」)。簡單地說,就是並非所有的ASCII字母和數字字符都存在大小寫形式,而某些字符在作為單詞首字母時會有單獨的標題格式(title case)。有時候在大寫和小寫之間並沒有明顯的一對一映射。常見的例子是希臘字母西格馬Σ,它有兩個小寫形式ζ和σ,在不區分大小寫的模式中,這三者應該是等價的。根據我的測試,只有Perl和Java的java.util.regex能夠正確處理它們。
另一個問題是,有時候單個字符會對應到一組字符。常見的例子是大寫的 s 是兩個字符的組合「SS」。這種情況只有Perl能夠正確處理。
Unicode還帶來了一些問題。例如單字符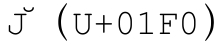 沒有對應的大寫形式的單字符。相反,
沒有對應的大寫形式的單字符。相反,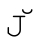 需要使用組合字符(☞107),U+004A和U+030C。而
需要使用組合字符(☞107),U+004A和U+030C。而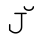 和
和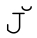 應該在不區分大小寫的模式中是等價的。類似的還有一對三的例子。幸好,這些都不是常用字符。
應該在不區分大小寫的模式中是等價的。類似的還有一對三的例子。幸好,這些都不是常用字符。
寬鬆排列和註釋模式
此模式會忽略字符組外部的所有空白字符。字符組內部的空白字符仍然有效(java.util.regex是例外),#符號和換行符之間的內容視為註釋。我們已經見過Perl(☞72)、Java(☞98)和VB.NET(☞99)中相應的例子。
不過,在java.util.regex中,字符組之外的所有空白字符並非都會被忽略,而是作為一個「無意義元字符(do-noting metacharacter)」。在理解「\12·3」時,這種區分很重要,因為它表示「3」接在「\12」之後,而不是有些人以為的「\123」。
當然,「空白字符」的定義取決於所採用的字符編碼的定義,以及此編碼對空白字符的支持程度。大多數程序只能識別ASCII的空白字符。
點號通配模式(dot-match-all match mode,也叫「單行模式」)
通常,點號是不能匹配換行符的。最初的Unix正則表達式工具是逐行處理的,直到sed和lex出現之後,才提出匹配換行符的要求。那時候,人們常用「.*」來匹配「本行中的其他內容(the rest of the line)」,為了保證一致,新的語法不能修改「.*」的定義(注9)。所以,能夠處理多行文本的工具(例如文本編輯器)通常不容許點號匹配換行符。
對現代編程語言來說,點號能夠匹配換行符的模式和不能匹配的模式同樣有用。這兩種模式哪個更方便,取決於具體的情況。許多程序提供了兩種方法供正則表達式選擇。
這種常規標準也有少數例外的情況。支持 Unicode 的系統,例如在 Sun 的正則表達式包,點號能夠匹配未使用此模式時點號不能匹配的所有單字符Unicode行終止符(☞109)。在Tcl的普通模式中,點號能夠匹配任何字符,但是在其特殊的「區分換行(newline-sensitive)」和「部分區分換行(partial newline-sensitive)」的匹配模式下,點號和排除型字符組都不能匹配換行符。
不幸的命名
/s修飾符對應的匹配模式第一次出現在Perl時,被稱為「單行文本模式(single-line mode)」。這個不幸的命名一直是混亂的起源,因為與下一節討論的「多行文本模式(multiline mode)」比較起來,它似乎與「^」和「$」沒有關係。其實「單行文本模式」指的是,點號不受限制,可以匹配任何字符。
增強的行錨點模式(Enhanced line-anchor match mode,也叫「多行文本模式」)
增強的行錨點模式會影響到行錨點「^」和「$」的匹配。通常情況下,錨點「^」不能匹配字符串內部的換行符,而只能匹配目標字符串的起始位置。但是在此增強模式下,它能夠匹配字符串中內嵌的文本行的開頭位置。前一章出現了這樣的例子(☞69),當時我們用Perl開發把文本內容轉換為超文本內容程序。其中,所有的文本保存在一個字符串中,所以我們可以通過查找-替換功能用 s/^$/<p>/mg 來把「…tags. It』s…」轉換為「…tags.
It』s…」轉換為「…tags. <p>
<p> It』s…」。該替換把空「行」替換為段落tag。
It』s…」。該替換把空「行」替換為段落tag。
「$」也是這樣,儘管「$」在正常情況下的匹配的基本規則比較難理解(☞129)。不過,就本節來說,我們只需要記住,「$」可以匹配字符串內部的換行符,就足夠了。
支持此模式的程序通常還提供了「\A」和「\Z」,它們的作用與普通的「^」和「$」一樣,只是在此模式下它們的意義不會發生變化。也就是說「\A」和「\Z」永遠不會匹配字符串內部的換行符。有些實現方式中,「$」和「\Z」能夠匹配字符串內部的換行符,不過它們通常會提供「\z」,唯一匹配整個字符串的結尾位置。詳見129頁。
對點號來說,常用標準有一些例外。在GNU Emacs之類的文本編輯器中,行錨點通常能夠匹配字符串中的換行符,因為在編輯器中這樣非常有意義。另一方面,lex的「$」只能匹配換行符之前的位置(其中「^」的意義與常見的一樣)。
此模式下,在Sun的java.util.regex之類支持Unicode的系統中,行錨點能夠匹配任何一種行終止符(☞109)。Ruby 的行錨點在正常情況下能夠匹配字符串中的換行符,Python的「\Z」類似「\z」,而不是普通的「$」。
長期以來,這種模式被稱為「多行模式(multiline mode)」。儘管它與「單行模式」沒有什麼關係,但看名字總容易覺得二者有關聯。後者修改的是點號的匹配規則,前者修改的是「^」和「$」的匹配規則。另一方面,它們從不同的思路處理換行符。第一個修改了點號處理換行符的方式,從「需要特殊處理」變為「不需要特殊處理」;第二個的做法則相反,改變了「^」和「$」匹配換行符的方式,從「不需要特殊處理」變為「需要特殊處理」(注10)。
文字文本模式
「文字文本(literal text)」模式幾乎不能識別任何正則表達式元字符。例如,文字文本模式下「[a-z]*」匹配字符串「[a-z]*」。完整的文字搜索(literal search)等於簡單的字符串搜索(「搜索這個字符串」,而不是「搜索這個正則表達式」),支持正則表達式的程序通常也提供了普通的字符串搜索功能。正則表達式的文字文本模式之所以更有趣,是因為它可以只作用於正則表達式的一部分,舉例來說,PCRE(因此也包括PHP)的正則表達式和Perl的正則表達式文本提供了特殊的序列\Q…\E,其中內容的元字符全部被忽略(當然,不包括\E)。