
A Casual Stroll Across the Regex Landscape
我喜歡在故事的開頭講講某些正則表達式的流派以及相應程序的演變過程。所以,請準備一杯你最喜歡的熱(或涼的)飲料,放輕鬆,我們一起來看看今天的正則表達式背後古怪的發展史。這樣做是為了讓你全面瞭解正則表達式,培養追問「為什麼會如此」的習慣。我們為有興趣的讀者準備了一些腳注,不過大部分腳注只能算是博得讀者一笑的花絮。
正則表達式的起源
The Origins of Regular Expressions
關於正則表達式,最初的想法來自20世紀40年代的兩位神經學家,Warren McCulloch和Walter Pitts,他們研究出一種模型,認為神經系統在神經元層面上就是這樣工作的(注1)。若干年後,數學家Stephen Kleene在代數學中正式描述了這種被他稱為「正則集合」(regular sets)的模型,正則表達式才成為現實。Stephen 發明了一套簡潔的表示正則集合的方法,他稱之為「正則表達式」(regular expressions)。
20世紀50年代和60年代,理論數學界對正則表達式進行了充分的研究。Robert Constable的文章為那些對數學感興趣的讀者提供了很不錯的簡介(注2)。
儘管存在更古老的應用正則表達式的證據,但我能找到的是,關於在計算方面使用正則表達式的資料,最早發表的是 1968 年 Ken Thompson 的文章 Regular Expression Search Algorithm(注 3),在文中,他描述了一種正則表達式編譯器,該編譯器生成了 IBM 7094的object代碼。由此也誕生了他的qed,這種編輯器後來成了Unix中ed編輯器的基礎。
ed的正則表達式並不如qed的先進,但是這是正則表達式第一次在非技術領域大規模使用。ed 有條命令,顯示正在編輯的文件中能夠匹配特定正則表達式的行。該命令「g/Regular Expression/p」,讀作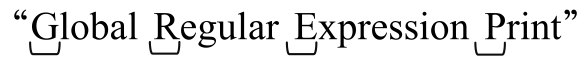 (應用正則表達式的全局輸出)。這個功能非常實用,最終成為獨立的工具grep(之後又產生了egrep——擴展的grep)。
(應用正則表達式的全局輸出)。這個功能非常實用,最終成為獨立的工具grep(之後又產生了egrep——擴展的grep)。
Grep中的元字符
相比egrep,grep和其他早期工具所支持的元字符相當有限。元字符*是受支持的,但是+和?則不受支持(不支持問號是很嚴重的缺陷)。Grep中用於捕獲元字符的是(…),而未轉義的括號會當作普通字符(注4)。grep支持行錨點(line anchors),但方式十分有限。如果^出現在正則表達式的開頭,它就是匹配行開頭的元字符。否則它就不是一個元字符,而只是一個普通的脫字符。同樣,$只有出現在正則表達式的末尾時才被當作元字符。結果,用戶沒法使用「end$|^start」這樣的表達式。不過這不要緊,因為grep不支持多選結構。
元字符的作用規則也很重要。例如,grep 的最大問題或許在於,星號無法用來限定括號內的子表達式,而只能用於限定普通的字符、字符組,或者點號。所以,在grep中,括號的作用僅限於捕獲已匹配的文本,而不能用來進行普通的分組。實際上,某些早期版本的grep甚至不支持括號嵌套。
Grep的發展歷程
儘管今天的許多系統都有對應的grep,但你會注意到,本書中提到grep時使用的都是過去時態(譯注1)。過去時對應舊版本所屬的流派,它們的歷史都超過30年了。在這段時間中,技術在不斷進步,舊的程序也會加入新的特性,grep也不例外。
在最老版本的grep之上,AT&T的貝爾實驗室加入了一些新的特性,例如從lex程序中借鑒來的{min,max}。他們還修正了-y選項,早期版本的grep通過-y進行不區分大小寫的匹配,但此功能並不正常。同時,Berkeley 的人加入了表示單詞開頭和結束的元字符,把-y改為-i。不幸的是,星號或其他量詞仍然無法作用於括號內的表達式。
Egrep的發展歷程
此時,Alfred Aho(同樣是AT&T的貝爾實驗室)寫出了egrep,它提供了第1章介紹的各種元字符中的大部分元字符。更重要的是,它以一種全然不同(但總的來說更好)的方式實現了這些功能。不但加上了「+」和「?」,還容許量詞作用於括號內的表達式,這大大增強了egrep的表達能力。
同時,多選結構加入了,行錨點也升級到「基礎級別」,可以在正則表達式的任何地方使用。不過,egrep也不夠完美——有時候它能匹配,但不會顯示結果,而且它缺乏某些當今流行的特性。不過無論如何,它都比grep有用得多。
其他工具的發展歷程
就在egrep演變的同時,其他程序,例如awk、lex和sed,也在按各自的腳步前進。通常,開發人員會把某個程序中自己喜歡的特性添加到其他程序中。有時候,結果並不盡如人意。例如,如果要在 grep 中增加對「+」的支持,就不能直接使用『+』,因為長期來以來在 grep中『+』都不是元字符,突然進行這種修改會讓大家感到不適應。因為『+』可能是 grep的用戶在正常情況下不會輸入的,把它作為「重現一次或多次」的元字符可能更合適。
有時候,添加新特性也會帶來新的bug。另外一些時候,新添加的特性不久後又被刪除了。構成流派的各個細微的方面,幾乎都沒有什麼文檔,所以新的工具軟件要麼形成了自己的流派,要麼嘗試模仿其他工具,提供「看來相似」的功能。
這一切,加上漫長的發展史,眾多的程序員,結果就是巨大的謎局(注5)。
POSIX——標準化的嘗試
誕生於1986年的POSIX是Portable Operating System Interface(可移植操作系統接口)的縮寫,它是一系列標準,確保操作系統之間的移植性。該標準的某些部分關乎正則表達式和使用他們的傳統工具,所以值得我們關注。不過,本書涉及的各種流派無一嚴格地遵守了所有的相關規定。為了釐清正則表達式的混亂局面,POSIX把各種常見的流派分為兩大類:Basic Regular Expressions(BREs)和Extended Regular Expressions(EREs)。POSIX程序必須支持其中的任意一種。下頁的表3-1簡要介紹了這兩種流派的元字符。
POSIX標準的主要特性之一是locale,它是一組關於語言和文化傳統——例如日期和時間的格式、貨幣幣值、字符編碼對應的意義等——的設定。locals的目的在於讓程序變得國際化。它們不是正則表達式相關的概念,儘管它們會影響正則表達式的使用。舉例來說,工作於Latin-1編碼(也稱為「ISO-8859-1」)之中時,a 和A(分別對應十進制編碼224和160)也被認為是「字符」,任何不區分大小寫的正則表達式都會認為這兩個字符是相等的。
表3-1:POSIX正則表達式流派概覽

另一個例子是w,通常用於表示「構成單詞的字符」(在很多流派中,它等價於[a-zA-Z0-9_])。這個特性並不是POSIX中必須的,但容許出現。如果支持的話,w就能對應locale中的所有字母和數字,而不僅僅限於ASCII編碼的字符和數字。
如果程序支持Unicode,那麼關於locale的問題就極大地簡化了。Unicode的詳細討論從106頁開始。
Henry Spencer的正則表達式包
同樣是在1986年,發生了於一件更重要的事情,Henry Spencer發佈了用C語言寫的正則表達式包,這個包可以毫無困難地置入其他程序中——這在當時具有開創性的意義。每一個使用 Henry 的包的程序——的確存在很多——都屬於相同的流派,除非程序的作者費盡周折去修改。
Perl的發展歷程
差不多在同時,Larry Wall開始開發一種工具,也就是日後的Perl語言。他的patch程序已經大大促進了分佈式軟件開發(distributed software development),但是Perl注定要產生重大的影響。
1987年12月,Larry發佈了Perl Version 1。Perl很快引起了關注,因為它糅合了其他語言的眾多特性,但指向一個明確的目的:就是我們日常所說的「實用(useful)」。
Perl的特性中值得一提的是,它提供了傳統上只有專用工具sed和awk才提供的正則表達式操作符——這在通用腳本語言中是個首創。正則引擎的代碼來自一個早期的項目——Larry的新聞閱讀器rn(其中的正則表達式代碼來自James Gosling的Emacs(注6))。Perl的正則流派,用當時的標準衡量是很強大的,但功能不如今天那樣齊全。它主要的問題在於,最多只能支持 9 組括號,9 個多選結構,最糟糕的是,括號內不容許出現「|」,也不能進行不區分大小寫的匹配,不支持字符組中的w(完全不支持d和s)。也不支持區間量詞{min,max}。
Perl 2發佈於1988年6月。Larry完全放棄了原有的正則表達式代碼,而採用了前面提到過的Henry Spencer的正則表達式包的增強版。括號的數目仍然只有9個,但是括號中可以使用「|」了。d和s的支持也加了進來,w現在可以匹配下畫線了,從這時開始,w能夠匹配 Perl 的變量名中容許出現的字符。此外,字符組之內也可以出現元字符(表示否定的元字符、D、W和S,也可以支持,但不能使用在字符組內部,而且總在有些情況下無法正常工作)。很重要的一點是,添加了/i量詞,能夠進行不區分大小寫的匹配。
Perl 3發佈於一年多以後的1989年10月。它添加了/e量詞,這樣極大地增強了替換運算符的能力,同時修正了之前版本中的一些與回溯相關的bug。也添加了{min,max}區間量詞。雖然很不幸,這些量詞不能保證在任何情況下都可以正常工作。還有,這時候 Perl 的正則引擎本不應該停留在只處理8位編碼數據的水平,但是面對非ASCII輸入時,會產生無法預料的結果。
Perl 4的發佈是在一年半以後,1991年3月,在接下來的兩年間,Perl 4一直在改進,直到1993年2月發佈最終升級。到此時,之前的bug已經修正,原有的限制也被突破(D之類可以應用在字符組中,而括號的數目也不再有限制),正則引擎也花了很多功夫來優化,不過真正的突破是在1994年。
Perl 5正式發佈於1994年10月。這一版的Perl經歷了全面的修整,在各個方面都比原來強上許多。就正則表達式來說,它進行了更多的內部優化,添加了少量元字符(G增強了迭代匹配的能力☞130)、非捕獲的括號(☞45)、忽略優先(lazy)的量詞(☞141)、順序環視功能(☞60),以及/x量詞(☞72)(注7)。
這些新增功能的意義並不限於功能本身,更重要的是,這些「新增」的修改使正則表達式本身成為一種強大的編程語言,並為它提供了進一步的發展空間。
新增的非捕獲型括號和順序環視結構都需要新的表達方式。而(…)、[…]、<…>和{…}都已經有了含義,所以Larry採用了我們今天使用的『(?』表示法。這個表示法並不好看,不過在之前的Perl正則表達式中這是不合規則的組合,所以添加起來完全沒有障礙。Larry也預見到,將來可能還需要新增其他的功能,所以他對『(?』之後的字符做了限制,這樣就能保留某些字符,用於將來更多的功能。
之後的各版 Perl 越來越健壯,錯誤越來越少,內部優化越來越棒,添加了越來越多的新特性。我相信,本書的第一版也為此做了小小的貢獻,因為鄙人研究和測試了正則表達式相關的特性,並將結果告知Larry和Perl Porters group,為改進提供了反饋。
後來添加的新特性包括逆序環視功能(☞60),「固化」分組(「atomic」 grouping☞139),和Unicode支持。新添加的條件判斷結構更是把正則表達式提升到了一個新的層次(☞140),它容許用戶在正則表達式中進行if-then-else的條件判斷和控制。如果這些還不夠強大的話,新的結構甚至容許程序員在正則表達式中運行 Perl 代碼,正則表達式和程序代碼之間的界限已經不復存在了 (☞327)。本書中使用的Perl的版本為5.8.8。
流派的部分整合
具有先見之明的Perl 5完全契合了互聯網革命的節拍。Perl的初衷是文本處理,而Web頁的生成其實正是文本處理,所以Perl迅速成為了開發Web程序的語言。Perl廣受歡迎,其中強大的正則流派也是如此。
其他語言的開發人員當然不會視而不見,最終在某種程度上「兼容Perl」(Perl compatible)的正則表達式包出現了。Tcl、Python、.NET、Ruby、PHP、C/C++都有各自的正則表達式包,Java語言中還有多個正則表達式包。
另一種形式的整合始於1997年(湊巧的是,本書的第一版也在當年面世),當時Philip Hazel開發了PCRE,這是一套兼容Perl正則表達式的庫,PCRE的正則引擎質量很高,全面仿製Perl 的正則表達式的語法和語義。其他的開發人員可以把 PCRE 整合到自己的工具和語言中,為用戶提供豐富而且極具表現力(也是眾所周知)的各種正則功能。許多流行的軟件都使用了PCRE,例如PHP、Apache 2、Exim、Postfix和Nmap(注8)。
本書對應的版本
表3-2列出了本書中使用的工具和庫的版本信息。更老的版本可能功能更少,bug更多,新的版本則會提供更多的特性,並修正之前的bug(當然也可能多出新的bug)。
表3-2:本書中提到的一些工具的版本

最初印象
At a Glance
我們用一張表格來比較常見工具軟件在幾方面的功能,以便理解仍然存在的差異。表 3-3提供了若幹工具軟件的正則表達式所屬流派在各方面的簡要信息。
其他書籍通常在比較各款工具軟件時,也會包含表3-3之類的表格。但是,這張表只是冰山一角——列出的每一種特性的背後,都有許多重要的知識。
最重要的是程序會不斷變化。舉例來說,Tcl以前是不支持反向引用和單詞分界符的,但是現在支持。最開始,用來表示單詞分界符的是難看的[:<:]和[:>:],至今仍是這樣,儘管這種表示法已經廢棄,取代它的是後來添加的m、M和y(單詞起始、單詞結束,或者兩者皆是)。
同樣,grep和egrep並沒有單一的作者,只要願意,任何人都可以開發,也能修改到符合到作者期望的任何流派。人人都希望按照自己的意願來,人性就是如此(例如,許多常用工具的GNU版本,比其他版本更強大,也更健壯)。
表3-3:若干常用工具的Flavor的(非常)簡要考察
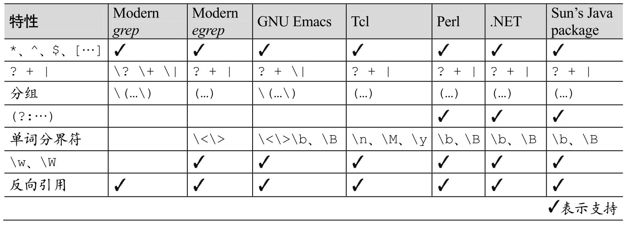
或許與列出的特性一樣重要的是流派之間的許多細微(有些並非細微)差別。從表格來看,Perl、.NET 和 Java 的正則表達式似乎是一樣的,而實際情況卻遠不是這樣。針對表 3-3,讀者可能提出的問題包括:
●星號之類的量詞能否作用於括號之內的子表達式?
●點號能否匹配換行符?排除型字符組能否匹配換行符?以上兩者能否匹配 NUL 字符?
●行錨點(line anchor)是名符其實的嗎(例如,他們能否識別目標字符串內部的換行符)?它們算正則表達式中的基礎級別(first-class)的元字符嗎?還是只能應用在某些結構中?
●字符組內部能出現轉義字符嗎?字符組內部還容許或不容許出現哪些字符?
●括號能夠嵌套嗎?如果是,嵌套的深度是否有限制呢(還有個問題是,一共容許出現多少括號呢)?
●如果容許反向引用,在進行不區分大小寫的匹配時,反向引用能順利進行嗎?在極端的情況下,反向引用的「行為」有意義嗎?
●是否可以出現八進制的轉義字符123?如果是,怎麼區分它和反向引用呢?十六進制的轉義字符呢?這種支持是正則引擎提供的,還是由其他工具提供的?
●w只支持數字和字符,還是包括其他字符?(表 3-3 列出的支持w的工具對w有不同的解釋)。不同的單詞分界符元字符對構成「單詞分界符」的字符的定義不一樣,w是否與它們保持一致?它們是按照locale的定義呢,還是支持Unicode?
即使表3-3這樣的介紹這樣簡單,我們仍然必須記得這些問題。如果你能意識到,在看起來光鮮的外表下面潛藏著許多問題,就容易保持清醒的頭腦來應付它們。
在本章開頭我們已經提到,許多問題只是語法的差異,但也有許多並非如此。比方說,瞭解到egrep的「(Jul|July)」在GNU Emacs中必須寫成「(Jul|July)」之後,你或許會認為所有的問題都是這樣,但事實並非如此。在匹配嘗試過程中的語義差異(或者,至少是看起來是在匹配嘗試過程中的)通常被忽視,但極其重要的問題是,它也解釋了為什麼兩個看起來一樣的表達式會獲得截然不同的結果:一個總是匹配『Jul』,即使目標文本是『July』。這些看起來毫無區別的語義也解釋了,為什麼兩個順序相反的正則表達式:「(July|Jul)」和「(July|Jul)」能夠取得同樣的匹配結果。其實,整個下一章都在講解這類問題。
當然,一款工具軟件能夠利用正則表達式實現的功能,通常比它所屬的正則流派更重要。例如,就算Perl的正則表達式功能不及egrep,在使用正則表達式時,Perl所具有的簡便性卻更有價值。我們會在本章逐個介紹各種特性,並在後面各章深入講解幾種編程語言。