
Java 8中,流有一個非常大的(也可能是最大的)局限性,使用時,對它操作一次僅能得到一個處理結果。實際操作中,如果你試圖多次遍歷同一個流,結果只有一個,那就是遭遇下面這樣的異常:
java.lang.IllegalStateException: stream has already been operated upon or closed
雖然流的設計就是如此,但我們在處理流時經常希望能同時獲取多個結果。譬如,你可能會用一個流來解析日誌文件,就像我們在5.7.3節中所做的那樣,而不是在某個單一步驟中收集多個數據。或者,你想要維持菜單的數據模型,就像我們第4章到第6章用於解釋流特性的那個例子,你希望在遍歷由“佳餚”構成的流時收集多種信息。
換句話說,你希望一次性向流中傳遞多個Lambda表達式。為了達到這一目標,你需要一個fork類型的方法,對每個複製的流應用不同的函數。更理想的情況是你能以並發的方式執行這些操作,用不同的線程執行各自的運算得到對應的結果。
不幸的是,這些特性目前還沒有在Java 8的流實現中提供。不過,本附錄會為你展示一種方法,利用一個通用API1,即Spliterator,尤其是它的延遲綁定能力,結合BlockingQueues和Futures來實現這一大有裨益的特性。
1本附錄接下來介紹的實現基於Paul Sandoz向lambda-dev郵件列表http://mail.openjdk.java.net/pipermail/lambda-dev/2013-November/011516.html提供的解決方案。
C.1 複製流
要達到在一個流上並發地執行多個操作的效果,你需要做的第一件事就是創建一個StreamForker,這個StreamForker會對原始的流進行封裝,在此基礎之上你可以繼續定義你希望執行的各種操作。我們看看下面這段代碼。
代碼清單C-1 定義一個StreamForker,在一個流上執行多個操作
public class StreamForker<T> {
private final Stream<T> stream;
private final Map<Object, Function<Stream<T>, ?>> forks =
new HashMap<>;
public StreamForker(Stream<T> stream) {
this.stream = stream;
}
public StreamForker<T> fork(Object key, Function<Stream<T>, ?> f) {
forks.put(key, f); ←─使用一個鍵對流上的函數進行索引
return this; ←─返回this 從而保證多次流暢地調用fork方法
}
public Results getResults {
// To be implemented
}
}
這裡的fork方法接受兩個參數。
-
Function參數,它對流進行處理,將流轉變為代表這些操作結果的任何類型。 -
key參數,通過它你可以取得操作的結果,並將這些鍵/函數對累積到一個內部的Map中。
fork方法返回StreamForker自身,因此,你可以通過複製多個操作構造一個流水線。圖C-1展示了StreamForker背後的主要思想。
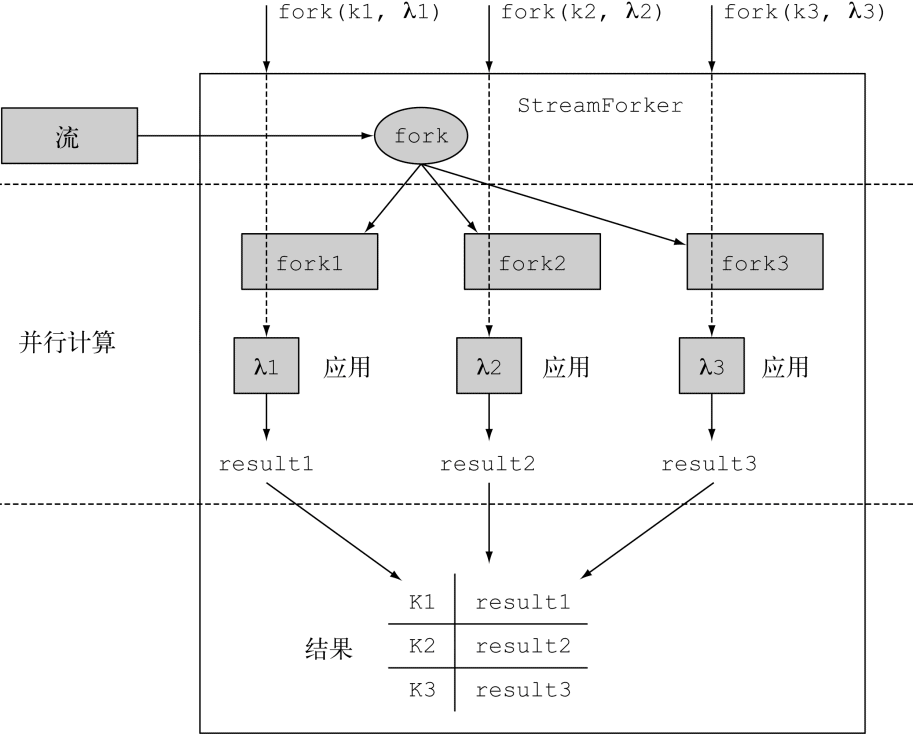
圖 C-1 StreamForker詳解
這裡用戶定義了希望在流上執行的三種操作,這三種操作通過三個鍵索引標識。StreamForker會遍歷原始的流,並創建它的三個副本。這時就可以並行地在複製的流上執行這三種操作,這些函數運行的結果由對應的鍵進行索引,最終會填入到結果的Map。
所有由fork方法添加的操作的執行都是通過getResults方法的調用觸發的,該方法返回一個Results接口的實現,具體的定義如下:
public static interface Results {
public <R> R get(Object key);
}
這一接口只有一個方法,你可以將fork方法中使用的key對像作為參數傳入,方法會返回該鍵對應的操作結果。
C.1.1 使用ForkingStreamConsumer實現Results接口
你可以用下面的方式實現getResults方法:
public Results getResults {
ForkingStreamConsumer<T> consumer = build;
try {
stream.sequential.forEach(consumer);
} finally {
consumer.finish;
}
return consumer;
}
ForkingStreamConsumer同時實現了前面定義的Results接口和Consumer接口。隨著我們進一步剖析它的實現細節,你會看到它主要的任務就是處理流中的元素,將它們分發到多個BlockingQueues中處理,BlockingQueues的數量和通過fork方法提交的操作數是一致的。注意,我們很明確地知道流是順序處理的,不過,如果你在一個並發流上執行forEach方法,它的元素可能就不是順序地被插入到隊列中了。finish方法會在隊列的末尾插入特殊元素表明該隊列已經沒有更多需要處理的元素了。build方法主要用於創建ForkingStreamConsumer,詳細內容請參考下面的代碼清單。
代碼清單C-2 使用build方法創建ForkingStreamConsumer
private ForkingStreamConsumer<T> build {
List<BlockingQueue<T>> queues = new ArrayList<>; ←─創建由隊列組成的列表,每一個隊列對應一個操作
Map<Object, Future<?>> actions = ←─建立用於標識操作的鍵與包含操作結果的Future之間的映射關係
forks.entrySet.stream.reduce(
new HashMap<Object, Future<?>>,
(map, e) -> {
map.put(e.getKey,
getOperationResult(queues, e.getValue));
return map;
},
(m1, m2) -> {
m1.putAll(m2);
return m1;
});
return new ForkingStreamConsumer<>(queues, actions);
}
代碼清單C-2中,你首先創建了我們前面提到的由BlockingQueues組成的列表。緊接著,你創建了一個Map,Map的鍵就是你在流中用於標識不同操作的鍵,值包含在Future中,Future中包含了這些操作對應的處理結果。BlockingQueues的列表和Future組成的Map會被傳遞給ForkingStreamConsumer的構造函數。每個Future都是通過getOperationResult方法創建的,代碼清單如下。
代碼清單C-3 使用getOperationResult方法創建Future
private Future<?> getOperationResult(List<BlockingQueue<T>> queues,
Function<Stream<T>, ?> f) {
BlockingQueue<T> queue = new LinkedBlockingQueue<>;
queues.add(queue); ←─創建一個隊列,並將其添加到隊列的列表中
Spliterator<T> spliterator =new BlockingQueueSpliterator<>(queue); ←─創建一個Spliterator,遍歷隊列中的元素
Stream<T> source = StreamSupport.stream(spliterator, false); ←─創建一個流,將Spliterator作為數據源
return CompletableFuture.supplyAsync( -> f.apply(source) ); ←─創建一個Future對象,以異步方式計算在流上執行特定函數的結果
}
getOperationResult方法會創建一個新的BlockingQueue,並將其添加到隊列的列表。這個隊列會被傳遞給一個新的BlockingQueueSpliterator對象,後者是一個延遲綁定的Spliterator,它會遍歷讀取隊列中的每個元素;我們很快會看到這是如何做到的。
接下來你創建了一個順序流對該Spliterator進行遍歷,最終你會創建一個Future在流上執行某個你希望的操作並收集其結果。這裡的Future使用CompletableFuture類的一個靜態工廠方法創建,CompletableFuture實現了Future接口。這是Java 8新引入的一個類,我們在第11章對它進行過詳細的介紹。
C.1.2 開發ForkingStreamConsumer和BlockingQueueSpliterator
還有兩個非常重要的部分你需要實現,分別是前面提到過的ForkingStreamConsumer類和BlockingQueueSpliterator類。你可以用下面的方式實現前者。
代碼清單C-4 實現ForkingStreamConsumer類,為其添加處理多個隊列的流元素
static class ForkingStreamConsumer<T> implements Consumer<T>, Results {
static final Object END_OF_STREAM = new Object;
private final List<BlockingQueue<T>> queues;
private final Map<Object, Future<?>> actions;
ForkingStreamConsumer(List<BlockingQueue<T>> queues,
Map<Object, Future<?>> actions) {
this.queues = queues;
this.actions = actions;
}
@Override
public void accept(T t) {
queues.forEach(q -> q.add(t)); ←─將流中遍歷的元素添加到所有的隊列中
}
void finish {
accept((T) END_OF_STREAM); ←─將最後一個元素添加到隊列中,表明該流已經結束
}
@Override
public <R> R get(Object key) {
try {
return ((Future<R>) actions.get(key)).get; ←─等待Future完成相關的計算,返回由特定鍵標識的處理結果
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
這個類同時實現了Consumer和Results接口,並持有兩個引用,一個指向由BlockingQueues組成的列表,另一個是執行了由Future構成的Map結構,它們表示的是即將在流上執行的各種操作。
Consumer接口要求實現accept方法。這裡,每當ForkingStreamConsumer接受流中的一個元素,它就會將該元素添加到所有的BlockingQueues中。另外,當原始流中的所有元素都添加到所有隊列後,finish方法會將最後一個元素添加所有隊列。BlockingQueueSpliterators碰到最後這個元素時會知道隊列中不再有需要處理的元素了。
Results接口需要實現get方法。一旦處理結束,get方法會獲得Map中由鍵索引的Future,解析處理的結果並返回。
最後,流上要進行的每個操作都會對應一個BlockingQueueSpliterator。每個BlockingQueueSpliterator都持有一個指向BlockingQueues的引用,這個BlockingQueues是由ForkingStreamConsumer生成的,你可以用下面這段代碼清單類似的方法實現一個BlockingQueueSpliterator。
代碼清單C-5 一個遍歷BlockingQueue並讀取其中元素的Spliterator
class BlockingQueueSpliterator<T> implements Spliterator<T> {
private final BlockingQueue<T> q;
BlockingQueueSpliterator(BlockingQueue<T> q) {
this.q = q;
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
T t;
while (true) {
try {
t = q.take;
break;
} catch (InterruptedException e) { }
}
if (t != ForkingStreamConsumer.END_OF_STREAM) {
action.accept(t);
return true;
}
return false;
}
@Override
public Spliterator<T> trySplit {
return null;
}
@Override
public long estimateSize {
return 0;
}
@Override
public int characteristics {
return 0;
}
}
這段代碼實現了一個Spliterator,不過它並未定義如何切分流的策略,僅僅利用了流的延遲綁定能力。由於這個原因,它也沒有實現trySplit方法。
由於無法預測能從隊列中取得多少個元素,所以estimatedSize方法也無法返回任何有意義的值。更進一步,由於你沒有試圖進行任何切分,所以這時的估算也沒什麼用處。
這一實現並沒有體現表7-2中列出的Spliterator的任何特性,因此characteristic方法返回0。
這段代碼中提供了實現的唯一方法是tryAdvance,它從BlockingQueue中取得原始流中的元素,而這些元素最初由ForkingSteamConsumer添加。依據getOperationResult方法創建Spliterator同樣的方式,這些元素會被作為進一步處理流的源頭傳遞給Consumer對像(在流上要執行的函數會作為參數傳遞給某個fork方法調用)。tryAdvance方法返回true通知調用方還有其他的元素需要處理,直到它發現由ForkingSteamConsumer添加的特殊對象,表明隊列中已經沒有更多需要處理的元素了。圖C-2展示了StreamForker及其構建模塊的概述。

圖 C-2 StreamForker及其合作的構造塊
這幅圖中,左上角的StreamForker中包含一個Map結構,以方法的形式定義了流上要執行的操作,這些方法分別由對應的鍵索引。右邊的ForkingStreamConsumer為每一種操作的對象維護了一個隊列,原始流中的所有元素會被分發到這些隊列中。
圖的下半部分,每一個隊列都有一個BlockingQueueSpliterator從隊列中提取元素作為各個流處理的源頭。最後,由原始流複製創建的每個流,都會被作為參數傳遞給某個處理函數,執行對應的操作。至此,你已經實現了 StreamForker所有組件,可以開始工作了。
C.1.3 將StreamForker運用於實戰
我們將StreamForker應用到第4章中定義的menu數據模型上,希望對它進行一些處理。通過複製原始的菜餚(dish)流,我們想以並發的方式執行四種不同的操作,代碼清單如下所示。這尤其適用於以下情況:你想要生成一份由逗號分隔的菜餚名列表,計算菜單的總熱量,找出熱量最高的菜餚,並按照菜的類型對這些菜進行分類。
代碼清單C-6 將StreamForker運用於實戰
Stream<Dish> menuStream = menu.stream;
StreamForker.Results results = new StreamForker<Dish>(menuStream)
.fork("shortMenu", s -> s.map(Dish::getName)
.collect(joining(", ")))
.fork("totalCalories", s -> s.mapToInt(Dish::getCalories).sum)
.fork("mostCaloricDish", s -> s.collect(reducing(
(d1, d2) -> d1.getCalories > d2.getCalories ? d1 : d2))
.get)
.fork("dishesByType", s -> s.collect(groupingBy(Dish::getType)))
.getResults;
String shortMenu = results.get("shortMenu");
int totalCalories = results.get("totalCalories");
Dish mostCaloricDish = results.get("mostCaloricDish");
Map<Dish.Type, List<Dish>> dishesByType = results.get("dishesByType");
System.out.println("Short menu: " + shortMenu);
System.out.println("Total calories: " + totalCalories);
System.out.println("Most caloric dish: " + mostCaloricDish);
System.out.println("Dishes by type: " + dishesByType);
StreamForker提供了一種使用簡便、結構流暢的API,它能夠複製流,並對每個複製的流施加不同的操作。這些應用在流上以函數的形式表示,可以用任何對象的方式標識,在這個例子裡,我們選擇使用String的方式。如果你沒有更多的流需要添加,可以調用StreamForker的getResults方法,觸發所有定義的操作開始執行,並取得StreamForker.Results。由於這些操作的內部實現就是異步的,getResults方法調用後會立刻返回,不會等待所有的操作完成,拿到所有的執行結果才返回。
你可以通過向StreamForker.Results接口傳遞標識特定操作的鍵取得某個操作的結果。如果該時刻操作已經完成,get方法會返回對應的結果;否則,該方法會阻塞,直到計算結束,取得對應的操作結果。
正如我們所預期的,這段代碼會產生下面這些輸出:
Short menu: pork, beef, chicken, french fries, rice, season fruit, pizza,
prawns, salmon
Total calories: 4300
Most caloric dish: pork
Dishes by type: {OTHER=[french fries, rice, season fruit, pizza], MEAT=[pork,
beef, chicken], FISH=[prawns, salmon]}
C.2 性能的考量
提起性能,你不應該想當然地認為這種方法比多次遍歷流的方式更加高效。如果構成流的數據都保存在內存中,阻塞式隊列所引發的開銷很容易就抵消了由並發執行操作所帶來的性能提升。
與此相反,如果操作涉及大量的I/O,譬如流的源頭是一個巨型文件,那麼單次訪問流可能是個不錯的選擇;因此(大多數情況下)優化應用性能唯一有意義的規則是“好好地度量它”。
通過這個例子,我們展示了怎樣一次性地在同一個流上執行多個操作。更重要地是,我們相信這個例子也證明了一點,即使某個特性原生的Java API暫時還不支持,充分利用Lambda表達式的靈活性和一點點的創意,整合現有的功能,你完全可以實現想要的新特性。