
本章第一節首先介紹了Go語言中的值、指針以及引用類型,因為理解這些概念對於本章的後續節以及本書的後續章節都是必要的。Go語言的指針與C和C++ 中的指針類似,無論是語法上還是語意上。但是Go語言的指針不支持指針運算,這樣就消除了在C和C++ 程序中一類潛在的bug。Go語言也不用free函數或者delete操作符,因為Go語言有垃圾回收器,並且自動管理內存[1]。Go語言引用類型的值以一種獨特而簡單的方式創建,並且一旦創建後就可以像Java或者Python中的對象引用一樣使用。Go語言的值的工作方式與其他大多數主流語言一致。
本章的其他節將深入講解Go語言內置的集合類型。其中包含了Go語言的所有內置類型:數組、切片和映射。這些類型功能齊全並且高效,能夠滿足大部分需求。標準庫中也提供了一些額外的更加特別的集合類型container/heap、container/list和container/ring。這些類型可能在某些特殊情況下更高效。後續章節中有些關於使用堆和列表的小程序(參見9.4.3節)。第6章有個例子,展示了如何創建一個平衡二叉樹(參見6.5.3節)。
4.1 值、指針和引用類型
本節我們討論變量持有什麼內容(值、指針以及指向數組、切片和映射的引用),並在接下來的節中討論如何使用數組、切片和映射。
通常情況下 Go語言的變量持有相應的值。也就是說,我們可以將一個變量想像成它所持有的值來使用。其中有些例外是對於通道、函數、方法、映射以及切片的引用變量,它們持有的都是引用,也即保存指針的變量。
值在傳遞給函數或者方法的時候會被複製一次。這對於布爾變量或者數值類型來說是非常廉價的,因為每個這樣的變量只佔1~8個字節。按值傳遞字符串也非常廉價,因為Go語言中的字符串是不可變的,Go語言編譯器會將傳遞過程進行安全的優化,因此無論傳遞的字符串長度多少,實際傳遞的數據量都會非常小。(每個字符串的代價在64位的機器上大概是16字節,在32位的機器上大概是8字節[2]。)當然,如果修改了一個傳入的字符串(例如,使用 += 操作符),Go語言必須創建一個新的字符串,並且複製原始的字符串並將其加到該字符串之後,這對於大字符串來說很可能代價非常大。
與C和C++ 不同,Go語言中的數組是按值傳遞的,因此傳遞一個大數組的代價非常大。幸運的是,在 Go語言中數組不常用到,因為我們可以使用切片來代替。我們將在下面章節講解切片的用法。傳遞一個切片的成本與字符串差不多(在64位機器上為16字節,在32位機器上為12字節),無論該切片的長度或者容量是多大[3]。另外,修改切片也不會導致寫時複製的負擔,因為不同於字符串的是,切片是可變的(如果一個切片被修改,這些修改對於其他所有指向該切片的引用變量都是可見的)。
圖4-1說明了變量及它們所佔用內存空間的關係。在圖中,內存地址以灰色顯示,因為它們是可變的,而粗體則表示變化。
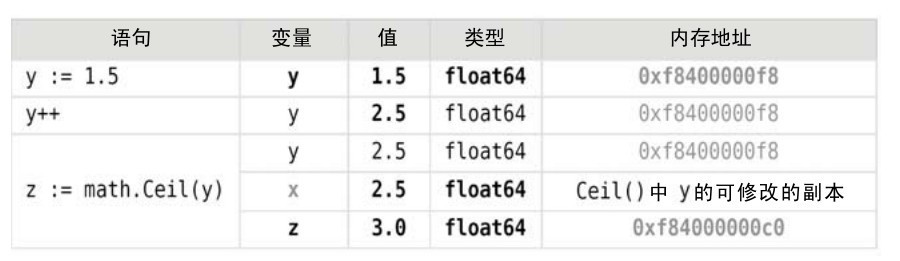
圖4-1 簡單類型值在內存中的表示
從概念上講,變量是賦給一內存塊的名字,該內存塊用於保存特定的數據類型。因此如果我們進行一個短聲明y := 1.5,Go語言就會分配一個足夠放置一個float64數的內存塊(8個字節)並將數字1.5保存到該內存塊中。之後只要y還保存在作用域中,Go語言就會將變量y等同於這個內存塊。因此如果我們在聲明語句後面跟上一條y++ 語句,Go語言將修改變量y對應的內存塊中保存的數值。然而如果我們將y傳遞給一個函數或者方法,Go語言就會傳遞一個y的副本。從另一方面來講,Go語言會創建另一個與所調用的函數的參數名相關聯的變量,並將y的值複製到為該新變量對應的新內存塊中。
有時我們需要一個函數修改我們傳入的值。由於值類型是複製的,因此任何修改只作用於其副本,而其原始值將保持不變。同時,傳值的成本也可能非常高,因為它們會很大(例如,一個數組或者一個包含許多字段的結構體)。此外,本地變量在不再使用時會被垃圾回收(當它們不再被引用或者不在作用域範圍時),然而在許多情況下我們希望自己來管理變量的生命週期而非由它們的作用域決定。
通過使用指針,我們可以讓參數的傳遞成本最低並且內容可修改,而且還可以讓變量的生命週期獨立於作用域。指針是指保存了另一個變量內存地址的變量。創建的指針是用來指向另一個某種類型的變量,這樣就保證了 Go語言知道該指針所指向的值佔用多大的空間。我們馬上會看到,一個被指針指向的變量可以通過該指針來修改。不管指針所指向值的大小,指針的傳遞是非常廉價的(64位的機器上佔8字節,32位的機器上佔4字節)。同時,對於某個指針所指向的變量,只要保證至少有一個指針指向該變量,該變量就會在內存中保存足夠長的時間,因此它們的生命週期獨立於我們所創建的作用域。[4]
在Go語言中&操作符有多重用處。當用作二元操作符時,它是按位與操作。當用作一元操作符時,它返回的是操作數的地址,該地址可由一個指針保存。在圖4-2的第三個語句中,我們將int型變量 x的內存地址賦值給類型為*int的變量pi(指向int型變量的指針)。一元操作符 & 有時也被稱為取址操作符。正如圖4-2中的箭頭所示,術語「指針」也描述了一個事實,即保存了另一變量內存地址的變量通常被認為是「指向」了那個變量。
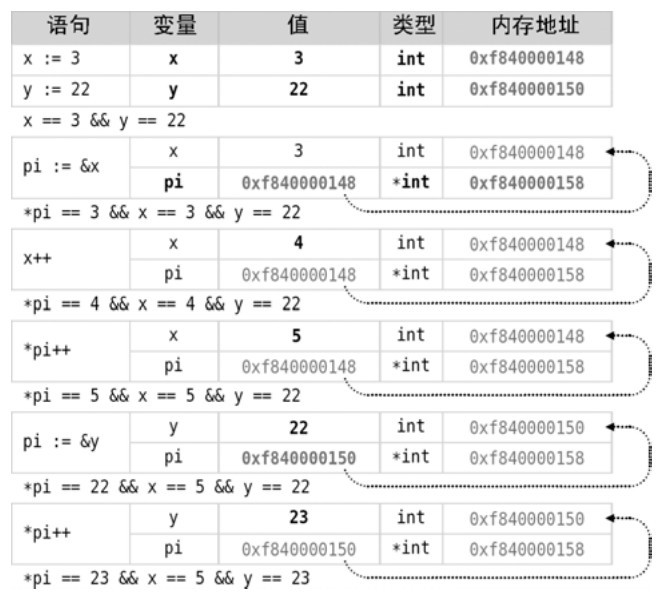
圖4-2 指針和值
同樣,*操作符也有多重用處。當用作二元操作符時,它將其操作數相乘。而當用作一元操作符時,它返回它所作用的指針所指向變量的值。因此,在圖4-2中,pi := &x語句之後*pi和x可以相互交換著使用(但當 pi 被賦值給另一個變量的指針後就不行了)。並且,由於它們與同一塊內存地址相關聯,任何作用於其中一個變量的改變都會改變另一個。一元操作符*有時也叫做內容操作符、間接操作符或者解引用操作符。
圖4-2說明了如果我們將指針所指向變量的值改變,其值如我們所預期的那樣改變,並且當我們將該指針解引用時(*pi),它返回修改後的新值。我們也可以通過指針來改變其值。例如,*pi++意味著將指針所指的值增加;當然,這只有在其類型支持++操作符時才能夠通過編譯,比如Go語言內置的數值類型。
一個指針不必始終指向同一個值。例如,從圖4-2的底部開始,我們將一個指針指向了不同的值(pi := &y),然後通過指針來改變其值。我們可以輕易地直接改變y的值(使用y++),然後使用*pi來返回y的新值。
指針也可以指向另一個指針(或者指向指針的指針的指針)。使用指向值的指針叫做間接引用。如果我們使用指向指針的指針,這就叫做使用多重間接引用。這在C和C++中非常普遍,但在Go語言中不常用到,因為Go語言使用引用類型。這裡有個簡單的例子。
z := 37 // z的類型為int
pi := &z // pi的類型為 *int(指向int型的指針)
ppi := &pi // ppi的類型為 **int (指向int類型指針的指針)
fmt.Println(z, *pi, **ppi)
**ppi++ // 語意上等同於(*(*ppi))++和*(*ppi)++
fmt.Println(z, *pi, **ppi)
37 37 37
38 38 38
在上面的代碼片段中,pi是一個*int類型(指向int類型的指針)的指針,它指向一個int類型的變量z,同時ppi是一個指向pi的**int類型的指針(指向int類型指針的指針)。當解引用時,對於每一層的間接引用我們使用*操作符,因此*ppi 解引用 ppi 變量產生一個*int,即一個內存地址,再次應用*操作符(**ppi)時,我們得到所指向的整型值。
除了當做乘法和解引用操作符之外,*操作符也可以當做類型修改符。當一個*置於類型名的左邊時,它將原來聲明一個特定類型的值的語義修改為了聲明一個指向特定類型值的指針。這在圖4-2的「類型」一欄中展示。
讓我們用一個小例子來解釋下目前為止所討論的內容。
i := 9
j := 5
product := 0
swapAndProduct1(&i, &j, &product)
fmt.Println(i, j, product)
5 9 45
這裡我們創建了 3 個類型為整型的變量,並給它們一個初始值。然後我們調用自定義的swapAndProduct1函數。該函數接收3個整型變量指針,保證指針指向的頭兩個整型數按遞增順序排列,並且讓第三個指針指向的整型數賦值為前兩個整型數的乘積。由於該函數接受指針而非值類型的參數,我們必須傳入指向int類型值的指針,而非該int類型值。每當我們看到取址操作符&被用於函數調用時,我們都要假設對應的變量值可能在函數內被修改。下面是該swapAndProduct1函數的實現。
func swapAndProduct1(x, y, product *int) {
if *x > *y {
*x, *y = *y, *x
}
*product = *x * *y // 編譯器也能處理這樣的寫法:*product=*x**y
}
函數的參數聲明*int使用*類型修改符來聲明其參數全是指向整型數的指針。當然,這也意味著我們只能傳入指向整型變量的指針(使用取址操作符 &),而非傳入整型變量或者整型數。
在函數內部,我們更關心指針所指向的值,因此我們從頭到尾都使用解引用操作符*。在最後一個可執行的行中,我們將兩個指針所指向的值乘起來,然後將其結果賦值給另一個指針所指向的變量。當有兩個連續的*出現時,Go語言會根據上下文將其識別成乘法而非兩個解引用。在函數內部,指針是x、y和product,但是在函數調用處,它們所指向的值為3個整型變量i、j和product。
在C和早期的C++代碼中,用這種方式實現函數是非常普遍的現象,但在Go語言中這種寫法不是必須的。如果我們只有一個或者不多的幾個值,在 Go語言中更符合常規的做法是直接返回它們,而如果有許多值要傳遞的話,以切片或者映射(我們馬上會看到,無需指針也可以非常廉價地傳遞它們)的形式傳遞就可以了,如果它們的類型不一致則將其放在一個結構體中再用指針傳遞。這裡有個沒用到指針的更簡單的改進版。
i := 9
j := 5
i, j, product := swapAndProduct2(i, j)
fmt.Println(i, j, product)
5 9 45
這裡是我們所寫的對應的swapAndProduct2函數。
func swapAndProduct2(x, y int) (int, int, int) {
if x > y {
x, y = y, x
}
return x, y, x * y
}
這個版本的函數應該比第一個版本清晰多了,但沒用指針也導致了該函數不能就地交換數據。
在C和C++中,函數參數包含一個布爾類型指針來表示成功或者失敗的做法是很常見的。這在Go語言中可以通過在函數簽名處包含一個*bool變量來實現,但直接以最後一個返回值的形式返回一個布爾型的成功標誌(或者最好是一個error值)的寫法更好用,這也是Go語言的推薦做法。
在目前為止已經展示的代碼片段中,我們使用取址操作符&來取得函數參數或者本地變量的地址。Go語言的自動內存管理機制使得這樣做非常安全,因為只要一個指針引用一個變量,那個變量就會在內存中得以保留。這也是為什麼在 Go語言的函數內部返回指向本地變量的指針是安全的(在C/C++中,對於非靜態變量的同樣操作將是災難)。
在某些場景下,我們需要傳遞非引用類型的可修改值,或者需要高效地傳入大類型的值,這個時候我們需要用到指針。Go語言提供了兩種創建變量的語法,同時獲得指向它們的指針。其中一種方法是使用內置的new函數,另一種方法是使用地址操作符。為了比較一下,我們將介紹這兩種語法,並用兩種語法分別創建一個扁平結構的結構體類型值。
type composer struct{
name string
birthYear int
}
給定這個結構體定義,我們可以創建 composer 值或指向 composer 值的指針,即*composer類型的變量。在這兩種情況下,我們都可以利用Go語言對結構體初始化的支持使用大括號來初始化數據。
antonio := composer{〞Antonio Teixeira〞, 1707} // composer類型值
agnes := new(composer) // 指向composer的指針
agnes.name, agnes.birthYear = 〞Agnes Zimmermann〞, 1845
julia := &composer{} // 指向composer的指針
julia.name, julia.birthYear = 〞Julia Ward Howe〞, 1819
augusta := &composer{〞Augusta Holmes〞, 1847} // 指向composer的指針
fmt.Println(antonio)
fmt.Println(agnes, augusta, julia)
{Antonio Teixeira 1707}
&{Agnes Zimmermann 1845} &{Augusta Holmes 1847} &{Julia Ward Howe 1819}
當 Go語言打印指向結構體的指針時,它會打印解引用後的結構體內容,但會將取址操作符&作為前綴來表示它是一個指針。上面創建了agnes和julia兩個指針的代碼片段用於解釋以下兩種用法的等同性,只要其類型可以使用大括號進行初始化:
new(Type) ≡&Type{}
這兩種語法都分配了一個Type類型的空值,同時返回一個指向該值的指針。如果Type不是一個可以使用大括號初始化的類型,我們只可以使用內置的new函數。當然,我們不必擔心該值的生命週期或怎麼將其刪除,因為Go語言的內存管理系統會幫我們打理一切。
使用結構體的&Type{}語法的一個好處是我們可以為其指定初始值,正如我們這裡創建augusta指針時所做的那樣(後面我們將看到,我們也可以只聲明一些可選的字段而將其他字段設為它們的0值,參見6.4節)。
除了值和指針之外,Go語言也有引用類型(另外Go語言還有接口類型,但在大多數實際使用中我們可以把接口看成某種類型的引用,引用類型將在本書稍後介紹,參見6.3節)。一個引用類型的變量指向內存中某個隱藏的值,它保存著實際的數據。保存引用類型的變量傳遞時也非常廉價(在64位機器上一個切片占16字節,一個映射占8字節),其使用語法與值一樣(我們不必取得一個引用類型的地址,在需要得到該引用所指的值時也無需解引用它)。
一旦我們遇到需要在一個函數或方法中返回超過四五個值的情況時,如果這些值是同一類型的話最好使用一個切片來傳遞,如果其值類型各異則最好傳遞一個指向結構體的指針。傳遞一個切片或一個指向結構體的指針的成本都比較低,同時也允許我們修改數據。讓我們用一些小例子來解釋這些。
grades := int{87, 55, 43, 71, 60, 43, 32, 19, 63}
inflate(grades, 3)
fmt.Println(grades)
[261 165 129 213 180 129 96 57 189]
這裡我們在一個整型切片之上進行一個操作。映射和切片都是引用類型,並且映射或者切片項中的任何修改(無論是直接的還是在它們所傳入的函數中間接的修改)對於引用它們的變量來說都是可見的。
func inflate(numbers int, factor int) {
for i := range numbers {
numbers[i] *= factor
}
}
grades切片作為參數numbers傳入函數。但與傳入值不同的是,任何作用於numbers的更改都會作用於grades,因為它們都指向同一個切片。
由於我們希望原地修改切片的值,所以使用了一個循環來輪流獲得其中的值。我們沒有使用for index、item...range這樣的循環是因為這樣只能得到其所操作的切片元素的副本,導致其副本與因數相乘之後將該值丟棄,而原始切片的值則保持不變。我們本來可以使用更熟悉的類似於其他語言的for循環(例如for i := 0; i < len(numbers); i++),但我們可以使用更為方便的for index := range語法(下一章會講解所有的for循環語法,參見5.3節)。
我們假設有一個矩形類型,將一個矩形的位置保存為左上角和右下角的x、y 坐標以及機器填充色。我們可以將該矩形的數據表示成一個結構體。
type rectangle struct {
x0, y0, x1, y1 int
fill color.RGBA
}
現在我們可以創建一個矩形類型的值,打印它的內容,調整大小,然後再打印它的內容。
rect := rectangle{4, 8, 20, color.RGBA{0xFF, 0, 0, 0xFF}}
fmt.Println(rect)
resizeRect(&rect, 5, 5)
fmt.Println(rect)
{4 8 20 10 {255 0 0 255}}
{4 8 25 15 {255 0 0 255}}
正如我們在前面章節所提到的,雖然 Go語言不認識我們所定義的矩形類型,但它還是能夠用合適的格式將其打印出來。代碼下面的輸出清楚地顯示出resizeRect功能的正確性。與傳入整個矩形(其中的整型至少占16字節)不同的是,我們只傳入其地址(無論結構體多大,在64位系統中都是8字節)。
func resizeRect(rect *rectangle, Δwidth, Δheight int) {
(*rect).x1 += Δwidth // 令人厭惡的顯式解引用
rect.y1 += Δheight // 〞.〞操作符能夠自動解引用結構體
}
函數的第一個語句使用顯式的解引用操作,展示了其底層發生的操作。(*rect)引用的是該指針所指出的矩形值,其中的.x1引用矩形的x1字段。第二個語句所給出的才是使用結構體值的常用方法。結構體指針也使用與第二個語句一樣的語法,在這種情況下,需依賴 Go語言來為我們解引用。之所以這樣是因為,Go語言的.(點)操作符能夠自動地將指針解引用為它所指向的結構體[5]。
Go語言中有些類型是引用類型:映射、切片、通道、函數和方法。與指針不同的是,引用類型沒有特殊的語法,因為它們就像值一樣。指針也可以指向一個引用類型,雖然它只對切片有用,但有時這個用法也很關鍵(我們將在下一章節中看到使用指向切片的指針的案例,參見5.7節)。
如果我們定義了一個變量來保存一個函數,該變量得到的實際是該函數的引用。函數引用知道它們所引用的函數的簽名,因此不能傳遞一個簽名不匹配的函數引用。這也消除了一些在某些語言中可能發生的非常麻煩的錯誤和崩潰,因為這些語言在使用函數指針時不保證這些函數的簽名正確。我們已經看到了一些傳入函數引用的例子,比如當我們傳遞一個映射函數給strings.Map函數時。我們會在本書餘下的部分看到更多使用指針和引用類型的例子。
4.2 數組和切片
Go語言的數組是一個定長的序列,其中的元素類型相同。多維數組可以簡單地使用自身為數組的元素來創建。
數組的元素使用操作符來索引,索引從0開始。因此一個數組的首元素是array[0],其最後元素是array[len(array)-1]。數組是可更改的,因此我們使用將array[index]放置在賦值操作符的左邊這樣的語法來設置index位置處的元素內容。我們也可以在一個賦值語句的右邊或者一個函數調用中使用該語法,以獲得該元素。
數組使用以下語法創建:
[length]Type
[N]Type{value1, value2,..., valueN}
[...]Type{value1, value2,..., valueN}
如果在這種場景中使用了...(省略符)操作符,Go語言會為我們自動計算數組的長度。(我們將在本章後面及第5章看到,這個省略操作符也可以用於其他目的。)在任何情況下,一個數組的長度都是固定的並且不可修改。
以下示例展示了如何創建和索引數組。
var buffer [20]byte
var grid1 [3][3]int
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := [3][3]int{{4, 3}, {8, 6, 2}}
cities := [...]string{〞Shanghai〞, 〞Mumbai〞, 〞Istanbul〞, 〞Beijing〞}
cities[len(cities)-1] = 〞Karachi〞
fmt.Println(〞Type Len Contents〞)
fmt.Printf(〞%-8T %2d %v\n〞, buffer, len(buffer), buffer)
fmt.Printf(〞%-8T %2d %q\n〞, cities, len(cities), cities)
fmt.Printf(〞%-8T %2d %v\n〞, grid1, len(grid1), grid1)
fmt.Printf(〞%-8T %2d %v\n〞, grid2, len(grid2), grid2)
Type Len Contents
[20]uint8 20 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[4]string 4 [〞Shanghai〞 〞Mumbai〞 〞Istanbul〞 〞Karachi〞]
[3][3]int 3[[000][862][000]]
[3][3]int 3[[430][862][000]]
正如上面的buffer、grid1和grid2變量所展示的,當創建數組時,如果沒有被顯式地初始化或者只是部分初始化,Go語言會保證數組的所有項都被初始化成其相應的零值。
數組的長度可以使用len函數獲得。由於數組的長度是固定的,因此它們的容量總是等於其長度,對於數組而言cap函數和len函數返回的數字一樣。數組可以使用與字符串或者切片一樣的語法進行切片,只是其結果為一個切片,而非數組。同時,就像字符串和切片一樣,數組也可以使用for...range循環來進行迭代(參見5.3節)。
一般而言,Go語言的切片比數組更加靈活、強大且方便。數組是按值傳遞的(即傳遞副本,雖然可以通過傳遞指針來避免)而不管切片的長度和容量如何,傳遞成本都會比較小,因為它們是引用。(無論包含了多少個元素,一個切片在64位機器上是以16字節的值進行傳遞的,在32位機器上是以12字節的值進行傳遞的。)數組是定長的,而切片可以調整長度。Go語言標準庫中的所有公開函數使用的都是切片而非數組[6]。我們建議使用切片來代替數組,除非在特殊的案例下有非常特別的需求必須用數組。數組和切片都可以使用表4-1中所給出的語法來進行切片。
表4-1 切片操作

Go語言中的切片是長度可變、容量固定的相同類型元素的序列。我們將在後文看到,雖然切片的容量固定,但也可以通過將其切片來收縮或者使用內置的append函數來增長。多維切片可以自然地使用類型為切片的元素來創建,並且多維切片內部的切片長度也可變。
雖然數組和切片所保存的元素類型相同,但在實際使用中並不受此限。這是因為其類型可以是一個接口。因此我們可以保存任意滿足所聲明的接口的元素(即它們定義了該接口所需的方法)。然後我們可以讓一個數組或者切片為空接口interface{},這意味著我們可以存儲任意類型的元素,雖然這會導致我們在獲取一個元素時需要使用類型斷言或者類型轉變,或者兩者配合使用。(接口會在第6章講到。反射的內容參見9.4.9節。)
我們可以使用以下語法創建切片:
make(Type, length, c apacity)
make(Type, length)
Type{}
Type{value1, value2,..., valueN}
內置函數 make用於創建切片、映射和通道。當用於創建一個切片時,它會創建一個隱藏的初始化為零值的數組,然後返回一個引用該隱藏數組的切片。該隱藏的數組與 Go語言中的所有數組一樣,都是固定長度的,如果使用第一種語法創建,那麼其長度即為切片的容量;如果使用第二種語法創建,那麼其長度即為切片的長度;如果使用復合語法創建(第三種或者第四種),那麼其長度為大括號中項的個數。
一個切片的容量即為其隱藏數組的長度,而其長度則為不超過該容量的任意值。在第一種語法中,切片的長度必須小於或者等於容量,雖然這種語法一般也是在我們希望其初始長度小於容量的時候才使用。第二種、第三種和第四種語法都是用於當我們希望其長度和容量相同時。復合語法(第四種)非常方便,因為它允許我們使用一些初始值來創建切片。
語法Type{}與語法 make(Type, 0)等價,兩者都創建一個空切片。這並不是無用的,因為我們可以使用內置的append函數來有效地增加切片的容量。然而在實際使用中如果我們需要一個初始化為空的切片,使用make函數來創建會更實用,只需將長度設為0,並且將容量設為一個我們估計該切片需要保存的元素個數。
一個切片的索引位置範圍為從 0 到 len(slice)-1。一個切片可以再重新切片以減小長度,並且如果一個切片的長度小於其容量值,那麼該切片也可以重新切片以將其長度增長為容量值。我們將在後文提到,可以使用內置的append函數來增加切片的容量。
圖4-3從概念的視角給出了切片與其隱藏數組的關係。下面這些是它所給出的切片。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
t := s[:5] // [A B C D E]
u := s[3 : len(s)-1] // [D E F]
fmt.Println(s, t, u)
u[1] = 〞X〞
fmt.Println(s, t, u)
[A B C D E F G] [A B C D E] [D E F]
[A B C D x F G] [A B C D x] [D x F]
由於切片s、t和u都是同一個底層數組的引用,其中一個改變會影響到其他所有指向該相同數組的任何其他引用。
s := new([7]string)[:]
s[0], s[1], s[2], s[3], s[4], s[5], s[6] = 〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞,〞G〞
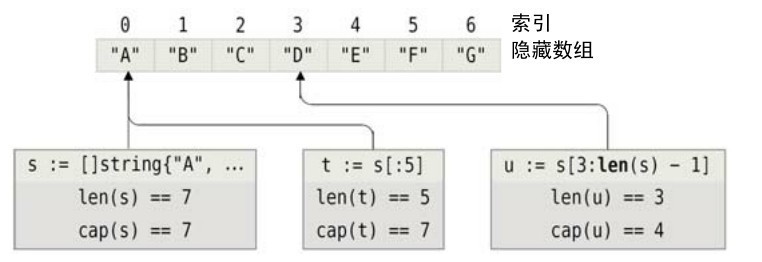
圖4-3 切片與其底層數組的概念圖
使用內置的make函數或者復合語法是創建切片的最好方式,但是這裡我們給出了一種在實際中不常用到但是能夠很明顯地說明數組及其切片之間關係的方法。第一條語句使用內置的new函數創建一個指向數組的指針,然後立即取得該數組的切片。這會創建一個其長度和容量都與數組的長度相等的切片,但是所有元素都會被初始化為零值(在這裡是空字符串)。第二條語句通過將每個元素設置成我們想要的初始值來完成整個切片的設置。設置完成之後,該切片與上文中使用復合語法創建的切片完全一樣。
下面基於切片的例子除了我們將buffer的容量設為大於其長度以演示如何使用外,與我們之前所看到的基於數組的例子功能完全一致。
bufer := make(byte, 20, 60)
grid1 := make(int, 3)
for i := range grid1 {
grid1[i] = make(int, 3)
}
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := int{{4, 3, 0}, {8, 6, 2}, {0, 0, 0}}
cities := string{〞Shanghai〞, 〞Mumbai〞, 〞Istanbul〞, 〞Beijing〞}
cities[len(cities)-1] = 〞Karachi〞
fmt.Println(〞Type Len Cap Contents〞)
fmt.Printf(〞%-8T %2d %3d %v\n〞, buffer, len(buffer), cap(buffer), buffer)
fmt.Printf(〞%-8T %2d %3d %q\n〞, cities, len(cities), cap(cities), cities)
fmt.Printf(〞%-8T %2d %3d %v\n〞, grid1, len(grid1), cap(grid1), grid1)
fmt.Printf(〞%-8T %2d %3d %v\n〞, grid1, len(grid2), cap(grid2), grid2)
Type Len Cap Contents
unit8 20 60[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
string 4 4[〞Shanghai〞 〞Mumbai〞 〞Istanbul〞 〞Karachi〞]
int 3 3 [[0 0 0] [8 6 2] [0 0 0]]
int 3 3 [[4 3 0] [8 6 2] [0 0 0]]
buffer的內容僅僅是前面 len(buffer)個項,除非我們將其重新切片,否則我們將無法取到其他元素。後面幾節會講到如何重新做切片。
我們使用初始值長度為3(即包含3個切片)和容量為3(由於無特殊說明的情況下默認初始容量的值為其長度)來創建一個切片的切片grid1。然後我們為grid1最外層的切片的每一項設置成包含它們自身的切片,該包含的切片也含有3個項。自然地,我們也可以讓最內層的切片長度不一。
對於grid2我們必須聲明每一個值,因為使用了復合語法來創建它,而Go語言沒有其他方法來知道我們需要多少個項。總之,我們創建了一個包含不同長度切片的切片,例如grid2 :=int{{9,7}, {8}, {4, 2, 6}}可以使得grid2是一個長度為3並且包含3個長度分別為2, 1和3的切片的切片。
4.2.1 索引與分割切片
一個切片是一個隱藏數組的引用,並且對於該切片的切片也引用同一個數組。這裡有一個例子可以解釋上面所提到的。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
t := s[2:6]
fmt.Println(t, s, 〞=〞, s[:4], 〞+〞, s[4:])
s[3] = 〞x〞
t[len(t)-1] = 〞y〞
fmt.Println(t, s, 〞=〞, s[:4], 〞+〞, s[4:])
[C D E F] [A B C D E F G] = [A B C D] + [E F G]
[C x E y] [A B C x E y G] = [A B C x] + [E y G]
我們可以改變數據,無論是通過原始切片s還是通過切片s的切片t,它們的底層數據都改變了,因此兩個切片都受影響。上面的代碼片段也說明,對於一個切片s和一個索引值i(0 <=i <= len(s)),s等於s[:i]與s[i:]的連接。在前面章節中講字符串引用的時候我們也看到了類似的相等性:
s == s[:i] + s[i:] // s是一個字符串,i是整型,0 <= i <= len(s)
圖4-4 展示了切片s,包括它所有有效的索引位置和上面代碼中用到的切片。任何切片中的第一個索引位置都為0,而最後一個則為len(s) - 1。
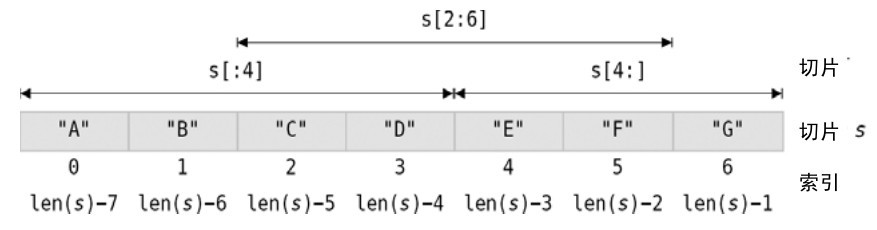
圖4-4 切片剖析
與字符串不同的是,切片不支持+或者+=操作符,然而可以很容易地往切片後面追加以及插入和刪除元素,我們隨後將看到(參見4.2.3節)。
4.2.2 遍歷切片
一個常用到的需求是遍歷一個切片中的元素。如果我們想要取得切片中的某個元素而不想修改它,那我們可以使用for...range循環,如果想要修改它則可以使用帶循環計數器的for循環。關於前者,這裡有一個例子。
amounts := float64{237.81, 261.87, 273.93, 279.99, 281.07, 303.17,
231.47, 227.33, 209.23, 197.09}
sum := 0.0
for _, amount := range amounts {
sum += amount
}
fmt.Printf(〞Σ %.1f→ %.1f\n〞, amounts, sum)
Σ[237.8 261.9 273.9 280.0 281.1 303.2 231.5 227.3 209.2 197.1]→2503.0
for...range循環首先初始化一個從0開始的循環計數器,在本例中我們使用空白符將該值丟棄(_),然後是從切片中複製對應元素。這種複製即使對於字符串來說也是代價很小的(因為它們按引用傳遞)。這意味著任何作用於該項的修改都只作用於該副本,而非切片中的項。
自然地,我們可以使用切片的方式來遍歷切片中的一部分。例如,如果我們想要遍歷切片的前5個元素,我們可以這樣寫for _, amount := range amounts[:5]。
如果我們想修改切片中的項,我們必須使用可以提供有效切片索引而非僅僅是元素副本的for循環。
for i := range amounts {
amounts[i] *= 1.05
sum += amounts[i]
}
fmt.Printf(〞Σ %.1f→ %.1f\n〞, amounts, sum)
Σ[249.7 275.0 287.6 294.0 295.1 318.3 243.0 238.7 219.7 206.9]→2628.1
這裡我們將切片中的每個元素值增加了5%,並將其總和累加起來。
當然,切片也可以包含自定義類型的元素。以下是包含了一個自定義方法的自定義類型。
type Product struct {
name string
price float64
}
func (product Product) String string{
return fmt.Sprintf(〞%s (%.2f)〞, product.name, product.price)
}
這裡將Product類型定義為一個包含一個字符串和一個float64類型字段的結構體。我們同時也定義了String方法來控制Go語言如何使用 %v格式符輸出Product的內容(我們之前介紹了打印格式符,參見3.5節。在1.5節中我們簡單地引入了自定義類型和方法。第6章將提供更多的內容。)
products := *Product{{〞Spanner〞, 3.99}, {〞Wrench〞, 2.49},
{〞Screwdriver〞, 1.99}}
fmt.Println(products)
for _, product := range products {
product.price += 0.50
}
fmt.Println(products)
[Spanner (3.99) Wrench (2.49) Screwdriver (1.99)]
[Spanner (4.49) Wrench (2.99) Screwdriver (2.49)]
這裡我們創建了一個包含指向 Product 指針(*Product)的切片,然後立即使用 3 個*Product 來將其初始化。之所以可以這樣做是因為 Go語言足夠靈活能夠識別出來一個*Product需要的是指向Product的指針。我們這裡所寫的只是products := *Product{&Product{〞Spanner〞, 3.99}, &Product{〞Wrench〞, 2.49}, &Product{〞Scre wdriver〞, 1.99}}的簡化版(在4.1節中,我們使用&Type{}來創建一個該類型的新值,並立即得到了一個指向它的指針)。
如果我們沒有定義Product.String方法,那麼格式符%v(該格式符在fmt.Println以及類似的函數中被顯式地調用)輸出的就是Product的內存地址,而非Product的內容。同時需注意的是Product.String 方法接收一個Product值,而非一個指針。然而這不成問題,因為Go語言足夠聰明,當需要傳值的地方傳入的是一個指針的時候,Go會自動將其解引用[7]。
我們之前也提到for...range循環不能用於修改所遍歷元素的值,然而在這裡我們成功地將切片中所有產品的價格都增加了。在每一次遍歷中,變量 product 被賦值為一個*Product副本,這是一個指向products所對應的底層Product的指針。因此,我們所做的修改是作用於指針所指向的值,而非*Product指針的副本。
4.2.3 修改切片
如果我們需要往切片中追加元素,可以使用內置的append函數。這個函數接受一個需要被追加的切片,以及一個或者多個需要被追加的元素。如果我們希望往一個切片中追加另一個切片,那麼我們必須使用...(省略號)操作符來告訴Go語言將被添加進來的切片當成多個元素。需要添加的元素類型必須與切片類型相同。以字符串為例,我們可以使用省略號語法將字節添加進一個字節類型切片中。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
t := string{〞K〞, 〞L〞, 〞M〞, 〞N〞}
u := string{〞m〞, 〞n〞, 〞o〞, 〞p〞, 〞q〞, 〞r〞}
s = append(s, 〞h〞, 〞i〞, 〞j〞) // 添加單一的值
s = append(s, t...) // 添加切片中的所有值
s = append(s, u[2:5]...) //添加一個子切片
b := byte{'U', 'V'}
letters := 〞WXY〞
b = append(b, letters...) //將一個字符串字節添加進一個字節切片中
fmt.Printf(〞%v\n%s\n〞, s, b)
[A B C D E F G h i j K L M N o p q]
UVwxy
內置的append函數接受一個切片和一個或者更多個值,返回一個(可能為新的)切片,其中包含原始切片的內容並將給定的值作為其後續項。如果原始切片的容量足夠容納新的元素(即其長度加上新元素數量的和不超過切片的容量),append函數將新的元素放入原始切片末尾的空位置,切片的長度隨著元素的添加而增長。如果原始切片沒有足夠的容量,那麼append函數會隱式地創建一個新的切片,並將其原始切片的項複製進去,再在該切片的末尾加上新的項,然後將新的切片返回,因此需要將append的返回值賦值給原始切片變量。
有時我們不僅想往切片的末尾插入項,也想往切片的前面或者中間插入項。下面這些例子使用了我們自定義的InsertStringSliceCopy函數,它接收一個我們要插入切片的參數、一個用於插入的切片以及需插入切片的索引位置。
s := string{〞M〞, 〞N〞, 〞O〞, 〞P〞, 〞Q〞, 〞R〞}
x := InsertStringSliceCopy(s, string{〞a〞, 〞b〞, 〞c〞}, 0) //At the front
y := InsertStringSliceCopy(s, string{〞x〞, 〞y〞}, 3) // In the middle
z := InsertStringSliceCopy(s, string{〞z〞}, len(s)) // At the end
fmt.Printf(〞%v\n%v\n%v\n%v\n〞, s, x, y, z)
[M N O P Q R]
[a b c M N O P Q R]
[M N O x y P Q R]
[M N O P Q R z]
自定義的InsertStringSliceCopy函數創建了一個新的切片(這也是為什麼在輸出的時候切片s沒有被改變的原因),使用內置的copy函數來複製第一個切片,並插入第二個切片。
func InsertStringSliceCopy(slice, insertion string, index int)string{
result := make(string, len(slice)+len(insertion))
at := copy(result, slice[:index])
at += copy(result[at:], insertion)
copy(result[at:], slice[index:])
return result
}
內置的copy函數接受兩個包含相同類型元素的切片(這兩個切片也可能是同一個切片的不同部分,包括重疊的部分)。該函數將第二個切片(源切片)的元素複製到第一個切片(目標切片),並返回所複製元素的數量。如果源切片為空,那麼copy函數將安全地什麼都不做。如果目標切片的長度不夠來容納目標切片中的項,那麼那些無法容納的項將被忽略。如果目標切片的容量比其長度大,我們可以在複製之前通過語句slice = slice[:cap(slice)]來將其長度增加至容量值。
傳入copy函數的兩個切片的類型必須相同(例外情況是當第一個切片(目標切片)的類型為byte時,第二個切片(源切片)可以是byte類型或者字符串類型)。如果源切片是一個字符串,那麼會將其字節碼拷入第一個參數。(關於這類用法的一個例子將在第6章6.3節講解。)
在自定義的函數InsertStringSliceCopy函數開始處,我們首先創建一個新的切片(result),其容量足夠容納所傳入的兩個切片的項。然後將第一個切片到索引位置處的子切片複製到result切片中。接下來我們將所需插入的切片複製到result切片的末尾,其位置從我們上次複製子切片時所到達的位置開始。然後再將第一個切片中剩下的子切片複製到result 切片中,其位置也從我們上次複製子切片時所到達的位置開始。對於最後一次複製,函數copy的返回值被忽略,因為我們不再需要它了。最後,返回result切片。
如果所傳入的索引位置為0,那麼第一條語句中的slice[:index]為slice[:0],因此無需進行複製。類似地,如果所傳入的索引位置大於等於切片的長度,則最後一條複製語句為slice[len(slice):](即一個空切片),因此也無需複製。
以下這個函數的功能與之前的InsertStringSliceCopy函數類似,但是更加簡短。不同點在於,InsertStringSlice函數會更改原始切片(也可能修改需插入的切片),然而InsertStringCopy函數不會修改這些切片。
func InsertStringSlice(slice, insertion string, index int) string {
return append(slice[:index], append(insertion, slice[index:]...)...)
}
InsertStringSlice函數將原始切片從索引位置處到末尾處的子切片追加到插入切片中,並將得到的切片插入到原始切片從開始處到索引位置處的子切片末尾。其返回值為被疊加後的原始切片。(回憶下,append函數接受一個切片和一個或者多個值,因此我們必須使用省略號語法來將一個切片轉換成它的多個元素值,而本例中我們必須這樣做兩次。)
使用Go語言的標準切片語法可以將元素從切片的開頭和末尾處刪除,但是將其從中間刪除就費點事。我們接下來首先看看如何在原地從一個切片的頭和尾刪除一個元素,然後是從中間刪除。之後再看看如何複製一個從原始切片刪除了部分元素後得到的切片,但原始切片保持不變。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
s = s[2:] // 從開始處刪除s[:2]子切片
fmt.Println(s)
[C D E F ]
通過使用再切片,可以輕易地從一個切片的開頭刪除元素。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
s = s[:4] // 從末尾處刪除s[4:]子切片
fmt.Println(s)
[A B C D]
從一個切片的末尾處刪除元素使用的也是再切片方法,與從切片的開頭處刪除元素一樣。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
s = append(s[:1], s[5:]...) // 從中間刪除s[1:5]
fmt.Println(s)
[A F G]
從中間取得元素非常簡單。例如,要取得切片 s 中間的3 個元素,我們可以使用表達式s[2:5]。但是要從切片的中間刪除元素就略微需要一點點技巧。這裡我們使用 append函數來將需要刪除元素的前後兩部分連接起來,並將其賦值回給s。
明顯地,使用append函數並且將新切片賦值回給原始切片來刪除元素這樣的做法會改變原始切片。以下幾個例子使用了自定義的RemoveStringSliceCopy函數,它會返回原始切片的副本,但刪除了其開始和結尾索引位置處之間的元素。
s := string{〞A〞, 〞B〞, 〞C〞, 〞D〞, 〞E〞, 〞F〞, 〞G〞}
x := RemoveStringSliceCopy(s, 0, 2) // 從頭部刪除s[:2]
y := RemoveStringSliceCopy(s, 1, 5) // 從中間刪除s[1:5]
z := RemoveStringSliceCopy(s, 4, len(s)) // 從結尾處刪除s[4:]
fmt.Printf(〞%v\n%v\n%v\n%v\n〞, s, x, y, z)
[A B C D E F G]
[C D E F G]
[A F G]
[A B C D]
由於RemoveStringSliceCopy函數首先複製了原始切片的元素,因此原始切片保持完整。
func RemoveStringSliceCopy(slice string, start, end int)string{
result := make(string, len(slice)-(end-start))
at := copy(result, slice[:start])
copy(result[at:], slice[end:])
return result
}
在RemoveStringSliceCopy函數中,我們首先創建一個新切片(result),並保證其容量足夠大。然後我們將原始切片中從開頭到start索引位置處的子切片拷進result切片中。接下來我們再將原始切片中從索引位置處到結尾處的子切片追加到result切片中。最後,我們返回result切片。
當然我們也可以創建一個更加簡單的工作於原始切片的RemoveStringSlice函數,而不是創建一個副本。
func RemoveStringSlice(slice string, start, end int) string{
return append(slice[:start], slice[end:]...)
}
這是對之前所給出的使用append函數從切片中間刪除元素的例子的通用化修改。其返回的切片為原始切片中將從start位置處到(但不包括)end位置處的項刪除後的切片。
4.2.4 排序和搜索切片
標準庫中的sort包提供了對整型、浮點型和字符串類型切片進行排序的函數,檢查一個切片是否排序好的函數,以及使用二分搜索算法在一個有序切片中搜索一個元素的函數。同時提供了通用的sort.Sort和sort.Search函數,可用於任何自定義的數據。這些函數在表4-2中有列出。
表4-2 sort包中的函數
正如我們在之前章節中所看到的,Go語言對數值的排序方式並不奇怪。然而,字符串的排序完全是字節排序,這點我們在前面章節中已討論過(參見3.2節)。這也意味著字符串的排序是區分大小寫的。這裡給出了一些字符串排序例子以及它們輸出的結果。
files := string{〞Test.conf〞, 〞uitl.go〞, 〞Makefile〞, 〞misc.go〞, 〞main.go〞}
fmt.Printf(〞Unsorted: %q\n〞, files)
sort.Strings(files) // 標準庫中的排序函數
fmt.Printf(〞Underlying bytes: %q\n〞, files)
SortFoldedStrings(files) // 自定義排序函數
fmt.Printf(〞Case insensitive: %q\n〞, files)
Unsorted: [〞Test.conf〞 〞util.go〞 〞Makefile〞 〞misc.go〞 〞main.go〞]
Underlying bytes:[〞Makefile〞 〞Test.conf〞 〞main.go〞 〞misc.go〞 〞util.go〞]
Case insensitive:[〞main.go〞 〞Makefile〞 〞misc.go〞 〞Test.conf〞 〞util.go〞]
標準庫中的sort.Strings函數接受一個string 切片,並將該字符串按照它們底層的字節碼在原地以升序排序。如果字符串使用的是同樣的字符到字節映射的編碼方案(例如,它們都是在本程序中創建的,或者是由其他Go程序創建的),該函數會按碼點排序。自定義的函數SortFoldedStrings功能與此類似,不同的是它使用sort包中通用的sort.Sort函數來對字符串進行大小寫無關的排序。
sort.Sort函數能夠對任意類型進行排序,只要其類型提供了sort.Interface接口中定義的方法,即只要這些類型根據相應的簽名實現了Len、Less和Swap等方法。我們創建了一個自定義類型FoldedStrings,提供了這些方法。下面是SortFoldedStrings函數、FoldedString類型以及相應方法的實現。
func SortFoldedStrings(slice string) {
sort.Sort(FoldedStrings(slice))
}
type FoldedStrings string
func (slice FoldedStrings) Len int { return len(slice) }
func (slice FoldedStrings) Less(i, j int) bool {
return strings.ToLower(slice[i]) < strings.ToLower(slice[j])
}
func (slice FoldedStrings) Swap(i, j int) {
slice[i], slice[j] = slice[j], slice[i]
}
SortFoldedStrings函數簡單地使用標準庫中的sort.Sort函數來完成工作,即使用Go語言的標準轉換語法將給定的string類型的值轉換成FoldedStrings類型的值。通常,當我們基於一個內置類型創建自定義的類型時,我們可以通過這樣的類型轉換方法將內置的類型轉換提升為自定義類型(自定義類型相關的內容將在第6章講解)。
FoldedStrings類型實現了3個方法以對應sort.Interface接口。這幾個方法都比較小巧,Less方法通過使用strings.ToLower函數來達到大小寫無關(如果我們要以逆序排序,可以簡單地將Less方法中的小於操作符 < 改成大於操作符 >)。
正如我們在前面章節(參見3.2節)中所討論的一樣,對於7位ASCII編碼(英語)的字符串而言,SortFoldedStrings函數的實現非常完美,但是對於其他非英語語言來說卻不一定能夠得到完美的排序結果。對 Unicode 編碼的字符串進行排序不是個簡單的任務,相關的詳細描述在Unicode排序算法的文檔中有解釋(unicode.org/reports/tr10)。
files := string{〞Test.conf〞, 〞util.go〞, 〞Makefile〞, 〞misc.go〞, 〞main.go〞}
target := 〞Makefile〞
for i, file := range files {
if file == target {
fmt.Printf(〞found \〞%s\〞 at files[%d]\n〞, file, i)
break
}
}
found 〞Makefile〞 at files[2]
對於無序數據來說,使用這樣的簡單的線性搜索是唯一的選擇,而這對於小切片(大至上百個元素)來說效果也不錯。但是對於大切片特別是如果我們需要進行重複搜索的話,線性搜索就會非常低效,平均每次都需要讓一半的元素相互比較。
Go提供了一個使用二分搜索算法的sort.Search方法:每次只需比較log2n個元素(其中n為切片中的元素總數)。從這個角度看,一個含1 000 000個元素的切片線性搜索平均需要500 000次比較,最壞時需要1 000 000次比較。而二分搜索即便是在最壞的情況下最多也只需要20次比較。
sort.Strings(files)
fmt.Printf(〞%q\n〞, files)
i := sort.Search(len(files),
func(i int) bool {return files[i] >= target })
if i < len(files) && files[i] == target {
fmt.Printf(〞found \〞%s\〞 at files[%d]\n〞, files[i], i)
}
[〞Makefile〞 〞Test.conf〞 〞main.go〞 〞misc.go〞 〞util.go〞]
found 〞Makefile〞 at files[0]
sort.Search函數接受兩個參數:所處理的切片的長度和一個將目標元素與有序切片的元素相比較的函數,如果該有序切片是升序排序的則使用 >= 操作符,如果逆序排序則使用 <=操作符。該函數必須是一個閉包,即它必須創建於該切片的作用域內。因為它必須將切片當成是其自身狀態的一部分。(閉包將在5.6.3節中講解。)sort.Search函數返回一個int型的值。只有當該值小於切片的長度並且在該索引位置的元素與目標元素相匹配時,我們才能夠確定找到了需要找的元素。
以下是這個函數的一個變形,它從一個不區分大小寫的有序string切片中搜索一個小寫的目標字符串。
target := 〞makefile〞
SortFoldedStrings(files)
fmt.Printf(〞%q\n〞, files)
caseInsensitiveCampare := func(i int) bool {
return strings.ToLower(files[i]) > = target
}
i := sort.Search(len(files), caseInsensitiveCampare)
if i <= len(files) && strings.EqualFold(files[i], target) {
fmt.Printf(〞found \〞%s\〞 at files[%d]\n〞, files[i], i)
}
[〞main.go〞 〞Makefile〞 〞misc.go〞 〞Test.conf〞 〞util.go〞]
found 〞Makefile〞 at files[1]
這裡我們除了調用sort.Search函數之外創建了一個比較函數。注意,與前面的例子一樣,該比較函數也必須是創建於切片作用域範圍內的閉包。我們本可以使用代碼 strings.ToLower(files[i]) == target 來做比較,但是這裡我們使用了更為方便的strings.EqualFold函數來不區分大小寫地比較字符串。
Go語言的切片是一種非常強大、方便,且功能非常方便的數據結構,難以想像會有哪個不太小的Go程序不需要用到它。我們將在本章後面看到實際的使用案例(參見4.4節)。
雖然切片足以滿足大多數數據結構的使用案例,但有些情況下我們不得不將數據保存為「鍵值」對來按鍵進行快速查找。這個功能由Go語言中的映射類型提供,也是本書下一節的主題。
4.3 映射
Go語言中的映射(map)是一種內置的數據結構,保存鍵-值對的無序集合,它的容量只受到機器內存的限制[8]。在一個映射裡所有的鍵都是唯一的而且必須是支持==和!=操作符的類型,大部分Go語言的基本類型都可以作為映射的鍵,例如,int、float64、rune、string、可比較的數組和結構體、基於這些類型的自定義類型,以及指針。Go語言的切片和不能用於比較的數組和結構體(這些類型的成員或者字段不支持==或者!=操作)或者基於這些的自定義類型則不能作為鍵。指針、引用類型或者任何內置類型的值、自定義類型都可以用做值,包括映射本身,所以它可以創建任意複雜的數據結構。表4-3列出了Go語言中映射支持的操作。
表4-3 映射的操作

因為映射屬於引用類型,所以不管一個映射保存了多少數據,傳遞都是很廉價的(在64 位機器上只需要8個字節,在32位機器上只需要4字節)。映射的查詢很快,甚至比線性搜索還快。從非正式的實驗結果來看[9],儘管映射的查找比數組或者切片裡的直接索引慢兩個數量級左右(即100倍),但在需要用到映射的地方來說,這仍然是非常快的了,實際使用中幾乎不大可能出現性能問題。圖4-5展示了一個map[string]float64類型的映射示意圖。
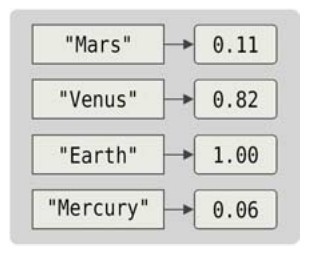
圖4-5 一個鍵為string類型、值為float64類型的映射的剖析
由於byte是一個切片,不能作為映射的鍵,但是我們可以先將byte轉換成字符串,例如string(byte),然後作為映射的鍵字段,等有需要的時候再轉換回來,這種轉換並不會改變原有切片的數據。
映射裡所有鍵的數據類型必須是相同的,值也必須如此,但鍵和值的數據類型可以不同(通常都不相同)。但是如果值的類型是接口類型,我們就可以將一個滿足這個接口定義的值作為映射的值,甚至我們可以創建一個值為空接口(interface{})的映射,這就意味著任意類型的值都可以作為這個映射的值。不過當我們需要訪問這個值的時候,需要使用類型開關和類型斷言獲得這個接口類型的實際類型,或者也可以通過類型檢視(type introspection)來獲得變量的實際類型。(接口會在第6章介紹,反射會在第9章介紹。)
映射的創建方式如下:
make(map[KeyType]ValueType, initialCapacity)
make(map[KeyType]ValueType)
map[KeyType]ValueType{}
map[KeyType]ValueType{key1: value1, key2: value2,..., keyN: valueN}
Go語言內置的make函數可用來創建切片、映射和通道。當用make來創建一個映射時,實際上得到一個空的映射,如果指定容量(initialCapacity)就會預先申請到足夠的內存,並且隨著加入的項越來越多,映射會自動擴容。第二種寫法和第三種寫法是完全一樣的,最後兩種寫法使用的是復合語法,實際編程中這是非常方便的,比如創建一個空的映射或者具有某些初始值的映射。
4.3.1 創建和填充映射
我們來創建一個映射結構,並往裡面填充一些數據,鍵為string類型,值是float64類型。
massForPlanet := make(map[string]float64) // 與map[string]float64{}相同
massForPlanet[〞Mercury〞] = 0.06
massForPlanet[〞Venus〞] = 0.82
massForPlanet[〞Earth〞] = 1.00
massForPlanet[〞Mars〞] = 0.11
fmt.Println(massForPlanet)
map[Venus:0.82 Mars:0.11 Earth:1 Mercury:0.06]
對於一些比較小的映射,我們沒必要考慮是否要指定它們的初始容量,但如果這個映射比較大,指定恰當的容量可以提高性能。通常如果你知道它的容量的話最好就指定它,即使是近似的也好。
映射和數組或切片一樣可以使用索引操作符,但和數組或切片不同的是,映射的鍵類型不必是int型的,例如我們現在用的是string類型的鍵。
我們使用了 fmt.Println函數打印映射,這個函數使用%v 格式符將映射中每項內容都以「鍵:值」的形式打印出,並且項與項之間以空格分開,因為映射裡面的項都是無序的,所以在其他機器上打印出來的結果順序可能和本書的不一樣。
之前提過,映射的鍵可以是一個指針,我們下面將會看到一個例子,它的鍵的類型是*Point,Point定義如下:
type Point struct{ x, y, z int }
func (point Point) String string {
return fmt.Sprintf(〞(%d,%d,%d)〞, point.x, point.y, point.z)
}
Point類型裡有了3個int類型的變量,還有一個String的方法,這樣就確保了當我們打印一個*Point時Go語言會調用它的String方法而不是簡單地輸出Point的內存地址。
順便說一句,我們可以使用%p格式符來強制Go語言打印出內存地址,格式符此前介紹過(參見3.5.6節)。
triangle := make(map[*Point]string, 3)
triangle[&Point{89, 47, 27}] = 〞α〞
triangle[&Point{86, 65, 86}] = 〞β〞
triangle[&Point{7, 44, 45}] = 〞γ〞
fmt.Println(triangle)
map[(7,44,45):γ (89,47,27):α (86,65,86):β]
這裡我們創建了一個初始存儲大小為3的映射,然後往裡添加指針類型的鍵和字符串值。使用復合語法創建每個 Point 值,然後用&操作符取得指針作為鍵,這樣鍵就是一個*Point指針而不是一個Point類型的值。因為Point實現了String方法,所以打印映射的時候我們能以可讀的方式看到 *Point的值。
使用指針作為映射的鍵意味著我們可以增加兩個相同的內容,只要分別創建它們就可以獲得不同的地址。但如果我們希望這個映射對任何實際上相同的內容只存儲一個的話會怎麼樣呢?這也是很容易的,只要我們存儲Point的值而不是指向Point的指針即可,要知道,Go語言允許將一個結構體作為映射的鍵,只要它們所有的字段都支持==和!=運算即可。下面是一個例子。
nameForPoint := make(map[Point]string) // 等同於: map[Point]string{}
nameForPoint[Point{54, 91, 78}] = 〞x〞
nameForPoint[Point{54, 158, 89}] = 〞y〞
fmt.Println(nameForPoint)
map[(54,91,78):x (54,158,89):y]
nameForPoint的每一個鍵都是唯一的Point結構,我們可以在任何時候改變它所映射的字符串。
populationForCity := map[string]int{〞Istanbul〞: 12610000,
〞Karachi〞: 10620000, 〞Mumbai〞: 12690000, 〞Shanghai〞: 13680000}
for city, population := range populationForCity {
fmt.Printf(〞%-10s %8d\n〞, city, population)
}
Shanghai 13680000
Mumbai 12690000
Istanbul 12610000
Karachi 10620000
這是我們這一節最後的例子了,同樣,我們使用復合語法創建了整個映射結構。當用一個for...range 循環來遍歷映射的時候,對於映射中的每一項都返回兩個變量鍵和值,直到遍歷完所有的鍵/值對或者循環被打破。如果只關心其中一個變量的話,因為映射裡的項都是無序的,我們並不知道每次迭代實際返回的是哪一個,更多的時候我們只是獲得所有遍歷出來的項並更新它們,所以遍歷出來的次序不重要。但是,如果我們想按照某種方式來遍歷,如按鍵序,這也不難,很快我們就可以看到了(見4.3.4節)。
4.3.2 映射查詢
Go語言提供了兩種類似的語法用於映射查詢,兩種方式都是使用操作符。下面是一種最簡單的方法。
population := populationForCity[〞Mumbai〞]
fmt.Println(〞Mumbai's population is〞, population)
population = populationForCity[〞Emerald City〞]
fmt.Println(〞Emerald City's population is〞, population)
Mumbai's population is 12690000
Emerald City's population is 0
如果我們查詢的鍵出現在映射裡面,那就返回它對應的值,如果這個鍵並沒有在映射裡,就會返回一個 0 值,但是 0 值也有可能是因為這個鍵不存在,所以這裡我們不能簡單地認為「Emerald City」這個城市的人口數就是0,或者說這個城市並不在這個映射中。Go語言還有一種語法解決了這個問題。
city := 〞Istanbul〞
if population, found := populationForCity[city]; found {
fmt.Printf(〞%s's population is %d\n〞, city, population)
} else {
fmt.Printf(〞%s's population data is unavailable\n〞, city)
}
city = 〞Emerald City〞
_, present := populationForCity[city]
fmt.Printf(〞%q is in the map == %t\n〞, city, present)
Istanbul's population is 12610000
〞Emerald City〞 is in the map == false
當我們使用索引操作符來查找映射中的鍵的時候,我們指定兩個返回變量,第一個用來獲得鍵對應的值(如果鍵不存在的話會返回0值),第二個變量是一個布爾類型(鍵存在則為true,否則為false),這樣我們就可以知道這個鍵是否真的在映射裡。像上述代碼裡面的第二個查詢一樣,如果我們只是關心某個鍵是否存在的話可以使用空變量(一個下劃線)來接受值。
4.3.3 修改映射
我們可以往映射裡插入或者刪除一項,所謂項(item),也就是一個「鍵/值」對,任何一項的值都可以修改,如下。
fmt.Println(len(populationForCity), populationForCity)
delete(populationForCity, 〞Shanghai〞) // 刪除
fmt.Println(len(populationForCity), populationForCity)
populationForCity[〞Karachi〞] = 11620000 // 更新
fmt.Println(len(populationForCity), populationForCity)
populationForCity[〞Beijing〞] = 11290000 // 插入
fmt.Println(len(populationForCity), populationForCity)
4 map[Shanghai:13680000 Mumbai:12690000 Istanbul:12610000 Karachi:10620000]
3 map[Mumbai:12690000 Istanbul:12610000 Karachi:10620000]
3 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000]
4 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000 Beijing:11290000]
插入和更新一個項的語法是完全一樣的,如果給定一個鍵對應的項不存在,那麼映射默認會創建一個新的項來保存這個「鍵/值」對,否則,就將這個鍵原來的值設置成新的值。如果我們嘗試去刪除映射裡一個不存在的項,Go語言並不會做任何不安全的事情。
對於鍵不能用同樣的方式修改,但可以用如下這種效果相同的做法:
oldKey, newKey := 〞Beijing〞, 〞Tokyo〞
value := populationForCity[oldKey]
delete(populationForCity, oldKey)
populationForCity[newKey] = value
fmt.Println(len(populationForCity), populationForCity)
4 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000 Tokyo:11290000]
我們先得到鍵的值,然後刪除這個鍵對應的項,接著創建一個新的項用來保存新的鍵和原來的值。
4.3.4 鍵序遍歷映射
當使用數據時,我們通常需要按照某種被認可的方式將這些數據顯示出來,下面的例子展示了如何按字典序(嚴格來說,是Unicode碼點的順序)顯示populationForCity裡的城市數據。
cities := make(string, 0, len(populationForCity))
for city := range populationForCity {
cities = append(cities, city)
}
sort.Strings(cities)
for _, city := range cities {
fmt.Printf(〞%-10s %8d\n〞, city, populationForCity[city])
}
Beijing 11290000
Istanbul 12610000
Karachi 11620000
Mumbai 12690000
首先我們創建一個類型為string的切片,Go語言會默認將其初始化為0值,但設置了足夠大的容量去保存映射裡的鍵。然後將我們遍歷映射得到的所有鍵(因為我們現在只會用到一個變量city,所以不需要得到完整的一個「鍵/值」對)追加到這個切片cities裡去。下一步,對cities排序,再遍歷cities(使用空變量忽略int型的索引),查詢每個city對應的城市人口數量。
這個算法的思想是,創建一個足夠大的切片去保存映射裡所有的鍵,然後對切片排序,遍歷切片得到鍵,再從映射裡得到這個鍵的值,這樣就可以實現順序輸出了。一般希望按鍵序來遍歷一個映射都可以這樣做。
另一種方法就是使用有序的數據結構,例如一個有序映射,我們在後面的章節會介紹一個例子(6.5.3節)。
按值排序也是可以的,例如將一個映射反轉,下一節將提到這個方法。
4.3.5 映射反轉
如果一個映射的值都是唯一的,且值的類型也是映射所支持的鍵類型的話,我們就可以很容易地將它反轉。
cityForPopulation := make(map[int]string, len(populationForCity))
for city, population := range populationForCity {
cityForPopulation[population] = city
}
fmt.Println(cityForPopulation)
map[12610000:Istanbul 11290000:Beijing 12690000:Mumbai 11620000:Karachi]
因為 populationForCity 是 map[string]int 類型的,所以我們創建一個map[int]string類型的cityForPopulation。然後遍歷populationForCity,並將得到的鍵和值反轉,插入 cityForPopulation 裡去,也就是說,原先的值將作為鍵,而原先的鍵則作為現在的值。
當然,如果原來映射的值不是唯一,反轉就會失敗,實質上只有最後一個不唯一的值對應的鍵被保存。可以通過創建一個多值的映射來解決這個問題,如在我們這個例子裡,反轉後的映射的類型是map[int]string(鍵是int類型的,值是string),很快我們就可以看到一個實際的例子(參見4.4.2節)。
4.4 例子
這一節我們來看兩個小例子,第一個是關於一維或者二維切片的,第二個主要是映射,包括當映射的值不唯一時如何反轉,也涉及切片和排序。
4.4.1 猜測分隔符
有時候我們可能收到很多數據文件需要去處理,每個文件每一行就是一條記錄,但是不同的文件可能使用不同的分隔符(例如,可能是製表符、空白符或者「*」等)。為了能夠大批量地處理這些文件我們必須能夠判斷每個文件所用的分隔符,這一節展示的guess_separator 例子(在文件guess_separator/guess_separator.go裡)嘗試去判斷所有給定文件的分隔符。
運行示例如下:
$./guess_separator information.dat
tab-separated
程序從給定文件裡讀取前 5 行(如果文件行數小於 5 則全讀取進來),然後分析所用的分隔符。我們從main函數以及它所調用的函數開始分析(除去例程),import部分略過。
func main {
if len(os.Args) == 1 || os.Args[1] == 〞-h〞 || os.Args[1] == 〞--help〞 {
fmt.Printf(〞usage: %s file\n〞, filepath.Base(os.Args[0]))
os.Exit(1)
}
separators := string{〞\t〞, 〞*〞, 〞|〞, 〞‧〞}
linesRead, lines := readUpToNLines(os.Args[1], 5)
counts := createCounts(lines, separators, linesRead)
separator := guessSep(counts, separators, linesRead)
report(separator)
}
main函數首先檢查命令行是否指定了文件,如果一個都沒有,就打印一條幫助消息然後退出程序。我們創建了一個string切片來保存我們感興趣的分隔符列表。按照慣例,對於使用空白分隔符的文件,我們當成是「」來處理(空字符串)。
第一步數據處理是從文件中讀取前5行內容。這裡沒有顯示readUpNLines函數的代碼,因為我們之前就有幾個這樣從文件中讀取行的例子。和之前例子不同的是,readUpToNLines函數只是讀取一定數量的行,如果文件實際的行數比指定的小,那就全讀,最後返回實際讀取了的行數及每行的數據。
然後就是createCounts函數,代碼如下。
func createCounts(lines, separators string, linesRead int) int {
counts := make(int, len(separators))
for sepIndex := range separators {
counts[sepIndex] = make(int, linesRead)
for lineIndex, line := range lines {
counts[sepIndex][lineIndex] =
strings.Count(line, separators[sepIndex])
}
}
return counts
}
createCounts的目的就是計算出一個保存了每一個分隔符在每行出現的次數的矩陣。
函數首先創建一個int 類型的二維切片 counts,大小和main 函數里的separators一樣。如果有4個分隔符,那麼counts的值是[nil nil nil nil],外圍的for循環將每一個nil替換成int,用來保存每個分隔符在每一行出現的次數,所以每一個nil都被替換成了[0 0 0 0 0],注意Go語言默認總是將一個值初始化為0值。
內部的for循環是用來計算counts矩陣的。每一行裡每一個分隔符出現的次數都會被統計下來並相應地更新 counts的值,strings.Count函數返回它的第二個參數指定的字符串在第一個參數指定的字符串裡出現的次數。
例如,對於一個使用製表符分隔的文件,其中某些字段包含圓點符號、空格和星號,我們可能得到這樣一個counts矩陣:[[3 3 3 3 3] [0 0 4 3 0] [0 0 0 0] [1 2 2 0 0]]。counts裡的每一項都是int類型的切片,保存了每一個分隔符(製表符、星號、豎槓、圓點)在每一行裡出現的次數。從這個數字看來每一行裡都出現了3個製表符,有兩行出現星號(一行3個,一行4個),有3行出現圓點,沒有一行出現豎槓。對我們來說很明顯製表符是分隔符,當然程序必須得自己發現這個,它是用guessSep函數來完成這個功能的。
func guessSep(counts int, separators string, linesRead int) string {
for sepIndex := range separators {
same := true
count := counts[sepIndex][0]
for lineIndex := 1; lineIndex < linesRead; lineIndex++ {
if counts[sepIndex][lineIndex] != count {
same = false
break
}
}
if count > 0 && same {
return separators[sepIndex]
}
}
return 〞〞
}
guessSep是這樣處理的:如果某個分隔符在每一行出現的次數都是相同的(但不能是0值),就認為文件使用的就是這個分隔符。外部的for循環檢查每一個分隔符,內部for循環檢查分隔符在每行出現的次數。same變量初始化為true,默認是假設當前分隔符在每行出現的次數都是一樣的,count為當前分隔符在第一行出現的次數。然後內循環開始,如果發現有一行的次數和count不一樣,same的值變為false,內循環退出,然後嘗試下一個分隔符。如果內循環沒有將false賦值給same變量,而且count的值大於0,就表示已經找到我們想要的分隔符了,並立即返回它。最後如果沒有找到分隔符,返回一個空的字符串,也就是說所有的行都是以空白符分隔的,或者完全沒有分隔。
func report(separator string) {
switch separator {
case 〞〞:
fmt.Println(〞whitespace-separated or not separated at all〞)
case 〞\t〞:
fmt.Println(〞tab-separated〞)
default:
fmt.Printf(〞%s-separated\n〞, separator)
}
}
report這個函數不怎麼重要,只是顯示文件所用的分隔符是什麼。
我們從這個例子瞭解到兩種切片的典型用法,一維的和二維的(separators、lines, 還有counts),下一個例子我們將會看到映射、切片還有排序。
4.4.2 詞頻統計
文本分析的應用很廣泛,從數據挖掘到語言學習本身。這一節我們來分析一個例子,它是文本分析最基本的一種形式:統計出一個文件裡單詞出現的頻度。
頻度統計後的結果可以以兩種不同的方式顯示,一種是將單詞按照字母順序把單詞和頻度排列出來,另一種是將頻度按照有序列表的方式把頻度和對應的單詞顯示出來。wordfrequency 程序(在文件wordfrequency/wordfrequency.go裡)生成兩種輸出,如下所示。
$./wordfrequency small-file.txt
Word Frequency
ability 1
about 1
above 3
...
years 1
you 128
Frequency→Words
1 ability, about, absence, absolute, absolutely, abuse, accessible,...
2 accept, acquired, after, against, applies, arrange, assumptions,...
...
128 you
151 or
192 to
221 of
345 the
即使是很小的文件,單詞的數量和不同頻度的數量都可能會非常大,篇幅有限,我們只顯示部分結果。
第一種輸出是比較直接的,我們可以使用一個map[string]int類型的結構來保存每一個單詞的頻度。但是要得到第二種輸出結果我們需要將整個映射進行反轉,但這並不是那麼容易,因為很可能具有相同的頻度的單詞不止一個,解決的方法就是反轉成多值類型的映射,如map[int]string,也就是說,鍵是頻度而值則是所有具有這個頻度的單詞。
我們將從程序的main函數開始,從上到下分析,和通常一樣,忽略掉import部分。
func main {
if len(os.Args) == 1 || os.Args[1] == 〞-h〞 || os.Args[1] == 〞--help〞 {
fmt.Printf(〞usage: %s <file1> [<file2> [...<fileN>]]\n〞,
filepath.Base(os.Args[0]))
os.Exit(1)
}
frequencyForWord := map[string]int{} // 與make(map[string]int)相同
for _, filename := range commandLineFiles(os.Args[1:]) {
updateFrequencies(filename, frequencyForWord)
}
reportByWords(frequencyForWord)
wordsForFrequency := invertStringIntMap(frequencyForWord)
reportByFrequency(wordsForFrequency)
}
main函數首先分析命令行參數,之後再進行相應處理。
我們使用復合語法創建一個空的映射,用來保存從文件讀到的每一個單詞和對應的頻度。接著我們遍歷從命令行得到的每一個文件,分析每一個文件後更新frequencyForWord的數據。
得到第一個映射之後,我們就輸出第一個報告:一個按照字母表順序排序的單詞列表和對應的出現頻率。然後我們創建一個反轉的映射,輸出第二個報告:一個排序的出現頻率列表和對應的單詞。
func commandLineFiles(files string) string {
if runtime.GOOS == 〞windows〞 {
args := make(string, 0, len(files))
for _, name := range files {
if matches, err := filepath.Glob(name); err != nil {
args = append(args, name) // 無效模式
} else if matches != nil { // 至少有一個匹配
args = append(args, matches...)
}
}
return args
}
return files
}
因為在Unix類系統(如Linux或Mac OS X等)的shell默認會自動處理通配符(也就是說,*.txt能匹配任意後綴為.txt的文件,如README.txt和INSTALL.txt等),而Windows平台的shell程序(cmd.exe)不支持通配符,所以如果用戶在命令行輸入,如 *.txt,那麼程序只能接收到 *.txt。為了保持平台之間的一致性,我們使用commandLineFiles函數來實現跨平台的處理,當程序運行在Windows平台時,我們自己把文件名通配功能給實現了。(另一種跨平台的辦法就是不同的平台使用不同的.go文件,這在9.1.1.1節有描述。)
func updateFrequencies(filename string, frequencyForWord map[string]int) {
var file *os.File
var err error
if file, err = os.Open(filename); err != nil {
log.Println(〞failed to open the file: 〞, err)
return
}
defer file.Close
readAndUpdateFrequencies(bufio.NewReader(file), frequencyForWord)
}
updateFrequencies 函數純粹就是用來處理文件的。它打開給定的文件,並使用defer讓函數返回時關閉文件句柄。這裡我們將文件作為一個*bufio.Reader(使用bufio.NewReader函數創建)傳給readAndUpdateFrequencies函數,因為這個函數是以字符串的形式一行一行地讀取數據的而不是讀取字節流。可見,實際的工作都是在readAndUpdate Frequencies函數里完成的,代碼如下。
func readAndUpdateFrequencies(reader *bufio.Reader, frequencyForWord map[string]int) {
for {
line, err := reader.ReadString('\n')
for _, word := range SplitOnNonLetters(strings.TrimSpace(line)) {
if len(word) > utf8.UTFMax || utf8.RuneCountInString(word) > 1 {
frequencyForWord[strings.ToLower(word)] += 1
}
}
if err != nil {
if err != io.EOF {
log.Println(〞failed to finish reading the file: 〞, err)
}
break
}
}
}
第一部分的代碼我們應該很熟悉了。我們用了一個無限循環來一行一行地讀一個文件,當讀到文件結尾或者出現錯誤(這種情況下我們將錯誤報告給用戶)的時候就退出循環,但我們並不退出程序,因為還有很多其他的文件需要去處理,我們希望做盡可能多的工作和報告我們捕獲到的任何問題,而不是將工作結束在第一個錯誤上面。
內循環就是處理結束的地方,也是我們最感興趣的。任意一行都可能包括標點、數字、符號或者其他非單詞字符,所以我們逐個單詞地去讀,將每一行分隔成單詞並使用SplitOnNonLetters函數忽略掉非單詞的字符。而且我們一開始就過濾掉字符串開頭和結束處的空白。
如果我們只關心至少兩個字母的單詞,最簡單的辦法就是使用只有一條語句的if 語句,也就是說,如果utf8.RuneCountInString(word)> 1,那這就是我們想要的。
剛才描述的那個簡單的if 語句可能有一點性能損耗,因為它會分析整個單詞。所以在這個程序裡我們用了一個兩個分句的if 語句,第一個分句用了一個非常高效的方法,它檢查這個單詞的字節數是否大於utf8.UTFMax(它是一個常量,值為4,用來表示一個UTF-8字符最多需要幾個字節)。這是最快的測試方法,因為Go語言的strings知道它們包含了多少個字節,還有Go語言的二進制布爾操作符號總是走捷徑的(2.2節)。當然,由4個或者更少字節組成的單詞(例如7位的ASCII碼字符或者一對2個字節的UTF-8字符)在第一次檢查時可能失敗,不過這不是問題,還有第二次檢查(rune的個數)也很快,因為它通常只有 4 個或者不到4 個字符需要去統計。在我們這個情況裡需要用到兩個分句的if語句嗎?這就取決於輸入了,越多的字符需要的處理時間就越長,就有更多可能優化的地方。唯一可以明確知道的辦法就是使用真實或者典型的數據集來做基準測試。
func SplitOnNonLetters(s string) string {
notALetter := func(char rune) bool { return !unicode.IsLetter(char) }
return strings.FieldsFunc(s, notALetter)
}
這個函數在非單詞字符上對一個字符串進行切分。首先我們為 strings.FieldsFunc函數創建一個匿名函數notALetter,如果傳入的是字符那就返回false,否則返回true。然後我們返回調用函數strings.FieldsFunc的結果,調用的時候將給定的字符串和notALetter作為它的參數。(我們在之前在3.6.1節裡討論過strings.FieldsFunc函數。)
func reportByWords(frequencyForWord map[string]int) {
words := make(string, 0, len(frequencyForWord))
wordWidth, frequencyWidth := 0, 0
for word, frequency := range frequencyForWord {
words = append(words, word)
if width := utf8.RuneCountInString(word); width > wordWidth {
wordWidth = width
}
if width := len(fmt.Sprint(frequency)); width > frequencyWidth {
frequencyWidth = width
}
}
sort.Strings(words)
gap := wordWidth + frequencyWidth - len(〞Word〞) - len(〞Frequency〞)
fmt.Printf(〞Word %*s%s\n〞, gap, 〞 〞, 〞Frequency〞)
for _, word := range words {
fmt.Printf(〞%-*s %*d\n〞, wordWidth, word, frequencyWidth,
frequencyForWord[word])
}
}
一旦計算出了frequencyForWord,就調用reportByWords將它的數據打印出來。因為我們希望輸出結果是按照字母順序排列的(實際上是按照Unicode碼點順序),所以我們首先創建一個空的容量足夠大的string切片來保存所有在frequencyForWord裡的單詞,同樣我們希望能知道最長的單詞和最高的頻度的字符寬度(比如說,頻度有多少個數字),所以我們可以以整齊的方式輸出我們的結果,用wordWidth和frequencyWidth來記錄這兩個結果。