
考慮數據如何存儲在程序中時,可以用圖直觀地表示,這很有用。
變量有一個值。

列表就像是把一行值串在一起。

有時還需要一個包含行和列的表。
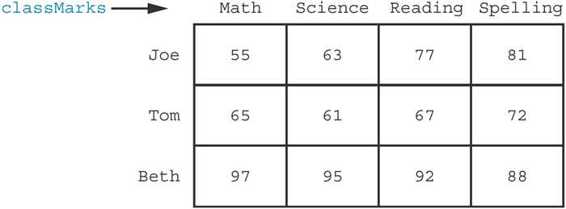
如何保存數據表呢?我們已經知道,列表中包含多個元素,可以把每個學生的成績放在一個列表中,像這樣:
>>> joeMarks = [55, 63, 77, 81]>>> tomMarks = [65, 61, 67, 72]>>> bethMarks = [97, 95, 92, 88] 或者對應每個課程使用一個列表,如下:
>>> mathMarks = [55, 65, 97]>>> scienceMarks = [63, 61, 95]>>> readingMarks = [77, 67, 92]>>> spellingMarks = [81, 72, 88] 不過我們可能希望把所有數據都收集到一個數據結構中。
術語箱
數據結構(data structure)是一種在程序中收集、存儲或表示數據的方法。數據結構包括變量、列表和其他一些我們還沒有討論到的內容。實際上,數據結構這個詞就表示程序中數據的組織方式。
要為我們的成績建立一個數據結構,可以這樣做:
>>> classMarks = [joeMarks, tomMarks, bethMarks]>>> print classMarks[[55, 63, 77, 81], [65, 61, 67, 72], [97, 95, 92, 88]] 這會得到一個元素列表,其中每個元素本身又是一個列表。我們創建了一個「列表的列表」(list of list),也就是雙重列表。classMarks 列表中的每個元素本身又都是一個列表。
還可以直接創建 classMarks,而不需要先創建 joeMarks、tomMarks 和 bethMarks,如下:
>>> classMarks = [ [55,63,77,81], [65,61,67,72], [97,95,92,88] ]>>> print classMarks[[55, 63, 77, 81], [65, 61, 67, 72], [97, 95, 92, 88]] 現在來顯示我們的數據結構:classMarks 有 3 個元素,每個元素分別對應一個學生。所以可以使用 in 來循環處理:
>>> for studentMarks in classMarks:print studentMarks[55, 63, 77, 81][65, 61, 67, 72][97, 95, 92, 88] 這裡我們對名為 classMarks 的列表完成循環處理。循環變量是 studentMarks。每次循環時,會打印列表中的一個元素。這裡的每一個元素分別是一個學生的成績,它本身也是一個列表。(前面創建過這些學生列表。)
可以注意到,這看上去與前一頁的表很類似,所以我們提出的這種數據結構可以把所有數據都保存在一個地方。
從表獲取一個值
怎麼得到這個表(也就是雙重列表)中的值呢?我們已經知道,第一個學生的成績(joeMarks)在一個列表中,而這個列表本身是 classMarks 中的第一個元素。
下面來檢查一下:
>>> print classMarks[0][55, 63, 77, 81] classMarks[0] 是 Joe 的 4 門課程成績的一個列表。現在我們想從 classMarks[0] 得到一個值。怎麼做呢?可以使用第二個索引。
如果希望得到他的第三個成績(閱讀課成績),也就是索引 2,可以這樣做:
>>> print classMarks[0][2]77 這會給出 classMarks 中的第一個元素(索引 0),也就是 Joe 的成績列表,以及這個列表中的第三個元素(索引 2),這正是他的閱讀課成績。看到一個名字後面帶著兩組中括號時,比如說 classMarks[0][2],這往往表示一個雙重列表。

classMarks 列表並不知道 Joe、Tom 和 Beth 這些名字,也不知道數學(Math)、科學(Science)、閱讀(Reading)和拼寫(Spelling)這些課程。這裡之所以這樣標,是因為我們知道想要在這個列表中儲存什麼信息。不過,對於 Python 來說,它們只是列表中一些已經編號的位置而已。這就像郵局裡編號的郵箱。郵箱上沒有名字,只有編號。郵遞員只負責明確哪封信歸哪個郵箱,而你知道哪個郵箱是你的。

要對 classMarks 表加標籤,一種更準確的方法應該是這樣:
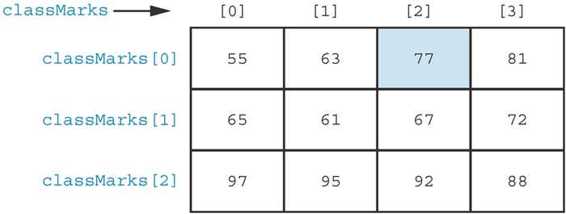
現在可以更容易地看出成績 77 存儲在 classMarks[0][2] 中。
如果編寫一個程序使用 classMarks 存儲我們的數據,就必須知道哪些數據存儲在哪一行哪一列。就像郵遞員一樣,我們的任務是明確哪個位置屬於哪個數據。