
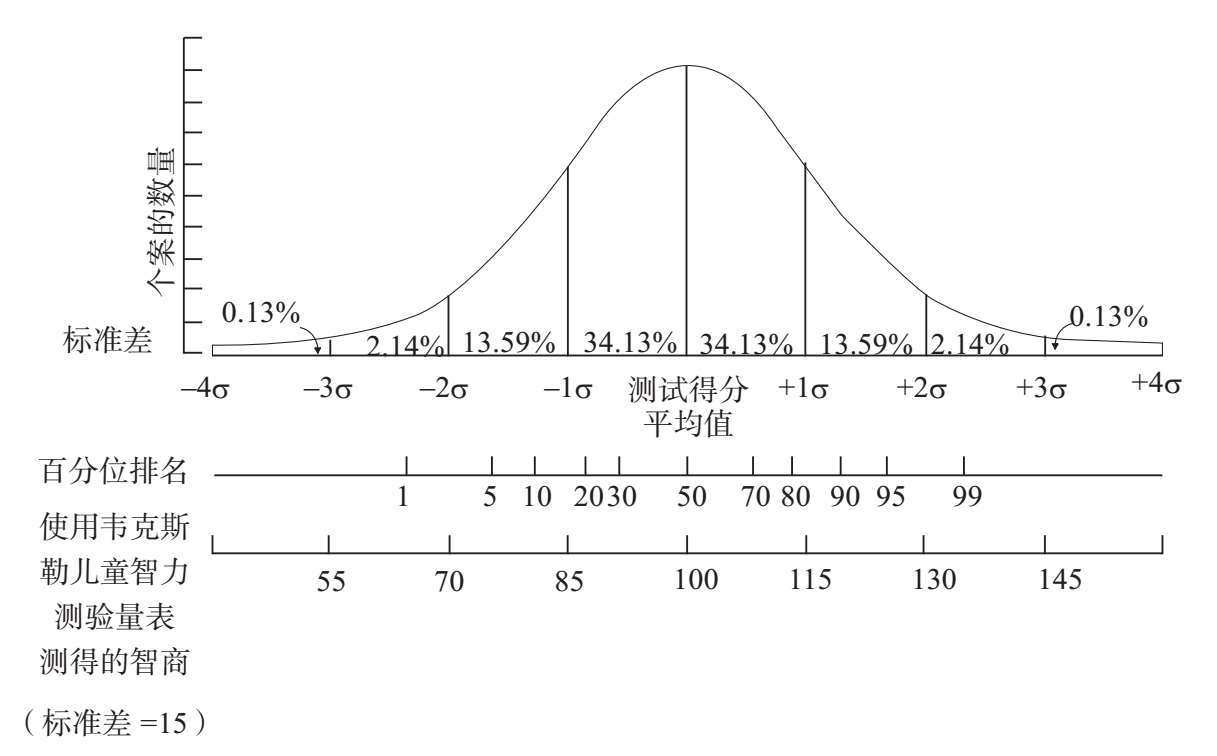
我們經過研究發現,各種各樣的現象都呈正態分佈,就像圖A–1中顯示的那種鍾形曲線。例如,如果我們要畫圖顯示不同母雞每週產蛋的數量,生產某型號汽車的過程中出現錯誤的數量,或者一群人的智力測試分數,代表這些數據的曲線的形狀大體上都接近鍾形。我們無須瞭解這些分佈呈現鍾形背後的數學原理。重要的是正態分佈曲線用處很大,能夠幫助我們找出一個觀測值與另一個觀測值之間的聯繫。圖A–1中顯示的正態分佈曲線按照標準差——用「標準差」來代表平均分與平均值的偏離程度——分為幾段。如果觀測值的數量足夠多,正態分佈的曲線就無限接近鍾形,也就是非常標準的正態分佈。在標準的正態分佈中,大約68%的觀測值都分佈在偏離平均值(也就是圖A–1中的曲線上0的位置)+1或–1個標準差的範圍內。標準差的概念還有一些用處,那就是百分位排名與標準差的關係。在所有的觀測值中,大約84%的數據都集中在+1個標準差或少於+1個標準差的範圍內;超出平均值+1個標準差的觀測值在整個分佈中對應的百分位排名就是第84位。幾乎98%的觀測值都集中在+2個標準差的範圍內。正好超出平均值+2個標準差的觀測值在整個分佈中對應的百分位排名就是第98位,剩下的2%觀測值對應的百分位排名則高於第98位。幾乎所有的觀測值都位於+3或–3個標準差的範圍內。按照慣例,大多數智力測試都將智商的標準差設定為15分(平均智商設定為100分)。
圖A–1 正態分佈曲線
標準差這一單位非常有用,我們可以用標準差來表示效果值的大小。例如,一項新的教學方法改善學習效果的程度就可以用標準差來表示。最常用的效果值的指標叫作Cohen』s d,是這樣計算的:A組的平均值減去B組的平均值再除以A、B兩組的標準差之和(或者有時候只除以A組的標準差)。
按照慣例,d的值為0.2或更小就被視為效果甚微。這相當於將實驗組分數的百分位排名從第50位提高到將近第60位。如果新的教學方法(百分位排名第60位)和老的教學方法(百分位排名第50位)相比能夠使孩子的成績排名提前10名,你或許並不認為這是很小的效果。你是否願意付錢使用新的教學方法,一部分也取決於百分位排名從第50位上升到第60位究竟具有多麼重要的意義。如果你用孩子盲打的速度達到每分鐘40字的熟練程度所需要的時間來衡量教學的效果,只需要幾天的時間就可以將百分位排名從第50位提高到第60位,很可能你就不願意為這樣的進步花費太多的錢,也不願意學校在上面花費太多。如果你根據SAT數學考試的平均成績來衡量兩所高中採用的數學教學方法的效果,採用一種教學方法後數學考試的平均成績是500分,而採用另一種教學方法的平均成績是520分,這就是百分位排名第50位與第60位之間的差距(假設SAT分數的標準差是100)。你或許願意為了孩子的分數得到這樣的提高而不惜花上大筆錢財。或許你還樂意你們的教育委員會為每位學生花上一些錢,以採取更有效的教學方法。
按照慣例,d的值為0.5左右被視為是一般的效果。不過,在智力測試和學業成就的概念裡,這麼大的效果值一般已經相當引人注目了,這相當於SAT數學部分的分數從500分提高到550分——有時這樣的差距就是考取中上水平的大學和考取名牌大學的差距。為了使普通孩子的SAT數學成績百分位排名從第50位提高到大約第70位(這就是0.5個標準差對應的效果值),你和學校或許願意花大價錢採用新的教學方法。
0.7~1個標準差被認為是很大的效果。1個標準差對於教育和智力的差距來說是非常大的。一般認為黑人與白人的智商差距就接近1個標準差。在第6章中,我們討論了黑人與白人的實際差距是否有如此之大。如果有,那就意味著黑人的平均智商在白人的智商分佈上對應的百分位排名是第16位。如果一項干預措施能夠使孩子在全國數學考試中的百分位排名從第50位提高到第84位,那麼人們一定認為在這項干預措施上花一大筆錢是值得的。對於一個國家來說,如果數學成績取得了這樣的進步從而使國家的競爭力有所增強,那麼國家就應該不惜成本地大力普及這項干預措施。
相關係數可以用來測量兩個變量之間線性聯繫的程度。例如,智商與學習成績之間的相關度恰好是0.5左右,也就是說兩者的聯繫較強。不過智商與學習成績之間至少應該具備相當的關聯度,因為設計智力測試就是為了預測人們在學校內的學習成績。相關係數的變化範圍是–1到+1之間,–1表示兩個變量完全成反比,+1表示兩個變量完全成正比。相關係數為0就意味著兩個變量之間沒有任何聯繫。相關係數也可以用來衡量效果值的大小,或者關聯度的大小。相關係數的數值小於0.3就是較小的相關度,0.3~0.5就是中等大小的相關度,在0.5以上就是較大的相關度。但是,和效果值一樣,關聯度是否重要取決於關聯度中的變量,而不是相關度的大小。我們也可以用標準差的概念來解釋相關係數。如果兩個變量的相關度是0.25,那麼第一個變量增加1個標準差,第二個變量就會增加0.25個標準差;如果相關度是0.5,那麼第二個變量就會增加0.5個標準差。如果班級的規模與學生在標準化考試中的成績之間的相關度是–0.25,那麼班級規模縮小1個標準差,學生的考試成績就應該提高0.25個標準差(假設班級規模與考試成績之間確實存在因果關係)。
多元回歸是一種分析方法,它能夠找出一些因變量(或預測變量)與結果變量(或某個目標變量)之間的關係。例如,我們或許想要比較哪些變量能夠最大限度地預測一所房子在房地產市場上的吸引力。我們可能會衡量房屋的面積有多少平方米,有幾間臥室,衛生間的舒適程度(例如水池的數量、是否能洗熱水澡、使用的材料質量好壞等),小區的平均收入,以及由潛在買主的數量代表的房屋的搶手程度。然後我們將這些變量同時與房屋在市場上的吸引力聯繫在一起,也就是房屋在市場上的售價——目標變量。不考慮所有其他變量對房屋價值的貢獻度(即將所有其他變量設為常數)的條件下,找出某個變量與市場價值之間相關度的大小,就可以估計出這個變量對於房屋市場價值的貢獻度。因此,當將所有其他變量設為常數時,房屋的搶手程度與市場價值之間的相關度可能是0.25,衛生間的舒適程度與市場價值之間的相關度可能是0.1。不過所有這些變量之間都存在一定的相關度,並且對某些變量的測量可能比其他變量更為準確,某些變量可能與其他一些變量存在一定的因果關係,而與另一些變量不存在因果關係,有些沒有測量的變量或許會對一些得到測量的變量產生一定的影響。這就導致多元回歸的結果有可能對我們產生誤導。房屋的搶手程度與市場價值之間的實際相關度,可能遠遠高於多元回歸分析得出的0.25,也可能遠遠低於0.25。
有無數個例子能夠說明,多元回歸分析得出的因果關係,往往與實驗得出的因果關係不一致。從因果推論的角度來看,這些實驗幾乎都比多元回歸分析更加可取。例如,大概在15年前,我曾經參加過全美衛生研究院召開的共識發展會議。這次會議的目的就是要重新審視關於冠狀動脈阻滯的治療方法的研究,究竟是臨床治療還是手術治療效果更好,並就這兩種治療方法的適當性達成共識。要審查的研究中有大量研究都是由政府資助的,耗資巨大。在這些研究中,研究人員將大量和患者有關的變量放入一個多元回歸方程式中,例如病史、年齡以及社會經濟地位等,然後在不考慮不同患者使用的其他治療方法的情況下,確定某種治療方法的療效。但是由於美國管理研究政策的內部審查委員會要求,必須給予患者選擇治療方法的自由(不過我們並不能確定這樣做實際上是否真的符合患者的利益),所以所有的實驗證據都因為帶有自我選擇的人為因素而動搖了。不過除了美國的研究以外,還有兩項歐洲的研究,都達到了隨機為患者安排各種治療方法的標準。因此,專門小組的成員放棄了耗資巨大的美國研究,只對兩項歐洲研究的結果進行了分析。
讓我們再考慮一個與本書更為相關的例子,那就是班級規模是否真的會影響學習成績。多元回歸分析告訴我們,不考慮學校的規模、學校所在社區全部家庭的平均收入、教師的薪酬、具備資格的教師的比例,以及學區內每名學生的教育支出等因素,規模一般的班級與學生的學習成績之間沒有聯繫。在另外一項隨機選取研究對象並實施得很好的研究中,進行比較的班級學生人數相差很多(將有13~17名學生的班級與有22~25名學生的班級進行比較)。結果這項研究發現,將班級人數縮減至13~17人,學生們在標準化考試中的成績提高了0.25個標準差以上——這對黑人孩子起到的作用也大於白人孩子(1999年)。這不僅僅是另外一項有關班級規模的影響的研究,它還取代了所有有關班級規模的多元回歸研究。
在本書中我偶爾會提到多元回歸研究,不過每次都會提醒大家注意研究的結果。
自我選擇是相關性研究和多元回歸分析面臨的難題之一。有很多原因要求我們必須要對自我選擇有所瞭解。如果我們說智力與未來的職業成就之間具有一定的相關度——比如0.4,那麼大家往往就會條件反射地認為,這樣的關係完全是因果關係——智商更高的人工作能力也更強。但是智力與其他因素也是相關的,例如智商較高的孩子通常其父母的社會經濟地位也較高。如果父母的社會經濟地位較高,那麼不論這個孩子智商高低,都更有可能念大學。同樣,不論這個孩子的智商高低,擁有大學學歷就有可能獲得更高的職業地位。因此,智力與職業成就之間的關聯就受到了其他因素的影響,例如父母的社會經濟地位以及大學學歷,那麼這個孩子,或是研究的對象,就具備了「自我選擇」的自由。(說一個人「自我選擇」了父母的社會經濟地位恐怕並不恰當,因為顯然這是不可能的。但是由於真正進行比較的研究人員不能決定這個變量的大小,所以就好像是研究對像決定了這個變量的大小。總之,一些與研究對像有關的變量是研究人員無法控制的,其大小也不能由他們選擇,有時他們甚至不知道這些變量的變化。)
只要一項研究僅對一個特定的變量進行測量而不是控制,我們就一定要注意到,對測量的變量(以及所有其他測量或不測量的變量)的大小進行選擇的是研究對象,而不是研究人員。這就在很大程度上限制了推理的準確性。在班級規模的例子中,研究人員使用了多元回歸的方法,使得班級規模這個變量的大小可以進行自我選擇(也就是說,研究人員不決定班級規模的大小),並且班級規模這個變量也許與其他各類變量都有聯繫,這些變量有可能會擴大或限制班級規模對於學習成績的影響。能夠完全避免自我選擇問題的唯一方法,就是讓研究人員來選擇因變量或預測變量的大小(例如,是人數較多的班級還是人數較少的班級),然後觀察因變量或預測變量對目標變量的效果(例如成就測試的成績)。由於不是總能做到這一點,所以我們只好滿足於相關性分析和多元回歸分析,同時對自我選擇的問題保持警戒。
最後,統計顯著性告訴我們,如果一項計劃實際上並沒有任何效果,那麼研究得出的效果值——例如班級規模對於學習成績的效果——就有可能是偶然產生的。按照慣例,如果統計顯著性的值為0.05,這就是說,在與進行的研究設計相同的研究中,兩個平均數之間的差距或某個特定大小的相關度在100次統計中只有5次出現的概率,或者20次中只有一次出現的概率。不過統計顯著性在很大程度上取決於觀測值的數量。如果觀測值數量足夠多,那麼即使在實踐中或理論上小到不具備任何意義的差距,在統計學上也可能會很重要。我在本書中提到的任何一項研究所得出的結果,其統計顯著性都達到了低於0.05的水平。只有一項我稱為「不太重要」的研究結果,其發生的概率低於0.1,這項研究的結果有可能是偶然獲得的。