
以前我一直希望人類基因組的序列在完全解開後,會有72415個基因。我之所以特別看重這個數目,跟人類基因組計劃第一個驚人的發現有關。1999年12月,第一個完成定序的染色體是位於兩大定序里程碑(10億和20億個鹼基序列)之間的第22號染色體。儘管它很小,在整個基因組中只佔1.1%,但仍長達3340萬個鹼基對。由小窺大,這是我們首次對基因組的全貌有概括的瞭解;如同《自然》雜誌的評論家所言,這就像「第一次看到新星球的表面或地景」。最有趣的是染色體上基因的密度。以第22號染色體作為整個基因組的縮影,應該是很合理的,所以照理說我們會在它的序列裡發現1.1%的人類基因、換句話說,教科書上估計人類基因的總數約為10萬個,照這樣推算,第22號染色體應該大約有1100個基因。但是我們卻只在它上面發現545個基因。這似乎強烈暗示,人類基因組不像我們原先所以為的有那麼多基因。
人類的基因數目突然成為熱門話題。2000年5月,在冷泉港實驗室一場有關基因組的會議上,來自桑格中心,負責以計算機分析基因組序列的伯尼(Ewan Birney),設下他稱之為Genesweep的賭局。這場賭局賭的是人類的基因總數,等2003年完成定序時就可以知道大概的正確數字,屆時誰猜的數目最接近,誰就是優勝者。伯尼會成為人類基因組計劃的地下賭注經紀人一點也不奇怪,因為數字正是他的專長。從伊頓公學畢業後,他借住我位於長島的房子,花了一年時間解決生物學上的定量問題。英國年輕人在高中畢業後上大學前的那一年,多半會選擇到喜馬拉雅山旅行或是到里約熱內盧的酒吧打工,但他的選擇大不相同。伯尼在冷泉港實驗室工作時就寫出兩篇重要的研究論文,那時他甚至還沒進牛津呢。

後基因組時代:基因啟閉模式的微陣列(microarray)分析。在這個圖例中,每個光點對應瘧原蟲6000個不同基因之一,瘧原蟲會引起最嚴重的一種瘧疾。我們在搜尋疫苗或解藥時,必須知道在生命週期的不同階段,哪些基因是活躍的。紅點顯示這個基因在一個階段是活躍的,但在另一個階段則不活躍,綠點則與之相反。在兩個階段都活躍的基因一般會以黃點呈現。
伯尼最初要求的賭資是1美元,但是隨著讓我們更接近最終數字的預測數目一發表,賭資也跟著提高。我從一開始就加入,所以只花了1美元押在72415上。這個數目可不是亂選的,我以第22號染色體的結果為本,考慮教科書10萬個的說法和當時的預測值5萬個後,才折中地選了它。
或許惟一會跟基因數一樣引起這麼多無聊臆測的問題,是我們所定序的究竟是誰的基因。原則上,這是機密數據,所以拿這個來打賭的話,大概不會有輸贏。就公共人類基因組計劃來說,我們定序的DNA樣本來自紐約州布法羅附近一些隨機選出的人,樣本的處理也是在相同的地區進行。所謂處理是先分離出DNA,再殖入人造細菌染色體,以便建立圖譜與定序。起初賽雷拉基因公司宣稱,他們的材料也是取自六個匿名捐贈、來自多種文化的人,但是在2002年,溫特忍不住把謎底公諸於世,宣稱他們定序的主要基因組其實是他的。如今,那個序列成了溫特跟賽雷拉之間僅餘的聯結。雖然人類基因組定序很吸引人,又有新聞價值,但是看來並沒有什麼商業效益,因此賽雷拉後來轉型為製藥公司,並在2002年和它的創辦人分道揚鑣。溫特又成立了兩家新公司,一家研究現代遺傳學引起的道德議題,另一家利用細菌基因組來尋找新的再生能源。
在人類基因組圖譜出爐後,已證實第22號染色體的基因密度並沒什麼出奇之處。其實,以它的大小小來說,擁有545個基因還算蠻多的。大小跟它差不多的第21號染色體,只找出236個基因。根據現在的估計,在人類的全套24條染色體(22條+X+Y)上,基因總數也只不過2萬多個。當然,尋找基因的工作還沒結束,我們還會發現更多基因,但基因總數絕對遠在3萬以下,距離從前教科書說的10萬就更遙遠了。
基因總數究竟會是多少?我們只能等著瞧。事實上,尋找基因不是這麼簡單:蛋白質編碼區全是由A,T,G,C構成的鏈,而且這些鏈深埋在基因組其他的A,T,G,C之間,一點也不明顯。我們也必須記得,人類基因組大約只有2%為蛋白質編碼,至於那些被稱為「垃圾」的部分,則是由顯然不具功能、長短不一的片段所構成,其中還有許多會重複出現。就連基因本身也含有垃圾片段;在有許多非編碼片段(即插入序列)的情況下,基因有時佔有一長段綿延的DNA,而編碼片段就像是分子高速公路上一段段荒涼道路之間零星、孤立的城鎮。目前已知最長的人類基因是肌萎縮蛋白(dystrophin,它發生突變時會引起肌肉萎縮症),長達240萬個鹼基對,其中只有11055個(僅佔基因的0.5%)為蛋白質編碼,其餘部分構成這個基因的79個插入序列(典型的人類基因有8個插入序列)。基因辨識工作之所以困難,原因就在於基因組這種龐雜的結構。
在我們對老鼠基因比較瞭解後,要尋找人類基因已沒有那麼棘手,這都要歸功於進化:如同所有哺乳動物的基因組,人類和老鼠的基因組中具有功能的部分相當類似,從人與鼠在遠古的共同祖先一直到現在,這些部分並未產生太大的歧異。相對之下,那些由垃圾DNA組成的部分向來走在進化的最前端;由於不像編碼片段有自然選擇的監督,因此垃圾區累積了大量突變,人與鼠在遺傳上的歧異程度也以這些區段為最高。因此尋找人與鼠在基因組序列中的相似部分,成了辨識基因具有功能的區段的有效方法。
完成河豚基因組的草圖也有助於辨識人類基因。這種日本老饕最愛的魚含有強烈的神經毒素;老練的廚師會先把含有毒素的器官移除,所以食客只會覺得嘴裡有點麻而已。但是每年大約有80人因河豚的製作過程不周而死亡,因此日本法律明文禁止皇室享受這道美食。10多年前,佈雷納開始「愛上」河豚,至少是把它們當做研究基因的對象。河豚基因組的規模只有人類的1/9,但所含的垃圾區段少得多:它的基因組中約1/3負責為蛋白質編碼。在佈雷納的領導下,河豚基因組的草圖只花了1200萬美元左右的經費就完成了,以基因組定序的標準來說,算是很便宜。目前看來,河豚基因數大約在3.2萬到4萬之間,和人類差不多。有趣的是,河豚基因的插入序列數目雖然跟人類及老鼠基因的差不多,但長度通常短得多。

人類第2號色體染色體上的基因:2.55億個鹼基對。
根據目前的估計,人類基因數大約是在3.5萬(註:原書如此,現在一般認為是在20000-25000之間)左右,即使基因數已大幅向下修正,但對一般人來說,光看這個數字可能會給他們一種錯覺,有點誇大了我們基因的複雜程度。在進化過程中,某些基因會衍生出一組相關的基因,形成一群功能類似、但有細微差異的基因。這些所謂的「基因家族」(gene family)完全是意外的產物:在製造卵細胞或精細胞的過程中,某染色體的一個區段無意間遭到複製,使得這個染色體上的某個特定基因多了一個復本。只要其中一個基因能發揮功能,自然選擇就不會去檢查另一個,而隨著突變不斷累積,這個額外的基因可能走上歧異的進化道路。偶爾這些突變會造成基因獲得新的功能,通常是與原基因密切相關的功能。人類基因所負責的「主題」,種類並不太多;事實上,我們許多基因的主題都一樣,只是略有變化而已。例如我們有575個基因負責編碼不同形式的蛋白質激酶(protein kinase enzyme),亦即在細胞周圍傳遞訊號的化學使者。大約有900個人類基因讓我們有嗅聞的能力:它們編碼的蛋白質是氣味受體,每種受體辨識一種不同氣味的分子或一整類分子。這900個偵察氣味的基因大體上也存在於老鼠體內,但其中有個差異:老鼠已經適應以夜行為主的生活,對嗅覺的需要程度較大——自然選擇篩選出嗅覺比較好的老鼠,並讓這900個氣味基因中的大多數持續運作。然而,人類的這些基因大約有60%已經在進化過程中退化。可能的原因是:當我們對視覺的依賴增加時,我們便不再需要那麼多嗅覺受體,所以當突變造成許多嗅覺基因無法製造正常的蛋白質,使我們的嗅覺變得比其他恆溫動物差時,自然選擇並沒有插手。
那麼,我們的基因數跟其他生物的基因數相比如何?
就基因的總量而言,我們也就比雜草類的植物多一點點而已!跟線蟲比,就更令人吃驚。線蟲只有959個細胞(人類估計約有100兆個細胞),其中302個是神經細胞,構成線蟲極度簡單的腦(我們的腦有1000億個神經細胞),我們和線蟲在結構的複雜度上有天壤之別,但我們的基因總數還不到線蟲的兩倍。我們要怎麼解釋這令人困窘的數字?其實我們一點也不必不好意思:看來我們人類就是能用這麼一套遺傳硬件來做更多的事。
事實上,我認為智力與低基因數之間有一種相互關係。我的看法是:所謂聰明,就是像我們或果蠅一樣,擁有一個相當不錯的神經中心,讓我們能以相對很少的基因,執行複雜的機能。(把幾萬個稱為「很少」,好像有點怪,不過這是相較而言。)腦賦予我們的感覺能力與神經操控肌肉運動的能力,遠超過沒有眼睛、移動緩慢的線蟲,因此我們可以選擇的行為反應,範圍大得多。至於不能移動的植物,選擇更少,它們得用上所有的遺傳資源才能應付環境中的偶發事件。相對地,聰明的物種在遇到天氣驟然變冷等偶發事件時,可以運用神經細胞去尋找更適合的環境(例如溫暖的洞穴)。

老鼠與人類同一個基因的DNA比較圖,包括一個插入序列(基因非編碼的區域,如黑框所示)和兩個表現序列的一部分(這些區域為該基因製造的蛋白質編碼)。黃色鹼基是人和鼠的序列歷經進化而一直沒有改變的部分,短橫線代表該物種在那個位置失去一個鹼基,老鼠和人類序列的相似性顯示,自然選擇在消除突變上非常有效,在插入序列中,突變通常無所謂,而在表規序列中的突變則有可能會破壞蛋白質的功能。我們可以看到人類和老鼠在插入序列上的差異比表現序列多得多。
脊椎動物也可能因為基因開關係統而變得更加複雜。基因開關一般位於基因附近,在基因組定序的工作完成後,我們現在可以仔細分析這些基因旁側的區域了。基因調節作用就是在這些區域發生的,由接合至DNA的調節蛋白質(reguatory protein)來啟動或關閉鄰近的基因。相較於比較簡單的生物,控制脊椎動物基因的啟閉機制似乎要複雜得多。脊推動物之所以這麼複雜,正是因為基因之間複雜精巧的協調作用。此外,一種特定基因有可能額外產生許多不同的蛋白質,這或者是因為不同的表現序列耦合在一起,從而創造出稍有不同的蛋白質(此過程稱為替代性剪接[clternative splicing]),不然就是因為蛋白質在製造後發生了生化上的變化。
人類基因數出乎意料地少,引起一些人在報刊的言論版撰文討論其意義,它們的主旨大多相同。進化生物學家古爾德(Stephen Jay Gould,他不幸於2002年病逝,激昂言論從此絕響)在《紐約時報》發表文章,認定低基因數為還原論(reductionism)敲響了喪鐘。還原論幾乎是所有的生物學研究遵奉的教條,這個理論認為一個複雜的系統是由下往上建立的,換句話說,要深入瞭解一個組織的複雜層次,就必須先瞭解這個組織比較簡單的層次,再把這些比較簡單的動態情況組合起來。根據這個看法,只要瞭解基因組的運作,我們最終必然可以瞭解生物體是如何組成的。古爾德等人以基因數少得驚人這一點作為證據,證明這種由下而上的方法不僅難以實行,也根本是無效的。有鑒於人類基因組比預想中簡單,反還原論者認為人類這個生物體就是活生生的證據,證明要瞭解我們自身,不是光靠把所有較小的過程相加就可以。對他們而言,人類的基因數少,正暗示著我們每一個人的主要決定因子是教養(後天因素),而不是天性(先天因素)。簡言之,這等於一篇獨立宣言,宣示我們人類不是像原先所想的,完全受基因支配。
我跟古爾德一樣,也瞭解教養在我們每一個人的塑造過程中很重要,但他在評估天性的角色上卻完全錯誤:我們的基因數低,並不能證明對生物系統採取還原論的方法是無效的,也不能在邏輯推論上證明我們不是由基因所決定的。包含黑猩猩基因組的受精卵必定會孕育出黑猩猩,而含有人類基因組的受精卵只會孕育出人類。無論接觸多少古典音樂或暴力的電視畫面,都不會改變這個事實。沒錯,我們還要許久的時間,才能充分瞭解這兩個極為類似的基因組中所含的資料是怎麼被運用的,為何能製造出兩種顯然極為不同的生物;但是,最後會形成哪種生物,其絕大部分的指令早就寫在每個細胞裡,亦即基因組中,這是不變的事實。事實上,我認為在以還原論的方法來研究生物學上,人類基因數少,反而是好消息:要理清3.5萬個基因的影響,要比理清10萬個簡單得多。
我們人類的基因數或許不是很多,但是就如同蕪蔓的肌萎縮蛋白基因所顯示的,我們擁有一個龐大雜亂的基因組。我們可以再度拿線蟲作比較:我們的基因數還不到線蟲的兩倍,但基因組的體積卻大了33倍。為何會有這樣的差異?建立基因圖譜的專家把人類的基因組描述為一個偶爾有綠洲(即基因)的沙漠。在基因組中,有50%是不具明顯功能、垃圾般的重複序列;我們的DNA足足有10%是由分散在各處的100萬個單一序列復本所構成,這個序列稱為Alu(節桿菌Arthrobacter luteus的縮寫,因為這個序列最初是在這種細菌中被分離出來):
GGCCGGGCGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGG
GAGGCCGAGGCGGGCGGATCACCTGAGGTCAGGAGTTCGAGA
CCAGCCTGGCCAACATGGTGAAACCCCGTCTCTACTAAAAATA
CAAAAATTAGCCGGGCGTGGTGGCGCGCGCCTGTAATCCCAG
CTACTCGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGA
GGCGGAGGTTGCAGTGAGCCGAGATCGCGCCACTGCACTCCA
GCCTGGGCGACAGAGCGAGACTCCGTCTCAAAAAA
把這個序列寫100萬次,就可以瞭解Alu序列在我們的DNA中佔了多大的規模。事實上,重複序列的數目甚至比表面上看來還多:一度可以立即辨識的重複序列,在經過許多世代的突變後,產生的歧異已經大到讓人看不出它們原本是某類重複DNA的成員了。假設現在有三個短的重複序列:ATTGATTGATTG。一段時間後,突變會改變它們,如果這段期間很短,我們仍可看出它們的來源:ACTGATGGGTTG。但是,如果時間較長,它們的原始身份就會在混雜的突變中完全消失:ACCTCGGGGTCG。在許多其他物種中,重複DNA的比例低得多:芥菜種子的基因組只有11%是重複序列,線蟲是7%,果蠅只有3%。我們人類的基因組體積大,主要就是因為包含的垃圾序列比其他許多物種多。
生物在垃圾DNA數量上的差異,解釋了長期以來的一個進化之謎。一般的預期是:複雜生物的基因組會比簡單生物的大,因為它們必須編碼更多的信息。基因組的大小和生物個體的複雜程度,的確有相互關係,例如酵母菌的基因組比大腸桿菌的基因組大,但比我們人類的小。然而,這個相互關係相當薄弱。

頭頂的洋蔥:這些洋蔥的基因組是洋蔥小販的基因組的六倍。
自然選擇會盡量使基因組變小,這是合理的假設。畢竟,每次細胞分裂時,它都必須複製所有的DNA;必須複製的內容愈多,出錯機會愈大,這個過程所需要的能量與時間也愈多。這對阿米巴原蟲、蠑螈或肺魚(lungfish)都是相當辛苦的工作。既然如此,這些物種的DNA數量為何會失控至此?就這些異常大的基因組而言,我們只能推論還有其他的選擇力量介入,抵消了保持小基因組的向然選擇推力。比方說,對有可能暴露在極端環境的生物來說,基因組大或許比較有利。肺魚住在陸地與水的交界處,可以借由把自己埋在泥巴裡來度過漫長的乾旱期;它們需要的基因硬件有可能比適應單一環境的生物來得多。
有兩個主要的進化機制可以解釋這種DNA過多的觀象:基因組加倍(genome doubling),以及一個基因組內特記序列的增殖(proliferation)。許多物種,尤其是植物,其實是兩個先前存在的物種互相雜交的結果。這些新物種通常只是結合了兩個親代的全套DNA,從而創造出雙倍基因組。或者也有可能因為某種遺傳意外,使一個基因組在沒有其他物種的輸入之下倍增。以麵包酵母為例,它大約有6000個基因,但進一步的檢視顯示,這些基因大部分是重複的,酵母的許多基因經常有兩個不同的復本。在酵母進化史的某個早期階段,它的基因組顯然倍增了。起初這些基因復本必定是一模一樣的,但是在長時間後,它們已經產生歧異。
另一個更豐富的多餘DNA來源是:能自行複製並插入基因組中多個位置的基因序列發生增殖。現在已經發現各種各樣「可移動遺傳因子」(mobile element)。但是1950年麥克林托克(Barbara McClintock)首次發表「跳躍基因」(jumping gene)的概念時,習於孟德爾那套簡單邏輯的科學家大多無法接受。麥克林托克是一位卓越的玉米遺傳學家,但研究生涯相當坎坷。1941年,她未能拿到密蘇里大學的永久教職後,來到冷泉港實驗室,後來一直是這裡的活躍成員,直到1992年以90歲高齡辭世為止。她曾經告訴一位同事說,「一定要相信自己眼中所見。」這就是她研究科學的方式:她認為一些遺傳因子會在基因組中移動的革命性構想,完全得自可觀察的事實。她研究決定玉米粒顏色的遺傳機制,發現有時個別玉米粒發育到一半時,顏色會變換,一顆玉米粒可能會變成雜色,有預期中的黃色細胞,也有紫色細胞。要怎麼解釋這種突然的轉換?麥克林托克推論,這是因為有可移動的遺傳因子在色素基因裡跳進跳出。

可移動遺傳因子的發現者麥克林托克最初提出這個概念時備受奚落;直到30年後,才在1983年獲得諾貝爾獎。
惟有在重組DNA技術問世後,我們才瞭解可移動因子有多常見;現在我們已經知道,它們就算不是大多數基因組,也是許多基因組的主要成分,包括人類基因組在內。這些可移動因子在相同基因組的不同位置一再出現,其中有些最常見的可移動因子所取的名字,反應出其四處移動的存在方式,例如有兩個果蠅的可移動因子取名為「吉普賽」(gypsy)和「流浪工人」(hobo)。有人在研究團藻(volvox)這種簡單植物時,發現其中一個可移動因子在基因組四周跳躍的能力特別強,因而稱之為「(麥克)喬丹因子」([Michael]Jordan element)。
可移動因子包含為一些酶編碼的DNA序列,這些酶有剪貼染色體DNA的能力,其功能就是要確保可移動因子的復本會插入染色體上的新位置。如果一個可移動因子跳躍至一個垃圾序列,生物體的功能不會受影響,惟一的結果是更多的垃圾DNA。但是,如果一個可移動因子跳至重要的基因,從而使這個基因喪失功能,則自然選擇就會介入:這個生物體可能死亡或因為不能生育等因素,無法將這個含有跳躍因子的新基因傳遞下去。可移動因子的移動鮮少會創造新基因或造成對原生物體有利的改變。因此,經過長久的進化過程後,可移動因子的影響似乎主要在於產生「新奇性」,例如雜色的玉米粒。奇怪的是,在最近的人類史上,極少有積極跳躍的遺傳因子之證據:我們的垃圾DNA似乎大多是在許久之前所產生的。相反地,老鼠基因組含有許多積極跳躍的可移動因子,但這似乎沒有對老鼠造成太多困擾;老鼠的繁殖能力原本就高,這可能使他們比較能夠容忍經常有因子跳至功能極重要的基因區所帶來的遺傳災難。
我們曾借由大腸桿菌瞭解許多有關DNA如何發揮功能的基本信息,它作為一種模型生物的貢獻真是無可比擬,難怪人類基因組計劃把破解它的基因組列為優先要務之一。威斯康辛大學的布萊特納(Fred Blattner)是最急於開始定序大腸桿菌的人,但他申請補助的提案沒有下文,直到人類基因組計劃獲得經費後,才撥給他一筆可觀的研究費。要不是他最初不願釆取自動化定序法,他的實驗室會是最早找出一種細菌基因組完整序列的。但是在1991年,他擴大研究規模的策略卻是釆取了傳統方法:僱用更多的大學生。另一位同樣較晚利用自動化的人是吉爾伯特,我早在兩年前就敦促他定序當時已知最小的細菌「支原體」(mycoplasma)的基因組,這種微小細菌以細胞為家。吉爾伯特想採取一種新的人工定序策略,遺憾的是,當這個策略無法成功時,支原體計劃也跟著結束。然而,布萊特納最後仍及時採取了自動化定序法,並在1997年發現大腸桿菌基因組包含大約4100個基因。
但是率先定序任一細菌之基因組的比賽,早在兩年前就已經由基因組研究所(TIGR)拔得頭籌,優勝者是由史密斯(Hamilton Smith)、溫特和他太太佛瑞瑟(Claire Fraser)率領的龐大團隊。他們定序的對象是流感嗜血桿菌。在更早的20年前,史密斯(他身高6.6英尺,原本主修數學,後來改念醫學院)就已經從這種細菌分離出第一個有用的DNA限制酶,而這個功績也讓他贏得1978年的諾貝爾生理醫學獎。他們這個團隊分工是由史密斯制備流感嗜血桿菌的DNA,然後由溫特和佛瑞瑟用全基因組隨機定序法(WGS)去定序這種桿菌的180萬個鹼基對。光是記錄這第一個「小」基因組,就足以讓人知道那些等著被定序、體積更大的基因組有多可觀:如果把流感嗜血桿菌基因組所有的A、T、G和C,都印在跟本書書頁同樣大小的紙張上,可能要4000頁左右才印得完。它一共有1727個基因,每個基因平均要用掉兩頁。在這些基因當中,只有55%的功能可以辨識:例如製造能量至少涉及112個基因,而DNA的複製、修補與重組至少需要87個基因。我們可以從它們的序列中看出,剩餘45%的基因也都有功能,只是在現階段還無法確認這些功能是什麼。
就細菌的標準而言,流感嗜血桿菌的基因組相當小。細菌基因組的大小與此特定菌種可能遭遇的環境多樣性有關。在毫無變化的單一環境(例如另一種生物的腸道)過著單調的生活,這個物種只需要相對較小的基因組就過得去。然而,如果它想看看廣大的世界,就比較容易遇到變化更多的情況,這時它必須具備足以應對環境的條件,而這種具有彈性的應對能力通常來自可供替換的好幾組基因,每組都適合特定的情況,而且隨時可以啟動。
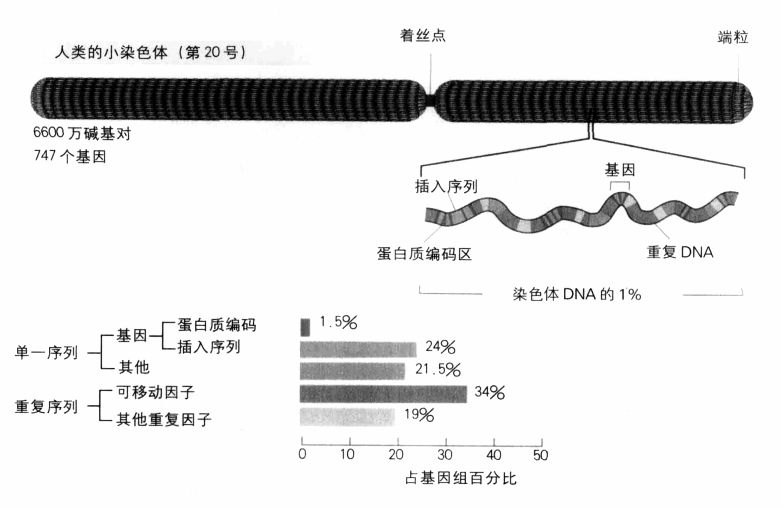
人類基因組的面貌:一個小染色體(第20號)的主要特徵。
銹色假單孢菌(pseudomonas aeruginosa,亦稱綠膿桿菌)是一種會在人體內引起感染的細菌(對纖維囊泡症病患者特別危險),它可以在許多不同的環境中存活。我們在第五章中看到,經過基因改造的一個相關菌種成為第一個被申請專利的活生物,在那個例子中,細菌適應了油膜裡的生活,而油膜是跟人的肺臟相當不同的環境。銹色假單孢菌基因組包含640萬個鹼基對,及5570個基因。在這些基因中,大約7%編碼轉錄因子,即可以開啟和關閉基因的蛋白質;因此這種菌的所有基因中,有相當可觀的比例是用於調節機制。在20世紀60年代初,莫諾和雅各布曾預測過大腸桿菌「抑制子」的存在(見第三章),這個抑制子正是這類轉錄因子。因此,我們獲得一條經驗法則:一個菌種可能遇到的各種環境愈多,它的基因組就愈大,而該基因組中用於基因啟閉的比例也愈高。
基因組研究所並沒有在做完流感嗜血桿菌後就歇手。1995年,在與北卡羅來納大學的哈奇森(Clyde Hutchison)合作下,這家研究機構在當時戲稱為「最小基因組計劃」的研究中,定序了生殖道支原體(Mycoplasma genitalium)基因組。生殖道支原體(雖然名稱有點不祥的味道,但它在人類排泄道中是無害的生物)擁有目前已知最小的非病毒基因組,約有58萬鹼基對。(病毒的基因組更小,但是它們可以利用宿主的各種基因,所以就算本身沒有許多基本功能所需的基因資源,但仍能生存。)後來發現這個相對較短的支原體序列包含517個基因。大家自然會問一個問題:這是維持生命所需最少的基因數嗎?後續的研究是破壞掉生殖道支原體的某些基因,看哪些是維持生命所必需的,哪些不是。目前看來,維持生命的最小基因組所包含的基因不超過350個,甚至可能少至260個。無可否認地,這個「最小」多少是人為定義的,因為,即使破壞細菌的一些基因,實驗所用的生長培養基仍能提供這些虛弱的細菌生存所需要的一切物質。這有點像宣稱腎臟不是生命所需,因為病人可以靠透析儀生存。
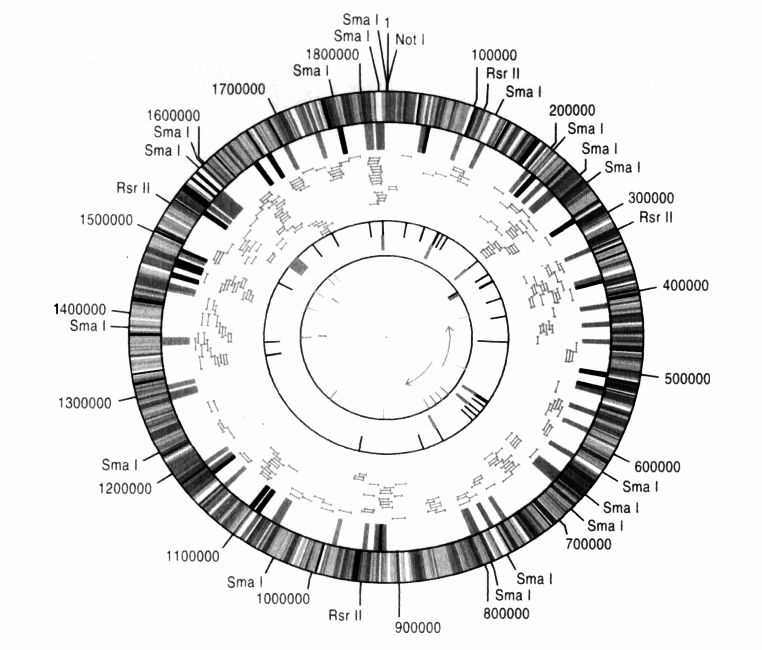
完整的基因組。流感嗜血桿菌的基因圖譜:180萬個鹼基對,1727個基因。
我們是否能無中生有,用人工結合個別的純化成分,製造出一個能夠發揮生命功能的最小細胞?有鑒於還有超過100個生殖道支原體的蛋白質的功能仍然是謎,要達到上述目標,可能還有一段漫長的路要走。支原體有500種左右的蛋白質,其中有些蛋白質是由大量分子組成,有些只有一小撮分子,它們所構成的生命系統已經極度複雜。就我個人而言,光是要看懂只有四五個主角的《高斯福德莊園》就挺困難的;想到要瞭解活細胞裡不同要素之間複雜的互動關係,就覺得這絕對是項艱巨的工作。因為活細胞絕不是一個簡單利落的迷你機器,如同佈雷納所說的,它們就像「一個蛇窩,許多分子相互扭纏在一起」。但是溫特仍然很有信心,認為人造細胞的時代即將來臨,而且他已經找了一批生物倫理學家來諮商,看看是否要繼續嘗試。他們跟我一樣,認為嘗試以這種方式「創造生命」並沒有道德上的問題。如果真的成就這個偉業,也只不過再度證實分子生物學界大多數人早已知道的事實:生命的本質就是複雜的化學作用,別無其他。在一個世紀前,這種「大發現」會成為頭條新聞,但在今日,這已經沒什麼大不了。惟有相反的結論,即細胞的生命不只是基本成分及其化學作用而已,那才會在科學界激起波瀾。
DNA分析改變了微生物學的面貌。在廣泛應用DNA技術之前,辨識菌種的方法在分析能力上極為有限:你可以記錄培養皿上菌落的形態,用微顯鏡觀察個別細胞的形狀,或使用相對來說很粗糙的生化分析法,例如依據細胞壁的特徵,把菌種分類為「陰性」或「陽性」的革蘭氏檢測(Gram test)。有了DNA定序法後,微生物學家等於突然擁有了一個辨識指標,而且這個指標絕對是每個物種所特有的。即使那些由於自然生長情況難以模擬,而無法在實驗室裡養殖的物種,例如棲息在海洋深處的物種,現在只要能從海洋深處取得樣本,同樣可以用DNA分析法來研究他們。
如今,在佛瑞瑟的領導下,基因組研究所仍是細菌基因組研究的龍頭。他們在很短的時間內,定序超過20種不同細菌的基因組,包括一種導致潰瘍的螺旋桿菌(Helicobacter)、一種導致霍亂的弧菌(Vibrio)、一種導致腦膜炎的奈瑟氏球菌(Neisseria),以及一種會引發呼吸道疾病的披衣菌(Chlamydia)。他們最大的勁敵是桑格中心的研究小組。這個英國團隊是由巴瑞爾(Bart Barrell)所領導,幸好他不在美國,否則以他有限的學歷,絕對無法登上學術界的高峰。他沒有博士學位,而是早在DNA定序法問世前,於高中畢業後直接擔任桑格的助手,從此踏入科學界。在開始研究細菌前,巴瑞爾是因為自動化的先驅而揚名,他用數個ABI定序儀來破解有1400萬個鹼基對的麵包酵母基因組,成功解開其中的40%,而這時歐洲其他的酵母菌定序小組仍執著於使用人工定序法。巴瑞爾的小組後來率先完成結核桿菌(Mycobacterium tuberculosis)的序列,這種桿菌會導致一度有「癆病」之稱的可怕疾病——肺結核。

基因組研究所的領導人佛瑞瑟女士。
在高中時,佛瑞瑟「覺得自己被同學排斥,因為修這麼多科學課程的女生並不酷」。在倫斯勒理工學院(Rensselaer Polytechnic Institute)唸書時,她首次對微生物產生興趣,於是申請進入醫學院就讀。後來她沒有接受著名的耶魯大學的入學許可,反而去了紐約州立大學布法羅分校,因為她的男友要搬去多倫多。這令耶魯的主管百思不解:「小姐,我希望你知道自己在做什麼。」但她跟男友的戀情並不長久;1981年,她嫁給了當時在布法羅擔任助理教授的溫特。她回憶說:「我們的蜜月旅行是去參加一場(科學)會議,還在那裡寫了一份經費申請書。」
運用DNA來分析微生物的做法,用在醫學診斷上極為成功。要有效治療感染,醫師必須先辨識引起感染的微生物。傳統的方法是利用被感染的組織來培養細菌,這過程慢得令人發瘋,特別是在時間緊迫的情況下。在運用快速簡單,也更加精確的DNA檢測來辨識微生物後,醫師可以迅速採取適當的治療方法。這種技術在國家緊急情況中也派上用場:2001年秋天美國發生炭疽熱下毒事件,基因組研究所的調查員找出第一位受害者身上炭疽熱細菌的序列,取得了歹徒所用菌種的「基因指紋」,希望借此追查到細菌來源,進而逮住罪犯。
在我們對微生物的基因組更加瞭解後,一個驚人的模式開始出現。我們先前已經看到,脊椎動物的進化就像一個累進的經濟體:通過逐漸增多的基因調節機制,同一個基因可以做的事愈來愈多。即使有新的基因出現,它們通常也只是既有曲目的變奏曲。相對地,細菌的進化是一趟激烈得多的改頭換面之旅,這個令人眼花撩亂的過程偏好輸入或產生全新的基因,而不是僅止於修改已經存在的基因。
事實上,重組技術之所以能問世,要歸功於細菌納入新DNA(通常是質體)片段的卓越能力。因此,微生物的進化會留存有過去驚人的基因輸入活動的痕跡,實在不足為奇。大腸桿菌在我們的腸道(和培養皿)中通常很和善,但是通過基因輸入,它們頓時成為變種殺手。有一種大腸桿菌菌株所製造的毒素,不時會引起食物中毒事件(1996—1997年曾造成蘇格蘭21人死亡)以及「殺人漢堡」事件(Killer Burgers,漢堡食材中含有桿菌毒素),這就是它們大量從其他物種「借用」基因造的禍。
遺傳物質通常是在親子中「垂直」傳遞(從祖先傳給後代),因此從外面輸入DNA稱為「水平轉移」(horizontal transfer)。把正常的大腸桿菌和致病菌株的基因組序列互相比較後,發現它們有共同的基因「骨幹」,由此可以確認這兩個菌株是屬於相同的菌種,但致病菌株有許多由變異的DNA構成的「小島」,這是它所特有的。整體而言,致病菌株缺乏正常菌株中的528個基因,但卻多出1387個正常菌株沒有的基因,數量可說相當驚人。這樣的變異把大自然最無害的產品之一變成了殺手。
在其他的致病菌中,也可以找到類似的證據,顯示曾發生過大量水平轉移。就細菌來說,霍亂弧菌(Vibrio cholerae)是很異常的細菌,因為它有兩個分離的染色體。較大的染色體(長度大約300萬鹼基對)似乎是這個微生物的原始配備,而細胞機能所需的大多數基因也在這裡。較小的染色體(長度大約100萬鹼基對)就像一個鑲嵌圖畫,由從其他物種輸入的大大小小DNA片段所構成。
複雜的生物,尤其是人類這種大型生物,天生就會嚴密守護本身內在的生化機制:在大多數情況下,如果我們不攝取或不吸入某一物質,該物質就無法大幅地改變我們。因此長期下來,所有脊椎動物的生化作用通常沒有多少變化。相對地,細菌暴露在異常化學環境中的情況多得多;一個菌落可能會發現自己突然陷入大量有毒化學藥劑中,例如家用漂白水等消毒劑。難怪這些非常脆弱的生物會進化出各種各樣的化學技能。事實上,細菌的進化是由化學創新所推動的,它們發明新酶(或修整舊酶)來做新的化學把戲。我們最近才開始解開其秘密的一群細菌,就是這種進化模式最驚人和最具教育意義的例子之一。這群細菌被稱為「極端微生物」(extremophiks),因為它們偏好世上最不適合棲息的環境。
我們已經發現有些細菌是棲息在黃石公園的熱泉裡(例如一種超嗜熱古細菌「激烈火球菌」[Pyrococcus furiosus]在滾沸的泉水中繁盛生長,在攝氏70度以下的溫度就會凍死),或是在海底噴口的超熱水域中生存(深海高壓使噴口週遭的海水無法沸騰)。有些細菌可以在像濃硫酸那麼酸的環境裡生存,有些則存活在強鹼性的環境中。嗜熱嗜酸菌(Thermophila acidophilum)是名副其實的極端微生物,能夠耐高溫與強酸。在石油礦的岩石裡也發現了一些菌種,它們可以把石油與其他有機物轉化為細胞能量的來源,很像微型的高科技汽車。其中一個菌種棲息在距地表一英里或更深的岩石裡,在有氧氣存在時就會死亡,這種細菌有個相稱的名字地獄桿菌(Bacillus infernos)。
生物學曾經有一個重要信條:生命作用的所有能量最終都來自太陽。但是近年發現的微生物之中,最驚人的或許就是那些推翻這個信念的微生物。支持這種信念的例子是,在沉積岩中發現的地獄桿菌和以石油為食的細菌,往回追溯,也都與有機物質有關:陽光在遠古以前就開始照耀動植物,而它們的遺骸最後形成了今日的化石燃料(石油、煤等)。但是,現在我們發現了一類「無機自養生物」(lithoautotroph),這種微生物能從完全由火山爆發所創造的岩石中取得所需的養分。這些岩石沒有包含有機物質的跡象,也不含陽光普照的史前時代所留下的任何能量。無機自養生物必須利用無機物來建造本身的有機分子,它們實際上是以岩石為食。
我們對微生物世界的不瞭解,最明顯的證據莫過於很晚才發現的原核綠球藻(Prochlorococcus),它們的浮游細胞在大海上可以進行光合作用。在每一毫升的海水中,可能就有多達20萬個原核綠球藻,因此它們大概是地球上數量最多的物種。它們當然也在海洋對全球食物鏈的貢獻上佔有極重要的比例。但我們卻一直到1988年才知道它們的存在。
從我們週遭神奇的微生物世界,可以看出無數世紀以來自然選擇所呈現的驚人力量。事實上,地球上的生命史主要是一出細菌的故事;比較複雜的生物,包括人類,都是很晚才登場的。35億年前左右,生命最早以細菌的形式出現在地球上。第一批真核生物(其基因包在細胞核內)大約在8億年後才出現,但其後的10億年,它們一直維持著單細胞的形態。直到距今5億年前才有一些突破發生,最終帶來了蚯蚓、果蠅等生物,以及人類。細胞的優勢可以從伊利諾伊大學的沃斯(Carl Woese)率先根據DNA重建的生命樹看出:這棵生命樹是一棵細菌樹,在較晚長出的小枝上才有一些多細胞生物出現。沃斯剛提出構想時遭到生物學界的強烈反對,但現已廣獲採納。不過,以DNA為基礎來建立生命樹,仍有一些令人難以接受的含義:例如它們顯示動物和植物的關係不像先前所想的那麼近,跟動物關係最近的生物反而是真菌——人類與洋菇有相同的進化根源!
人類基因組計劃已經證明,達爾文的進化論比他自己敢於想像的還要正確。所有的生物都因為共同的傳承而互有關係,而這也是分子相似性的來源。一個成功的進化上的「發明」(在自然選擇上有利的一個或一組突變)會代代相傳。隨著生命樹的逐漸多樣化(原有譜系分開,產生新譜系,例如爬蟲類現在仍繼續存在,但也衍生出鳥類和哺乳類的譜系),進化的「發明」最終可能出現在大量後代物種上。例如我們在酵母裡發現的蛋白質,約有46%也見於人類身上。酵母(真菌類)譜系和最終造成人類出現的譜系,可能是在10億年前分開的,後來這兩個譜系獨立發展,各走各的進化道路。事實上,從酵母與人類的共同祖先開始,進化就足足進行了10億年;但是在這段期間,存在於共同祖先裡的那一組蛋白質只有些微改變。一旦進化解決了一個特殊問題(例如設計出一種酶來催化特定的生化反應),就會一直沿用相同的解決方法。我們先前已經看到,這種進化惰性是造成RNA主導細胞作用的原因:生命始於RNA世界,而這個遺產一直存留至今。這樣的惰性也延伸至更細膩的生化層次:蠕蟲蛋白質中有43%跟人類蛋白質的序列相似,果蠅蛋白質有61%,河豚蛋白質則有75%。
比較不同生物的基因組也可以看出蛋白質的進化過程。蛋白質分子一般可以視為不同結構域(domain)的集合體,所謂結構域是具有特定功能或形成特定三維結構的氨基酸鏈段,而進化似乎是借由置換結構域,創造新的排列來運作的。大多數的新排列大概都是隨機產生,不具功用,注定要在自然選擇下消失。但是在一些罕見例子中,某個新排列證明是有利的,這時一種新蛋白質就會產生。從人類蛋白質中辨識出來的結構域,大約有90%也見於果蠅和蠕蟲的蛋白質。因此,人類特有的蛋白質其實可能只是果蠅的一個蛋白質重新排列的結果。
生物體之間這種基本的生化相似性,最好的證明莫過於所謂的「拯救實驗」(rescue experiment),這種實驗是消除掉一個物種的某個特定蛋白質,然後利用從其他物種取得的相應蛋白質來「拯救」喪失掉的功能。這個策略已經用於胰島素。由於人類與牛的胰島素非常相似,因此無法自行製造胰島素的糖尿病患者可以接受牛的胰島素作為替代品。
下面這個例子很像二流科幻片的驚悚情節:研究人員借由操控控制眼睛生長部位的基因,讓果蠅在腳上長出眼睛!這個基因會促使許多與製造一個完整眼睛有關的基因在指定的部位工作,讓眼睛在那裡長出來。老鼠體內控制眼睛生長部位的基因與果蠅的非常類似,所以在基因工程師的操控下,把老鼠的這個基因植入一個該基因被消除的果蠅體內,它便會發揮相同的功能。這樣的事可謂相當驚人:套用先前人類與酵母同時沿不同路線進化的邏輯,果蠅和老鼠在進化上至少已經分開5億年之久,因此這個基因其實已存續了10億年以上。如果想到果蠅和老鼠的眼睛在結構與光學上截然不同,這樣的事實更顯驚人。每個譜系各自發展出適合其目的的眼睛,但決定眼睛位置的基因機制不需要改良,所以仍維持不變。
人類基因組計劃最令我們感到謙卑的地方,在於我們發現自己對絕大多數人類基因的功能所知甚少。為了妥善運用得來不易的信息,我們必須設計出以基因組規模來研究基因功能的方法。
在人類基因組計劃之後,「後基因組時代」有兩個新領域出現,它們的英文名稱都含有和基因組同樣的字根-omic:蛋白質組學(proteomics)和轉錄組學(transcriptomics)。蛋白質組學研究基因編碼的蛋白質;轉錄組學則致力於探索基因表現的位置與時間,亦即在一個特定的細胞裡,哪些基因在轉錄上是活躍的。如果我們要瞭解基因組的實際動態表現,不應僅視之為一套組合生命的指令,而應視之為生命這齣電影的腳本——一部按照精確順序寫下生命中所有應該上演的劇情的腳本,那麼蛋白質組學和轉錄組學就是瞭解現場演出的關鍵。我們瞭解得愈多,看到的「生命電影」愈多。
我們很早就知道,從生物學觀點來看,蛋白質絕不僅是一條線狀的氨基酸鏈而已。這條鏈折疊成特殊的三維構造的方式,與其功能息息相關,而這也是蛋白質組學想要瞭解的。現在結構分析仍是依賴X光衍射:用X射線照射分子時,它們會在碰到原子後反彈並散開成一定的模式,從中可以推知三維形狀。1962年,我以前在劍橋大學卡文迪什實驗室的同事肯德魯和佩魯茨,分別以解開肌紅素(將氧儲存在肌肉裡)和血紅素(運送血液中的氧)的結構而得到諾貝爾化學獎。他們的研究具有劃時代的意義。他們必須解讀的X光衍射影像非常複雜,相較之下,DNA簡單得多了!
有關蛋白質三維結構的知識,對醫藥化學家尋找新藥幫助很大,許多藥物就是靠抑制蛋白質的機能來治病的。藥物研發日趨專業化與自動化,數家公司現在正試圖決定蛋白質的結構,好像它們就是生產線上的商品。比起肯德魯和佩魯茨的時代,現在這類研究工作簡單得多了:如今我們有更強大的X光源,自動化的數據記錄,還有更聰明的軟件讓計算機速度變得更快,所以解開一個結構所需的時間已從數年減少至數星期。
從三維結構本身經常看不出蛋白質的功能,但是研究神秘的蛋白質與其他已知蛋白質的互動,可以提供重要線索。有一個簡單的方法可以辨識這類的相互作用:在顯微鏡載玻片上放一組已知蛋白質的樣本,然後把神秘蛋白質灑在它上面;這些神秘蛋白質事先已經過處理,在紫外線照射下會發出螢光。當神秘蛋白質「黏」到載玻片上蛋白質網格的某個位點,這表示它在這個位點上已和另一蛋白質接合在一起,這使後者也變得會發螢光。由此便可以推知,這兩個蛋白質在細胞內會產生互動。
在理想狀況下,要知道生命腳本、要看到生命電影,我們必須找出在個體發育期間的蛋白質組成過程中所有的精確變化,從受精時刻開始一直到成年時期為止。我們會發現,許多蛋白質在整個過程中都發揮作用,但有一些蛋白質在特定的發育階段才有用,所以在不同的成長階段我們會看到不同的蛋白質組,例如成人和胎兒的血紅素便有略微不同。同樣地,每種組織會製造其專屬的蛋白質。
要找出一個組織樣本中不同的蛋白質,仍是長久以來所使用的方法最可靠,亦即利用蛋白質分子的電荷和重量差異,以二維凝膠電泳法來分離它們。然後用質譜儀(mass spectrometer)分析分離出來的數千個蛋白質小點,定出每個蛋白質的氨基酸序列。不幸的是,要應用這類的蛋白質組學來分析由整個基因組編碼的大量蛋白質,所需的經費往往超過學術界的科學家所能負擔。因此,這類昂貴的研究大多是由經費比較充足的大製藥廠研究人員來做。但是由於這個方法本身的限制,如果蛋白質的含量很低,即使是這些實驗室也無法每次都成功。
由於這類高處理量的蛋白質組學需要昂貴的硬件設備,還必須要有產業規模的複雜自動化程序,因此今日大多數科學家在研究整個基因組的基因功能時,並不使用這種方法,大多釆取轉錄組學的方法,因為它比較便宜,也比較容易實施:一個基因組裡所有基因的機能,可以借用測量個別信使RNA產物的相對數量來追蹤。如果你對表現在人類肝細胞裡的基因感興趣,你可以分離出肝臟組織內信使RNA的樣本。從這個樣本可以大致瞭解肝細胞內的信使RNA族群。在信使RNA樣本裡,最常被轉錄和製造出許多信使RNA分子、非常活躍的基因,所佔的復本比例會較高,而鮮少被轉錄的基因則只有少量復本存在。
轉錄組學的關鍵在於一個相當簡單的發明,即DNA微陣列(DNA microarray)。你可以想像一個顯微鏡的載玻片,上面有蝕刻了3.5萬個點狀小井的格網;然後利用精確的微小取量(micropipetting)技術,在每個點狀井放入一個基因的DNA序列,讓格網裡包含人類基因組的每一個基因。重要的是必須知道各個基因的DNA是位於載玻片上哪個位置。斯坦福附近的Affymetrix公司甚至已經進一步縮小這些數組,把它們蝕刻在小如計算機芯片的一塊硅芯片上,這便是「DNA芯片」(DNA chip)。
使用標準的生化技術,你可以為肝臟信使RNA加上化學標籤,例如讓它們在紫外線照射下發出螢光,如同前述的蛋白質。接下來的步驟更凸顯出微陣列法功能的強大及簡單:你只要把信使RNA樣本放到微陣列3.5萬個裝滿基因的棋盤狀小井裡,使雙螺旋體兩股結合的鹼基配對鍵,會驅使每個信使RNA分子跟原先產出它的基因配對。這種互補配對萬無一失。來自基因X的信使RNA只會跟在微陣列上基因X所在的點結合。接下來只要觀察哪些點與發螢光的信使RNA結合。如果微陣列上的某個點沒有螢光,就代表這個樣本裡沒有互補的信使RNA,因此我們可以推論這個基因在肝細胞裡沒有活躍的轉錄作用。反之,許多點發出了螢光,有些還特別亮,這顯示許多信使RNA分子已經連結上去。結論是:這是個非常活躍的基因。因此,只要有一個簡單的實驗分析報告,就可以辨識出活躍於肝臟中的每一個基因。我們之所以能巡遊分子世界,要歸功於人類基因組計劃的成功,以及它帶給生物學家的新思維:我們不必再滿足於研究零零碎碎的細節,現在我們可以縱覽分子天下,一睹其最壯觀的全貌。
難怪斯坦福的布朗(Pat Brown)視DNA微陣列為「一種新的顯微鏡」。布朗是應用這個方法的佼佼者之一,對這項技術揭露基因世界嶄新全貌的潛力感到不可思議,他曾經表示:「我們現在就像才剛開始探索世界的學步小兒。」
轉錄組學不僅是一項卓越的技術創新而已,它也讓我們在追蹤致病基因時更上一層樓。我們可以利用微陣列技術,研究健康與生病組織在基因表現功能上的差異,從而找出特定疾病的化學基礎。這個邏輯很簡單:我們對正常組織與癌症組織進行微陣列基因表現分析,然後找出這兩者之間的差異,亦即找出在一個組織有表現,但在另一組織無表現的基因。一旦確認運作失常的基因(例如在癌症組織中表現過度或表現不足的基因),我們就可以找出目標,用精確的分子療法來攻擊這個目標,而不是使用具有廣泛毒性、會同時摧毀健康與生病細胞的放射線療法和化學療法。
我們也可以運用這種技術來區分相同疾病的不同形式。在這方面標準顯微鏡的幫助有限:對通過目鏡來觀察的病理學家來說,癌症看起來都差不多,但它們在分子層面的差異是極大的。例如淋巴瘤細胞有多種形式,但這些光靠視覺難以區分,即便用放大倍率最高的顯微鏡也很難區別,但是這些細胞在基因表現上的差異卻很明顯,這對發明最有效的療法極為重要。在談到早期認為特定組織的癌全都有相同根源的看法時,布朗指出:「這就像把胃痛想成只有一個原因。辨識同類病症細微的差異,讓我們能更適切地治療這些癌症。」
在冷泉港實驗室,魏格勒(Michael Wigler)以不同的方式來使用微陣列法:他不是把RNA加到微陣列上,然後尋找基因表現,而是加入癌細胞的DNA,建立呈現在腫瘤裡的基因多樣性。許多癌症是染色體重新排列所引起的。例如當一個染色體的片段在無意間複製,導致為促進生長的蛋白質編碼的基因數目過多時,就有可能造成癌症。有些癌症之所以會發生,是因為失去了能為抑制細胞生長的蛋白質編碼的基因。醫師可以運用魏格勒的方法,檢查來自同一人的癌組織和健康組織的活組織切片。癌組織的DNA以紅色染劑加上化學標籤,正常組織的DNA則用綠色。然後把這兩種樣本的混合物,加入包含所有已知人類基因的DNA微陣列。如同標準微陣列實驗裡的信使RNA,這些加上標籤的DNA分子的鹼基對會和陣列中互補序列的鹼基對鍵結。癌細胞擴增的基因會呈現紅點(因為和那一點鍵結的紅標分子比綠標分子多出許多),沒有癌細胞的基因會呈現為綠點(因為沒有紅標分子和它鍵結)。這類實驗使得目前已知會造成乳癌的基因名單大幅加長。
我們在對付一種人類疾病時,總會發現自己像在黑暗中摸索。如果我們對正常情況下的基因表現多瞭解一點,我們就能更快找到問題核心,知道究竟是哪裡出了問題,以及要如何修正。如果對於從受精卵正常發育為健康成人期間的所有基因發揮功能的時間與位置,我們都能有動態層面的瞭解的話,就能以此為基準,瞭解每一種病痛——我們所需要的就是完整的人類「轉錄組」(transcriptome)。這是遺傳學的下一個「聖盃」,也是下一個需要巨額經費的大型研究計劃。就短期而言,一個比較可能實現,甚至比較重要的目標是取得老鼠的完整轉錄組。先做老鼠而非人類實驗的優點,在於我們可以在胚胎發育期間進行觀察,以及用實驗技術來進行干涉。即使是從老鼠身上收集這類相關的重要數據,也需要投資大量的時間與金錢。此外,如同DNA定序實驗所證明的,更好的做法是先花些時間去完成更簡單的模型生物轉錄組,盡量精進我們的技術,然後再開始研究老鼠,人類當然得擺在更後面。
細胞分裂:一個細胞的染色體(藍色)進行複製,先沿特殊的「紡錘體"(spindle,綠色)排列,然後才分配至每個子細胞。高科技影像技術協助呈現出令人驚異的染色體華爾茲舞曲,而這也正是生命本身能永久存續的基礎。
以微陣列法研究酵母細胞週期中的基因表現後,我們發現,光是細胞分裂的分子動態就已經極度複雜。這當中牽涉到800多個基因,每個都在細胞週期的某個時間開始發揮作用。我們在這裡再度看到,進化不願修補沒有壞的東西:一個生物過程一旦成功地進化,只要生命持續下去,這個過程就很可能繼續使用相同的基本分子。就我們目前所知,在酵母細胞週期期間主導發育的基本分子,在人類細胞中也扮演類似的角色。
最終,研究這三個「組」(基因組、蛋白質組和轉錄組)的目標都在於針對生命的組成與運作,建立精細至個別分子層面的全貌。如同先前所見,即使是最簡單的生命,也複雜得令人迷惑,而且儘管近10年來在這方面已有可觀的進展,但我們仍要面對許多艱巨的挑戰。就複雜的生物體而言,要想瞭解主導他們發育的分子作用——也就是在四個字母組成的密碼串的操控下,由卵到成體的神奇之旅最好的途徑還是從果蠅著手。
自從成為摩根的研究對像後,果蠅向來是遺傳學研究的重心;在其後的年代,通過持續的創新實驗,果蠅至今仍是基因的金礦。20世紀70年代晚期,在德國海德堡的歐洲分子生物學實驗室(European Molecular Biology Laboratory),紐斯蘭—渥荷德(Christiane 「Janni」 Nusslein-Volhard)和魏斯豪斯(Eric Wieschaus)開始了一項抱負遠大的果蠅計劃。他們利用化學製品誘發突變,然後尋找果蠅後代在非常早期的胚胎階段所發生的阻斷現象。傳統上,果蠅遺傳學家的研究對像一直是影響成體的突變,如同摩根所發現會造成白眼(而非紅眼)的突變。但是紐、魏兩人不同,他們把注意力放在胚胎上,耗費眼力,花了多年時間用顯微鏡尋找難以捉摸的突變,這也讓他們進入了無人研究過的新領域,收穫相當驚人。他們分析發現了好幾組規劃果蠅幼蟲基本發育計劃的基因。
紐斯蘭—渥荷德和魏斯豪斯的研究工作也傳達出一個更普遍的訊息:遺傳信息是按等級規劃的。他們發現,有些突變種的改變範圍廣泛,但有些突變種的變化則較為有限;他們根據這一點正確地推論出,效果廣泛的基因是在發育早期發揮作用,亦即它們是位於啟閉階級的頂端,相對地,效果有限的基因是在比較後期才發揮作用。他們發現了逐級傳達式的轉錄因子:一些基因啟動其他基因,而這些被啟動的基因又啟動其他基因,依次類推。事實上,這種逐級傳達式的基因啟閉機制正是建造複雜個體的關鍵。這就像負責建造磚塊的基因可以獨立製造出一排磚塊;然而在夥伴的協調運作下,它可以建造出一面牆,最終蓋好一整棟房子。
一個個體若要正常發育,其細胞就必須「知道」自己在個體內的位置。畢竟,果蠅翅膀尖端的細胞所走的發育路線,應該跟果蠅腦部的細胞極為不同。第一條有關發育部位的必要信息最簡單:發育中的果蠅胚胎怎麼知道哪一端在哪裡?頭應該往哪邊長?bicoid蛋白質是由母體的一個基因所製造的,它會以不同的濃度分佈在整個胚胎中。這個效應稱為「濃度梯度」(concentration gradient):這種蛋白質的含量在頭端最高,愈接近尾端含量愈低。因此,bicoid濃度梯度會告訴胚胎中的所有細胞,它們在頭-尾軸上的位置。果蠅發育是環節式的,它的身體分為數節,這些體節都有許多共同點,但每一節又各有獨特之處。在許多方面,頭部的組織方式跟胸部(昆蟲身體的中間一節)相同,但頭部有其特有的器官,例如眼睛,胸部也有其特有的器官,例如腳。紐斯蘭—渥荷德和魏斯豪斯發現,有數群基因負責指定不同體節的身份,例如「成對規則基因」(pair-rule gene)為相隔體節的轉錄因子(基因開關)編碼,所以「成對規則基因」發生突變時,會造成胚胎每隔一個體節就發生缺陷。
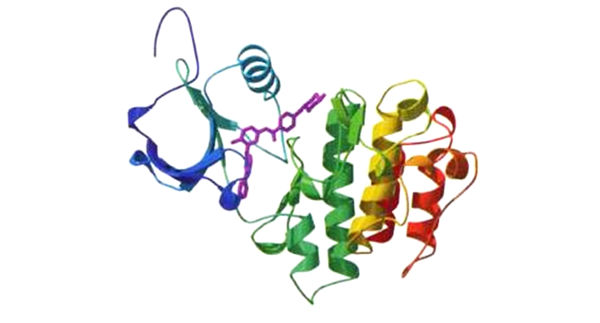
蛋白質組學:上圖為致癌蛋白質BCR-ABL的三維結構。染色體異常使BCR和ABL這兩個基因結合在一起,產生了這種蛋白質,它會刺激細胞增殖,而且可能引起一種形式的白血病。紫色部分是一種小分子藥物Gleevec,可以抑制BCR-ABL的功能(見第五章)。在未來,這類三維結構的信息可以用於設計針對特定蛋白質的藥物。這個BCR-ABL的結構模型沒有顯示出原子或個別氨基酸的細節,但仍精確呈現出蛋白質的整體結構。
1995年,紐斯蘭—渥荷德和魏斯豪斯因為他們開創性的研究,榮獲諾貝爾生理醫學獎。他們在得獎後仍活躍於實驗室,而不是退居以獎狀裝飾的寬敞辦公室,這跟大多數桂冠得主不同。對魏斯豪斯而言,科學的魅力無法抵擋:「因為胚胎很美,也因為細胞的工作令人讚歎,所以我每天都懷著極大的熱忱走進實驗室。」他在亞拉巴馬州的伯明翰長大,小時夢想當個藝術家。但他在聖母大學(University of Notre Dame)念大二時,由於錢不夠用,就接下了科學界最臭、最卑微的工作之一:替實驗室的果蠅族群調配「果蠅食物」(臭味衝鼻的膠狀物,大多由糖蜜構成)。為數十萬隻骯髒又不知感激的昆蟲下廚烹飪後,大多數的人可能會終生厭惡此種生物,但魏斯豪斯恰恰相反:他從此獻身於研究果繩及它們的發育之謎。
紐斯蘭—渥荷德出生於德國的藝術家庭,從小在自己感興趣的領域樣樣出色,但對其他事物完全不理會。她在果蠅的發育遺傳學上所獲得的成果,足以讓她發展兩個職業生涯,但在獲得諾貝爾獎後,她反而把她專注無比的注意力轉移到斑馬魚(zebra fish)的發育上:這個新工作渴望解開許多脊椎動物的發育秘密。2001年,在諾貝爾獎的百年紀念活動上,我突然發現她是眾多白髮男士當中惟一的女科學家。事實上,截至當時在科學界只有10位女性榮獲過諾貝爾獎,她是其中之一。
其他不再年輕的男科學家包括加州理工學院的劉易斯(Ed Lewis),他也是果蠅專家,和紐斯蘭—渥荷德及魏斯豪斯共享這個榮耀。其實劉易斯不太像典型的銀髮族,雖然在參加斯德哥爾摩的頒獎典禮時,他已經年逾80,但在不必穿燕尾服時,他經常穿著慢跑裝!他長期研究果蠅發育的基因調控,但對同源轉化突變(homeotic mutations)特別感興趣。這類突變會造成最奇特的結果:發育中的一個體節誤拿到相鄰體節的身份。在現在這個經常跟著流行制定科學計劃的時代,一些價值觀正逐漸消失,但是劉易斯在研究導致這些突變發生的霍克斯基因群(Hox genes)上所作的長期努力,卻成了良好的典範。
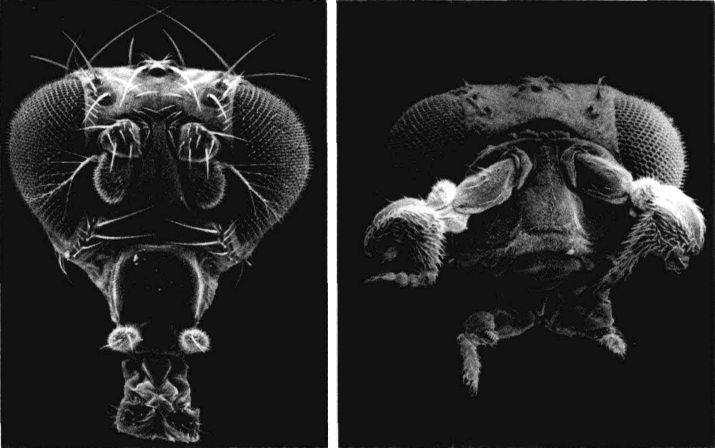
果蠅的臉:左圖是正常個體,前額上長出一對有毛的觸角。右圖是觸足突變種(antennapedia mutant),它的觸角被完整的前足所取代。
現在我們已經知道同源轉化突變會阻斷為轉錄因子編碼的基因(亦即基因開關),這種突變可能產生戲劇性的效果。觸足(antennapedia)突變使果蠅在原本應長出觸角的前額長出一對完整的腳。雙胸型(bithomx)突變幾乎同樣怪異。在正常情況下,胸節之一會長出一對翅膀,而下一個比較接近尾端的胸節則會長出一對具有穩定作用的小結構,稱為平衡棒(halter)。但是在雙胸型果蠅突變種身上,原本應該長平衡棒的體節誤長出翅膀,因此原本應該只有兩個翅膀的果蠅變成有四個翅膀,而且第二對翅膀跟第一對同樣完整。
正常運作的基因會調控體節的身份,確認每個體節的器官都長在正確位置上:頭節長出觸角,胸節長出翅膀和腳。但在發生同源轉化突變時,各節的身份卻發生混淆。以觸足突變為例,頭節以為自己是胸節,因此長出腳,而不是觸角。值得注意的是,儘管腳的位置不對,但它的功能仍很完整。這暗示觸足位置基因啟動的是一整組的基因,它們通常是製造觸角的基因或製造腳的基因(在異常發生時);但是在錯誤時間於錯誤位置被啟動的整組基因,內部的協調工作並未受到阻撓。在這裡我們再次看到,發育等級較高的基因控制了等級較低的許多基因。如同每個圖書館員都知道的,等級組織在儲存和取得信息上效率較高。由於有這種等級式的安排,有時極少數的基因就足以造成很大的影響。
人類基因組計劃締造的驚人成就,引領我們進入了生物學最遼闊的一個新紀元。我們走在新研究領域「發育遺傳學」(developmental genetics)的最前端時,竟然又折回去研究果蠅,好像有些奇怪。但我們必須「回到未來」,往回、往根源去探索,才能邁入未來,因為,即使已經解開整個人類基因組,但執行遺傳指令的程序與線索仍是個巨大的謎。最終我們必會知道人類的生命腳本,如同我們研究的果蠅的腳本。我們將能完整地描述人類基因表現的模式(轉錄組),並且建立所有蛋白質作用的清單(蛋白質組)。我們將會對每個人極度複雜的組成全貌,以及構成我們的分子大軍中的每一個是如何發揮功能的,有充分而完整的瞭解。