
如果你是家長,在你孩子長到3歲這段時間,關於學習的整個奧秘會在你眼前揭開。新生兒無法說話、走路、識別物體,甚至不知道,當他看不到某個東西時,它仍然存在。但一個月又一個月過去,大步小步向前走,經過不斷摸索,終於取得概念理解上的大進步,孩子終於理解世界如何運轉、人們如何行事,以及如何進行溝通。孩子過了3歲生日,所有這些學習行為就會聚合成穩定的狀態,即一種貫穿我們一生的意識流。較大的孩子和成年人可以進行時空旅行,也就是記住過去的事,但也只能回憶到3歲的事。如果我們能重新回憶嬰兒和蹣跚學步時期的自己,然後從新生兒的角度看待這個世界,那麼許多關於學習的疑問,甚至關於存在本身,都會突然變得清晰明朗。但實際上,宇宙中最大的奧秘並不在於它如何開始和滅亡,或者又是由怎樣無窮細的線編織而成,而在於幼小孩子的大腦裡正在發生什麼:一磅的膠狀物如何變成意識的所在處。
對於兒童學習的科學研究尚不成熟,幾十年前才正式開始,卻已經研究得很深入。嬰兒無法填寫問卷或者遵守實驗規則,但我們可以推導出關於他們大腦活動的、讓人驚訝的數量,方法就是在實驗過程中,對他們的反應進行錄製並研究。連貫的圖片就出現了:嬰兒的大腦不僅能揭開一項預設的基因程序,或者是用於記錄感測數據中相互關係的生物裝置,還可以積極整合他們自身的實際情況,這種情況會隨時間發生徹底改變。
漸漸地,與我們最為相關的認知科學家以算法的形式來表達關於兒童學習的理論。許多機器學習研究人員由此得出靈感:我們需要的一切都存在於孩子的大腦中,如果能用編碼的形式來獲取其精華就好了。一些研究人員甚至認為,創造智能機器的方法,就是要造出一個機器嬰兒,讓它像人類嬰兒那樣去體驗世界,研究人員就是它的父母(甚至可能還會有來自眾包的協助,賦予「地球村」這個術語以全新的含義)。小羅比,我們就這麼叫它吧(為了向《禁忌星球》中胖乎乎且高大的機器人致敬),是我們造出的唯一的機器人嬰兒。一旦它學會3歲小孩都知道的事情,那麼人工智能的難題就得到解決了。我們可以把它腦子裡的內容複製到其他機器人中,想複製幾個都可以,這樣最困難的工作就完成了。
當然,問題在於羅比出生時,腦子裡該運行哪種算法。受到兒童心理學影響的研究人員會看不慣神經網絡學,因為一個神經元的微型運作與孩子最基本行為的複雜度也相差十萬八千里,這些行為包括伸手去拿東西、抓住東西,然後睜大眼睛好奇地觀察它。我們需以更抽像的水平來模擬兒童的學習,以免只見樹木、不見森林。首先,雖然孩子理所當然從父母那裡獲得了許多幫助,但很多時候他們是在沒人監督的情況下進行自學,這才是最不可思議的地方。目前為止,我們見過的算法還無法做到這一點,但我們會發現有幾種算法可以讓我們看到離終極算法更進一步了。
物以類聚,人以群分
我們輕輕按下「打開」按鈕,羅比的視頻眼第一次睜開了,但馬上它就淹沒在威廉·詹姆斯令人記憶深刻的所謂世界的「雜亂無章」中。隨著新圖片以每秒幾十張的速度湧入視線,它必須做的第一件事就是學會將這些圖片組織成更大的圖片塊。真實的世界由持續存在一段時間的物體組成,而不是由從這一刻到下一刻隨意變換的像素組成。媽媽走開時,她還是她,不會被更小的媽媽代替。把一個盤子放在桌上,桌面不會出現白色的洞。如果一隻泰迪熊從屏幕裡經過,然後再出現時變成一架飛機,那麼幼小的嬰兒不會對此感到驚訝;但一歲小孩卻會。不知為什麼,他弄明白了泰迪熊和飛機不一樣,而且無法自行轉化。之後不久,他會弄明白有些物體和其他物體更像,然後開始進行分類。假定有一大堆馬形玩偶和鉛筆可以玩,9個月大的孩子不會將其分類成馬形玩偶和鉛筆兩個範疇,但一個18個月的孩子卻會。
將世界組織成客體和類別,對於成年人來說,這是第二天性;對於嬰兒來說卻不是;對於機器人羅比來說,更沒有可能。我們可以以多層感知器的形式賦予它視覺皮質,然後為它展示分類好的世界裡所有的客體和類別的例子——媽媽走近了,媽媽走遠了,但我們絕不可能做到。我們需要一種能夠自發將所有相似物體或者同一物體的不同圖片集中起來的算法。這就是聚類問題,這在機器學習當中也是人們研究最多的主題之一。
一個集群相當於一組相似的實體,或者以最低限度來說,一組相似的實體之間的相似度比和其他集群中的組成部分的相似度要大。對事物進行聚類,這是人類的天性,也是獲取知識的第一步。當我們仰望夜空時,會禁不住去看星座,然後根據形狀來為其命名。注意到某些元素組有很相似的化學屬性,這是發現元素週期表的第一步,那些相似元素現在就是元素週期表中的一列。我們察覺到的一切就是一個集群,從朋友的臉到說話聲。沒有這些,我們就會不知所措:在學會識別組成語言的獨特聲音之前,兒童無法學習語言。這需要他們在一歲時學習,而且如果沒有單詞指代的真實事物群集,他們學習的所有單詞就會沒有意思。面對大數據(大量的事物),我們首先採用的辦法就是把大數據分成若干更好處理的集群。比如,整個市場過於粗化,單個消費者又過於細微,因此市場營銷人員會將市場分成若幹部分,這些部分就成為集群。甚至物體本身也是觀察的底層集群,從由不同角度照射到媽媽臉上的光線,到寶寶聽到的關於「媽媽」一詞的不同聲波。沒有物體,我們就無法進行思考,也許這也是量子力學如此非直觀的原因:我們想把亞原子世界形象化,看作粒子碰撞或者波形干擾的世界,但這樣也並不真實。
我們可以通過集群的典型元素來表示該集群:你用心靈之眼看到母親的形象,或者典型的貓、跑車、郊區住宅和熱帶海灘。依據市場營銷知識,伊利諾伊州的皮奧瑞亞是典型的美國小鎮。鮑勃·伯恩斯是康涅狄格州溫德姆小鎮的一名房屋維修主管,今年53歲,是美國最普通的市民——如果你相信凱文·奧基夫《普通美國人》一書講的是對的,那麼至少是這樣的。任何由數字屬性描述的東西,比如人們的身高、體重、圍度、鞋碼、頭髮長度等,使得計算平均數變得簡單:他的身高就是所有集群成員的平均身高,他的體重就是所有體重的平均數……對於分類屬性來說,比如性別、頭髮顏色、郵政編碼或者最喜愛的運動,「平均」就是出現頻率最高的值。這組屬性描述的普通成員可能不是真實存在的人,但不管怎樣,它是十分有用的參考:如果你在進行頭腦風暴,考慮如何營銷新產品,把皮奧瑞亞當作產品發佈的地點,或者把鮑勃·伯恩斯當作目標客戶,這要比考慮「市場」或者「消費者」之類的抽像實體要好。
儘管這樣的平均值很有用,但我們可以做得更好。的確,大數據和機器學習的全部要點在於避免粗糙的思考。我們的集群可能是許多人組成的專業性很強的組,甚至是同一個人的不同方面:愛麗絲買工作用的書、休閒相關的書,或者作為聖誕禮物的書;愛麗絲心情好,或愛麗絲心情憂鬱。亞馬遜想把愛麗絲買給自己的書和送給男朋友的書區分開來,因為這樣可以使它在恰當的時間做恰當的推薦。不幸的是,採購不會貼著「自己的禮物」或者「鮑勃的禮物」標籤,而亞馬遜要懂得如何將這些進行分類。
假設羅比的世界中的實體分成五個集群(人類、傢俱、玩具、食物和動物),但我們不知道這些東西分別屬於哪個集群。當我們啟動羅比時,這就是它面臨的問題類型。將實體分類成集群的一個簡單方法,就是隨機挑選5個物體作為集群典範,再利用每個典範來對比每個實體,然後將其分到最相似典範的集群中(正如在類比學習中,相似度測量的選擇很重要。如果屬性是數值型的,它可能就與歐幾里得距離一樣簡單,但還有其他許多選擇)。這時我們就需要更新典範。畢竟,集群的典範就是其成員的平均化,儘管當每個集群中只有一個成員時情況也是如此,但通常這種情況不會出現在我們將一堆新成員加入每個集群之後。因此對每個集群來說,我們先計算其成員的平均特性,然後將其當作新的典範。這時,我們需要再更新集群的成員:因為典範已經移走,與給定實體最接近的典範可能也已經改變。我們可以把某個類別的典範想像成一隻泰迪熊,把另外某個類別的典範想像成一根香蕉。也許在第一輪,我們會把動物餅乾和熊歸為一類,但在第二輪中我們會把它和香蕉歸為一類。最初動物餅乾看起來像玩具,但現在它看起來更像食物。一旦我重新將動物餅乾歸入香蕉那一類,也許那個類別的典型項也已經改變,從香蕉變為餅乾。隨著實體被分到越來越恰當的集群中,這個良性循環會繼續下去,直到實體到集群的分配不再發生改變(因此集群典範也不再發生改變)。
該算法被稱為k均值算法(k–means algorithm),它的起源可以追溯到20世紀50年代。它精密、簡單、人氣很高,但有幾個不足,而其中的一些問題和其他問題相比較容易解決。例如,我們要提前確定集群的數量,但在真實世界中,羅比總會遇到新類型的物體。有一個選擇,就是如果某物與其他現存的物體迥然不同,那麼就讓物體開啟新的集群。另外一個選擇,就是允許集群分裂,然後隨著我們前進而合併。不論哪種方法,我們都會想讓算法偏向選擇更少的集群,以免我們最後以每個物體作為自己的集群而結束(如果我們想讓集群由相似物體組成,這很難辦到,但顯然這並不是目標)。
有一個更大的問題,那就是k均值算法只有在集群易於區分的情況下才能起作用:在超空間中,每個集群可看作一個球團,每個團距離彼此都很遠,而它們都有相似的體積,並包含相近數量的物體。如果其中的一個團出現故障,不好的事情就會發生:細長的集群會分成兩個不同的集群,較小的那個集群會被附近更大的集群吸收,以此類推。幸運的是,還有一個更好的選擇。
假設我們確認,讓羅比在真實世界中閒逛是一種過於緩慢、麻煩的學習方法。相反,就像飛行學員在飛行模擬器中進行學習一樣,我們會讓羅比觀看計算機生成的圖片。雖然知道圖片來自什麼集群,但我們不會告訴羅比。相反,我們生成每張圖片的方法,就是首先要隨意選擇一個集群(比如說玩具),然後綜合該集群中的一個例子(毛茸茸的、棕色的小泰迪有一雙黑色的大眼睛、圓耳朵,還戴著蝴蝶結)。我們還是隨意選擇例子的屬性:尺寸來自一個正態分佈的均值,比如10英吋,毛是棕色的概率為80%,否則就為白色,以此類推。當羅比看到許多圖片由這個方法生成後,它應該學會將它們分為人類、傢俱、玩具等類別中,因為人類和傢俱相比,人類更像人類。有一個有趣的問題:如果我們從羅比的角度看,它發現集群的最佳算法是什麼?答案讓人驚訝:樸素貝葉斯算法。我們開始瞭解該算法時,它是監督式學習的一種算法。區別在於現在羅比不知道類別,因此它得猜這些東西。
顯然,如果羅比不知道它們,事情就會一帆風順,因為在樸素貝葉斯算法中,每個集群都由其概率(17%生成的物體都是玩具)和集群成員當中每個屬性的概率分佈來定義(例如,80%的玩具是棕色的)。羅比可以估算這些概率,只要數清數據中玩具的數量,以及棕色玩具的數量等。為了做到這點,我們需要知道哪個物體是玩具。這看起來很棘手,但最後發現我們已經知道如何做到這一點。如果羅比有一個樸素貝葉斯算法分類器且要弄明白新物體的類別,它要做的就是應用分類器,然後在給定物體屬性的條件下計算每個類別的概率(小小的、毛茸茸的、棕色的、有大眼睛、戴著蝴蝶結?可能是玩具,也可能是動物)。
因此羅比面臨的是雞和蛋的問題:如果它知道物體的類別,就可以通過數數的方式來掌握類別的模型;如果它知道模型,可以推斷物體的類別。我們好像又遇到困難了,但遠非如此:只要在開始時,以你喜歡的方式來猜測每個物體的類別(即使是隨機的),然後你就有的忙了。從那些類別和數據中,你可以掌握類別模型;在這些模型的基礎上,你可以重新推導類別,以此類推。乍一看,這看起來像一個瘋狂的計劃:它可能絕不會結束,而是處在由模型推斷類別,到由類別推斷模型的永恆循環中。即使它停止了,也沒有理由相信會停在有意義的集群上。但1977年,來自哈佛大學的三個統計學家(亞瑟·鄧普斯特、南·萊爾德、唐納德·魯賓)表明,這個瘋狂的計劃其實可以生效:每次我們繞著圈走時,集群模型就會變得更好,而當模型是可能性的一個局部最大值時,循環結束。他們稱該計劃為期望最大化演算法(Expectation Maximization,EM算法),其中E表示期望(推斷預期的概率),而M代表最大化(估算可能性最大的參數)。他們還表明,許多之前的算法都是EM的特殊情況。例如,為了掌握隱馬爾科夫模型,我們交替進行以下工作:推斷隱藏狀態,在此基礎上估算過度和觀察概率。無論何時,當我們想掌握某個統計模型,但又缺乏一些關鍵信息時(例如,例子的類別),就可以利用EM。這使它在所有機器學習中成為最受歡迎的算法。
你可能已經注意到k均值算法和EM之間的某個相似性,因為它們都交替進行兩項工作:將實體分配給集群,然後更新集群的描述。這並不是一場意外:k均值本身就是EM的一種特殊情況,當所有屬性都會有「狹窄的」正態分佈時(有很小變量的正態分佈),你就會找到它。當集群重疊很多時,舉個例子,實體可能會歸屬於概率為0.7的集群A和概率為0.3的集群B。而在信息不丟失的情況下,我們無法決定它是否屬於集群A。EM會將其考慮進來,會將實體分配給兩個集群,然後根據依據來更新它們的描述。但是,如果描述非常集中,實體歸屬於附近集群的概率也總接近1,而我們要做的就是將實體分配給集群,以及對每個集群中的實體都進行平均化,以獲得其均值,這是典型的k均值算法。
到目前為止,我們只看到如何掌握集群的一個水平。當然,這個世界要豐富得多,集群中又有集群,一直到單個物體:活著的東西聚類成植物和動物,動物聚類成為哺乳動物、鳥類、魚類等,一直到寵物和家狗。沒問題,一旦我們掌握了集群組,就可以將其看作物體,然後反過來對其進行聚類,以此類推,直到對所有東西都進行聚類。或者,我們可以由粗略的聚類作為開始,然後將每一個集群分成亞集群,如羅比的玩具被分成填充動物玩具、組裝玩具等;填充動物玩具又可分為泰迪熊、長絨毛小貓等。兒童似乎會從中間開始,然後起起伏伏努力前進。例如,他們在學習「動物」或者「小獵犬」之前先學會「狗」這個詞,這對於羅比來說也許是一個很好的策略。
發現數據的形狀
數據湧入羅比的大腦,靠的是它的直覺,或者是數百萬個亞馬遜顧客的點擊流,將大量實體分類成更小數量的集群只是戰役的一半,另一半則會縮短每個實體的描述。羅比看到的媽媽的第一張照片也許包含100萬像素,每個像素都有自己的顏色,但你很少需要100萬個變量來描述臉部。同樣,在亞馬遜網站上點擊每一樣東西,都會提供關於你的一點信息,但亞馬遜真正想知道的是你喜歡什麼、不喜歡什麼,而不是你點擊的東西。前者非常穩定,在後者中可能會有點體現,當你利用網址時,後者會毫無限制地增長。漸漸地,所有這些鼠標點擊會增加對你的品位的瞭解,還附上一張圖,與那些像素聚集起來,形成你的品位的大致情況,這和所有那些像素合起來變成你的臉是一個道理。問題在於如何添加。
一張臉大約有50塊肌肉,因此50個數字足以用來描述所有可能的表情,而且還有很大的剩餘空間。眼睛、鼻子、嘴巴等的樣子(就是讓你區分於別人的特點)的數量也不應該超過幾十種。畢竟如果面部特點只有10個選擇,那麼警察局的拼圖師就能大概描繪出疑犯的肖像,足以用來認出他。你可以添加幾個數量,用來確定光線和姿態,這樣就差不多了。因此如果你給我100多個數量,就已經足以重新構造一張臉部圖片。相反,羅比的大腦應該可以儲存臉部圖片,然後快速簡化到真正起到作用的100個數量。
機器學習算法稱該過程為維數約簡,因為該過程將大量的可見維度(像素)簡化成幾個隱性維度(表情、面部特徵)。維數約簡對於應對大數據(像每秒鐘通過你的知覺而進入的數據)來說很關鍵。一張圖可能抵得上1000個字,但要處理和記住所做的付出,卻要高出100萬倍。你的視覺皮質好歹把大數據削減為數量上可管理的信息,足以用來引導這個世界、識別人和物、記住你看見的東西。這是認知最偉大的奇跡之一,並且如此自然,你甚至意識不到自己正在做這些事。
當你整理書櫃上的書時,會把類似的書放在一起,你正在做一種維數約簡,從廣闊的主題範圍到一個維數的書架。不可避免的是,有些書密切相關,最後在書架上卻離得很遠,但你還是可以想辦法避免這樣的情況再次發生。這就是維數約簡算法所做的工作。
假設我給你加利福尼亞州帕羅奧多市所有店舖的GPS(全球定位系統)坐標,然後你把其中的幾個畫在了一張紙上(見圖8–1)。
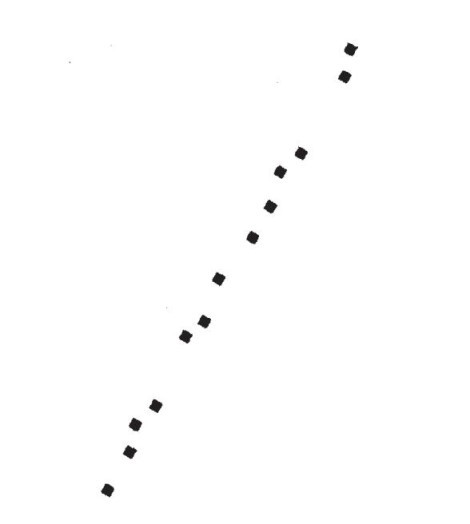
圖8–1
通過看圖8–1,也許你只能判斷帕羅奧多市的一條街道是西南—東北向。雖然沒有畫出街道,但你可以憑直覺知道它就在那裡,因為所有的點落在一條直線上(或者接近這條直線,可能在街道兩邊)。的確,這條街是大學街,如果你想在帕羅奧多市購物或吃飯,可以去那裡。你一旦知道大學街上的店舖,就可以不需要兩個數據來定位它們了,只要一個就可以:街道編號(或者,如果你真的想做到精確,從商舖到加利福尼亞站的距離,在西南角,此處正是大學街的起點)。
如果把更多的店舖畫上去,你可能會注意到有些在十字街上,距離大學街有點距離,還有幾個完全在別處(見圖8–2)。
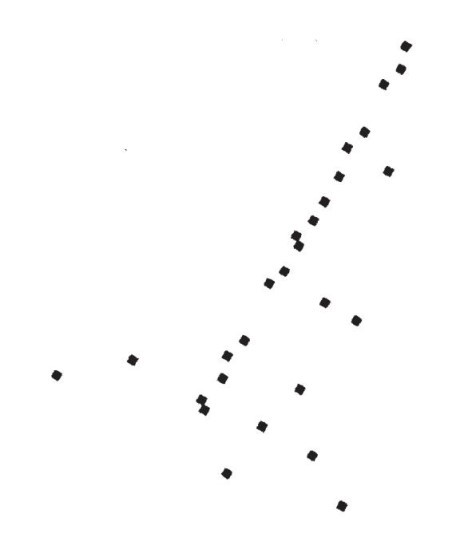
圖8–2
雖然如此,但大多數店舖還是靠近大學街。如果只給你一個數據來確定店舖的位置,那麼店舖到加利福尼亞站的沿街距離就是很好的選擇:走了那段距離之後,往周圍看也許就足以找到該店舖。所以,你把「帕羅奧多市店舖位置」的維數由二減到一。
雖然羅比沒有你的優勢(擁有高度進化的視覺系統),但如果你想讓它去伊利特洗衣店取洗好的衣物,你只要允許他的帕羅奧多市地圖有一個坐標,它就可以用一種算法從店舖的GPS坐標中「找到」大學街。完成這件事的關鍵在於要注意到,如果把x和y坐標的原點放在店舖地點的中心位置,然後慢慢地旋轉坐標軸,當旋轉大約60°時,店舖距離x軸最近,此時x軸與大學街近乎重合(見圖8–3)。
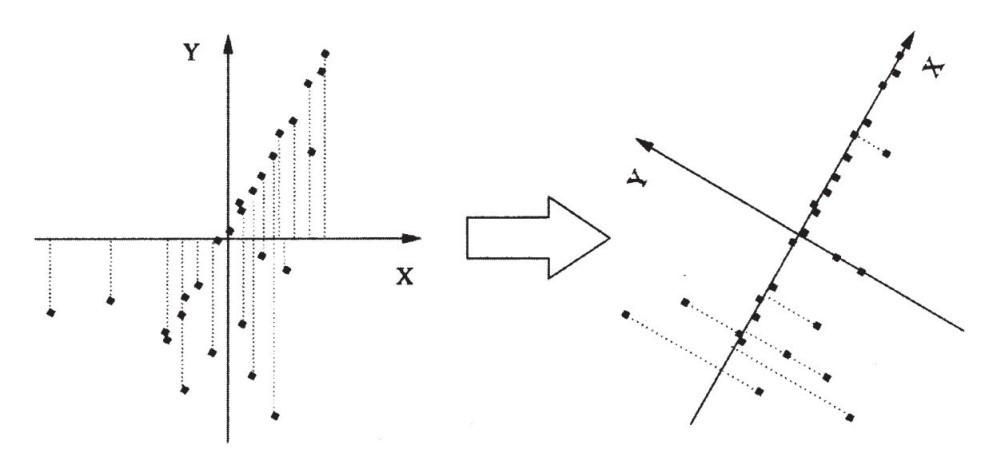
圖8–3
這個方向(人們稱之為數據的第一主成分)也是數據傳播最多的方向(請注意,如果你將商舖投在x軸上,在圖8–3的右圖中它們離得比左圖中的要遠)。你找到第一主要成分之後,可以找第二個,在這個例子中就是差別最大、與大學街成直角的方向。在地圖上,只剩下一種可能的方向(十字街的方向)。如果帕羅奧多市在山坡上,前兩個主要成分之中的一個將會部分處於上坡位置,第三和第四主要成分可能就懸在空中。我們可以將同樣的思想應用到幾千個或者幾百萬個維數中,比如面部圖片,不斷尋找最大差別的方向,直到剩下的變量很小,這時我們才能停下來。例如,在圖8–3中旋轉坐標軸之後,多數商舖的y=0,因此y的均值會很小,而我們不會因為忽略y軸的坐標而丟失過多的信息。而且如果我們決定保留y,那麼z(在空中)肯定也是無意義的。結果就是,尋找主要成分的整個過程,可以利用線性代數一次性完成。首先,幾個維度往往會造成高維度數據中大量的變異。雖然事實並非如此,但盯住前兩三個維度不放往往會產生許多洞見,因為它利用了你視覺系統的強大感知力。
主要成分分析(principle–component analysis,PCA),正如人們對該過程的瞭解,是科學家的工具箱中關鍵的工具之一。可以說,PCA與無人監督學習的關係,正如線性回歸與無人監督多樣性之間的關係。例如,眾所周知的全球變暖曲棍球桿曲線,就是找到各類溫度相關數據序列(樹的年輪、冰芯等)的主要成分並假設那就是溫度的結果。生物學家利用PCA來將幾千個不同的基因表達水平概括起來,變成幾條途徑。心理學家已經發現,個性可以簡化為5個維度(外向、隨和、盡責、神經質、開放性),他們可以通過你的推特文章和博客帖子來進行推斷(黑猩猩可能還有一個維度——反應性,但推特數據對它們並不適用)。把PCA應用到國會投票時,民意數據顯示,與普遍觀點相反,政治並不主要是自由黨與保守黨之間的競爭。相反,人們主要在兩個維度上存在差別:一個是經濟問題,一個是社會問題。我們一方面可以把這些黨派瓦解變成單一軸,然後與平民主義者和自由論者混合起來,這兩個派別會處於兩個極端,這樣就創造了有很多溫和派位於中間的假象。試圖成功吸引他們不太可能。另一方面,如果自由黨和自由論者消除了對對方的厭惡,那麼他們就可以在社會問題上進行聯盟,在這些問題上,雙方都支持個人自由。
當羅比長大了,可以利用PCA的一個變量來解決「雞尾酒會」問題,也就是從嘈雜的人群中辨認出單個聲音。相關的方法可以幫助它掌握閱讀能力。如果每個單詞就是一個維度,那麼在話語空間中,一篇文章就是一個點,而該空間的主要方向則是意思的成分。例如,「奧巴馬總統」和「白宮」在話語空間中相距很遠,而在意義空間上卻很接近,因為這兩個詞可能會出現在相似的背景下。信不信由你,計算機就需要這種類型的分析來對SAT(美國學術能力測驗)文章進行打分,並且做得和人類一樣好。網飛運用了相似的方法,不只是為有相同品位的用戶推薦電影,它首先會將用戶和電影納入更低維度的「品位空間」中,然後如果在該空間中某部電影接近用戶,那麼它就會向用戶推薦。利用這種方法,它可以向用戶推薦之前連用戶都不知道自己會喜歡的電影。
雖然如此,當你看到臉部數據集的主要成分時,可能會感到失望。因為它們並不像你期望的那樣會是面部表情或者某些特徵,它們看起來很猙獰,因為十分模糊而無法辨認。這是因為PCA屬於線性算法,因此所有可能的主要成分都是對真實臉部像素的平均值進行加權(也稱為「特徵臉」,因為它們是數據集中協方差矩陣的特徵向量,但我不同意這點)。為了真正瞭解面部,以及世界上的大部分形狀,我們需要另一樣東西——非線性降維算法。
假設我們縮小帕羅奧多市的地圖,而給你海灣地區主要城市的GPS坐標(見圖8–4)。
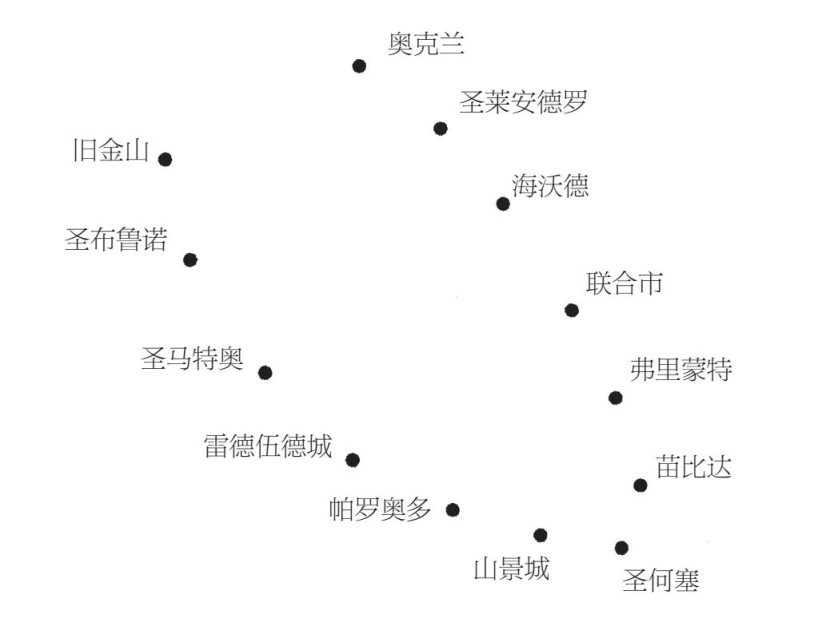
圖8–4
你可以再次僅僅通過看這張圖來猜測這些城市是在海灣上,如果你畫一條線穿過這些城市,可以僅利用一個數據就可以確定每個城市的位置:沿著這條線,該城市距離舊金山有多遠。但PCA無法找到這條線,相反,它會畫一條正好在海灣中間的線,當然,那裡並沒有城市。PCA完全沒有解釋數據的形狀,而是將其模糊化了。
想像一下我們打算從頭開始對海灣地區進行開發。我們已經決定每個城市的方位,預算允許我們鋪一條連接這些城市的公路。我們會鋪一條從舊金山到聖布魯諾,再到聖馬特奧,最後一直到奧克蘭的公路。這條公路是海灣地區很完美的一維表示方法,而且可以通過一種簡單的算法來實現:在每對附近的城市鋪一條路。當然,一般情況下這種做法會建成一個公路網絡,而不僅僅是一條每個城市都會使用的公路。我們可以強行鋪一條最接近該網絡的公路,從這個意義上講,城市之間在這條公路上的距離,也就可以盡可能地與在網絡上的距離相近。
對於非線性降維算法來說,最受歡迎的算法——等距映射算法,就可以實現這一點。在高維度空間中(比如一張臉),它可以把每個數據點與所有附近的點(很相似的臉)連接起來,依據得出的網絡計算每一對數據點之間的最短距離,然後找到與這些距離最接近的簡化坐標。與PCA相反,該空間中的「臉部坐標」往往意義重大:一個坐標可能表示臉部朝哪個方向(左剖面、半側面、正面等);另一個坐標表示這張臉的表情(非常傷心、有點傷心、不動聲色、開心、非常開心等)……從瞭解視頻中的動作到探測言語中的情緒,等距映射算法有驚人的能力,可以對準複雜數據中最重要的維度。
這是一個有趣的實驗。從羅比的眼睛中提取出視頻流,在圖片空間中把每個框架當作一個點,然後簡化那組圖片變成單個維度。你會發現什麼?時間。就像圖書管理員整理書架上的書,時間會將每張圖片放置在與之最接近的圖片旁邊。也許我們對它的感知,僅僅是大腦降維技術的自然結果。在記憶這個道路網絡中,時間是主要的通道,而我們很快就能找到它。時間,換句話說,就是記憶的主要成分。
擁護享樂主義的機器人
聚類和維度簡化雖然使我們更加靠近人類學習,但仍丟失了一些很重要的東西。孩子們並不只是消極地觀察這個世界,他們會行動,會將看到的東西撿起來,和這些東西玩、到處跑、吃東西、哭、問問題。如果無法幫助羅比與周圍環境互動,那麼最先進的視覺系統也毫無用處。羅比不僅要知道東西的位置,也要知道每一刻該做什麼。原則上,我們可以教會它使用步進指令(step–by–step instruction),把傳感器讀數和正確的行為組成一對,但這只對精密任務可行。採取什麼樣的行為由你的目標決定,而不僅取決於當前感知到的所有東西,這些目標也許只有在遙遠的未來才能實現。在任何情況下,步進監督(step–by–step supervision)都不應該被採用。家長不會教自己的孩子爬、走或者跑,他們都是自己摸索。目前為止,所有的學習算法都不能做到這一點。
人類確實有穩定的嚮導:情感。我們追求快樂,躲避痛苦。當你碰到熱的爐子時,會本能地縮手。這是簡單的部分,困難的部分在於學習如何一開始不去碰那個爐子。你需要移動手指以避免之前沒有感受過的刺痛。為了避免這種刺痛感,大腦要將它和你碰爐子的那一刻,以及導致這種劇痛的動作聯繫起來,愛德華·桑代克稱該過程為「效果律」(law of effect)。人們更有可能重複引起愉悅感的動作,而導致疼痛感的動作則不太可能重複。過去的愉悅感可以穿越,可以這麼說,而行為最終可以與那些離得很遠的效果相聯繫。和其他動物相比,人類能更好地完成這種遠程追求獎賞的任務,而且這對我們的成功也很重要。在一個著名實驗中,工作人員在孩子們面前展示了棉花糖,並告訴他們如果可以堅持幾分鐘不吃棉花糖,就會得到兩朵棉花糖。那些能成功做到這一點的孩子在學校生活、成人後的生活中表現得會更好。也許不那麼明顯,但利用機器學習來改善其網頁和業務的公司也會面臨相似的問題。這些公司可能會因為短期利益而做出改變,比如銷售成本較低的劣質商品,以賺取同等價格優質商品的差價。這種做法忽略了一點:從長遠看,這樣的商家會失去顧客。
前幾章中學習算法都由「即時滿足」這一原則引導:每個行為,無論是標記垃圾郵件,還是購買股票,都會從「老師」那裡得到即時獎勵(或者處罰)。有一個機器學習的子域致力於這樣的算法:進行主動探索,偶然得到獎勵,然後弄清楚將來怎樣才能再得到獎勵。這很像嬰兒到處爬和把東西放到嘴裡。
這個過程稱為「強化學習」,你的第一個家用機器人可能會經常用到這種方法。如果你剛打開羅比的包裝,並啟動它,就讓它來為你煎雞蛋和培根,它可能需要點時間。然而,在你工作的時候,它會自己探索廚房,注意各類東西的位置,以及你用哪種爐子。你回來的時候,飯菜已經做好了。
強化學習的一個重要先驅是跳棋遊戲程序,這是IBM的研究員阿瑟·塞繆爾於20世紀50年代編寫的。棋盤遊戲是強化學習問題的典範:你得走好多步棋,卻得不到任何反饋,獎勵或懲罰都在最後一刻揭曉,其形式也就是贏和輸。塞繆爾的程序可以自學下棋,而且下得和大多數人一樣好。它不會直接學棋盤上每步棋該怎麼走,因為這太困難;相反,它會學習如何評價每個棋的位置(從該位置出發,贏的概率有多大),然後選擇走能到達最佳棋位的那一步。起初,它知道如何進行評價的唯一位置就是最後的結果:贏、平局或是輸。一旦它知道某個特定位置能贏,也就知道哪些位置有利於讓它達到這個位置。IBM前總裁小托馬斯·沃森就預測,該程序被證實之後,IBM的股票會上漲15個點。最後,它被證實了。這個教訓並沒有被IBM忽略,後來IBM製造了一個國際象棋冠軍和一個《危險邊緣》冠軍。
強化學習的首要思想是:並不是所有的狀態都有獎勵(正面或者負面),但每種狀態都會有價值。在棋類遊戲中,唯獨最後的位置才有獎勵(比如1、0、–1,分別代表贏、平局或者輸)。雖然其他位置沒有即時獎勵,但有價值,因為通過這些位置可以得到最後的獎勵。因為某個位置在某步棋時可起到「將死」(棋類術語)的作用,從實踐角度看,這相當於贏一盤棋,所以有較高的價值。我們可以將這種推理方式傳播至好的與壞的開場走法中,即使在那個距離內連接完全不明顯。在視頻遊戲中,獎勵通常是分數,而一種狀態的價值就是從該狀態開始你能積累的分數。在現實生活中,即時獎勵要好於未來獎勵,投資也一樣,未來獎勵的回報率可能會打折扣。當然,獎勵取決於你選擇什麼行為,強化學習的目標往往是採取那個能獲得最豐厚獎勵的行為。你該不該打電話約你的朋友出來約會?這可能會是一段美好關係的開始,或者你只會得到一個痛苦的回絕。即使你的朋友答應約會,這個約會的結果可能好也可能壞。從某種程度上說,你得概括所有未來可能會走的道路,然後現在做決定。強化學習通過估算每種狀態的價值來做到這一點,從該狀態開始你所期望得到的全部獎勵,然後選擇能將獎勵最大化的行為。
假設你在一條隧道中行走,像印第安納·瓊斯那樣,然後你到了一個三岔口。地圖顯示左邊的隧道通往寶藏,右邊的則通往蛇洞。你所站位置的價值(就在三岔口前)也就是寶藏的價值,因為你會選擇往左走。如果你總是選擇最佳可能的行為,那麼某個狀態的價值與成功狀態的價值的差異,僅僅在於你因實施該行為而獲得的即時獎勵(如果有)。如果我們知道每種狀態的即時獎勵,就可以利用這個觀察來更新相鄰狀態的價值,以此類推,直到所有狀態都會有一致的價值。寶藏的價值會沿著隧道反向傳播,直到到達岔路口或者超過這個地方。你一旦知道每種狀態的價值,就可以知道在每種狀態中該採取什麼行動(能夠將即時獎勵和最終狀態價值最大化的行動)。這很大程度是由控制論理論家理查德·貝爾曼解決的,但強化學習中真正的問題會在你沒有某區域的地圖時出現。你唯一可做的就是探索並發現獎勵在哪裡。你可能發現寶藏,也可能陷入蛇洞。每當你要採取行動時,就會注意即時獎勵和最終狀態,這很大限度上可以由監督式學習來實現。但你還是得更新你採取行動後的狀態的價值,使其與剛剛觀察的價值一致,也就是說,你獲得的獎勵加上所處新狀態的價值。當然,這個價值可能並不準確,但如果你已經花了足夠長的時間來邊徘徊邊做這件事,那麼最終會停在所有狀態的正確價值以及對應行動上。簡言之,這就是強化學習。
請注意強化學習算法如何面對我們在第五章遇到的利用—探索困境:為了使獎勵最大化,你很自然地想選擇能達到高價值狀態的行動,但這可能會阻止你發現其他價值更高的獎勵。強化學習算法解決這個問題的方法是時而選擇最佳行動,時而隨機選擇(為此,大腦甚至似乎有一台「噪聲發生器」)。早些時候有很多可以學習的東西,進行大量探索就會很有意義。一旦你發現了某個區域,最好集中精力來使用它,這就是人一生要做的事:兒童會去探索,成年人想著如何使用(除了科學家,因為他們是永遠的孩子)。兒童的遊戲比表面看起來要嚴肅。如果進化過程產生一個沒有用的生物,並在出生後的幾年給其父母帶來沉重負擔,那麼付出這麼大的成本一定是為了更豐厚的利益。實際上,強化學習就是一種加速進化過程——嘗試、丟棄,然後在單個生命的一生而不是幾代中改進行動——有了這個標準,它的效率就會很高。
對於強化學習的研究自20世紀80年代早期才正式開始,馬薩諸塞大學的裡奇·薩頓和安迪·巴爾托參與了研究工作。他們認為學習取決於與環境的互動,這一點很關鍵,但監督算法並沒有發現這一點;而且他們在動物習得心理學領域找到靈感。薩頓成為強化學習的主要倡導者。另一個關鍵進展發生在1989年,當時劍橋大學的克裡斯·沃特金斯在兒童學習實驗發現的推動下,實現了強化學習的現代形式,即在未知環境中進行最優控制。
然而,到目前為止,我們看到的強化學習算法還不是很現實,因為它們在某個狀態中不知道該做什麼,除非它們之前進入過那種狀態,而在現實世界中,並沒有哪兩個情形是完全相似的。我們需要對之前所處的狀態到新狀態進行概括。幸運的是,我們已經知道該如何做到這一點:用強化學習來將之前見過的一個監督式學習算法(例如,多層感知器)包括進來。這時神經網絡的工作就是預測狀態的價值,而反向傳播的誤差信號就是預測價值與所觀察到的價值之間的差別。還存在一個問題:在監督式學習中,某個狀態的目標價值總是一樣的;但在強化學習中,它會不斷變化(這是達到附近狀態的結果)。因此,帶有歸納性的強化學習往往無法確定穩定的解決方法,除非內部學習算法很簡單,就像線性函數那樣。雖然如此,帶有神經網絡的強化學習已經取得一些顯著成就。早期的成就包括製造出具備人類水平的西洋雙陸棋選手。最近的一種強化學習算法,來自DeepMind(倫敦的一家創業公司),在電視體育遊戲及其他簡單的大型電玩中打敗了一位專家級的人類選手。它利用深層網絡來從控制台屏幕低像素的動作中預測其價值。有了端對端的視野、學習和控制,該系統與人工大腦至少有一點相似之處。這可以解釋為什麼DeepMind是一家沒有產品和利潤,員工也寥寥無幾的公司,但谷歌卻向它投了5億美元。
除了遊戲,研究人員還可以利用強化學習來平衡極點、控制簡筆畫的體操運動員、使汽車倒車入位、駕駛直升機顛倒飛行、管理自動電話對話、分配手機網絡中的頻道、調度電梯、安排航天飛機貨運裝載等。強化學習也對心理學和神經科學產生了影響。大腦利用神經遞質多巴胺來傳播期望獎勵與實際獎勵之間的區別。強化學習解釋了巴甫洛夫條件反射作用,但不像行為主義,它允許動物有內部心理狀態。覓食的蜜蜂會利用它,在迷宮中找到奶酪的老鼠也是如此。你的日常生活由一連串你很少注意到的、由強化學習形成的奇跡組成。你起床、穿衣服、吃早餐,然後開車去上班,這些過程中你一直在思考別的事情。實際上,強化學習會不斷精心安排和調整這個奇妙的動作交響曲。強化學習片段(為習慣)組成大多數你做的事。當你覺得餓了時,會走到冰箱前,拿一點零食。正如查爾斯·杜希格在《習慣的力量》一書中表明的那樣,理解並控制由線索、日常、獎勵組成的循環關係是成功的關鍵,不僅對個人,而且對企業甚至整個社會來說都是這樣。
作為強化學習的創始人,裡奇·薩頓是最具有熱情的。對於他來說,強化學習就是終極算法,而且解決了這個問題就相當於解決了人工智能問題。但克裡斯·沃特金斯卻並不滿意。他看到許多兒童能做但強化學習算法做不了的事:解決問題,經過幾次嘗試之後能更好地解決問題,制訂計劃,獲取逐漸抽像的知識。幸運的是,對於這些較高水平的能力,我們也有相應的學習算法,其中最重要的就是組塊算法。
熟能生巧
學習的目的就是為了更好地實踐。你現在可能記不得學著繫鞋帶有多難了。一開始,你完全學不會,雖然當時你已經5歲了。接著,你的鞋帶鬆開的速度比你系的速度還要快。慢慢地,你學會更快、更好地繫鞋帶了,直到你不自覺地繫鞋帶。很多其他事情也是同樣的道理,比如爬、走、跑、騎單車、開車、閱讀、寫作、算術、演奏樂器、進行體育活動、做飯和使用計算機等。諷刺的是,人在最痛苦時學到的東西往往最多。在早期,每一步都很艱難,你不斷失敗,即便你成功了,結果也並不會有多好。當你掌握高爾夫揮桿動作或者網球發球之後,可能會花幾年完善這些技能,但這些年你取得的進步會比開始學時的前幾周少很多。通過練習你會做得更好,但不會以恆定的速度進步:一開始你進步很快,接下來就沒那麼快了,最後變得很慢。無論是玩遊戲還是彈吉他,技能提高時間曲線圖(你做某事的表現或者做某事所花費的時間)有一個非常特殊的形式(見圖8–5)。
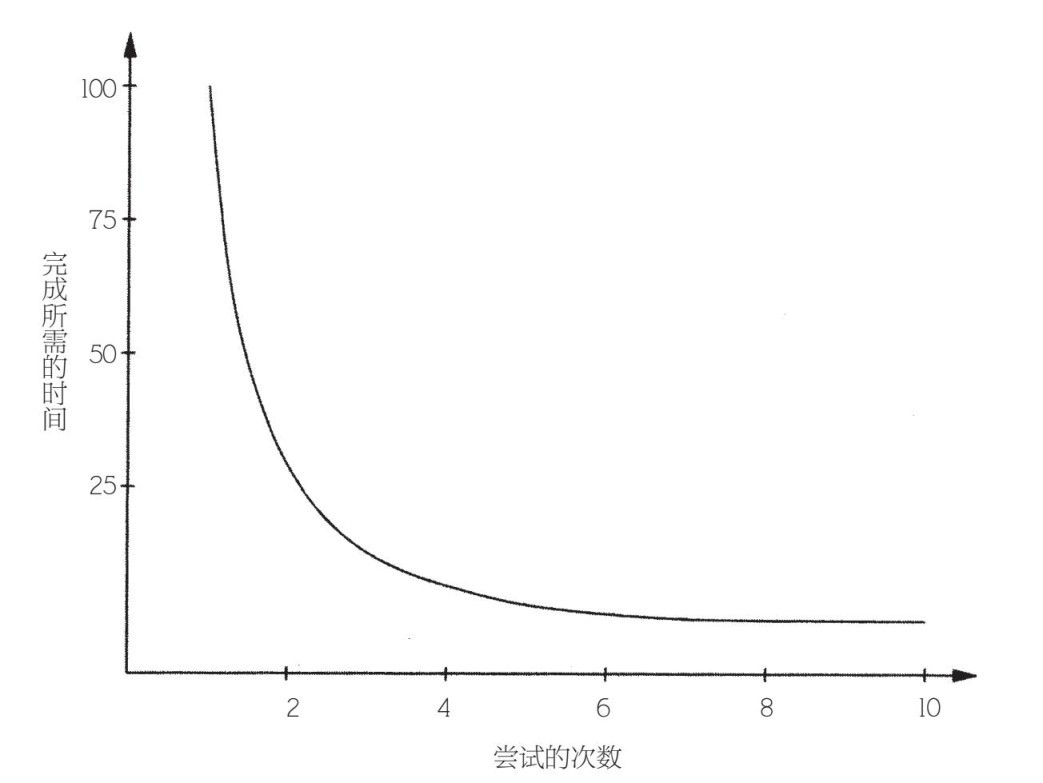
圖8–5
這種類型的曲線被稱為「冪法則」(a power law),因為隨著時間達到某負冪時,表現會出現變化。例如,在圖8–5中,完成所需的時間與嘗試的次數的負二次方成正比(或者相當於1除以嘗試次數的平方)。幾乎每項人類技能都會遵循冪法則,不同的冪會對應不同的技能(相反,Windows系統則不會隨著實踐次數的增多而變快——這是微軟該解決的問題。)
1979年,艾倫·紐厄爾和保羅·羅森布魯姆開始探索這個所謂的「冪法則」實踐存在的原因。紐厄爾是人工智能的創始人之一,也是主要的認知心理學家,而羅森布魯姆則是他在卡內基–梅隆大學的研究生之一。當時,沒有哪個實踐模式可以解釋冪法則,紐厄爾和羅森布魯姆懷疑這可能與組塊有關。組塊是一個來自感知與記憶心理學的概念。我們以組塊的形式來感知並記住東西,而在任意給定的時間內(根據喬治·米勒的經典論文的結論為7±2),我們只能通過短暫記憶來記住這麼多組塊。關鍵是將信息聚集成組塊可以讓我們處理得更多,否則我們處理不了那麼多信息。這就是電話號碼有連字符的原因:1–723–458–3897比17234583897要好記得多。赫伯特·西蒙(紐厄爾的長期合作夥伴以及人工智能的共同創始人)早期已經發現,新棋手和專業棋手的主要區別在於,新棋手一次記一個象棋位置,而專業棋手則看到涉及多個位置、更大的模式。要提高國際象棋技能主要涉及獲取更多、更大這樣的組塊。紐厄爾和羅森布魯姆假設,在掌握所有技能而不僅僅是下棋技能中,類似的過程在起作用。
在感知和記憶中,組塊僅僅是一種符號,代表了其他符號的模式,就像AI代表人工智能。紐厄爾和羅森布魯姆將這個思想運用到紐厄爾和西蒙早期創建的問題解決理論中。紐厄爾和西蒙讓實驗對像解決問題,例如,在黑板上利用一個數學公式推導出另外一個數學公式,同時大聲描述他們如何得到這個公式。他們發現,人類解決問題的方式是將問題分解為小問題,再將小問題再分解為更小的問題,然後系統地減少初始狀態(比如第一個公式)與目標狀態(第二個公式)之間的差異。然而,這樣做需要找到能起作用的行動順序,這需要時間。紐厄爾和羅森布魯姆的假設是,每次當我們解決一個小問題時,會形成一個組塊,這樣我們就可以直接從解決問題前的狀態進入解決問題後的狀態。這種意義下的組塊有兩個部分:刺激(你從外部世界或者短暫記憶中識別出的模式)和反饋(你因此而執行的行動順序)。一旦掌握一個組塊,你就會將其儲存在長期記憶中,下次你解決同樣的小問題時,就可以直接應用該組塊,會節省尋找的時間。這個過程在所有水平層面都會發生,直到你找到一個能解決所有問題的組塊,並且能夠自行解決這些問題。為了繫好你的鞋帶,先打結,然後用一端栓個套,用這個套繞住另一端,然後將其從中間的洞穿過。對於5歲的孩子來說,這些並不簡單,可一旦你掌握相應的組塊,就差不多學會了。
紐厄爾和羅森布魯姆將他們的組塊程序應用於解決一系列問題,測量它在每次嘗試中花費的時間,這就彈出一系列冪法則曲線。但這僅僅是開始,接下來他們將組塊併入「猛增」(Soar)理論中,這是紐厄爾和另一個學生約翰·萊爾德一起創建的一般認知理論。「猛增」程序不僅為某個預設了等級的目標而努力,當每次遇到障礙時,還都可以定義並解決新的子問題。一旦它形成新的組塊,「猛增」程序就會對其進行一般化,以應用到相似的問題中,這與逆向演繹的方式類似。除了冪法則實踐,「猛增」中的組塊最後成為許多學習現象的良好模型。通過對數據和類推法進行組塊,它甚至可以應用到掌握新知識中。於是紐厄爾、羅森布魯姆、萊爾德做出這樣的假設——組塊是學習所需的「唯一」機制,換句話說,就是終極算法。
作為典型的人工智能類型,紐厄爾、西蒙及其學生和擁護者都非常相信問題解決的重要地位。如果問題解決者很強大,那麼學習算法就會依賴其能力而變得簡單。的確,學習只是另外一種問題的解決方式。紐厄爾和同伴共同努力,將所有學習簡化為組塊,將所有認知簡化為「猛增」程序,最後他們失敗了。其中一個問題是,嘗試這些步驟的成本變得很高,程序變得越來越慢。從某種程度上說,人類要避免這一點的發生,但到目前為止,該領域的研究人員還找不到解決方法。最重要的是,嘗試將強化學習、監督式學習,以及別的一切簡化成組塊,基本上會製造更多的問題,而不會解決問題。最終,「猛增」的研究人員承認失敗,然後將那些其他類型的學習作為分離機制併入「猛增」。雖然如此,組塊還是學習算法的典型例子,受到心理學的啟發,還是真正的終極算法。無論它最後變成什麼,肯定會分享其通過實踐得到提升的能力。
組塊和強化學習在商業中的應用不如在監督式學習、聚類或者維數簡約中廣泛,但是通過與環境互動進行的相似學習類型是掌握行動(或相應行動)的效果。如果現在你的電子商務網站主頁的背景是藍色的,你在想讓它變成紅色會不會提高銷量,那麼可以將紅色網頁用在10萬個隨機挑選的用戶身上試試看,然後將結果與常規網站進行比較。這種手法稱為A/B測試,起初主要用在藥物試驗中,之後運用到許多領域。在這些領域中,數據可以根據需要集中起來,從營銷到對外援助。它還可以概括成一次性嘗試許多變化組合,而不會忽略什麼樣的改變會帶來什麼(或者失去什麼)。諸如亞馬遜、谷歌之類的公司對此深信不疑,你可能已經不知不覺參與了幾千項A/B測試。A/B測試證明常聽到的批評言論的錯誤:大數據只對尋找相關關係有好處,對尋找因果關係則沒用。除了哲學要點,掌握因果關係就是掌握行動的效果,而任何有數據流並能影響數據流的人都能做到這一點——從一歲孩子在浴缸中戲水到總統再次參加競選。
學會關聯
如果我們賦予羅比機器人在本書中提到的所有學習能力,它會變得很智能,但還會有點孤僻。它會把世界看成一群獨立的物體,可以對其進行識別、操縱甚至預測,但它不理解世界是一張相互聯繫的網絡。羅比醫生會很擅長根據病人的症狀來診斷其患有感冒,但無法猜想這個病人患的是豬流感,因為它和感染該疾病的人有過接觸。在谷歌出現之前,搜索引擎會通過看它的內容來決定某網頁是否與你的搜索相關——還有別的嗎?布林和佩奇的觀點是,與該網頁相關的最明顯標誌在於,相關的網頁會與它有鏈接。同樣的道理,如果你想預測某個青少年是否有開始吸煙的危險,到目前為止,你能做得最有效的事就是調查他的好朋友是否吸煙。一種酶的形狀與其分子形狀的關係,就像鎖與鑰匙的關係一樣不可分割。捕食者與獵物有纏繞很緊的屬性,每種屬性會進化出打敗對方的屬性。在所有這些例子中,瞭解一個實體的最佳方法——無論它是人、動物、網頁還是分子——就是瞭解它如何與其他實體進行連接。這就需要一種新的學習方式:不會將數據當作不相關物體的隨機樣本,而是對複雜網絡的一瞥。網絡中的節點會互相作用;你對這個節點做了什麼,會影響到其他節點,最後還會返回來對你進行影響。關聯學習算法,正如它們的名字那樣,也許不太有社交智能,但它們將是最好的東西。在傳統統計學習中,每個人都是一座島,與世隔絕;在關聯學習中,每個人都是一塊陸地,是主要大陸的一部分。人類是關聯學習者,被相互連接起來,我們如果想讓羅比成長為一個有知覺、擅長社交的機器人,就需要對它進行布線,然後連接。
我們面臨的第一個困難就是,當數據變成整個大網絡時,似乎就沒有許多例子來學習了,只剩一個,而且這不夠。樸素貝葉斯算法通過數發燒流感病人的數量來知道發燒是感冒的一種症狀。如果它只能看到一位病人,可能會得出結論:流感總會引起發燒,或者不會引起發燒。這兩個結論都是錯的。我們想確認流感是傳染性疾病,方法就是通過觀察在社交網絡中的感染模式——感染的人群在這邊,沒有感染的人群在那邊——但我們只能看到一個模式,即使它處於70億人的網絡中,因此如何概括尚不清晰。關鍵在於要注意到,嵌入該網絡中,我們有許多對人的實例。如果熟人與未曾相見的人相比,更有可能患流感,那麼認識流感病人也會讓你成為流感病人的可能性增大。然而,不幸的是,我們不能只數數據中都患流感的熟人的對數,然後把這些數變成概率。因為一個人可以有許多熟人,而所有成對的概率不會總計為相關模式。舉個例子,該模式會讓我們計算在給定他們熟人的情況下,計算某人得流感的概率。當例子都分開時,我們就不會有這樣的問題了,我們也不會關注這個例子,比如丁克家庭中,每個人都住在自己的「荒島」上。這並不是真實世界,而且無論如何,這裡絕對不會有什麼流行病。
解決辦法就是找到一組特徵,並掌握它們的權值,就像在馬爾科夫網絡中那樣。對於每個人(X),我們可以有「X患有流感」的特徵,對於每對熟人X和Y,特徵就是「X和Y患有流感」,等等。正如在馬爾科夫網絡中那樣,最大似然權值使每個特徵以在數據中觀察到的頻率出現。如果有很多人患有流感,那麼「X患有流感」的權值就會比較高。如果當X患有流感時,熟人Y也患有流感的概率會比隨機抽選的網絡成員患有流感的概率大,因此「X和Y都患有流感」的權值會較高。如果40%的人有流感,那麼16%的所有熟人兩人組也會患有流感,那麼「X和Y都患有流感」的權值將等於零,因為我們不需要該特徵來準確複製數據的統計(0.4×0.4=0.16)。如果特徵的權值為正,流感更有可能發生在人群當中,而不會十分容易隨機感染某個人。也就是說,如果你熟悉的人患有流感,那麼你感染流感的概率會更大。
請注意,網絡會為每對熟人賦予分離的特徵,比如愛麗絲和鮑勃都患有流感,愛麗絲和克裡斯都患有流感,等等。但我們無法為每個兩人組確定一個分離權值,因為他們只有一個數據點(無論是否受感染了)。對於尚未確診的網絡成員,我們不能將他們一概而論(伊薇特和扎克都患有流感嗎)。我們只能在自己見過的所有實例的基礎上,為相同形式的所有特徵確定一個權值。實際上,「X和Y患有流感」是特徵模板,可以利用每對熟人進行實例化(愛麗絲和鮑勃,愛麗絲和克裡斯,等等)。模板的所有實例的權值被「捆綁在一起」,從這個意義上講,它們有同樣的價值。也就是說,即便只有一個實例(整個網絡),我們也可以進行推理。在非關聯學習中,一個模型的參數僅以一種方式捆綁——越過所有獨立例子(比如所有被診斷過的病人)。在關聯學習中,每個我們創造的特徵模板將捆綁所有實例的參數。
我們不僅限於成對的或者單獨的特徵。臉書想預測哪些人是你的朋友,這樣才能為你推薦朋友,為此它可以利用「朋友的朋友可能成為朋友」這個規則,因為每個實例都涉及三個人。比如,如果愛麗絲和鮑勃是朋友,而鮑勃和克裡斯也是朋友,那麼愛麗絲和克裡斯有可能成為朋友。H·L·門肯說過一句妙語:如果一個人掙的錢比他的妻子的妹妹的丈夫要多,那麼他就是富有的。這句話涉及四個人。這些規則中的每一條都可以變成關聯模型中的特徵模板,而在特徵出現在數據中的頻率的基礎上,可以確定它的一個權值。正如在馬爾科夫網絡中那樣,特徵也可以通過數據確定。
關聯學習算法可以從一個網絡推廣到另一個網絡(比如確定流感如何在亞特蘭大傳播的模型,然後在波士頓運用),它們也可以在多個網絡上學習(比如亞特蘭大和波士頓,假設亞特蘭大沒有人和波士頓人有聯繫)。不像「常規」學習,這裡所有的例子必須有同等數量的屬性。在關聯學習中,網絡可以在大小方面有所不同。同樣的模板,較大的網絡會比較小的網絡有更多的實例。當然,從較小的網絡到較大的網絡的推廣可能準確,也可能不準確,需要指出的是,沒有什麼會阻止它。從局部上看,大型網絡往往和小型網絡的表現沒有差異。
關聯學習算法能達到的最佳效果就是讓懶散的老師變得勤奮。對於普通分類器來說,沒有歸類的例子毫無用處。如果我只知道病人的症狀,卻不知道診斷結果,那麼這對我學習看病毫無幫助。如果我知道患者的一些朋友感染了流感,那麼可能間接證明他也感染了流感。在一個網絡中確診幾個人,然後將這些診斷結果推測到他們的朋友,以及他們朋友的朋友身上,這就是接下來診斷所有人的最佳做法。推測出來的診斷結果可能有干擾因素,但關於症狀如何與流感相關聯的整體統計,與只有幾個診斷結果可利用相比,前者要準確和完整得多。孩子很擅長充分利用他們受到的分散式監督(只要不選擇忽略它),關聯學習算法也有部分這樣的能力。
然而,這種力量也是要付出代價的。在普通分類器中,比如決策樹或者感知器,從實體的屬性推斷出其類別,這就涉及幾次查找工作和一些計算。在一個網絡中,每個節點的類別間接取決於所有其他節點,而我們不可以孤立地對其進行推斷。我們可以求助於同樣用於貝葉斯網絡的推理技術,比如環路信念傳播或者MCMC,但數值範圍是不一樣的。典型的貝葉斯網絡可能會有幾千個變量,但典型的社交網絡卻有數百萬個節點甚至更多。幸運的是,因為網絡模型由許多有相同權值的相同特徵不斷重複形成,我們往往可以將網絡壓縮變成「超節點」,每個超節點由許多節點組成。我們知道這些節點有相同的概率,而且會解決許多更細小的問題,結果也完全相同。
關聯學習有悠久的歷史,其歷史可以至少追溯到20世紀70年代,以及符號學派技巧(如逆向演繹)。但隨著互聯網的出現,它需要新的動力。突然之間,網絡變得無處不在,而對網絡進行模仿變得刻不容緩。我發現有一個特別有趣的現象——口碑傳播。信息如何在社交網絡中傳播?我們可否測量每個成員的影響力,然後將目標確定在數量夠多、影響力最大的成員身上,以開啟一輪口頭傳播?我和學生裡特·理查森一起設計了一種算法就能夠做到這一點。我們將其運用到Epinions網頁(一個產品評論網站)上,可以允許成員說出他們信任誰的評論。研究發現之一是,向單個最有影響力的成員營銷產品(該成員被許多擁護者的信任,而這些擁護者也被自身的擁護者信任等)和對1/3的所有成員進行推銷相比,效果是一樣的。隨之而來的是一大批關於此問題的研究。此後,我就已經開始將關聯學習應用到其他許多領域,包括預測誰會在社交網絡中形成鏈接、整合數據庫、使機器人能夠繪製周圍環境的地圖。
如果你想瞭解世界如何運轉,那麼關聯學習就是很好的工具。在艾薩克·阿西莫夫的《基地》一書中,科學家哈里·謝頓可以從數學角度預測人類的未來,從而將其從衰落中拯救出來。此外,保羅·克魯格曼也承認,就是這個誘人的夢想,讓他成為一名經濟學家。依據謝頓的觀點,人類就像氣體中的分子,大數法則保證,即使個人無法預測,整個社會卻可以。關聯學習表明事實並非如此,如果人類是獨立的,每個人孤立地做決定,社會的確就會變得可預測,因為所有那些隨意的決定會合計為一個相當恆定的均值。但當人們互動時,較大的集合體會比較小的集合體更不那麼可預測。如果信心和恐懼可以傳染,每種情緒都會主導一段時間,但常常整個社會會從這種情緒轉化到另一種情緒。雖然如此,並不是所有消息都是壞的。如果我們可以估計人們之間相互影響的強度,也就可以估計這種轉換在多久之後會發生,即使這是第一次轉換。換個說法,黑天鵝並不一定不可預測。
對於大數據,抱怨較普遍的就是擁有的數據越多,就越容易在大數據中發現偽模式。如果數據僅僅是一大組分離的實體,那麼這一點可能正確;但如果它們相互關聯,情況就不一樣了。例如,那些利用數據挖掘來逮捕恐怖分子的批評者認為,除了倫理問題,這絕不會起作用,因為無辜的人太多,而恐怖分子卻極少,因此它要麼會引發過多的錯誤警報,要麼不會逮捕任何人。當某個遊客或者恐怖分子在劃定爆炸地點的範圍時,有人對紐約市政廳進行錄像了嗎?購買大量硝酸銨的人是農民還是爆炸製造者?所有這些人單獨看都很無辜,但如果「遊客」和「農民」一直保持密切的電話聯繫,而後者只是開著他的拉登皮卡進入曼哈頓,可能是時候需要一個人來盯緊他了。美國國家安全局喜歡搜尋誰給誰打過電話的記錄,這不僅僅因為可以說這是合法的,而且因為對於預測算法來說,它們往往比通話內容的信息量更大,而通話內容需要人進行分析才能被理解。
除了社交網絡,關聯學習的殺手級應用正在瞭解活細胞如何運作。一個細胞是一個複雜的代謝網絡,在這個過程中,基因為蛋白質編碼,蛋白質又調節其他基因,還有一長串的化學反應,而產物會從這個細胞器運輸到另一個細胞器。獨立的實體,孤立地進行工作,找不到任何蹤影。治癌藥物必須在不干擾正常細胞的情況下,打破癌細胞的運轉。如果我們有兩者準確的關聯模型,就可以在計算機中嘗試許多不同的藥物,讓模型推斷它們好的以及不好的效果,然後只將最好的留下,先從體外,最後再從體內進行測試。
就像人類的記憶,關聯學習編織了一個豐富的關聯網。它連接認知,諸如羅比之類的機器人可以通過聚類和維數簡約來獲取認知並習得技能。它可以通過強化和聚類來學習,利用由閱讀得來的更高水平的知識去學校與人類進行互動。關聯學習是最後一塊拼圖,也是我們需要為自己的煉金術提供的最後的原料。現在是時候重建實驗室,使所有這些元素變成終極算法了。