
機器學習的應用非常廣泛,更為驚人的是,相同算法可完成不同的事情。在機器學習領域之外,如果你要解決兩個不同的問題,就得編寫兩個不同的程序。這些程序可能用到相同的基礎架構,如相同的編程語言或數據庫系統。但是,如果你想處理信用卡申請,諸如下棋的程序則毫無用處。在機器學習領域,如果提供適當的數據來讓機器學習,那麼相同的算法既可以處理信用卡申請,也可以下棋。實際上,大量的機器學習應用僅僅由幾個算法來負責,在接下來的幾個章節中我們會談到這些算法。
例如,樸素貝葉斯算法就是一個可以用短方程來表達的學習算法。只要提供患者病歷的數據庫,包括病人的症狀、檢查結果,或者他們是否有什麼特殊情況,樸素貝葉斯算法就可在一秒之內做出診斷,而且往往比那些花幾年在醫學院學習的醫生還要強,甚至它還可打敗花費數千小時構建的醫學專家系統。該算法還可應用於學習垃圾郵件過濾器,乍一看,這和醫療診斷毫無關係。另外一個簡單的學習算法就是最近鄰算法,它的用途十分廣泛,從筆跡識別到控制機器人手,以及推薦你可能喜歡的書籍或者電影。決策樹學習算法也同樣擅長決定你的信用卡申請是否應被通過、尋找DNA中的絞接點,以及下棋時指導下一步該怎麼走。
相同的學習算法不僅可以完成無窮無盡且不同的事情,而且和被它們替代的傳統算法相比,它們要簡單得多。多數學習算法可能只需數百行或者數千行代碼。相比之下,傳統程序則需幾十萬甚至上百萬行代碼,並且單個學習算法就可以導出無數個不同的程序。
如果那麼少的學習算法就可以做那麼多事,那麼有一個邏輯上的疑問:單個學習算法可以把所有事情都做完嗎?換句話說,單個算法可以學習所有能從數據中學習的東西嗎?這是一個非常艱巨的任務,因為這基本上包含成年人大腦裡以及人類進步所創造的一切,還有所有科學知識的總和。實際上,對所有主要的學習算法——包括最近鄰算法、決策樹學習算法以及貝葉斯網絡(樸素貝葉斯的概括)——來說,如果你為學習算法提供足夠、適當的數據,該算法可以實現任一功能(對學習任何東西來說,都與數學相關)。需要注意的是,「足夠數據」也有可能無限。學習無限數據需要做出假設,如我們會看到的那樣,而且不同的學習算法會有不同的假設。
如果不把這些假設嵌入算法中,而是將其連同數據一起,當作顯示輸入,並允許用戶選擇插入哪一個,甚至陳述新的假設,那麼會怎樣?有沒有這種算法,可以接收任何數據及假設並輸出隱藏其中的知識?我相信有。當然,我們得限制假設的可能性,否則如果把整個目標知識都以假設形式賦予算法,那就是在作弊。
我們可以通過限制輸入的規模、要求假設弱於當前學習算法等方法,來實現這個目的。
那麼疑問就會變成:這些假設要弱到何種程度,但仍能夠從無限數據中獲得所有相關知識?注意「相關」這個詞:我們僅僅對存在於世界的知識感興趣,對不存在的世界沒有興趣。因此發明一種通用的學習算法可歸結為發現宇宙最深層的規律,所有現象都遵循該規律,然後找出計算的有效方法來將其與數據結合起來。要找到這個「計算的有效方法」,就不能將物理定律視為萬物規律,如我們將看到的那樣。然而,這並不意味著通用的學習算法要和專用算法一樣高效。正如在計算機科學中常發生的那樣,我們寧願犧牲效率來換取通用性。這在學習既定目標知識所需數據的量上也適用:一般通用學習算法會比專用算法需要更多的數據(但如果我們有必要的數量,就沒問題),而且數據越多,越有可能會這樣。
那麼,這就是本書的中心假設:
所有知識,無論是過去的、現在的還是未來的,都有可能通過單個通用學習算法來從數據中獲得。
我將該學習算法稱為「終極算法」。如果這種算法成為可能,它的發明將成為人類最偉大的科學成就之一。實際上,終極算法是我們最不願意發明的東西,因為一旦對其放鬆,它會繼續發明一切有可能發明的東西。我們要做的,就是為它提供足夠、適當的數據,通過這些數據,它會發現相應的知識:給它視頻流,它就會觀看;給它圖書館,它就會閱讀;給它物理實驗結果,它就會發現物理定律;給它DNA晶體學數據,它就會發現DNA的結構。
這可能聽起來有點八竿子打不著:一種算法怎麼可能學習那麼多不同的事情,而且是這麼難的事情呢?但實際上,種種證據表明終極算法是存在的。下面我們來看看它們是什麼樣的。
來自神經科學的論證
2000年4月,麻省理工學院的神經系統科學家團隊在《自然》雜誌上發佈了一項非同尋常的實驗結果。他們對雪貂的大腦進行重新布線,改變了雪貂從眼睛到聽覺皮層(大腦負責處理聲音的部分)以及從耳朵到視覺皮層之間的連接。你可能覺得實驗結果就是雪貂會嚴重致殘,但並沒有:聽覺皮層學會看,視覺皮層學會聽,而且雪貂沒事。一般的哺乳動物,其視覺皮層都包含一張視網膜地圖:皮層中,與視網膜附近區域相連的神經元彼此相互接近。相反,大腦被重新布線的雪貂在聽覺皮層中形成了這張視網膜圖。如果視覺信息重新導入軀體感覺皮層(負責感知觸覺),軀體感覺皮層也會學會看。其他哺乳動物也有這樣的能力。
對於天生看不見的人,視覺皮層可以負責大腦的其他功能。對於聽不見的人,聽覺皮層也可以這麼做。盲人可以借助舌頭來學會「看」,方法是將頭戴式攝像機的視頻圖像發送至舌頭上的一組電極上,高電壓與高像素對應,低電壓與低像素對應。本·安德伍德是盲人,小時候就自學像蝙蝠那樣,用回聲定位來導航。
通過咂舌頭、聽回聲,他能夠到處走動且不會撞到障礙物,會踩滑板車,甚至還能打籃球。所有這些例子都證明,大腦自始至終只使用了一種相同的學習算法,那些負責不同知覺的區域,區別也僅僅在於與其相連、輸入信息的器官(如眼睛、耳朵、鼻子)。反過來,關聯區(大腦的各個皮層)通過與不同的感覺區(各個感覺器官)相連,來實現其機能,而執行區則通過連接關聯區來實現其機能,然後輸出反饋。
通過在顯微鏡下觀察皮層可以得出相同的結論。同樣的布線模式不斷重複,隨處可見。皮質是一個6層的柱狀物,反饋回路達到大腦一個叫丘腦的結構,以及短程序抑制連接和遠程興奮性連接反覆出現的模式。雖然表現出一定數量的變異,但這看起來更像是來自同一算法(而不是不同算法)的不同參數或者設置。低級感官領域會有更為明顯的差異,但正如重新布線實驗表明的那樣,這些都不具有決定性。小腦是比大腦更早進化的部分,負責簡單的運動調節,有著非常明顯且有規律的架構,由小很多的神經元構成,因此,看起來至少動作學習使用的是不同的算法。然而,如果一個人的小腦受到損傷,大腦皮層會接管它的機能。人的生物進化過程保留了小腦,但這並不意味著小腦能做大腦皮層不能做的事情,只是因為小腦更加高效。
自始至終,大腦構造中發生的運算也同樣相似。大腦中的所有信息都以同樣方式(通過神經元的放電模式)來表示。學習機制也相同:記憶通過加強集群放電神經元之間的連接得以形成,涉及一個叫作長時程增強的生物化學過程。不僅人腦是這樣,不同的動物,其大腦運行機制都很相似。我們的大腦異常大,但似乎與其他動物一樣,其構建遵循同樣的原則。
證明大腦皮層統一性的另一個證據來自所謂的基因組貧乏。人類大腦中的連接數量是基因組中字母數量的100萬餘倍,因此從物理角度,基因組不可能弄明白大腦構造的細節。
然而,關於大腦是終極算法這個觀點的最重要論據,就是大腦負責我們能感知以及想像的一切。如果某物存在,但大腦無法對其進行學習,那麼我們就不知道它的存在。我們可能只是沒看見它,或者認為它是隨機出現的。不管怎樣,如果我們將大腦放入計算機中運行,那個算法就能掌握我們能學會的一切。因此發明終極算法的一種途徑(可以說是最流行的一種)就是對人腦進行逆向解析。傑夫·霍金斯(Jeff Hawkins)在他的著作《人工智能的未來》(On Intelligence)中對此進行了嘗試。雷·庫茲韋爾(Ray Kurzweil)把他的希望放在奇點上——人工智能的崛起遠遠超過人類的多樣性。這樣做的同時,他還在《如何創造思維》(How to Create a Mind)一書中對此進行了嘗試。雖然如此,我們會看到,這僅僅是幾個可能途徑中的一個。這甚至不一定是最有可能的一個,因為大腦非常複雜,而我們還處於解密大腦的初級階段。另一方面,如果我們找不到終極算法,奇點也不會很快發生。
並不是所有的神經系統科學家都相信大腦皮層的統一性,在我們肯定這個觀點之前,需要學習很多東西。關於大腦能掌握以及不能掌握的東西,這個問題也引起了業界激烈的討論。如果有我們知道但大腦不能學習的東西,那麼這個東西肯定已經通過進化被掌握了。
來自進化論的論證
生物多樣性源於單一機制:自然選擇。值得注意的是,計算機科學家對該機制非常熟悉:我們通過反覆研究嘗試許多備選方法來解決問題,選擇並改進最優方案,並盡可能多地嘗試這些步驟。進化論是一種算法。套用查爾斯·巴貝奇(維多利亞時期的計算機先驅人物)的觀點,上帝創造的不是物種,而是創造物種的算法。達爾文在《物種起源》的總結部分提到的「無限形體,美麗至極」掩飾了最美的統一性:所有這些形體都被編碼在DNA中,所有這些形體都通過改變和連接這些染色體來表現。只通過該算法的一個描述,誰會猜出它產生了你和我?如果進化論這個算法能學習我們,可以想像它還可以學習能學習到的一切,條件是我們將進化論這個算法運用到足夠強的計算機上。的確,在機器學習領域,通過模仿自然選擇來使程序進化是許多人正在努力做的事情。因此,進化論是另外一個有希望通往終極算法的途徑。
利用足夠多的數據,一種簡單的算法能掌握什麼?關於這個問題,最經典的例子就是進化論。輸入進化論這個算法的信息是所有存在過的、活著的生物的經歷以及命運(對現在的算法來說是大數據)。此外,這個進化論算法已經在地球上最強大的計算機運行了300多萬年——這台強大的計算機就是地球自己。運行這個算法的真正計算機應該比地球這台「計算機」運轉得更快、數據密集性更低。哪一個模型更適合終極算法:進化還是大腦?這是和機器學習有關、自然與培育之間的辯論。正如我們的存在依靠的是自然與培育的共同力量,也許真正的終極算法包含這兩個方面。
來自物理學的論證
在1959年的一篇著名文章中,物理學家、諾貝爾物理學獎得主尤金·維格納驚歎「數學在自然科學中不可思議的有效性」。由少量的觀察推導出規律,是什麼神奇的力量讓這些規律可以運用到超出其預測範圍的領域?這些規律都是基於數據得來的,而為什麼這些規律比數據還要準確好幾個數量級?最重要的是,為什麼簡潔、抽像的數學語言能夠如此精確地解釋我們無限複雜的世界?維格納覺得這是一個很大的謎,覺得既幸運又無法理解。數學就是如此,而且終極算法就是其邏輯的延伸。
如果這個世界僅僅是一個不斷變大、喧嘩嘈雜的困惑體,那麼我們有理由懷疑通用學習算法的存在。但如果我們所經歷的一切,僅僅是幾個簡單規律的產物,那麼單個算法能推導出所有一切能推導的東西,就是可以理解的。終極算法要做的就是提供一條捷徑,通過實際觀察,用簡短的算式推導(而不是長長的算式)來得出這些規律的結果。
例如,我們雖然相信物理定律引起進化,但是不知道具體怎麼進行。我們知道自己可以像達爾文那樣,通過觀察直接推導出自然選擇規律。無數錯誤的推論就是由那些觀察得出的,但多數人不會做出那些錯誤的推論,因為我們對世界有著廣泛的認識,會對自己的推論形成良性影響,而且那些認識也與自然規律相符。
物理規律之美多大程度滲透到更高的領域(如生物學、社會學),這一點有待觀察。但對混沌的研究提供了許多誘人的例子,這些例子和擁有相似行為的不同系統相關,而普適性理論可以解釋這些例子。曼德布洛特集合(Mandelbrot Set)就是很完美的例子,能解釋一個很簡單的重複程序如何產生無數種類的形式。如果世界上的山峰、河流、雲朵以及樹木都是這些重複程序的產物(分形幾何學表明它們就是),也許那些程序只是單個程序的不同參數化,而該單個程序可以從那些程序推導中得出。
在物理學中,適用於不同數量的方程,往往可以用來描述發生在不同領域的現象,例如量子力學、電磁學、流體動力學。波動方程、擴散方程、泊松方程表明:一旦我們在某個領域發現它們,也很快能在其他領域發現它們;一旦我們在某個領域懂得解開它們,也能在所有領域將它們解開。此外,所有這些方程都很簡單,涉及幾個和空間、時間有關的數量的相同導數。很容易想像,它們都是主方程的幾個例子,而終極算法要做的,就是用不同的數據集來將它實例化。
另外的證據來自最優化。最優化是數學的分支,關注的是為函數找到輸入值,使其產生最大輸出值。例如,找到購買及銷售股票的排序,用來最大化你的全部回報,這就是一個最優化問題。在最優化中,簡單的函數往往能引出驚人的複雜方案。最優化幾乎在每個領域都扮演十分重要的角色,包括科學、技術、商業,還有機器學習。每個領域在約束條件下進行最優化,該限制條件由其他領域的最優化狀態來決定。我們努力在經濟的限制下將幸福感最大化,這也是公司在受到當前技術水平限制下的最佳方案,反過來成為我們在生物學及物理學限制下能找到的最佳方案。反過來,生物學是進化學在物理學和化學的約束下進行優化的結果,而物理定律本身又是最優化問題的解決方法。因此,可能所有事物的存在,都是一個中心優化問題進一步的解決方案,而終極算法隨著那個中心問題的敘述而產生。
不僅物理學家和數學家在尋找不同領域之間意想不到的聯繫,生物學家也在尋找。在《論契合:知識的統合》(Consilience)一書中,著名生物學家愛德華·威爾遜慷慨激昂地闡釋了知識(從科學到人文學)的統一性。終極算法就是該統一性的完美表達:如果所有知識共同遵循一個模式,那麼終極算法就存在,反之則不存在。
然而,物理學的簡潔性獨一無二。在物理學和工程學之外,數學的軌跡就更加混合。有時數學僅限於用起來有效,而有時它的模型又過於簡單,無法使用。然而,過於簡單的傾向源於人類思維的各種限制,而不是源於數學的種種限制。大腦的大多數硬件(或許該叫「濕件」)負責人體感知和活動,而為了做算術,我們就得借用因語言得到進化的那部分大腦。計算機就沒有這樣的限制,而且可以輕易地將大數據變成非常負責的模型。在數學的過度有效性與數據的過度有效性面前,你就會選擇機器學習。生物學和社會學絕對不會像物理學一樣簡單,但我們發現其真理的方法可以做到那樣簡單。
來自統計學的論證
根據一個統計學流派的觀點,所有形式的學習都是基於一個簡單的公式——如我們所知,就是貝葉斯定理。貝葉斯定理會告訴你,每當你看到新的證據後,如何更新你的想法。一種簡單的貝葉斯學習算法對世界進行一系列假設,由此開始進行學習。當它看到新的數據時,與該數據匹配的假設更有可能會成立(或者不可能成立)。在觀察足夠的數據後,某個假設會成立,或者幾個假設同時成立。例如,我在尋找一個能夠準確預測股票走勢的程序,該程序預測某只股票會下跌,結果該股票卻上漲了,那麼該程序就會失去我的信任。我審核幾個備選程序之後,只選擇了幾個可信賴的程序,它們概括了我對股票市場的新認識。
貝葉斯定理就是將數據變成知識的機器。據貝葉斯統計學派的觀點,貝葉斯定理是將數據變成知識的唯一正確方法。如果該學派的觀點正確,貝葉斯定理要麼就是終極算法,要麼就是推動終極算法發展的動力。關於貝葉斯定理使用的方法,其他統計學派持非常保守的觀點,而且會更願意用不同方法來對數據進行學習。在計算機發明出來之前,貝葉斯定理只能應用在非常簡單的問題中,說它是通用的學習算法未免有點牽強附會。然而,在大數據和大計算的輔助下,貝葉斯定理在廣闊的假設空間中找到了出路,而且已經擴展到每個人們能想到的領域中。如果說存在貝葉斯算法無法學習的東西,只是現在還沒發現它們。
來自計算機科學的論證
我在大四時,用了一個夏天玩俄羅斯方塊遊戲,這是一個涉及方塊疊加的電子遊戲,遊戲中由正方形組成的各種形狀的圖案往下掉,你要將這些圖案堆起來,堆得越緊密越好。如果圖案堆到屏幕頂部,那麼遊戲就結束了。當時我完全沒有意識到,這就是我接觸NP完全問題[4]的開始,這是理論計算機科學最重要的一個問題。後來我才知道,俄羅斯方塊完全不是簡單用來消遣的遊戲,掌握這個遊戲(徹底掌握它),就是你這輩子做得最有用的事情。如果你一步到位,解決了俄羅斯方塊問題,你就解決了科學、技術、管理中數千個最難、最有意義的問題,因為本質上這些難題就是同一個問題。這是在所有科學領域中最讓人驚訝的事實。
弄明白蛋白質如何折疊成特定形狀;通過DNA來重新構建一系列物種的進化史;在命題邏輯中證明定理;利用交易成本來發現市場中的套利機會;從二維視圖中推出三維形狀;將數據壓縮到磁盤上;在政治活動中組成穩定聯盟;在剪切流中模擬湍流;按照給定回報率找出最安全的投資組合、到達幾個城市的捷徑、微芯片上元件的最佳佈局方案、生態系統中傳感器的最佳佈局、自旋玻璃門最低的能量狀態;安排好航班、課程、工廠工作;最優化資源分配、城市交通流、社會福利,以及提高你的俄羅斯方塊分數(最重要的)——這些都是NP完全問題,意思是,如果你能有效解決其中的一個問題,就能有效解決所有NP類問題,包括相互間的問題。誰會猜到,這些表面上看起來迥然不同的問題,會是同一個問題?如果它們真的是同一個問題,就可以說一種算法能學會解決所有問題(或更準確地說,所有能有效解決的例子)。
在計算機科學中,P和NP是兩類最重要的問題(很遺憾,名字不是很有助於記憶)。如果我們能有效解決它,那麼這個問題就屬於P;如果我們能有效找到其解決方案,那麼這個問題屬於NP。著名的P=NP的問題就是,能有效找到的問題是否可以得到有效解決。因為NP完全問題,回答這個問題需要的只是證明某個NP完全問題可被有效解決(或者無法被有效解決)。NP在計算機科學領域並不是最難的一類問題,但可以說,它是最難的「現實」類問題:如果在宇宙滅亡之前,你無法找到問題的解決方法,那你努力解決這個問題的意義在哪裡?人類擅長給出NP難題的近似解,而相反,我們感興趣的問題(如俄羅斯方塊問題)往往涉及NP問題。人工智能的其中一個定義是,人工智能包括找到NP完全問題的所有啟發性解決方案。為了找到解決方案,我們常常把問題變成可滿足性問題,也就是典型的NP完全問題:給定的邏輯公式是否永遠都是對的,或者它是不是自相矛盾?如果我們發明一種學習算法,能夠學習解決可滿足性問題,那麼有充分理由認為,這個算法就是終極算法。
拋開NP完全問題,計算機的存在本身就明顯預示著終極算法的存在。如果你穿越回到20世紀早期,告訴人們很快會有一種機器發明出來,能夠解決人類所有領域的難題——所有難題都通過同一台機器解決,那麼沒有人會相信你。人們會說,每台機器只能解決一個問題:縫紉機不會打字,打字機不會縫紉。1936年,艾倫·圖靈想像出一個奇怪的裝置,它有一條紙帶和機器頭,頭可以在紙帶上進行閱讀和書寫,就是現在人們知道的圖靈機。每一個可以想得到的、可以用邏輯推理解決的難題,都可以通過圖靈機解決。此外,一台所謂的萬能圖靈機可以通過閱讀紙帶上的具體要求來模仿所有東西,換句話說,我們能夠對圖靈機進行編程,用它來做所有事情。
算法是歸納的過程,而學習的過程對圖靈機來說,就是演繹的過程。圖靈機能通過對算法輸入、輸出行為進行閱讀來模仿其他算法。就像存在許多與圖靈機對等的計算模型,可能也存在通用學習算法的許多不同的等價公式。然而,問題的關鍵是必須找到第一個這樣的公式,就像圖靈找到通用計算機的第一個公式那樣。
機器學習算法與知識工程師
當然,有很多人支持終極算法,也有很多人懷疑終極算法。當某方法可以簡單解決複雜問題時,存在懷疑符合情理。對終極算法最堅定的反抗來自機器學習永恆的敵人:知識工程。根據知識工程支持者的觀點,知識無法自動被學習,必須通過人類專家編入計算機,才能對它進行學習。的確,學習算法能從數據中提取一些東西,但你不能將這些東西和真知識混為一談。對知識工程師來說,大數據不是新石油,而是騙人的新蛇油。
在人工智能出現早期,機器學習似乎是通往類人智能計算機的途徑。圖靈和其他人認為,機器學習是唯一看似合理的途徑。但後來知識工程師進行了回擊,而且20世紀70年代機器學習處於次要地位。在20世紀80年代的一段時間,似乎知識工程師要接管世界了,還有許多企業和國家對知識工程領域進行大量投資。但後來人們開始對該領域失望,而機器學習也開始崛起,一開始悄無聲息,後來就突飛猛進。
儘管機器學習成功了,知識工程師們還是覺得不信服。他們相信,機器學習的局限性很快會變得明顯,鐘擺會擺回來,局勢會扭轉。馬文·明斯基是麻省理工學院的教授、人工智能的先驅人物,也是該陣營的重要成員。明斯基不僅懷疑機器學習能替代知識工程,他也懷疑人工智能的所有統一思想。明斯基在其《意識社會》(The Society of Mind)一書中提到了關於智能的理論,這個理論可以被不客氣地歸納為「意識就是一個接一個該死的東西」。《意識社會》包含的就是一長串分散的觀點,每個觀點都毫不相關。這種實現人工智能的方法根本沒什麼用,它只是由計算機進行的收集活動。沒有機器學習,需要建立智能代理的觀點將會變得無限多。如果一個機器人掌握了人類所有的技能,但就是沒有學習能力,那麼人類不久就會把它扔在一邊。
明斯基是Cyc項目(Cyc project)的狂熱支持者,這是人工智能歷史上最臭名昭著的失敗項目。Cyc項目的目標是通過將所有必要知識輸入計算機中,來解決人工智能問題。20世紀80年代這個項目剛開始時,它的領導者道格·萊納特(Doug Lenat)就信心滿滿地預測,10年之內該項目就會取得成功。30年後,Cyc項目不停擴大,但仍無法做常理性推理。具有諷刺意味的是,萊納特終於支持通過挖掘網頁來將Cyc填滿,這並非因為Cyc可以閱讀,而是因為別無他法。
即使奇跡發生,我們能夠對所有必要的數據進行編程,麻煩也會不斷出現。過去幾年,幾個研究組已經嘗試構建完整的智能代理,方法就是將所有算法集中起來,用於想像、語音識別、語言理解、推理、計劃、導航、操作等。沒有統一的結構,這些嘗試將碰到「複雜性」這個難以解決的難題:有太多的活動件、太多的交互、太多的漏洞,可憐的人類軟件工程師也難以應付。知識工程師相信,人工智能的問題僅僅是工程學的問題,但是我們還沒達到那個點——工程學能帶領我們走完下面的路。1962年,肯尼迪發表登月演講。那時登上月球是一個工程學問題,但1662年,它就不是了,而當今它則更加靠近人工智能所在的領域。
在工業領域中,除了在一些利基領域,沒有任何跡象表明知識工程學可以永遠和機器學習競爭。為什麼要花費精力來讓專家緩慢而痛苦地將知識編碼成計算機能識別的形式,而你明明可以在一秒內將其從數據中提取出來?你會怎麼對待那些專家不懂,你卻可以從數據中發現的東西?而當數據不足時,知識工程學的成本倒是很少會超過其帶來的益處。反過來,想像一下,如果農民要將每株玉米進行工程化,而不去播種並讓它們生長,那麼我們都得挨餓。
另一個對機器學習持懷疑態度的人是語言學家諾姆·喬姆斯基。喬姆斯基認為,語言必須是與生俱來的,因為孩子聽到的合乎語法的句子僅僅是一些例子,不足以學習語法。然而,這種說法僅僅將學習語言的任務交給了進化,它並沒有反對終極算法,只是反對「終極算法是大腦」這個觀點。此外,如果存在通用語法(喬姆斯基認為存在),闡發它就是闡發終極算法的步驟之一。這種情況不成立的唯一可能就是,語言和其他認知能力沒有共同點,考慮到進化的近因,這令人難以置信。
無論如何,如果我們將喬姆斯基「刺激貧乏」論形式化,我們會發現這個觀點很明顯是錯的。1969年,霍寧證明,概率上下文無關語法(probabilistic context–free grammar)只能通過正面例子掌握,後面緊跟的是更有力的結果(上下文無關語法是語言學家研究的內容,而概率類型模擬每個規則被使用的概率)。另外,語言學習不會發生在一個真空當中,孩子需要從父母和周圍環境獲取各種語言學習線索。如果我們能從幾年時間裡學習的例子中學習語言,部分也只是因為語言結構與世界結構存在相似性。對這個共同結構,我們感興趣,而且從霍寧和其他人那裡知道,有這個共同結構就足夠了。
總體來講,喬姆斯基批評所有統計學習。他把統計學習算法不能學習的東西列了一個單子,但這個單子已經過時50年了。喬姆斯基似乎把機器學習等同於行為主義了,根據行為主義,動物的行為淪為反應與獎勵之間的聯合,但機器學習不是行為主義。現代學習算法能夠掌握豐富的內在表象,而不僅僅是刺激物之間的兩兩關係。
最後,事實勝於雄辯。統計學語言算法起作用了,而手工設計的語言系統卻沒起作用。第一件令人大開眼界的事發生於20世紀70年代,當時五角大樓的研究機構DARPA組織了第一個大型語音識別項目。讓所有人驚訝的是,一種簡單的序列學習算法——喬姆斯基嘲笑的類型,輕易地打敗了一個複雜的知識系統。現在像這樣的學習算法幾乎用於每一個語音識別器中,包括Siri(蘋果公司產品上的一項智能語音控制功能)。弗雷德·賈裡尼克(IBM語音研究組的領導)說過一句著名的俏皮話:「每開除一名語言學家,我的語音識別系統的錯誤率就降低一個百分點。」20世紀80年代,陷入知識工程學的泥潭裡,計算機語言學差點走向盡頭。自那以後,基於學習算法的浪潮已經席捲這個領域,在計算機語言學會議中,幾乎每篇文章都會提到學習。統計分析軟件以近乎人類水平的精確度來分析文章,而手編程序已經遠遠落在後面。機器翻譯、拼寫糾正、詞性標注、詞義消歧、問題回答、對話、概括——這些領域的所有最好的系統都利用了學習。沒有學習,沃森不可能在《危險邊緣》遊戲中戰勝人類。
對此,喬姆斯基可能會回應,工程學的成功並不能證明其科學有效性。換句話說,如果你的樓房倒塌了,而且你的發電機不工作了,那麼也許就是因為你的物理學觀點有問題。喬姆斯基認為,語言學應該把重點放在他定義的「理想的」說話者和聽話者上,這讓他忽略了諸如類似的問題:語言學習過程涉及統計學。因此,很少有實驗主義者拿他的理論當回事,這並不奇怪。
另外一個可能會反對終極算法的觀點來自心理學家傑瑞·福多,他認為心理是由一系列模塊組成的,這些模塊之間只有有限的聯繫。例如,當看電視時,你的「高級腦」知道,那只是光線在光滑表面的閃爍,但視覺系統仍然會看見三維形狀。即使我們相信心理模塊理論,這個理論也並沒有暗指不同的模塊會使用不同的學習算法。同種算法對諸如視覺及語言之類的信息都起作用,這個說法才足夠有力。
像明斯基、喬姆斯基和福多這樣的批評家曾經佔據上風,但萬幸,他們的影響力已經逐漸減弱。即便如此,我們仍需將他們的批評銘記於心,這樣才能到達終極算法這個終點,原因有兩個:第一,知識工程師和機器學習算法一樣,遇到許多相同的問題,雖然他們沒有成功,但學到了許多寶貴的教訓;第二,學習和知識以異常微妙的形式相互交織,而我們很快就會發現這一點。遺憾的是,這兩個陣營各說各話。他們討論不同的主題:機器學習討論概率,而知識工程學討論邏輯。本書後面會提到如何解決這個問題。
天鵝咬了機器人
「無論你的算法有多聰明,總有它無法掌握的東西。」除了人工智能和認知科學,反對機器學習的常見觀點幾乎都可以用這句話概況。納西姆·塔勒布(Nassim Taleb)在《黑天鵝》(The Black Swan)一書中強調了這個觀點。有些事真的無法預料。如果你只見過白天鵝,會覺得看到黑天鵝的概率是0。2008年的金融危機就是一隻「黑天鵝」。
有些事可預料,而有些事卻不能預料,這個說法是正確的,而機器學習算法的首要任務就是區別可預測的事與不可預測的事。但終極算法的目標是要學習一切能認知的東西,這比塔勒布和其他人想像的要廣闊得多。房地產泡沫還遠遠不是一隻「黑天鵝」,相反,房地產泡沫是經過人們普遍預測的。大多數銀行的模型沒能預測它的到來,也只是因為那些模型的局限性,而不是機器學習的局限性。學習算法很擅長精確預測稀有、未曾發生的事件。甚至你也可以說,這是機器學習的主要任務。如果你沒見過黑天鵝,那麼它出現在你面前的概率是多少?它是已知物種的一部分,最後變成黑色的天鵝,這樣的概率是多少?這僅僅是一些粗略的例子,我們會在本書看到更深刻的例子。
另外一個反對機器學習的觀點與以上觀點相關,就是我們常聽到的——「數據無法代替人類的直覺」。實際上,這句話可以反過來:人類直覺無法代替數據。直覺就是你在不知道事實的情況下依靠的東西,而因為你不常用它,所以直覺非常寶貴。但如果證據擺在你面前,為什麼還要拒絕證據?統計分析在棒球界打敗球探(正如邁克爾·劉易斯在《魔球:逆境中制勝的智慧》一書中明確記錄的那樣),在品酒時打敗內行。統計分析能做很多事情,我們每天都能看到新的例子。因為大量數據的湧入,證據與直覺的界限正在迅速改變,而正如所有革命一樣,要拋棄所有墨守成規的方法。如果我是Y公司X領域的專家,我就不想被某人用數據推翻。行業裡有句話:「多聽聽顧客的話,而不是HiPPO。」(HiPPO是「領最高薪水的人說的話」的簡寫。)如果想成為明天的權威人士,你要依靠數據,而不是與之鬥爭。
好了,有人會說,機器學習能從數據中找到統計規律,但它絕不會發現更深刻的東西,如牛頓定律。可以說,它還沒有找到那樣深刻的定律,但我肯定它將來會找到。儘管有蘋果落下的故事,但深刻的科學真理並不是那麼容易就能獲得。科學經歷了三個時期:布拉赫時期、開普勒時期、牛頓時期。對於布拉赫時期,我們收集了很多數據,就像第谷·布拉赫日復一日、年復一年耐心記錄行星的位置那樣。對於開普勒時期,我們使經驗規律符合數據,就像開普勒對行星運動所做的那樣。對於牛頓時期,我們發現了更深刻的真理。大多數科學研究和布拉赫、開普勒所做的工作相似,這樣的工作就是科學研究的內容,像牛頓偶然發現定律的例子則少見。當今,大數據所做的工作是布拉赫的數十億倍,機器學習的工作內容是開普勒的數百萬倍。如果(但願如此)有更多像牛頓偶然發現定律這樣的時刻,這樣的時刻也可能發生在未來的學習算法中,或者發生在未來手足無措的科學家身上,或者至少是發生在兩種可能都存在的情況下(當然,諾貝爾獎會頒發給科學家,不管他們是持重要的觀點,還是只按了一下按鈕。學習算法就沒有那樣的志向,要拿諾貝爾獎)。本書將會提到那些算法是怎樣的,並推測它們會發現什麼,例如,治癒癌症的方法。
終極算法是狐狸,還是刺蝟
我們有必要考慮藏得更深、反對終極算法的觀點,這個觀點可能是所有反對觀點中最嚴肅的一個。這個觀點不是來自知識工程師或者不滿意的專家,而是來自機器學習實踐人員。假設我是持反對觀的機器學習實踐者,可能會說:「終極算法和我日常生活看到的不一樣。我嘗試用許多學習算法的數百種變形來解決所有給定的問題,而且對各類不同問題都會有更好的算法,那麼單個算法(我們說的終極算法)怎麼可能代替所有這些算法?」
這個問題的答案是:的確如此。不用嘗試多種算法的數百種變形,而只用嘗試單個算法的數百種變形,這不是更輕鬆嗎?只要我們弄明白,每個算法中重要的與不重要的東西,重要部分的共同點,以及這些部分如何進行互補,那麼我們真的可以從這些多種算法中合成一個終極算法。這就是我們在本書中要做的事情,或者說盡可能要做到的事情。親愛的讀者,也許你在閱讀本書時,會有自己的一些觀點。
終極算法會複雜到什麼程度?它包含幾千行代碼?還是幾百萬行?我們現在還不知道,但機器學習有一段可喜的歷史:簡單的算法意外地將精心設計的算法打敗了。在《人工科學》(The Sciences of the Artificia)一書的著名章節中,人工智能先驅人物、諾貝爾獎得主赫伯特·西蒙(Herbert Simon)讓我們想像螞蟻費力地穿過沙灘回家。螞蟻的路線非常複雜,這不是因為螞蟻本身複雜,而是因為沙灘這個環境對螞蟻來說意味著要爬很多山丘,繞很多卵石。如果我們通過對每條可能的路線進行編程,模仿螞蟻,那麼我們注定會失敗。同樣,在機器學習中,複雜性存在於數據中。終極算法需要做的就是消化複雜性,因此,如果終極算法變得非常簡單,那麼我們也不用感到驚訝。雖然人類的手很簡單(四個手指,一個大拇指),但是它卻可以製作並使用無數種工具。終極算法與算法的關係,就如同手指與鋼筆、劍、螺絲刀、叉子的關係。
正如以賽亞·伯林明確提出的那樣,有些思想家就是狐狸——他們知道許多微小的事情;而有些思想家則是刺蝟——他們知道一件大事。學習算法也是同樣的情況。我希望終極算法是一隻刺蝟,但即使它是隻狐狸,我們也沒法很快抓住它。當今學習算法最大的問題,不是它們數量太多,而是儘管它們有用,卻不能完成我們讓它們做的所有事情。我們利用機器學習來發現深刻的真理之前,得先找到關於機器學習的深刻真理。
我們正面臨什麼危機
假設你被診斷患有癌症,而且傳統療法(手術、化療、放療)都失敗了,那麼接下來發生的事情就會決定你是活下去,還是走到生命盡頭。第一步就是要對腫瘤進行基因排序。諸如在劍橋、馬薩諸塞州的基礎醫學公司會為你做這些工作:把腫瘤樣本郵寄給他們,然後他們會發給你一個列表,列表是已知的、和癌症相關的基因變異。這個步驟十分有必要,因為每種癌症都不一樣,單種藥不可能治療所有癌症。當癌症擴散到全身時會變異,通過自然選擇,最能抵抗你所服用藥物的變異細胞最有可能繼續會生長。對你有用的藥物可能只對5%的病人有用,或者你需要結合其他藥物一起服用,這些藥可能你之前從未服用過。也有可能要設計一種新藥,專門治療你的癌症,或者需要一系列的藥來避開癌症的適應性。這些藥物可能會有副作用,而且對你來說會致命,但對其他很多人來說可能沒有問題。即使瞭解你的病歷和癌症基因,也沒有哪個醫生可以記錄你所有的病情,以便預測最好的療法。對機器來說,這是一個完美的任務,但當今的學習算法還無法完成這個任務。終極算法就是一個完整包:將終極算法應用於大量的患者及藥物數據中,同時參考從生物醫學文獻中挖掘的知識,這就是我們將來治療癌症的方法。
許多領域迫切需要通用學習算法,包括與生死有關的領域以及普通領域等。你可以想像理想的推薦系統是什麼樣的,它能推薦書籍、電影以及小玩意兒,它們正是你有時間慢慢細看時會挑選的東西。亞馬遜的算法與這個系統則大相逕庭,部分是因為亞馬遜的算法沒有足夠的數據——它知道的主要信息僅僅是你之前從亞馬遜購買的東西——但如果你氣瘋了,把自出生以來能想到的東西都一股腦地輸給它,那麼它就不知道該拿這些東西怎麼辦了。你如何將生活的萬花筒、做過的各類選擇轉化成連貫的畫面,用來告訴你:你是誰,你想要什麼?這是當今學習算法無法理解的。但有了足夠的數據,終極算法將能夠大概瞭解你以及你最好的朋友。
未來某一天,每個房間都會有一個機器人,做飯、鋪床,甚至在父母去上班時照看孩子。這一天要多久才來,取決於尋找終極算法的過程有多艱難。如果我們能做的,只是將許多不同的學習算法結合起來,每種算法只能解決人工智能的一小部分問題,那麼很快我們就會撞到複雜性這堵牆。這種零碎的方法在《危險邊緣》比賽中奏效了,但很少有人相信,未來的家用機器人就是沃森的子孫。這並不是說終極算法會單槍匹馬破解人工智能的難題,還有許多偉大的工程要完成,沃森就是一個很好的開始。但「二八原則」也適用:終極算法會提供80%的方案,做20%的工作量,所以這是開始的最佳時機。
終極算法對技術的影不僅限於人工智能。通用的學習算法是打擊複雜性怪獸的有力武器。當今人類建立起來的很複雜的系統將來會變得簡單。計算機會在我們更少的輔助下做更多的事情。它們不會不斷重複同一些錯誤,而會像人一樣,從實踐中學習經驗。有時,就像傳說中的管家,我們還沒說想要什麼,計算機就已經先猜出來了。如果計算機能讓我們變聰明,那麼運行終極算法的計算機會讓我們感覺自己就是天才。技術進步的步伐會明顯加快,不僅僅在計算機科學,在許多不同的領域也會這樣。這就反過來推動經濟發展,降低貧困率。終極算法會輔助匯總和傳播知識,這樣一個機構的情報會比其各個分機構的情報總數還要多,而不會更少。日常工作將自動化完成,並由更有意思的工作來代替。每項工作都會比當今完成得更好,無論這個工作是由更熟練的人、計算機,或者通過二者的結合來完成。股市崩盤的概率會越來越低,規模也會越來越小。傳感器會在地球上形成密集的網格,人類掌握的模型會持續接收終極算法輸出的信息,這樣我們就不會盲目飛行了,地球的情況會變得越來越好。你的一個模型會代表你和世界進行談判,和其他人及實體模型玩複雜的遊戲。因為有了這些,我們會更長壽、更幸福,也更多產。
因為反對觀點的潛在影響太大,我們應該努力發明終極算法,哪怕成功的概率很低。即使這個過程會很久,但找到一種通用學習算法卻有很多能即刻感受到的好處。其中一個就是我們能通過統一觀點更好地瞭解機器學習。有太多的商業決策是在不瞭解統計學的情況下做出來的,而統計學對商業決策起著支撐作用。事情本該不是這樣的。為了使用一項技術,不必掌握其內部工作原理,但我們得有關於它的一個好的概念模型。我們有必要知道如何找到收音機上的一個電台,或者懂得如何調音量。當下,那些不是機器學習專家的人,對學習算法會用來做什麼,沒有什麼概念模型。我們使用谷歌、臉書時驅動的算法,或者最新的分析套件,有點像一輛帶有有色窗戶的黑色豪華轎車,在某個夜晚神秘地出現在我們的家門口:我們該上車嗎?這輛車會帶我們去哪裡?現在是時候坐在司機的座位上了。明白不同的算法所做的假設會幫助我們選擇合適的算法用於工作中,而不是從偶然出現的算法中隨機挑一個用,然後忍受它好幾年,最後痛苦地領悟從一開始我們就該知道的東西。通過瞭解學習算法優化的內容,我們可以肯定它們優化的是我們關注的東西,而不是裝在盒子裡的東西。也許最重要的是,一旦我們知道特殊的學習算法得出的結論,就會知道用這些信息來做什麼——該相信什麼,該如何回報發明者,以及下次該如何取得更好的結果。有了通用學習算法(我們在本書中將其作為概念模型),我們就能在沒有認知負載的情況下,把所有這些事情做完。機器學習本質上是簡單的,我們只需削掉數學及行話這些外皮,然後把最裡面的「俄羅斯套娃」展示出來。
這些好處都可應用於我們的私人生活和工作中。我們在現代世界留下自己的印記,數據記錄了我們的每一個印記,但我們應該如何充分利用這些數據呢?每個互動都有兩個方面:這個互動為你完成了什麼;對於剛和你交互的系統,它教會了這個系統什麼。懂得這些是在21世紀過上幸福生活的第一步。教授學習算法,這些算法就會為你服務,但首先你得瞭解它們。我工作的哪些部分可以交給學習算法來完成,哪些不可以?最重要的是,我該如何利用機器學習把工作做得更好?計算機是你的工具,而不是對手。有了機器學習的輔助,經理會變成超級經理,科學家會變成超級科學家,工程師會變成超級工程師。未來屬於那些深深懂得如何將自己的獨特專長與算法的擅長結合起來的人。
也許終極算法就像一個潘多拉盒子,最好不要打開。計算機會奴役甚至消滅我們嗎?機器學習會變成獨裁者或者邪惡公司的侍女嗎?知道機器學習的發展方向有助於幫助我們瞭解該擔心什麼、不該擔心什麼、應該怎麼處理問題。《終結者》中,超級人工智能變得有情感,並通過機器人軍隊征服了人類。這個場景不會和我們將在本書中談到的學習算方法一起發生。因為計算機會學習,並不意味著它們可以魔法般地實現自己的願望。學習算法學著完成我們為它們設定的目標,它們不會改變這些目標。我們要擔心的是,它們服務我們的方法可能會對我們有害,而不是有益。因為它們知道的東西不多,改善的方法就是教它們更好的方法。
很多時候,我們得考慮,如果終極算法落入壞人手中,它會做些什麼。第一道防線就是確保好人第一個拿到它,或者如果它不明白誰是好人,就要保證它是開源的。第二道防線就是要意識到,無論學習算法有多好用,也只是在獲得數據時好用。控制了數據的人也就控制了學習算法。你對數字化生活的反應,不應該是退回到木屋中——樹林裡也裝滿了傳感器,而應努力拿到對你來說重要的數據。能有推薦系統為你找到想要的東西,並把東西帶給你,這樣很好,沒有這些系統你會感到失落。它們帶給你的應該是你想要的東西,而不是其他人想讓你擁有的。控制好數據,控制好算法掌握的模型的所有權,這就是21世紀戰爭的內容,這些戰爭可能會發生在政府、企業、工會以及個人之間。為了共同利益,你也有道德義務來分享數據。只依靠機器學習不能治癒癌症,依靠癌症病人卻可以做到這一點,方法就是為了將來的病人,分享自己的信息。
新的萬有理論
當今的科學已經被徹底四分五裂,就像巴別塔中的亞社會都說著自己的俚語,只能看到相鄰的幾個亞社會。終極算法會給出所有學科的統一思想,並有潛力提出一套新的萬有理論。乍一看,這個說法可能會有點奇怪。機器學習所做的,就是從數據中引出理論。終極算法本身如何能發展為一套理論?難道弦理論是萬有理論,而終極算法和萬有理論沒有任何相似點?
為了回答這些問題,我們得首先明白什麼是科學理論,什麼不是。理論是關於世界是什麼的一系列約束條件,而不是對世界的完整描述。為了獲得對世界的完整描述,你必須將理論和數據結合起來。例如,想想牛頓第二定律。定律說明力等於質量與加速度的乘積,或者寫成F=ma。定律並沒有說明是哪個東西的質量或者加速度,或者作用力是什麼。定律只要求,如果某物體的質量是m,加速度是a,那麼作用在它之上的所有力的總和就肯定是ma。雖然該定律排除了宇宙的某些自由度,但沒有排除所有。所有其他物理理論也都如此,包括相對論、量子力學以及弦理論,這些理論其實都是對牛頓定律的完善。
理論的強大之處在於它簡化了我們對世界的描述。有了牛頓定律,我們首先只需知道某個時間點所有物體的質量、狀態、速度,其次就是所有時段的狀態及速度。憑借過去、未來宇宙歷史中可區分時刻的數量這樣一個因素,牛頓定律概括了我們對世界的描述。太了不起了!當然,牛頓定律也僅僅是接近準確的物理定律,因此讓我們用弦理論來替代它,同時忽略弦理論是否永遠證實有效的問題。我們能做得更好嗎?可以,有以下兩個原因。
第一,實際上,我們沒有足夠的數據來完全確定世界,甚至忽略不確定性原則,準確知道世界上所有粒子某個時間點的狀態和速度,也遠遠做不到。因為物理定律是混沌的,不確定性隨時會混雜進來,而且在短時間內能確定的東西太少。為了準確描述這個世界,每隔一段時間,我們就需要一批新數據。實際上,物理定律只告訴我們局部會發生的事情。這一點大大削減了它們的力量。
第二,雖然我們在某個時間點擁有關於世界的完整知識,物理定律還是不能讓我們確定這個世界的過去和未來。這是因為,確定世界的過去和未來所需的全部計算量,對於能想像得出的計算機來說,超出了它們的能力範圍。實際上,為了完善魔法宇宙,我們需要另外一個一模一樣的宇宙。這也是為什麼弦理論多數情況下在物理學之外就變得無關緊要了。我們在生物學、心理學、社會學或者政治學中的理論,並不是由物理定律推理得來的,這些理論得從零開始構建。我們假定,當這些理論應用到細胞、大腦、社會中時,它們就是物理定律對此所做預測的近似理論,但我們無法知道。
不像特定領域的理論只在該領域中才有權威,終極算法在所有領域中都有權威。在X領域中,終極算法不如X領域的主流理論有權威,卻在所有領域中比該主流理論有權威——當我們考慮到整個世界時——終極算法普遍比所有其他理論有權威得多。終極算法是所有理論的起源。為了獲得X理論,我們要給終極算法添加的就是推導X理論所需要的最少量的數據(在物理學中,需要添加的僅僅是大約幾百個重要實驗的結果)。結果就是,在同樣的情況下,終極算法很有可能成為萬有理論的最佳出發點。請史蒂芬·霍金原諒,和弦理論相比,終極算法最後會告訴我們更多關於上帝思考的東西。
有些人可能會說,尋找通用學習算法就是一種追求虛榮心的表現。其實夢想並不是追求虛榮心,在魔法石以及永動機並肩作戰下,也許終極算法在眾多偉大的幻想中會代替虛榮心的位置。尋找終極算法更像測定海上的經度,人們一開始認為這太困難,於是放棄了,直到一個孤獨的天才解決了這個問題。尋找終極算法更有可能就是一代一代人的任務,就像天主教堂是由一塊塊石頭砌成的一樣。找到終極算法的唯一方法就是,早早動身踏上旅途。
未達標準的終極算法候選項
那麼,如果終極算法存在,它是什麼?看起來很明顯的一種候選項就是記憶:只要記住你見過的所有東西,過一段時間,你就好像見過世上的一切東西,所以也就無所不知了。這裡的問題是,正如赫拉克利特說的那樣,你無法兩次踏入同一條河流。世上的東西比你能看到的多得多。無論你觀察過多少朵雪花,下一朵還是會不一樣。即使宇宙大爆炸時你在場,但從那以後無論在哪裡,對於未來你可能看到的事物,你現在看到的也只是一小部分。如果你目睹一萬年前地球上的生命,也不會對你未來將看到的東西有什麼影響。在某城市長大的人搬到另外一個城市,他不會陷入癱瘓,但只會記憶的機器人就會陷入癱瘓。此外,知識不僅是事實清單,知識的範圍很廣,而且還有結構。「人固有一死」比70億條死亡聲明要簡潔得多。記憶無法像終極算法那樣讓我們做到這些。
終極算法的另外一個候選項就是微處理器。計算機裡的微處理器可以看作單一算法,其任務是執行其他算法,就像通用的圖靈機那樣。而且微處理器可以運行一切可以想得到的算法,這由它的內存和速度上限決定。實際上,對一台微處理器來說,一種算法也只是另外一種數據。這裡的問題是,如果微處理器單獨工作,那麼它什麼也不會幹,它只會待在那兒,一整天什麼也幹不了。它運行的算法從哪裡來?如果這些算法由人類程序員來編碼,那麼就不會涉及任何學習行為。即便如此,人們還是會有一種感覺,認為微處理器是終極算法的完美模擬。微處理器不是運行一切特殊算法最好的硬件,最好的硬件應該是特定用途集成電路,專為那種算法而精確設計。我們卻把微處理器幾乎用於所有應用中,因為即使它效率較低,但卻非常靈活。如果我們得為每個新的應用構建一個特定用途集成電路,那麼信息革命也絕不會發生。同樣,終極算法也不是學習一切特定知識最好的算法,最好的算法應該是已經編碼了大多數知識的算法(或者說所有知識,這樣數據就變得多餘)。問題卻在於從數據中得出知識,因為這樣做更簡單,成本也更低,所以學習算法越通用越好。
一個更加極端的候選項就是普通的「或非門」:這是一個邏輯開關,只有輸入的是兩個0時,才會輸出1。本書前面提到,計算機是由晶體管組成的邏輯門構成的,所有的運算都可以簡化為「且」「或」「非」邏輯門的結合。「或非門」只是一個「或」門後面接著一個「非」門:對於分離(「或」)的否定,就像「只要我不挨餓或生病,我就開心」這句話的意思一樣。「且」「或」「非」都可以通過「或非門」得以執行,所以「或非門」可以做所有事情,而實際上這也是一些微型處理器使用的東西。那麼為什麼或非門不是終極算法?當然「或非門」的簡潔無與倫比,但遺憾的是,「或非門」不是終極算法,就像樂高磚不是萬能玩具一樣。對於玩具來說,「或非門」當然可以是一種萬能建築材料,但一堆樂高磚不會自發地將自己組裝成玩具。這個道理同樣適用於其他簡單的運算格式,如Petri網(Petri Net是對離散並行系統的數學表示)或細胞自動機。
這裡將談到更為複雜的候選項。那些所有可以回應搜索的良好的數據引擎,或者統計軟件包裡的簡單算法怎麼樣,可以代替終極算法嗎?它們還不足夠嗎?這個數據引擎和簡單算法是更大的樂高磚,但也僅僅是磚。數據引擎無法發現新東西,只能告訴你它知道的東西。即使數據庫中所有的人都終究會死,它也不會將人會死的概率推廣到其他人身上(數據工程師看到這一點會大吃一驚)。很多數據只是和驗證假設有關,但總得有人先提出假設。統計軟件包可以做線性回歸以及進行其他簡單的程序,但是做這些對它們能學的東西來說,限制很低,無論你提供給它們多少數據。雖然更好的軟件包會跳過統計學和機器學習的灰色地帶,但它們還是無法發現許多種知識。
好了,是時候坦白了:終極算法就是等式U(X)=0。這個等式不僅適合做T恤圖案,還適合做郵票圖案。啊?U(X)=0表達的是某未知數X(可能很複雜)的某函數U(可能很複雜)等於0。每個等式都可以簡化為這種形式,例如,F=ma等於F–ma=0,那麼如果你把F–ma當作F的一個函數U,則U(F)=0。一般情況,X可以是所有輸入的數據,U可以是所有算法,所以可以肯定的是,終極算法和這個函數同樣通用,那麼這個函數就一定是終極算法了。當然,我只是開玩笑,這個函數不是終極算法,但它指出了機器學習中的真正危機:想到一個非常通用的學習算法,裡面卻沒有足夠的東西可以拿來用。
那麼為了可以拿來用,一種學習算法至少要有多少內容呢?物理定律夠了嗎?畢竟,世界上的一切都遵守物理定律(我們相信是這樣的),而且這些定律引出進化論,而通過進化論,又引出與大腦相關的學科。那麼也許終極算法就隱藏在物理定律中,如果是的話,我們就要把它找出來。把數據輸入到物理定律中,不會有新的定律產生。我們可以這樣思考:也許某個領域的主理論就是物理定律,只不過是將該物理定律編成對該領域研究來說更方便的形式。如果是這樣,我們就需要一種算法,可以找到連接該領域數據與該領域理論的捷徑,而不知道物理定律能否在其中起作用。另外一個問題就是,如果物理定律不一樣,終極算法還是有可能在許多例子中找到它們。數學家喜歡說,上帝可以違反物理定律,但他永遠不能違抗邏輯規律。也許的確如此,但邏輯規律是用來演繹的。除了歸納,我們需要的是對等的東西。
機器學習的五大學派
當然,我們不必從零開始尋找終極算法,而有幾十年的機器學習研究可以利用。地球上最聰明的那些人已經把他們的畢生貢獻給發明學習算法,而有些人甚至聲明,他們手上已經有通用的學習算法。我們會站在這些巨人的肩膀上,但對這樣的聲明持保守態度。這樣的聲明會引起相關問題:出現的一種和終極算法相似的算法,只是改變了參數,除了數據還有最小量輸入信息,可以像人類一樣很好地看懂視頻和文本,並在生物學、人類學以及其他學科中有重大發現,如果是這樣,我們怎麼知道已經找到了終極算法?很明顯,如果按照這個標準,即使終極算法真的已經存在,它也沒法證明自己就是終極算法。
關鍵是,終極算法不需要在遇到每個新問題時,都從零開始。這個標準對所有算法來說都太高了,而且它也不像人類所做的那樣。例如,語言無法存在於真空中;如果沒有該學科的相關知識,我們就無法理解一門學科。因此,當學習閱讀時,終極算法可以依靠之前所學的東西來看、聽,以及控制一個機器人。同樣的道理,科學家不會只是盲目地將模型和數據進行配對,他們會利用自己在該領域的知識來解決這個問題。因此,當在生物學領域有所發現時,終極算法會首先閱讀它需要的生物學知識,依靠的是之前就學會的閱讀技巧。終極算法不只是被動地消耗知識,它可以和周圍的環境進行互動,然後積極尋找它想要的數據,就像機器人科學家「亞當」一樣,或者像所有探索世界的孩子一樣。
我們尋找終極算法的過程是複雜且活躍的,因為在機器學習領域存在不同思想的學派,主要學派包括符號學派、聯結學派、進化學派、貝葉斯學派、類推學派。每個學派都有其核心理念以及其關注的特定問題。在綜合幾個學派理念的基礎上,每個學派都已經找到該問題的解決方法,而且有體現本學派的主算法。
對於符號學派來說,所有的信息都可以簡化為操作符號,就像數學家那樣,為瞭解方程,會用其他表達式來代替本來的表達式。符號學者明白你不能從零開始學習:除了數據,你還需要一些原始的知識。他們已經弄明白,如何把先前存在的知識併入學習中,如何結合動態的知識來解決新問題。他們的主算法是逆向演繹,逆向演繹致力於弄明白,為了使演繹進展順利,哪些知識被省略了,然後弄明白是什麼讓主算法變得越來越綜合。
對於聯結學派來說,學習就是大腦所做的事情,因此我們要做的就是對大腦進行逆向演繹。大腦通過調整神經元之間連接的強度來進行學習,關鍵問題是找到哪些連接導致了誤差,以及如何糾正這些誤差。聯結學派的主算法是反向傳播學習算法,該算法將系統的輸出與想要的結果相比較,然後連續一層一層地改變神經元之間的連接,目的是為了使輸出的東西接近想要的東西。
進化學派認為,所有形式的學習都源於自然選擇。如果自然選擇造就我們,那麼它就可以造就一切,我們要做的,就是在計算機上對它進行模仿。進化主義解決的關鍵問題是學習結構:不只是像反向傳播那樣調整參數,它還創造大腦,用來對參數進行微調。進化學派的主算法是基因編程,和自然使有機體交配和進化那樣,基因編程也對計算機程序進行配對和提升。
貝葉斯學派最關注的問題是不確定性。所有掌握的知識都有不確定性,而且學習知識的過程也是一種不確定的推理形式。那麼問題就變成,在不破壞信息的情況下,如何處理嘈雜、不完整甚至自相矛盾的信息。解決的辦法就是運用概率推理,而主算法就是貝葉斯定理及其衍生定理。貝葉斯定理告訴我們,如何將新的證據併入我們的信仰中,而概率推理算法盡可能有效地做到這一點。
對於類推學派來說,學習的關鍵就是要在不同場景中認識到相似性,然後由此推導出其他相似性。如果兩個病人有相似的症狀,那麼也許他們患有相同的疾病。問題的關鍵是,如何判斷兩個事物的相似程度。類推學派的主算法是支持向量機,主算法找出要記憶的經歷,以及弄明白如何將這些經歷結合起來,用來做新的預測。
每個學派對其中心問題的解決方法都是一個輝煌、來之不易的進步,但真正的終極算法應該把5個學派的5個問題都解決,而不是只解決一個。例如,為了治癒癌症,我們要瞭解細胞的代謝網絡:哪些基因調節哪些別的基因,由此產生的蛋白質控制哪些化學反應,以及將新微粒加入混合物中將會對網絡產生什麼影響。從零開始努力學習這些東西顯得有點愚蠢,因為這種做法忽略了過去幾十年生物學家苦心積累的知識。符號學派懂得如何將這些知識與來自DNA測序儀、基因表達芯片等的數據結合起來,並得出結果。只有知識或數據,你得不出這些結果,可是我們通過逆向演繹得到的知識都是純定性的。我們要瞭解的不僅是誰和誰交互,還有可以交互的程度,以及反向傳播如何做到這些。即便如此,如果沒有某個基礎結構,逆向演繹和反向傳播將會迷失在太空中。有了這個基礎結構,它們找到的交互和參數才能構成整體。基因編程可以找到這個基礎結構。這時,有了新陳代謝的完整知識,以及給定病人的相關數據,我們就可以為他找到治療方法。但實際上,我們擁有的知識總是非常不完整的,甚至在有些地方會出錯。即使如此,我們還是要繼續進行,這也就是概率推理的目標。在情形最困難的例子中,病人的癌症看起來與之前的癌症病例有很大不同,而我們掌握的知識對此也束手無策。基於相似性的算法會扭轉大局,方法就是從看似有很大差別的情形中找到相似點,把重點放在相似點上,然後忽略其他不同點。
本書將綜合出一個擁有所有這些功能的終極算法:
我們對終極算法的追尋之旅將讓我們瞭解這5個學派。學派與學派相遇、談判、衝突的地方,也是這個旅程最艱難的部分。每個學派都有自己不同的觀點,我們必須將這些觀點集中起來。機器學習算法和所有科學家一樣,類似盲人和大象:有個盲人摸到象鼻,就以為那是蛇;另一個盲人靠著象腿,以為那是樹;還有一個盲人摸到象牙,以為那是公牛。我們的目標是,摸清楚每個部位,而不是過早下結論。一旦摸到所有部位,我們就努力拼出整個大象的形象。將所有信息集中起來變成解決方案的方法,並不是很容易找到,有些人甚至說不可能找到,但這就是我們要做的事情。
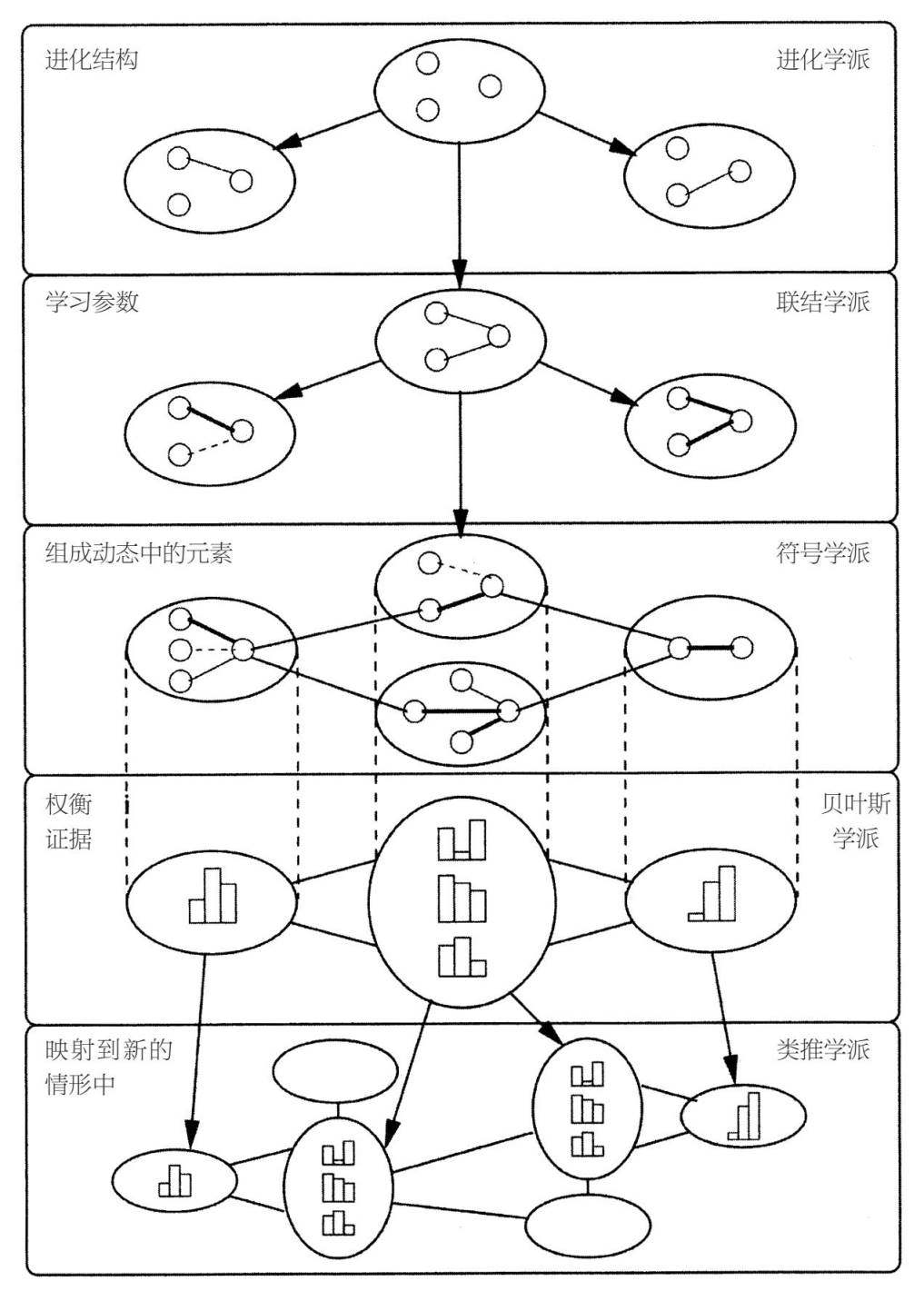
圖2–1
我們要找到的算法還不是終極算法,原因我們在下文會提到,但這已經是所有人能達到的、最接近終極算法的水平了。我們會一直積聚財富,讓大富豪們嫉妒。即便如此,本書僅僅是終極算法傳奇的第一部分。第二部分的主角就是你——親愛的讀者。你的使命(如果你願意接受)就是完成尋找終極算法之旅,然後把戰利品拿回來。在第一部分我將是你卑微的導遊,從這裡出發,走向已知的盡頭。你可能抗議說自己懂的不夠多,或者算法不是你的長處。不要害怕!計算機科學還年輕,而且不像物理學或生物學那樣,要發起一場革命,你並不需要博士學位(可以去問問比爾·蓋茨、謝爾蓋·布林、拉裡·佩奇、馬克·扎克伯克)。洞察力和堅持才是最重要的東西。
你準備好了嗎?我們的旅程由拜訪符號學派開始,這個學派的歷史最漫長。
[4] NP完全問題(non–determinstic polynomial completeness),即多項式複雜程度的非確定性問題。——編者注